
Afbeelding door upklyak on Freepik
Ik weet zeker dat iedereen de algoritmen GBM en XGBoost kent. Het zijn go-to-algoritmen voor veel praktijksituaties en concurrentie, omdat de metrische output vaak beter is dan die van de andere modellen.
Voor degenen die GBM en XGBoost niet kennen: GBM (Gradient Boosting Machine) en XGBoost (eXtreme Gradient Boosting) zijn ensemble-leermethoden. Ensemble learning is een machine learning-techniek waarbij meerdere ‘zwakke’ modellen (vaak beslissingsbomen) worden getraind en gecombineerd voor verdere doeleinden.
Het algoritme was gebaseerd op de techniek voor het stimuleren van ensemble-leren die in hun naam wordt weergegeven. Boosting-technieken zijn een methode die probeert meerdere zwakke leerlingen achter elkaar te combineren, waarbij elke leerling zijn voorganger corrigeert. Elke leerling zou leren van zijn eerdere fouten en de fouten van de voorgaande modellen corrigeren.
Dat is de fundamentele overeenkomst tussen GBM en XGB, maar hoe zit het met de verschillen? We zullen dat in dit artikel bespreken, dus laten we erop ingaan.
Zoals hierboven vermeld, is GBM gebaseerd op boosting, waarbij de zwakke leerling opeenvolgend wordt herhaald om van de fout te leren en een robuust model te ontwikkelen. GBM ontwikkelde voor elke iteratie een beter model door de verliesfunctie te minimaliseren met behulp van gradiëntafdaling. Gradiëntdaling is een concept om bij elke iteratie de minimumfunctie te vinden, zoals de verliesfunctie. De iteratie zou doorgaan totdat het stopcriterium wordt bereikt.
Voor de GBM-concepten kunt u deze in onderstaande afbeelding zien.
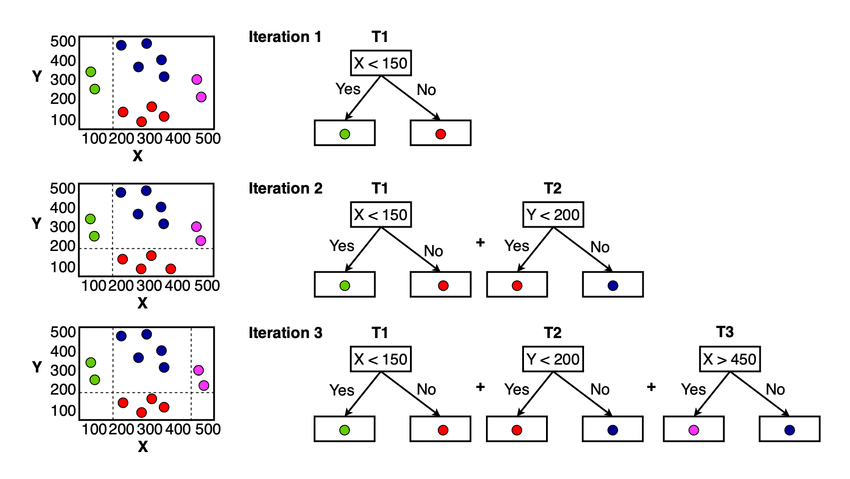
GBM-modelconcept (Chhetri et al. (2022))
Je kunt in de afbeelding hierboven zien dat het model voor elke iteratie probeert de verliesfunctie te minimaliseren en te leren van de vorige fout. Het uiteindelijke model zou de hele zwakke leerling zijn die alle voorspellingen van het model samenvat.
XGBoost of eXtreme Gradient Boosting is een machinaal leeralgoritme gebaseerd op het gradiëntversterkingsalgoritme ontwikkeld door Tiangqi Chen en Carlos Guestrin in 2016. Op een basisniveau volgt het algoritme nog steeds een sequentiële strategie om het volgende model op basis van gradiëntafdaling te verbeteren. Een paar verschillen met XGBoost zorgen er echter voor dat dit model een van de beste is op het gebied van prestaties en snelheid.
1. Regularisatie
Regularisatie is een techniek in machine learning om overfitting te voorkomen. Het is een verzameling methoden om ervoor te zorgen dat het model te ingewikkeld wordt en een slecht generalisatievermogen heeft. Het is een belangrijke techniek geworden omdat veel modellen te goed bij de trainingsgegevens passen.
GBM implementeert geen regularisatie in hun algoritme, waardoor het algoritme zich alleen richt op het bereiken van minimale verliesfuncties. Vergeleken met de GBM implementeert XGBoost de regularisatiemethoden om het overfitting-model te bestraffen.
Er zijn twee soorten regularisatie die XGBoost zou kunnen toepassen: L1-regularisatie (Lasso) en L2-regularisatie (Ridge). L1-regularisatie probeert de kenmerkgewichten of coëfficiënten tot nul te minimaliseren (in feite een kenmerkselectie te worden), terwijl L2-regularisatie probeert de coëfficiënt gelijkmatig te verkleinen (helpen bij het omgaan met multicollineariteit). Door beide regularisaties te implementeren, zou XGBoost overfitting beter kunnen voorkomen dan de GBM.
2. Parallellisatie
GBM heeft doorgaans een langzamere trainingstijd dan de XGBoost, omdat het laatste algoritme parallellisatie implementeert tijdens het trainingsproces. De boosttechniek kan sequentieel zijn, maar parallellisatie kan nog steeds worden uitgevoerd binnen het XGBoost-proces.
De parallellisatie heeft tot doel het proces van het bouwen van bomen te versnellen, voornamelijk tijdens het splitsingsevenement. Door alle beschikbare verwerkingskernen te gebruiken, kan de XGBoost-trainingstijd worden verkort.
Over het versnellen van het XGBoost-proces gesproken: de ontwikkelaar heeft de gegevens ook voorbewerkt in het door hen ontwikkelde gegevensformaat, DMatrix, voor geheugenefficiëntie en verbeterde trainingssnelheid.
3. Ontbrekende gegevensverwerking
Onze trainingsdataset kan ontbrekende gegevens bevatten, die we expliciet moeten verwerken voordat we ze in het algoritme doorgeven. XGBoost heeft echter zijn eigen ingebouwde ontbrekende gegevenshandler, terwijl GBM dat niet heeft.
XGBoost implementeerde hun techniek om ontbrekende gegevens te verwerken, genaamd Sparsity-aware Split Finding. Voor alle sparsities-gegevens die XGBoost tegenkomt (Missing Data, Dense Zero, OHE), zou het model van deze gegevens leren en de meest optimale splitsing vinden. Het model wijst aan waar de ontbrekende gegevens tijdens het splitsen moeten worden geplaatst en kijkt in welke richting het verlies tot een minimum wordt beperkt.
4. Snoeien van bomen
De groeistrategie voor de GBM is om te stoppen met splitsen nadat het algoritme tot het negatieve verlies in de splitsing is gekomen. De strategie zou tot suboptimale resultaten kunnen leiden, omdat deze alleen gebaseerd is op lokale optimalisatie en het algemene beeld zou kunnen verwaarlozen.
XGBoost probeert de GBM-strategie te vermijden en laat de boom groeien totdat de ingestelde parameter maximale diepte achteruit begint te snoeien. De splitsing met negatief verlies wordt gesnoeid, maar er is een geval waarin de splitsing met negatief verlies niet werd verwijderd. Wanneer de splitsing tot een negatief verlies leidt, maar de verdere splitsing positief is, blijft dit verlies behouden als de algehele splitsing positief is.
5. Ingebouwde kruisvalidatie
Kruisvalidatie is een techniek om ons modelgeneralisatie- en robuustheidsvermogen te beoordelen door de gegevens systematisch te splitsen gedurende verschillende iteraties. Gezamenlijk zou hun resultaat laten zien of het model overfitting is of niet.
Normaal gesproken heeft het machine-algoritme externe hulp nodig om de kruisvalidatie te implementeren, maar XGBoost heeft een ingebouwde kruisvalidatie die tijdens de trainingssessie kan worden gebruikt. De kruisvalidatie zou bij elke boost-iteratie worden uitgevoerd en ervoor zorgen dat de productboom robuust is.
GBM en XGBoost zijn populaire algoritmen in veel praktijkgevallen en wedstrijden. Conceptueel gezien stimuleren beide algoritmen die zwakke leerlingen gebruiken om betere modellen te bereiken. Ze bevatten echter weinig verschillen in de implementatie van hun algoritmen. XGBoost verbetert het algoritme door regularisatie in te bedden, parallellisatie uit te voeren, beter ontbrekende gegevensverwerking, verschillende boomsnoeistrategieën en ingebouwde kruisvalidatietechnieken.
Cornellius Yudha Wijaya is een data science assistent-manager en dataschrijver. Terwijl hij fulltime bij Allianz Indonesia werkt, deelt hij graag Python- en Data-tips via sociale media en schrijvende media.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.kdnuggets.com/wtf-is-the-difference-between-gbm-and-xgboost?utm_source=rss&utm_medium=rss&utm_campaign=wtf-is-the-difference-between-gbm-and-xgboost

