Gesponsorde content
Door Jim Dowling, medeoprichter en CEO van Hopsworks
In dit artikel wordt een uniform architectonisch patroon geïntroduceerd voor het bouwen van zowel batch- als realtime machine learning-systemen (ML). We noemen dit de FTI-pijplijnarchitectuur (Feature, Training, Inference). FTI-pijpleidingen doorbreken het monolithische ML-pijplijn in 3 onafhankelijke pijpleidingen, elk met duidelijk gedefinieerde inputs en outputs, waarbij elke pijpleiding onafhankelijk kan worden ontwikkeld, getest en geëxploiteerd. Voor een historisch perspectief op de evolutie van de FTI Pipeline-architectuur kunt u het volledige boek lezen diepgaande mentale kaart voor MLOps artikel.
De afgelopen jaren heeft Machine Learning Operations (MLops) heeft populariteit verworven als een ontwikkelingsproces, geïnspireerd door de DevOps-principes, dat geautomatiseerd testen, versiebeheer van ML-middelen en operationele monitoring introduceert om ML-systemen stapsgewijs ontwikkeld en ingezet worden. De bestaande MLOps-benaderingen bieden echter vaak een complex en overweldigend landschap, waardoor veel teams moeite hebben om het pad van modelontwikkeling naar productie te navigeren. In dit artikel introduceren we een frisse kijk op het bouwen van ML-systemen via het concept van FTI-pijpleidingen. De FTI-architectuur heeft talloze ontwikkelaars in staat gesteld om met gemak robuuste ML-systemen te creëren, de cognitieve belasting te verminderen en een betere samenwerking tussen teams te bevorderen. We verdiepen ons in de kernprincipes van FTI-pijplijnen en verkennen hun toepassingen in zowel batch- als realtime ML-systemen.
De FTI-aanpak voor dit architectuurpatroon is gebruikt om honderden ML-systemen te bouwen. Het patroon is als volgt: een ML-systeem bestaat uit drie onafhankelijk ontwikkelde en beheerde ML-pijpleidingen:
- een functiepijplijn die als invoer ruwe gegevens gebruikt die worden omgezet in functies (en labels)
- een trainingspijplijn die als invoerfuncties (en labels) een getraind model gebruikt en uitvoert, en
- een inferentiepijplijn die nieuwe functiegegevens en een getraind model gebruikt en voorspellingen doet.
In deze FTI is er geen enkele ML-pijplijn. De verwarring over wat de ML-pijplijn doet (bestaat deze uit ingenieurs- en treinmodellen of doet deze ook gevolgtrekkingen of slechts één daarvan?) verdwijnt. De FTI-architectuur is van toepassing op zowel batch-ML-systemen als realtime ML-systemen.

Figuur 1: De Feature/Training/Inference (FTI)-pijplijnen voor het bouwen van ML-systemen
De functiepijplijn kan een batchprogramma of een streamingprogramma zijn. De trainingspijplijn kan alles opleveren, van een eenvoudig XGBoost-model tot een parameter-efficiënt verfijnd (PEFT) groottaalmodel (LLM), getraind op veel GPU's. Ten slotte kan de inferentiepijplijn een batchprogramma zijn dat een batch voorspellingen produceert voor een online service die verzoeken van klanten aanneemt en in realtime voorspellingen retourneert.
Een groot voordeel van FTI-pijplijnen is dat het een open architectuur is. Je kunt Python, Java of SQL gebruiken. Als u feature-engineering moet uitvoeren op grote hoeveelheden gegevens, kunt u Spark, DBT of Beam gebruiken. De training vindt doorgaans plaats in Python met behulp van een ML-framework, en batch-inferentie kan in Python of Spark plaatsvinden, afhankelijk van uw gegevensvolumes. Online-inferentiepijplijnen bevinden zich echter bijna altijd in Python, omdat modellen doorgaans met Python trainen.
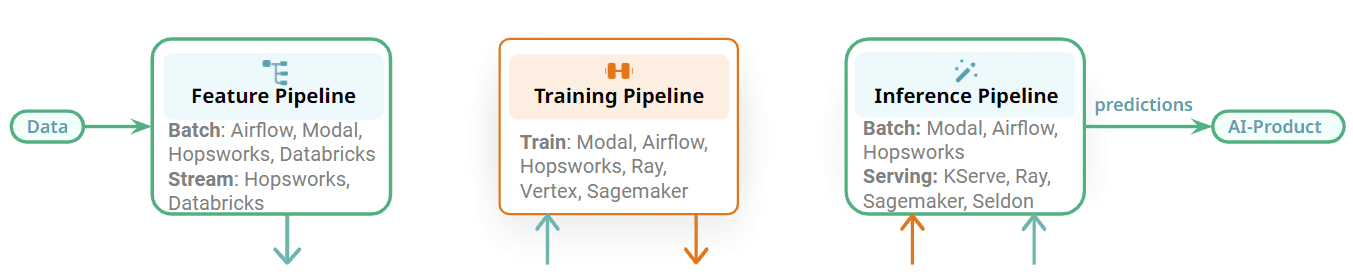
Figuur 2: Kies de beste Orchestrator voor uw ML-pijplijn/service.
Ook de FTI-pijpleidingen zijn modulair en er is een duidelijke interface tussen de verschillende fasen. Elke FTI-pijpleiding kan onafhankelijk worden geëxploiteerd. Vergeleken met de monolithische ML-pijplijnkunnen nu verschillende teams verantwoordelijk zijn voor de ontwikkeling en exploitatie van elke pijpleiding. De impact hiervan is dat voor orkestratie bijvoorbeeld één team één orkestrator kan gebruiken voor een functiepijplijn en een ander team een andere orkestrator kan gebruiken voor de batch-inferentiepijplijn. U kunt ook dezelfde Orchestrator gebruiken voor de drie verschillende FTI-pijplijnen voor een batch-ML-systeem. Enkele voorbeelden van Orchestrators die in ML-systemen kunnen worden gebruikt, zijn Orchestrators met veel functies voor algemene doeleinden, zoals Airflow, of lichtgewicht Orchestrators, zoals Modal, of beheerde Orchestrators die worden aangeboden door functieplatforms.
Sommige van de FTI-pijplijnen zullen echter geen orkestratie nodig hebben. Trainingspijplijnen kunnen op aanvraag worden uitgevoerd wanneer een nieuw model nodig is. Pijplijnen voor streamingfuncties en online-inferentiepijplijnen worden continu als services uitgevoerd en vereisen geen orkestratie. Flink, Spark Streaming en Beam worden als services uitgevoerd op platforms zoals Kubernetes, Databricks of Hopsworks. Online-inferentiepijplijnen worden met hun model geïmplementeerd op modelserveerplatforms, zoals KServe (Hopsworks), Seldon, Sagemaker en Ray. De belangrijkste conclusie hier is dat de ML-pijplijnen modulair zijn met duidelijke interfaces, waardoor u de beste technologie kunt kiezen voor het runnen van uw FTI-pijplijnen.
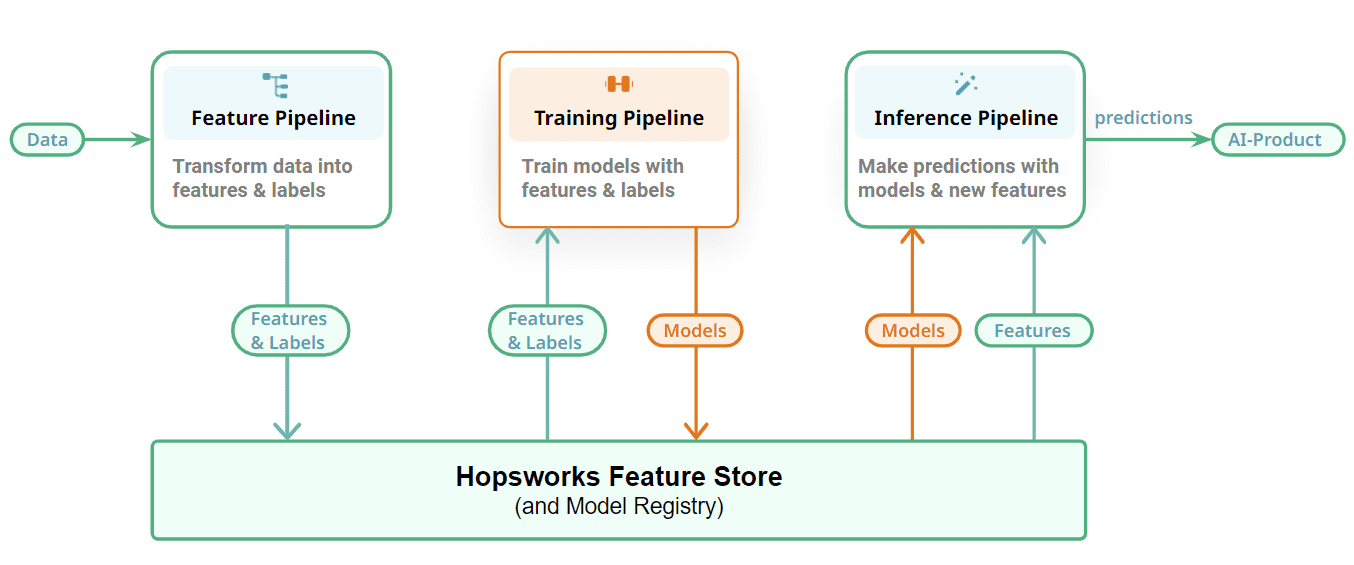
Figuur 3: Verbind uw ML-pijplijnen met een Feature Store en Model Registry
Ten slotte laten we zien hoe we onze FTI-pijplijnen verbinden met een stateful laag om de ML-artefacten op te slaan: functies, trainings-/testgegevens en modellen. Feature-pijplijnen slaan hun uitvoer, features, op als DataFrames in de feature store. Incrementele tabellen slaan elke nieuwe update/toevoeging/verwijdering op als afzonderlijke commits met behulp van een tabelindeling (we gebruiken Apache Hudi in Hopswerken). Trainingspijplijnen lezen point-in-time consistente momentopnamen van trainingsgegevens uit Hopsworks om modellen mee te trainen en het getrainde model uit te voeren naar een modelregister. U kunt hier uw favoriete modelregister opnemen, maar we zijn bevooroordeeld ten opzichte van het modelregister van Hopsworks. Batch-inferentiepijplijnen lezen ook point-in-time consistente momentopnamen van inferentiegegevens uit het functiearchief en produceren voorspellingen door het model op de inferentiegegevens toe te passen. Online-inferentiepijplijnen berekenen functies op aanvraag en lezen vooraf berekende functies uit de functieopslag om een kenmerkende vector die wordt gebruikt om voorspellingen te doen in reactie op verzoeken van online applicaties/diensten.
Functiepijplijnen
Functiepijplijnen lezen gegevens uit gegevensbronnen, berekenen functies en nemen deze op in de functieopslag. Enkele van de vragen die voor een bepaalde functiepijplijn moeten worden beantwoord, zijn onder meer:
- Is de functiepijplijn batchgewijs of streaming?
- Zijn functie-opnamen incrementele of volledige bewerkingen?
- Welk raamwerk/taal wordt gebruikt om de functiepijplijn te implementeren?
- Wordt er vóór opname gegevensvalidatie uitgevoerd op de functiegegevens?
- Welke Orchestrator wordt gebruikt om de functiepijplijn te plannen?
- Als sommige functies al zijn berekend door een upstream-systeem (bijvoorbeeld een datawarehouse), hoe voorkom je dan dat die gegevens worden gedupliceerd en lees je alleen die functies bij het maken van trainings- of batch-inferentiegegevens?
Trainingspijplijnen
In trainingspijplijnen zijn enkele details die kunnen worden ontdekt door te dubbelklikken:
- Welk raamwerk/de taal wordt gebruikt om de trainingspijplijn te implementeren?
- Welk platform voor het volgen van experimenten wordt gebruikt?
- Wordt de trainingspijplijn volgens een schema uitgevoerd (zo ja, welke Orchestrator wordt er gebruikt) of wordt deze op aanvraag uitgevoerd (bijvoorbeeld als reactie op prestatievermindering van een model)?
- Zijn GPU's nodig voor training? Zo ja, hoe worden deze toegewezen aan trainingspijplijnen?
- Welke functiecodering/-schaling wordt uitgevoerd op welke functies? (We slaan functiegegevens doorgaans ongecodeerd op in de functieopslag, zodat deze kunnen worden gebruikt voor EDA (verkennende gegevensanalyse). Het coderen/schalen wordt op een consistente manier uitgevoerd, training en gevolgtrekkingspijplijnen). Voorbeelden van feature-coderingstechnieken zijn scikit-learn-pijplijnen of declaratieve transformaties in functieweergaven (Hopfabriek).
- Welk modelevaluatie- en validatieproces wordt gebruikt?
- Welk modelregister wordt gebruikt om de getrainde modellen op te slaan?
Inferentiepijplijnen
Inferentiepijplijnen zijn net zo divers als de toepassingen die ze door AI mogelijk maken. In inferentiepijplijnen zijn enkele details die kunnen worden ontdekt door te dubbelklikken:
- Wat is de voorspellingsconsument – is het een dashboard, een online applicatie – en hoe gebruikt deze voorspellingen?
- Is het een batch- of online-inferentiepijplijn?
- Welk type functiecodering/-schaling wordt uitgevoerd op welke functies?
- Welk raamwerk/taal wordt er gebruikt voor een batch-inferentiepijplijn? Welke Orchestrator wordt gebruikt om het volgens een schema uit te voeren? Welke sink wordt gebruikt om de geproduceerde voorspellingen te verwerken?
- Welk modelserveerserver wordt voor een online-inferentiepijplijn gebruikt om het geïmplementeerde model te hosten? Hoe wordt de online inferentiepijplijn geïmplementeerd – als een voorspellende klasse of met een afzonderlijke transformatorstap? Zijn GPU's nodig voor gevolgtrekking? Is er een SLA (Service Level Agreements) voor hoe lang het duurt om op voorspellingsverzoeken te reageren?
De bestaande mantra is dat MLOps gaat over het automatiseren van continue integratie (CI), continue levering (CD) en continue training (CT) voor ML-systemen. Maar dat is voor veel ontwikkelaars te abstract. MLOps gaat eigenlijk over de voortdurende ontwikkeling van ML-compatibele producten die in de loop van de tijd evolueren. De beschikbare invoergegevens (functies) veranderen in de loop van de tijd, het doel dat u probeert te voorspellen verandert in de loop van de tijd. U moet wijzigingen aanbrengen in de broncode en u wilt er zeker van zijn dat de wijzigingen die u aanbrengt uw ML-systeem niet beschadigen of de prestaties ervan verslechteren. En u wilt de tijd die nodig is om die wijzigingen door te voeren en te testen versnellen voordat deze wijzigingen automatisch in productie worden geïmplementeerd.
Vanuit ons perspectief is een kernachtigere definitie van MLOps die het mogelijk maakt dat ML-systemen in de loop van de tijd veilig kunnen worden ontwikkeld, dat het op zijn minst geautomatiseerd testen, versiebeheer en monitoring van ML-artefacten vereist. MLOps gaat over geautomatiseerd testen, versiebeheer en monitoring van ML-artefacten.
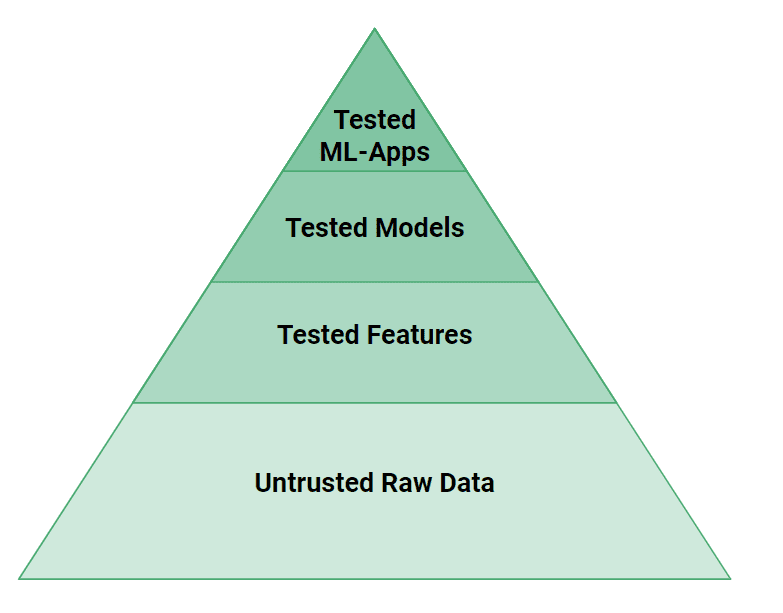
Figuur 4: De testpiramide voor ML-artefacten
In figuur 4 kunnen we zien dat er meer testniveaus nodig zijn in ML-systemen dan in traditionele softwaresystemen. Kleine bugs in gegevens of code kunnen er gemakkelijk voor zorgen dat een ML-model onjuiste voorspellingen doet. Vanuit testperspectief: als webapplicaties propellervliegtuigen zijn, zijn ML-systemen straalmotoren. Er zijn aanzienlijke technische inspanningen nodig om ML-systemen te testen en te valideren om ze veilig te maken!
Op een hoog niveau moeten we zowel de broncode als de gegevens voor ML Systems testen. De logica van de functies die door functiepijplijnen zijn gemaakt, kan worden getest met eenheidstests en hun invoergegevens kunnen worden gecontroleerd met gegevensvalidatietests (bijv. Great Expectations). De modellen moeten worden getest op prestaties, maar ook op een gebrek aan vooringenomenheid tegenover bekende groepen kwetsbare gebruikers. Ten slotte moeten ML-Systems, bovenaan de piramide, hun prestaties testen met A/B-tests voordat ze kunnen overstappen op het gebruik van een nieuw model.
Ten slotte moeten we ML-artefacten een versie geven zodat de operators van ML-systemen veilig versies van geïmplementeerde modellen kunnen bijwerken en terugdraaien. Systeemondersteuning voor het met een druk op de knop upgraden/downgraden van modellen is een van de heilige graals van MLOps. Maar modellen hebben functies nodig om voorspellingen te kunnen doen, dus modelversies zijn verbonden met functieversies en modellen en functies moeten synchroon worden geüpgraded/downgraded. Gelukkig heb je als Google SRE geen rotatiejaar nodig om modellen eenvoudig te kunnen upgraden/downgraden. Platformondersteuning voor ML-artefacten met versiebeheer zou dit een eenvoudige onderhoudsoperatie voor het ML-systeem moeten maken.
Hier is een voorbeeld van enkele van de beschikbare open-source ML-systemen die zijn gebouwd op de FTI-architectuur. Ze zijn grotendeels gebouwd door beoefenaars en studenten.
Batch ML-systemen
Realtime ML-systeem
Dit artikel introduceert de FTI-pijplijnarchitectuur voor MLOps, waarmee talloze ontwikkelaars efficiënt ML-systemen kunnen maken en onderhouden. Op basis van onze ervaring vermindert deze architectuur de cognitieve belasting die gepaard gaat met het ontwerpen en uitleggen van ML-systemen aanzienlijk, vooral in vergelijking met traditionele MLOps-benaderingen. In bedrijfsomgevingen bevordert het verbeterde communicatie tussen teams door duidelijke interfaces tot stand te brengen, waardoor samenwerking wordt bevorderd en de ontwikkeling van hoogwaardige ML-systemen wordt versneld. Hoewel het de overkoepelende complexiteit vereenvoudigt, maakt het ook een diepgaande verkenning van de individuele pijpleidingen mogelijk. Ons doel voor de FTI-pijplijnarchitectuur is om verbeterd teamwerk en een snellere modelimplementatie mogelijk te maken, waardoor uiteindelijk de maatschappelijke transformatie, aangedreven door AI, wordt versneld.
Lees meer over de fundamentele principes en elementen waaruit de FTI Pipelines-architectuur bestaat diepgaande mentale kaart voor MLOps.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.kdnuggets.com/2023/09/hopsworks-unify-batch-ml-systems-feature-training-inference-pipelines?utm_source=rss&utm_medium=rss&utm_campaign=unify-batch-and-ml-systems-with-feature-training-inference-pipelines

