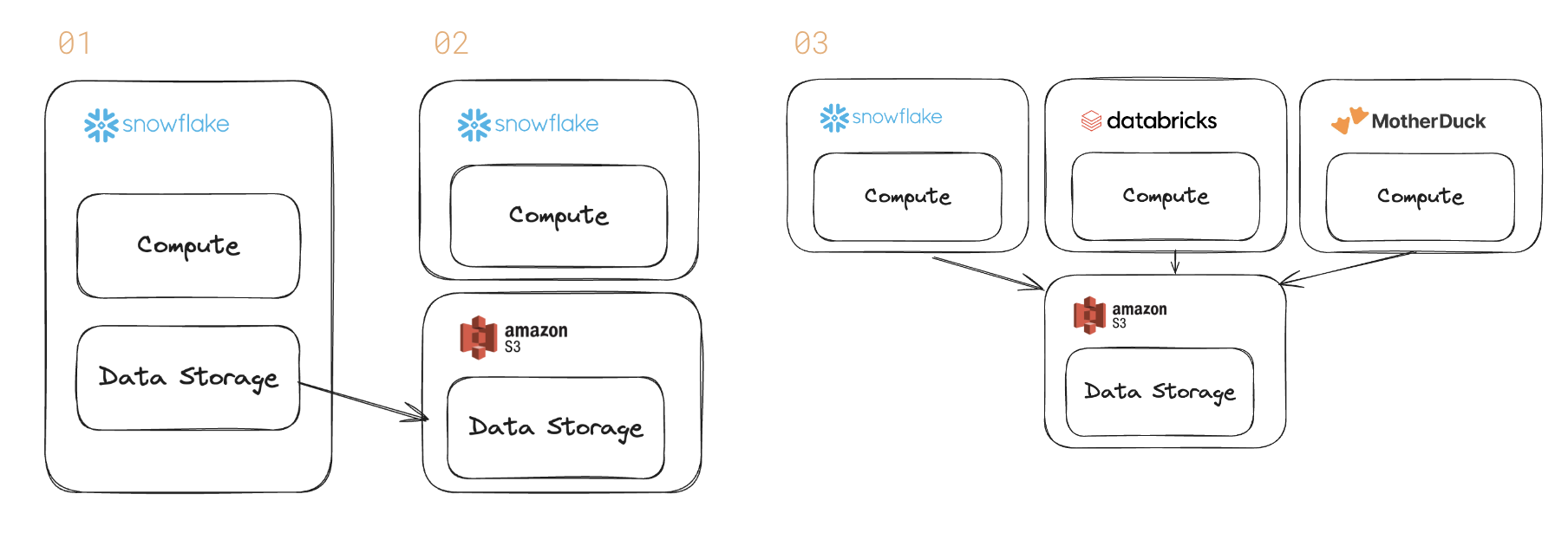
De database wordt ontbundeld. Historisch gezien verkocht een database als Snowflake zowel gegevensopslag als een query-engine (en de rekenkracht om de query uit te voeren). Dat is stap 1 hierboven.
Maar klanten dringen aan op een diepere scheiding tussen rekenkracht en opslag. De recente winstoproep van Snowflake benadrukte deze trend. Grotere klanten geven de voorkeur aan open formaten vanwege interoperabiliteit (stap 2 en 3).
Veel grote klanten willen open bestandsformaten hebben om hen de opties te geven... Data-interoperabiliteit is dus heel belangrijk en onze AI-producten kunnen over het algemeen ook reageren op gegevens die zich in de cloudopslag bevinden.
We verwachten dat een aantal van onze grote klanten Iceberg-formaten zullen gaan gebruiken en hun gegevens uit Snowflake zullen verplaatsen, waarbij we die opslaginkomsten verliezen en ook de rekeninkomsten die gepaard gaan met het verplaatsen van die gegevens naar Snowflake.
In plaats van de gegevens in één database op te sluiten, geven klanten er de voorkeur aan om deze in open formaten zoals Apache Arrow, Apache Parquet en Apache Iceberg te hebben.
Naarmate het datagebruik binnen een onderneming is toegenomen, neemt ook de diversiteit aan eisen aan die data toe.
In plaats van het elke keer te kopiëren voor een ander doel, of het nu gaat om verkennende analyses, business intelligence of AI-workloads, waarom zouden we de gegevens dan niet centraliseren en er vervolgens veel verschillende systemen toegang toe geven?
Dit bespaart geld: de opslag bedraagt voor Snowflake in totaal zo'n 280 tot 300 miljoen dollar.
Ter herinnering: ongeveer 10% tot 11% van onze totale inkomsten houdt verband met opslag.
Maar het vereenvoudigt ook architecturen.
Het luidt ook een tijdperk in waarin de query-engines zullen concurreren om verschillende werklasten op basis van prijs en prestaties. Snowflake is misschien beter voor grootschalige BI; Databricks' Spark voor AI-datapijplijnen; Moeder Eend voor interactieve analyses.
Leveranciers van datawarehouses hebben de scheiding van opslag en computergebruik in het verleden. Maar die boodschap ging over het schalen van het systeem om grotere gegevens binnen hun eigen product te verwerken.
Klanten eisen een diepere scheiding – een wereld waarin databases geen kosten in rekening brengen voor opslag.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.tomtunguz.com/why-databases-wont-charge-storage/

