Store språkmodeller (LLMs) er generelt trent på store offentlig tilgjengelige datasett som er domeneagnostiske. For eksempel, Metas lama modeller trenes på datasett som f.eks CommonCrawl, C4, Wikipedia og arxiv. Disse datasettene omfatter et bredt spekter av emner og domener. Selv om de resulterende modellene gir utrolig gode resultater for generelle oppgaver, som tekstgenerering og enhetsgjenkjenning, er det bevis på at modeller som er trent med domenespesifikke datasett kan forbedre LLM-ytelsen ytterligere. For eksempel treningsdataene som brukes til BloombergGPT er 51 % domenespesifikke dokumenter, inkludert økonomiske nyheter, innleveringer og annet økonomisk materiale. Den resulterende LLM overgår LLM-er som er trent på ikke-domenespesifikke datasett når de testes på økonomispesifikke oppgaver. Forfatterne av BloombergGPT konkluderte med at modellen deres overgår alle andre modeller som er testet for fire av de fem økonomiske oppgavene. Modellen ga enda bedre ytelse når den ble testet for Bloombergs interne økonomiske oppgaver med bred margin – så mye som 60 poeng bedre (av 100). Selv om du kan lære mer om de omfattende evalueringsresultatene i papir, følgende prøve tatt fra BloombergGPT papir kan gi deg et glimt av fordelen med å trene LLM-er ved å bruke økonomiske domenespesifikke data. Som vist i eksempelet ga BloombergGPT-modellen riktige svar mens andre ikke-domenespesifikke modeller slet:
Dette innlegget gir en veiledning for opplæring av LLM-er spesielt for det økonomiske domenet. Vi dekker følgende nøkkelområder:
- Datainnsamling og forberedelse – Veiledning om innhenting og kurering av relevante økonomiske data for effektiv modelltrening
- Kontinuerlig fortrening kontra finjustering – Når du skal bruke hver teknikk for å optimalisere LLMs ytelse
- Effektiv kontinuerlig fortrening – Strategier for å effektivisere den kontinuerlige føropplæringsprosessen, og spare tid og ressurser
Dette innlegget samler ekspertisen til forskningsteamet for anvendt vitenskap innen Amazon Finance Technology og AWS Worldwide Specialist-teamet for den globale finansindustrien. Noe av innholdet er basert på papiret Effektiv kontinuerlig foropplæring for å bygge domenespesifikke store språkmodellene.
Innsamling og utarbeidelse av finansdata
Kontinuerlig forhåndsopplæring for domene krever et storskala, høykvalitets, domenespesifikt datasett. Følgende er hovedtrinnene for kurering av domenedatasett:
- Identifiser datakilder – Potensielle datakilder for domenekorpus inkluderer åpent web, Wikipedia, bøker, sosiale medier og interne dokumenter.
- Domenedatafiltre – Fordi det endelige målet er å kurere domenekorpus, må du kanskje bruke flere trinn for å filtrere ut prøver som er irrelevante for måldomenet. Dette reduserer ubrukelig korpus for kontinuerlig foropplæring og reduserer treningskostnadene.
- forbehandling – Du kan vurdere en rekke forbehandlingstrinn for å forbedre datakvaliteten og treningseffektiviteten. For eksempel kan visse datakilder inneholde et rimelig antall støyende tokens; deduplisering anses som et nyttig skritt for å forbedre datakvaliteten og redusere opplæringskostnadene.
For å utvikle økonomiske LLM-er kan du bruke to viktige datakilder: News CommonCrawl og SEC-arkivering. En SEC-arkivering er et regnskap eller annet formelt dokument sendt til US Securities and Exchange Commission (SEC). Børsnoterte selskaper er pålagt å sende inn ulike dokumenter regelmessig. Dette skaper et stort antall dokumenter gjennom årene. News CommonCrawl er et datasett utgitt av CommonCrawl i 2016. Det inneholder nyhetsartikler fra nyhetssider over hele verden.
Nyheter CommonCrawl er tilgjengelig på Amazon enkel lagringstjeneste (Amazon S3) i commoncrawl bøtte kl crawl-data/CC-NEWS/. Du kan få oversikt over filer ved å bruke AWS kommandolinjegrensesnitt (AWS CLI) og følgende kommando:
In Effektiv kontinuerlig foropplæring for å bygge domenespesifikke store språkmodellene, bruker forfatterne en URL- og nøkkelordbasert tilnærming for å filtrere økonomiske nyhetsartikler fra generiske nyheter. Nærmere bestemt opprettholder forfatterne en liste over viktige finansnyheter og et sett med nøkkelord relatert til finansnyheter. Vi identifiserer en artikkel som finansnyheter hvis den enten kommer fra finansielle nyhetskanaler eller noen søkeord vises i URL-en. Denne enkle, men effektive tilnærmingen lar deg identifisere økonomiske nyheter fra ikke bare finansielle nyhetskanaler, men også finansseksjoner av generiske nyhetskanaler.
SEC-arkiver er tilgjengelige online gjennom SECs EDGAR-database (Electronic Data Gathering, Analysis and Retrieval), som gir åpen datatilgang. Du kan skrape arkivene fra EDGAR direkte, eller bruke APIer i Amazon SageMaker med noen få linjer med kode, for en hvilken som helst tidsperiode og for et stort antall ticker (dvs. den SEC-tildelte identifikatoren). For å lære mer, se SEC-arkivinnhenting.
Tabellen nedenfor oppsummerer de viktigste detaljene for begge datakildene.
| . | Nyheter CommonCrawl | SEC-arkivering |
| Dekning | 2016-2022 | 1993-2022 |
| Størrelse | 25.8 milliarder ord | 5.1 milliarder ord |
Forfatterne går gjennom noen ekstra forbehandlingstrinn før dataene mates inn i en treningsalgoritme. For det første observerer vi at SEC-arkiver inneholder støyende tekst på grunn av fjerning av tabeller og figurer, så forfatterne fjerner korte setninger som anses å være tabell- eller figuretiketter. For det andre bruker vi en lokalitetssensitiv hashing-algoritme for å deduplisere de nye artiklene og registreringene. For SEC-arkivering dedupliserer vi på seksjonsnivå i stedet for dokumentnivå. Til slutt setter vi sammen dokumenter i en lang streng, tokeniserer den og deler tokeniseringen i stykker med maksimal inndatalengde støttet av modellen som skal trenes. Dette forbedrer gjennomstrømningen av kontinuerlig fortrening og reduserer treningskostnadene.
Kontinuerlig fortrening kontra finjustering
De fleste tilgjengelige LLM-er er generelle formål og mangler domenespesifikke evner. Domene LLM-er har vist betydelig ytelse innen medisinske, økonomiske eller vitenskapelige domener. For at en LLM skal tilegne seg domenespesifikk kunnskap, er det fire metoder: opplæring fra bunnen av, kontinuerlig foropplæring, instruksjonsfinjustering av domeneoppgaver og Retrieval Augmented Generation (RAG).
I tradisjonelle modeller brukes finjustering vanligvis for å lage oppgavespesifikke modeller for et domene. Dette betyr å opprettholde flere modeller for flere oppgaver som enhetsutvinning, intensjonsklassifisering, sentimentanalyse eller svar på spørsmål. Med bruken av LLM-er har behovet for å opprettholde separate modeller blitt foreldet ved å bruke teknikker som læring i kontekst eller spørring. Dette sparer innsatsen som kreves for å vedlikeholde en stabel med modeller for relaterte, men distinkte oppgaver.
Intuitivt kan du trene LLM-er fra bunnen av med domenespesifikke data. Selv om det meste av arbeidet med å lage domene LLM-er har fokusert på opplæring fra bunnen av, er det uoverkommelig dyrt. For eksempel koster GPT-4-modellen over $ 100 millioner å trene. Disse modellene er trent på en blanding av åpne domenedata og domenedata. Kontinuerlig forhåndstrening kan hjelpe modeller til å tilegne seg domenespesifikk kunnskap uten å pådra seg kostnadene for forhåndstrening fra bunnen av fordi du forhåndstrener en eksisterende åpen domene LLM på kun domenedataene.
Med instruksjonsfinjustering på en oppgave kan du ikke få modellen til å skaffe domenekunnskap fordi LLM kun henter domeneinformasjon som finnes i instruksjonsfinjusteringsdatasettet. Med mindre det brukes et veldig stort datasett for instruksjonsfinjustering, er det ikke nok å tilegne seg domenekunnskap. Å hente instruksjonsdatasett av høy kvalitet er vanligvis utfordrende og er grunnen til å bruke LLM-er i første omgang. Finjustering av instruksjoner på én oppgave kan også påvirke ytelsen på andre oppgaver (som vist i dette papiret). Finjustering av instruksjon er imidlertid mer kostnadseffektiv enn noen av alternativene før trening.
Følgende figur sammenligner tradisjonell oppgavespesifikk finjustering. vs læringsparadigme i kontekst med LLM-er.
 RAG er den mest effektive måten å veilede en LLM til å generere svar basert på et domene. Selv om den kan veilede en modell for å generere svar ved å gi fakta fra domenet som hjelpeinformasjon, får den ikke det domenespesifikke språket fordi LLM fortsatt er avhengig av ikke-domenespråkstil for å generere svarene.
RAG er den mest effektive måten å veilede en LLM til å generere svar basert på et domene. Selv om den kan veilede en modell for å generere svar ved å gi fakta fra domenet som hjelpeinformasjon, får den ikke det domenespesifikke språket fordi LLM fortsatt er avhengig av ikke-domenespråkstil for å generere svarene.
Kontinuerlig pre-trening er en mellomting mellom før-trening og instruksjon finjustering i form av kostnader samtidig som det er et sterkt alternativ til å få domenespesifikk kunnskap og stil. Det kan gi en generell modell som ytterligere finjustering av instruksjoner på begrensede instruksjonsdata kan utføres over. Kontinuerlig foropplæring kan være en kostnadseffektiv strategi for spesialiserte domener der sett med nedstrømsoppgaver er store eller ukjente og merket instruksjonsjusteringsdata er begrenset. I andre scenarier kan instruksjonsfinjustering eller RAG være mer egnet.
For å lære mer om finjustering, RAG og modelltrening, se Finjuster en grunnmodell, Retrieval Augmented Generation (RAG)og Tren en modell med Amazon SageMaker, henholdsvis. For dette innlegget fokuserer vi på effektiv kontinuerlig fortrening.
Metodikk for effektiv kontinuerlig foropplæring
Kontinuerlig fortrening består av følgende metodikk:
- Domain-Adaptive Continual Pre-training (DACP) – I avisen Effektiv kontinuerlig foropplæring for å bygge domenespesifikke store språkmodellene, fortrener forfatterne kontinuerlig Pythia-språkmodellpakken på finanskorpuset for å tilpasse den til finansdomenet. Målet er å lage finansielle LLM-er ved å mate data fra hele det økonomiske domenet inn i en åpen kildekodemodell. Fordi opplæringskorpuset inneholder alle de kuraterte datasettene i domenet, bør den resulterende modellen tilegne seg finansspesifikk kunnskap, og dermed bli en allsidig modell for ulike økonomiske oppgaver. Dette resulterer i FinPythia-modeller.
- Task-Adaptive Continual Pre-training (TACP) – Forfatterne forhåndstrener modellene videre på merket og umerket oppgavedata for å skreddersy dem for spesifikke oppgaver. Under visse omstendigheter kan utviklere foretrekke modeller som gir bedre ytelse på en gruppe med oppgaver innen domene i stedet for en domenegenerisk modell. TACP er designet som kontinuerlig foropplæring med sikte på å forbedre ytelsen på målrettede oppgaver, uten krav til merkede data. Nærmere bestemt, fortrener forfatterne kontinuerlig de åpne kildemodellene på oppgavetokenene (uten etiketter). Den primære begrensningen til TACP ligger i å konstruere oppgavespesifikke LLM-er i stedet for grunnleggende LLM-er, på grunn av den eneste bruken av umerkede oppgavedata for opplæring. Selv om DACP bruker et mye større korpus, er det uoverkommelig dyrt. For å balansere disse begrensningene, foreslår forfatterne to tilnærminger som tar sikte på å bygge domenespesifikke grunnleggende LLM-er samtidig som de bevarer overlegen ytelse på måloppgaver:
- Effektiv oppgavelignende DACP (ETS-DACP) – Forfatterne foreslår å velge en delmengde av finanskorpus som er svært lik oppgavedataene ved å bruke innebygde likheter. Dette undersettet brukes til kontinuerlig fortrening for å gjøre det mer effektivt. Spesifikt fortrener forfatterne kontinuerlig LLM med åpen kildekode på et lite korpus hentet fra finanskorpuset som er nær måloppgavene i distribusjon. Dette kan bidra til å forbedre oppgaveytelsen fordi vi bruker modellen til distribusjon av oppgavetokens til tross for at merket data ikke er nødvendig.
- Effektiv oppgaveagnostisk DACP (ETA-DACP) – Forfatterne foreslår å bruke beregninger som forvirring og tokentype-entropi som ikke krever oppgavedata for å velge prøver fra finanskorpus for effektiv kontinuerlig forhåndstrening. Denne tilnærmingen er designet for å håndtere scenarier der oppgavedata er utilgjengelige eller mer allsidige domenemodeller for det bredere domenet foretrekkes. Forfatterne tar i bruk to dimensjoner for å velge dataprøver som er viktige for å få domeneinformasjon fra en undergruppe av domenedata før opplæring: nyhet og mangfold. Nyhet, målt ved forvirringen registrert av målmodellen, refererer til informasjonen som var usett av LLM før. Data med høy nyhet indikerer ny kunnskap for LLM, og slike data blir sett på som vanskeligere å lære. Dette oppdaterer generiske LLM-er med intensiv domenekunnskap under kontinuerlig foropplæring. Mangfold, på den annen side, fanger opp mangfoldet av fordelinger av tokentyper i domenekorpuset, noe som er dokumentert som et nyttig trekk i forskningen av læreplanlæring på språkmodellering.
Følgende figur sammenligner et eksempel på ETS-DACP (venstre) vs. ETA-DACP (høyre).

Vi bruker to prøvetakingsordninger for aktivt å velge datapunkter fra kuratert finanskorpus: hard prøvetaking og myk prøvetaking. Førstnevnte gjøres ved først å rangere finanskorpuset etter tilsvarende beregninger og deretter velge topp-k-prøvene, der k er forhåndsbestemt i henhold til opplæringsbudsjettet. For sistnevnte tildeler forfatterne prøvetakingsvekter for hvert datapunkt i henhold til de metriske verdiene, og prøver deretter tilfeldig k datapunkter for å møte treningsbudsjettet.
Resultat og analyse
Forfatterne evaluerer de resulterende økonomiske LLM-ene på en rekke økonomiske oppgaver for å undersøke effektiviteten av kontinuerlig foropplæring:
- Financial Phrase Bank – En sentimentklassifiseringsoppgave på finansnyheter.
- FiQA SA – En aspektbasert sentimentklassifiseringsoppgave basert på økonomiske nyheter og overskrifter.
- overskrift – En binær klassifiseringsoppgave om hvorvidt en overskrift på en finansiell enhet inneholder bestemt informasjon.
- NER – En finansiell navngitt enhetsutvinningsoppgave basert på kredittrisikovurderingsdelen av SEC-rapporter. Ord i denne oppgaven er merket med PER, LOC, ORG og DIVERSE.
Fordi finansielle LLM-er er finjustert instruksjon, evaluerer forfatterne modeller i en 5-skudds setting for hver oppgave for robusthetens skyld. I gjennomsnitt overgår FinPythia 6.9B Pythia 6.9B med 10 % på tvers av fire oppgaver, noe som demonstrerer effektiviteten av domenespesifikk kontinuerlig forhåndstrening. For 1B-modellen er forbedringen mindre dyp, men ytelsen forbedres fortsatt med 2 % i gjennomsnitt.
Følgende figur illustrerer ytelsesforskjellen før og etter DACP på begge modellene.

Følgende figur viser to kvalitative eksempler generert av Pythia 6.9B og FinPythia 6.9B. For to finansrelaterte spørsmål angående en investorforvalter og en finansiell term, forstår ikke Pythia 6.9B begrepet eller gjenkjenner navnet, mens FinPythia 6.9B genererer detaljerte svar riktig. De kvalitative eksemplene viser at kontinuerlig foropplæring gjør det mulig for LLM-ene å tilegne seg domenekunnskap under prosessen.

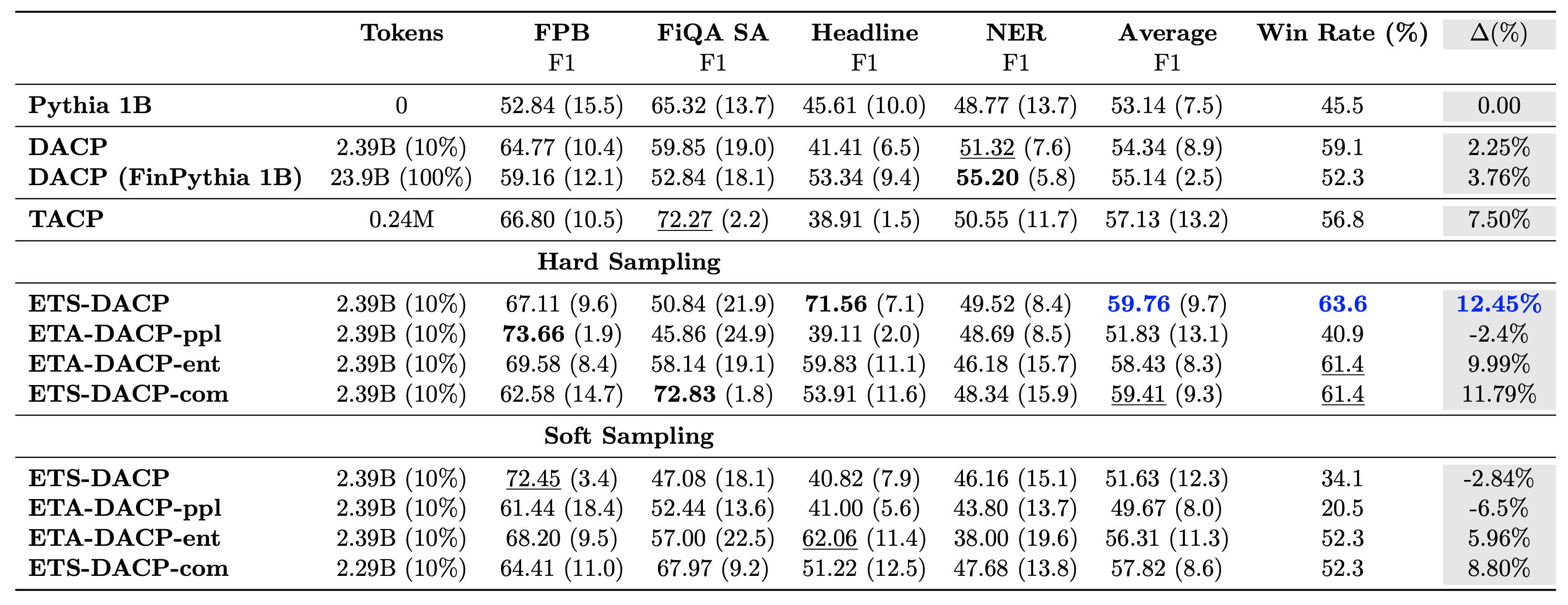
Tabellen nedenfor sammenligner ulike effektive tilnærminger til kontinuerlig før-trening. ETA-DACP-ppl er ETA-DACP basert på forvirring (nyhet), og ETA-DACP-ent er basert på entropi (mangfold). ETS-DACP-com ligner DACP med datavalg ved å beregne gjennomsnittet av alle tre beregningene. Følgende er noen få ting fra resultatene:
- Datavalgmetoder er effektive – De overgår standard kontinuerlig fortrening med bare 10 % av treningsdataene. Effektiv kontinuerlig foropplæring inkludert Task-Similar DACP (ETS-DACP), Task-Agnostic DACP basert på entropi (ESA-DACP-ent) og Task-Similar DACP basert på alle tre metrikkene (ETS-DACP-com) overgår standard DACP i gjennomsnitt til tross for at de er opplært på kun 10 % av finanskorpus.
- Oppgavebevisst datavalg fungerer best i tråd med forskning på små språkmodeller – ETS-DACP registrerer den beste gjennomsnittlige ytelsen blant alle metodene og, basert på alle tre beregningene, registrerer den nest beste oppgaveytelsen. Dette antyder at bruk av umerkede oppgavedata fortsatt er en effektiv tilnærming for å øke oppgaveytelsen når det gjelder LLM-er.
- Oppgaveagnostisk datavalg er nær nummer to – ESA-DACP-ent følger ytelsen til den oppgavebevisste datavalgtilnærmingen, noe som antyder at vi fortsatt kan øke oppgaveytelsen ved aktivt å velge prøver av høy kvalitet som ikke er knyttet til spesifikke oppgaver. Dette baner vei for å bygge økonomiske LLM-er for hele domenet samtidig som man oppnår overlegen oppgaveytelse.
Et kritisk spørsmål angående kontinuerlig foropplæring er om det påvirker ytelsen på ikke-domeneoppgaver negativt. Forfatterne evaluerer også den kontinuerlig forhåndstrente modellen på fire mye brukte generiske oppgaver: ARC, MMLU, TruthQA og HellaSwag, som måler evnen til å besvare spørsmål, resonnere og fullføre. Forfatterne finner at kontinuerlig fortrening ikke påvirker ytelsen utenfor domene negativt. For flere detaljer, se Effektiv kontinuerlig foropplæring for å bygge domenespesifikke store språkmodellene.
konklusjonen
Dette innlegget ga innsikt i datainnsamling og kontinuerlige forhåndsopplæringsstrategier for opplæring av LLM-er for finansielt domene. Du kan begynne å trene dine egne LLM-er for økonomiske oppgaver ved å bruke Amazon SageMaker-opplæring or Amazonas grunnfjell i dag.
Om forfatterne
 Yong Xie er en anvendt vitenskapsmann i Amazon FinTech. Han fokuserer på å utvikle store språkmodeller og Generative AI-applikasjoner for finans.
Yong Xie er en anvendt vitenskapsmann i Amazon FinTech. Han fokuserer på å utvikle store språkmodeller og Generative AI-applikasjoner for finans.
 Karan Aggarwal er en Senior Applied Scientist med Amazon FinTech med fokus på Generativ AI for finansbruk. Karan har lang erfaring innen tidsserieanalyse og NLP, med spesiell interesse for å lære av begrensede merkede data
Karan Aggarwal er en Senior Applied Scientist med Amazon FinTech med fokus på Generativ AI for finansbruk. Karan har lang erfaring innen tidsserieanalyse og NLP, med spesiell interesse for å lære av begrensede merkede data
 Aitzaz Ahmad er en Applied Science Manager hos Amazon hvor han leder et team av forskere som bygger ulike applikasjoner for maskinlæring og generativ AI i finans. Hans forskningsinteresser er i NLP, Generative AI og LLM Agents. Han fikk sin doktorgrad i elektroteknikk fra Texas A&M University.
Aitzaz Ahmad er en Applied Science Manager hos Amazon hvor han leder et team av forskere som bygger ulike applikasjoner for maskinlæring og generativ AI i finans. Hans forskningsinteresser er i NLP, Generative AI og LLM Agents. Han fikk sin doktorgrad i elektroteknikk fra Texas A&M University.
 Qingwei Li er maskinlæringsspesialist hos Amazon Web Services. Han fikk sin Ph.D. i Operations Research etter at han brøt sin rådgivers forskningsstipendkonto og ikke klarte å levere Nobelprisen han lovet. For tiden hjelper han kunder innen finansielle tjenester med å bygge maskinlæringsløsninger på AWS.
Qingwei Li er maskinlæringsspesialist hos Amazon Web Services. Han fikk sin Ph.D. i Operations Research etter at han brøt sin rådgivers forskningsstipendkonto og ikke klarte å levere Nobelprisen han lovet. For tiden hjelper han kunder innen finansielle tjenester med å bygge maskinlæringsløsninger på AWS.
 Raghvender Arni leder Customer Acceleration Team (CAT) innen AWS Industries. CAT er et globalt tverrfunksjonelt team av kundevendte skyarkitekter, programvareingeniører, dataforskere og AI/ML-eksperter og designere som driver innovasjon via avansert prototyping, og driver skyoperasjonsdyktighet via spesialisert teknisk ekspertise.
Raghvender Arni leder Customer Acceleration Team (CAT) innen AWS Industries. CAT er et globalt tverrfunksjonelt team av kundevendte skyarkitekter, programvareingeniører, dataforskere og AI/ML-eksperter og designere som driver innovasjon via avansert prototyping, og driver skyoperasjonsdyktighet via spesialisert teknisk ekspertise.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://aws.amazon.com/blogs/machine-learning/efficient-continual-pre-training-llms-for-financial-domains/

