
Afbeelding van Canva
De snelheid waarmee de gegevens de afgelopen jaren zijn gemaakt, is exponentieel geweest, wat in de eerste plaats duidt op de toegenomen verspreiding van de digitale wereld.
Dat wordt geschat? 90% van de gegevens in de wereld alleen al in de afgelopen twee jaar is gegenereerd.
Hoe meer we omgaan met internet in verschillende vormen? - van het verzenden van sms-berichten, het delen van video's of het maken van muziek?, we dragen bij aan de pool van trainingsgegevens die GenAI-technologieën (Generative AI) mogelijk maakt.
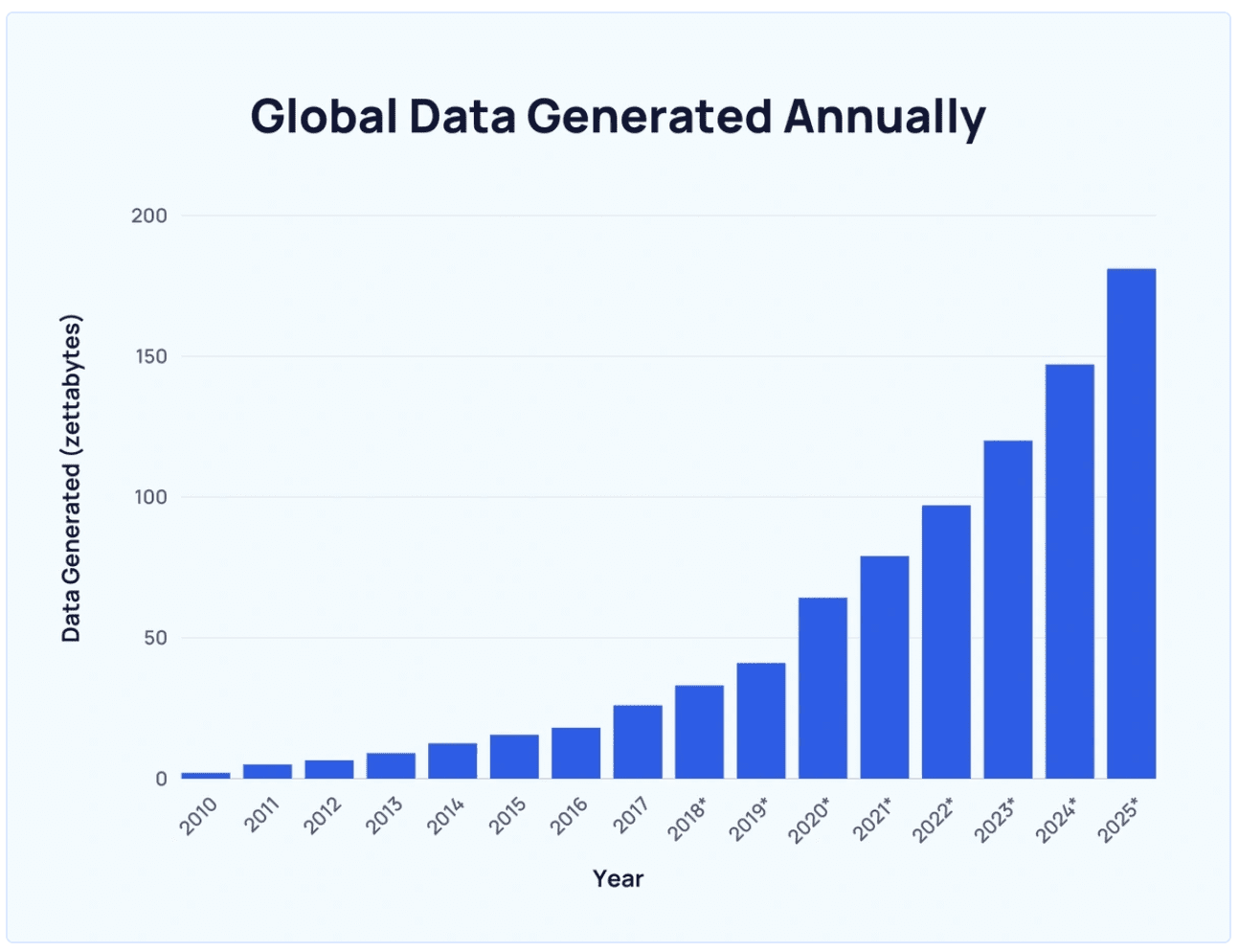
Wereldwijde gegevens die jaarlijks worden gegenereerd uit explosieonderwerpen.com
In principe gaan onze data als input naar deze geavanceerde AI-algoritmen die leren en nieuwere data genereren.
Onnodig te zeggen dat het in eerste instantie intrigerend klinkt, maar het begint in verschillende vormen risico's te vormen naarmate de realiteit begint door te dringen.
De andere kant van deze technologische ontwikkelingen opent al snel de doos met problemen van pandora? in de vorm van desinformatie, misbruik, informatierisico's, deep fakes, koolstofemissies en nog veel meer.
Verder is het van cruciaal belang om op te merken welke impact deze modellen hebben op het overbodig maken van veel banen.
Volgens Mckinsey's recente rapport "Generatieve AI en de toekomst van werk in Amerika”?—? Banen die veel repetitieve taken, gegevensverzameling en elementaire gegevensverwerking met zich meebrengen, lopen een verhoogd risico om verouderd te raken.
Het rapport noemt automatisering, waaronder GenAI, als een van de redenen voor de afname van het aantal gebruikers vraag naar elementaire cognitieve en handmatige vaardigheden.
Bovendien is gegevensprivacy een essentiële zorg die voortduurt uit het pre-GenAI-tijdperk en die voor uitdagingen blijft zorgen. De gegevens, die de kern vormen van GenAI-modellen, worden samengesteld via internet, dat een klein deel van onze identiteit omvat.

Afbeelding van The Conversation
Van een van die LLM wordt beweerd dat hij op sommigen is getraind 300 miljard woorden met gegevens die van internet zijn geschraapt, waaronder boeken, artikelen, websites en berichten. Wat zorgwekkend is, is dat we al die tijd niet op de hoogte waren van de verzameling, het verbruik en het gebruik ervan.
MIT Technology Review vindt het "bijna onmogelijk voor OpenAI om te voldoen aan de regels voor gegevensbescherming".
Aangezien we allemaal fractionele bijdragers zijn aan deze gegevens, is er de verwachting dat we het algoritme open source maken en het voor iedereen begrijpelijk maken.
Terwijl modellen met open toegang details geven over code, trainingsgegevens, modelgewichten, architectuur en evaluatieresultaten - eigenlijk alles onder de motorkap dat u moet weten.

Afbeelding van Canva
Maar zouden de meesten van ons het kunnen begrijpen? Waarschijnlijk niet!
Dit geeft aanleiding tot de noodzaak om deze essentiële details te delen in het juiste forum - een commissie van experts, waaronder beleidsmakers, praktijkmensen en de overheid.
Deze commissie zal kunnen beslissen wat het beste is voor de mensheid - iets dat geen enkele individuele groep, regering of organisatie vandaag alleen kan beslissen.
Het moet de impact op de samenleving als een hoge prioriteit beschouwen en het effect van GenAI evalueren vanuit verschillende lenzen - sociaal, economisch, politiek en daarbuiten.
Afgezien van de gegevenscomponent doen de ontwikkelaars van dergelijke kolossale modellen enorme investeringen om rekenkracht te leveren om deze modellen te bouwen, waardoor het hun voorrecht is om ze gesloten toegang te houden.
De aard van het doen van investeringen houdt in dat ze een rendement op dergelijke investeringen willen hebben door ze voor commercieel gebruik te gebruiken. Daar begint de verwarring.
Het hebben van een bestuursorgaan dat de ontwikkeling en release van AI-aangedreven applicaties kan reguleren, staat innovatie niet in de weg en belemmert de bedrijfsgroei niet.
In plaats daarvan is het primaire doel om vangrails en beleid te bouwen die bedrijfsgroei door middel van technologie mogelijk maken en tegelijkertijd een meer verantwoorde aanpak bevorderen.
Dus, wie bepaalt het verantwoordelijke quotiënt, en hoe komt dat bestuursorgaan tot stand?
Behoefte aan een verantwoordelijk forum
Er moet een onafhankelijke entiteit zijn bestaande uit experts uit onderzoek, de academische wereld, bedrijven, beleidsmakers en regeringen/landen. Ter verduidelijking: onafhankelijk betekent dat haar fondsen niet mogen worden gesponsord door een speler die een belangenconflict kan veroorzaken.
Haar enige agenda is om te denken, te rationaliseren en te handelen namens 8 miljard mensen in deze wereld en het juiste oordeel te vellen, waarbij hoge verantwoordingsnormen worden gehanteerd voor haar beslissingen.
Dat is een grote uitspraak, wat betekent dat de groep lasergericht moet zijn en de aan hen toevertrouwde taak moet behandelen als ondergeschikt aan geen enkele. Wij, de wereld, kunnen het ons niet veroorloven om de besluitvormers aan zo'n kritieke missie te laten werken als een good-to-have of nevenproject, wat ook betekent dat ze ook goed moeten worden gefinancierd.
De groep heeft de taak om een plan en een strategie uit te voeren die de nadelen kunnen aanpakken zonder concessies te doen aan het realiseren van de voordelen van de technologie.
We hebben het eerder gedaan
AI wordt vaak vergeleken met nucleaire technologie. De baanbrekende ontwikkelingen hebben het gehaald moeilijk om de risico's te voorspellen die erbij horen.
Ik citeer Rumman uit Bedraad over hoe de Internationale Organisatie voor Atoomenergie (IAEA)?—?er werd een onafhankelijk orgaan opgericht dat vrij was van regeringen en bedrijven, om oplossingen te bieden voor de verreikende vertakkingen en schijnbaar oneindige mogelijkheden van nucleaire technologieën.
We hebben dus voorbeelden van wereldwijde samenwerking in het verleden waar de wereld samenkwam om orde op zaken te stellen. Ik weet zeker dat we er ooit zullen komen. Maar het is van cruciaal belang om eerder samen te komen en de vangrails te vormen om het snel evoluerende tempo van implementaties bij te houden.
De mensheid kan het zich niet veroorloven om zich te laten leiden door vrijwillige maatregelen van bedrijven, die een verantwoorde ontwikkeling en inzet door technologiebedrijven wensen.
Vidhi Chugh is een AI-strateeg en leider op het gebied van digitale transformatie en werkt op het snijvlak van product, wetenschap en engineering om schaalbare machine learning-systemen te bouwen. Ze is een bekroonde innovatieleider, een auteur en een internationale spreker. Ze is op een missie om machine learning te democratiseren en het jargon te doorbreken zodat iedereen deel kan uitmaken van deze transformatie.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. Automotive / EV's, carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- ChartPrime. Verhoog uw handelsspel met ChartPrime. Toegang hier.
- BlockOffsets. Eigendom voor milieucompensatie moderniseren. Toegang hier.
- Bron: https://www.kdnuggets.com/2023/08/whose-responsibility-get-generative-ai-right.html?utm_source=rss&utm_medium=rss&utm_campaign=whose-responsibility-is-it-to-get-generative-ai-right

