
Foto door Skylar Zilka on Unsplash
Het evalueren van modelrelevantie stopt niet bij het meten van de prestaties. Om vele redenen is het belangrijk om te weten hoe het uiteindelijk zulke voorspellingen deed. Het bevordert met name: een beter begrip van modellen, uitleggen hoe het werkt aan niet-dataspecialisten, het controleren van bias en modelconsistentie, en debuggen,...
Een machine learning-model kan worden uitgelegd met behulp van lokale uitlegbaarheid of globale uitlegbaarheid.
In dit artikel gebruiken we a complementaire benadering door te combineren uitlegbaarheid en monster plukken.
Monsters plukken is een proces met grote toegevoegde waarde om modellen, hun sterktes en zwaktes beter te begrijpen. Om deze aanpak toe te lichten beantwoorden we 3 vragen:
Waarom monsters selecteren? Wat voor monsters wilt u analyseren? Wat te analyseren in deze monsters?
Lokale en globale verklaarbaarheid
Laten we eerst kort de lokale en globale noties van verklaarbaarheid in herinnering roepen.
De klassieke vormen van lokale verklaarbaarheid zijn op gewicht gebaseerde methoden.
De voorspelling van een gegeven steekproef wordt verklaard door het gewicht van elke functie die in het machine learning-model wordt gebruikt, te ontleden.

Afbeelding door auteur
Globale verklaarbaarheid bestaat uit het meten hoe kenmerken belangrijk zijn voor modelvoorspelling. Deze verklaarbaarheid wordt vaak als volgt weergegeven:
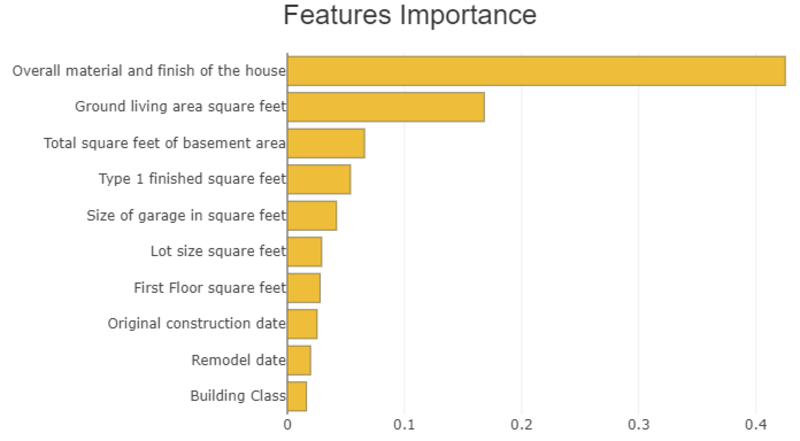
Afbeelding door auteur
Nu we snel de noties van verklaarbaarheid hebben geïntroduceerd, gaan we terug naar de vragen over plukken.
Om dit te illustreren gebruiken we Sjapas, een open-source Python-bibliotheek over verklaarbaarheid. Hierin vindt u de algemene presentatie van Shapash dit artikel.
De onderstaande illustraties zijn gebaseerd op de beroemde Kaggle-datasets: "Titanisch" (voor classificatie) en "Huis prijzen" (voor regressie).
- Uitleggen hoe het model werkt en wat de kenmerken zijn van een enkel exemplaar of van een subpopulatie.
Laten we bijvoorbeeld het regressiemodel van de prijs van een huis nemen op basis van deze kenmerken.
U kunt een koper uitleggen waarom de woning op deze prijs wordt gewaardeerd. Of hoe het model huizen inschat met grotere oppervlakten, gelegen in een specifieke wijk, en gebouwd met hout.
- Om verkeerde voorspellingen beter te begrijpen
Dit kan leiden tot de volgende vragen: Komt het probleem door de datakwaliteit?
Als we een zeer lage werkelijke prijs hebben en we schatten dat deze hoger zal zijn omdat de vierkante meters van het huis hoog zijn, kan dit de kwaliteit van de "Oppervlakte" -functie in twijfel trekken.
Kan een extra functie de voorspelling verbeteren?
Als een makelaar een tekstuele beschrijving geeft van wat de koper het leukst vindt. Zelfs als deze tekstuele variabele niet beschikbaar is op het moment van de voorspelling, kunnen we deze gebruiken om de voorspellingsfout op monsters te vergelijken met de feedback van de koper.
- Om correcte voorspellingen van het model te illustreren
We kunnen voorbeelden nemen om de voorspelling van een machine learning-model uit te leggen. Dit proces is eenvoudiger wanneer de meest relevante voorbeelden worden gemarkeerd.
- Om monsters te selecteren waarop gegevenskwaliteitsvalidatie moet worden uitgevoerd of om de resultaten te valideren
Als datawetenschapper kunt u een idee hebben van de prijs voor sommige verkopen die het model zou moeten schatten. Als u de lokale verklaarbaarheid ervan onderzoekt, krijgt u ook mogelijke redenen om de schatting te rationaliseren. Dan kun je het verschil waarnemen tussen jouw gedachten en de lokale verklaarbaarheid. Op basis hiervan zou je de datakwaliteit, de voorspelling van het model en de verklaarbaarheid al dan niet kunnen valideren.
- Voorbeelden bestuderen met experts die bekend zijn met de use case.
Door verkoop te selecteren, kunt u met de makelaar zien wat hij vindt van de prijsvoorspelling en het belang van de kenmerken op de prijs.
Het is mogelijk om te analyseren:
- ruwe modelvoorspellingen
- correcte voorspellingen/fouten (door de associatie van voorspellingen met de bekende doelstatus)
- een subset volgens uitvoerkansen van de modelvoorspelling, doel om te voorspellen, waarden van verklarende kenmerken
Waarom geen willekeurige steekproeven nemen?
Naar bespaar tijd en heb een uitputtende visie van de verschillende gevallen. Aangezien we gewoonlijk geen honderden steekproeven evalueren, kan het willekeurig selecteren van deze steekproeven ertoe leiden dat er willekeurig vergelijkbare steekproeven worden genomen. Het zou dus mogelijk zijn om potentieel interessante gevallen over het hoofd te zien.
Sinds Shapash-versie 2.2.0, U kunt deze voorbeelden identificeren door de modelkansen voor elk geleverd monster uit te zetten als een functie van hun ware label, zoals:
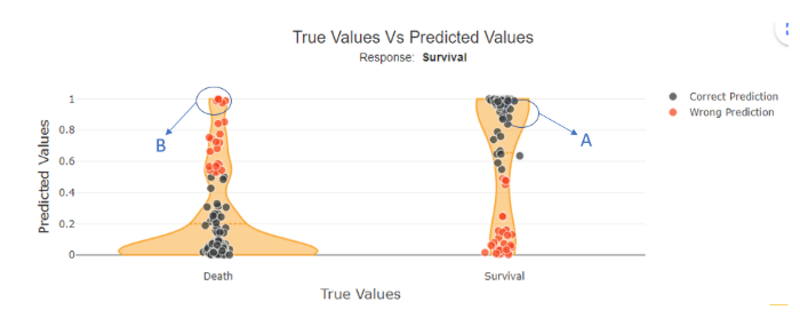
Figuur 1 door auteur
Voor binaire classificatie met modeluitvoerkansen tussen 0 en 1 zouden we een goed voorspelde klasse 1-steekproef kunnen selecteren. In dit geval vertoont deze klasse 1, zoals verwacht, een grote kans om in klasse 1 te vallen (zoals te zien is in figuur 1, voorbeeld A).
Omgekeerd kunnen we ook een verkeerd voorspelde klasse 1-steekproef selecteren. Hier zou deze steekproef moeten worden voorspeld als 0, maar de kans is groot dat deze in klasse 1 valt (zoals te zien is in figuur 1, voorbeeld B).
Voor regressie bevordert het uitzetten van de voorspelde waarden tegen de werkelijke waarden de directe identificatie en studie van de beste of slechtste voorspellingen die door het model worden geretourneerd.
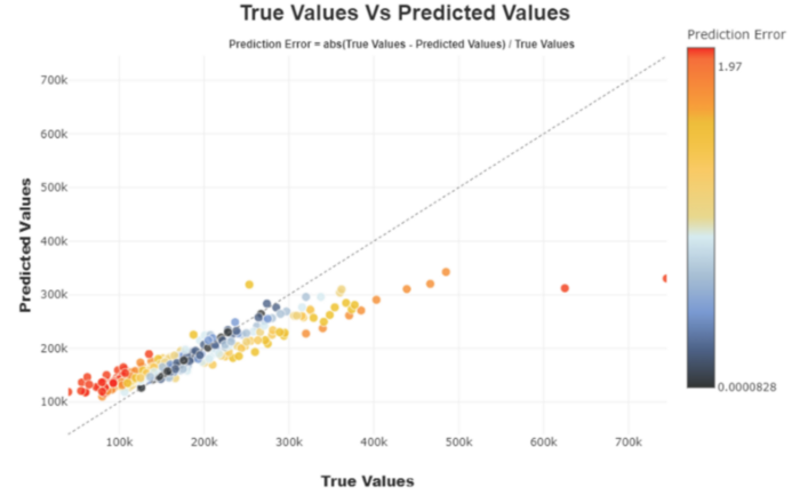
Figuur 2 door auteur
De selectie van een subset kan het begrip van het gedrag van een populatie vergemakkelijken:
Voor binaire classificatie zou de subset zich kunnen concentreren op alle punten die worden voorspeld als klasse 1 die in feite klasse 0 zijn (dwz de "fout-negatieve" subpopulatie).

Afbeelding door auteur
Voor regressie kan het interessant zijn om te focussen op een reeks goed geschatte, over- of onderschatte waarden.
U kunt ook een subset selecteren op basis van de kenmerken van de verklarende kenmerken.
Op huizenprijs kunt u bijvoorbeeld huizen selecteren waarvan de bouwdatum hoger is dan 2000. Of volgens de ligging van de woning.
- Wanneer je een enkele steekproef wilt verklaren, is het interessant om te kijken naar de lokale verklaarbaarheid ervan.
Met de shapash-webapp kunt u bijvoorbeeld een enkel monster selecteren dat u wilt analyseren in de lokale plot:
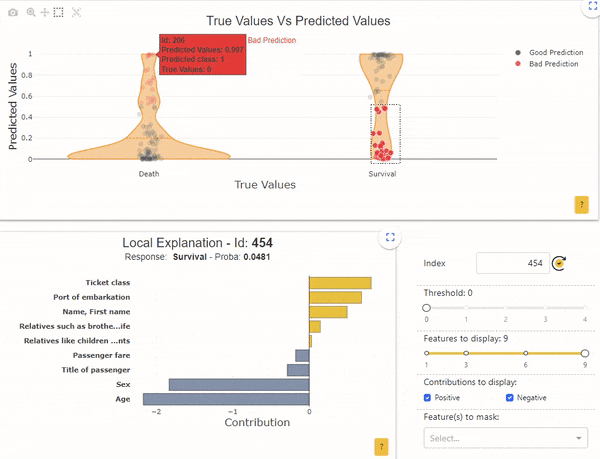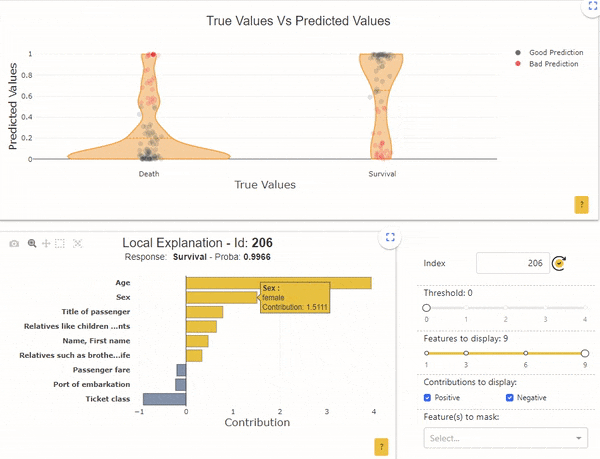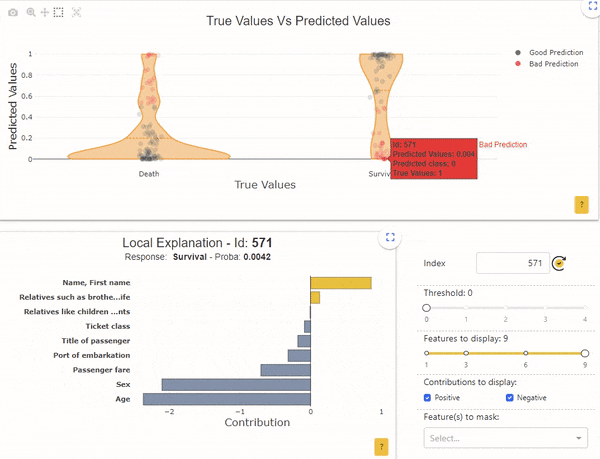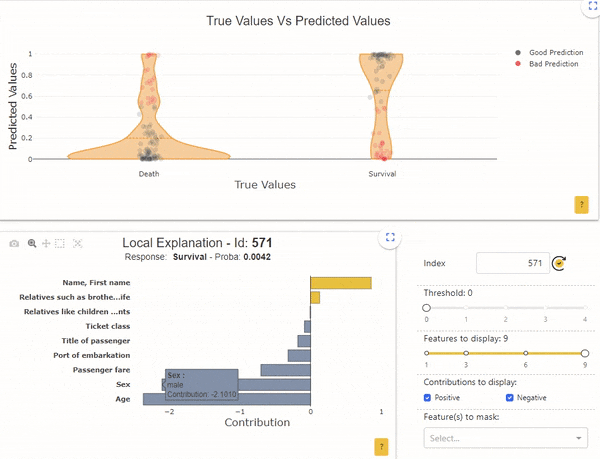
Afbeelding door auteur
Het monster met de index "206" heeft een overlevingskans van 0.99, maar het echte label is "Dood". Voor deze persoon geeft de lokale interpreteerbaarheid aan dat de kans vooral bepaald wordt door de leeftijd (2 jaar) en door het geslacht (vrouw).
Omgekeerd heeft de steekproef met de index "571" een overlevingskans van 0.005, maar het echte label is "Overleving". Ook hier geeft de lokale interpreteerbaarheid aan dat de kans vooral bepaald wordt door de leeftijd (62 jaar) en door het geslacht (man).
In deze 2 gevallen, met betrekking tot de globale werking van het model, begrijpen we dat het normaal is dat het model ongelijk heeft. Controleer bijvoorbeeld of de 'leeftijd'-gegevens correct zijn verzameld, of vraag of andere gegevens kunnen verklaren dat oudere mannen het hebben overleefd. We kunnen ons ook afvragen of dit soort personen vaak in de dataset voorkomen. Als er maar een paar voorbeelden zijn, is het model niet in staat betrouwbare regels goed te leren.
In andere gevallen kan het helpen om de datakeuze, datakwaliteit of de noodzaak om andere kenmerken te verzamelen in twijfel te trekken.
- Als je een subpopulatie wilt begrijpen, kun je kijken naar de globale verklaarbaarheid van die subpopulatie en deze vergelijken met de wereldbevolking.
Als u bijvoorbeeld wilt inzoomen op de "False negative" in deze app:
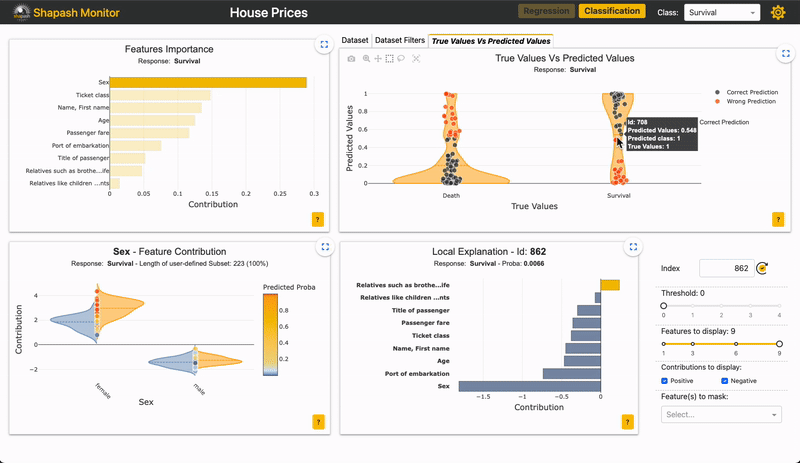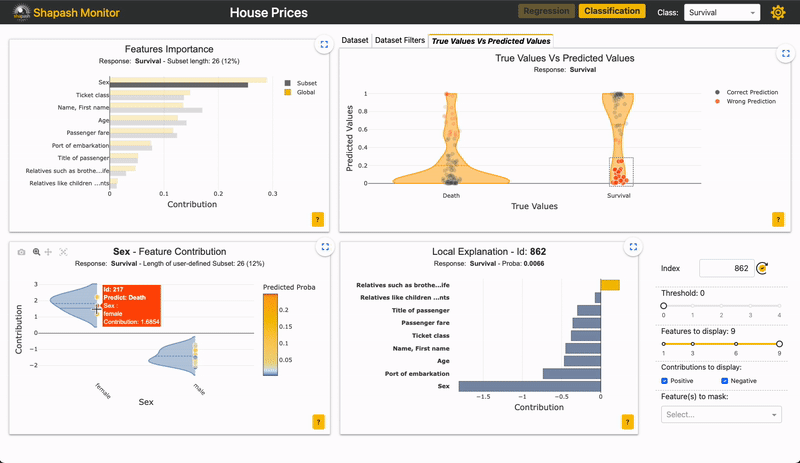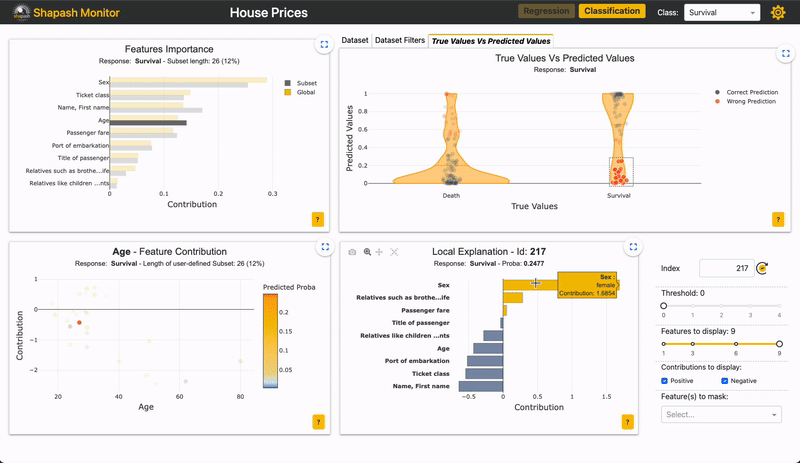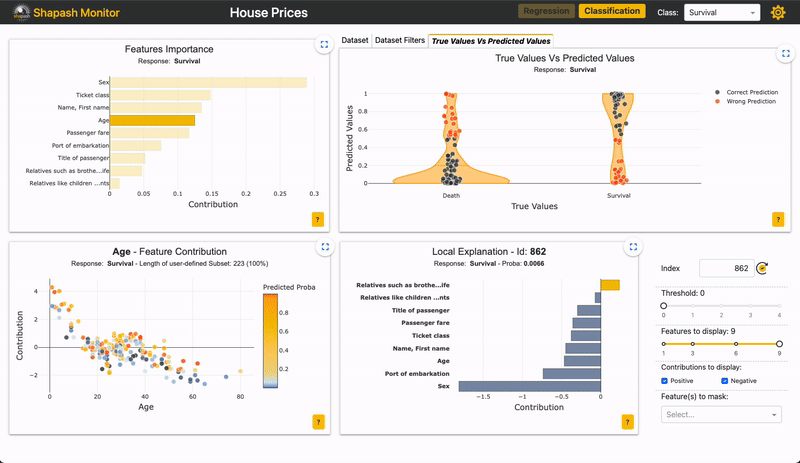
Afbeelding door auteur
U kunt zien of het belang van kenmerken voor de subset vergelijkbaar is met de totale populatie.
Voor de “False negative” subpopulatie is er een afname in het gewicht van de “Sex”-functie op de voorspelling (grijze versus gele balk). Dit zou kunnen berusten op het feit dat vrouwen ondervertegenwoordigd zijn in deze subgroep. Omdat de functie 'Seks' minder impact heeft, nemen de andere functies het over. We kunnen zien dat veel verkeerde voorspellingen berusten op de variabele "leeftijd", voor personen tussen de 20 en 30 jaar oud.
Het voordeel van het selecteren van een deelverzameling in plaats van een enkele steekproef is dat we dat kunnen generaliseren verkeerde of correcte voorspellingen, en specifiek kijken naar hun globale verklaarbaarheid met betrekking tot de gehele bevolking.
In dit voorbeeld zou een extra kenmerk kunnen helpen om mannen van in de twintig beter te classificeren.
pluk enkele monsters of subgroep is een aanvullende benadering die datawetenschappers helpt hun modellen te begrijpen.
Deze benaderingen kunnen worden gebruikt als krachtige instrumenten om leg de modellen uit aan niet-datatechnici. Het biedt betrouwbare verklaringen van voorspellingen over monsters illustreren hoe het model werkt.
Subpopulaties kunnen ook worden beschreven en gekwalificeerd met behulp van clusterbenaderingen.
Als u pluktechnieken gebruikt om een model te helpen begrijpen, kunt u dit in de opmerkingen uitleggen!
Thomas Bouche is een datawetenschapper bij MAIF.
- Coinsmart. Europa's beste Bitcoin- en crypto-uitwisseling.Klik Hier
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://www.kdnuggets.com/2022/11/picking-examples-understand-machine-learning-model.html?utm_source=rss&utm_medium=rss&utm_campaign=picking-examples-to-understand-machine-learning-model

