Det har vært enorm fremgang innen distribuert dyp læring for store språkmodeller (LLM), spesielt etter utgivelsen av ChatGPT i desember 2022. LLM-er fortsetter å vokse i størrelse med milliarder eller til og med billioner av parametere, og de vil ofte ikke gjøre det. passe inn i en enkelt akseleratorenhet som GPU eller til og med en enkelt node som ml.p5.32xlarge på grunn av minnebegrensninger. Kunder som trener LLM-er må ofte fordele arbeidsmengden sin på hundrevis eller til og med tusenvis av GPU-er. Å muliggjøre opplæring i en slik skala er fortsatt en utfordring i distribuert opplæring, og effektiv trening i et så stort system er et annet like viktig problem. I løpet av de siste årene har det distribuerte treningsmiljøet introdusert 3D-parallellisme (dataparallellisme, pipeline-parallellisme og tensorparallellisme) og andre teknikker (som sekvensparallellisme og ekspertparallellisme) for å møte slike utfordringer.
I desember 2023 kunngjorde Amazon utgivelsen av SageMaker modell parallellbibliotek 2.0 (SMP), som oppnår state-of-the-art effektivitet i trening av store modeller, sammen med SageMaker distribuerte dataparallellismebibliotek (SMDDP). Denne utgivelsen er en betydelig oppdatering fra 1.x: SMP er nå integrert med åpen kildekode PyTorch Fullstendig delte data parallelt (FSDP) APIer, som lar deg bruke et kjent grensesnitt når du trener store modeller, og er kompatibel med Transformatormotor (TE), låser opp tensorparallellismeteknikker ved siden av FSDP for første gang. For å lære mer om utgivelsen, se Amazon SageMaker modell parallellbibliotek akselererer nå PyTorch FSDP arbeidsbelastninger med opptil 20 %.
I dette innlegget utforsker vi ytelsesfordelene ved Amazon SageMaker (inkludert SMP og SMDDP), og hvordan du kan bruke biblioteket til å trene store modeller effektivt på SageMaker. Vi demonstrerer ytelsen til SageMaker med benchmarks på ml.p4d.24xlarge klynger opptil 128 forekomster, og FSDP blandet presisjon med bfloat16 for Llama 2-modellen. Vi starter med en demonstrasjon av nær-lineær skaleringseffektivitet for SageMaker, etterfulgt av å analysere bidrag fra hver funksjon for optimal gjennomstrømning, og avslutter med effektiv trening med ulike sekvenslengder opp til 32,768 XNUMX gjennom tensorparallellisme.
Nær-lineær skalering med SageMaker
For å redusere den totale treningstiden for LLM-modeller, er det avgjørende å bevare høy gjennomstrømning ved skalering til store klynger (tusenvis av GPUer) gitt kommunikasjonsoverhead mellom noder. I dette innlegget demonstrerer vi robust og nær-lineær skalering (ved å variere antall GPUer for en fast total problemstørrelse) effektivitet på p4d-forekomster som påkaller både SMP og SMDDP.
I denne delen demonstrerer vi SMPs nesten-lineære skaleringsytelse. Her trener vi Llama 2-modeller av forskjellige størrelser (7B, 13B og 70B parametere) ved å bruke en fast sekvenslengde på 4,096, SMDDP-backend for kollektiv kommunikasjon, TE-aktivert, en global batchstørrelse på 4 millioner, med 16 til 128 p4d-noder . Følgende tabell oppsummerer vår optimale konfigurasjon og treningsytelse (modell TFLOPs per sekund).
| Modellstørrelse | Antall noder | TFLOPs* | sdp* | tp* | avlast* | Skaleringseffektivitet |
| 7B | 16 | 136.76 | 32 | 1 | N | 100.0% |
| 32 | 132.65 | 64 | 1 | N | 97.0% | |
| 64 | 125.31 | 64 | 1 | N | 91.6% | |
| 128 | 115.01 | 64 | 1 | N | 84.1% | |
| 13B | 16 | 141.43 | 32 | 1 | Y | 100.0% |
| 32 | 139.46 | 256 | 1 | N | 98.6% | |
| 64 | 132.17 | 128 | 1 | N | 93.5% | |
| 128 | 120.75 | 128 | 1 | N | 85.4% | |
| 70B | 32 | 154.33 | 256 | 1 | Y | 100.0% |
| 64 | 149.60 | 256 | 1 | N | 96.9% | |
| 128 | 136.52 | 64 | 2 | N | 88.5% |
*Ved den gitte modellstørrelsen, sekvenslengden og antall noder viser vi den globalt optimale gjennomstrømningen og konfigurasjonene etter å ha utforsket ulike sdp-, tp- og aktiveringsavlastningskombinasjoner.
Den foregående tabellen oppsummerer de optimale gjennomstrømningstallene underlagt sharded data parallel (sdp) grad (vanligvis ved bruk av FSDP hybrid sharding i stedet for full sharding, med flere detaljer i neste avsnitt), tensor parallell (tp) grad, og aktiveringsavlastningsverdiendringer, demonstrerer en nesten lineær skalering for SMP sammen med SMDDP. For eksempel, gitt Llama 2-modellen størrelse 7B og sekvenslengde 4,096, oppnår den totalt sett skaleringseffektiviteter på 97.0 %, 91.6 % og 84.1 % (i forhold til 16 noder) ved henholdsvis 32, 64 og 128 noder. Skaleringseffektiviteten er stabil på tvers av ulike modellstørrelser og øker litt etter hvert som modellstørrelsen blir større.
SMP og SMDDP viser også lignende skaleringseffektiviteter for andre sekvenslengder som 2,048 og 8,192.
SageMaker modell parallellbibliotek 2.0 ytelse: Llama 2 70B
Modellstørrelser har fortsatt å vokse de siste årene, sammen med hyppige toppmoderne ytelsesoppdateringer i LLM-fellesskapet. I denne delen illustrerer vi ytelsen i SageMaker for Llama 2-modellen ved å bruke en fast modellstørrelse 70B, sekvenslengde på 4,096 og en global batchstørrelse på 4 millioner. For å sammenligne med forrige tabells globalt optimale konfigurasjon og gjennomstrømning (med SMDDP backend, typisk FSDP hybrid sharding og TE), utvider følgende tabell til andre optimale gjennomstrømninger (potensielt med tensorparallellisme) med ekstra spesifikasjoner på den distribuerte backend (NCCL og SMDDP) , FSDP-sharding-strategier (full sharding og hybrid sharding), og aktivering av TE eller ikke (standard).
| Modellstørrelse | Antall noder | TFLOPS | TFLOPs #3 konfig | TFLOPs forbedring over baseline | ||||||||
| . | . | NCCL full skjæring: #0 | SMDDP full skjæring: #1 | SMDDP hybrid skjæring: #2 | SMDDP hybrid skjæring med TE: #3 | sdp* | tp* | avlast* | #0 → #1 | #1 → #2 | #2 → #3 | #0 → #3 |
| 70B | 32 | 150.82 | 149.90 | 150.05 | 154.33 | 256 | 1 | Y | -0.6% | 0.1% | 2.9% | 2.3% |
| 64 | 144.38 | 144.38 | 145.42 | 149.60 | 256 | 1 | N | 0.0% | 0.7% | 2.9% | 3.6% | |
| 128 | 68.53 | 103.06 | 130.66 | 136.52 | 64 | 2 | N | 50.4% | 26.8% | 4.5% | 99.2% | |
*Ved den gitte modellstørrelsen, sekvenslengden og antall noder viser vi den globalt optimale gjennomstrømningen og konfigurasjonen etter å ha utforsket ulike sdp-, tp- og aktiveringsavlastningskombinasjoner.
Den siste utgivelsen av SMP og SMDDP støtter flere funksjoner, inkludert innebygd PyTorch FSDP, utvidet og mer fleksibel hybridskjæring, transformatormotorintegrasjon, tensorparallellisme og optimert alt samle-kollektiv drift. For bedre å forstå hvordan SageMaker oppnår effektiv distribuert opplæring for LLM-er, utforsker vi inkrementelle bidrag fra SMDDP og følgende SMP kjernefunksjoner:
- SMDDP-forbedring over NCCL med FSDP full sharding
- Erstatter FSDP full sharding med hybrid sharding, som reduserer kommunikasjonskostnadene for å forbedre gjennomstrømningen
- En ytterligere økning av gjennomstrømmingen med TE, selv når tensorparallellisme er deaktivert
- Ved lavere ressursinnstillinger kan aktiveringsavlastning muliggjøre trening som ellers ville vært umulig eller veldig sakte på grunn av høyt minnetrykk
FSDP full sharding: SMDDP-forbedring over NCCL
Som vist i den forrige tabellen, når modellene er fullstendig sønderdelt med FSDP, selv om NCCL (TFLOPs #0) og SMDDP (TFLOPs #1) gjennomstrømninger er sammenlignbare ved 32 eller 64 noder, er det en enorm forbedring på 50.4 % fra NCCL til SMDDP ved 128 noder.
Ved mindre modellstørrelser observerer vi konsistente og betydelige forbedringer med SMDDP i forhold til NCCL, og starter ved mindre klyngestørrelser, fordi SMDDP er i stand til å redusere kommunikasjonsflaskehalsen effektivt.
FSDP hybrid skjæring for å redusere kommunikasjonskostnadene
I SMP 1.0 lanserte vi sharded data parallellisme, en distribuert treningsteknikk drevet av Amazon internt MiCS teknologi. I SMP 2.0 introduserer vi SMP hybrid sharding, en utvidbar og mer fleksibel hybrid sharding-teknikk som gjør at modeller kan sønderdeles blant et undersett av GPUer, i stedet for alle trenings-GPUer, som er tilfellet for FSDP full sharding. Det er nyttig for mellomstore modeller som ikke trenger å deles over hele klyngen for å tilfredsstille minnebegrensninger per GPU. Dette fører til at klynger har mer enn én modellreplika og hver GPU kommuniserer med færre jevnaldrende under kjøring.
SMPs hybrid-sharding muliggjør effektiv modell-sharding over et bredere område, fra den minste shard-graden uten problemer med minnet opp til hele klyngestørrelsen (som tilsvarer full sharding).
Følgende figur illustrerer gjennomstrømningsavhengigheten av sdp ved tp = 1 for enkelhets skyld. Selv om det ikke nødvendigvis er det samme som den optimale tp-verdien for NCCL eller SMDDP full sharding i forrige tabell, er tallene ganske nærme. Det validerer tydelig verdien av å bytte fra full sharding til hybrid sharding ved en stor klyngestørrelse på 128 noder, som gjelder både NCCL og SMDDP. For mindre modellstørrelser starter betydelige forbedringer med hybrid sharding ved mindre klyngestørrelser, og forskjellen fortsetter å øke med klyngestørrelsen.
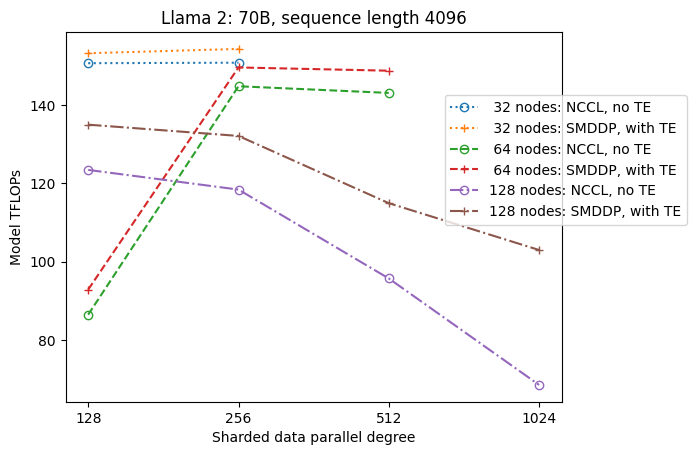
Forbedringer med TE
TE er designet for å akselerere LLM-trening på NVIDIA GPUer. Til tross for at vi ikke bruker FP8 fordi den ikke støttes på p4d-forekomster, ser vi fortsatt betydelig hastighetsøkning med TE på p4d.
På toppen av MiCS trent med SMDDP-backend, introduserer TE et konsekvent løft for gjennomstrømning på tvers av alle klyngestørrelser (det eneste unntaket er full sharding ved 128 noder), selv når tensorparallellisme er deaktivert (tensorparallellgrad er 1).
For mindre modellstørrelser eller ulike sekvenslengder er TE-boosten stabil og ikke-triviell, i området ca. 3–7.6 %.
Aktivering avlasting ved lave ressursinnstillinger
Ved lave ressursinnstillinger (gitt et lite antall noder), kan FSDP oppleve et høyt minnetrykk (eller til og med tom for minne i verste fall) når aktiveringssjekkpunkt er aktivert. For slike scenarier med flaskehalser av minne, er å slå på aktiveringsavlasting potensielt et alternativ for å forbedre ytelsen.
For eksempel, som vi så tidligere, selv om Llama 2 i modellstørrelse 13B og sekvenslengde 4,096 er i stand til å trene optimalt med minst 32 noder med aktiveringssjekkpunkt og uten aktiveringsavlasting, oppnår den den beste gjennomstrømningen med aktiveringsavlasting når den er begrenset til 16 noder.
Aktiver trening med lange sekvenser: SMP tensor parallellisme
Lengre sekvenslengder er ønsket for lange samtaler og kontekst, og får mer oppmerksomhet i LLM-miljøet. Derfor rapporterer vi forskjellige langsekvensgjennomstrømmer i følgende tabell. Tabellen viser optimale gjennomstrømninger for Llama 2-trening på SageMaker, med ulike sekvenslengder fra 2,048 32,768 opp til 32,768 32. Ved sekvenslengde 4 XNUMX er innfødt FSDP-trening umulig med XNUMX noder med en global batchstørrelse på XNUMX millioner.
| . | . | . | TFLOPS | ||
| Modellstørrelse | Sekvenslengde | Antall noder | Innfødt FSDP og NCCL | SMP og SMDDP | SMP forbedring |
| 7B | 2048 | 32 | 129.25 | 138.17 | 6.9% |
| 4096 | 32 | 124.38 | 132.65 | 6.6% | |
| 8192 | 32 | 115.25 | 123.11 | 6.8% | |
| 16384 | 32 | 100.73 | 109.11 | 8.3% | |
| 32768 | 32 | NA | 82.87 | . | |
| 13B | 2048 | 32 | 137.75 | 144.28 | 4.7% |
| 4096 | 32 | 133.30 | 139.46 | 4.6% | |
| 8192 | 32 | 125.04 | 130.08 | 4.0% | |
| 16384 | 32 | 111.58 | 117.01 | 4.9% | |
| 32768 | 32 | NA | 92.38 | . | |
| *: maks | . | . | . | . | 8.3% |
| *: median | . | . | . | . | 5.8% |
Når klyngestørrelsen er stor og gitt en fast global batchstørrelse, kan noe modelltrening være umulig med innfødt PyTorch FSDP, som mangler en innebygd rørledning eller støtte for tensorparallellisme. I den foregående tabellen, gitt en global batchstørrelse på 4 millioner, 32 noder og sekvenslengde 32,768 0.5, er den effektive batchstørrelsen per GPU 2 (for eksempel tp = 1 med batchstørrelse XNUMX), noe som ellers ville vært umulig uten å introdusere tensorparallellisme.
konklusjonen
I dette innlegget demonstrerte vi effektiv LLM-trening med SMP og SMDDP på p4d-forekomster, og tilskrev bidrag til flere nøkkelfunksjoner, som SMDDP-forbedring over NCCL, fleksibel FSDP-hybrid-sharding i stedet for full sharding, TE-integrasjon og muliggjør tensorparallellisme til fordel for lange sekvenslengder. Etter å ha blitt testet over et bredt spekter av innstillinger med ulike modeller, modellstørrelser og sekvenslengder, viser den robuste nær-lineære skaleringseffektiviteter, opptil 128 p4d-forekomster på SageMaker. Oppsummert fortsetter SageMaker å være et kraftig verktøy for LLM-forskere og praktikere.
For å lære mer, se SageMaker modell parallellisme bibliotek v2, eller kontakt SMP-teamet på sm-model-parallel-feedback@amazon.com.
Takk til
Vi vil gjerne takke Robert Van Dusen, Ben Snyder, Gautam Kumar og Luis Quintela for deres konstruktive tilbakemeldinger og diskusjoner.
Om forfatterne

Xinle Sheila Liu er en SDE i Amazon SageMaker. På fritiden liker hun lesing og utendørssport.
 Suhit Kodgule er en programvareutviklingsingeniør med AWS Artificial Intelligence-gruppen som jobber med rammeverk for dyp læring. På fritiden liker han å gå tur, reise og lage mat.
Suhit Kodgule er en programvareutviklingsingeniør med AWS Artificial Intelligence-gruppen som jobber med rammeverk for dyp læring. På fritiden liker han å gå tur, reise og lage mat.
 Victor Zhu er programvareingeniør i distribuert dyplæring hos Amazon Web Services. Han kan bli funnet å nyte fotturer og brettspill rundt SF Bay Area.
Victor Zhu er programvareingeniør i distribuert dyplæring hos Amazon Web Services. Han kan bli funnet å nyte fotturer og brettspill rundt SF Bay Area.
 Derya Cavdar jobber som programvareingeniør i AWS. Hennes interesser inkluderer dyp læring og distribuert treningsoptimalisering.
Derya Cavdar jobber som programvareingeniør i AWS. Hennes interesser inkluderer dyp læring og distribuert treningsoptimalisering.
 Teng Xu er en programvareutviklingsingeniør i gruppen Distribuert opplæring i AWS AI. Han liker å lese.
Teng Xu er en programvareutviklingsingeniør i gruppen Distribuert opplæring i AWS AI. Han liker å lese.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://aws.amazon.com/blogs/machine-learning/distributed-training-and-efficient-scaling-with-the-amazon-sagemaker-model-parallel-and-data-parallel-libraries/

