Dette blogginnlegget er skrevet sammen med Caroline Chung fra Veoneer.
Veoneer er et globalt selskap innen bilelektronikk og verdensledende innen elektroniske sikkerhetssystemer for biler. De tilbyr klassens beste sikkerhetskontrollsystemer og har levert over 1 milliard elektroniske kontrollenheter og kollisjonssensorer til bilprodusenter globalt. Selskapet fortsetter å bygge på en 70-årig historie med utvikling av bilsikkerhet, og spesialiserer seg på banebrytende maskinvare og systemer som forhindrer trafikkhendelser og reduserer ulykker.
Automotive in-cabin sensing (ICS) er et fremvoksende rom som bruker en kombinasjon av flere typer sensorer som kameraer og radar, og kunstig intelligens (AI) og maskinlæring (ML) baserte algoritmer for å øke sikkerheten og forbedre kjøreopplevelsen. Å bygge et slikt system kan være en kompleks oppgave. Utviklere må manuelt kommentere store mengder bilder for opplærings- og testformål. Dette er svært tidkrevende og ressurskrevende. Omløpstiden for en slik oppgave er flere uker. Videre må bedrifter håndtere problemer som inkonsekvente merker på grunn av menneskelige feil.
AWS er fokusert på å hjelpe deg med å øke utviklingshastigheten og redusere kostnadene for å bygge slike systemer gjennom avanserte analyser som ML. Vår visjon er å bruke ML for automatisert merknad, muliggjør omskolering av sikkerhetsmodeller og sikre konsistente og pålitelige ytelsesmålinger. I dette innlegget deler vi hvordan, ved å samarbeide med Amazons verdensomspennende spesialistorganisasjon og Generativt AI Innovasjonssenter, utviklet vi en aktiv læringspipeline for avgrensningsbokser for bildehoder i kabinen og annotering av nøkkelpunkter. Løsningen reduserer kostnadene med over 90 %, akselererer merknadsprosessen fra uker til timer når det gjelder behandlingstid, og muliggjør gjenbruk for lignende ML-datamerkingsoppgaver.
Løsningsoversikt
Aktiv læring er en ML-tilnærming som involverer en iterativ prosess med å velge og kommentere de mest informative dataene for å trene en modell. Gitt et lite sett med merkede data og et stort sett med umerkede data, forbedrer aktiv læring modellens ytelse, reduserer merkeinnsatsen og integrerer menneskelig ekspertise for robuste resultater. I dette innlegget bygger vi en aktiv læringspipeline for bildekommentarer med AWS-tjenester.
Følgende diagram viser det overordnede rammeverket for vår aktive læringspipeline. Merkingsrørledningen tar bilder fra en Amazon enkel lagringstjeneste (Amazon S3) bøtte og gir ut kommenterte bilder i samarbeid med ML-modeller og menneskelig ekspertise. Opplæringspipelinen forhåndsbehandler data og bruker dem til å trene ML-modeller. Den første modellen er satt opp og trent på et lite sett med manuelt merkede data, og vil bli brukt i merkingspipelinen. Merkingsrørledningen og opplæringsrørledningen kan itereres gradvis med flere merkede data for å forbedre modellens ytelse.
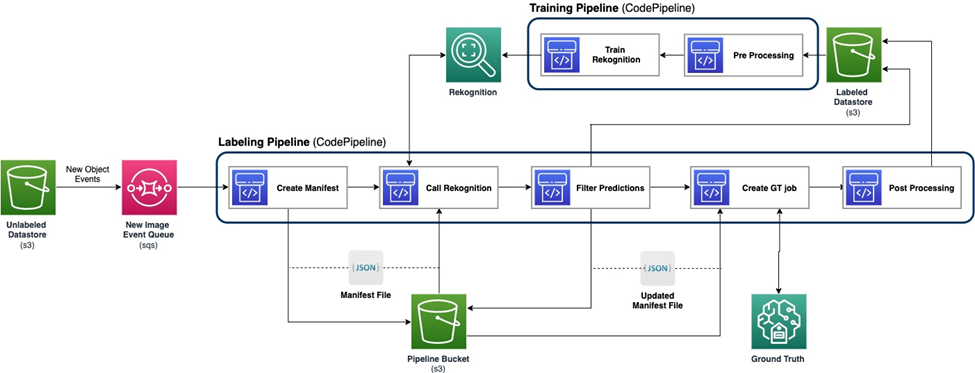
I merkingsrørledningen, en Amazon S3 hendelsesvarsling påkalles når en ny gruppe bilder kommer inn i Unlabeled Datastore S3-bøtten, og aktiverer merkerørledningen. Modellen produserer slutningsresultatene på de nye bildene. En tilpasset vurderingsfunksjon velger deler av dataene basert på konfidenspoengsummen eller andre brukerdefinerte funksjoner. Disse dataene, med sine slutningsresultater, sendes for en menneskelig merkingsjobb på Amazon SageMaker Ground Truth skapt av rørledningen. Den menneskelige merkingsprosessen hjelper til med å kommentere dataene, og de modifiserte resultatene kombineres med de gjenværende automatisk kommenterte dataene, som kan brukes senere av treningspipelinen.
Modellomopplæring skjer i opplæringspipelinen, der vi bruker datasettet som inneholder menneskemerkede data for å omskolere modellen. En manifestfil produseres for å beskrive hvor filene er lagret, og den samme innledende modellen omskoleres på de nye dataene. Etter omskolering erstatter den nye modellen den opprinnelige modellen, og neste iterasjon av den aktive læringspipelinen starter.
Modellutplassering
Både merkerørledningen og opplæringsrørledningen er utplassert på AWS CodePipeline. AWS CodeBuild instanser brukes til implementering, som er fleksibel og rask for en liten mengde data. Når fart er nødvendig, bruker vi Amazon SageMaker endepunkter basert på GPU-forekomsten for å tildele flere ressurser for å støtte og akselerere prosessen.
Modellomopplæringsrørledningen kan påkalles når det er nytt datasett eller når modellens ytelse trenger forbedring. En kritisk oppgave i omskoleringsrørledningen er å ha versjonskontrollsystemet for både opplæringsdata og modell. Selv om AWS-tjenester som f.eks Amazon-anerkjennelse har den integrerte versjonskontrollfunksjonen, som gjør pipelinen enkel å implementere, tilpassede modeller krever metadatalogging eller ekstra versjonskontrollverktøy.
Hele arbeidsflyten implementeres ved hjelp av AWS skyutviklingssett (AWS CDK) for å lage nødvendige AWS-komponenter, inkludert følgende:
- To roller for CodePipeline og SageMaker jobber
- To CodePipeline-jobber, som orkestrerer arbeidsflyten
- To S3-bøtter for kodeartefaktene til rørledningene
- Én S3-bøtte for merking av jobbmanifestet, datasett og modeller
- For- og etterbehandling AWS Lambda funksjoner for SageMaker Ground Truth-merkejobber
AWS CDK-stablene er svært modularisert og kan gjenbrukes på tvers av forskjellige oppgaver. Opplæringen, slutningskoden og SageMaker Ground Truth-malen kan erstattes for lignende aktive læringsscenarier.
Modelltrening
Modelltrening inkluderer to oppgaver: annotering av hodegrenseboks og annotering av menneskelige nøkkelpunkter. Vi introduserer dem begge i denne delen.
Merknad for hodeavgrensningsramme
Annotering av hodegrenseboks er en oppgave for å forutsi plasseringen av en avgrensningsramme til menneskehodet i et bilde. Vi bruker en Amazon Rekognition Egendefinerte etiketter modell for merknader for hodeavgrensende bokser. Følgende prøve notatbok gir en trinn-for-trinn-veiledning om hvordan du trener en Rekognition Custom Labels-modell via SageMaker.
Vi må først forberede dataene for å starte opplæringen. Vi genererer en manifestfil for opplæringen og en manifestfil for testdatasettet. En manifestfil inneholder flere elementer, som hver er for et bilde. Følgende er et eksempel på manifestfilen, som inkluderer bildebane, størrelse og merknadsinformasjon:
Ved å bruke manifestfilene kan vi laste datasett til en Rekognition Custom Labels-modell for opplæring og testing. Vi itererte modellen med forskjellige mengder treningsdata og testet den på de samme 239 usette bildene. I denne testen er mAP_50 poengsummen økte fra 0.33 med 114 treningsbilder til 0.95 med 957 treningsbilder. Følgende skjermbilde viser ytelsesverdiene til den endelige Rekognition Custom Labels-modellen, som gir god ytelse når det gjelder F1-poengsum, presisjon og tilbakekalling.

Vi testet modellen videre på et tilbakeholdt datasett som har 1,128 bilder. Modellen forutsier konsekvent nøyaktige grenseboksprediksjoner på de usynlige dataene, og gir en høy mAP_50 på 94.9 %. Følgende eksempel viser et automatisk kommentert bilde med en hodeavgrensningsramme.

Viktige punkter annotering
Nøkkelpunktkommentarer produserer plasseringer av nøkkelpunkter, inkludert øyne, ører, nese, munn, nakke, skuldre, albuer, håndledd, hofter og ankler. I tillegg til plasseringsprediksjonen, er det nødvendig med synlighet av hvert punkt for å forutsi i denne spesifikke oppgaven, som vi designer en ny metode for.
For nøkkelpunktkommentarer bruker vi en Yolo 8 Pose modell på SageMaker som den første modellen. Vi forbereder først dataene for opplæring, inkludert generering av etikettfiler og en konfigurasjons-.yaml-fil som følger Yolos krav. Etter å ha forberedt dataene, trener vi modellen og lagrer artefakter, inkludert modellvektfilen. Med den trente modellvektfilen kan vi kommentere de nye bildene.
I treningsstadiet brukes alle de merkede punktene med plasseringer, inkludert synlige punkter og okkluderte punkter, til trening. Derfor gir denne modellen som standard plasseringen og tilliten til prediksjonen. I den følgende figuren er en stor konfidensterskel (hovedterskel) nær 0.6 i stand til å dele punktene som er synlige eller okkluderte kontra utenfor kameraets synspunkter. Okkluderte punkter og synlige punkter er imidlertid ikke atskilt av konfidensen, noe som betyr at den forutsagte konfidensen ikke er nyttig for å forutsi synligheten.

For å få prediksjonen av synlighet introduserer vi en ekstra modell som er trent på datasettet som kun inneholder synlige punkter, ekskluderer både okkluderte punkter og utenfor kameraets synspunkter. Følgende figur viser fordelingen av punkter med ulik synlighet. Synlige punkter og andre punkter kan skilles i tilleggsmodellen. Vi kan bruke en terskel (ekstra terskel) nær 0.6 for å få de synlige punktene. Ved å kombinere disse to modellene designer vi en metode for å forutsi plassering og synlighet.

Et nøkkelpunkt predikeres først av hovedmodellen med plassering og hovedkonfidens, deretter får vi tilleggskonfidensprediksjonen fra tilleggsmodellen. Synligheten blir deretter klassifisert som følger:
- Synlig, hvis hovedkonfidensen er større enn hovedterskelen, og den ekstra konfidensen er større enn tilleggsterskelen
- Okkludert, hvis hovedkonfidensen er større enn hovedterskelen, og den ekstra konfidensen er mindre enn eller lik tilleggsterskelen
- Utenfor kameraets anmeldelse, hvis annet
Et eksempel på nøkkelpunktkommentarer er vist i følgende bilde, der solide merker er synlige punkter og hule merker er okkluderte punkter. Utenfor kameraets vurderingspunkter vises ikke.

Basert på standarden OKS definisjon på MS-COCO-datasettet, er metoden vår i stand til å oppnå mAP_50 på 98.4 % på det usynlige testdatasettet. Når det gjelder synlighet, gir metoden en klassifiseringsnøyaktighet på 79.2 % på samme datasett.
Menneskelig merking og omskolering
Selv om modellene oppnår god ytelse på testdata, er det fortsatt muligheter for å gjøre feil på nye virkelige data. Menneskelig merking er prosessen for å korrigere disse feilene for å forbedre modellens ytelse ved å bruke omskolering. Vi utviklet en vurderingsfunksjon som kombinerte konfidensverdien som ble levert fra ML-modellene for utdata fra alle hodeavgrensningsbokser eller nøkkelpunkter. Vi bruker sluttresultatet til å identifisere disse feilene og de resulterende dårlige merkede bildene, som må sendes til den menneskelige merkingsprosessen.
I tillegg til dårlig merkede bilder, er en liten del av bildene tilfeldig valgt for menneskelig merking. Disse menneskemerkede bildene legges til i den gjeldende versjonen av treningssettet for omskolering, forbedring av modellytelse og generell annoteringsnøyaktighet.
I implementeringen bruker vi SageMaker Ground Truth for menneskelig merking prosess. SageMaker Ground Truth gir et brukervennlig og intuitivt brukergrensesnitt for datamerking. Følgende skjermbilde demonstrerer en SageMaker Ground Truth-merkejobb for annotering av hodeavgrensende bokser.

Følgende skjermbilde demonstrerer en SageMaker Ground Truth-merkejobb for viktige punkter.

Kostnad, hastighet og gjenbrukbarhet
Kostnad og hastighet er de viktigste fordelene ved å bruke løsningen vår sammenlignet med menneskelig merking, som vist i tabellene nedenfor. Vi bruker disse tabellene for å representere kostnadsbesparelser og hastighetsakselerasjoner. Ved å bruke den akselererte GPU SageMaker-forekomsten ml.g4dn.xlarge, er trenings- og slutningskostnadene for hele livet på 100,000 99 bilder 10 % mindre enn kostnadene for menneskelig merking, mens hastigheten er 10,000–XNUMX XNUMX ganger raskere enn menneskelig merking, avhengig av oppgave.
Den første tabellen oppsummerer kostnadsytelsesberegningene.
| Modell | mAP_50 basert på 1,128 testbilder | Opplæringskostnad basert på 100,000 XNUMX bilder | Sluttkostnad basert på 100,000 XNUMX bilder | Kostnadsreduksjon sammenlignet med menneskelig merknad | Konklusjonstid basert på 100,000 XNUMX bilder | Tidsakselerasjon sammenlignet med menneskelig merknad |
| Avgrensningsboks for gjenkjennelseshode | 0.949 | $4 | $22 | 99% mindre | 5.5 h | Dager |
| Yolo Nøkkelpunkter | 0.984 | $27.20 | * $ 10 | 99.9% mindre | minutter | uker |
Tabellen nedenfor oppsummerer ytelsesberegninger.
| Merknadsoppgave | mAP_50 (%) | Opplæringskostnad ($) | Inferenskostnad ($) | Konklusjonstid |
| Hodeavgrensende boks | 94.9 | 4 | 22 | 5.5 timer |
| Viktige punkter | 98.4 | 27 | 10 | 5 minutter |
Dessuten gir vår løsning gjenbrukbarhet for lignende oppgaver. Utviklingen av kameraoppfatning for andre systemer som avansert førerassistentsystem (ADAS) og kabinsystemer kan også ta i bruk løsningen vår.
Oppsummering
I dette innlegget viste vi hvordan man bygger en aktiv læringspipeline for automatisk merknad av bilder i kabinen ved å bruke AWS-tjenester. Vi demonstrerer kraften til ML, som lar deg automatisere og fremskynde merknadsprosessen, og fleksibiliteten til rammeverket som bruker modeller enten støttet av AWS-tjenester eller tilpasset på SageMaker. Med Amazon S3, SageMaker, Lambda og SageMaker Ground Truth kan du strømlinjeforme datalagring, merknader, opplæring og distribusjon, og oppnå gjenbrukbarhet samtidig som du reduserer kostnadene betydelig. Ved å implementere denne løsningen kan bilbedrifter bli mer smidige og kostnadseffektive ved å bruke ML-basert avansert analyse som automatisert bildekommentar.
Kom i gang i dag og lås opp kraften til AWS tjenester og maskinlæring for brukstilfellene for registrering i kabinen i bilen din!
Om forfatterne
 Yanxiang Yu er en Applied Scientist ved Amazon Generative AI Innovation Center. Med over 9 års erfaring med å bygge AI og maskinlæringsløsninger for industrielle applikasjoner, spesialiserer han seg på generativ AI, datasyn og tidsseriemodellering.
Yanxiang Yu er en Applied Scientist ved Amazon Generative AI Innovation Center. Med over 9 års erfaring med å bygge AI og maskinlæringsløsninger for industrielle applikasjoner, spesialiserer han seg på generativ AI, datasyn og tidsseriemodellering.
 Tianyi Mao er en Applied Scientist ved AWS basert i Chicago-området. Han har 5+ års erfaring med å bygge maskinlæring og dyplæringsløsninger og fokuserer på datasyn og forsterkende læring med menneskelige tilbakemeldinger. Han liker å jobbe med kunder for å forstå deres utfordringer og løse dem ved å lage innovative løsninger ved å bruke AWS-tjenester.
Tianyi Mao er en Applied Scientist ved AWS basert i Chicago-området. Han har 5+ års erfaring med å bygge maskinlæring og dyplæringsløsninger og fokuserer på datasyn og forsterkende læring med menneskelige tilbakemeldinger. Han liker å jobbe med kunder for å forstå deres utfordringer og løse dem ved å lage innovative løsninger ved å bruke AWS-tjenester.
 Yanru Xiao er en Applied Scientist ved Amazon Generative AI Innovation Center, hvor han bygger AI/ML-løsninger for kunders virkelige forretningsproblemer. Han har jobbet innen flere felt, inkludert produksjon, energi og landbruk. Yanru oppnådde sin Ph.D. i informatikk fra Old Dominion University.
Yanru Xiao er en Applied Scientist ved Amazon Generative AI Innovation Center, hvor han bygger AI/ML-løsninger for kunders virkelige forretningsproblemer. Han har jobbet innen flere felt, inkludert produksjon, energi og landbruk. Yanru oppnådde sin Ph.D. i informatikk fra Old Dominion University.
 Paul George er en dyktig produktleder med over 15 års erfaring innen bilteknologi. Han er dyktig til å lede produktledelse, strategi, Go-to-Market og systemingeniørteam. Han har inkubert og lansert flere nye sanse- og persepsjonsprodukter globalt. Hos AWS leder han strategi og go-to-market for autonome kjøretøyarbeidsmengder.
Paul George er en dyktig produktleder med over 15 års erfaring innen bilteknologi. Han er dyktig til å lede produktledelse, strategi, Go-to-Market og systemingeniørteam. Han har inkubert og lansert flere nye sanse- og persepsjonsprodukter globalt. Hos AWS leder han strategi og go-to-market for autonome kjøretøyarbeidsmengder.
 Caroline Chung er ingeniørsjef i Veoneer (oppkjøpt av Magna International), hun har over 14 års erfaring med å utvikle sanse- og persepsjonssystemer. Hun leder for tiden pre-utviklingsprogrammer for interiørføling ved Magna International, og leder et team av databehandlingsingeniører og dataforskere.
Caroline Chung er ingeniørsjef i Veoneer (oppkjøpt av Magna International), hun har over 14 års erfaring med å utvikle sanse- og persepsjonssystemer. Hun leder for tiden pre-utviklingsprogrammer for interiørføling ved Magna International, og leder et team av databehandlingsingeniører og dataforskere.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://aws.amazon.com/blogs/machine-learning/build-an-active-learning-pipeline-for-automatic-annotation-of-images-with-aws-services/

