I dag bruker kunder i alle bransjer – enten det er finansielle tjenester, helsevesen og biovitenskap, reise og gjestfrihet, media og underholdning, telekommunikasjon, programvare som en tjeneste (SaaS), og til og med proprietære modellleverandører – store språkmodeller (LLM) for å bygge applikasjoner som spørsmål og svar (QnA) chatbots, søkemotorer og kunnskapsbaser. Disse generativ AI applikasjoner brukes ikke bare til å automatisere eksisterende forretningsprosesser, men har også muligheten til å transformere opplevelsen for kunder som bruker disse applikasjonene. Med fremskritt som gjøres med LLM-er som Mixtral-8x7B Instruk, avledet av arkitekturer som f.eks blanding av eksperter (MoE), leter kunder kontinuerlig etter måter å forbedre ytelsen og nøyaktigheten til generative AI-applikasjoner samtidig som de lar dem effektivt bruke et bredere spekter av lukkede og åpen kildekode-modeller.
En rekke teknikker brukes vanligvis for å forbedre nøyaktigheten og ytelsen til en LLMs utgang, for eksempel finjustering med parameter effektiv finjustering (PEFT), forsterkende læring fra menneskelig tilbakemelding (RLHF), og opptrer kunnskapsdestillasjon. Men når du bygger generative AI-applikasjoner, kan du bruke en alternativ løsning som tillater dynamisk inkorporering av ekstern kunnskap og lar deg kontrollere informasjonen som brukes for generering uten å måtte finjustere din eksisterende grunnmodell. Det er her Retrieval Augmented Generation (RAG) kommer inn, spesielt for generative AI-applikasjoner i motsetning til de dyrere og robuste finjusteringsalternativene vi har diskutert. Hvis du implementerer komplekse RAG-applikasjoner i dine daglige oppgaver, kan du støte på vanlige utfordringer med RAG-systemene dine, som unøyaktig henting, økende størrelse og kompleksitet på dokumenter og overflyt av kontekst, noe som kan påvirke kvaliteten og påliteligheten til genererte svar betydelig. .
Dette innlegget diskuterer RAG-mønstre for å forbedre responsnøyaktigheten ved å bruke LangChain og verktøy som den overordnede dokumenthenteren i tillegg til teknikker som kontekstuell komprimering for å gjøre det mulig for utviklere å forbedre eksisterende generative AI-applikasjoner.
Løsningsoversikt
I dette innlegget demonstrerer vi bruken av Mixtral-8x7B Instruct tekstgenerering kombinert med BGE Large En embedding-modellen for å effektivt konstruere et RAG QnA-system på en Amazon SageMaker-notisbok ved å bruke det overordnede dokumenthentingsverktøyet og kontekstuell komprimeringsteknikk. Følgende diagram illustrerer arkitekturen til denne løsningen.
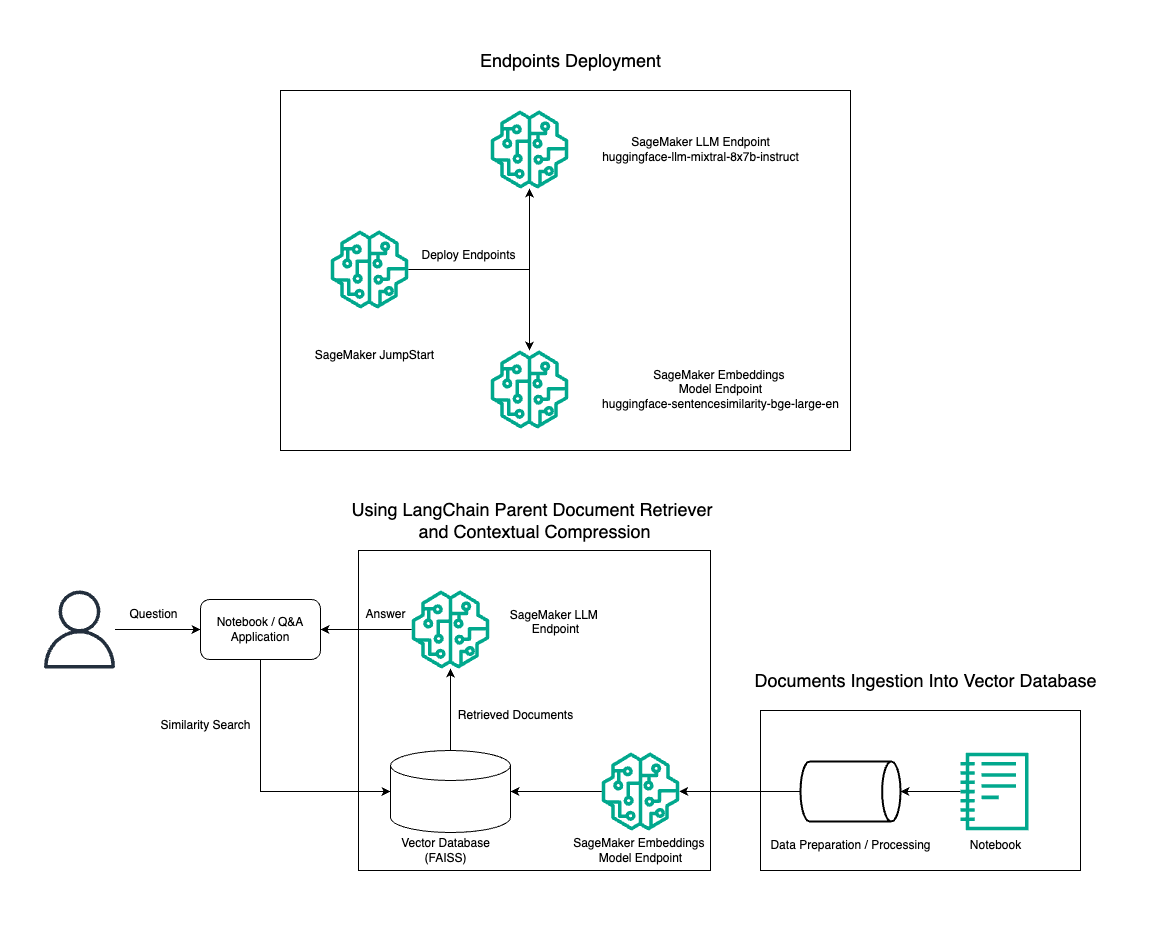
Du kan distribuere denne løsningen med bare noen få klikk ved å bruke Amazon SageMaker JumpStart, en fullt administrert plattform som tilbyr toppmoderne grunnmodeller for ulike brukstilfeller som innholdsskriving, kodegenerering, svar på spørsmål, copywriting, oppsummering, klassifisering og informasjonsinnhenting. Den gir en samling av forhåndstrente modeller som du kan distribuere raskt og enkelt, og akselererer utviklingen og distribusjonen av maskinlæringsapplikasjoner (ML). En av nøkkelkomponentene til SageMaker JumpStart er Model Hub, som tilbyr en stor katalog av forhåndsutdannede modeller, som Mixtral-8x7B, for en rekke oppgaver.
Mixtral-8x7B bruker en MoE-arkitektur. Denne arkitekturen lar ulike deler av et nevralt nettverk spesialisere seg i forskjellige oppgaver, og effektivt dele arbeidsmengden mellom flere eksperter. Denne tilnærmingen muliggjør effektiv opplæring og distribusjon av større modeller sammenlignet med tradisjonelle arkitekturer.
En av hovedfordelene med MoE-arkitekturen er dens skalerbarhet. Ved å fordele arbeidsmengden på flere eksperter, kan MoE-modeller trenes på større datasett og oppnå bedre ytelse enn tradisjonelle modeller av samme størrelse. I tillegg kan MoE-modeller være mer effektive under inferens fordi bare en undergruppe av eksperter må aktiveres for en gitt inngang.
For mer informasjon om Mixtral-8x7B Instruct på AWS, se Mixtral-8x7B er nå tilgjengelig i Amazon SageMaker JumpStart. Mixtral-8x7B-modellen er gjort tilgjengelig under den tillatelige Apache 2.0-lisensen, for bruk uten begrensninger.
I dette innlegget diskuterer vi hvordan du kan bruke Langkjede å skape effektive og mer effektive RAG-applikasjoner. LangChain er et åpen kildekode Python-bibliotek designet for å bygge applikasjoner med LLM-er. Det gir et modulært og fleksibelt rammeverk for å kombinere LLM-er med andre komponenter, for eksempel kunnskapsbaser, gjenfinningssystemer og andre AI-verktøy, for å lage kraftige og tilpassbare applikasjoner.
Vi går gjennom å bygge en RAG-rørledning på SageMaker med Mixtral-8x7B. Vi bruker Mixtral-8x7B Instruct-tekstgenereringsmodellen med BGE Large En-innbyggingsmodellen for å lage et effektivt QnA-system ved å bruke RAG på en SageMaker-notisbok. Vi bruker en ml.t3.medium-instans for å demonstrere distribusjon av LLM-er via SageMaker JumpStart, som kan nås via et SageMaker-generert API-endepunkt. Dette oppsettet gir mulighet for utforskning, eksperimentering og optimalisering av avanserte RAG-teknikker med LangChain. Vi illustrerer også integreringen av FAISS Embedding-butikken i RAG-arbeidsflyten, og fremhever dens rolle i lagring og henting av embeddings for å forbedre systemets ytelse.
Vi utfører en kort gjennomgang av SageMaker-notisboken. For mer detaljerte og trinnvise instruksjoner, se Avanserte RAG-mønstre med Mixtral på SageMaker Jumpstart GitHub-repo.
Behovet for avanserte RAG-mønstre
Avanserte RAG-mønstre er avgjørende for å forbedre de nåværende mulighetene til LLM-er når det gjelder å behandle, forstå og generere menneskelignende tekst. Etter hvert som størrelsen og kompleksiteten til dokumenter øker, kan det å representere flere fasetter av dokumentet i én enkelt innebygging føre til tap av spesifisitet. Selv om det er viktig å fange den generelle essensen av et dokument, er det like viktig å gjenkjenne og representere de varierte underkontekstene innenfor. Dette er en utfordring du ofte står overfor når du arbeider med større dokumenter. En annen utfordring med RAG er at med henting er du ikke klar over de spesifikke spørsmålene som dokumentlagringssystemet ditt vil håndtere ved inntak. Dette kan føre til at informasjon som er mest relevant for et søk, blir begravd under tekst (kontekstoverflyt). For å redusere feil og forbedre den eksisterende RAG-arkitekturen, kan du bruke avanserte RAG-mønstre (overordnet dokumenthenting og kontekstuell komprimering) for å redusere gjenfinningsfeil, forbedre svarkvaliteten og muliggjøre kompleks spørsmålshåndtering.
Med teknikkene som er diskutert i dette innlegget, kan du løse viktige utfordringer knyttet til ekstern kunnskapsinnhenting og integrasjon, slik at applikasjonen din kan levere mer presise og kontekstuelt bevisste svar.
I de følgende avsnittene undersøker vi hvordan overordnede dokumenthentere og kontekstuell komprimering kan hjelpe deg med å håndtere noen av problemene vi har diskutert.
Overordnet dokumenthenter
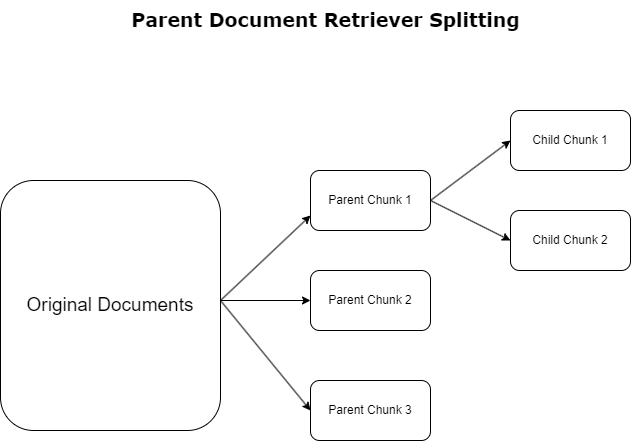
I forrige avsnitt belyste vi utfordringer som RAG-søknader møter ved håndtering av omfattende dokumenter. For å møte disse utfordringene, overordnede dokumenthentere kategorisere og utpeke innkommende dokumenter som overordnede dokumenter. Disse dokumentene er anerkjent for sin omfattende natur, men brukes ikke direkte i sin opprinnelige form for innebygging. I stedet for å komprimere et helt dokument til en enkelt innebygging, dissekerer overordnede dokumenthentere disse overordnede dokumentene til barnedokumenter. Hvert underordnede dokument fanger opp forskjellige aspekter eller emner fra det bredere overordnede dokumentet. Etter identifiseringen av disse underordnede segmentene, tildeles individuelle innebygginger til hver, og fanger deres spesifikke tematiske essens (se følgende diagram). Under henting påkalles det overordnede dokumentet. Denne teknikken gir målrettede, men likevel brede søkefunksjoner, og gir LLM et bredere perspektiv. Overordnede dokumenthentere gir LLM-er en todelt fordel: spesifisiteten til underordnede dokumentinnbygginger for presis og relevant informasjonshenting, kombinert med påkalling av overordnede dokumenter for responsgenerering, som beriker LLMs utdata med en lagdelt og grundig kontekst.
Kontekstuell komprimering
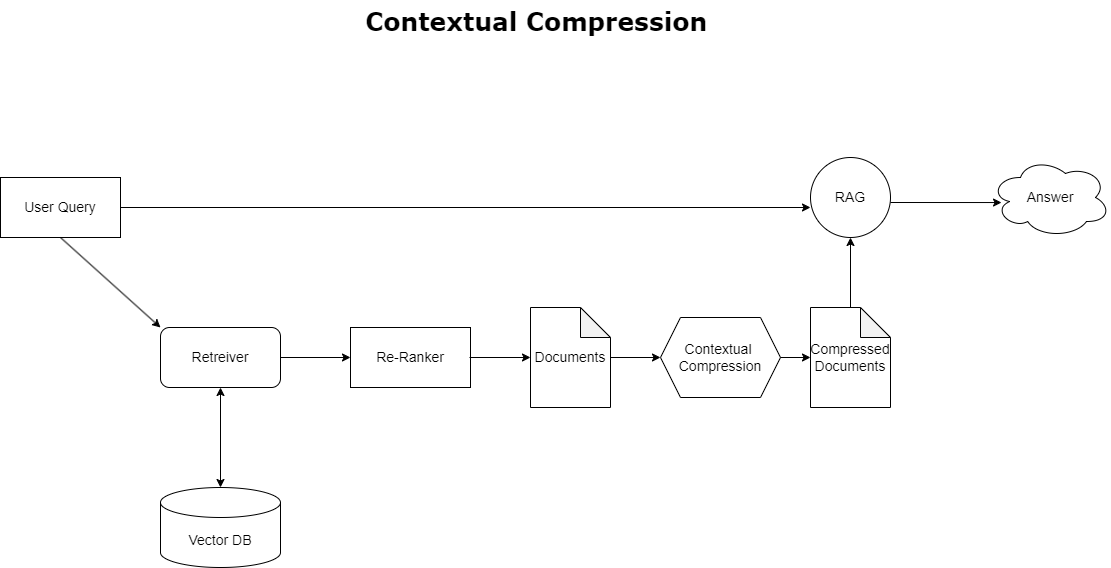
For å løse problemet med kontekstoverflyt diskutert tidligere, kan du bruke kontekstuell komprimering for å komprimere og filtrere de hentede dokumentene i samsvar med søkets kontekst, slik at bare relevant informasjon oppbevares og behandles. Dette oppnås gjennom en kombinasjon av en base retriever for innledende dokumenthenting og en dokumentkompressor for å avgrense disse dokumentene ved å redusere innholdet eller ekskludere dem helt basert på relevans, som illustrert i følgende diagram. Denne strømlinjeformede tilnærmingen, tilrettelagt av den kontekstuelle komprimeringsgjenvinneren, forbedrer RAG-applikasjonseffektiviteten betraktelig ved å tilby en metode for å trekke ut og bruke bare det som er essensielt fra en masse informasjon. Den takler spørsmålet om overbelastning av informasjon og irrelevant databehandling direkte, noe som fører til forbedret responskvalitet, mer kostnadseffektive LLM-operasjoner og en jevnere generell gjenfinningsprosess. I hovedsak er det et filter som skreddersyr informasjonen til søket for hånden, noe som gjør det til et sårt tiltrengt verktøy for utviklere som tar sikte på å optimalisere RAG-applikasjonene sine for bedre ytelse og brukertilfredshet.
Forutsetninger
Hvis du er ny på SageMaker, se Amazon SageMaker utviklingsveiledning.
Før du begynner med løsningen, opprette en AWS-konto. Når du oppretter en AWS-konto, får du en enkelt påloggingsidentitet (SSO) som har full tilgang til alle AWS-tjenestene og ressursene i kontoen. Denne identiteten kalles AWS-kontoen root bruker.
Pålogging til AWS-administrasjonskonsoll bruk av e-postadressen og passordet du brukte til å opprette kontoen gir deg full tilgang til alle AWS-ressursene i kontoen din. Vi anbefaler på det sterkeste at du ikke bruker root-brukeren til daglige oppgaver, selv ikke de administrative.
Følg i stedet beste praksis for sikkerhet in AWS identitets- og tilgangsadministrasjon (IAM), og opprette en administrativ bruker og gruppe. Lås deretter rotbrukerlegitimasjonen på en sikker måte og bruk dem til å utføre bare noen få konto- og tjenesteadministrasjonsoppgaver.
Mixtral-8x7b-modellen krever en ml.g5.48xlarge-instans. SageMaker JumpStart gir en forenklet måte å få tilgang til og distribuere over 100 forskjellige open source- og tredjeparts fundamentmodeller. For å lanser et endepunkt for å være vert for Mixtral-8x7B fra SageMaker JumpStart, kan det hende du må be om å øke tjenestekvoten for å få tilgang til en ml.g5.48xlarge-forekomst for endepunktbruk. Du kan be om økte tjenestekvoter gjennom konsollen, AWS kommandolinjegrensesnitt (AWS CLI), eller API for å gi tilgang til disse ekstra ressursene.
Sett opp en SageMaker notatbokforekomst og installer avhengigheter
For å komme i gang, opprett en SageMaker notatbokforekomst og installer de nødvendige avhengighetene. Referere til GitHub repo for å sikre et vellykket oppsett. Etter at du har konfigurert den bærbare forekomsten, kan du distribuere modellen.
Du kan også kjøre den bærbare PC-en lokalt på ditt foretrukne integrerte utviklingsmiljø (IDE). Sørg for at du har Jupyter notebook lab installert.
Distribuer modellen
Distribuer Mixtral-8X7B Instruct LLM-modellen på SageMaker JumpStart:
Distribuer BGE Large En embedding-modellen på SageMaker JumpStart:
Sett opp LangChain
Etter å ha importert alle nødvendige biblioteker og distribuert Mixtral-8x7B-modellen og BGE Large En embeddings-modellen, kan du nå sette opp LangChain. For trinnvise instruksjoner, se GitHub repo.
Dataforberedelse
I dette innlegget bruker vi flere år med Amazons brev til aksjonærene som et tekstkorpus å utføre QnA på. For mer detaljerte trinn for å forberede dataene, se GitHub repo.
Svar på spørsmål
Når dataene er klargjort, kan du bruke innpakningen levert av LangChain, som vikler seg rundt vektorlageret og tar inndata for LLM. Denne innpakningen utfører følgende trinn:
- Ta innspillsspørsmålet.
- Lag en innbygging av spørsmål.
- Hent relevante dokumenter.
- Inkorporer dokumentene og spørsmålet i en ledetekst.
- Påkall modellen med ledeteksten og generer svaret på en lesbar måte.
Nå som vektorbutikken er på plass, kan du begynne å stille spørsmål:
Vanlig retrieverkjede
I det foregående scenariet utforsket vi den raske og greie måten å få et kontekstbevisst svar på spørsmålet ditt. La oss nå se på et mer tilpassbart alternativ ved hjelp av RetrievalQA, hvor du kan tilpasse hvordan dokumentene som hentes skal legges til ledeteksten ved å bruke parameteren chain_type. For å kontrollere hvor mange relevante dokumenter som skal hentes, kan du også endre k-parameteren i følgende kode for å se forskjellige utdata. I mange scenarier vil du kanskje vite hvilke kildedokumenter LLM brukte for å generere svaret. Du kan få disse dokumentene i utdataene ved å bruke return_source_documents, som returnerer dokumentene som er lagt til konteksten til LLM-ledeteksten. RetrievalQA lar deg også gi en tilpasset forespørselsmal som kan være spesifikk for modellen.
La oss stille et spørsmål:
Overordnet dokumenthenterkjede
La oss se på et mer avansert RAG-alternativ ved hjelp av ParentDocumentRetriever. Når du arbeider med dokumentinnhenting, kan du støte på en avveining mellom å lagre små biter av et dokument for nøyaktig innebygging og større dokumenter for å bevare mer kontekst. Den overordnede dokumenthenteren oppnår den balansen ved å dele opp og lagre små databiter.
Vi bruker en parent_splitter å dele opp originaldokumentene i større deler kalt overordnede dokumenter og en child_splitter for å lage mindre underordnede dokumenter fra originaldokumentene:
De underordnede dokumentene indekseres deretter i et vektorlager ved hjelp av innbygginger. Dette muliggjør effektiv gjenfinning av relevante underordnede dokumenter basert på likhet. For å hente relevant informasjon, henter den overordnede dokumenthenteren først de underordnede dokumentene fra vektorlageret. Den slår deretter opp foreldre-ID-ene for disse underdokumentene og returnerer de tilsvarende større overordnede dokumentene.
La oss stille et spørsmål:
Kontekstuell kompresjonskjede
La oss se på et annet avansert RAG-alternativ kalt kontekstuell komprimering. En utfordring med henting er at vi vanligvis ikke vet hvilke spesifikke spørsmål dokumentlagringssystemet ditt vil møte når du tar inn data i systemet. Dette betyr at den informasjonen som er mest relevant for en spørring, kan være begravd i et dokument med mye irrelevant tekst. Å sende det fullstendige dokumentet gjennom søknaden din kan føre til dyrere LLM-samtaler og dårligere svar.
Den kontekstuelle komprimeringsgjenvinneren løser utfordringen med å hente relevant informasjon fra et dokumentlagringssystem, der relevante data kan begraves i dokumenter som inneholder mye tekst. Ved å komprimere og filtrere de hentede dokumentene basert på den gitte spørringskonteksten, returneres kun den mest relevante informasjonen.
For å bruke kontekstuell komprimeringsretriever trenger du:
- En base retriever – Dette er den første henteren som henter dokumenter fra lagringssystemet basert på spørringen
- En dokumentkompressor – Denne komponenten tar de opprinnelig hentede dokumentene og forkorter dem ved å redusere innholdet i individuelle dokumenter eller slette irrelevante dokumenter helt, ved å bruke søkekonteksten for å bestemme relevansen
Legger til kontekstuell komprimering med en LLM-kjedeuttrekker
Pakk først inn base retrieveren med en ContextualCompressionRetriever. Du legger til en LLMChainExtractor, som vil iterere over de opprinnelig returnerte dokumentene og trekke ut fra hvert av bare innholdet som er relevant for spørringen.
Initialiser kjeden ved å bruke ContextualCompressionRetriever med en LLMChainExtractor og send ledeteksten inn via chain_type_kwargs argument.
La oss stille et spørsmål:
Filtrer dokumenter med et LLM-kjedefilter
De LLMChainFilter er en litt enklere, men mer robust kompressor som bruker en LLM-kjede for å bestemme hvilke av de opprinnelig hentede dokumentene som skal filtreres ut og hvilke som skal returneres, uten å manipulere dokumentinnholdet:
Initialiser kjeden ved å bruke ContextualCompressionRetriever med en LLMChainFilter og send ledeteksten inn via chain_type_kwargs argument.
La oss stille et spørsmål:
Sammenlign resultater
Tabellen nedenfor sammenligner resultater fra forskjellige søk basert på teknikk.
| Teknikk | Spørring 1 | Spørring 2 | Sammenligning |
| Hvordan utviklet AWS seg? | Hvorfor er Amazon vellykket? | ||
| Vanlig Retriever-kjedeutgang | AWS (Amazon Web Services) utviklet seg fra en i utgangspunktet ulønnsom investering til en årlig omsetningsvirksomhet på $85 milliarder med sterk lønnsomhet, som tilbyr et bredt spekter av tjenester og funksjoner, og har blitt en betydelig del av Amazons portefølje. Til tross for skepsis og kortsiktig motvind, fortsatte AWS å innovere, tiltrekke seg nye kunder og migrere aktive kunder, og tilby fordeler som smidighet, innovasjon, kostnadseffektivitet og sikkerhet. AWS utvidet også sine langsiktige investeringer, inkludert utvikling av brikke, for å gi nye muligheter og endre hva som er mulig for kundene. | Amazon er vellykket på grunn av sin kontinuerlige innovasjon og ekspansjon til nye områder som teknologiske infrastrukturtjenester, digitale leseenheter, stemmedrevne personlige assistenter og nye forretningsmodeller som tredjepartsmarkedet. Dens evne til å skalere operasjoner raskt, som sett i den raske utvidelsen av oppfyllelses- og transportnettverk, bidrar også til suksessen. I tillegg har Amazons fokus på optimalisering og effektivitetsgevinster i prosessene resultert i produktivitetsforbedringer og kostnadsreduksjoner. Eksemplet med Amazon Business fremhever selskapets evne til å utnytte sine e-handels- og logistikkstyrker i forskjellige sektorer. | Basert på svarene fra den vanlige retrieverkjeden, legger vi merke til at selv om den gir lange svar, lider den av kontekstoverflyt og unnlater å nevne noen vesentlige detaljer fra korpuset i forhold til å svare på spørringen som er gitt. Den vanlige gjenfinningskjeden er ikke i stand til å fange nyansene med dybde eller kontekstuell innsikt, og mangler potensielt kritiske aspekter ved dokumentet. |
| Utdata for overordnet dokumenthenting | AWS (Amazon Web Services) startet med en funksjonsfattig første lansering av Elastic Compute Cloud (EC2)-tjenesten i 2006, og ga kun én forekomststørrelse, i ett datasenter, i én region i verden, med kun Linux-operativsystemforekomster , og uten mange nøkkelfunksjoner som overvåking, lastbalansering, automatisk skalering eller vedvarende lagring. AWSs suksess gjorde det imidlertid mulig for dem å raskt gjenta og legge til de manglende egenskapene, og til slutt utvide til å tilby ulike smaker, størrelser og optimaliseringer av databehandling, lagring og nettverk, samt utvikle sine egne brikker (Graviton) for å presse pris og ytelse ytterligere . AWS sin iterative innovasjonsprosess krevde betydelige investeringer i økonomiske og menneskelige ressurser over 20 år, ofte i god tid før den skulle betale seg, for å møte kundenes behov og forbedre langsiktige kundeopplevelser, lojalitet og avkastning for aksjonærene. | Amazon har suksess på grunn av sin evne til å kontinuerlig innovere, tilpasse seg endrede markedsforhold og møte kundenes behov i ulike markedssegmenter. Dette er tydelig i suksessen til Amazon Business, som har vokst til å drive rundt 35 milliarder dollar i årlig bruttosalg ved å levere utvalg, verdi og bekvemmelighet til bedriftskunder. Amazons investeringer i e-handel og logistikk har også muliggjort opprettelsen av tjenester som Buy with Prime, som hjelper selgere med direkte-til-forbruker-nettsteder med å drive konvertering fra visninger til kjøp. | Den overordnede dokumenthenteren går dypere inn i detaljene i AWS sin vekststrategi, inkludert den iterative prosessen med å legge til nye funksjoner basert på tilbakemeldinger fra kunder og den detaljerte reisen fra en funksjonsfattig initial lansering til en dominerende markedsposisjon, samtidig som den gir en kontekstrik respons. . Svarene dekker et bredt spekter av aspekter, fra tekniske innovasjoner og markedsstrategi til organisatorisk effektivitet og kundefokus, og gir et helhetlig syn på faktorene som bidrar til suksess sammen med eksempler. Dette kan tilskrives den overordnede dokumenthenterens målrettede, men likevel brede søkefunksjoner. |
| LLM Chain Extractor: Kontekstuell komprimeringsutgang | AWS utviklet seg ved å starte som et lite prosjekt i Amazon, som krevde betydelige kapitalinvesteringer og møtte skepsis fra både i og utenfor selskapet. AWS hadde imidlertid et forsprang på potensielle konkurrenter og trodde på verdien det kunne gi kunder og Amazon. AWS forpliktet seg til å fortsette å investere, noe som resulterte i over 3,300 2022 nye funksjoner og tjenester lansert i 85. AWS har transformert hvordan kundene administrerer teknologiinfrastrukturen sin og har blitt en virksomhet med høy lønnsomhet på $2 milliarder årlig omsetning. AWS har også kontinuerlig forbedret tilbudene sine, for eksempel å forbedre ECXNUMX med tilleggsfunksjoner og tjenester etter den første lanseringen. | Basert på den angitte konteksten kan Amazons suksess tilskrives dens strategiske ekspansjon fra en boksalgsplattform til en global markedsplass med et levende tredjeparts selgerøkosystem, tidlig investering i AWS, innovasjon ved introduksjonen av Kindle og Alexa, og betydelig vekst i årlige inntekter fra 2019 til 2022. Denne veksten førte til utvidelse av oppfyllingssenterets fotavtrykk, opprettelse av et siste-mile-transportnettverk og bygging av et nytt sorteringssenternettverk, som var optimalisert for produktivitet og kostnadsreduksjoner. | LLM-kjedeavtrekkeren opprettholder en balanse mellom å dekke nøkkelpunkter omfattende og unngå unødvendig dybde. Den justerer seg dynamisk til søkets kontekst, slik at utdataene er direkte relevante og omfattende. |
| LLM-kjedefilter: Kontekstuell komprimeringsutgang | AWS (Amazon Web Services) utviklet seg ved først å lansere funksjonsfattige, men gjenta raskt basert på tilbakemeldinger fra kunder for å legge til nødvendige funksjoner. Denne tilnærmingen gjorde det mulig for AWS å lansere EC2 i 2006 med begrensede funksjoner og deretter kontinuerlig legge til nye funksjoner, som ekstra forekomststørrelser, datasentre, regioner, operativsystemalternativer, overvåkingsverktøy, lastbalansering, automatisk skalering og vedvarende lagring. Over tid forvandlet AWS seg fra en funksjonsfattig tjeneste til en virksomhet med flere milliarder dollar ved å fokusere på kundebehov, smidighet, innovasjon, kostnadseffektivitet og sikkerhet. AWS har nå en årlig omsetning på 85 milliarder dollar og tilbyr over 3,300 XNUMX nye funksjoner og tjenester hvert år, som serverer et bredt spekter av kunder fra oppstartsbedrifter til multinasjonale selskaper og offentlige organisasjoner. | Amazon er vellykket på grunn av sine innovative forretningsmodeller, kontinuerlige teknologiske fremskritt og strategiske organisatoriske endringer. Selskapet har konsekvent forstyrret tradisjonelle næringer ved å introdusere nye ideer, for eksempel en e-handelsplattform for ulike produkter og tjenester, en tredjeparts markedsplass, skyinfrastrukturtjenester (AWS), Kindle e-leser og Alexa stemmedrevne personlige assistenter . I tillegg har Amazon foretatt strukturelle endringer for å forbedre effektiviteten, for eksempel å omorganisere sitt amerikanske oppfyllingsnettverk for å redusere kostnader og leveringstider, noe som ytterligere bidrar til suksessen. | I likhet med LLM-kjedeuttrekkeren sørger LLM-kjedefilteret for at selv om nøkkelpunktene er dekket, er produksjonen effektiv for kunder som leter etter konsise og kontekstuelle svar. |
Ved å sammenligne disse forskjellige teknikkene, kan vi se at i sammenhenger som å detaljere AWS sin overgang fra en enkel tjeneste til en kompleks enhet på flere milliarder dollar, eller forklare Amazons strategiske suksesser, mangler den vanlige retrieverkjeden presisjonen de mer sofistikerte teknikkene tilbyr, fører til mindre målrettet informasjon. Selv om svært få forskjeller er synlige mellom de avanserte teknikkene som er diskutert, er de langt mer informative enn vanlige retrieverkjeder.
For kunder i bransjer som helsevesen, telekommunikasjon og finansielle tjenester som ønsker å implementere RAG i sine applikasjoner, gjør begrensningene til den vanlige retrieverkjeden med å gi presisjon, unngå redundans og effektivt komprimere informasjon den mindre egnet til å oppfylle disse behovene sammenlignet med til den mer avanserte overordnede dokumenthenteren og kontekstuelle komprimeringsteknikker. Disse teknikkene er i stand til å destillere enorme mengder informasjon til den konsentrerte, virkningsfulle innsikten du trenger, samtidig som de bidrar til å forbedre prisytelsen.
Rydd opp
Når du er ferdig med å kjøre notatblokken, slett ressursene du opprettet for å unngå påløping av kostnader for ressursene som er i bruk:
konklusjonen
I dette innlegget presenterte vi en løsning som lar deg implementere den overordnede dokumentgjenvinneren og kontekstuelle komprimeringskjedeteknikkene for å forbedre LLM-ers evne til å behandle og generere informasjon. Vi testet ut disse avanserte RAG-teknikkene med Mixtral-8x7B Instruct- og BGE Large En-modellene tilgjengelig med SageMaker JumpStart. Vi utforsket også bruk av vedvarende lagring for innebygging og dokumentbiter og integrasjon med bedriftsdatalagre.
Teknikkene vi utførte avgrenser ikke bare måten LLM-modeller får tilgang til og innlemmer ekstern kunnskap, men forbedrer også kvaliteten, relevansen og effektiviteten til resultatene deres betydelig. Ved å kombinere henting fra store tekstkorpuer med språkgenereringsevner, gjør disse avanserte RAG-teknikkene det mulig for LLM-er å produsere mer faktabaserte, sammenhengende og konteksttilpassede svar, og forbedre ytelsen deres på tvers av ulike naturlig språkbehandlingsoppgaver.
SageMaker JumpStart er i sentrum av denne løsningen. Med SageMaker JumpStart får du tilgang til et omfattende utvalg av modeller med åpen og lukket kildekode, som effektiviserer prosessen med å komme i gang med ML og muliggjør rask eksperimentering og distribusjon. For å komme i gang med å distribuere denne løsningen, naviger til notatboken i GitHub repo.
Om forfatterne
 Niithiyn Vijeaswaran er løsningsarkitekt hos AWS. Fokusområdet hans er generative AI og AWS AI Accelerators. Han har en bachelorgrad i informatikk og bioinformatikk. Niithiyn jobber tett med Generative AI GTM-teamet for å aktivere AWS-kunder på flere fronter og akselerere deres bruk av generativ AI. Han er en ivrig fan av Dallas Mavericks og liker å samle joggesko.
Niithiyn Vijeaswaran er løsningsarkitekt hos AWS. Fokusområdet hans er generative AI og AWS AI Accelerators. Han har en bachelorgrad i informatikk og bioinformatikk. Niithiyn jobber tett med Generative AI GTM-teamet for å aktivere AWS-kunder på flere fronter og akselerere deres bruk av generativ AI. Han er en ivrig fan av Dallas Mavericks og liker å samle joggesko.
 Sebastian Bustillo er løsningsarkitekt hos AWS. Han fokuserer på AI/ML-teknologier med en dyp lidenskap for generativ AI og dataakseleratorer. Hos AWS hjelper han kundene med å låse opp forretningsverdi gjennom generativ AI. Når han ikke er på jobb, liker han å brygge en perfekt kopp spesialkaffe og utforske verden sammen med kona.
Sebastian Bustillo er løsningsarkitekt hos AWS. Han fokuserer på AI/ML-teknologier med en dyp lidenskap for generativ AI og dataakseleratorer. Hos AWS hjelper han kundene med å låse opp forretningsverdi gjennom generativ AI. Når han ikke er på jobb, liker han å brygge en perfekt kopp spesialkaffe og utforske verden sammen med kona.
 Armando Diaz er løsningsarkitekt hos AWS. Han fokuserer på generativ AI, AI/ML og dataanalyse. Hos AWS hjelper Armando kunder med å integrere banebrytende generative AI-funksjoner i systemene sine, og fremmer innovasjon og konkurransefortrinn. Når han ikke er på jobb, liker han å tilbringe tid med kona og familien, gå på fotturer og reise verden rundt.
Armando Diaz er løsningsarkitekt hos AWS. Han fokuserer på generativ AI, AI/ML og dataanalyse. Hos AWS hjelper Armando kunder med å integrere banebrytende generative AI-funksjoner i systemene sine, og fremmer innovasjon og konkurransefortrinn. Når han ikke er på jobb, liker han å tilbringe tid med kona og familien, gå på fotturer og reise verden rundt.
 Dr. Farooq Sabir er senior spesialistløsningsarkitekt for kunstig intelligens og maskinlæring ved AWS. Han har PhD- og MS-grader i elektroteknikk fra University of Texas i Austin og en MS i informatikk fra Georgia Institute of Technology. Han har over 15 års arbeidserfaring og liker også å undervise og veilede studenter. Hos AWS hjelper han kunder med å formulere og løse forretningsproblemer innen datavitenskap, maskinlæring, datasyn, kunstig intelligens, numerisk optimalisering og relaterte domener. Basert i Dallas, Texas, elsker han og familien å reise og dra på lange bilturer.
Dr. Farooq Sabir er senior spesialistløsningsarkitekt for kunstig intelligens og maskinlæring ved AWS. Han har PhD- og MS-grader i elektroteknikk fra University of Texas i Austin og en MS i informatikk fra Georgia Institute of Technology. Han har over 15 års arbeidserfaring og liker også å undervise og veilede studenter. Hos AWS hjelper han kunder med å formulere og løse forretningsproblemer innen datavitenskap, maskinlæring, datasyn, kunstig intelligens, numerisk optimalisering og relaterte domener. Basert i Dallas, Texas, elsker han og familien å reise og dra på lange bilturer.
 Marco Punio er en løsningsarkitekt med fokus på generativ AI-strategi, anvendte AI-løsninger og forskning for å hjelpe kunder med å hyperskalere på AWS. Marco er en digital native sky-rådgiver med erfaring innen FinTech, Healthcare & Life Sciences, Software-as-a-service, og nå sist innen telekommunikasjonsindustrien. Han er en kvalifisert teknolog med lidenskap for maskinlæring, kunstig intelligens og fusjoner og oppkjøp. Marco er basert i Seattle, WA og liker å skrive, lese, trene og bygge applikasjoner på fritiden.
Marco Punio er en løsningsarkitekt med fokus på generativ AI-strategi, anvendte AI-løsninger og forskning for å hjelpe kunder med å hyperskalere på AWS. Marco er en digital native sky-rådgiver med erfaring innen FinTech, Healthcare & Life Sciences, Software-as-a-service, og nå sist innen telekommunikasjonsindustrien. Han er en kvalifisert teknolog med lidenskap for maskinlæring, kunstig intelligens og fusjoner og oppkjøp. Marco er basert i Seattle, WA og liker å skrive, lese, trene og bygge applikasjoner på fritiden.
 AJ Dhimine er løsningsarkitekt hos AWS. Han spesialiserer seg på generativ AI, serverløs databehandling og dataanalyse. Han er et aktivt medlem/mentor i Machine Learning Technical Field Community og har publisert flere vitenskapelige artikler om ulike AI/ML-emner. Han jobber med kunder, alt fra oppstartsbedrifter til bedrifter, for å utvikle AWSome generative AI-løsninger. Han er spesielt lidenskapelig opptatt av å utnytte store språkmodeller for avansert dataanalyse og utforske praktiske applikasjoner som løser utfordringer i den virkelige verden. Utenom jobben liker AJ å reise, og er for tiden i 53 land med et mål om å besøke alle land i verden.
AJ Dhimine er løsningsarkitekt hos AWS. Han spesialiserer seg på generativ AI, serverløs databehandling og dataanalyse. Han er et aktivt medlem/mentor i Machine Learning Technical Field Community og har publisert flere vitenskapelige artikler om ulike AI/ML-emner. Han jobber med kunder, alt fra oppstartsbedrifter til bedrifter, for å utvikle AWSome generative AI-løsninger. Han er spesielt lidenskapelig opptatt av å utnytte store språkmodeller for avansert dataanalyse og utforske praktiske applikasjoner som løser utfordringer i den virkelige verden. Utenom jobben liker AJ å reise, og er for tiden i 53 land med et mål om å besøke alle land i verden.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://aws.amazon.com/blogs/machine-learning/advanced-rag-patterns-on-amazon-sagemaker/

