Nauwkeurigheid en AUC (Area Under the Curve) zijn maatstaven om de goedheid van modelprestaties te evalueren. Beide zijn nuttig om de modelprestaties te meten, afhankelijk van het type zakelijk probleem dat u probeert op te lossen. Dus welke moet je gebruiken en wanneer? Nou, het korte antwoord is - het hangt ervan af!
In dit bericht zullen we eerst beide statistieken beschrijven en vervolgens elk van de statistieken in detail leren en begrijpen wanneer ze moeten worden gebruikt.
Nauwkeurigheid is de meest populaire statistiek die het percentage correcte voorspellingen van het model bepaalt.
Het wordt berekend als een verhouding van het aantal ware voorspellingen met dat van het totale aantal monsters in de dataset. De resulterende hoeveelheid wordt gemeten in procenten. Als het model bijvoorbeeld 90% van de items in uw dataset correct heeft voorspeld, heeft het een nauwkeurigheid van 90%.
Wiskundig wordt het geschreven als:
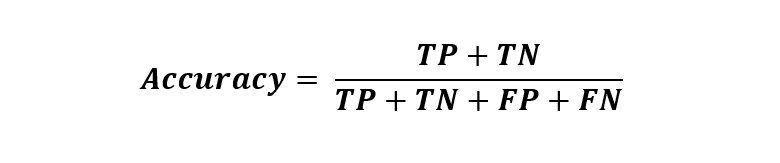
De vier componenten in de formule zijn gebaseerd op de hieronder gedefinieerde werkelijke waarden en bijbehorende modelvoorspellingen:
- True Positive (TP) – aantal keren dat het model een positieve klasse correct identificeert.
- True Negative (TN) – aantal gevallen waarin het model een negatieve klasse correct identificeert.
- False Positive (FP) – het aantal keren dat het model ten onrechte een negatieve klasse identificeert.
- False Negative (FN) – aantal gevallen waarin het model ten onrechte een positieve klasse identificeert.
Deze statistieken worden afgeleid door een geschikte grens toe te passen op de voorspelde waarschijnlijkheidsscore van het model. Hierin wordt een gedetailleerde uitleg gegeven van elk van de termen en hun relatie met de verwarringsmatrix dit artikel.
AUC staat voor "Area Under the Curve" in het algemeen en "Area under the Receiver Operating Characteristic Curve" in lange vorm. Het legt het gebied onder de ROC-curve (Receiver Operating Characteristic) vast en vergelijkt de relatie tussen de True Positive Rate (TPR) met die van de False Positive Rate (FPR) over verschillende afkapdrempels.
Maar laten we, voordat we diep in AUC duiken, eerst begrijpen wat deze nieuwe termen betekenen.
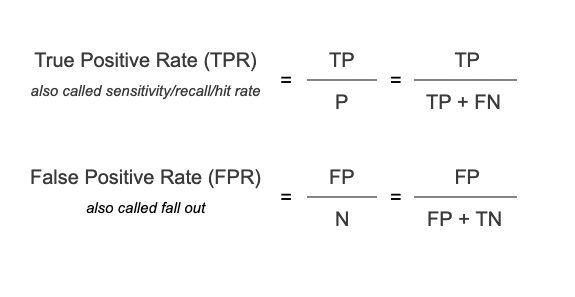
TPR of True Positive Rate
Het is de verhouding van correct voorspelde positieve gevallen van alle positieve monsters. Als het model bijvoorbeeld de taak heeft om de frauduleuze transacties te identificeren, wordt TPR gedefinieerd als het aandeel van correct voorspelde frauduleuze transacties onder alle frauduleuze transacties.
FPR of fout-positief percentage
Het is het percentage onjuist voorspelde negatieve gevallen. Voortbordurend op het model voor fraudedetectie, wordt de FPR gedefinieerd als het aandeel van foutief voorspelde frauduleuze waarschuwingen van alle legitieme transacties.
Wiskundig worden TPR en FPR uitgedrukt als:
Nu we TPR en FPR per definitie begrijpen, gaan we kijken hoe ze zich verhouden tot de AUC-metriek.
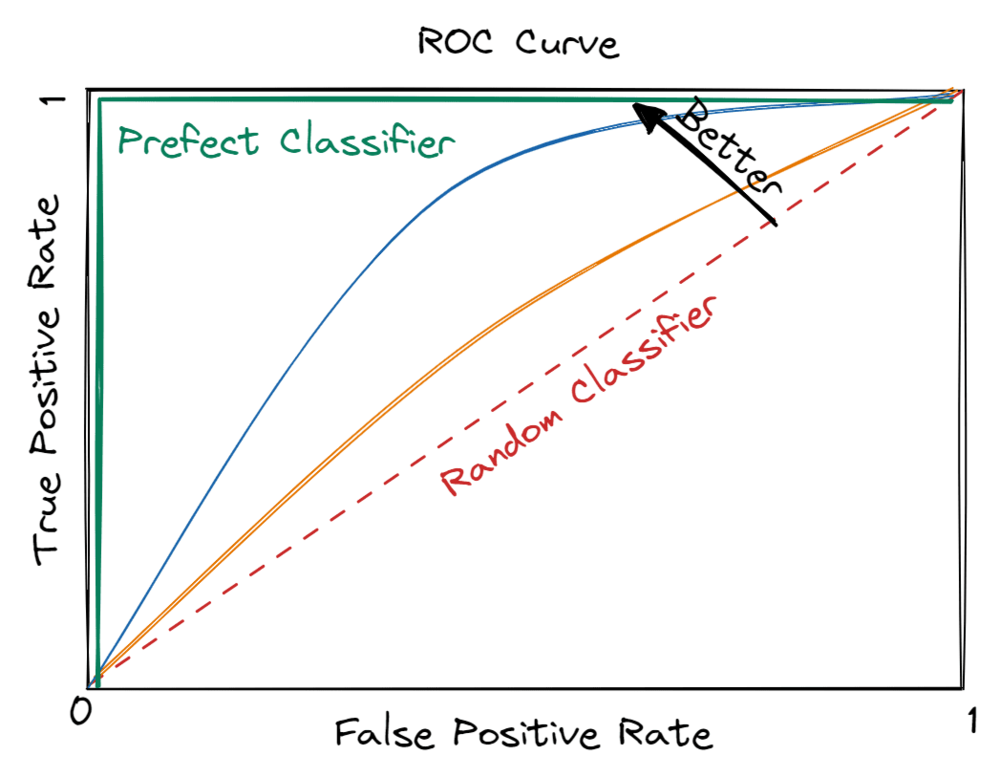
Afbeelding door redacteur
Zoals blijkt uit de afbeelding hierboven, is de linkerbovenhoek, dwz hoge TP's en lage FP's, de gewenste toestand. De paarse kleurcurve vormt dus een perfecte classificator met een AUC van 1, dwz het vierkante gebied onder deze curve is 1.
Maar het construeren van zo'n ideale classificator is praktisch niet haalbaar in real-world toepassingen. Daarom is het belangrijk om de ondergrens van een classificator te begrijpen die wordt aangegeven door een diagonale rode lijn. Het is geannoteerd als een willekeurige classificator en heeft een AUC van 0.5, dwz de oppervlakte van een driehoek onder de rode stippellijn. Het wordt een willekeurige classificatie genoemd omdat de voorspellingen zo goed zijn als het willekeurig opgooien van een munt.
Samengevat, de prestaties van een machine learning-model liggen tussen een willekeurige classificator en de perfecte classificator, wat aangeeft dat de verwachte AUC wordt begrensd tussen 0.5 (willekeurige toestand) en 1 (perfecte toestand).
In wezen streven datawetenschappers naar het maximaliseren van de AUC, dwz een groter gebied onder de curve. Het duidt op de goedheid van het model in het genereren van correcte voorspellingen oftewel het streven naar de hoogste TPR met behoud van de laagst mogelijke FPR.
Nauwkeurigheid wordt gebruikt voor gebalanceerde datasets, dwz wanneer de klassen gelijk verdeeld zijn.
Een praktijkvoorbeeld is fraudedetectie die frauduleuze transacties (klasse van belang) correct moet identificeren en onderscheiden van reguliere transacties. Gewoonlijk zijn frauduleuze transacties zeldzaam, dwz dat ze in de trainingsdataset minder dan ~1% voorkomen.
Nauwkeurigheid zou in dit geval een bevooroordeelde weergave zijn van de modelprestaties en zou het model goed verklaren, zelfs als het elke transactie als niet-frauduleus identificeert. Een dergelijk model zou een hoge nauwkeurigheid hebben, maar kan geen frauduleuze transactie voorspellen, waardoor het doel van het bouwen van het model teniet wordt gedaan.
AUC is zeer geschikt voor onevenwichtige datasets. Het fraudedetectiemodel moet bijvoorbeeld fraude correct identificeren, zelfs als dit ten koste gaat van het markeren van (een klein aantal) van de niet-frauduleuze transacties als frauduleus.
Het is zeer waarschijnlijk dat het model, terwijl het zich richt op het correct identificeren van de interesseklasse (frauduleuze transacties), dwz de TP's, enkele fouten maakt, dwz FP's (het markeren van niet-frauduleuze transacties als frauduleus). Het is dus belangrijk om te kijken naar een maatstaf die TPR en FPR vergelijkt. Dit is waar AUC in past.
Nauwkeurigheid en AUC worden beide gebruikt voor classificatiemodellen. Er zijn echter een paar dingen waarmee u rekening moet houden wanneer u beslist welke u wilt gebruiken.
Een model met hoge nauwkeurigheid geeft zeer weinig onjuiste voorspellingen aan. Hierbij wordt echter geen rekening gehouden met de zakelijke kosten van die onjuiste voorspellingen. Het gebruik van nauwkeurigheidsstatistieken bij dergelijke zakelijke problemen abstraheert de details zoals TP en FP, en geeft een opgeblazen gevoel van vertrouwen in modelvoorspellingen dat schadelijk is voor zakelijke doelstellingen.
AUC is de go-to-statistiek in dergelijke scenario's, omdat het de wisselwerking tussen gevoeligheid en specificiteit kalibreert bij de best gekozen drempel.
Verder meet nauwkeurigheid hoe goed een enkel model het doet, terwijl AUC twee modellen vergelijkt en de prestaties van hetzelfde model over verschillende drempels evalueert.
Het kiezen van de juiste statistiek voor uw model is van cruciaal belang voor het verkrijgen van de gewenste resultaten. Nauwkeurigheid en AUC zijn twee populaire evaluatiestatistieken om de prestaties van het model objectief te meten. Ze zijn beide nuttig om te beoordelen hoe goed een model het doet en om het ene model met het andere te vergelijken. De post legde uit waarom nauwkeurigheid een voldoende maatstaf is voor gebalanceerde gegevens, maar AUC is zeer geschikt om de prestaties van het model op een ongebalanceerde set te meten.
Vidhi Chugh is een bekroonde AI/ML-innovatieleider en een AI-ethicus. Ze werkt op het snijvlak van datawetenschap, product en onderzoek om zakelijke waarde en inzichten te leveren. Ze is een pleitbezorger voor datacentrische wetenschap en een vooraanstaand expert in datagovernance met een visie om betrouwbare AI-oplossingen te bouwen.

