Introductie
In een wereld die wordt overspoeld met informatie is het efficiënt verkrijgen en extraheren van relevante gegevens van onschatbare waarde. ResearchBot is een geavanceerd LLM-aangedreven applicatieproject dat gebruik maakt van de mogelijkheden van OpenAI's LLM (Grote taalmodellen) met Langchain voor het ophalen van informatie. Dit artikel is een soort stapsgewijze handleiding voor het maken van uw eigen ResearchBot en hoe deze in het echte leven nuttig kan zijn. Het is alsof u een intelligente assistent heeft die uit een zee van gegevens de informatie vindt die u nodig heeft. Of u nu van coderen houdt of geïnteresseerd bent in AI, deze gids is er om u te helpen uw onderzoek te versterken met een op maat gemaakte LLM-aangedreven AI-assistent. Het is jouw reis om het potentieel van LLM's te ontsluiten en een revolutie teweeg te brengen in de manier waarop je toegang krijgt tot informatie.

leerdoelen
- Begrijp de meer diepgaande concepten van LLM's (grote taalmodellen), Langchain, vectordatabase en insluitingen.
- Ontdek real-world toepassingen van LLM's en ResearchBot op gebieden als onderzoek, klantenondersteuning en het genereren van inhoud.
- Ontdek best practices voor het integreren van ResearchBot in bestaande projecten of workflows, waardoor de productiviteit en besluitvorming worden verbeterd.
- Bouw ResearchBot om het proces van gegevensextractie en het beantwoorden van vragen te stroomlijnen.
- Blijf op de hoogte van de trends in LLM-technologie en het potentieel ervan om een revolutie teweeg te brengen in de manier waarop we toegang krijgen tot deze informatie en deze gebruiken.
Dit artikel is gepubliceerd als onderdeel van het Data Science-blogathon.
Inhoudsopgave
Wat is ResearchBot?
ResearchBot is een onderzoeksassistent, mogelijk gemaakt door LLM's. Het is een innovatieve tool die inhoud snel kan openen en samenvatten, waardoor het een geweldige partner is voor professionals in verschillende sectoren.
Stel je voor dat je een persoonlijke assistent hebt die meerdere artikelen, documenten en websitepagina's kan lezen en begrijpen en je kan voorzien van relevante en korte samenvattingen. Ons doel van de ResearchBot is om de tijd en moeite die nodig is voor uw onderzoeksdoeleinden te verminderen.
Gebruiksscenario's uit de echte wereld
- Financiële analyse: Blijf op de hoogte van het laatste marktnieuws en ontvang snel antwoord op financiële vragen.
- Journalistiek: Verzamel efficiënt achtergrondinformatie, bronnen en referenties voor artikelen.
- Gezondheidszorg: Toegang tot actuele medische onderzoeksdocumenten en samenvattingen voor onderzoeksdoeleinden.
- academici: Vind relevante academische artikelen, onderzoeksmateriaal en antwoorden op onderzoeksvragen.
- Juridisch onderzoek: Haal snel juridische documenten, uitspraken en inzichten over juridische kwesties op.
Technische terminologie
Vector-database
Een container voor het opslaan van vectorinbedding van tekstgegevens is cruciaal voor efficiënte, op overeenkomsten gebaseerde zoekopdrachten.
Semantisch zoeken
Inzicht in de intentie en context van gebruikersquery's om zoekopdrachten uit te voeren zonder volledig afhankelijk te zijn van perfecte trefwoordmatching.
Inbedding
Een numerieke weergave van tekstgegevens die efficiënt vergelijken en zoeken mogelijk maakt.
Technische architectuur van het project
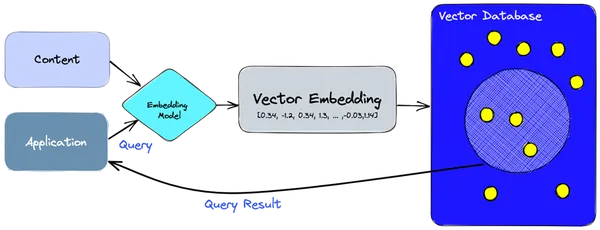
- We gebruiken het insluitingsmodel om vectorinsluitingen te maken voor de informatie of inhoud die we moeten indexeren.
- De vectorinsluiting wordt in de vectordatabase ingevoegd, met enige verwijzing naar de originele inhoud waaruit de insluiting is gemaakt.
- Wanneer de applicatie een query uitvoert, gebruiken we hetzelfde inbeddingsmodel om inbedding voor de query te maken, en gebruiken we die inbedding om de database te doorzoeken op vergelijkbare vectorinbedding.
- Deze vergelijkbare insluitingen zijn gekoppeld aan de originele inhoud die is gebruikt om ze te maken.
Hoe werkt de ResearchBot?
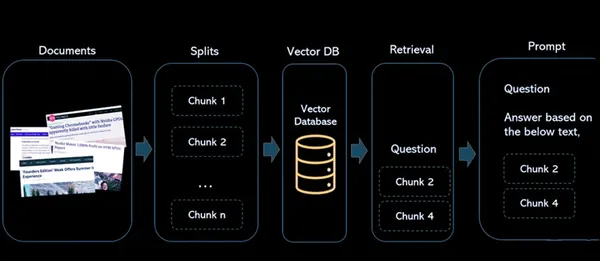
Deze architectuur vergemakkelijkt de opslag, het ophalen en de interactie met inhoud, waardoor onze ResearchBot een krachtig hulpmiddel is voor het ophalen en analyseren van informatie. Het maakt gebruik van vectorinbedding en een vectordatabase om snelle en nauwkeurige zoekopdrachten naar inhoud mogelijk te maken.
COMPONENTEN
- Documenten: Dit zijn de artikelen of inhoud die u wilt indexeren zodat u deze in de toekomst kunt raadplegen en terugvinden.
- Splitst: Dit regelt het proces waarbij de documenten in kleinere, beheersbare brokken worden opgedeeld. Dit is belangrijk voor het werken met grote documenten of artikelen, zodat ze perfect passen binnen de beperkingen van het taalmodel en voor efficiënte indexering.
- Vectordatabase: De vectordatabase is een cruciaal onderdeel van de architectuur. Het slaat de vectorinsluitingen op die op basis van de inhoud zijn gegenereerd. Elke vector wordt geassocieerd met de originele inhoud waarvan hij is afgeleid, waardoor een link ontstaat tussen de numerieke representatie en het bronmateriaal.
- ophalen: Wanneer een gebruiker een query uitvoert op het systeem, wordt hetzelfde inbeddingsmodel gebruikt om inbedding voor de query te maken. Deze zoekinbeddingen worden vervolgens gebruikt om in de vectordatabase te zoeken naar vergelijkbare vectorinbeddingen. Het resultaat is een grote groep vergelijkbare vectoren, elk geassocieerd met de oorspronkelijke inhoudsbron.
- prompt: Er wordt gedefinieerd waar de gebruiker met het systeem communiceert. Gebruikers voeren zoekopdrachten in en het systeem verwerkt deze zoekopdrachten om relevante informatie uit de vectordatabase op te halen en antwoorden en verwijzingen naar de broninhoud te bieden.
Documentladers in LangChain
Gebruik documentladers om gegevens uit een bron in de vorm van een document te laden. Een document is een stuk tekst en bijbehorende metadata. Er zijn bijvoorbeeld documentladers voor het laden van een eenvoudig .txt-bestand, voor het laden van de tekstinhoud van artikelen of blogs, of zelfs voor het laden van een transcriptie van een YouTube-video.
Er zijn veel soorten documentladers:
| Lader | Gebruik |
|---|---|
| Tekstlader | Laadt platte tekstdocumenten voor verwerking. |
| CSVLoader | Importeert gegevens uit CSV-bestanden. |
| DirectoryLoader | Leest en laadt inhoud uit mappen. |
| OngestructureerdeHTMLLoader | Haalt en verwerkt ongestructureerde HTML-inhoud op. |
| JSONLoader | Laadt gegevens uit JSON-bestanden. |
| OngestructureerdeMarkdownLoader | Verwerkt en laadt ongestructureerde Markdown-inhoud. |
| PyPDFLoader | Extraheert tekstinhoud uit PDF-bestanden voor verdere verwerking. |
Voorbeeld – TextLoader
Deze code toont de functionaliteit van een TextLoader uit de Langchain. Het laadt tekstgegevens uit het bestaande bestand, “Langchain.txt”, in de klasse TextLoader, waardoor het klaar wordt gemaakt voor verdere verwerking. De variabele 'file_path' slaat het pad op naar het bestand dat wordt geladen voor toekomstige doeleinden.
# Import the TextLoader class from the langchain.document_loaders module
from langchain.document_loaders import TextLoader # consider the TextLoader class by mentioning the file to load, Here "Langchain.txt"
loader = TextLoader("Langchain.txt") # Load the content from provided file ("Langchain.txt") into the TextLoader class
loader.load() # Check the type of the 'loader' instance, which should be 'TextLoader'
type(loader) # The file path associated with the TextLoader in the 'file_path' variable
loader.file_path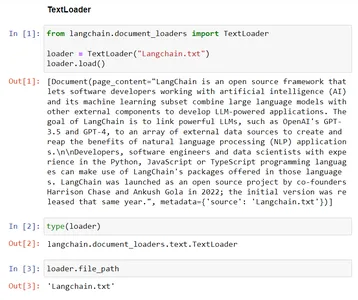
Tekstsplitters in LangChain
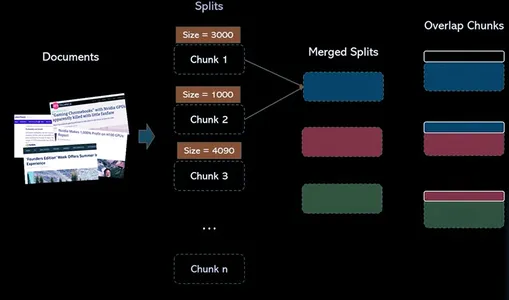
Tekstsplitters zijn verantwoordelijk voor het opsplitsen van een document in kleinere documenten. Deze kleinere eenheden maken het gemakkelijker om met de inhoud te werken en deze efficiënt te verwerken. In de context van ons ResearchBot-project gebruiken we tekstsplitters om de gegevens voor te bereiden voor verdere analyse en opvraging.
Waarom hebben we tekstsplitters nodig?
LLM's hebben tokenlimieten. Daarom moeten we de tekst, die groot kan zijn, in kleine stukjes splitsen, zodat elke stukgrootte onder de tokenlimiet valt.
Handmatige aanpak waarbij de tekst in stukjes wordt gesplitst
# Taking some random text from wikipedia
text # Say LLM token limit is 100, in our code we can do simple thing such as this text[:100]

Nou, maar we willen volledige woorden en willen dit voor de hele tekst doen. Misschien kunnen we de splitsfunctie van Python gebruiken
words = text.split(" ")
len(words) chunks = [] s = ""
for word in words: s += word + " " if len(s)>200: chunks.append(s) s = "" chunks.append(s) chunks[:2]
Het opsplitsen van gegevens in stukjes kan in native Python worden gedaan, maar het is een tijdrovend proces. Indien nodig moet u mogelijk ook op een opeenvolgende manier met de meerdere scheidingstekens experimenteren om ervoor te zorgen dat elk deel de tokenlengtelimiet van de betreffende LLM niet overschrijdt.
Langchain biedt een betere manier om tekstsplitterklassen te doorlopen. Er zijn meerdere tekstsplitterklassen in langchain waarmee we dit kunnen doen.
1. Tekentekstsplitter
Deze klasse is ontworpen om tekst in kleinere stukken te splitsen op basis van specifieke scheidingstekens. Zoals alinea's, punten, komma's en regeleinden(n). Het is handiger om tekst op te splitsen in een mix van stukjes voor verdere verwerking.
from langchain.text_splitter import CharacterTextSplitter splitter = CharacterTextSplitter( separator = "n", chunk_size=200, chunk_overlap=0
) chunks = splitter.split_text(text)
len(chunks) for chunk in chunks: print(len(chunk))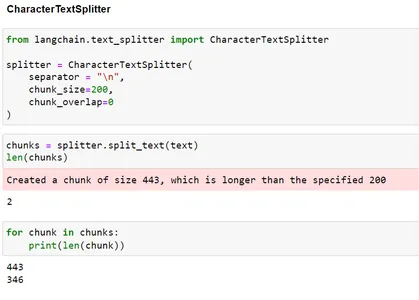
Zoals je kunt zien, hebben we, hoewel we een chunkgrootte van 200 hebben opgegeven, omdat de splitsing gebaseerd was op n, uiteindelijk chunks gecreëerd die groter zijn dan maat 200.
Een andere klasse van Langchain kan worden gebruikt om de tekst recursief te splitsen op basis van een lijst met scheidingstekens. Deze klasse is RecursiveTextSplitter. Laten we kijken hoe het werkt.
2. Recursieve tekstsplitter
Dit is een soort tekstsplitter die werkt door tekens in een tekst recursief te analyseren. Het probeert de tekst op te splitsen in verschillende karakters, iteratief verschillende karaktercombinaties te vinden totdat het een splitsingsaanpak identificeert die de tekst en verschillende soorten shells effectief verdeelt.
from langchain.text_splitter import RecursiveCharacterTextSplitter r_splitter = RecursiveCharacterTextSplitter( separators = ["nn", "n", " "], # List of separators chunk_size = 200, # size of each chunk created chunk_overlap = 0, # size of overlap between chunks length_function = len # Function to calculate size,
) chunks = r_splitter.split_text(text) for chunk in chunks: print(len(chunk)) first_split = text.split("nn")[0]
first_split
len(first_split) second_split = first_split.split("n")
second_split
for split in second_split: print(len(split)) second_split[2]
second_split[2].split(" ")
Laten we begrijpen hoe we deze brokken hebben gevormd:
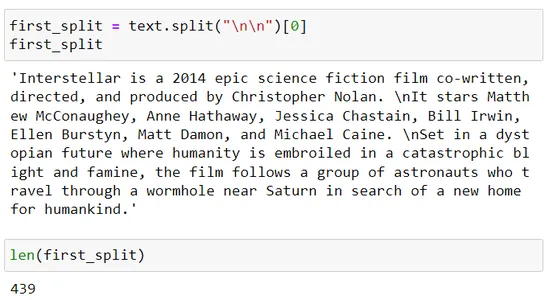
Recursieve tekstsplitter gebruikt een lijst met scheidingstekens, dwz scheidingstekens = [“nn”, “n”, “.”]
Dus nu zal het eerst splitsen met behulp van nn en als de resulterende chunkgrootte groter is dan de chunk_size parameter, die in deze scène 200 is, dan zal het het volgende scheidingsteken gebruiken, namelijk n.
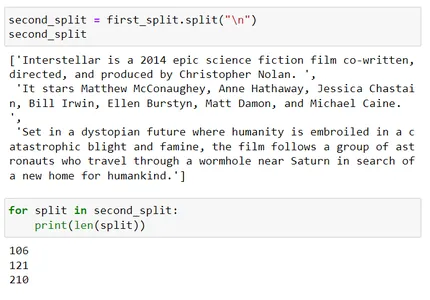
De derde splitsing overschrijdt de chunkgrootte 200. Nu zal het verder proberen dat te splitsen met behulp van het derde scheidingsteken dat ' ' (spatie) is.
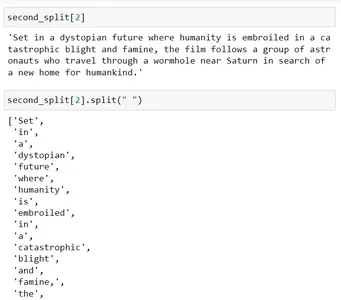
Wanneer je dit splitst met behulp van een spatie (dat wil zeggen second_split[2].split(” “)), wordt elk woord gescheiden en vervolgens worden die stukjes samengevoegd zodat hun grootte bijna 200 is.
Vector-database
Overweeg nu een scenario waarin u miljoenen of zelfs miljarden woordinsluitingen moet opslaan; dit zou de belangrijke scène zijn in een echte toepassing. Relationele databases zijn weliswaar in staat om gestructureerde gegevens op te slaan, maar zijn mogelijk niet geschikt vanwege hun beperkingen bij het verwerken van zulke grotere hoeveelheden gegevens.
Dit is waar vectordatabases een rol gaan spelen. Een vectordatabase is ontworpen om vectorgegevens efficiënt op te slaan en op te halen, waardoor deze geschikt is voor het insluiten van woorden.
Vectordatabases zorgen voor een revolutie in het ophalen van informatie door gebruik te maken van semantisch zoeken. Ze maken gebruik van de kracht van woordinsluitingen en slimme indexeringstechnieken om zoekopdrachten sneller en nauwkeuriger te maken.
Wat is het verschil tussen een vectorindex en een vectordatabase?
Op zichzelf staande vectorindexen zoals FAISS (Facebook AI Likenity Search) kan het zoeken en ophalen van vectorinsluitingen verbeteren, maar ze missen de mogelijkheden die wel bestaan in een van de db(database). Vectordatabases zijn daarentegen speciaal gebouwd om vectorinbedding te beheren, waardoor ze meerdere voordelen bieden ten opzichte van het gebruik van op zichzelf staande vectorindexen.
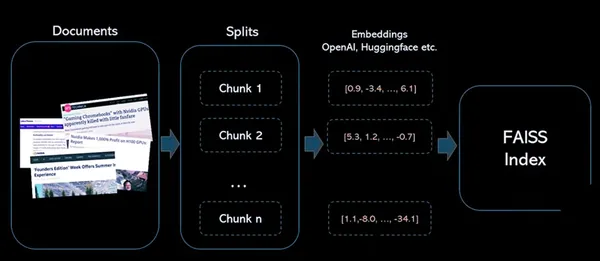
Stappen:
1: Maak broninsluitingen voor de tekstkolom
2: Bouw een FAISS-index voor vectoren
3: Normaliseer de bronvectoren en voeg ze toe aan de index
4: Codeer de zoektekst met dezelfde encoder en normaliseer de uitvoervector
5: Zoek naar vergelijkbare vectoren in de gemaakte FAISS-index
df = pd.read_csv("sample_text.csv")
df # Step 1 : Create source embeddings for the text column
from sentence_transformers import SentenceTransformer
encoder = SentenceTransformer("all-mpnet-base-v2")
vectors = encoder.encode(df.text)
vectors # Step 2 : Build a FAISS Index for vectors
import faiss
index = faiss.IndexFlatL2(dim) # Step 3 : Normalize the source vectors and add to index
index.add(vectors)
index # Step 4 : Encode search text using same encoder
search_query = "looking for places to visit during the holidays"
vec = encoder.encode(search_query)
vec.shape
svec = np.array(vec).reshape(1,-1)
svec.shape # Step 5: Search for similar vector in the FAISS index
distances, I = index.search(svec, k=2)
distances
row_indices = I.tolist()[0]
row_indices
df.loc[row_indices]Als we deze dataset bekijken,
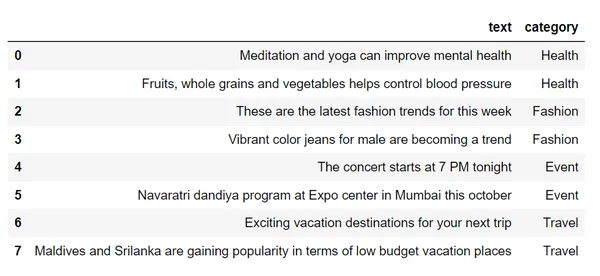
we zullen deze tekst omzetten in vectoren met behulp van woordinsluitingen
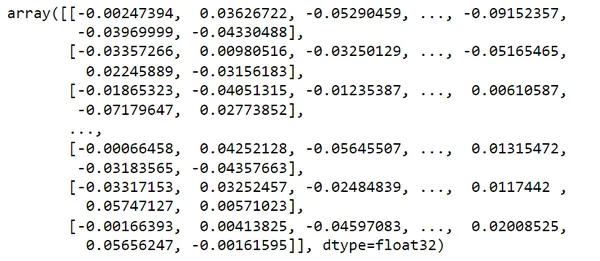
Gezien mijn search_query = “op zoek naar plaatsen om te bezoeken tijdens de vakantie”

Het levert de twee meest vergelijkbare resultaten op die verband houden met mijn zoekopdracht met behulp van semantisch zoeken in de reiscategorie.
Wanneer u een zoekopdracht uitvoert, gebruikt de database technieken zoals Locality-Sensitive Hashing (LSH) om het proces te versnellen. LSH groepeert vergelijkbare vectoren in buckets, waardoor sneller en gerichter kan worden gezocht. Dit betekent dat u uw queryvector niet met elke opgeslagen vector hoeft te vergelijken.
Ophalen
Wanneer een gebruiker een query uitvoert op het systeem, wordt hetzelfde inbeddingsmodel gebruikt om inbedding voor de query te maken. Deze zoekinbeddingen worden vervolgens gebruikt om in de vectordatabase te zoeken naar vergelijkbare vectorinbeddingen. Het resultaat is een groep vergelijkbare vectoren, elk geassocieerd met de oorspronkelijke inhoudsbron.
Uitdagingen bij het ophalen
Het ophalen bij semantisch zoeken brengt verschillende uitdagingen aan het licht, zoals de tokenlimiet die wordt opgelegd door taalmodellen zoals GPT-3. bij het omgaan met meerdere relevante gegevensbrokken vindt overschrijding van de responslimiet plaats.
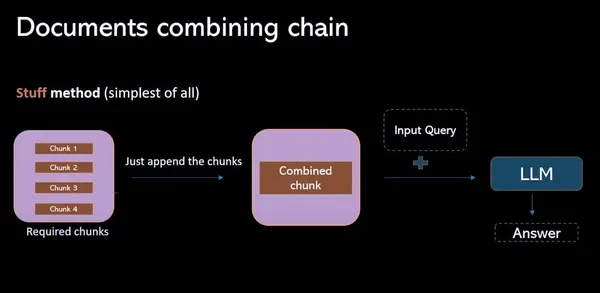
Stuff-methode
In dit model gaat het om het verzamelen van alle relevante gegevensbrokken uit de vectordatabase en deze te combineren tot een prompt (individueel). Het grootste nadeel van dit proces is dat de tokenlimiet wordt overschreden, waardoor onvolledige antwoorden ontstaan.
Kaartreductiemethode
Om de uitdaging van de tokenlimiet te overwinnen en het QA-proces voor het ophalen te stroomlijnen, biedt dit proces een oplossing die in plaats van relevante brokken te combineren in een prompt (individueel), als er vier brokken zijn. Ga allemaal door discrete geïsoleerde LLM's. Deze vragen bieden contextuele informatie waarmee het taalmodel zich afzonderlijk op de inhoud van elk deel kan concentreren. Dit resulteert in een reeks afzonderlijke antwoorden voor elk deel. Ten slotte wordt er een laatste LLM-oproep gedaan om al deze solo-antwoorden te combineren om het beste antwoord te vinden op basis van de inzichten die uit elk deel zijn verzameld.
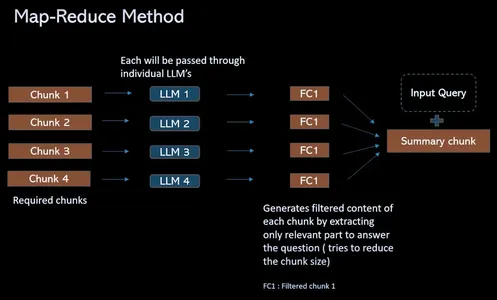
Werkstroom van ResearchBot
(1) Gegevens laden
In deze stap worden gegevens, zoals tekst of documenten, geïmporteerd en klaar voor verdere verwerking, zodat deze beschikbaar zijn voor analyse.
#provide urls to scrape the data loaders = UnstructuredURLLoader(urls=[ "", ""
])
data = loaders.load() len(data)(2) Gegevens splitsen om segmenten te maken
De gegevens zijn opgedeeld in kleinere, beter beheersbare secties of brokken, waardoor een efficiënte verwerking en verwerking van grote tekst of documenten mogelijk wordt.
text_splitter = RecursiveCharacterTextSplitter( chunk_size=1000, chunk_overlap=200
) # use split_documents over split_text in order to get the chunks.
docs = text_splitter.split_documents(data)
len(docs)
docs[0](3) Maak insluitingen voor deze chunks en sla ze op in de FAISS-index
De tekstfragmenten worden omgezet in numerieke vectorrepresentaties (inbedding) en opgeslagen in een Faiss-index, waardoor het ophalen van vergelijkbare vectoren wordt geoptimaliseerd.
# Create the embeddings of the chunks using openAIEmbeddings
embeddings = OpenAIEmbeddings() # Pass the documents and embeddings inorder to create FAISS vector index
vectorindex_openai = FAISS.from_documents(docs, embeddings) # Storing vector index create in local
file_path="vector_index.pkl"
with open(file_path, "wb") as f: pickle.dump(vectorindex_openai, f) if os.path.exists(file_path): with open(file_path, "rb") as f: vectorIndex = pickle.load(f)(4) Haal vergelijkbare inbedding op voor een bepaalde vraag en bel LLM om het definitieve antwoord op te halen
Voor een bepaalde zoekopdracht halen we vergelijkbare insluitingen op en gebruiken we deze vectoren om te communiceren met een taalmodel (LLM) om het ophalen van informatie te stroomlijnen en het definitieve antwoord op de vraag van de gebruiker te geven.
# Initialise LLM with the necessary parameters
llm = OpenAI(temperature=0.9, max_tokens=500) chain = RetrievalQAWithSourcesChain.from_llm( llm=llm, retriever=vectorIndex.as_retriever()
)
chain query = "" #ask your query langchain.debug=True chain({"question": query}, return_only_outputs=True)Laatste aanvraag
Na al deze fasen te hebben gebruikt (Document Loader, Text Splitter, Vector DB, Retrieval, Prompt) en een applicatie te bouwen met behulp van streamlit. We hebben het bouwen van onze ResearchBot voltooid.
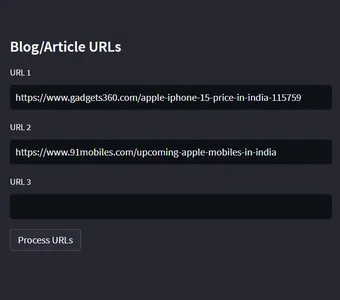
Dit is een gedeelte op de pagina, waar de url's van blogs of artikelen in worden ingevoegd. Ik gaf de links van de nieuwste iPhone-mobiele telefoons die in 2023 zijn uitgebracht. Voordat we beginnen met het bouwen van deze applicatie ResearchBot, zal iedereen een vraag hebben: we hebben de ChatGPT al, waarom bouwen we deze ResearchBot dan. Hier is het antwoord:
ChatGPT's antwoord:

ResearchBot's antwoord:
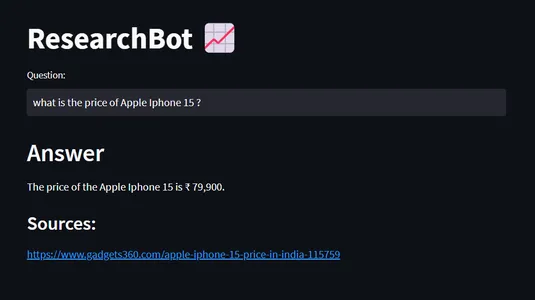
Hier is mijn vraag “Wat is de prijs van Apple Iphone 15?”
Deze gegevens zijn uit 2023 en deze gegevens zijn niet beschikbaar met de ChatGPT 3.5, maar we hebben onze ResearchBot getraind met de nieuwste informatie over Iphone's. Dus we kregen ons vereiste antwoord van onze ResearchBot.
Dit zijn de 3 problemen bij het gebruik van ChatGPT:
- Kopiëren en plakken van de artikelinhoud is een vervelende klus.
- We hebben een geaggregeerde kennisbank nodig.
- Woordlimiet – 3000 woorden
Conclusie
We zijn getuige geweest van de concepten van semantisch zoeken en vectordatabases in het echte wereldscenario. Het vermogen van onze ResearchBot om efficiënt antwoorden op te halen uit een vectordatabase met behulp van Semantic Search, laat ResearchBot het enorme potentieel zien voor diepgaande LLM's (adv) op het gebied van het ophalen van informatie en systemen voor het beantwoorden van vragen. We hebben een veelgevraagde tool gemaakt waarmee u gemakkelijk belangrijke informatie kunt vinden en samenvatten met hoge mogelijkheden en zoekfuncties. Het is een krachtige oplossing voor mensen die op zoek zijn naar kennis. Deze technologie opent nieuwe horizonten voor systemen voor het ophalen van informatie en het beantwoorden van vragen, waardoor het een game-changer wordt voor iedereen die op zoek is naar datagestuurde inzichten.
Veelgestelde Vragen / FAQ
A. Het is de ruggengraat van moderne semantische zoekmachines. Vectordatabases zijn gespecialiseerde databases die zijn ontworpen om hoogdimensionale vectorgegevens te verwerken. Ze bieden efficiënte manieren om hoogdimensionale gegevens op te slaan en te doorzoeken, zoals vectoren die teksten of andere typen vertegenwoordigen, afhankelijk van de complexiteit en granulariteit van de gegevens.
A. Een semantische zoekmachine kan de betekenis van een woord beter interpreteren. Het kan de intentie van de zoekopdracht beter begrijpen en kan zoekresultaten genereren die relevanter zijn voor de zoeker dan wat een traditionele zoekmachine kan laten zien.
A. FAISS is zelf geen vectordatabase, maar een vectorzoekbibliotheek. Het is een vectorzoekbibliotheek en een zelfstandige bibliotheek die wordt gebruikt om vectorovereenkomsten te zoeken. Enkele populaire voorbeelden zijn FAISS, HNSW en Annoy.
A. Een groot taalmodel (LLM) is een type algoritme voor kunstmatige intelligentie (AI) dat deep learning-technieken en enorm grote datasets gebruikt om nieuwe inhoud te begrijpen, samen te vatten, te genereren en te voorspellen. Deze chatbots beschikken over veel vaardigheden op het gebied van het begrijpen van natuurlijke taal en conversatie.
De in dit artikel getoonde media zijn geen eigendom van Analytics Vidhya en worden naar goeddunken van de auteur gebruikt.
Verwant
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.analyticsvidhya.com/blog/2023/10/empower-your-research-with-a-tailored-llm-powered-ai-assistant/

