Trino is een open source gedistribueerde SQL-query-engine die is ontworpen voor interactieve analytische workloads. Op AWS kun je Trino gebruiken Amazon EMR, waar u de flexibiliteit heeft om uw favoriete versie van open source Trino uit te voeren Amazon Elastic Compute-cloud (Amazon EC2)-instanties die u beheert of waarop u deze beheert Amazone Athene voor een serverloze ervaring. Wanneer u Trino op Amazon EMR of Athena gebruikt, krijgt u de nieuwste open source community-innovaties samen met eigen, door AWS ontwikkelde optimalisaties.
Vanaf Amazon EMR 6.8.0 en Athena engine versie 2 heeft AWS optimalisaties voor het queryplan en het motorgedrag ontwikkeld die de queryprestaties op Trino verbeteren. In dit bericht vergelijken we Amazon EMR 6.15.0 met open source Trino 426 en laten we zien dat TPC-DS-query's tot 2.7 keer sneller liepen op Amazon EMR 6.15.0 Trino 426 vergeleken met open source Trino 426. Later leggen we enkele van de door AWS ontwikkelde prestatie-optimalisaties uit die bijdragen aan deze resultaten.
Benchmark-opstelling
Bij onze tests hebben we de dataset van 3 TB gebruikt die is opgeslagen in Amazon S3 in gecomprimeerd Parquet-formaat en metagegevens voor databases en tabellen worden opgeslagen in de AWS lijm Gegevenscatalogus. Deze benchmark maakt gebruik van ongewijzigde TPC-DS-gegevensschema's en tabelrelaties. Feitentabellen zijn gepartitioneerd in de datumkolom en bevatten partities van 200-2100. Voor geen van de tabellen waren tabel- en kolomstatistieken aanwezig. We gebruikten TPC-DS-query's van de open source Trino Github-repository zonder wijziging. Benchmarkquery's werden opeenvolgend uitgevoerd op twee verschillende Amazon EMR 6.15.0-clusters: één met Amazon EMR Trino 426 en de andere met open source Trino 426. Beide clusters gebruikten 1 r5.4xlarge-coördinator en 20 r5.4xlarge-werknemersinstanties.
Resultaten waargenomen
Onze benchmarks laten consistent betere prestaties zien met Trino op Amazon EMR 6.15.0 vergeleken met open source Trino. De totale queryruntime van Trino op Amazon EMR was 2.7 keer sneller vergeleken met open source. In de volgende grafiek ziet u prestatieverbeteringen gemeten aan de hand van de totale queryruntime (in seconden) voor de benchmarkquery's.
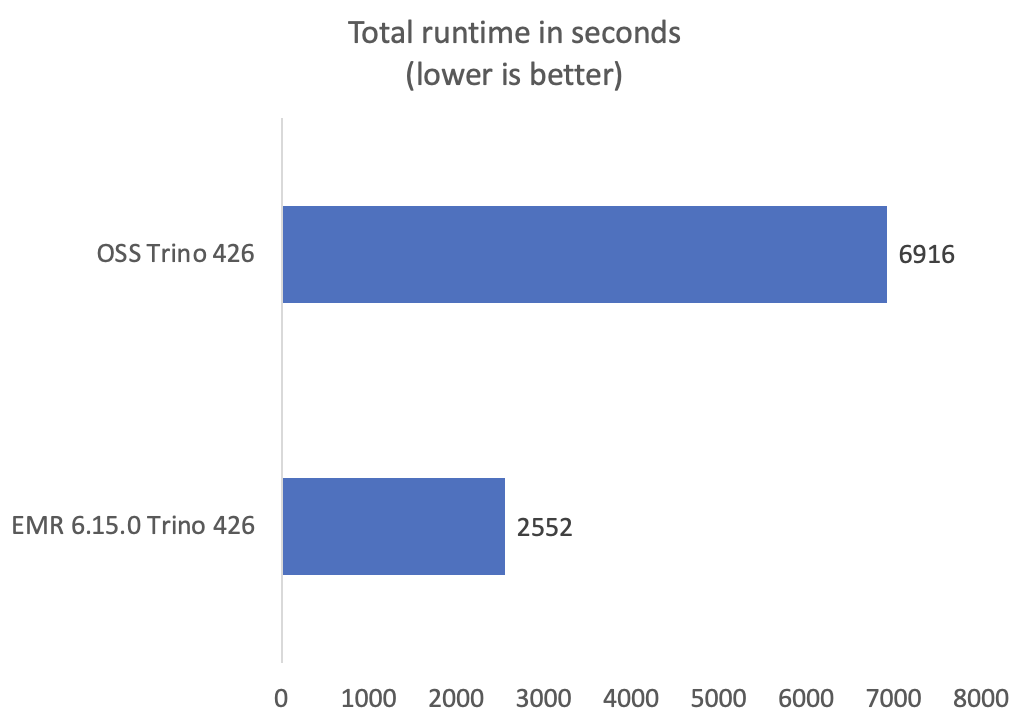
Veel van de TPC-DS-query's lieten prestatieverbeteringen zien die meer dan vijf keer zo snel waren in vergelijking met open source Trino. Sommige zoekopdrachten lieten zelfs nog betere prestaties zien, zoals zoekopdracht 72, die 160 keer verbeterde. In de volgende grafiek ziet u de top 10 van TPC-DS-query's met de grootste verbetering in runtime. Voor een beknopte weergave en om scheefheid van prestatieverbeteringen in de grafiek te voorkomen, hebben we q72 uitgesloten.

Prestatieverbeteringen
Nu we de prestatiewinsten met Trino op Amazon EMR begrijpen, gaan we dieper in op enkele van de belangrijkste innovaties die zijn ontwikkeld door AWS-engineering en die bijdragen aan deze verbeteringen.
Het kiezen van een betere joinvolgorde en een beter jointype is van cruciaal belang voor betere queryprestaties, omdat dit van invloed kan zijn op de hoeveelheid gegevens die uit een bepaalde tabel worden gelezen, hoeveel gegevens via het netwerk naar de tussenliggende fasen worden overgedragen en hoeveel geheugen er nodig is om op te bouwen. een hashtabel om een join te vergemakkelijken. Beslissingen over de samenvoegingsvolgorde en het samenvoegingsalgoritme zijn doorgaans een functie die wordt uitgevoerd door op kosten gebaseerde optimalisatieprogramma's, die statistieken gebruiken om queryplannen te verbeteren door te beslissen hoe tabellen en subquery's worden samengevoegd.
Tabelstatistieken zijn echter vaak niet beschikbaar, verouderd of te duur om op grote tabellen te verzamelen. Wanneer er geen statistieken beschikbaar zijn, gebruiken Amazon EMR en Athena metadata van S3-bestanden om queryplannen te optimaliseren. Metagegevens van S3-bestanden worden gebruikt om kleine subquery's en tabellen in de query af te leiden, terwijl de join-volgorde of het join-type worden bepaald. Neem bijvoorbeeld de volgende vraag:
De syntactische joinvolgorde is store_sales sluit zich aan store_returns sluit zich aan call_center. Met het Amazon EMR-jointype en de optimalisatieregels voor orderselectie wordt de optimale joinvolgorde bepaald, zelfs als deze tabellen geen statistieken bevatten. Voor de voorgaande query if call_center wordt beschouwd als een kleine tabel nadat de geschatte grootte is geschat via metagegevens van S3-bestanden, dan worden de join-optimalisatieregels van EMR samengevoegd store_sales Met call_center eerst en converteer de join naar een broadcast-join, waardoor de query wordt versneld en het geheugenverbruik wordt verminderd. Door de volgorde van joins te wijzigen, wordt de tussenresultaatgrootte geminimaliseerd, waardoor de algehele queryruntime verder wordt verkort.
Met Amazon EMR 6.10.0 en hoger zijn op metagegevens gebaseerde join-optimalisaties van S3-bestanden standaard ingeschakeld. Als u Amazon EMR 6.8.0 of 6.9.0 gebruikt, kunt u deze optimalisaties inschakelen door de sessie-eigenschappen van Trino-clients in te stellen of door de volgende eigenschappen toe te voegen aan de trino-config-classificatie bij het maken van uw cluster. Verwijzen naar Configureer applicaties voor meer informatie over hoe u de standaardconfiguraties voor een toepassing kunt overschrijven.
Configuratie voor selectie van jointype:
Configuratie voor het opnieuw ordenen van joins:
Conclusie
Met Amazon EMR 6.8.0 en hoger kun je zoekopdrachten op Trino aanzienlijk sneller uitvoeren dan op open source Trino. Zoals u in deze blogpost kunt zien, liet onze TPC-DS-benchmark een 2.7 keer betere verbetering zien in de totale runtime van zoekopdrachten met Trino op Amazon EMR 6.15.0. De optimalisaties die in dit bericht worden besproken, en vele andere, zijn ook beschikbaar bij het uitvoeren van Trino-query's op Athena, waar vergelijkbare prestatieverbeteringen worden waargenomen. Raadpleeg voor meer informatie de Voer zoekopdrachten 3x sneller uit met tot 70% kostenbesparingen op de nieuwste Amazon Athena-engine.
In onze missie om namens klanten te innoveren, brengen Amazon EMR en Athena regelmatig prestatie- en betrouwbaarheidsverbeteringen uit voor hun nieuwste versies. Controleer de Amazon EMR en Amazone Athene releasepagina's voor meer informatie over nieuwe functies en verbeteringen.
Over de auteurs
 Bhargavi Sagi is een softwareontwikkelingsingenieur bij Amazon Athena. Ze kwam in 2020 bij AWS en heeft gewerkt aan verschillende gebieden van Amazon EMR en Athena engine V3, waaronder motorupgrades, motorbetrouwbaarheid en motorprestaties.
Bhargavi Sagi is een softwareontwikkelingsingenieur bij Amazon Athena. Ze kwam in 2020 bij AWS en heeft gewerkt aan verschillende gebieden van Amazon EMR en Athena engine V3, waaronder motorupgrades, motorbetrouwbaarheid en motorprestaties.
 Sushil Kumar Shivashankar is de engineeringmanager voor het EMR Trino- en Athena Query Engine-team. Sinds 2014 richt hij zich op de big data-analyseruimte.
Sushil Kumar Shivashankar is de engineeringmanager voor het EMR Trino- en Athena Query Engine-team. Sinds 2014 richt hij zich op de big data-analyseruimte.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/run-trino-queries-2-7-times-faster-with-amazon-emr-6-15-0/

