Dette innlegget er skrevet sammen med Chaoyang He, Al Nevarez og Salman Avestimehr fra FedML.
Mange organisasjoner implementerer maskinlæring (ML) for å forbedre deres forretningsbeslutninger gjennom automatisering og bruk av store distribuerte datasett. Med økt tilgang til data har ML potensial til å gi enestående forretningsinnsikt og muligheter. Imidlertid utgjør deling av rå, ikke-renset sensitiv informasjon på tvers av forskjellige steder betydelig sikkerhets- og personvernrisiko, spesielt i regulerte bransjer som helsevesenet.
For å løse dette problemet, er federated learning (FL) en desentralisert og samarbeidende ML-treningsteknikk som tilbyr datavern samtidig som nøyaktighet og troskap opprettholdes. I motsetning til tradisjonell ML-trening, foregår FL-trening innenfor et isolert klientsted ved hjelp av en uavhengig sikker økt. Klienten deler bare utgangsmodellparametrene sine med en sentralisert server, kjent som treningskoordinatoren eller aggregeringsserveren, og ikke de faktiske dataene som brukes til å trene modellen. Denne tilnærmingen lindrer mange bekymringer om personvern samtidig som den muliggjør effektivt samarbeid om modellopplæring.
Selv om FL er et skritt mot å oppnå bedre datavern og sikkerhet, er det ikke en garantert løsning. Usikre nettverk som mangler tilgangskontroll og kryptering kan fortsatt avsløre sensitiv informasjon for angripere. I tillegg kan lokalt trent informasjon avsløre private data hvis den rekonstrueres gjennom et slutningsangrep. For å redusere disse risikoene bruker FL-modellen personlig tilpassede treningsalgoritmer og effektiv maskering og parameterisering før de deler informasjon med treningskoordinatoren. Sterk nettverkskontroll på lokale og sentraliserte steder kan ytterligere redusere slutnings- og eksfiltrasjonsrisiko.
I dette innlegget deler vi en FL-tilnærming ved å bruke FedML, Amazon Elastic Kubernetes-tjeneste (Amazon EKS), og Amazon SageMaker for å forbedre pasientresultatene samtidig som man tar opp datavern og sikkerhetsproblemer.
Behovet for føderert læring i helsevesenet
Helsevesenet er sterkt avhengig av distribuerte datakilder for å gi nøyaktige spådommer og vurderinger om pasientbehandling. Å begrense de tilgjengelige datakildene for å beskytte personvernet påvirker resultatnøyaktigheten negativt og, til syvende og sist, kvaliteten på pasientbehandlingen. Derfor skaper ML utfordringer for AWS-kunder som trenger å sikre personvern og sikkerhet på tvers av distribuerte enheter uten å kompromittere pasientresultatene.
Helseorganisasjoner må navigere etter strenge overholdelsesbestemmelser, slik som Health Insurance Portability and Accountability Act (HIPAA) i USA, mens de implementerer FL-løsninger. Å sikre personvern, sikkerhet og overholdelse av data blir enda mer kritisk i helsevesenet, og krever robust kryptering, tilgangskontroller, revisjonsmekanismer og sikre kommunikasjonsprotokoller. I tillegg inneholder helsedatasett ofte komplekse og heterogene datatyper, noe som gjør datastandardisering og interoperabilitet til en utfordring i FL-innstillinger.
Bruk saksoversikt
Brukssaken som er skissert i dette innlegget er hjertesykdomsdata i forskjellige organisasjoner, hvor en ML-modell vil kjøre klassifiseringsalgoritmer for å forutsi hjertesykdom hos pasienten. Fordi disse dataene er på tvers av organisasjoner, bruker vi forent læring for å samle funnene.
De Hjertesykdom datasett fra University of California Irvines Machine Learning Repository er et mye brukt datasett for kardiovaskulær forskning og prediktiv modellering. Den består av 303 prøver, som hver representerer en pasient, og inneholder en kombinasjon av kliniske og demografiske attributter, samt tilstedeværelse eller fravær av hjertesykdom.
Dette multivariate datasettet har 76 attributter i pasientinformasjonen, hvorav 14 attributter er mest brukt for å utvikle og evaluere ML-algoritmer for å forutsi tilstedeværelsen av hjertesykdom basert på de gitte attributtene.
FedML rammeverk
Det er et bredt utvalg av FL-rammeverk, men vi bestemte oss for å bruke FedML rammeverk for denne brukssaken fordi den er åpen kildekode og støtter flere FL-paradigmer. FedML tilbyr et populært åpen kildekode-bibliotek, MLOps-plattform og applikasjonsøkosystem for FL. Disse forenkler utvikling og distribusjon av FL-løsninger. Den gir en omfattende pakke med verktøy, biblioteker og algoritmer som gjør det mulig for forskere og praktikere å implementere og eksperimentere med FL-algoritmer i et distribuert miljø. FedML adresserer utfordringene med datavern, kommunikasjon og modellaggregering i FL, og tilbyr et brukervennlig grensesnitt og tilpassbare komponenter. Med sitt fokus på samarbeid og kunnskapsdeling, har FedML som mål å akselerere innføringen av FL og drive innovasjon på dette nye feltet. FedML-rammeverket er modellagnostisk, inkludert nylig lagt til støtte for store språkmodeller (LLM). For mer informasjon, se Slippe FedLLM: Bygg dine egne store språkmodeller på proprietære data ved å bruke FedML-plattformen.
FedML blekksprut
Systemhierarki og heterogenitet er en nøkkelutfordring i virkelige FL-brukstilfeller, der forskjellige datasiloer kan ha ulik infrastruktur med CPU og GPUer. I slike scenarier kan du bruke FedML blekksprut.
FedML Octopus er den industrielle plattformen til cross-silo FL for trening på tvers av organisasjoner og kontoer. Sammen med FedML MLOps, gjør det utviklere eller organisasjoner i stand til å gjennomføre åpent samarbeid fra hvor som helst i alle skalaer på en sikker måte. FedML Octopus kjører et distribuert treningsparadigme inne i hver datasilo og bruker synkron eller asynkron trening.
FedML MLOps
FedML MLOps muliggjør lokal utvikling av kode som senere kan distribueres hvor som helst ved hjelp av FedML-rammeverk. Før du starter opplæring, må du opprette en FedML-konto, samt opprette og laste opp server- og klientpakkene i FedML Octopus. For flere detaljer, se trinn og Vi introduserer FedML Octopus: skalere føderert læring til produksjon med forenklede MLOps.
Løsningsoversikt
Vi distribuerer FedML i flere EKS-klynger integrert med SageMaker for eksperimentsporing. Vi bruker Amazon EKS Blueprints for Terraform å distribuere den nødvendige infrastrukturen. EKS Blueprints hjelper med å komponere komplette EKS-klynger som er fullt oppstartet med den operasjonelle programvaren som er nødvendig for å distribuere og betjene arbeidsbelastninger. Med EKS Blueprints blir konfigurasjonen for ønsket tilstand av EKS-miljøet, slik som kontrollplanet, arbeidernoder og Kubernetes-tillegg, beskrevet som en infrastruktur som kode (IaC) blueprint. Etter at en blåkopi er konfigurert, kan den brukes til å skape konsistente miljøer på tvers av flere AWS-kontoer og regioner ved hjelp av kontinuerlig distribusjonsautomatisering.
Innholdet som deles i dette innlegget gjenspeiler virkelige situasjoner og opplevelser, men det er viktig å merke seg at utplasseringen av disse situasjonene på forskjellige steder kan variere. Selv om vi bruker én enkelt AWS-konto med separate VPC-er, er det viktig å forstå at individuelle omstendigheter og konfigurasjoner kan variere. Derfor bør informasjonen som gis brukes som en generell veiledning og kan kreve tilpasning basert på spesifikke krav og lokale forhold.
Følgende diagram illustrerer løsningsarkitekturen.
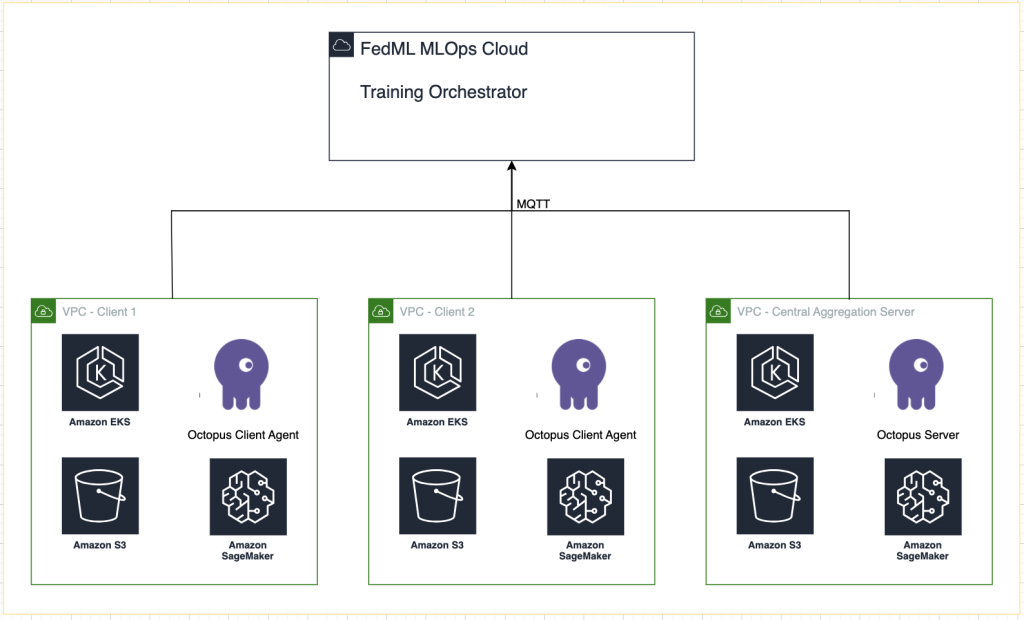
I tillegg til sporingen som tilbys av FedML MLOps for hvert treningsløp, bruker vi Amazon SageMaker-eksperimenter å spore ytelsen til hver klientmodell og den sentraliserte (aggregator)modellen.
SageMaker Experiments er en funksjon i SageMaker som lar deg lage, administrere, analysere og sammenligne ML-eksperimentene dine. Ved å registrere eksperimentdetaljer, parametere og resultater, kan forskere nøyaktig reprodusere og validere arbeidet sitt. Det gir mulighet for effektiv sammenligning og analyse av ulike tilnærminger, noe som fører til informert beslutningstaking. I tillegg letter sporingseksperimenter iterativ forbedring ved å gi innsikt i utviklingen av modeller og gjøre det mulig for forskere å lære av tidligere iterasjoner, og til slutt akselerere utviklingen av mer effektive løsninger.
Vi sender følgende til SageMaker Experiments for hver kjøring:
- Modellevalueringsberegninger – Treningstap og Area Under the Curve (AUC)
- Hyperparametere – Epoke, læringshastighet, batchstørrelse, optimalisering og vektreduksjon
Forutsetninger
For å følge med på dette innlegget, bør du ha følgende forutsetninger:
Distribuere løsningen
For å begynne, klone depotet som er vert for eksempelkoden lokalt:
Deretter distribuerer use case-infrastrukturen ved å bruke følgende kommandoer:
Terraform-malen kan ta 20–30 minutter å distribuere fullstendig. Etter at den er distribuert, følg trinnene i de neste delene for å kjøre FL-applikasjonen.
Opprett en MLOps-distribusjonspakke
Som en del av FedML-dokumentasjonen må vi lage klient- og serverpakkene, som MLOps-plattformen vil distribuere til serveren og klientene for å begynne opplæringen.
For å lage disse pakkene, kjør følgende skript som finnes i rotkatalogen:
Dette vil opprette de respektive pakkene i følgende katalog i prosjektets rotkatalog:
Last opp pakkene til FedML MLOps-plattformen
Fullfør følgende trinn for å laste opp pakkene:
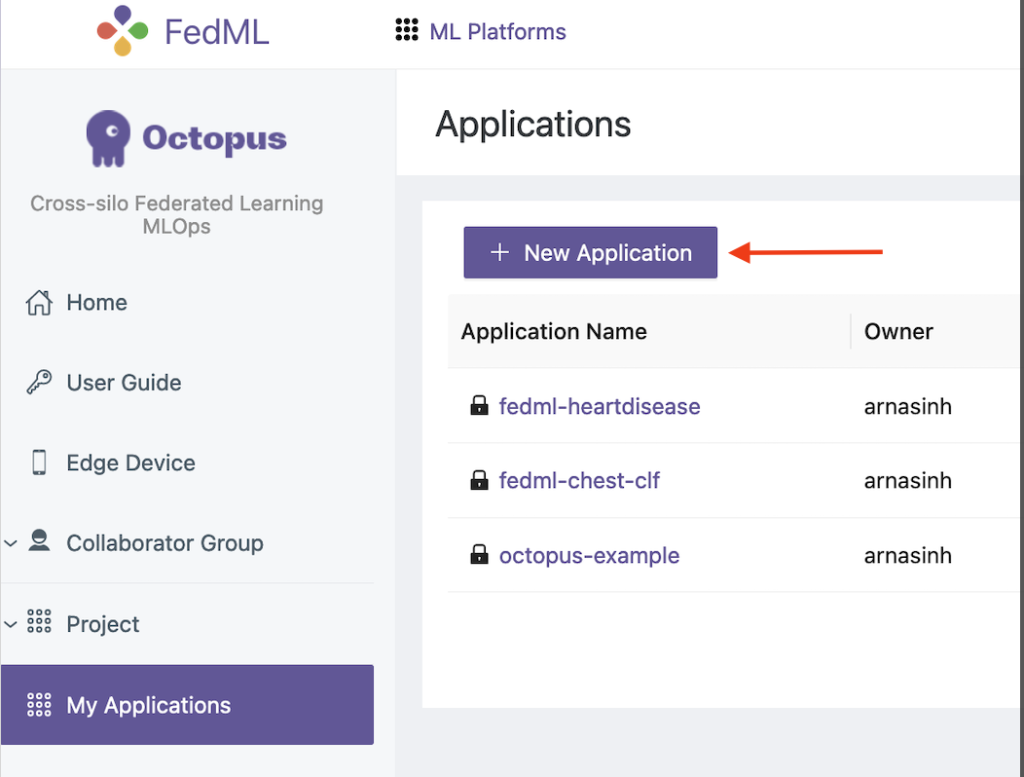
- På FedML UI velger du Mine applikasjoner i navigasjonsruten.
- Velg Ny applikasjon.
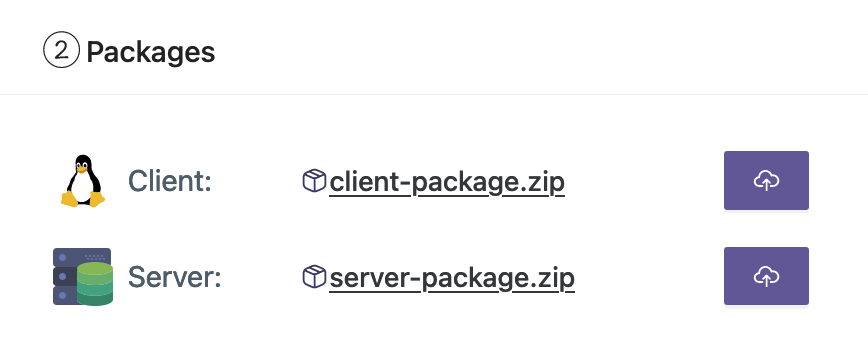
- Last opp klient- og serverpakkene fra arbeidsstasjonen.
- Du kan også justere hyperparametrene eller opprette nye.

Utløs forbundstrening
For å kjøre forent trening, fullfør følgende trinn:
- På FedML UI velger du Prosjektliste i navigasjonsruten.
- Velg Lag et nytt prosjekt.
- Skriv inn et gruppenavn og et prosjektnavn, og velg deretter OK.

- Velg det nyopprettede prosjektet og velg Opprett nytt løp for å utløse et treningsløp.
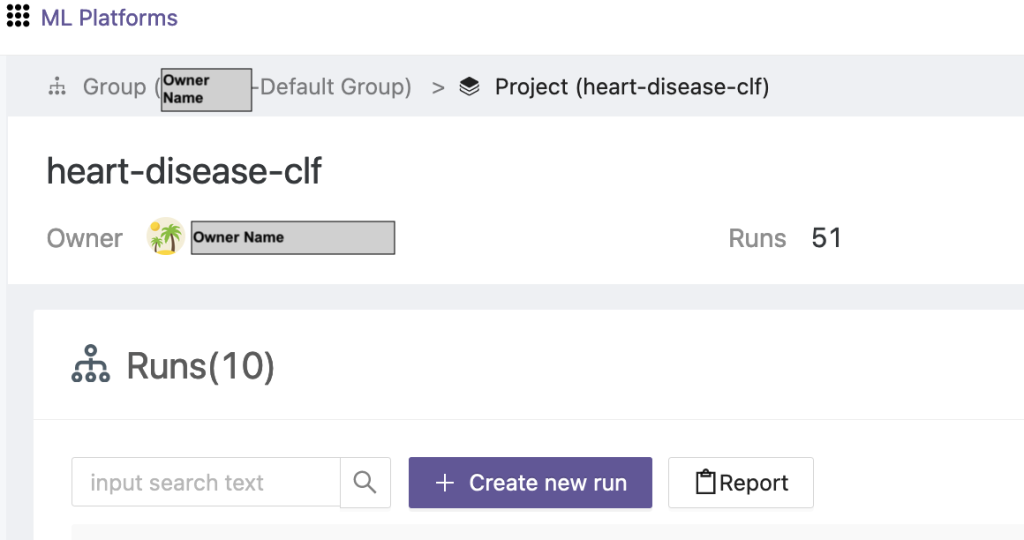
- Velg edge-klientenhetene og den sentrale aggregatorserveren for denne treningskjøringen.
- Velg applikasjonen du opprettet i de forrige trinnene.

- Oppdater noen av hyperparametrene eller bruk standardinnstillingene.
- Velg Start å begynne å trene.

- Velg treningsstatus og vent til treningskjøringen er fullført. Du kan også navigere til de tilgjengelige fanene.
- Når opplæringen er fullført, velg System fanen for å se treningstidsvarighetene på edge-serverne og aggregeringshendelser.
Se resultater og eksperimentdetaljer
Når opplæringen er fullført, kan du se resultatene ved hjelp av FedML og SageMaker.
På FedML UI, på Modeller fanen, kan du se aggregator- og klientmodellen. Du kan også laste ned disse modellene fra nettsiden.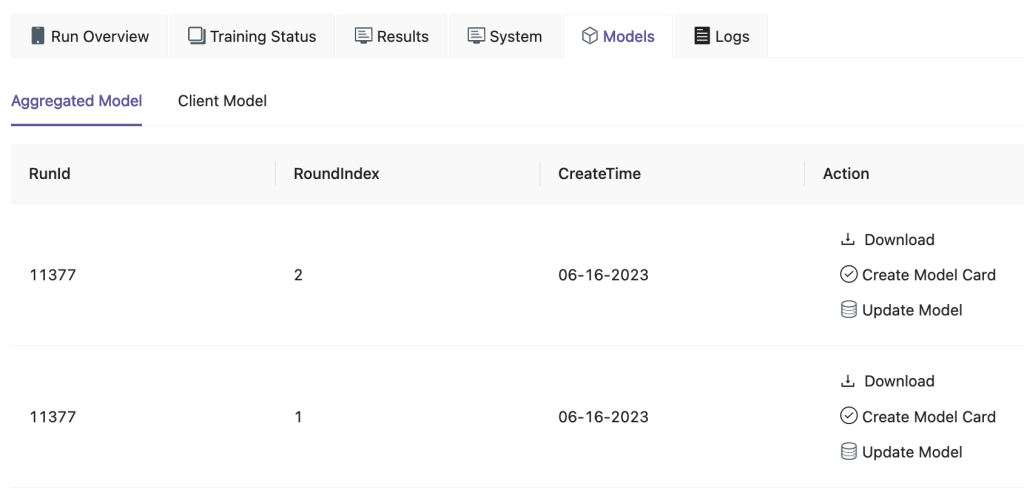
Du kan også logge inn på Amazon SageMaker Studio Og velg eksperimenter i navigasjonsruten.
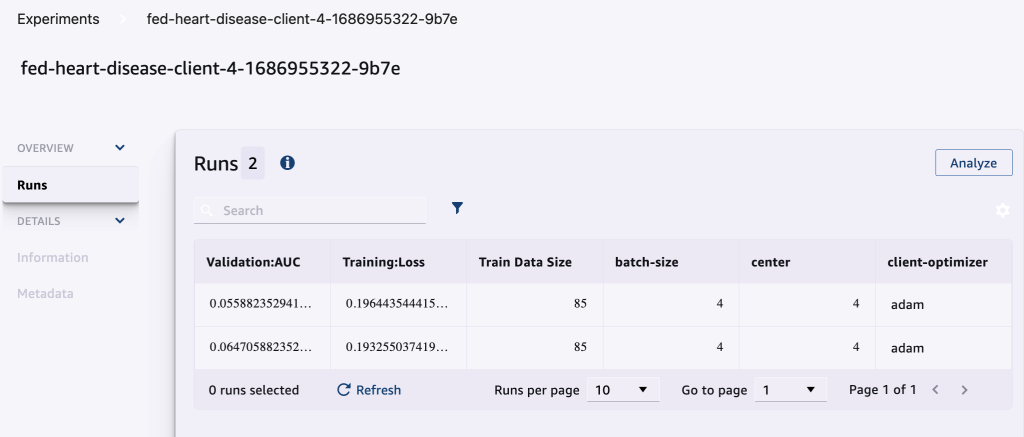
Følgende skjermbilde viser de loggede eksperimentene.
Eksperimentsporingskode
I denne delen utforsker vi koden som integrerer SageMaker-eksperimentsporing med FL-rammetrening.
Åpne følgende mappe i et redigeringsprogram du velger, for å se redigeringene av koden for å injisere SageMaker-eksperimentsporingskode som en del av opplæringen:
For sporing av treningen, vi lage et SageMaker-eksperiment med parametere og beregninger logget ved hjelp av log_parameter og log_metric kommando som beskrevet i følgende kodeeksempel.
En oppføring i config/fedml_config.yaml filen erklærer eksperimentprefikset, som det refereres til i koden for å lage unike eksperimentnavn: sm_experiment_name: "fed-heart-disease". Du kan oppdatere denne til hvilken som helst verdi du ønsker.
Se for eksempel følgende kode for heart_disease_trainer.py, som brukes av hver klient for å trene modellen på sitt eget datasett:
For hver klientkjøring spores eksperimentdetaljene ved hjelp av følgende kode i heart_disease_trainer.py:
På samme måte kan du bruke koden i heart_disease_aggregator.py å kjøre en test på lokale data etter oppdatering av modellvektene. Detaljene logges etter hver kommunikasjonskjøring med klientene.
Rydd opp
Når du er ferdig med løsningen, sørg for å rydde opp i ressursene som brukes for å sikre effektiv ressursutnyttelse og kostnadsstyring, og unngå unødvendige utgifter og ressurssløsing. Aktiv opprydding i miljøet, som sletting av ubrukte instanser, stopp av unødvendige tjenester og fjerning av midlertidige data, bidrar til en ren og organisert infrastruktur. Du kan bruke følgende kode for å rydde opp i ressursene dine:
Oppsummering
Ved å bruke Amazon EKS som infrastruktur og FedML som rammeverk for FL, er vi i stand til å tilby et skalerbart og administrert miljø for opplæring og distribusjon av delte modeller samtidig som vi respekterer datavernet. Med den desentraliserte karakteren til FL kan organisasjoner samarbeide sikkert, låse opp potensialet til distribuerte data og forbedre ML-modeller uten å gå på bekostning av personvernet.
Som alltid tar AWS gjerne tilbakemeldinger fra deg. Legg igjen dine tanker og spørsmål i kommentarfeltet.
Om forfatterne
 Randy DeFauw er Senior Principal Solutions Architect hos AWS. Han har en MSEE fra University of Michigan, hvor han jobbet med datasyn for autonome kjøretøy. Han har også en MBA fra Colorado State University. Randy har hatt en rekke stillinger innen teknologiområdet, alt fra programvareutvikling til produktadministrasjon. Han gikk inn i big data-området i 2013 og fortsetter å utforske det området. Han jobber aktivt med prosjekter i ML-området og har presentert på en rekke konferanser, inkludert Strata og GlueCon.
Randy DeFauw er Senior Principal Solutions Architect hos AWS. Han har en MSEE fra University of Michigan, hvor han jobbet med datasyn for autonome kjøretøy. Han har også en MBA fra Colorado State University. Randy har hatt en rekke stillinger innen teknologiområdet, alt fra programvareutvikling til produktadministrasjon. Han gikk inn i big data-området i 2013 og fortsetter å utforske det området. Han jobber aktivt med prosjekter i ML-området og har presentert på en rekke konferanser, inkludert Strata og GlueCon.
 Arnab Sinha er en Senior Solutions Architect for AWS, som fungerer som Field CTO for å hjelpe organisasjoner med å designe og bygge skalerbare løsninger som støtter forretningsresultater på tvers av datasentermigrasjoner, digital transformasjon og applikasjonsmodernisering, big data og maskinlæring. Han har støttet kunder på tvers av en rekke bransjer, inkludert energi, detaljhandel, produksjon, helsevesen og biovitenskap. Arnab innehar alle AWS-sertifiseringer, inkludert ML spesialitetssertifisering. Før han begynte i AWS, var Arnab teknologileder og hadde tidligere arkitekt- og ingeniørlederroller.
Arnab Sinha er en Senior Solutions Architect for AWS, som fungerer som Field CTO for å hjelpe organisasjoner med å designe og bygge skalerbare løsninger som støtter forretningsresultater på tvers av datasentermigrasjoner, digital transformasjon og applikasjonsmodernisering, big data og maskinlæring. Han har støttet kunder på tvers av en rekke bransjer, inkludert energi, detaljhandel, produksjon, helsevesen og biovitenskap. Arnab innehar alle AWS-sertifiseringer, inkludert ML spesialitetssertifisering. Før han begynte i AWS, var Arnab teknologileder og hadde tidligere arkitekt- og ingeniørlederroller.
 Prachi Kulkarni er Senior Solutions Architect hos AWS. Spesialiseringen hennes er maskinlæring, og hun jobber aktivt med å designe løsninger ved hjelp av ulike AWS ML-, big data- og analysetilbud. Prachi har erfaring innen flere domener, inkludert helsetjenester, fordeler, detaljhandel og utdanning, og har jobbet i en rekke stillinger innen produktteknikk og arkitektur, ledelse og kundesuksess.
Prachi Kulkarni er Senior Solutions Architect hos AWS. Spesialiseringen hennes er maskinlæring, og hun jobber aktivt med å designe løsninger ved hjelp av ulike AWS ML-, big data- og analysetilbud. Prachi har erfaring innen flere domener, inkludert helsetjenester, fordeler, detaljhandel og utdanning, og har jobbet i en rekke stillinger innen produktteknikk og arkitektur, ledelse og kundesuksess.
 Tamer Sherif er en hovedløsningsarkitekt hos AWS, med en mangfoldig bakgrunn innen teknologi- og bedriftskonsulenttjenester, og strekker seg over 17 år som løsningsarkitekt. Med fokus på infrastruktur, dekker Tamers ekspertise et bredt spekter av industrivertikaler, inkludert kommersiell, helsevesen, bilindustri, offentlig sektor, produksjon, olje og gass, medietjenester og mer. Hans ferdigheter strekker seg til ulike domener, for eksempel skyarkitektur, edge computing, nettverk, lagring, virtualisering, forretningsproduktivitet og teknisk lederskap.
Tamer Sherif er en hovedløsningsarkitekt hos AWS, med en mangfoldig bakgrunn innen teknologi- og bedriftskonsulenttjenester, og strekker seg over 17 år som løsningsarkitekt. Med fokus på infrastruktur, dekker Tamers ekspertise et bredt spekter av industrivertikaler, inkludert kommersiell, helsevesen, bilindustri, offentlig sektor, produksjon, olje og gass, medietjenester og mer. Hans ferdigheter strekker seg til ulike domener, for eksempel skyarkitektur, edge computing, nettverk, lagring, virtualisering, forretningsproduktivitet og teknisk lederskap.
 Hans Nesbitt er en senior løsningsarkitekt ved AWS basert i Sør-California. Han jobber med kunder over hele det vestlige USA for å lage svært skalerbare, fleksible og spenstige skyarkitekturer. På fritiden liker han å tilbringe tid med familien, lage mat og spille gitar.
Hans Nesbitt er en senior løsningsarkitekt ved AWS basert i Sør-California. Han jobber med kunder over hele det vestlige USA for å lage svært skalerbare, fleksible og spenstige skyarkitekturer. På fritiden liker han å tilbringe tid med familien, lage mat og spille gitar.
 Chaoyang He er medgründer og CTO av FedML, Inc., en oppstart som driver for en fellesskapsbygging åpen og samarbeidende AI fra hvor som helst og uansett skala. Forskningen hans fokuserer på distribuerte og fødererte maskinlæringsalgoritmer, systemer og applikasjoner. Han fikk sin doktorgrad i informatikk fra University of South California.
Chaoyang He er medgründer og CTO av FedML, Inc., en oppstart som driver for en fellesskapsbygging åpen og samarbeidende AI fra hvor som helst og uansett skala. Forskningen hans fokuserer på distribuerte og fødererte maskinlæringsalgoritmer, systemer og applikasjoner. Han fikk sin doktorgrad i informatikk fra University of South California.
 Al Nevarez er direktør for produktledelse i FedML. Før FedML var han gruppeproduktsjef hos Google, og seniorsjef for datavitenskap hos LinkedIn. Han har flere dataproduktrelaterte patenter, og han studerte ingeniørfag ved Stanford University.
Al Nevarez er direktør for produktledelse i FedML. Før FedML var han gruppeproduktsjef hos Google, og seniorsjef for datavitenskap hos LinkedIn. Han har flere dataproduktrelaterte patenter, og han studerte ingeniørfag ved Stanford University.
 Salman Avestimehr er medgründer og administrerende direktør i FedML. Han har vært dekanprofessor ved USC, direktør for USC-Amazon Center on Trustworthy AI, og Amazon Scholar i Alexa AI. Han er ekspert på forent og desentralisert maskinlæring, informasjonsteori, sikkerhet og personvern. Han er stipendiat ved IEEE og mottok sin doktorgrad i EECS fra UC Berkeley.
Salman Avestimehr er medgründer og administrerende direktør i FedML. Han har vært dekanprofessor ved USC, direktør for USC-Amazon Center on Trustworthy AI, og Amazon Scholar i Alexa AI. Han er ekspert på forent og desentralisert maskinlæring, informasjonsteori, sikkerhet og personvern. Han er stipendiat ved IEEE og mottok sin doktorgrad i EECS fra UC Berkeley.
 Samir Lad er en dyktig bedriftsteknolog med AWS som jobber tett med kundenes C-nivå ledere. Som en tidligere C-suite-leder som har drevet transformasjoner på tvers av flere Fortune 100-selskaper, deler Samir sine uvurderlige erfaringer for å hjelpe kundene sine med å lykkes i sin egen transformasjonsreise.
Samir Lad er en dyktig bedriftsteknolog med AWS som jobber tett med kundenes C-nivå ledere. Som en tidligere C-suite-leder som har drevet transformasjoner på tvers av flere Fortune 100-selskaper, deler Samir sine uvurderlige erfaringer for å hjelpe kundene sine med å lykkes i sin egen transformasjonsreise.
 Stephen Kraemer er styre- og CxO-rådgiver og tidligere leder i AWS. Stephen tar til orde for kultur og lederskap som grunnlaget for suksess. Han bekjenner sikkerhet og innovasjon som driverne bak nettskytransformasjon som muliggjør svært konkurransedyktige, datadrevne organisasjoner.
Stephen Kraemer er styre- og CxO-rådgiver og tidligere leder i AWS. Stephen tar til orde for kultur og lederskap som grunnlaget for suksess. Han bekjenner sikkerhet og innovasjon som driverne bak nettskytransformasjon som muliggjør svært konkurransedyktige, datadrevne organisasjoner.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://aws.amazon.com/blogs/machine-learning/federated-learning-on-aws-using-fedml-amazon-eks-and-amazon-sagemaker/

