Apache-bijenkorf is een op SQL gebaseerd datawarehouse-systeem voor het verwerken van zeer gedistribueerde datasets op het Apache Hadoop-platform. Er zijn twee belangrijke onderdelen van Apache Hive: de Hive SQL-query-engine en de Hive-metastore (HMS). De Hive-metastore is een opslagplaats van metadata over de SQL-tabellen, zoals databasenamen, tabelnamen, schema, serialisatie- en deserialisatie-informatie, gegevenslocatie en partitiedetails van elke tabel. Apache Hive, Apache Spark, Presto en Trino kunnen allemaal een Hive Metastore gebruiken om metadata op te halen om query's uit te voeren. De Hive-metastore kan worden gehost op een Apache Hadoop-cluster of kan worden ondersteund door een relationele database die extern is aan een Hadoop-cluster. Hoewel de Hive-metastore de metadata van tabellen opslaat, kunnen de daadwerkelijke gegevens van de tabel zich bevinden Amazon eenvoudige opslagservice (Amazon S3), het Hadoop Distributed File System (HDFS) van het Hadoop-cluster of andere door Hive ondersteunde datastores.
Omdat Apache Hive bovenop Apache Hadoop is gebouwd, gebruiken veel organisaties de software vanaf het moment dat ze Hadoop gebruikten voor big data-verwerking. Hive metastore biedt ook flexibele integratie met vele andere open-source big data-software zoals Apache HBase, Apache Spark, Presto en Apache Impala. Daarom zijn organisaties ertoe gekomen om enorme hoeveelheden metadata van hun gestructureerde datasets in de Hive-metastore te hosten. Een metastore is een cruciaal onderdeel van een datameer en het is belangrijk om deze informatie beschikbaar te hebben, waar deze zich ook bevindt. Veel AWS-analyseservices integreren echter niet standaard met de Hive-metastore en daarom moesten organisaties hun gegevens naar de Hive-metastore migreren. AWS lijm Data Catalog om deze services te gebruiken.
AWS Lake-formatie heeft ondersteuning gelanceerd voor gebruikerstoegang tot Apache Hive-metastores beheren via een gefedereerde AWS Glue-verbinding. Voorheen kon u Lake Formation gebruiken om gebruikersrechten op te beheren AWS-lijmgegevenscatalogus alleen middelen. Met de Hive-metastore-verbinding van AWS Glue kunt u verbinding maken met een database in een Hive-metastore buiten de Data Catalog, deze toewijzen aan een gefedereerde database in de Data Catalog, Lake Formation-machtigingen toepassen op de Hive-database en tabellen, ze delen met andere AWS-accounts en vraag ze op met behulp van services zoals Amazone Athene, Amazon Roodverschuivingsspectrum, Amazon EMR, en AWS Glue ETL (extraheren, transformeren en laden). Raadpleeg voor meer informatie over hoe de Hive-metastore-integratie met Lake Formation werkt Machtigingen beheren voor datasets die externe metastores gebruiken.
Use cases voor Hive-metastore-integratie met de Data Catalog omvatten het volgende:
- Een externe Apache Hive-metastore die wordt gebruikt voor oudere big data-workloads, zoals on-premises Hadoop-clusters met gegevens in Amazon S3
- Tijdelijke Amazon EMR-workloads met onderliggende data in Amazon S3 en de Hive-metastore aan Amazon relationele databaseservice (Amazon RDS)-clusters.
In dit bericht laten we zien hoe u Lake Formation-machtigingen toepast op een Hive-metastore-database en -tabellen en deze opvraagt met Athena. We illustreren een use-case voor het delen van meerdere accounts, waarbij een Lake Formation-steward in producentenaccount A een gefedereerde Hive-database en tabellen deelt met behulp van LF-Tags naar consumentenaccount B.
Overzicht oplossingen
Produceraccount A host een Apache Hive-metastore in een EMR-cluster, met onderliggende gegevens in Amazon S3. We lanceren de AWS Glue Hive metastore-connector vanaf AWS serverloze toepassingsrepository in account A en maak de Hive-metastore-verbinding in de gegevenscatalogus van account A. Nadat we de HMS-verbinding tot stand hebben gebracht, maken we een database in de gegevenscatalogus van account A (de gefedereerde database genoemd) en wijzen deze toe aan een database in de Hive-metastore met behulp van de verbinding. De tabellen uit de Hive-database zijn vervolgens toegankelijk voor de Lake Formation-beheerder in account A, net als alle andere tabellen in de Data Catalog. De beheerder gaat door met het instellen van Lake Formation op tags gebaseerde toegangscontrole (LF-TBAC) op de gefedereerde Hive-database en deelt deze met account B.
De data lake-gebruikers in account B hebben toegang tot de Hive-database en tabellen van account A, net zoals het opvragen van elke andere gedeelde Data Catalog-resource met behulp van Lake Formation-machtigingen.
Het volgende diagram illustreert deze architectuur.

De oplossing bestaat uit stappen in beide accounts. Voer in rekening A de volgende stappen uit:
- Maak een S3-bucket om de voorbeeldgegevens te hosten.
- Start een EMR 6.10-cluster met Hive. Download de voorbeeldgegevens naar de S3-bucket. Maak een database en externe tabellen, verwijzend naar de gedownloade voorbeeldgegevens, in de Hive-metastore.
- Implementeer de applicatie GlueDataCatalogFederation-HiveMetastore van AWS Serverless Application Repository en configureer het om de Amazon EMR Hive-metastore te gebruiken. Hiermee wordt een AWS Glue-verbinding gemaakt met de Hive-metastore die wordt weergegeven op de Lake Formation-console.
- Maak met behulp van de Hive-metastore-verbinding een gefedereerde database in de AWS Glue Data Catalog.
- Maak LF-Tags en koppel ze aan de gefedereerde database.
- Verleen machtigingen voor de LF-Tags aan account B. Verleen database- en tabelmachtigingen aan account B met behulp van LF-Tag-expressies.
Voer in account B de volgende stappen uit:
- Bekijk en accepteer als data lake-beheerder het AWS Resource Access Manager (AWS RAM) nodigt uit voor de aandelen van account A.
- De data lake-beheerder ziet vervolgens de gedeelde database en tabellen. De beheerder maakt een bronkoppeling naar de database en verleent gedetailleerde machtigingen aan een gegevensanalist in dit account.
- Zowel de data lake-beheerder als de data-analist bevragen de Hive-tabellen die voor hen beschikbaar zijn met behulp van Athena.
Account A heeft de volgende persona's:
- hmsblog-producersteward – Beheert het datameer in het producentenaccount A
Account B heeft de volgende persona's:
- hmsblog-consumersteward – Beheert het datameer in het consumentenaccount B
- hmsblog-analist – Een data-analist die toegang nodig heeft tot geselecteerde Hive-tabellen
Voorwaarden
Om de tutorial in dit bericht te volgen, heb je het volgende nodig:
Lake Formation en AWS CloudFormation instellen in account A
Om de installatie eenvoudig te houden, hebben we een IAM-beheerder geregistreerd als data lake-beheerder. Voer de volgende stappen uit:
- Log in bij de AWS-beheerconsole En kies de
us-west-2Regio. - Op de Lake Formation-console, onder machtigingen in het navigatievenster, kies Administratieve rollen en taken.
- Kies Beheren beheerders in de Data Lake-beheerders pagina.
- Onder IAM-gebruikers en -rollen, kies de IAM admin-gebruiker waarmee u bent aangemeld en kies Bespaar.
- Kies Start Stack om de CloudFormation-sjabloon te implementeren:

- Kies Volgende.
- Geef een naam op voor de stapel en kies Volgende.
- Kies op de volgende pagina Volgende.
- Bekijk de details op de laatste pagina en selecteer Ik erken dat AWS CloudFormation IAM-bronnen kan creëren.
- Kies creëren.
Het maken van een stapel duurt ongeveer 10 minuten. De stapel stelt de producentenaccount A als volgt in:
- Maakt een S3 data lake-bucket
- Registreert de data lake-bucket bij Lake Formation met de Catalogusfederatie inschakelen vlag
- Lanceert een EMR 6.10-cluster met Hive en voert twee stappen uit in Amazon EMR:
- Downloadt de voorbeeldgegevens van de openbare S3-bucket naar de nieuw gemaakte bucket
- Creëert een Hive-database en vier externe tabellen voor de gegevens in Amazon S3, met behulp van een HQL-script
- Maakt een IAM-gebruiker aan (
hmsblog-producersteward) en stelt deze gebruiker in als Lake Formation-beheerder - Maakt LF-Tags (
LFHiveBlogCampaignRole=Admin,Analyst)
Bekijk CloudFormation-stackuitvoer in account A
Voer de volgende stappen uit om de uitvoer van uw CloudFormation-stack te bekijken:
- Log in op de console als de IAM-beheerder die u eerder gebruikte om de CloudFormation-sjabloon uit te voeren.
- Open de CloudFormation-console in een ander browsertabblad.
- Bekijk en noteer de stapel Uitgangen tabblad gegevens.

- Kies de onderstaande link Waarde For
ProducerStewardCredentials.
Dit opent de AWS-geheimenmanager console.
- Kies Waarde ophalen en noteer de geloofsbrieven van
hmsblog-producersteward.

Stel een gefedereerde AWS Glue-verbinding in account A in
Voer de volgende stappen uit om een gefedereerde AWS Glue-verbinding in te stellen:
- Open de AWS Serverless Application Repository-console in een ander browsertabblad.
- Kies in het navigatievenster Beschikbare applicaties.
- kies Apps weergeven die aangepaste IAM-rollen of resourcebeleid maken.
- Typ Glue in de zoekbalk.
Dit zal verschillende applicaties opsommen.
- Kies de applicatie met de naam
GlueDataCatalogFederation-HiveMetastore.
Dit opent de AWS Lambda consoleconfiguratiepagina voor een Lambda-functie die de connectortoepassingscode uitvoert.

Om de Lambda-functie te configureren, hebt u details nodig van het EMR-cluster dat is gelanceerd door de CloudFormation-stack.
- Open op een ander tabblad van uw browser de Amazon EMR-console.
- Navigeer naar het cluster dat voor dit bericht is gelanceerd en noteer de volgende details van de pagina met clusterdetails:
- Openbare DNS van primair knooppunt
- Subnet-ID
- Beveiligingsgroep-ID van het primaire knooppunt


- Terug op de Lambda-configuratiepagina, onder Controleren, configureren en implementeren, in de Applicatie-instellingen sectie, geeft u de volgende details op. Laat de rest als de standaardwaarden.
- Voor GlueConnectionNaam, ga naar binnen
hive-metastore-connection. - Voor HiveMetastoreURI's invoeren
thrift://<Primary-node-public-DNS-of your-EMR>:9083. For example, thrift://ec2-54-70-203-146.us-west-2.compute.amazonaws.com:9083, Waar9083is de Hive-metastore-poort in het EMR-cluster. - Voor VPCSecurityGroupIds, voert u de beveiligingsgroep-ID van het primaire EMR-knooppunt in.
- Voor VPCSubnetIds, voer de subnet-ID van het EMR-cluster in.
- Voor GlueConnectionNaam, ga naar binnen
- Kies Implementeren.

Wacht op de Aanmaken Voltooid status van de Lambda-applicatie. U kunt de details van de Lambda-applicatie bekijken op de Lambda-console.

- Open de Lake Formation-console en kies in het navigatievenster Het delen van gegevens.
Je zou moeten zien hive-metastore-connection voor aansluitingen.

- Kies het en bekijk de details.

- In het navigatievenster, onder Administratieve rollen en taken, kiezen LF-tags.
U zou de gemaakte LF-tag moeten zien LFHiveBlogCampaignRole met twee waarden: Analyst en Admin.

- Kies LF-Tag-machtigingen En kies Grant.
- Kies IAM-gebruikers en -rollen en ga naar binnen
hmsblog-producersteward. - Onder LF-tags, kiezen LF-tag toevoegen.
- Enter
LFHiveBlogCampaignRoleFor sleutel en ga naar binnenAnalystenAdminFor Values. - Onder machtigingenselecteer Beschrijven en Associëren For LF-Tag-machtigingen en Verleenbare machtigingen.
- Kies Grant.
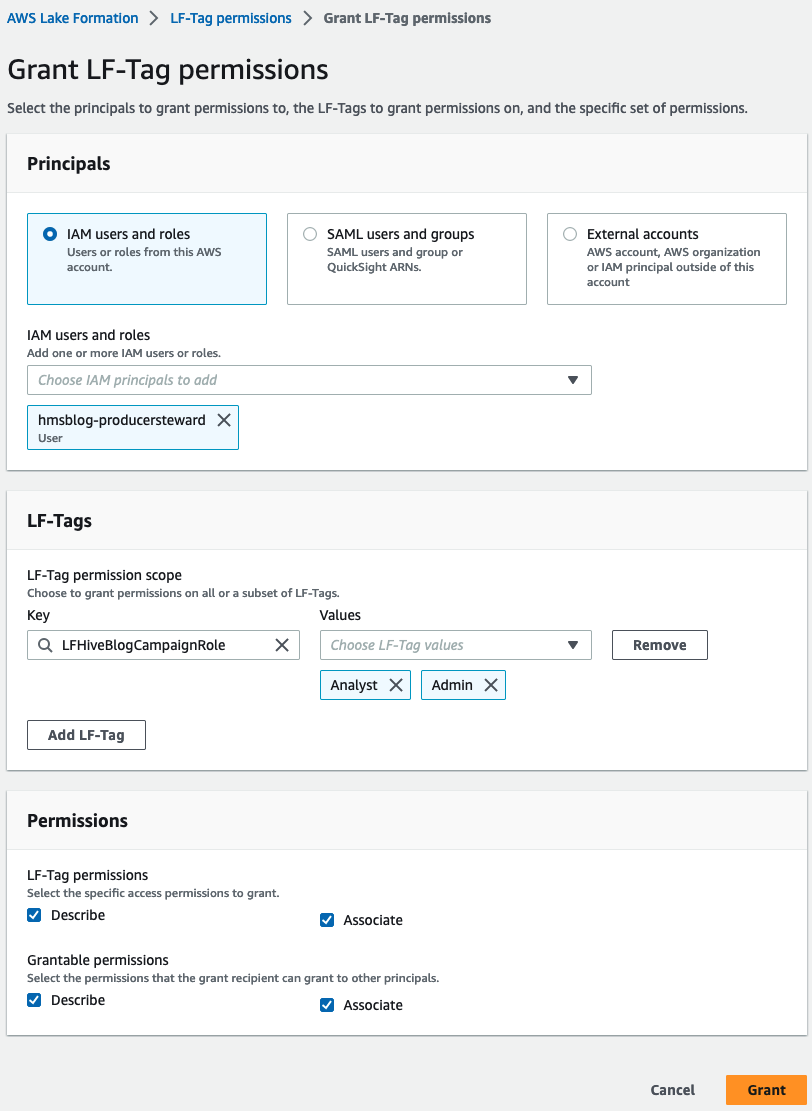
Dit geeft LF-Tags machtigingen voor de producer steward.
- Meld u af als de IAM-beheerder.
Geef toestemming aan Lake Formation als producer steward
Voer de volgende stappen uit:
- Meld u aan bij de console als
hmsblog-producersteward, met behulp van de inloggegevens van de CloudFormation-stack uitgang tabblad dat u eerder hebt genoteerd. - Kies op de Lake Formation-console in het navigatiedeelvenster Administratieve rollen en taken.
- Onder Database-makers, kiezen Grant.

- Toevoegen
hmsblog-producerstewardals databasemaker.
- Kies in het navigatievenster Het delen van gegevens.
- Onder aansluitingen, kies de
hive-metastore-connectionhyperlink.
- Op de Verbindingsdetails pagina, kies Maak een database.
- Voor Database naam, ga naar binnen
federated_emrhivedb.
Dit is de gefedereerde database in de lokale AWS Glue Data Catalog die verwijst naar een Hive-metastore-database. Dit is een één-op-één toewijzing van een database in de gegevenscatalogus aan een database in de externe Hive-metastore.
- Voor Database-ID, voert u de naam van de database in de EMR Hive-metastore in die is gemaakt met het Hive SQL-script. Voor deze post gebruiken we
emrhms_salesdb.
- Eenmaal gemaakt, selecteert u
federated_emrhivedbEn kies Tabellen bekijken.
Hiermee worden de database- en tabelmetadata opgehaald uit de Hive-metastore op het EMR-cluster en worden de tabellen weergegeven die zijn gemaakt door het Hive-script.

Nu koppelt u de LF-Tags die zijn gemaakt door het CloudFormation-script aan deze gefedereerde database en deelt u deze met het consumentenaccount B met behulp van LF-Tag-expressies.
- Kies in het navigatievenster databases.
- kies
federated_emrhivedben in de Acties menu, kies Bewerk LF-tags. - Kies Nieuwe LF-Tag toewijzen.
- Enter
LFHiveBlogCampaignRoleFor Toegewezen toetsen enAdminFor Values, kies dan Bespaar.
- Kies in het navigatievenster Data lake-machtigingen.
- Kies Grant.
- kies Externe accounts en vul het B-nummer van de consumentenrekening in.
- Onder LF-tags of catalogusbronnen, kiezen Bron gematcht door LF-Tags.
- Kies LF-tag toevoegen.
- Enter
LFHiveBlogCampaignRoleFor sleutel enAdminFor Values.
- In het Databasemachtigingen sectie, selecteer Beschrijven For Databasemachtigingen en Verleenbare machtigingen.
- In het Tabelrechten sectie, selecteer Selecteer en beschrijf For Tabelrechten en Verleenbare machtigingen.
- Kies Grant.

- In het navigatievenster, onder Administratieve rollen en taken, kiezen LF-Tag-machtigingen.
- Kies Grant.
- kies Externe accounts en voer het account-ID van consumentenaccount B in.
- Onder LF-tags, ga naar binnen
LFHiveBlogCampaignRoleFor sleutel en ga naar binnenAnalystenAdminFor Values. - Onder machtigingenselecteer Beschrijven en Associëren voor LF-Tag-machtigingen en Verleenbare machtigingen.
- Kies Grant en controleer of de verleende LF-Tag-machtigingen correct worden weergegeven.

- Kies in het navigatievenster Data lake-machtigingen.
U kunt de machtigingen die zijn verleend aan account B bekijken en verifiëren.
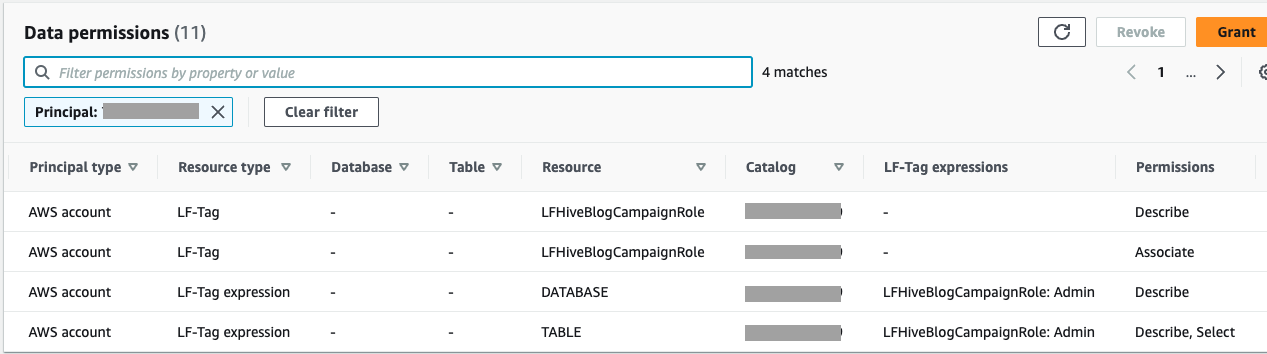
- In het navigatievenster, onder Administratieve rollen en taken, kiezen LF-Tag-machtigingen.
U kunt de machtigingen die zijn verleend aan account B bekijken en verifiëren.

- Meld u af bij account A.
Lake Formation en AWS CloudFormation instellen in account B
Om de installatie eenvoudig te houden, gebruiken we een IAM-beheerder die is geregistreerd als data lake-beheerder.
- Log in bij de AWS-beheerconsole van rekening B en selecteer de
us-west-2Regio. - Op de Lake Formation-console, onder machtigingen in het navigatievenster, kies Administratieve rollen en taken.
- Kies Beheer beheerders in de Data Lake-beheerders pagina.
- Kies onder IAM-gebruikers en -rollen de IAM-beheerder waarmee u bent aangemeld en kies Bespaar.
- Kies Start Stack om de CloudFormation-sjabloon te implementeren:
- Kies Volgende.
- Geef een naam op voor de stapel en kies Volgende.
- Kies op de volgende pagina Volgende.
- Bekijk de details op de laatste pagina en selecteer Ik erken dat AWS CloudFormation IAM-bronnen kan creëren.
- Kies creëren.
Het maken van een stapel duurt ongeveer 5 minuten. De stapel stelt de set-up van producentenaccount B als volgt in:
- Maakt een IAM-gebruiker aan
hmsblog-consumerstewarden stelt deze gebruiker in als Lake Formation-beheerder - Maakt nog een IAM-gebruiker aan
hmsblog-analyst - Creëert een S3 data lake-bucket om Athena-queryresultaten op te slaan
ListBucketen schrijf objectrechten naar beidehmsblog-consumerstewardenhmsblog-analyst
Noteer de details van de stapeluitvoer.

Accepteer resourceshares in account B
Meld u aan bij de console als hmsblog-consumersteward en voer de volgende stappen uit:
- Navigeer op de AWS CloudFormation-console naar de stapel Uitgangen Tab.
- Kies de link voor
ConsumerStewardCredentialsom te worden doorgestuurd naar de Secrets Manager-console. - Kies op de Secrets Manager-console Haal geheime waarde op en kopieer het wachtwoord voor de consumer steward-gebruiker.
- Gebruik de
ConsoleIAMLoginURLwaarde uit de CloudFormation-sjabloon uitgang om in te loggen op account B met de gebruikersnaam van de steward van de consumenthmsblog-consumerstewarden het wachtwoord dat u uit Secrets Manager hebt gekopieerd. - Open de AWS RAM-console in een ander browsertabblad.
- In het navigatievenster, onder Gedeeld met mij, kiezen Resource-aandelen om de openstaande uitnodigingen te bekijken.
Als het goed is, ziet u twee uitnodigingen voor het delen van bronnen van producentenaccount A: één voor een gedeelde database op databaseniveau en één voor een gedeelde map op tabelniveau.

- Kies elke koppeling voor het delen van bronnen, bekijk de details en maak een keuze ACCEPTEREN.

Nadat u de uitnodigingen hebt geaccepteerd, verandert de status van de resourceshares van In behandeling naar Actief.
- Open de Lake Formation-console in een ander browsertabblad.
- Kies in het navigatievenster databases.
U zou de gedeelde database moeten zien federated_emrhivedb van producentenaccount A.
- Kies de database en kies Tabellen bekijken om de lijst met gedeelde tabellen onder die database te bekijken.

U zou de vier tabellen van de Hive-database moeten zien die wordt gehost op het EMR-cluster in het producentenaccount.

Machtigingen verlenen in account B
Voer de volgende stappen uit om machtigingen te verlenen in account B hmsblog-consumersteward:
- Kies op de Lake Formation-console in het navigatiedeelvenster Administratieve rollen en taken.
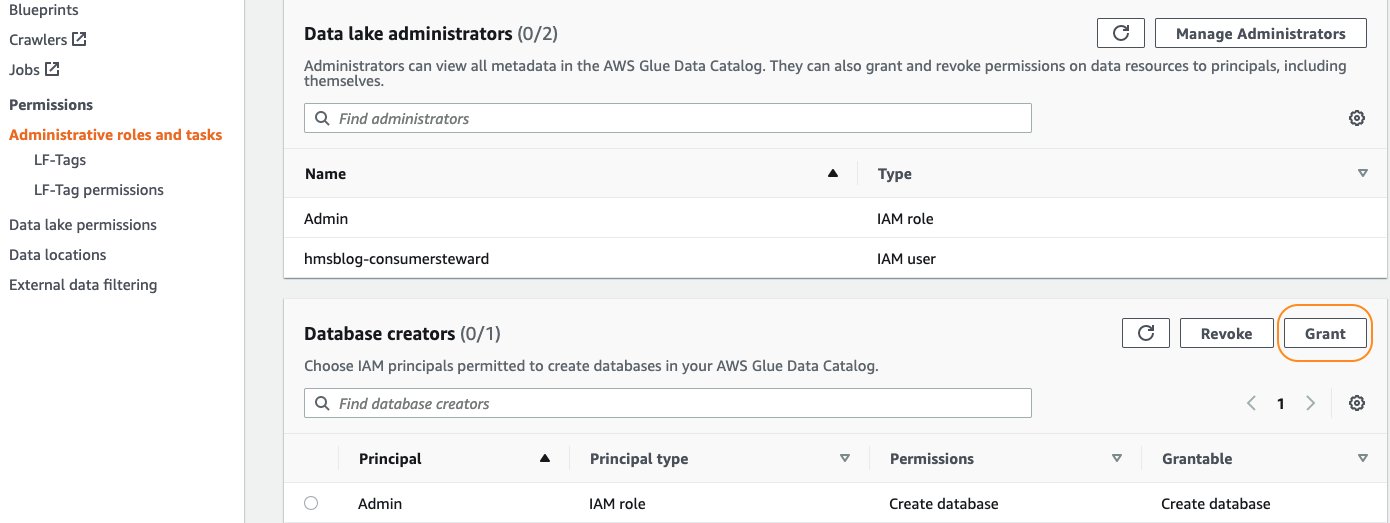
- Onder Database-makers, kiezen Grant.
- Voor IAM-gebruikers en -rollen, ga naar binnen
hmsblog-consumersteward. - Voor Catalogusmachtigingenselecteer Maak een database.
- Kies Grant.

Dit staat toe hmsblog-consumersteward om een koppeling met een databasebron te maken.
- Kies in het navigatievenster databases.
- kies
federated_emrhivedben in de Acties menu, kies Maak een resourcekoppeling.
- Enter
rl_federatedhivedbFor Naam bronlink En kies creëren.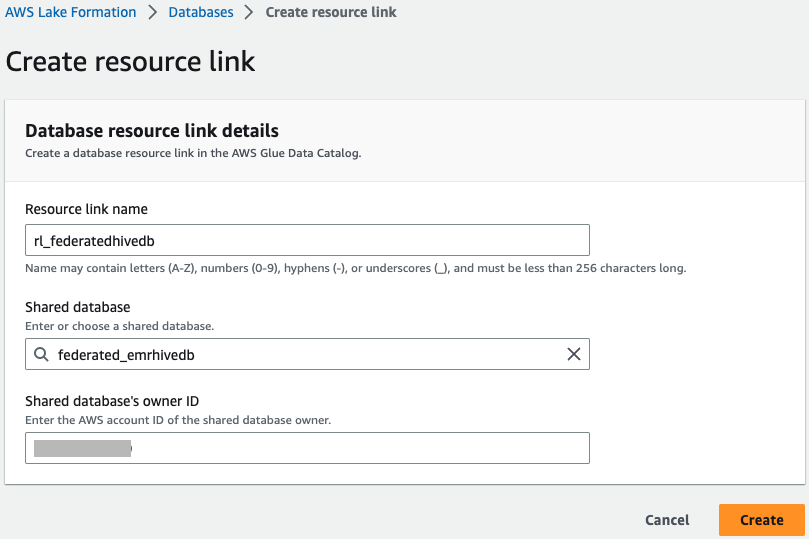
- Kies databases in het navigatievenster.
- Selecteer de bronkoppeling
rl_federatedhivedben in de Acties menu, kies Grant. - Kies
hmsblog-analystFor IAM-gebruikers en -rollen.
- Onder Rechten voor bronlinkselecteer Beschrijven, kies dan Grant.
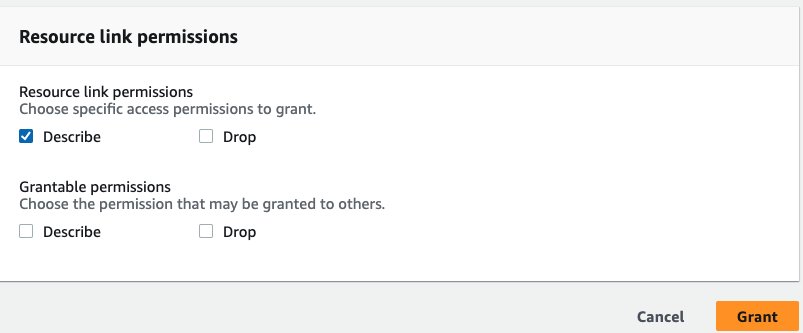
- kies databases in het navigatievenster.
- Selecteer de bronkoppeling
rl_federatedhivedben in de Acties menu, kies Subsidie op doel. - Kies
hmsblog-analystFor IAM-gebruikers en -rollen. - Kies
hms_productcategoryenhms_supplierFor Tafels.
- Voor Tabelrechtenselecteer kies en Beschrijven, kies dan Grant.

- Kies in het navigatievenster Data lake-machtigingen en bekijk de machtigingen die zijn verleend aan
hms-analyst.
Vraag de Apache Hive-database van de producent van de consument Athena
Voer de volgende stappen uit:
- Navigeer op de Athena-console naar de query-editor.
- Kies Instellingen bewerken om de Athena-queryresultaten te configureren bucked.

- Blader en kies de S3-bucket
hmsblog-athenaresults-<your-account-B>-us-west-2die de CloudFormation-sjabloon heeft gemaakt. - Kies Bespaar.

hmsblog-consumersteward heeft toegang tot alle vier onderstaande tabellen federated_emrhivedb van het producentenaccount.
- Kies de database in de Athena-query-editor
rl_federatedhivedben voer een query uit op een van de tabellen.
U kon een externe Apache Hive-metastore-database van het producentenaccount opvragen via de AWS Glue Data Catalog en Lake Formation-machtigingen met behulp van Athena vanuit het ontvangende consumentenaccount.
- Meld u af bij de console als
hmsblog-consumerstewarden log opnieuw in alshmsblog-analyst. - Gebruik dezelfde methode als eerder uitgelegd om de inloggegevens van de CloudFormation-stack op te halen Uitgangen Tab.
hmsblog-analyst heeft machtigingen Beschrijven voor de bronkoppeling en toegang tot twee van de vier Hive-tabellen. U kunt verifiëren dat u ze ziet op de databases en Tafels pagina's op de Lake Formation-console.


Op de Athena-console configureert u nu de Athena-queryresultatenbucket, vergelijkbaar met hoe u deze hebt geconfigureerd hmsblog-consumersteward.
- Kies in de query-editor Instellingen bewerken.
- Blader en kies de S3-bucket
hmsblog-athenaresults-<your-account-B>-us-west-2die de CloudFormation-sjabloon heeft gemaakt. - Kies Bespaar.
- Kies de database in de Athena-query-editor
rl_federatedhivedben voer een query uit op de twee tabellen.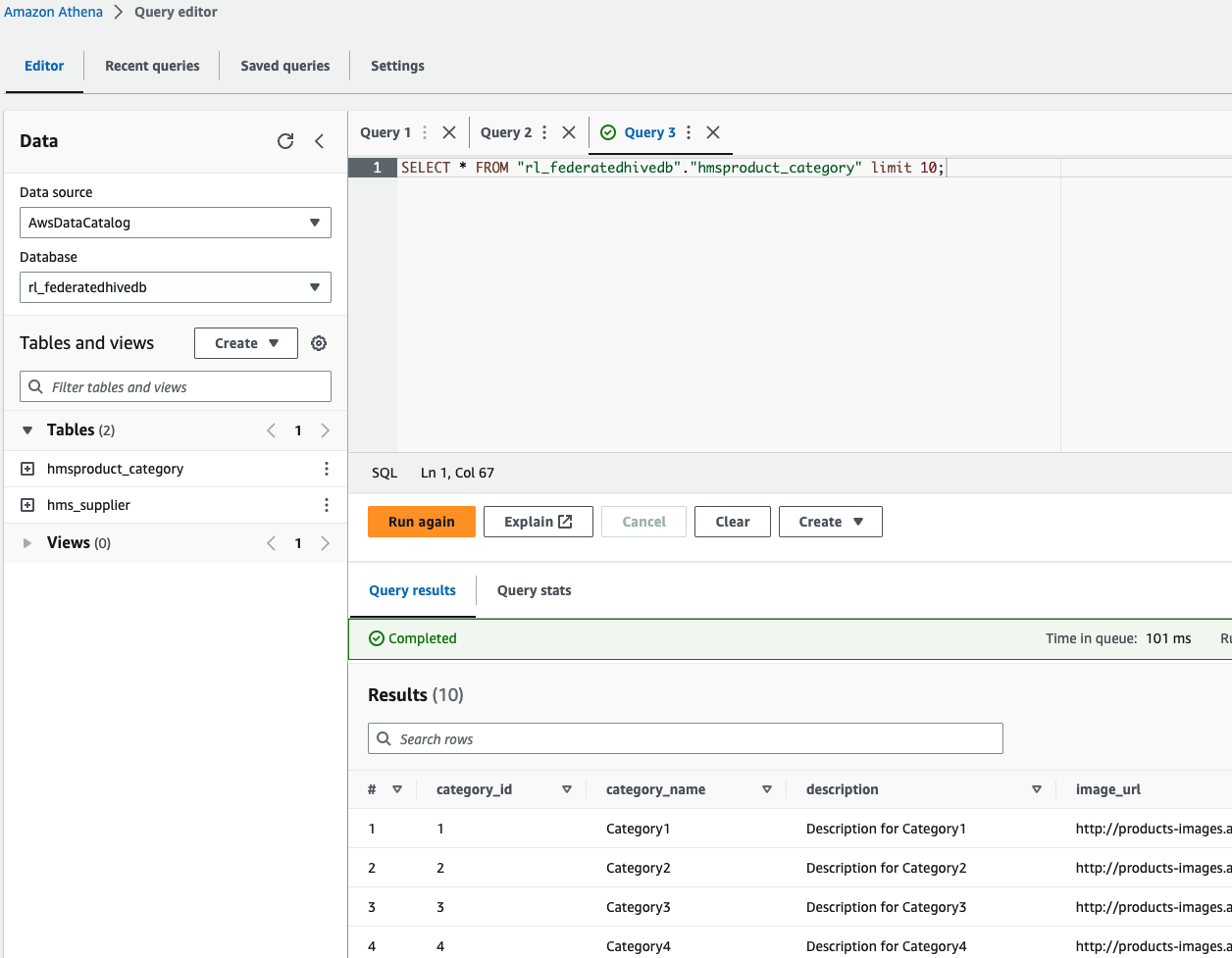
- Meld u af bij de console als
hmsblog-analyst.
U kon het delen van de externe Apache Hive-metastore-tabellen beperken met behulp van Lake Formation-machtigingen van het ene account naar het andere en ze opvragen met behulp van Athena. U kunt ook de Hive-tabellen opvragen met behulp van Redshift Spectrum, Amazon EMR en AWS Glue ETL vanuit het consumentenaccount.
Opruimen
Om te voorkomen dat er kosten in rekening worden gebracht voor de AWS-bronnen die in dit bericht zijn gemaakt, kunt u de volgende stappen uitvoeren.
Resources opschonen in account A
Er zijn twee CloudFormation-stacks gekoppeld aan producentenaccount A. U moet de afhankelijkheden en de twee stacks in de juiste volgorde verwijderen.
- Log in als de admin-gebruiker op producentenaccount B.
- Kies op de Lake Formation-console Data lake-machtigingen in het navigatievenster.
- Kies Grant.
- Geef Drop-machtigingen aan uw rol of gebruiker op
federated_emrhivedb.
- Kies in het navigatievenster databases.
- kies
federated_emrhivedben in de Acties menu, kies Verwijder om de gefedereerde database te verwijderen die is gekoppeld aan de Hive-metastore-verbinding.
Hierdoor is de CloudFormation-stack van de AWS Glue-verbinding klaar om te worden verwijderd.

- Kies in het navigatievenster Administratieve rollen en taken.
- Onder Database-makersselecteer Intrekken en verwijder
hmsblog-producerstewardmachtigingen. - Verwijder op de CloudFormation-console de stapel met de naam
serverlessrepo-GlueDataCatalogFederation-HiveMetastorekopen.
Dit is degene die is gemaakt door uw AWS SAM-toepassing voor de Hive-metastore-verbinding. Wacht tot het verwijderen is voltooid.
- Verwijder de CloudFormation-stack die u hebt gemaakt voor het instellen van het producentenaccount.
Hiermee worden de S3-buckets, het EMR-cluster, aangepaste IAM-rollen en -beleid, en de LF-tags, database, tabellen en machtigingen verwijderd.
Resources opschonen in account B
Voer de volgende stappen uit in account B:
- Toestemming voor intrekken
hmsblog-consumerstewardals database-maker, vergelijkbaar met de stappen in de vorige sectie. - Verwijder de CloudFormation-stack die u hebt gemaakt voor de configuratie van het consumentenaccount.
Hiermee worden de IAM-gebruikers, de S3-bucket en alle machtigingen van Lake Formation verwijderd.
Als er links naar bronnen en machtigingen over zijn, verwijdert u deze handmatig in Lake Formation van beide accounts.
Conclusie
In dit bericht hebben we u laten zien hoe u de AWS Glue Hive-metastore-federatietoepassing start vanuit AWS Serverless Application Repository, deze configureert met een Hive-metastore die draait op een EMR-cluster, een gefedereerde database maakt in de AWS Glue Data Catalog en deze toewijst aan een Hive-metastore-database op het EMR-cluster. We hebben geïllustreerd hoe u de Hive-databasetabellen kunt delen en openen voor een scenario met meerdere accounts en de voordelen van het gebruik van Lake Formation om machtigingen te beperken.
Alle functies van Lake Formation, zoals delen met IAM-principals binnen hetzelfde account, delen met externe accounts, delen met externe IAM-principals, kolomtoegang beperken en gegevensfilters instellen, werken op gefedereerde Hive-database en -tabellen. U kunt elk van de AWS-analyseservices gebruiken die zijn geïntegreerd met Lake Formation, zoals Athena, Redshift Spectrum, AWS Glue ETL en Amazon EMR om de gefedereerde Hive-database en -tabellen te doorzoeken.
We raden u aan om de functies van de AWS Glue Hive-metastore-federatieconnector te bekijken en Lake Formation-machtigingen voor uw Hive-database en -tabellen te verkennen. Reageer op dit bericht of praat met uw AWS-accountteam om feedback over deze functie te delen.
Zie voor meer informatie Machtigingen beheren voor datasets die externe metastores gebruiken.
Over de auteurs
 Aarthi Srinivasan is een Senior Big Data Architect bij AWS Lake Formation. Ze bouwt graag data lake-oplossingen voor AWS-klanten en -partners. Als ze niet achter het toetsenbord zit, verkent ze de nieuwste wetenschappelijke en technologische trends en brengt ze tijd door met haar gezin.
Aarthi Srinivasan is een Senior Big Data Architect bij AWS Lake Formation. Ze bouwt graag data lake-oplossingen voor AWS-klanten en -partners. Als ze niet achter het toetsenbord zit, verkent ze de nieuwste wetenschappelijke en technologische trends en brengt ze tijd door met haar gezin.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. Automotive / EV's, carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- BlockOffsets. Eigendom voor milieucompensatie moderniseren. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/query-your-apache-hive-metastore-with-aws-lake-formation-permissions/

