I dag er vi glade for å kunngjøre muligheten til å finjustere Code Llama-modeller ved hjelp av Meta Amazon SageMaker JumpStart. Code Llama-familien av store språkmodeller (LLM) er en samling av forhåndstrente og finjusterte kodegenereringsmodeller som varierer i skala fra 7 milliarder til 70 milliarder parametere. Finjusterte Code Llama-modeller gir bedre nøyaktighet og forklarbarhet i forhold til grunnleggende Code Llama-modeller, noe som fremgår av testingen mot HumanEval og MBPP-datasett. Du kan finjustere og distribuere Code Llama-modeller med SageMaker JumpStart ved å bruke Amazon SageMaker Studio UI med noen få klikk eller ved å bruke SageMaker Python SDK. Finjustering av Llama-modeller er basert på skriptene gitt i Lama-oppskrifter GitHub repo fra Meta ved bruk av PyTorch FSDP, PEFT/LoRA og Int8 kvantiseringsteknikker.
I dette innlegget går vi gjennom hvordan du finjusterer Code Llama-fortrente modeller via SageMaker JumpStart gjennom en ett-klikks brukergrensesnitt og SDK-opplevelse tilgjengelig i det følgende GitHub repository.
Hva er SageMaker JumpStart
Med SageMaker JumpStart kan utøvere av maskinlæring (ML) velge fra et bredt utvalg av offentlig tilgjengelige grunnmodeller. ML-utøvere kan distribuere grunnmodeller til dedikerte Amazon SageMaker forekomster fra et nettverksisolert miljø og tilpasse modeller ved hjelp av SageMaker for modellopplæring og distribusjon.
Hva er Code Llama
Code Llama er en kodespesialisert versjon av Lama 2 som ble opprettet ved å videreutdanne Llama 2 på dets kodespesifikke datasett og prøvetaking av flere data fra det samme datasettet i lengre tid. Code Llama har forbedrede kodefunksjoner. Den kan generere kode og naturlig språk om kode, fra både kode og naturlige språkoppfordringer (for eksempel "Skriv meg en funksjon som gir ut Fibonacci-sekvensen"). Du kan også bruke den til kodefullføring og feilsøking. Den støtter mange av de mest populære programmeringsspråkene som brukes i dag, inkludert Python, C++, Java, PHP, Typescript (JavaScript), C#, Bash og mer.
Hvorfor finjustere Code Llama-modeller
Meta publiserte Code Llama ytelsesbenchmarks på HumanEval og MBPP for vanlige kodespråk som Python, Java og JavaScript. Ytelsen til Code Llama Python-modeller på HumanEval demonstrerte varierende ytelse på tvers av forskjellige kodespråk og oppgaver, fra 38 % på 7B Python-modellen til 57 % på 70B Python-modeller. I tillegg har finjusterte Code Llama-modeller på SQL-programmeringsspråk vist bedre resultater, noe som er tydelig i SQL-evalueringsbenchmarks. Disse publiserte benchmarkene fremhever de potensielle fordelene ved å finjustere Code Llama-modeller, noe som muliggjør bedre ytelse, tilpasning og tilpasning til spesifikke kodingsdomener og -oppgaver.
Finjustering uten kode via SageMaker Studio UI
For å begynne å finjustere Llama-modellene dine ved å bruke SageMaker Studio, fullfør følgende trinn:
- På SageMaker Studio-konsollen velger du tjuvstart i navigasjonsruten.
Du vil finne lister over over 350 modeller, alt fra åpen kildekode og proprietære modeller.
- Søk etter Code Llama-modeller.

Hvis du ikke ser Code Llama-modeller, kan du oppdatere SageMaker Studio-versjonen din ved å slå av og starte på nytt. For mer informasjon om versjonsoppdateringer, se Slå av og oppdater Studio-apper. Du kan også finne andre modellvarianter ved å velge Utforsk alle kodegenereringsmodeller eller søker etter Code Llama i søkefeltet.
SageMaker JumpStart støtter for tiden instruksjonsfinjustering for Code Llama-modeller. Følgende skjermbilde viser finjusteringssiden for Code Llama 2 70B-modellen.
- Til Plassering av treningsdatasett, kan du peke på Amazon enkel lagringstjeneste (Amazon S3) bøtte som inneholder opplærings- og valideringsdatasettene for finjustering.
- Angi distribusjonskonfigurasjon, hyperparametere og sikkerhetsinnstillinger for finjustering.
- Velg Tog for å starte finjusteringsjobben på en SageMaker ML-forekomst.
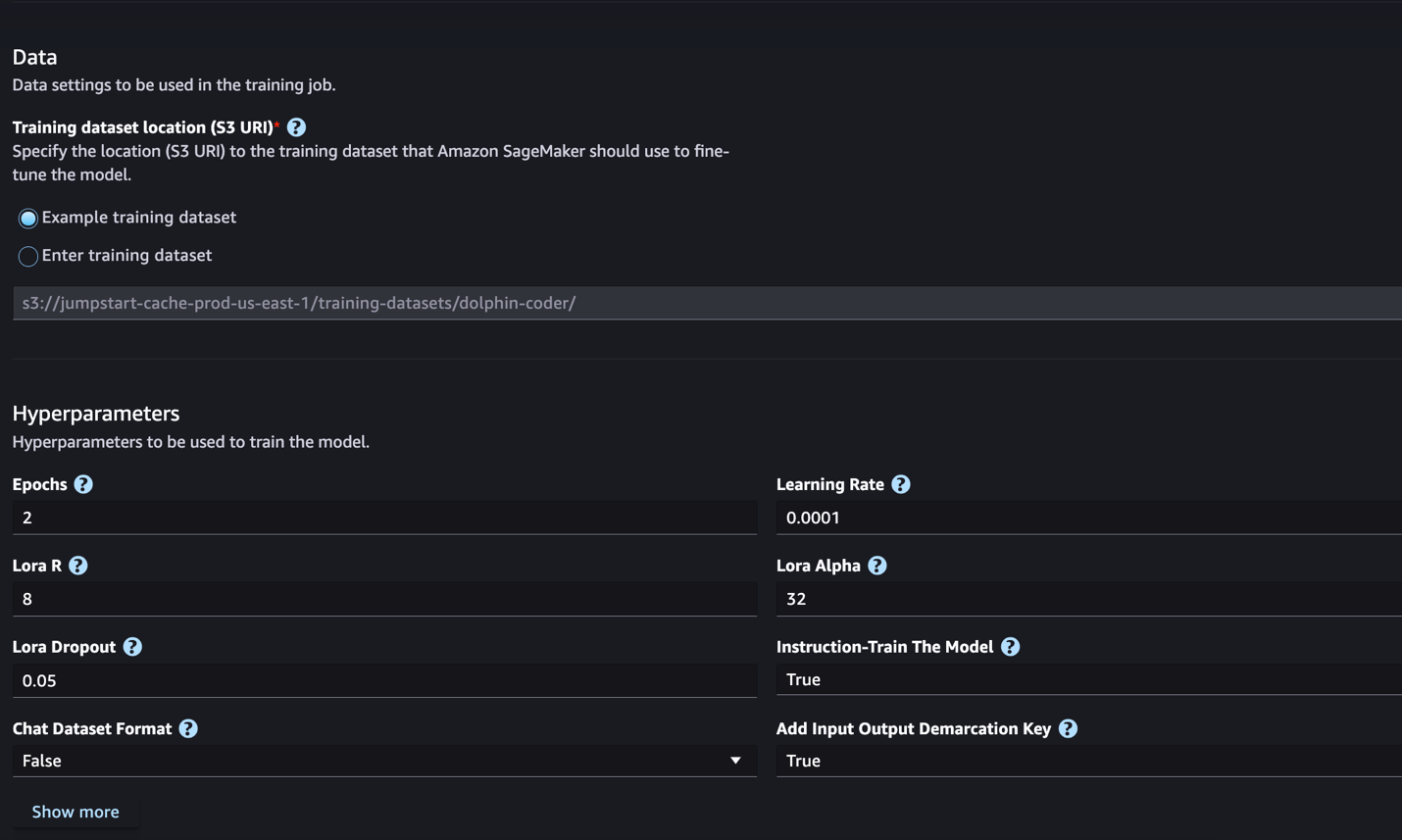
Vi diskuterer datasettformatet du trenger forberede for instruksjonsfinjustering i neste avsnitt.
- Etter at modellen er finjustert, kan du distribuere den ved å bruke modellsiden på SageMaker JumpStart.
Alternativet for å distribuere den finjusterte modellen vil vises når finjusteringen er fullført, som vist i følgende skjermbilde.

Finjuster via SageMaker Python SDK
I denne delen viser vi hvordan du finjusterer Code LIama-modeller ved å bruke SageMaker Python SDK på et instruksjonsformatert datasett. Spesifikt er modellen finjustert for et sett med naturlig språkbehandling (NLP) oppgaver beskrevet ved hjelp av instruksjoner. Dette bidrar til å forbedre modellens ytelse for usynlige oppgaver med null-shot-meldinger.
Fullfør følgende trinn for å fullføre finjusteringsjobben. Du kan få hele finjusteringskoden fra GitHub repository.
La oss først se på datasettformatet som kreves for finjustering av instruksjonen. Treningsdataene skal formateres i et JSON-linjer (.jsonl)-format, der hver linje er en ordbok som representerer et dataeksempel. Alle treningsdata må være i én enkelt mappe. Den kan imidlertid lagres i flere .jsonl-filer. Følgende er et eksempel i JSON-linjeformat:
Opplæringsmappen kan inneholde en template.json fil som beskriver inngangs- og utdataformatene. Følgende er en eksempelmal:
For å matche malen må hver prøve i JSON-linjefilene inkludere system_prompt, questionog response Enger. I denne demonstrasjonen bruker vi Dolphin Coder datasett fra Hugging Face.
Etter at du har klargjort datasettet og lastet det opp til S3-bøtten, kan du begynne å finjustere ved å bruke følgende kode:
Du kan distribuere den finjusterte modellen direkte fra estimatoren, som vist i følgende kode. For detaljer, se notatboken i GitHub repository.
Finjusteringsteknikker
Språkmodeller som Llama er mer enn 10 GB eller til og med 100 GB i størrelse. Finjustering av slike store modeller krever instanser med betydelig høyt CUDA-minne. Videre kan treningen av disse modellene være veldig treg på grunn av størrelsen på modellen. Derfor, for effektiv finjustering, bruker vi følgende optimaliseringer:
- Low-Rank Adaptation (LoRA) – Dette er en type parameter effektiv finjustering (PEFT) for effektiv finjustering av store modeller. Med denne metoden fryser du hele modellen og legger bare til et lite sett med justerbare parametere eller lag i modellen. For eksempel, i stedet for å trene alle 7 milliarder parametere for Llama 2 7B, kan du finjustere mindre enn 1 % av parameterne. Dette bidrar til betydelig reduksjon av minnekravet fordi du bare trenger å lagre gradienter, optimeringstilstander og annen treningsrelatert informasjon for bare 1 % av parameterne. Videre hjelper dette med å redusere treningstiden så vel som kostnadene. For mer informasjon om denne metoden, se LoRA: Lavrangstilpasning av store språkmodeller.
- Int8 kvantisering – Selv med optimaliseringer som LoRA, er modeller som Llama 70B fortsatt for store til å trene. For å redusere minnefotavtrykket under trening, kan du bruke Int8 kvantisering under trening. Kvantisering reduserer vanligvis presisjonen til flyttallsdatatyper. Selv om dette reduserer minnet som kreves for å lagre modellvekter, forringer det ytelsen på grunn av tap av informasjon. Int8 kvantisering bruker bare en kvart presisjon, men medfører ikke forringelse av ytelsen fordi den ikke bare slipper bitene. Den runder dataene fra en type til en annen. For å lære om Int8 kvantisering, se LLM.int8(): 8-biters matrisemultiplikasjon for transformatorer i skala.
- Fullt delte data parallelt (FSDP) – Dette er en type dataparallell treningsalgoritme som sønderdeler modellens parametere på tvers av dataparallelle arbeidere og kan eventuelt overføre deler av treningsberegningen til CPU-ene. Selv om parametrene er delt på tvers av forskjellige GPUer, er beregningen av hver mikrobatch lokal for GPU-arbeideren. Den skjærer parametere mer jevnt og oppnår optimalisert ytelse via kommunikasjon og beregningsoverlapping under trening.
Tabellen nedenfor oppsummerer detaljene for hver modell med forskjellige innstillinger.
| Modell | Standardinnstilling | LORA + FSDP | LORA + Ingen FSDP | Int8 Kvantisering + LORA + Ingen FSDP |
| Kode Llama 2 7B | LORA + FSDP | Ja | Ja | Ja |
| Kode Llama 2 13B | LORA + FSDP | Ja | Ja | Ja |
| Kode Llama 2 34B | INT8 + LORA + INGEN FSDP | Nei | Nei | Ja |
| Kode Llama 2 70B | INT8 + LORA + INGEN FSDP | Nei | Nei | Ja |
Finjustering av Llama-modeller er basert på skript levert av følgende GitHub repo.
Støttede hyperparametre for trening
Code Llama 2 finjustering støtter en rekke hyperparametre, som hver kan påvirke minnekravet, treningshastigheten og ytelsen til den finjusterte modellen:
- epoke – Antall passeringer som finjusteringsalgoritmen tar gjennom treningsdatasettet. Må være et heltall større enn 1. Standard er 5.
- learning_rate – Hastigheten som modellvektene oppdateres med etter å ha jobbet gjennom hver gruppe med treningseksempler. Må være en positiv float større enn 0. Standard er 1e-4.
- instruction_tuned – Om man skal instruere-trene modellen eller ikke. Må være
TrueorFalse. Standard erFalse. - per_device_train_batch_size – Batchstørrelsen per GPU-kjerne/CPU for trening. Må være et positivt heltall. Standard er 4.
- per_device_eval_batch_size – Batchstørrelsen per GPU-kjerne/CPU for evaluering. Må være et positivt heltall. Standard er 1.
- max_train_samples – For feilsøkingsformål eller raskere opplæring, avkort antall treningseksempler til denne verdien. Verdi -1 betyr å bruke alle treningsprøvene. Må være et positivt heltall eller -1. Standard er -1.
- max_val_samples – For feilsøkingsformål eller raskere opplæring, avkort antall valideringseksempler til denne verdien. Verdi -1 betyr å bruke alle valideringsprøvene. Må være et positivt heltall eller -1. Standard er -1.
- max_input_length – Maksimal total inndatasekvenslengde etter tokenisering. Sekvenser lengre enn dette vil bli avkortet. Hvis -1,
max_input_lengther satt til minimum 1024 og maksimal modelllengde definert av tokenizeren. Hvis satt til en positiv verdi,max_input_lengther satt til minimum av den angitte verdien ogmodel_max_lengthdefinert av tokenizeren. Må være et positivt heltall eller -1. Standard er -1. - validation_split_ratio – Hvis valideringskanalen er
none, må forholdet mellom togvalideringsdelingen fra togdataene være mellom 0–1. Standard er 0.2. - train_data_split_seed – Hvis valideringsdata ikke er tilstede, fikser dette den tilfeldige oppdelingen av inndata treningsdata til trenings- og valideringsdata som brukes av algoritmen. Må være et heltall. Standard er 0.
- forbehandling_antall_arbeidere – Antall prosesser som skal brukes til forbehandling. Hvis
None, brukes hovedprosessen til forbehandling. Standard erNone. - lora_r – Lora R. Må være et positivt heltall. Standard er 8.
- lora_alpha – Lora Alpha. Må være et positivt heltall. Standard er 32
- lora_frafall – Lora Dropout. må være en positiv flyte mellom 0 og 1. Standard er 0.05.
- int8_kvantisering - Hvis
True, modellen er lastet med 8-bits presisjon for trening. Standard for 7B og 13B erFalse. Standard for 70B erTrue. - aktivere_fsdp – Hvis det er sant, bruker trening FSDP. Standard for 7B og 13B er True. Standard for 70B er False. Noter det
int8_quantizationstøttes ikke med FSDP.
Når du velger hyperparametere, bør du vurdere følgende:
- Stille
int8_quantization=Truereduserer hukommelseskravet og fører til raskere trening. - Avtagende
per_device_train_batch_sizeogmax_input_lengthreduserer minnekravet og kan derfor kjøres på mindre forekomster. Innstilling av svært lave verdier kan imidlertid øke treningstiden. - Hvis du ikke bruker Int8 kvantisering (
int8_quantization=False), bruk FSDP (enable_fsdp=True) for raskere og effektiv trening.
Støttede instanstyper for trening
Tabellen nedenfor oppsummerer de støttede forekomsttypene for opplæring av ulike modeller.
| Modell | Standard forekomsttype | Støttede forekomsttyper |
| Kode Llama 2 7B | ml.g5.12xlarge |
ml.g5.12xlarge, ml.g5.24xlarge, ml.g5.48xlarge, ml.p3dn.24xlarge, ml.g4dn.12xlarge |
| Kode Llama 2 13B | ml.g5.12xlarge |
ml.g5.24xlarge, ml.g5.48xlarge, ml.p3dn.24xlarge, ml.g4dn.12xlarge |
| Kode Llama 2 70B | ml.g5.48xlarge |
ml.g5.48xlarge ml.p4d.24xlarge |
Når du velger forekomsttype, bør du vurdere følgende:
- G5-forekomster gir den mest effektive opplæringen blant forekomsttypene som støttes. Derfor, hvis du har G5-forekomster tilgjengelig, bør du bruke dem.
- Treningstiden avhenger i stor grad av mengden av antall GPUer og CUDA-minnet som er tilgjengelig. Derfor er opplæring på instanser med samme antall GPUer (for eksempel ml.g5.2xlarge og ml.g5.4xlarge) omtrent det samme. Derfor kan du bruke den billigere instansen til trening (ml.g5.2xlarge).
- Når du bruker p3-forekomster, vil trening bli utført med 32-biters presisjon fordi bfloat16 ikke støttes på disse forekomstene. Derfor vil treningsjobben forbruke dobbelt så mye CUDA-minne når man trener på p3-instanser sammenlignet med g5-instanser.
For å lære om kostnadene for opplæring per forekomst, se Amazon EC2 G5-forekomster.
Evaluering
Evaluering er et viktig skritt for å vurdere ytelsen til finjusterte modeller. Vi presenterer både kvalitative og kvantitative evalueringer for å vise forbedring av finjusterte modeller i forhold til ikke-finjusterte. I kvalitativ evaluering viser vi et eksempelsvar fra både finjusterte og ikke-finjusterte modeller. I kvantitativ evaluering bruker vi HumanEval, en testsuite utviklet av OpenAI for å generere Python-kode for å teste evnene til å produsere korrekte og nøyaktige resultater. HumanEval-depotet er under MIT-lisens. Vi finjusterte Python-varianter av alle Code LIama-modeller over forskjellige størrelser (Code LIama Python 7B, 13B, 34B og 70B på Dolphin Coder datasett), og presenter evalueringsresultatene i de følgende avsnittene.
Kvalitativ evaluering
Med den finjusterte modellen utplassert, kan du begynne å bruke endepunktet til å generere kode. I det følgende eksempelet presenterer vi svar fra både basis- og finjusterte Code LIama 34B Python-varianter på en testprøve i Dolphin Coder datasett:
Den finjusterte Code Llama-modellen genererer, i tillegg til å gi koden for den foregående spørringen, en detaljert forklaring av tilnærmingen og en pseudokode.
Kode Llama 34b Python Ikke-finjustert respons:
Kode Llama 34B Python finjustert respons
Bakkenes sannhet
Interessant nok gir vår finjusterte versjon av Code Llama 34B Python en dynamisk programmeringsbasert løsning til den lengste palindromiske understrengen, som er forskjellig fra løsningen gitt i grunnsannheten fra det valgte testeksemplet. Vår finjusterte modell begrunner og forklarer den dynamiske programmeringsbaserte løsningen i detalj. På den annen side hallusinerer den ikke-finjusterte modellen potensielle utganger rett etter print uttalelse (vist i venstre celle) fordi utgangen axyzzyx er ikke det lengste palindromet i den gitte strengen. Når det gjelder tidskompleksitet, er den dynamiske programmeringsløsningen generelt bedre enn den første tilnærmingen. Den dynamiske programmeringsløsningen har en tidskompleksitet på O(n^2), der n er lengden på inngangsstrengen. Dette er mer effektivt enn den opprinnelige løsningen fra den ikke-finjusterte modellen, som også hadde en kvadratisk tidskompleksitet på O(n^2), men med en mindre optimalisert tilnærming.
Dette ser lovende ut! Husk at vi bare finjusterte Code LIama Python-varianten med 10 % av Dolphin Coder datasett. Det er mye mer å utforske!
Til tross for grundige instruksjoner i svaret, må vi fortsatt undersøke riktigheten av Python-koden som er gitt i løsningen. Deretter bruker vi et evalueringsrammeverk kalt Menneskelig Eval å kjøre integrasjonstester på den genererte responsen fra Code LIama for å systematisk undersøke kvaliteten.
Kvantitativ evaluering med HumanEval
HumanEval er en evalueringssele for å evaluere en LLMs problemløsningsevne på Python-baserte kodingsproblemer, som beskrevet i artikkelen Evaluering av store språkmodeller trent på kode. Nærmere bestemt består den av 164 originale Python-baserte programmeringsproblemer som vurderer en språkmodells evne til å generere kode basert på gitt informasjon som funksjonssignatur, docstring, body og enhetstester.
For hvert Python-basert programmeringsspørsmål sender vi det til en Code LIama-modell distribuert på et SageMaker-endepunkt for å få k svar. Deretter kjører vi hver av de k-svarene på integrasjonstestene i HumanEval-depotet. Hvis noen respons fra k-svarene består integrasjonstestene, regner vi med at testtilfellet er vellykket; ellers mislyktes. Deretter gjentar vi prosessen for å beregne forholdet mellom vellykkede saker som den endelige evalueringspoengsummen pass@k. Etter standard praksis setter vi k som 1 i vår evaluering, for å kun generere ett svar per spørsmål og teste om det består integrasjonstesten.
Følgende er en eksempelkode for bruk av HumanEval-depot. Du kan få tilgang til datasettet og generere et enkelt svar ved å bruke et SageMaker-endepunkt. For detaljer, se notatboken i GitHub repository.
Tabellen nedenfor viser forbedringene av de finjusterte Code LIama Python-modellene i forhold til de ikke-finjusterte modellene på tvers av forskjellige modellstørrelser. For å sikre korrekthet, distribuerer vi også de ikke-finjusterte Code LIama-modellene i SageMaker-endepunkter og kjører gjennom Human Eval-evalueringer. De pass@1 tall (den første raden i følgende tabell) samsvarer med de rapporterte tallene i Code Llama-forskningsoppgave. Inferensparametrene er konsekvent satt som "parameters": {"max_new_tokens": 384, "temperature": 0.2}.
Som vi kan se fra resultatene, viser alle de finjusterte Code LIama Python-variantene betydelig forbedring i forhold til de ikke-finjusterte modellene. Spesielt overgår Code LIama Python 70B den ikke-finjusterte modellen med omtrent 12 %.
| . | 7B Python | 13B Python | 34B | 34B Python | 70B Python |
| Pre-trent modellytelse (pass@1) | 38.4 | 43.3 | 48.8 | 53.7 | 57.3 |
| Finjustert modellytelse (pass@1) | 45.12 | 45.12 | 59.1 | 61.5 | 69.5 |
Nå kan du prøve å finjustere Code LIama-modeller på ditt eget datasett.
Rydd opp
Hvis du bestemmer deg for at du ikke lenger vil holde SageMaker-endepunktet i gang, kan du slette det ved å bruke AWS SDK for Python (Boto3), AWS kommandolinjegrensesnitt (AWS CLI), eller SageMaker-konsoll. For mer informasjon, se Slett endepunkter og ressurser. I tillegg kan du slå av SageMaker Studio-ressursene som ikke lenger er nødvendig.
konklusjonen
I dette innlegget diskuterte vi finjustering av Metas Code Llama 2-modeller ved å bruke SageMaker JumpStart. Vi viste at du kan bruke SageMaker JumpStart-konsollen i SageMaker Studio eller SageMaker Python SDK for å finjustere og distribuere disse modellene. Vi diskuterte også finjusteringsteknikken, forekomsttyper og støttede hyperparametre. I tillegg skisserte vi anbefalinger for optimalisert trening basert på ulike tester vi gjennomførte. Som vi kan se fra disse resultatene av finjustering av tre modeller over to datasett, forbedrer finjustering oppsummeringen sammenlignet med ikke-finjusterte modeller. Som et neste trinn kan du prøve å finjustere disse modellene på ditt eget datasett ved å bruke koden gitt i GitHub-depotet for å teste og benchmarke resultatene for brukstilfellene dine.
Om forfatterne
 Dr. Xin Huang er Senior Applied Scientist for Amazon SageMaker JumpStart og Amazon SageMaker innebygde algoritmer. Han fokuserer på å utvikle skalerbare maskinlæringsalgoritmer. Hans forskningsinteresser er innen naturlig språkbehandling, forklarbar dyp læring på tabelldata og robust analyse av ikke-parametrisk rom-tid-klynger. Han har publisert mange artikler i ACL, ICDM, KDD-konferanser og Royal Statistical Society: Series A.
Dr. Xin Huang er Senior Applied Scientist for Amazon SageMaker JumpStart og Amazon SageMaker innebygde algoritmer. Han fokuserer på å utvikle skalerbare maskinlæringsalgoritmer. Hans forskningsinteresser er innen naturlig språkbehandling, forklarbar dyp læring på tabelldata og robust analyse av ikke-parametrisk rom-tid-klynger. Han har publisert mange artikler i ACL, ICDM, KDD-konferanser og Royal Statistical Society: Series A.
 Vishaal Yalamanchali er en Startup Solutions Architect som jobber med generativ AI, robotikk og autonome kjøretøyselskaper i tidlig stadium. Vishaal jobber med kundene sine for å levere banebrytende ML-løsninger og er personlig interessert i forsterkende læring, LLM-evaluering og kodegenerering. Før AWS var Vishaal en undergraduate ved UCI, med fokus på bioinformatikk og intelligente systemer.
Vishaal Yalamanchali er en Startup Solutions Architect som jobber med generativ AI, robotikk og autonome kjøretøyselskaper i tidlig stadium. Vishaal jobber med kundene sine for å levere banebrytende ML-løsninger og er personlig interessert i forsterkende læring, LLM-evaluering og kodegenerering. Før AWS var Vishaal en undergraduate ved UCI, med fokus på bioinformatikk og intelligente systemer.
 Meenakshisundaram Thandavarayan jobber for AWS som AI/ML-spesialist. Han har en lidenskap for å designe, skape og fremme menneskesentrerte data- og analyseopplevelser. Meena fokuserer på å utvikle bærekraftige systemer som leverer målbare, konkurransefortrinn for strategiske kunder av AWS. Meena er en koblings- og designtenker, og streber etter å drive virksomheter til nye måter å jobbe på gjennom innovasjon, inkubasjon og demokratisering.
Meenakshisundaram Thandavarayan jobber for AWS som AI/ML-spesialist. Han har en lidenskap for å designe, skape og fremme menneskesentrerte data- og analyseopplevelser. Meena fokuserer på å utvikle bærekraftige systemer som leverer målbare, konkurransefortrinn for strategiske kunder av AWS. Meena er en koblings- og designtenker, og streber etter å drive virksomheter til nye måter å jobbe på gjennom innovasjon, inkubasjon og demokratisering.
 Dr. Ashish Khetan er en Senior Applied Scientist med Amazon SageMaker innebygde algoritmer og hjelper til med å utvikle maskinlæringsalgoritmer. Han fikk sin doktorgrad fra University of Illinois Urbana-Champaign. Han er en aktiv forsker innen maskinlæring og statistisk inferens, og har publisert mange artikler på NeurIPS, ICML, ICLR, JMLR, ACL og EMNLP-konferanser.
Dr. Ashish Khetan er en Senior Applied Scientist med Amazon SageMaker innebygde algoritmer og hjelper til med å utvikle maskinlæringsalgoritmer. Han fikk sin doktorgrad fra University of Illinois Urbana-Champaign. Han er en aktiv forsker innen maskinlæring og statistisk inferens, og har publisert mange artikler på NeurIPS, ICML, ICLR, JMLR, ACL og EMNLP-konferanser.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://aws.amazon.com/blogs/machine-learning/fine-tune-code-llama-on-amazon-sagemaker-jumpstart/

