Amazon DynamoDB is een volledig beheerde, serverloze NoSQL-database met sleutelwaarde, ontworpen om krachtige applicaties op elke schaal uit te voeren. DynamoDB biedt ingebouwde beveiliging, continue back-ups, geautomatiseerde replicatie in meerdere regio's, caching in het geheugen en tools voor het importeren en exporteren van gegevens. De schaalbaarheid en het flexibele dataschema van DynamoDB maken het zeer geschikt voor een verscheidenheid aan gebruiksscenario's. Deze omvatten web- en mobiele applicaties op internetschaal, metadatawinkels met lage latentie, drukbezochte retailwebsites, Internet of Things (IoT) en tijdreeksgegevens, online gaming en meer.
Gegevens opgeslagen in DynamoDB vormen de basis voor waardevolle business intelligence (BI)-inzichten. Om deze data toegankelijk te maken voor data-analisten en andere consumenten, kunt u gebruik maken van Amazone Athene. Athena is een serverloze, interactieve service waarmee u gegevens uit verschillende bronnen in heterogene formaten kunt opvragen, zonder dat u daarvoor hoeft te zorgen. Athena heeft via de open source toegang tot gegevens die zijn opgeslagen in DynamoDB Amazon Athena DynamoDB-connector. Metagegevens van tabellen, zoals kolomnamen en gegevenstypen, worden opgeslagen met behulp van de AWS-lijmgegevenscatalogus.
Ten slotte kunt u BI-inzichten visualiseren Amazon QuickSight, een cloudgebaseerde bedrijfsanalyseservice. QuickSight maakt het voor organisaties eenvoudig om visualisaties te bouwen, ad-hocanalyses uit te voeren en snel zakelijke inzichten uit hun gegevens te halen, altijd en op elk apparaat. Zijn generatieve BI-mogelijkheden stelt u in staat om in natuurlijke taal vragen te stellen over uw gegevens, zonder dat u SQL-query's hoeft te schrijven of een BI-tool hoeft te leren.
Dit bericht laat zien hoe u de Athena DynamoDB-connector kunt gebruiken om eenvoudig gegevens in DynamoDB op te vragen met SQL en inzichten te visualiseren in QuickSight.
Overzicht oplossingen
Het volgende diagram illustreert de oplossingsarchitectuur.
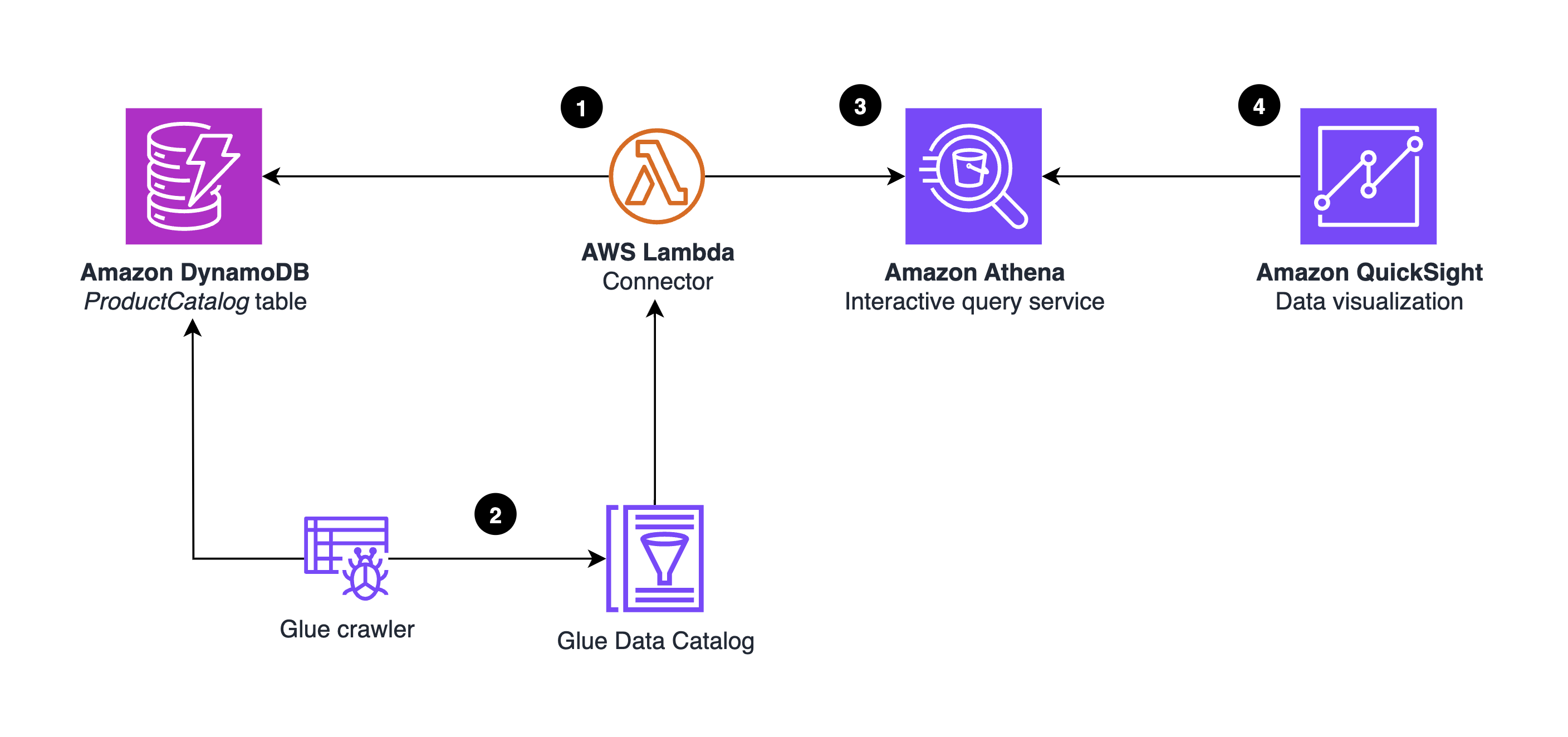
- De Athena DynamoDB-connector draait in een vooraf gebouwd, serverloos AWS Lambda functie. U hoeft geen code te schrijven.
- AWS lijm biedt aanvullende metagegevens uit de DynamoDB-tabel. In het bijzonder een AWS lijmcrawler wordt uitgevoerd om de DynamoDB-tabelindeling, het schema en de bijbehorende eigenschappen af te leiden en op te slaan in de Lijmgegevenscatalogus.
- De Athena-editor wordt gebruikt om de connector te testen en analyses uit te voeren via SQL-query's.
- QuickSight gebruikt de Athena-connector om BI-inzichten uit DynamoDB te visualiseren.
Deze walkthrough maakt gebruik van gegevens uit de ProductCatalog tafel, onderdeel van de DynamoDB ontwikkelaarshandleiding voorbeeldgegevensbestanden.
Voorwaarden
Voordat u aan de slag gaat, moet u aan de volgende vereisten voldoen:
Stel de Athena DynamoDB-connector in
De Athena DynamoDB-connector omvat een vooraf gebouwde, serverloze Lambda-functie van AWS die communiceert met DynamoDB, zodat u uw tabellen kunt opvragen met SQL met behulp van Athena. De connector is verkrijgbaar in de AWS serverloze toepassingsrepository, en wordt gebruikt om de Gegevensbron Athena voor later gebruik bij data-analyse en visualisatie. Voer de volgende stappen uit om de connector in te stellen:
- Kies op de Athena-console Data bronnen in het navigatievenster.
- Kies Maak een gegevensbron.
- Zoek en kies in de zoekbalk Amazon DynamoDB.
- Kies Next.
- Onder Gegevensbrongegevens, voer een naam in. Houd er rekening mee dat deze naam uniek moet zijn en dat er naar wordt verwezen in uw SQL-instructies wanneer u uw Athena-gegevensbron opvraagt.
- Onder Verbindingsdetails, kiezen Lambda-functie maken.
Dit brengt u naar de Lambda-toepassingen pagina op de Lambda-console. Sluit het tabblad voor het maken van Athena-gegevensbronnen niet; u komt er in een latere stap op terug.
- Blader naar beneden naar Applicatie-instellingen en voer een waarde in voor de volgende parameters (laat de andere parameters standaard):
SpillBucket– Specificeert de Amazon eenvoudige opslagservice (Amazon S3) bucketnaam voor het opslaan van gegevens die de responsgroottelimieten van de Lambda-functie overschrijden. Raadpleeg voor het maken van een S3-bucket Een bucket maken.AthenaCatalogName– Een naam in kleine letters voor de Lambda-functie die moet worden gemaakt.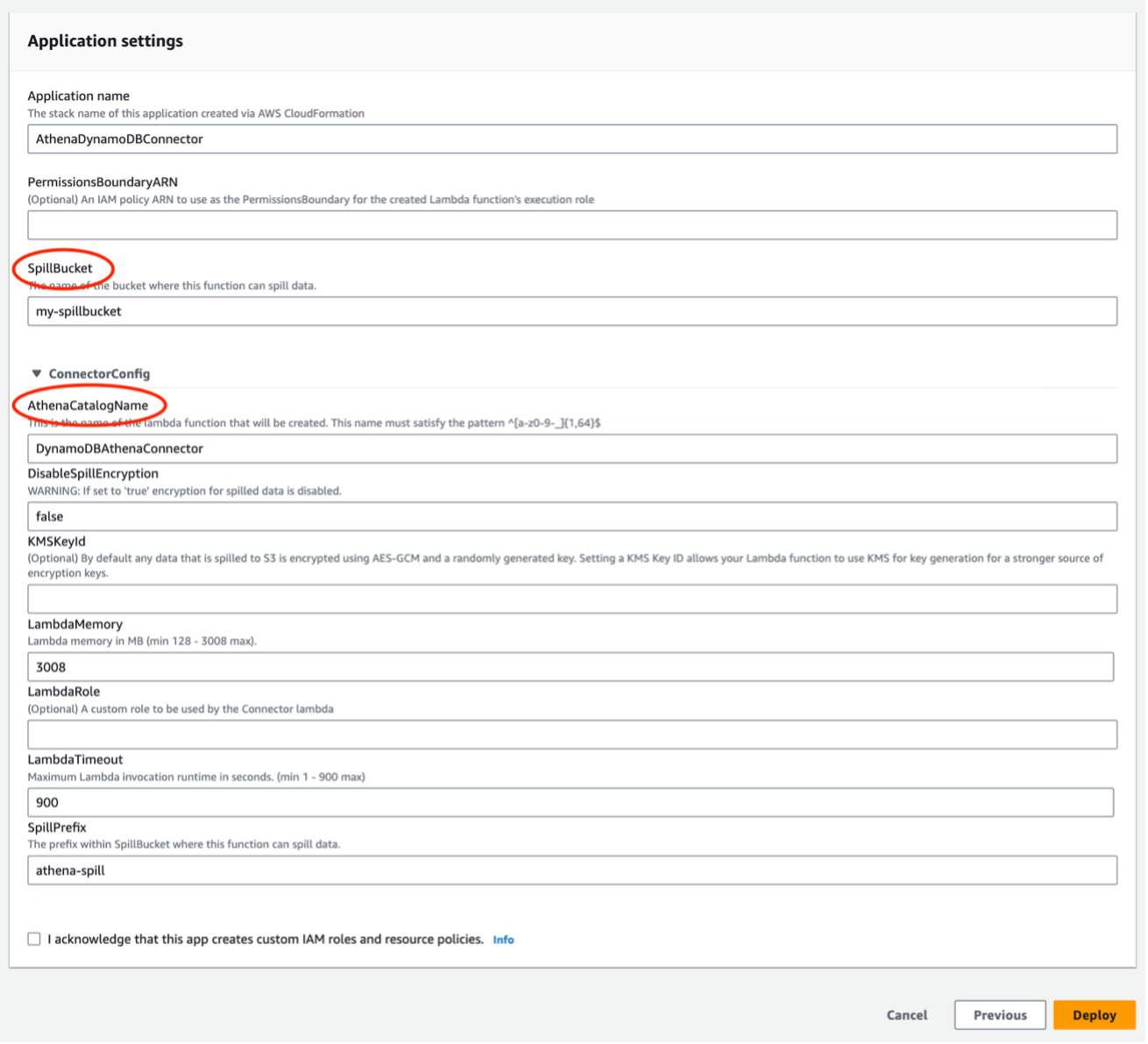
- Schakel het selectievakje voor bevestiging in en kies Implementeren.
Wacht tot de implementatie is voltooid voordat u doorgaat naar de volgende stap.
- Keer terug naar het tabblad voor het maken van Athena-gegevensbronnen.
- Onder Verbindingsdetails, kies het vernieuwingspictogram en kies de Lambda-functie die u hebt gemaakt.
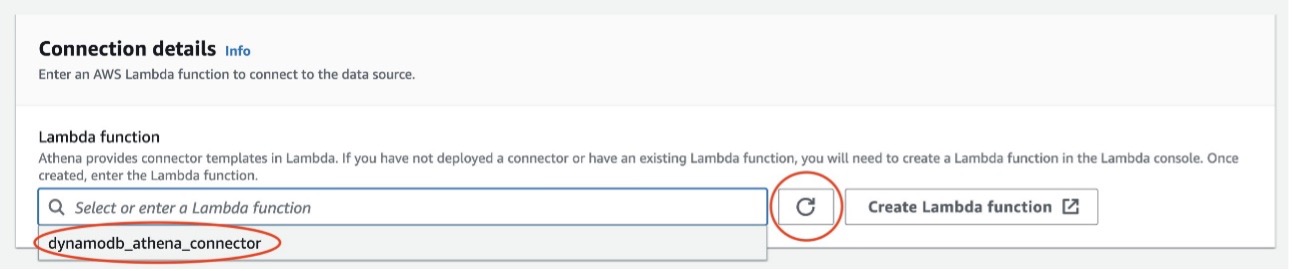
- Kies Volgende.
- Beoordeel en kies Maak een gegevensbron.
Bied aanvullende metadata aan via AWS Glue
De Athena-connector wordt al geleverd met een ingebouwde inferentiemogelijkheid om de schema- en tabeleigenschappen van uw gegevensbron te ontdekken. Deze mogelijkheid is echter beperkt. Om de metadata van uw DynamoDB-tabel nauwkeurig te ontdekken en het schemabeheer te centraliseren naarmate uw gegevens in de loop van de tijd evolueren, kan de connector worden geïntegreerd met AWS Glue.
Om dit te bereiken wordt een AWS Glue-crawler uitgevoerd om automatisch het formaat, het schema en de bijbehorende eigenschappen te bepalen van de onbewerkte gegevens die zijn opgeslagen in uw DynamoDB-tabel, en de resulterende metagegevens naar een Lijm-database. Glue-databases bevatten tafels, die metagegevens uit verschillende gegevensopslagplaatsen bevatten, onafhankelijk van de daadwerkelijke locatie van de gegevens. De Athena-connector verwijst vervolgens naar de Glue-tabel en haalt de bijbehorende DynamoDB-metagegevens op om query's mogelijk te maken.
Maak de AWS Glue-database
Voer de volgende stappen uit om de Glue-database te maken:
- Op de AWS Glue-console, onder Gegevenscatalogus in het navigatievenster, kies databases.
- Kies Voeg database toe (u kunt ook een bestaande database bewerken als u er al een heeft).
- Voor Naam, voer een databasenaam in.
- Voor Locatie, voer de tekenreeks letterlijk in
dynamo-db-flag. Dit trefwoord geeft aan dat de database tabellen bevat die de connector kan gebruiken voor aanvullende metagegevens. - Kies Maak een database.
Op basis van de best practices op het gebied van beveiliging wordt ook aanbevolen dat u encryptie in rust inschakelt voor uw gegevenscatalogus. Voor details, zie Uw gegevenscatalogus coderen.
Maak de AWS Glue-crawler
Voer de volgende stappen uit om de Glue-crawler te maken en uit te voeren:
- Op de AWS Glue-console, onder Gegevenscatalogus in het navigatievenster, kies crawlers.
- Kies Creëren van crawler.
- Voer een crawlernaam in en kies Volgende.
- Voor Data bronnen, kiezen Een gegevensbron toevoegen.
- Op de Databron vervolgkeuzemenu, kies DynamoDB. Voor Tafel naam, voer de naam in van uw DynamoDB-tabel (letterlijke tekenreeks).
- Kies Voeg een DynamoDB-gegevensbron toe.
- Kies Volgende.
- Voor IAM-rol, kiezen Nieuwe IAM-rol maken.
- Voer een rolnaam in en kies creëren. Hierdoor wordt automatisch een IAM-rol die AWS Glue vertrouwt en toestemming heeft om toegang te krijgen tot de crawlerdoelen.
- Kies Volgende.
- Voor Doeldatabase, kies de eerder gemaakte database.
- Kies Volgende.
- Beoordeel en kies Creëren van crawler.
- Kies op de nieuw gemaakte crawlerpagina Voer de crawler uit.
Crawlerruntimes zijn afhankelijk van de grootte en eigenschappen van uw DynamoDB-tabel. Details over de crawlerruns vindt u onder Crawler loopt.
Valideer de uitvoermetagegevens
Wanneer uw crawler-uitvoeringsstatus wordt weergegeven als Voltooid, volgt u de onderstaande stappen om de uitvoermetagegevens te valideren:
- Kies op de AWS Glue-console: Tafels in het navigatievenster. Hier kunt u bevestigen dat er een nieuwe tabel aan de database is toegevoegd als resultaat van de crawlerrun.
- Navigeer naar de nieuw gemaakte tabel en bekijk de Schema tabblad. Op dit tabblad worden de kolomnamen, gegevenstypen en andere parameters weergegeven die zijn afgeleid van uw DynamoDB-tabel.
- Bewerk indien nodig het schema door te kiezen Schema bewerken.
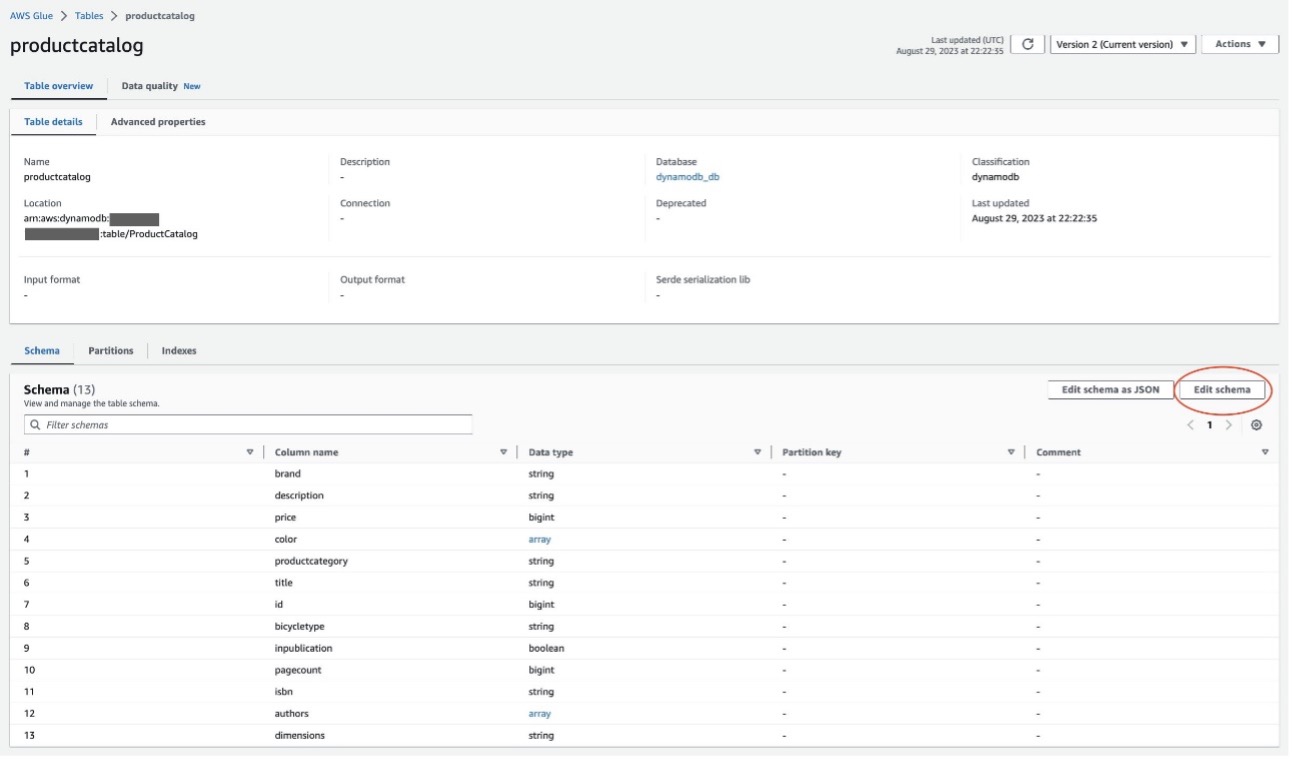
- Kies Geavanceerde eigenschappen.
- Onder Tabel eigenschappen, controleer of de crawler automatisch is gemaakt en stel de
classificationtoetsdynamodb. Dit geeft aan de Athena-connector aan dat de tabel kan worden gebruikt voor aanvullende metadata. - Voeg optioneel de volgende eigenschappen toe om DynamoDB-gegevens correct te catalogiseren en ernaar te verwijzen in AWS Glue- en Athena-query's. Dit komt doordat hoofdletters niet zijn toegestaan in AWS Glue-tabel- en kolomnamen, maar wel in DynamoDB-tabel- en attribuutnamen.
- Als uw DynamoDB-tabelnaam hoofdletters bevat, kiest u Acties en Tabel bewerken en voeg als volgt een extra tabeleigenschap toe:
- Sleutel:
sourceTable - Waarde:
YourDynamoDBTableName
- Sleutel:
- Als uw DynamoDB-tabel attributen heeft die hoofdletters bevatten, voegt u als volgt een extra tabeleigenschap toe:
- Sleutel:
columnMapping - Waarde:
yourcolumn1=YourColumn1,yourcolumn2=YourColumn2, autodashborden en meer
- Sleutel:
- Als uw DynamoDB-tabelnaam hoofdletters bevat, kiest u Acties en Tabel bewerken en voeg als volgt een extra tabeleigenschap toe:
Test de connector met de Athena SQL-editor
Nadat de Athena DynamoDB-connector is geïmplementeerd en de AWS Glue-tabel is gevuld met aanvullende metagegevens, is de DynamoDB-tabel klaar voor analyse. Het voorbeeld in dit bericht gebruikt de Athena-editor om SQL-query's uit te voeren naar het ProductCatalog tafel. Voor verdere opties voor interactie met Athena, zie Toegang tot Athene.
Voer de volgende stappen uit om de connector te testen:
- Open de Athena-query-editor.
- Als dit de eerste keer is dat u de Athena-console in uw huidige AWS-regio bezoekt, voert u de volgende stappen uit. Dit is een vereiste voordat u Athena-query's kunt uitvoeren. Zien Ermee beginnen voor meer details.
- Kies Query-editor in het navigatievenster om de editor te openen.
- Navigeer naar Instellingen En kies Beheren om een zoekresultaatlocatie in Amazon S3 in te stellen.
- Onder Data, selecteer de gegevensbron en database die u hebt gemaakt (mogelijk moet u het vernieuwingspictogram kiezen om ze te synchroniseren met Athena).
- Tabellen die bij de geselecteerde database horen, verschijnen onder Tafels. U kunt een tabelnaam kiezen voor Athena om de tabelkolomlijst en gegevenstypen weer te geven.
- Test de connector door gegevens uit uw tabel te halen via een SELECT-instructie. Wanneer u Athena-query's uitvoert, kunt u verwijzen naar Athena-gegevensbronnen, databases en tabellen als
<datasource_name>.<database>.<table_name>. Opgehaalde records worden weergegeven onder Resultaten.
Voor meer veiligheid, zie Versleuteling van Athena-queryresultaten opgeslagen in Amazon S3 om queryresultaten in rust te versleutelen.

Voor dit bericht voeren we een SELECT-instructie uit om het proces te valideren. U kunt verwijzen naar de SQL-referentie voor Athena om complexere queries en analyses te bouwen.
Visualiseer in QuickSight
Met QuickSight kunt u moderne interactieve dashboards, gepagineerde rapporten, ingebedde analyses en zoekopdrachten in natuurlijke taal bouwen via een uniforme BI-oplossing. In deze stap gebruiken we QuickSight om visuele inzichten te genereren uit de DynamoDB-tabel door verbinding te maken met de eerder gemaakte Athena-gegevensbron.
Geef QuickSight toegang tot bronnen
Voer de volgende stappen uit om QuickSight toegang tot bronnen te verlenen:
- Kies op de QuickSight-console het profielpictogram en kies Beheer QuickSight.
- Kies in het navigatievenster Beveiliging en machtigingen.
- Onder QuickSight-toegang tot AWS-services, kiezen Beheren.
- QuickSight kan u vragen om over te schakelen naar de regio waarin gebruikers en groepen in uw account worden beheerd. Om de huidige regio te wijzigen, navigeert u naar het profielpictogram op de QuickSight-console en kiest u de regio waarnaar u wilt overschakelen.
- Voor IAM-rol, kiezen Gebruik een door QuickSight beheerde rol (standaard).
Bij daaropvolgende instructies wordt ervan uitgegaan dat de standaard door QuickSight beheerde rol wordt gebruikt. Als dit niet het geval is, zorg er dan voor dat u de bestaande rol met hetzelfde effect bijwerkt.
- Onder Sta toegang en automatische detectie toe voor deze bronnenselecteer IAM en Amazon S3.
- Voor Amazon S3, kiezen Selecteer S3-bakken.
- Kies de spill-bucket die u eerder hebt opgegeven bij het implementeren van de Lambda-functie voor de connector en de bucket die u hebt opgegeven als de resultaatlocatie van de Athena-query in Amazon S3.
- Selecteer voor beide buckets Schrijftoestemming voor Athena Workgroup.
- Kies Amazone Athene.
- Kies in het pop-upvenster Volgende.
- Kies Lambda en kies de Amazon Resource Name (ARN) van de Lambda-functie die eerder werd gebruikt voor de Athena-gegevensbronconnector.
- Kies Finish.
- Kies Bespaar.
Maak de Athena-gegevensset
Voer de volgende stappen uit om de Athena-gegevensset te maken:
- Kies op de QuickSight-console het gebruikersprofiel en schakel over naar de regio waarin u de Athena-gegevensbron hebt geïmplementeerd.
- Keer terug naar de QuickSight-startpagina.
- Kies in het navigatievenster datasets.
- Kies Nieuwe dataset.
- Voor Een gegevensset makenselecteer Athene.
- Voor Naam gegevensbron, voer een naam in en kies Verbinding valideren.
- Wanneer de verbinding wordt weergegeven als Gevalideerd, kiezen Maak een gegevensbron.
- Onder Catalogus, Database en Tafels, selecteer de Athena-gegevensbron, de AWS Glue-database en de eerder gemaakte AWS Glue-tabel.
- Kies kies.
- Op de Voltooi het maken van datasets 4040 hand404040 details hand4040 hand 3 details hand40 hand40 hand details details details details hand 3 Importeer naar SPICE voor snellere analyses.
- Kies Visualiseer.
Voor meer informatie over QuickSight-querymodi, zie Gegevens importeren in SPICE en SQL gebruiken om gegevens aan te passen.
Bouw QuickSight-visualisaties
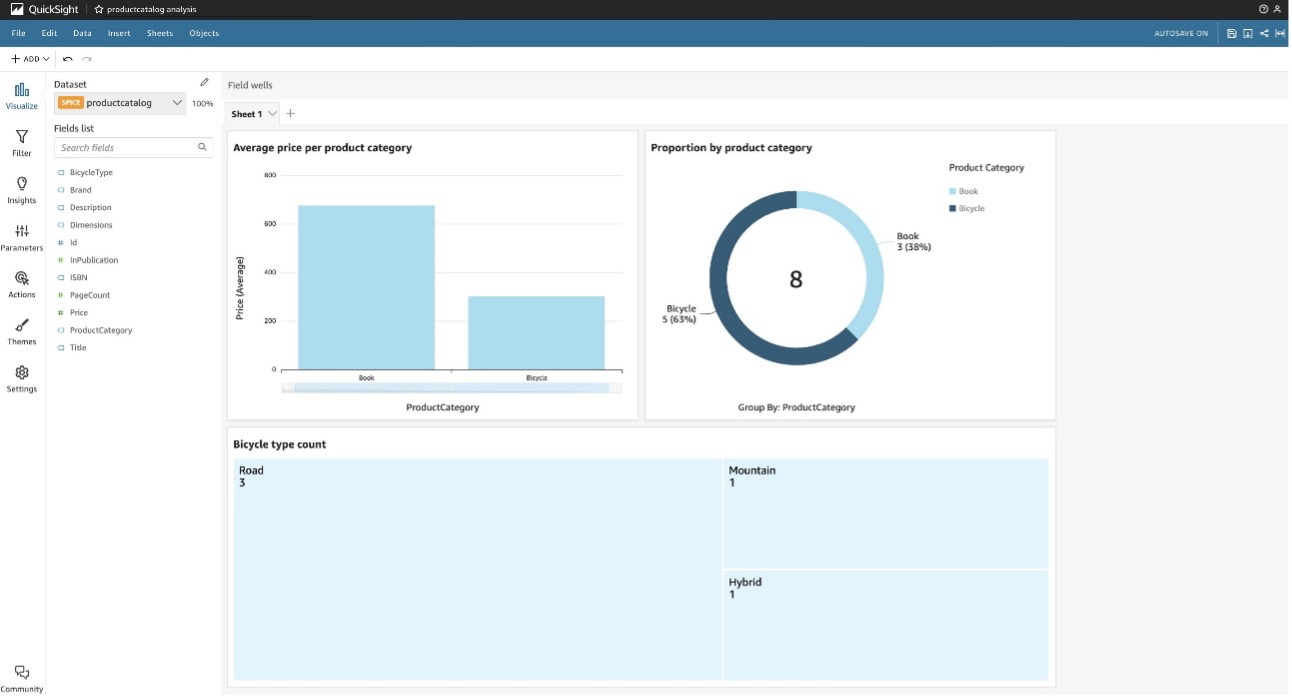
Zodra de DynamoDB-gegevens beschikbaar zijn in QuickSight via de Athena DynamoDB-connector, zijn deze klaar om te worden gevisualiseerd. De QuickSight-analyse in het onderstaande voorbeeld toont een verticaal gestapeld staafdiagram met de gemiddelde prijs per productcategorie voor de ProductCatalog voorbeeldgegevensset. Daarnaast toont het een ringdiagram met het aandeel producten per productcategorie, en een boomkaart met het aantal fietsen per fietstype.
Als u in SPICE geïmporteerde gegevens gebruikt in een QuickSight-analyse, is de gegevensset pas beschikbaar nadat het importeren is voltooid. Voor meer details, zie SPICE-gegevens gebruiken in een analyse.
Voor uitgebreide informatie over het maken en delen van visualisaties in QuickSight raadpleegt u Gegevens visualiseren in Amazon QuickSight en Gegevens delen en abonneren op Amazon QuickSight.
Opruimen
Om te voorkomen dat er voortdurend AWS-gebruikskosten in rekening worden gebracht, moet u ervoor zorgen dat u alle bronnen verwijdert die zijn gemaakt als onderdeel van deze walkthrough.
- Verwijder de Athena-gegevensbron:
- Schakel op de Athena-console over naar de regio waarin u uw grondstoffen heeft ingezet.
- Kies Data bronnen in het navigatievenster.
- Selecteer de gegevensbron die u hebt gemaakt en op de Acties menu, kies Verwijder.
- Verwijder de Lambda-applicatie:
- Schakel op de AWS CloudFormation-console over naar de regio waarin u uw bronnen heeft geïmplementeerd.
- Kies Stacks in het navigatievenster.
- kies
serverlessrepo-AthenaDynamoDBConnectorEn kies Verwijder.
- Verwijder de AWS Glue-bronnen:
- Schakel op de AWS Glue-console over naar de regio waarin u uw bronnen heeft ingezet.
- Kies databases in het navigatievenster.
- Selecteer de database die u hebt gemaakt en kies Verwijder.
- Kies crawlers in het navigatievenster.
- Selecteer de crawler die u heeft gemaakt en op de Actie menu, kies Crawler verwijderen.
- Verwijder de QuickSight-bronnen:
- Schakel op de QuickSight-console over naar de regio waarin u uw bronnen heeft ingezet.
- Verwijder de analyse gemaakt voor deze walkthrough.
- Verwijder de Athena-gegevensset gemaakt voor deze walkthrough.
- Als u de Athena-gegevensbron niet langer nodig heeft om andere gegevenssets te maken, verwijder de gegevensbron.
Samengevat
Dit bericht demonstreerde hoe u de Athena DynamoDB-connector kunt gebruiken om gegevens in DynamoDB op te vragen met SQL en visualisaties te bouwen in QuickSight.
Lees meer over de Athena DynamoDB-connector in de Amazon Athena-gebruikershandleiding. Ontdekken meer beschikbare gegevensbronconnectoren om een verscheidenheid aan gegevensbronnen te bevragen en te visualiseren zonder een infrastructuur op te zetten of te beheren, terwijl u alleen betaalt voor de zoekopdrachten die u uitvoert.
Voor geavanceerde QuickSight-mogelijkheden, mogelijk gemaakt door AI, zie Inzicht verkrijgen met machine learning (ML) in Amazon QuickSight en Zakelijke vragen beantwoorden met Amazon QuickSight Q.
Over de auteurs
 Antonio Samaniego Jurado is oplossingsarchitect bij Amazon Web Services. Met een sterke passie voor moderne technologie helpt Antonio klanten bij het bouwen van state-of-the-art applicaties op AWS. Hij is een maker in hart en nieren en houdt van community-gedreven leren en het delen van best practices binnen het AWS-serviceportfolio om het beste uit de cloud van klanten te halen.
Antonio Samaniego Jurado is oplossingsarchitect bij Amazon Web Services. Met een sterke passie voor moderne technologie helpt Antonio klanten bij het bouwen van state-of-the-art applicaties op AWS. Hij is een maker in hart en nieren en houdt van community-gedreven leren en het delen van best practices binnen het AWS-serviceportfolio om het beste uit de cloud van klanten te halen.
 Pascal Vogel is oplossingsarchitect bij Amazon Web Services. Pascal helpt startups en ondernemingen bij het bouwen van cloud-native oplossingen. Als cloudliefhebber houdt Pascal ervan om nieuwe technologieën te leren en contact te maken met gelijkgestemde klanten die een verschil willen maken in hun cloudreis.
Pascal Vogel is oplossingsarchitect bij Amazon Web Services. Pascal helpt startups en ondernemingen bij het bouwen van cloud-native oplossingen. Als cloudliefhebber houdt Pascal ervan om nieuwe technologieën te leren en contact te maken met gelijkgestemde klanten die een verschil willen maken in hun cloudreis.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/visualize-amazon-dynamodb-insights-in-amazon-quicksight-using-the-amazon-athena-dynamodb-connector-and-aws-glue/

