Tegen het einde van 2022, AWS heeft de algemene beschikbaarheid van realtime streaming-opname aangekondigd naar Amazon roodverschuiving For Amazon Kinesis-gegevensstromen en Amazon Managed Streaming voor Apache Kafka (Amazon MSK), waardoor het niet meer nodig is om streaminggegevens in te voeren Eenvoudige opslagservice van Amazon (Amazon S3) voordat het in Amazon Redshift wordt opgenomen.
Streaming opname van Amazon MSK naar Amazon Redshift, vertegenwoordigt een geavanceerde benadering van realtime gegevensverwerking en -analyse. Amazon MSK fungeert als een zeer schaalbare en volledig beheerde service voor Apache Kafka, waardoor een naadloze verzameling en verwerking van enorme gegevensstromen mogelijk is. Het integreren van streaminggegevens in Amazon Redshift levert enorme waarde op door organisaties in staat te stellen het potentieel van realtime analyses en datagestuurde besluitvorming te benutten.
Met deze integratie kunt u een lage latentie bereiken, gemeten in seconden, terwijl u honderden megabytes aan streaminggegevens per seconde in Amazon Redshift opneemt. Tegelijkertijd zorgt deze integratie ervoor dat de meest actuele informatie direct beschikbaar is voor analyse. Omdat de integratie geen staging-gegevens in Amazon S3 vereist, kan Amazon Redshift streaminggegevens opnemen met een lagere latentie en zonder tussentijdse opslagkosten.
U kunt Amazon Redshift-streamingopname op een Redshift-cluster configureren met behulp van SQL-instructies om een MSK-onderwerp te verifiëren en er verbinding mee te maken. Deze oplossing is een uitstekende optie voor data-ingenieurs die datapijplijnen willen vereenvoudigen en de operationele kosten willen verlagen.
In dit bericht geven we een compleet overzicht van hoe u kunt configureren Amazon Redshift-streamingopname van Amazon MSK.
Overzicht oplossingen
Het volgende architectuurdiagram beschrijft de AWS-services en -functies die u gaat gebruiken.

De workflow omvat de volgende stappen:
- Je begint met het configureren van een Amazon MSK Connect bronconnector, om een MSK-onderwerp te maken, nepgegevens te genereren en deze naar het MSK-onderwerp te schrijven. Voor dit bericht werken we met nep-klantgegevens.
- De volgende stap is om verbinding te maken met een Redshift-cluster met behulp van de Query-editor v2.
- Ten slotte configureert u een extern schema en creëert u een gerealiseerde weergave in Amazon Redshift, om de gegevens uit het MSK-onderwerp te gebruiken. Deze oplossing is niet afhankelijk van een MSK Connect-sinkconnector om de gegevens van Amazon MSK naar Amazon Redshift te exporteren.
Het volgende oplossingsarchitectuurdiagram beschrijft in meer detail de configuratie en integratie van de AWS-services die u gaat gebruiken.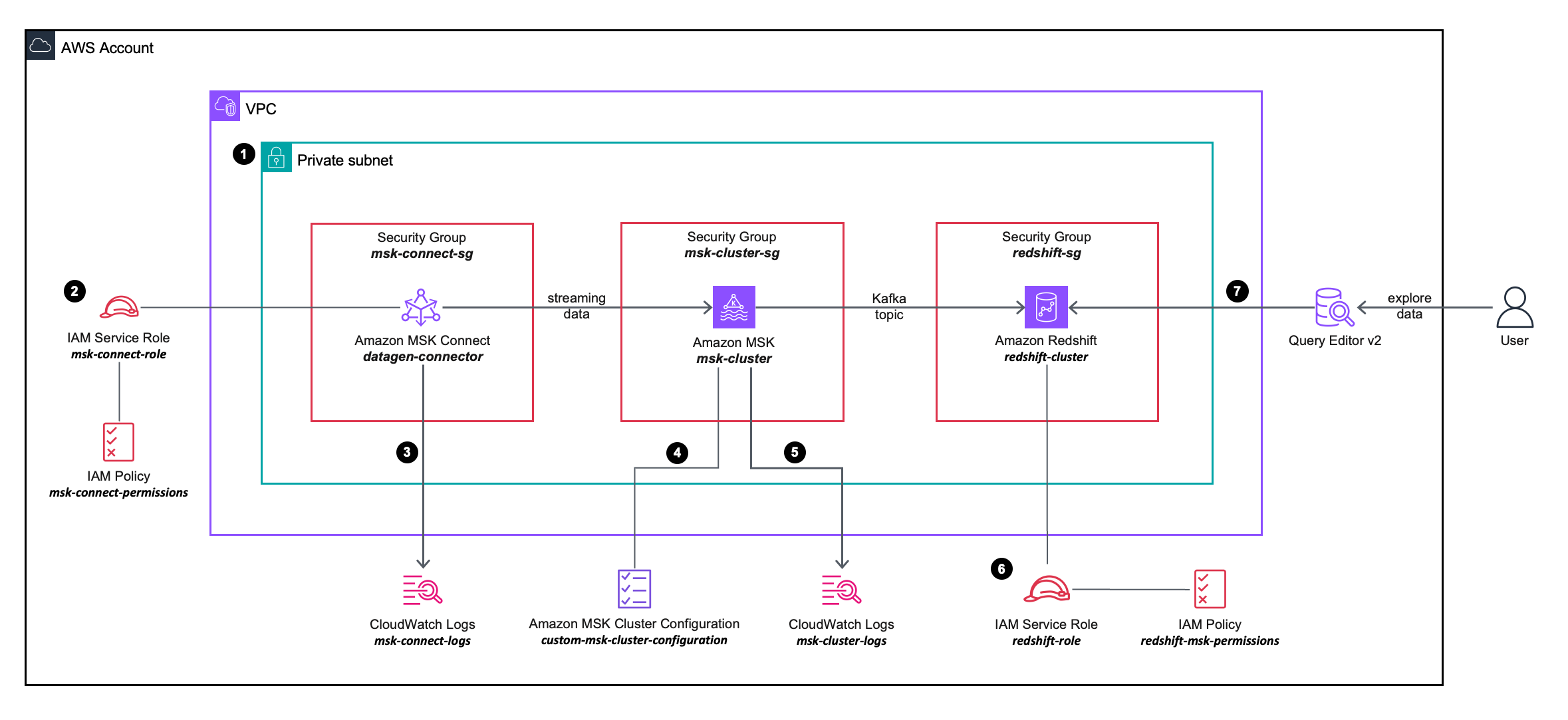
De workflow omvat de volgende stappen:
- U implementeert een MSK Connect-bronconnector, een MSK-cluster en een Redshift-cluster binnen de privé-subnetten op een VPC.
- De MSK Connect-bronconnector maakt gebruik van gedetailleerde machtigingen die zijn gedefinieerd in een AWS identiteits- en toegangsbeheer (IAM) lijnbeleid bevestigd aan een IAM-rol, waarmee de bronconnector acties kan uitvoeren op het MSK-cluster.
- De MSK Connect-bronconnectorlogboeken worden vastgelegd en verzonden naar een Amazon Cloud Watch log groep.
- Het MSK-cluster maakt gebruik van een aangepaste MSK-clusterconfiguratie, waardoor de MSK Connect-connector onderwerpen op het MSK-cluster kan maken.
- De MSK-clusterlogboeken worden vastgelegd en verzonden naar een Amazon CloudWatch-loggroep.
- Het Redshift-cluster maakt gebruik van gedetailleerde machtigingen die zijn gedefinieerd in een in-line IAM-beleid dat is gekoppeld aan een IAM-rol, waardoor het Redshift-cluster acties kan uitvoeren op het MSK-cluster.
- U kunt de Query Editor v2 gebruiken om verbinding te maken met het Redshift-cluster.
Voorwaarden
Om de inrichting en configuratie van de vereiste bronnen te vereenvoudigen, kunt u het volgende gebruiken AWS CloudFormatie sjabloon:
![]()
Voer de volgende stappen uit bij het starten van de stapel:
- Voor Stack naam, voer een betekenisvolle naam in voor de stapel, bijvoorbeeld
prerequisites. - Kies Next.
- Kies Next.
- kies Ik erken dat AWS CloudFormation IAM-bronnen met aangepaste namen kan maken.
- Kies Verzenden.
De CloudFormation-stack maakt de volgende bronnen aan:
- Een VPC
custom-vpc, gemaakt in drie Beschikbaarheidszones, waarvan er drie zijn openbare subnetten en drie privé subnetten:- De openbare subnetten zijn gekoppeld aan een openbare routetabel en uitgaand verkeer wordt naar een internetgateway geleid.
- De privé-subnetten zijn gekoppeld aan een privéroutetabel en uitgaand verkeer wordt naar een NAT-gateway verzonden.
- An internet-gateway gekoppeld aan de Amazon VPC.
- A NAT-gateway dat is gekoppeld aan een elastische IP en wordt geïmplementeerd in een van de openbare subnetten.
- Drie beveiligingsgroepen:
msk-connect-sg, die later zal worden gekoppeld aan de MSK Connect-connector.redshift-sg, die later zal worden geassocieerd met het Redshift-cluster.msk-cluster-sg, die later zal worden geassocieerd met het MSK-cluster. Het maakt inkomend verkeer mogelijk vanmsk-connect-sgenredshift-sg.
- Twee CloudWatch-logboekgroepen:
msk-connect-logs, te gebruiken voor de MSK Connect-logboeken.msk-cluster-logs, te gebruiken voor de MSK-clusterlogboeken.
- Twee IAM-rollen:
msk-connect-role, inclusief gedetailleerde IAM-machtigingen voor MSK Connect.redshift-role, inclusief gedetailleerde IAM-machtigingen voor Amazon Redshift.
- A aangepaste MSK-clusterconfiguratie, waardoor de MSK Connect-connector onderwerpen op het MSK-cluster kan maken.
- Een MSK-cluster, met drie makelaars geïmplementeerd in de drie privé-subnetten van
custom-vpc. Demsk-cluster-sgbeveiligingsgroep en decustom-msk-cluster-configurationconfiguratie worden toegepast op het MSK-cluster. De brokerlogboeken worden afgeleverd bij demsk-cluster-logsCloudWatch-logboekgroep. - A Roodverschuivingsclustersubnetgroep, dat gebruik maakt van de drie privé-subnetten van
custom-vpc. - Een Redshift-cluster, met één enkel knooppunt geïmplementeerd in een privé-subnet binnen de Redshift-cluster-subnetgroep. De
redshift-sgbeveiligingsgroep enredshift-roleDe IAM-rol wordt toegepast op het Redshift-cluster.
Maak een aangepaste MSK Connect-plug-in
Voor deze post gebruiken we een Amazon MSK-gegevensgenerator geïmplementeerd in MSK Connect, om nep-klantgegevens te genereren en deze naar een MSK-onderwerp te schrijven.
Voer de volgende stappen uit:
- Download de Amazon MSK-gegevensgenerator JAR-bestand met afhankelijkheden van GitHub.

- Upload het JAR-bestand naar een S3-bucket in uw AWS-account.
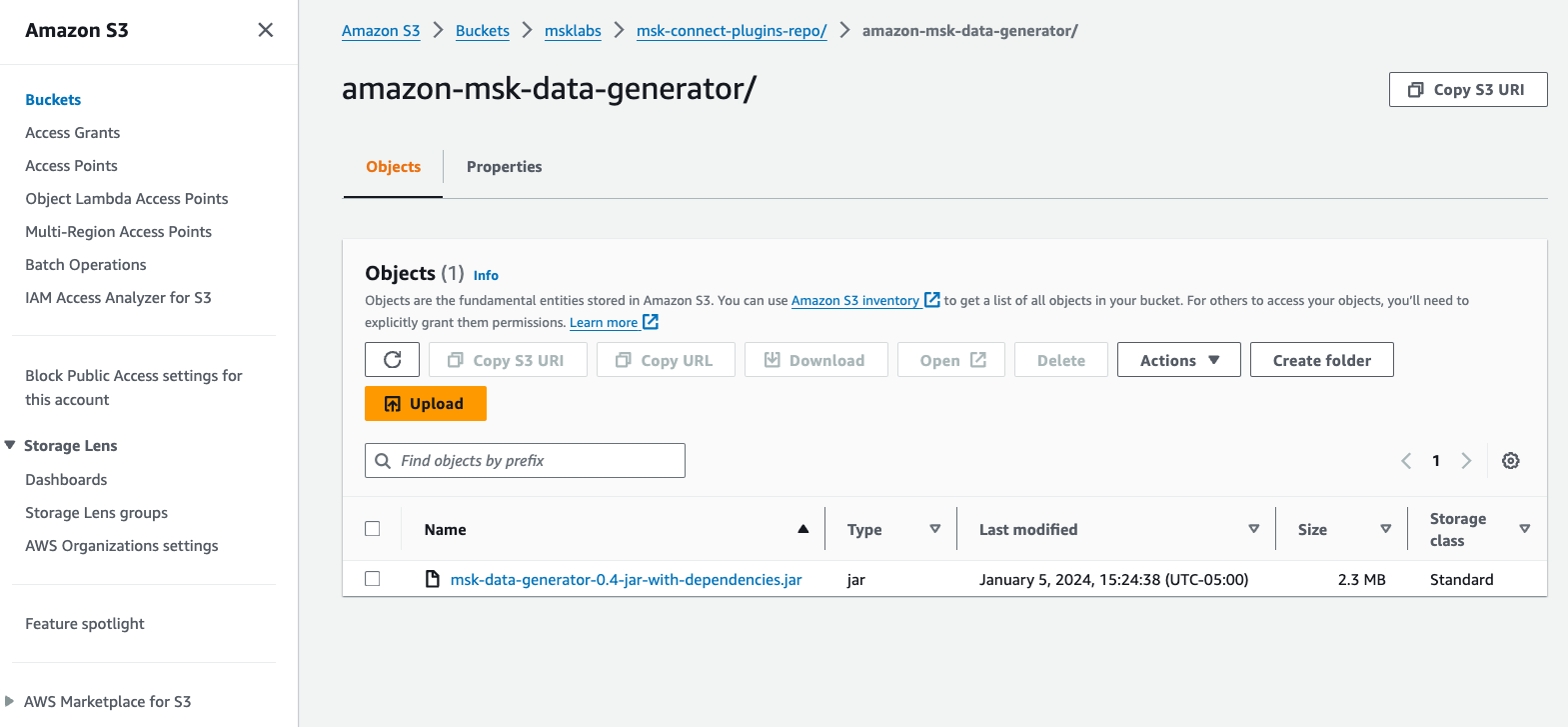
- Kies op de Amazon MSK-console: Aangepaste plug-ins voor MSK-verbinding in het navigatievenster.
- Kies Maak een aangepaste plug-in.
- Kies Blader door S3, zoek naar het JAR-bestand van de Amazon MSK-datagenerator dat u naar Amazon S3 hebt geüpload en kies vervolgens Kies.
- Voor Aangepaste plug-innaam, ga naar binnen
msk-datagen-plugin. - Kies Maak een aangepaste plug-in.
Wanneer de aangepaste plug-in is gemaakt, ziet u dat de status ervan is Actiefen u kunt naar de volgende stap gaan.
Maak een MSK Connect-connector
Voer de volgende stappen uit om uw connector te maken:
- Kies op de Amazon MSK-console: Connectoren voor MSK-verbinding in het navigatievenster.
- Kies Maak een connector.
- Voor Aangepast plug-intype, kiezen Gebruik bestaande plug-in.
- kies
msk-datagen-plugin, kies dan Next. - Voor Connectornaam:, ga naar binnen
msk-datagen-connector. - Voor Clustertype, kiezen Zelfbeheerd Apache Kafka-cluster.
- Voor VPC, kiezen
custom-vpc. - Voor Subnet 1, kiest u het privé-subnet binnen uw eerste Beschikbaarheidszone.
Voor de custom-vpc gemaakt door de CloudFormation-sjabloon, gebruiken we oneven CIDR-bereiken voor openbare subnetten, en zelfs CIDR-bereiken voor de privé-subnetten:
-
- De CIDR's voor de openbare subnetten zijn 10.10.1.0/24, 10.10.3.0/24 en 10.10.5.0/24
- De CIDR's voor de privé-subnetten zijn 10.10.2.0/24, 10.10.4.0/24 en 10.10.6.0/24
- Voor Subnet 2selecteert u het privé-subnet binnen uw tweede Beschikbaarheidszone.
- Voor Subnet 3, selecteert u het privé-subnet binnen uw derde Beschikbaarheidszone.
- Voor Bootstrap-servers, voert u de lijst met bootstrapservers in voor TLS-authenticatie van uw MSK-cluster.
Naar haal de bootstrap-servers voor uw MSK-cluster op, navigeer naar de Amazon MSK-console, kies Clusters, kiezen msk-cluster, kies dan Klantinformatie bekijken. Kopieer de TLS-waarden voor de bootstrap-servers.
- Voor Beveiligingsgroepen, kiezen Gebruik specifieke beveiligingsgroepen met toegang tot dit clusteren kies
msk-connect-sg. - Voor Connector configuratie, vervang de standaardinstellingen door het volgende:
- Kies voor Connectorcapaciteit Voorzien.
- Voor MCU-aantal per werknemer, kiezen 1.
- Voor Aantal arbeiders, kiezen 1.
- Voor Werknemer configuratie, kiezen Gebruik de standaardconfiguratie van MSK.
- Voor Toegangsrechten, kiezen
msk-connect-role. - Kies Next.
- Selecteer voor Codering TLS-gecodeerd verkeer.
- Kies Next.
- Voor Levering van logboeken, kiezen Leveren aan Amazon CloudWatch Logs.
- Kies Bladerselecteer
msk-connect-logsen kies Kies. - Kies Next.
- Beoordeel en kies Maak een connector.
Nadat de aangepaste connector is gemaakt, ziet u dat de status ervan is Hardlopenen u kunt naar de volgende stap gaan.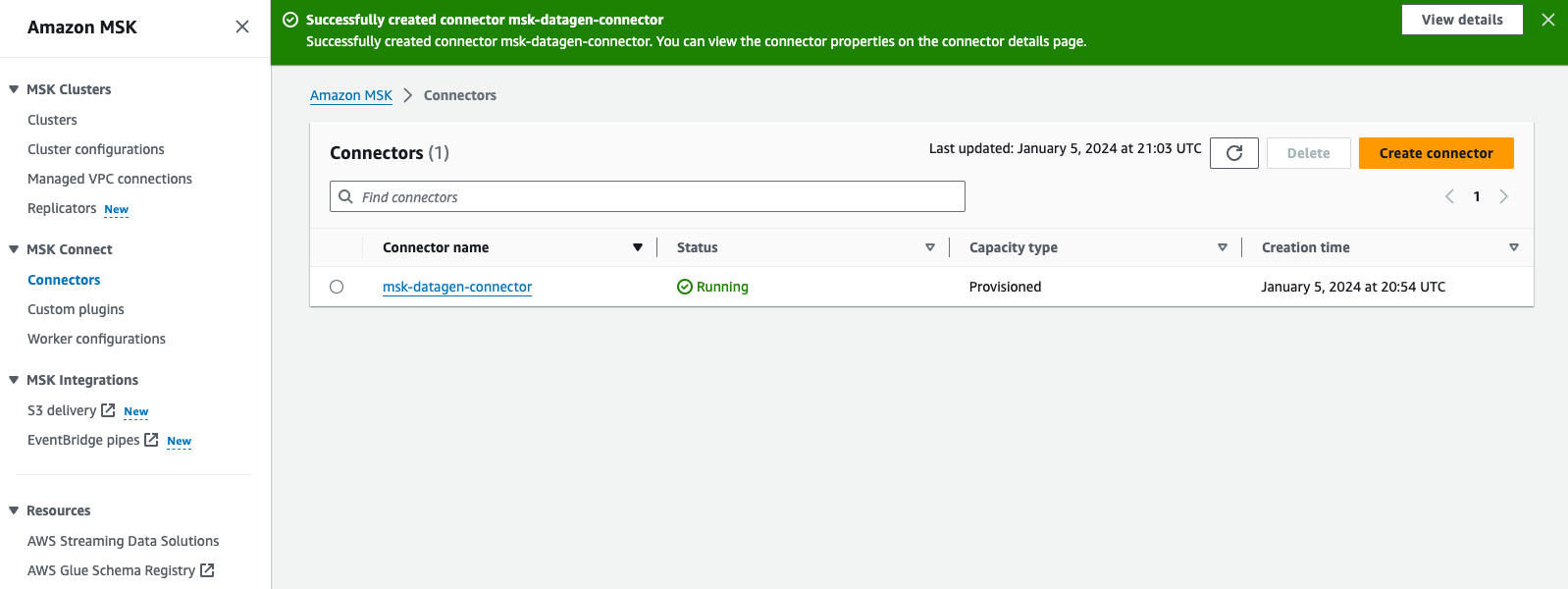
Configureer Amazon Redshift-streamingopname voor Amazon MSK
Voer de volgende stappen uit om streaming-opname in te stellen:
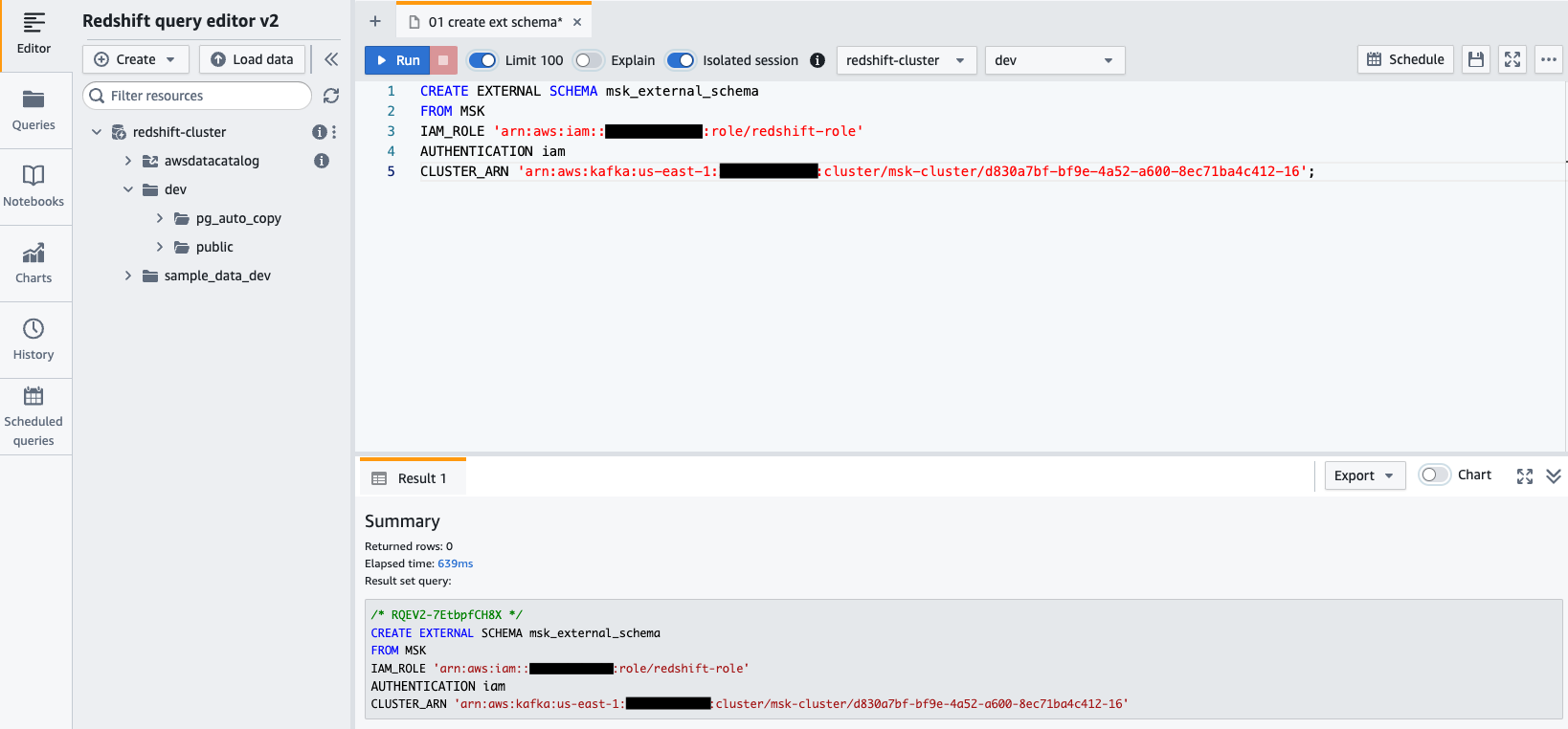
- Maak verbinding met uw Redshift-cluster met behulp van Query Editor v2 en verifieer met de databasegebruikersnaam
awsuser, en wachtwoordAwsuser123. - Maak een extern schema van Amazon MSK met behulp van de volgende SQL-instructie.
Voer in de volgende code de waarden in voor de redshift-role IAM-rol, en de msk-cluster cluster ARN.
- Kies lopen om de SQL-instructie uit te voeren.
- Maak een gematerialiseerde weergave met behulp van de volgende SQL-instructie:
- Kies lopen om de SQL-instructie uit te voeren.
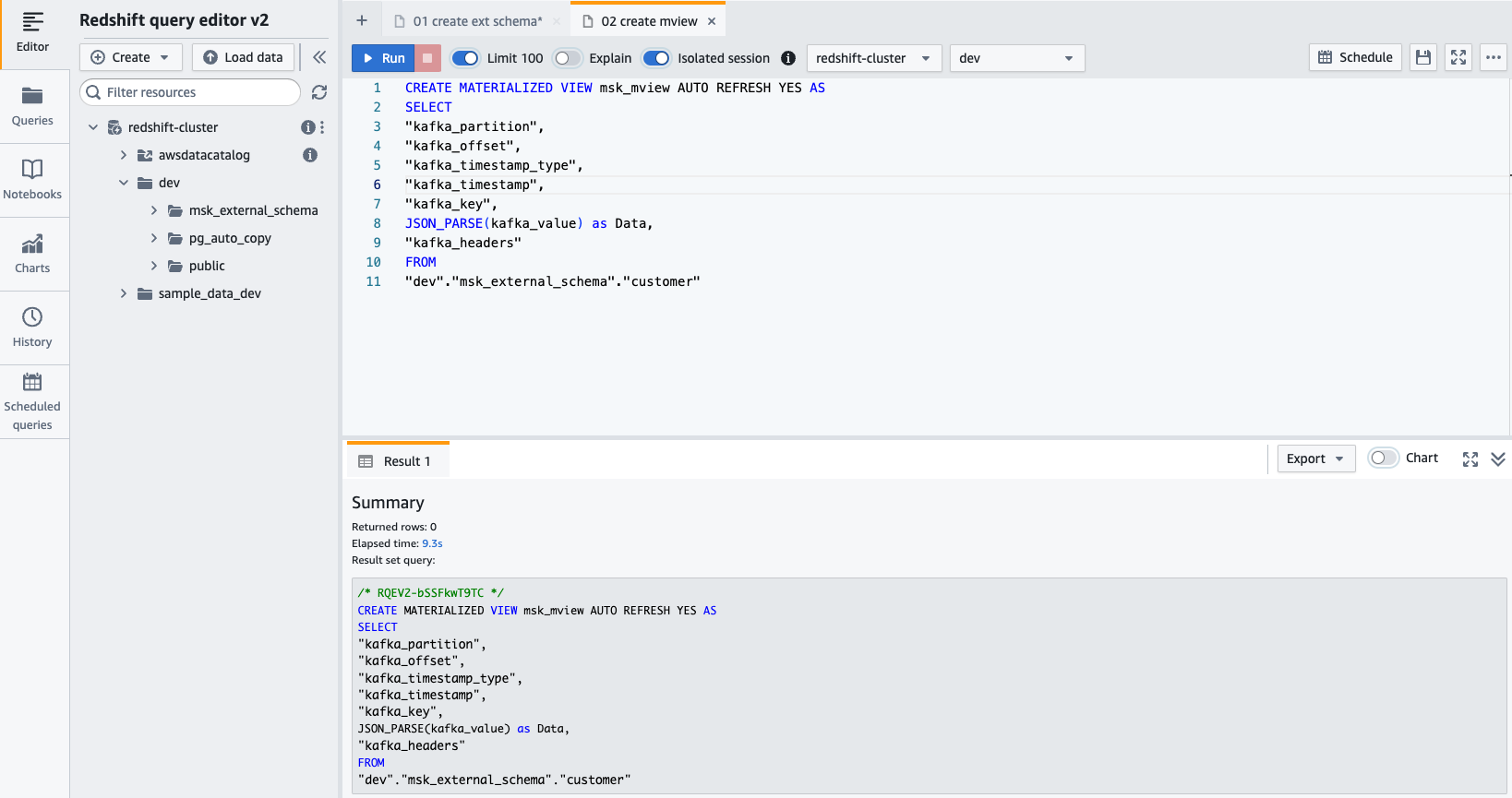
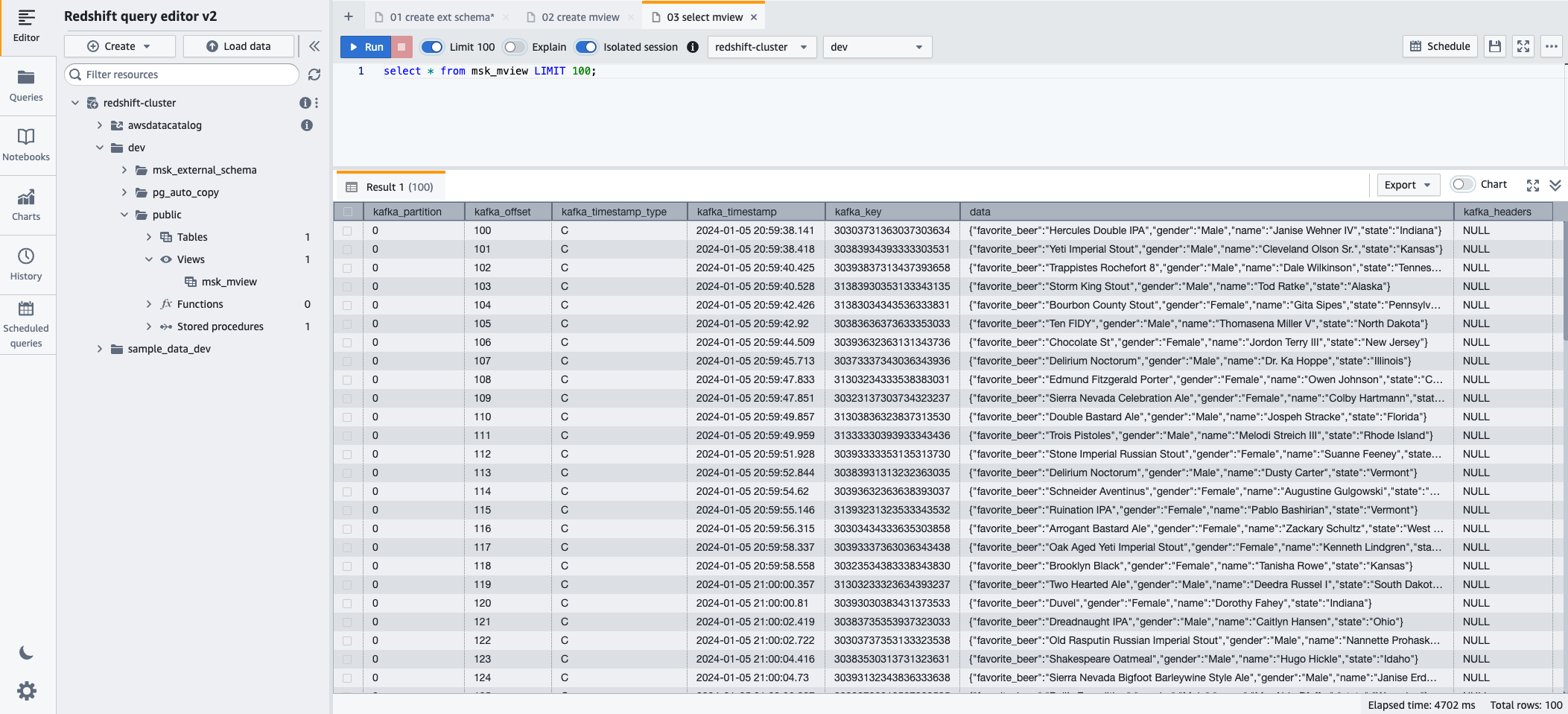
- U kunt nu de gerealiseerde weergave opvragen met behulp van de volgende SQL-instructie:
- Kies lopen om de SQL-instructie uit te voeren.
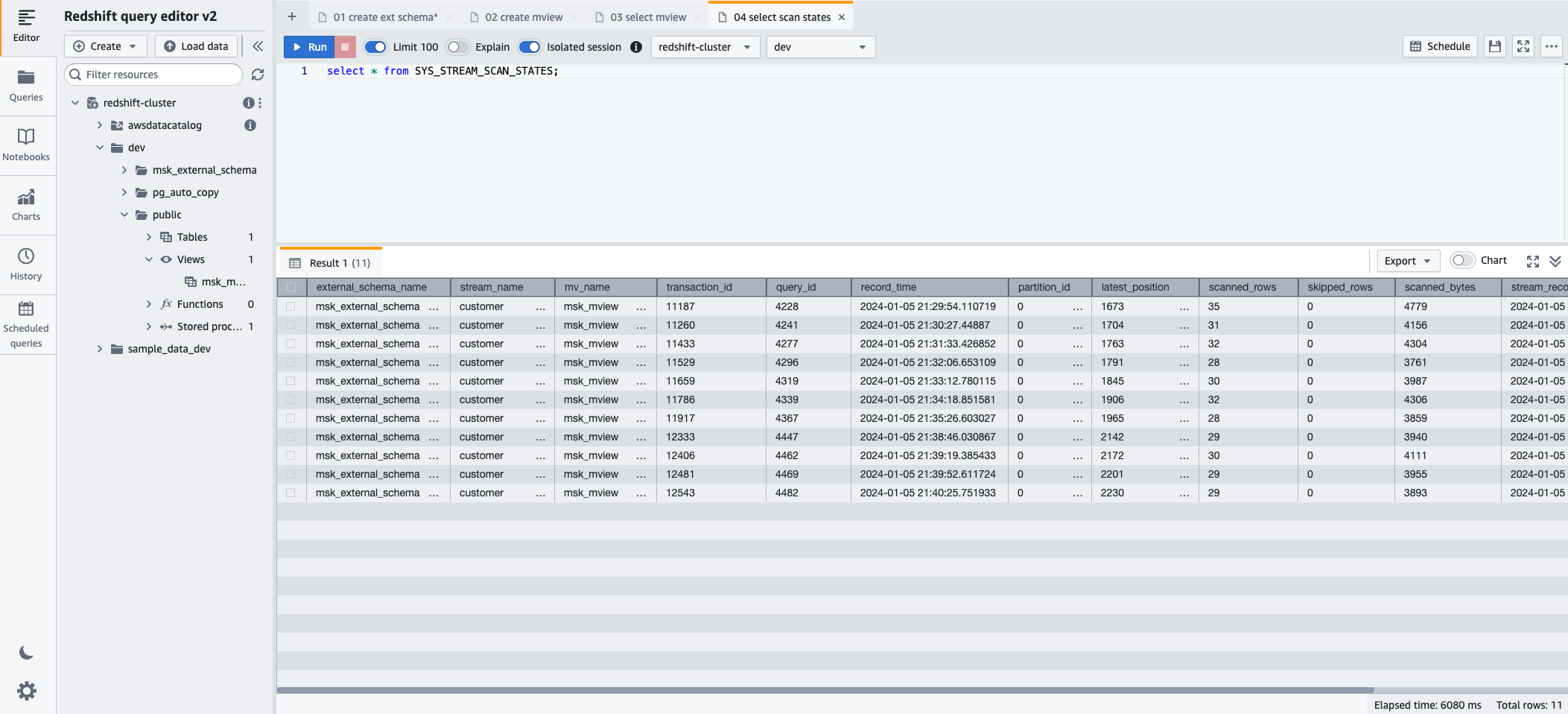
- Als u de voortgang wilt volgen van records die zijn geladen via streaming-opname, kunt u profiteren van de SYS_STREAM_SCAN_STATES monitoringweergave met behulp van de volgende SQL-instructie:
- Kies lopen om de SQL-instructie uit te voeren.
- Als u fouten wilt monitoren die zijn aangetroffen in records die zijn geladen via streaming-opname, kunt u profiteren van de SYS_STREAM_SCAN_ERRORS monitoringweergave met behulp van de volgende SQL-instructie:
- Kies lopen om de SQL-instructie uit te voeren.
Opruimen
Als u de door u gemaakte bronnen niet langer nodig heeft, verwijdert u ze in de volgende volgorde om te voorkomen dat er extra kosten in rekening worden gebracht:
- Verwijder de MSK Connect-connector
msk-datagen-connector. - Verwijder de MSK Connect-plug-in
msk-datagen-plugin. - Verwijder het JAR-bestand van de Amazon MSK-datagenerator dat u hebt gedownload en verwijder de S3-bucket die u heeft gemaakt.
- Nadat u uw MSK Connect-connector hebt verwijderd, kunt u de CloudFormation-sjabloon verwijderen. Alle bronnen die door de CloudFormation-sjabloon zijn gemaakt, worden automatisch verwijderd uit uw AWS-account.
Conclusie
In dit bericht hebben we gedemonstreerd hoe je Amazon Redshift-streamingopname van Amazon MSK kunt configureren, met de nadruk op privacy en beveiliging.
De combinatie van het vermogen van Amazon MSK om datastromen met hoge doorvoer te verwerken met de robuuste analytische mogelijkheden van Amazon Redshift stelt bedrijven in staat snel bruikbare inzichten te verkrijgen. Deze realtime data-integratie verbetert de wendbaarheid en het reactievermogen van organisaties bij het begrijpen van veranderende datatrends, klantgedrag en operationele patronen. Het maakt tijdige en geïnformeerde besluitvorming mogelijk, waardoor een concurrentievoordeel wordt verkregen in het huidige dynamische zakelijke landschap.
Deze oplossing is ook toepasbaar voor klanten die hiervan gebruik willen maken Amazon MSK Serverloos en Amazon Redshift Serverloos.
We hopen dat dit bericht een goede gelegenheid was om meer te leren over de integratie en configuratie van AWS-services. Laat ons uw feedback weten in het opmerkingengedeelte.
Over de auteurs
 Sebastiaan Vlad is een Senior Partner Solutions Architect bij Amazon Web Services, met een passie voor data- en analyseoplossingen en klantensucces. Sebastian werkt samen met zakelijke klanten om hen te helpen bij het ontwerpen en bouwen van moderne, veilige en schaalbare oplossingen om hun bedrijfsresultaten te bereiken.
Sebastiaan Vlad is een Senior Partner Solutions Architect bij Amazon Web Services, met een passie voor data- en analyseoplossingen en klantensucces. Sebastian werkt samen met zakelijke klanten om hen te helpen bij het ontwerpen en bouwen van moderne, veilige en schaalbare oplossingen om hun bedrijfsresultaten te bereiken.
 Sharad Pai is een hoofdtechnische consultant bij AWS. Hij is gespecialiseerd in streaminganalyses en helpt klanten bij het bouwen van schaalbare oplossingen met behulp van Amazon MSK en Amazon Kinesis. Hij heeft meer dan 16 jaar ervaring in de sector en werkt momenteel met mediaklanten die livestreamplatforms hosten op AWS, waarbij hij een piekconcurrency van meer dan 50 miljoen beheert. Voordat Sharad bij AWS kwam, omvatte Sharad's carrière als hoofdsoftwareontwikkelaar 9 jaar coderen, waarbij hij werkte met open source-technologieën zoals JavaScript, Python en PHP.
Sharad Pai is een hoofdtechnische consultant bij AWS. Hij is gespecialiseerd in streaminganalyses en helpt klanten bij het bouwen van schaalbare oplossingen met behulp van Amazon MSK en Amazon Kinesis. Hij heeft meer dan 16 jaar ervaring in de sector en werkt momenteel met mediaklanten die livestreamplatforms hosten op AWS, waarbij hij een piekconcurrency van meer dan 50 miljoen beheert. Voordat Sharad bij AWS kwam, omvatte Sharad's carrière als hoofdsoftwareontwikkelaar 9 jaar coderen, waarbij hij werkte met open source-technologieën zoals JavaScript, Python en PHP.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/simplify-data-streaming-ingestion-for-analytics-using-amazon-msk-and-amazon-redshift/

