In de datagestuurde wereld van vandaag is het vermogen om moeiteloos gegevens over verschillende platforms te verplaatsen en te analyseren essentieel. Amazon-app-stroom, een volledig beheerde data-integratieservice, loopt voorop bij het stroomlijnen van gegevensoverdracht tussen AWS-services, Software as a Service (SaaS)-applicaties en nu Google BigQuery. In deze blogpost ontdek je het nieuwe Google BigQuery-connector in Amazon AppFlow en ontdek hoe het het proces van het overbrengen van gegevens van het datawarehouse van Google naar Eenvoudige opslagservice van Amazon (Amazon S3), wat aanzienlijke voordelen biedt voor dataprofessionals en organisaties, waaronder de democratisering van multi-cloud datatoegang.
Overzicht van Amazon AppFlow
Amazon-app-stroom is een volledig beheerde integratieservice die u kunt gebruiken om gegevens veilig over te dragen tussen SaaS-applicaties zoals Google BigQuery, Salesforce, SAP, Hubspot en ServiceNow, en AWS-services zoals Amazon S3 en Amazon roodverschuiving, met slechts een paar klikken. Met Amazon AppFlow kun je gegevensstromen op vrijwel elke schaal en met de door jou gekozen frequentie uitvoeren: volgens een schema, als reactie op een zakelijk evenement of op aanvraag. U kunt mogelijkheden voor gegevenstransformatie configureren, zoals filteren en validatie, om rijke, gebruiksklare gegevens te genereren als onderdeel van de stroom zelf, zonder extra stappen. Amazon AppFlow codeert automatisch gegevens die in beweging zijn, en stelt u in staat te voorkomen dat gegevens over het openbare internet stromen voor SaaS-applicaties die zijn geïntegreerd met AWS PrivéLink, waardoor de blootstelling aan veiligheidsbedreigingen wordt verminderd.
Maak kennis met de Google BigQuery-connector
De nieuwe Google BigQuery-connector in Amazon AppFlow onthult mogelijkheden voor organisaties die de analytische mogelijkheden van het datawarehouse van Google willen gebruiken en gegevens uit BigQuery moeiteloos willen integreren, analyseren, opslaan of verder verwerken, en deze willen omzetten in bruikbare inzichten.
Architectuur
Laten we de architectuur bekijken om gegevens van Google BigQuery naar Amazon S3 over te dragen met behulp van Amazon AppFlow.

- Selecteer een gegevensbron: In Amazon-app-stroom, selecteert u Google BigQuery als uw gegevensbron. Geef de tabellen of gegevenssets op waaruit u gegevens wilt extraheren.
- Veldkartering en transformatie: Configureer de gegevensoverdracht met behulp van de intuïtieve visuele interface van Amazon AppFlow. U kunt gegevensvelden in kaart brengen en indien nodig transformaties toepassen om de gegevens af te stemmen op uw vereisten.
- Overdrachtsfrequentie: beslis hoe vaak u gegevens wilt overdragen, bijvoorbeeld dagelijks, wekelijks of maandelijks, ter ondersteuning van flexibiliteit en automatisering.
- Bestemming: geef een S3-bucket op als bestemming voor uw gegevens. Amazon AppFlow verplaatst de gegevens efficiënt, waardoor deze toegankelijk worden in uw Amazon S3-opslag.
- Verbruik: Gebruik Amazone Athene om de gegevens in Amazon S3 te analyseren.
Voorwaarden
De dataset die in deze oplossing wordt gebruikt, wordt gegenereerd door synthea, een synthetische patiëntenpopulatiesimulator en een opensourceproject onder de Apache-licentie 2.0. Laad deze gegevens in Google BigQuery of gebruik uw bestaande dataset.
Koppel Amazon AppFlow aan uw Google BigQuery-account
Voor dit bericht gebruik je een Google-account, een OAuth-client met de juiste rechten en Google BigQuery-gegevens. Om Google BigQuery-toegang vanuit Amazon AppFlow in te schakelen, moet u vooraf een nieuwe OAuth-client instellen. Voor instructies, zie Google BigQuery-connector voor Amazon AppFlow.
Amazon S3 instellen
Elk object in Amazon S3 wordt opgeslagen in een bucket. Voordat u gegevens in Amazon S3 kunt opslaan, moet u dit doen maak een S3-bucket om de resultaten op te slaan.
Maak een nieuwe S3-bucket voor Amazon AppFlow-resultaten
Voer de volgende stappen uit om een S3-bucket te maken:
- Op de AWS-beheerconsole voor Amazon S3, kiezen Maak een bucket.
- Voer een globaal uniek in naam voor je emmer; bijvoorbeeld,
appflow-bq-sample. - Kies Maak een bucket.
Maak een nieuwe S3-bucket voor Amazon Athena-resultaten
Voer de volgende stappen uit om een S3-bucket te maken:
- Op de AWS-beheerconsole voor Amazon S3, kiezen Maak een bucket.
- Voer een globaal uniek in naam voor je emmer; bijvoorbeeld,
athena-results. - Kies Maak een bucket.
Gebruikersrol (IAM-rol) voor AWS Glue Data Catalog
Om de gegevens te catalogiseren die u met uw stroom overdraagt, moet u over de juiste gebruikersrol beschikken AWS identiteits- en toegangsbeheer (IAM). U geeft deze rol aan Amazon AppFlow om de machtigingen te verlenen die nodig zijn om een AWS-lijmgegevenscatalogus, tabellen, databases en partities.
Zie voor een voorbeeld van een IAM-beleid dat over de vereiste machtigingen beschikt Op identiteit gebaseerde beleidsvoorbeelden voor Amazon AppFlow.
Doorloop van het ontwerp
Laten we nu een praktische gebruikscasus doornemen om te zien hoe de Amazon AppFlow Google BigQuery naar Amazon S3-connector werkt. Voor de use case gebruik je Amazon AppFlow om historische gegevens van Google BigQuery naar Amazon S3 te archiveren voor langdurige opslag en analyse.
Stel Amazon AppFlow in
Maak een nieuwe Amazon AppFlow-stroom om gegevens over te dragen van Google Analytics naar Amazon S3.
- Op de Amazon AppFlow-console, kiezen Stroom creëren.
- Voer een naam in voor uw stroom; Bijvoorbeeld,
my-bq-flow. - Voeg nodig toe Tags; bijvoorbeeld voor sleutel invoeren
enven voor Waarde invoerendev.

- Kies Volgende.
- Voor Bron naam, kiezen Google BigQuery.
- Kies Nieuwe verbinding maken.
- Voer uw OAuth in klant-ID en Cliëntgeheimen geef vervolgens uw verbinding een naam; Bijvoorbeeld,
bq-connection.
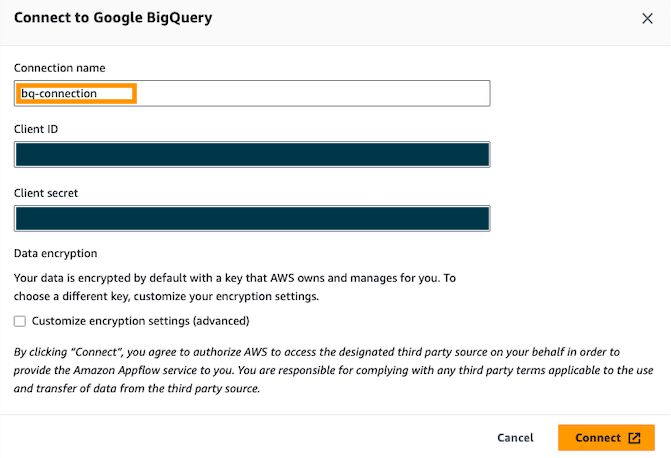
- In het pop-upvenster kiest u ervoor om amazon.com toegang te verlenen tot de Google BigQuery API.
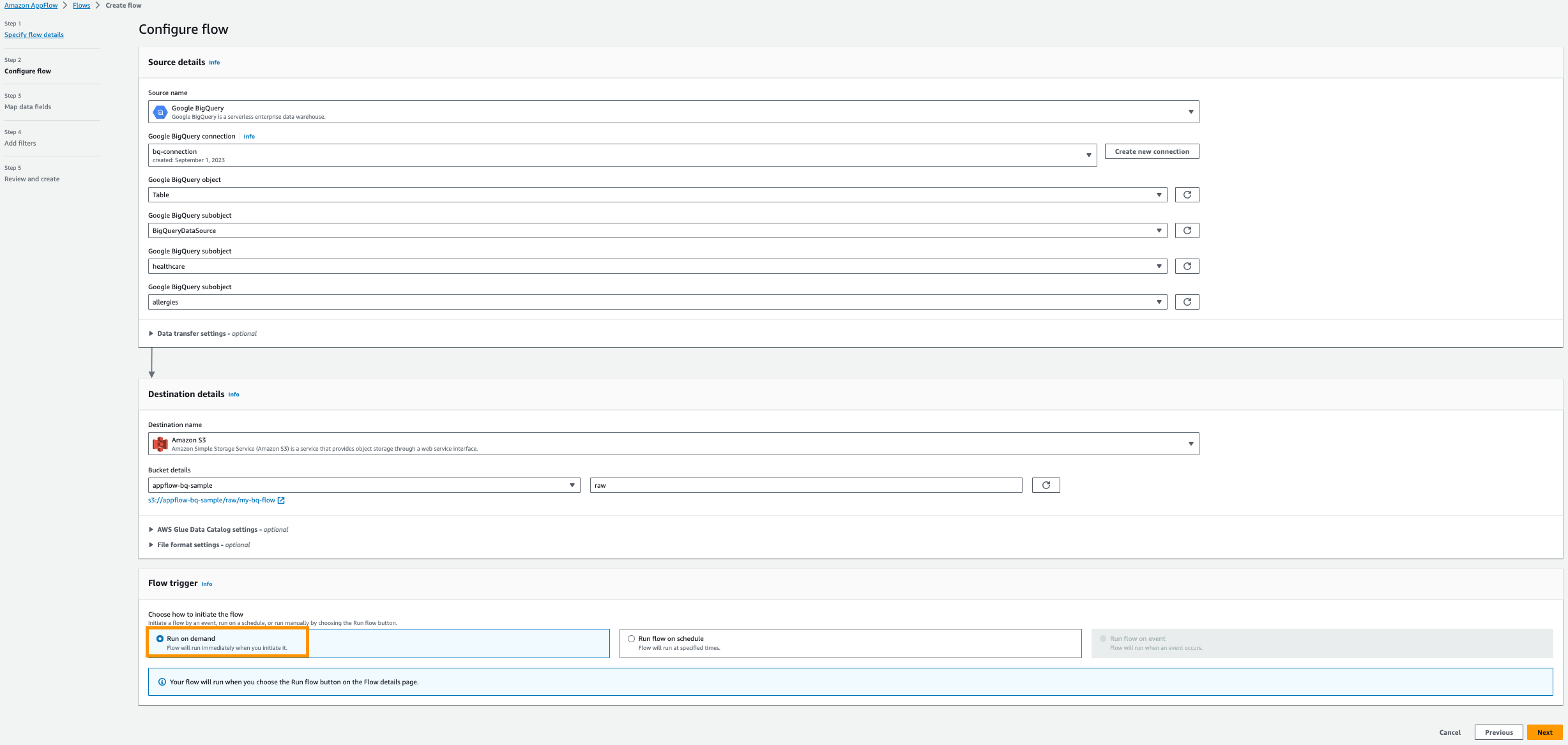
- Voor Kies het Google BigQuery-object, kiezen tafel.
- Voor Kies het Google BigQuery-subobject, kiezen BigQueryProjectnaam.
- Voor Kies het Google BigQuery-subobject, kiezen Database naam.
- Voor Kies het Google BigQuery-subobject, kiezen Tafel naam.
- Voor Bestemmingsnaam, kiezen Amazon S3.
- Voor Emmer details, kiest u de Amazon S3-bucket die u hebt gemaakt voor het opslaan van Amazon AppFlow-resultaten in de vereisten.
- Enter
raween voorvoegsel.
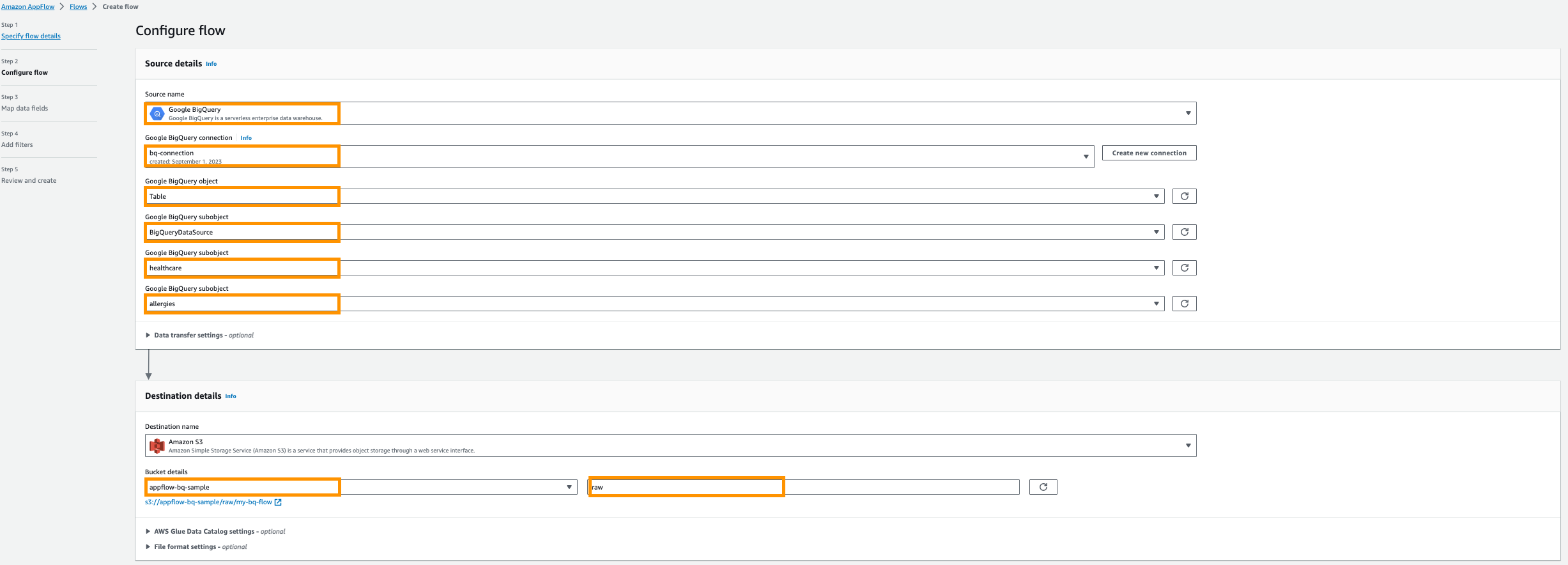
- Geef vervolgens aan AWS-lijmgegevenscatalogus instellingen om een tabel te maken voor verdere analyse.
- Selecteer het Gebruikersrol (IAM-rol) gemaakt in de vereisten.
- Maak nieuwe databank bijvoorbeeld
healthcare. - Verschaffen tabelvoorvoegsel instellen van bijvoorbeeld
bq.

- kies Rennen op aanvraag.
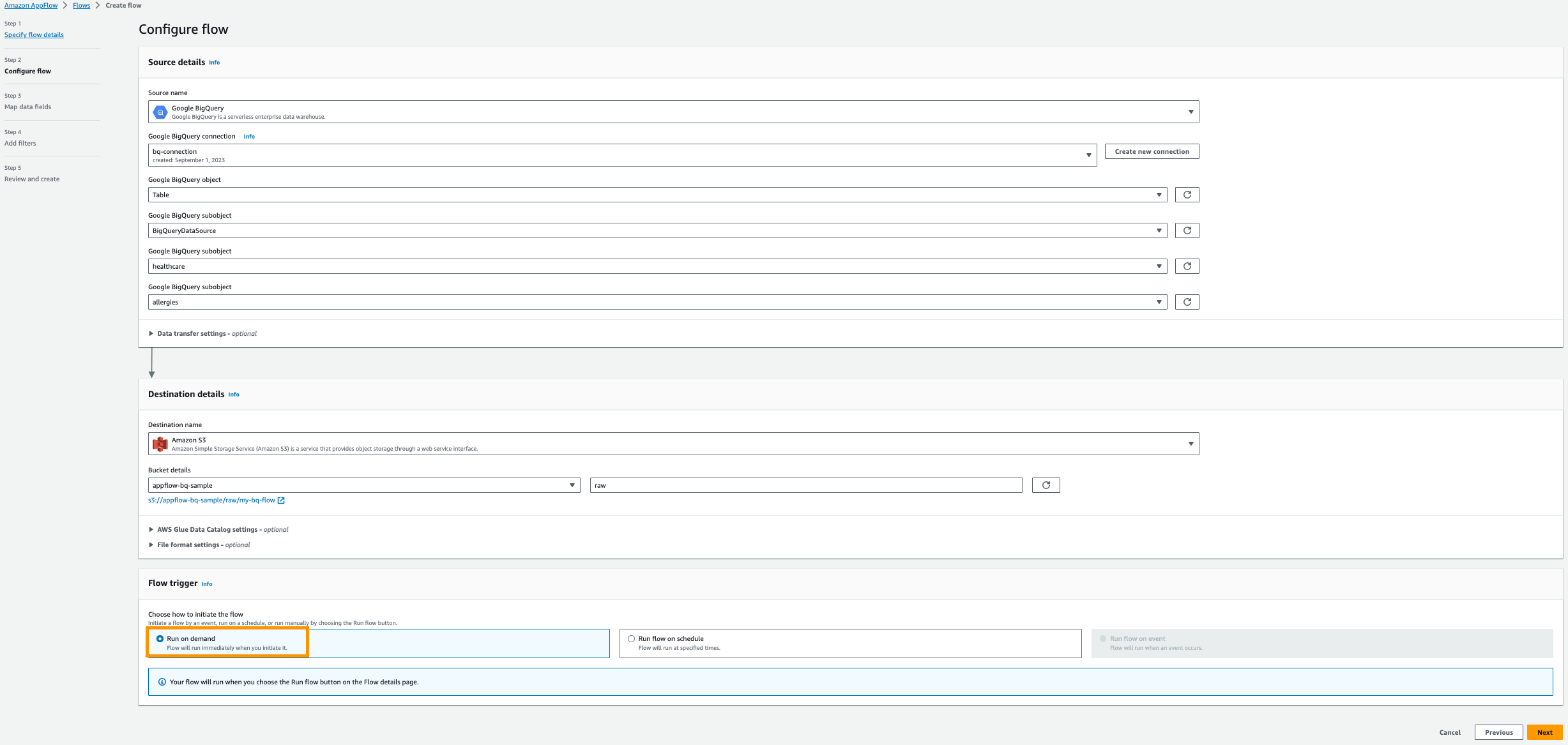
- Kies Next.
- kies Velden handmatig toewijzen.
- Selecteer de volgende zes velden voor Naam bronveld uit de tabel Allergieën:
- Start
- Patiënt
- Code
- Omschrijving
- Type
- Categorie
- Kies Velden direct in kaart brengen.
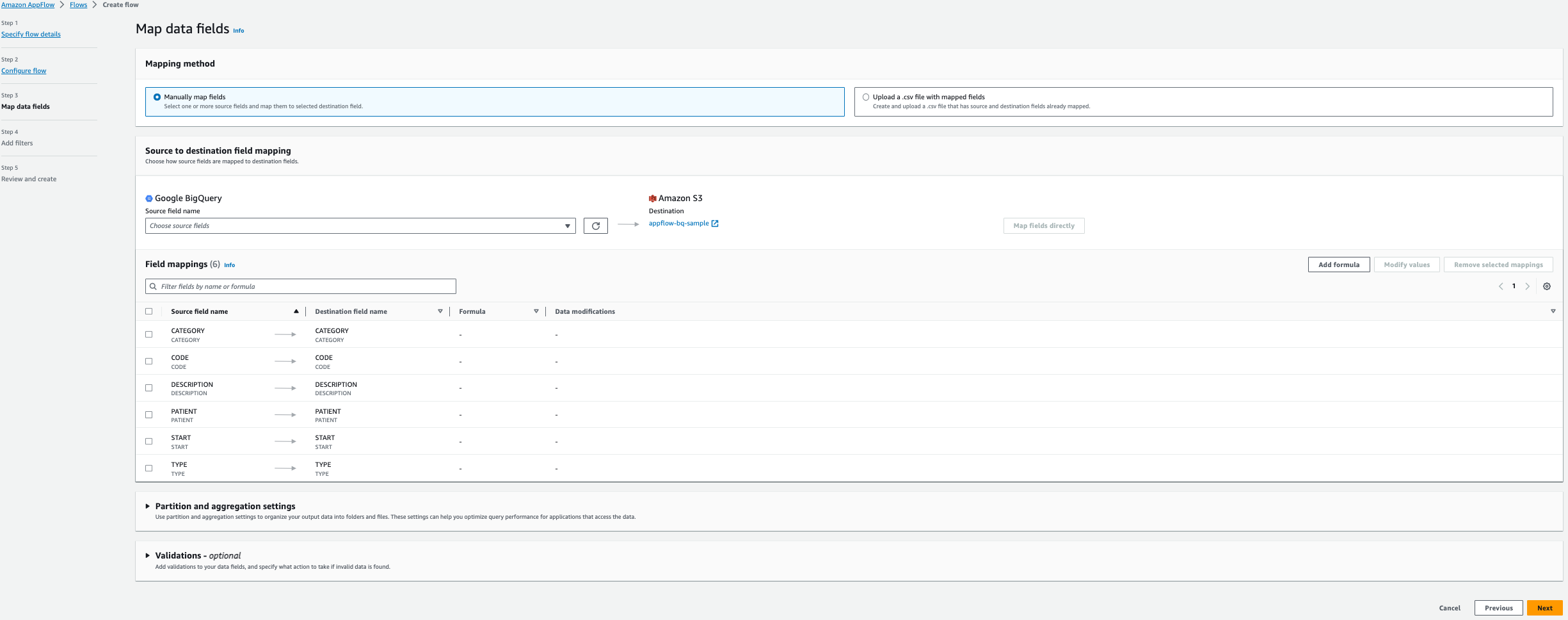
- Kies Volgende.
- In de Filters toevoegen sectie, kies Volgende.
- Kies Stroom creëren.
Voer de stroom uit
Nadat u uw nieuwe stroom hebt gemaakt, kunt u deze op aanvraag uitvoeren.
- Op de Amazon AppFlow-console, kiezen
my-bq-flow. - Kies Stroom uitvoeren.

Voor deze walkthrough kiest u ervoor om de taak op aanvraag uit te voeren, zodat u deze gemakkelijker kunt begrijpen. In de praktijk kunt u een geplande taak kiezen en periodiek alleen nieuw toegevoegde gegevens extraheren.
Vraag via Amazon Athena
Wanneer u de optionele AWS Glue Data Catalog-instellingen selecteert, maakt Data Catalog de catalogus voor de gegevens, waardoor Amazon Athena query's kan uitvoeren.
Als u wordt gevraagd een locatie voor queryresultaten te configureren, navigeert u naar de Instellingen tab en kies Beheren. Onder Beheer instellingen, kies de Athena-resultatenbucket die is gemaakt in de vereisten en kies Bespaar.
- Op de Amazon Athena-console, selecteer de gegevensbron als
AWSDataCatalog. - Selecteer vervolgens Database as
healthcare. - Nu kunt u de tabel selecteren die door de AWS Glue-crawler is gemaakt en er een voorbeeld van bekijken.

- U kunt ook een aangepaste zoekopdracht uitvoeren om de top 10 allergieën te vinden, zoals weergegeven in de volgende zoekopdracht.
Note: Vervang in de onderstaande query in dit geval de tabelnaam bq_appflow_mybqflow_1693588670_latest, met de naam van de tabel die in uw AWS-account is gegenereerd.
- Kies Voer de query uit.
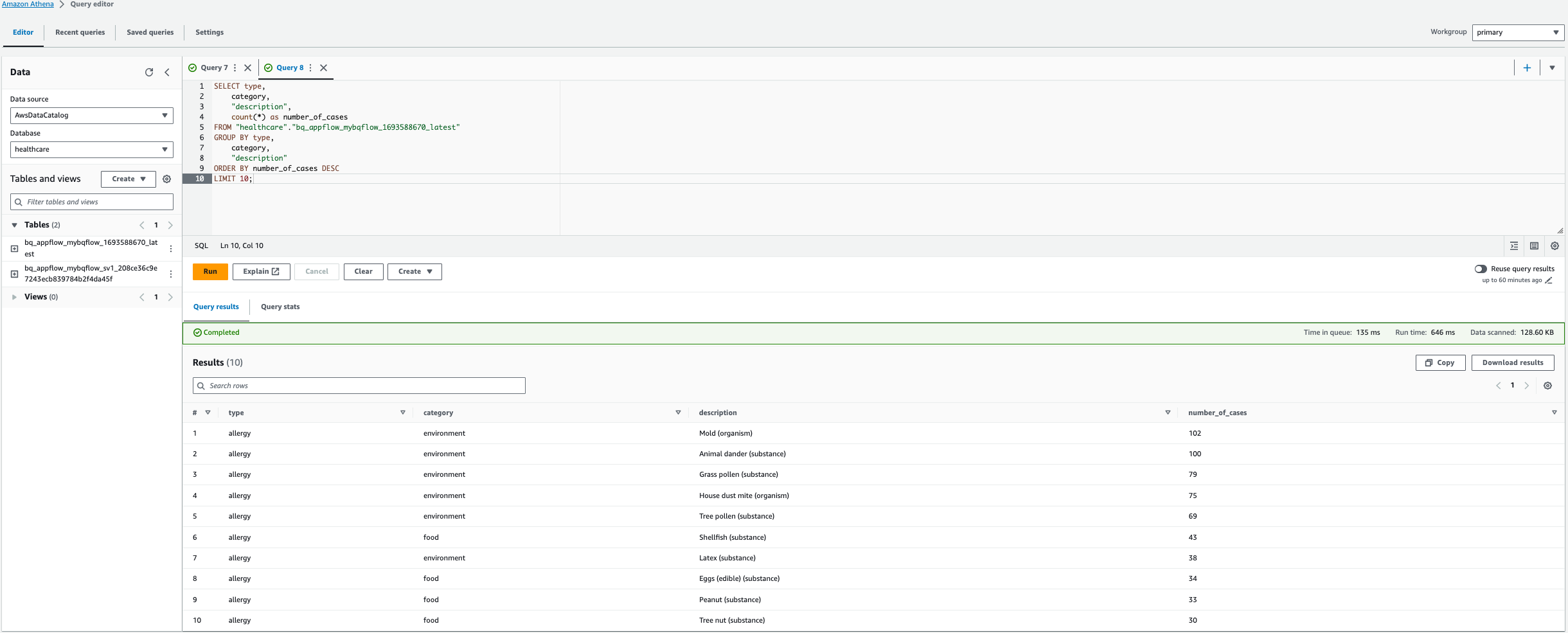
Dit resultaat toont de top 10 van allergieën op basis van het aantal gevallen.
Opruimen
Om te voorkomen dat er kosten in rekening worden gebracht, ruimt u de bronnen in uw AWS-account op door de volgende stappen te voltooien:
- Kies op de Amazon AppFlow-console Stromen in het navigatievenster.
- Selecteer de stroom in de lijst met stromen
my-bq-flowen verwijder het. - Voer delete in om de stroom te verwijderen.
- Kies aansluitingen in het navigatievenster.
- Kies Google BigQuery selecteer in de lijst met connectoren
bq-connectoren verwijder het. - Voer delete in om de connector te verwijderen.
- Kies op de IAM-console rollen op de navigatiepagina, selecteer vervolgens de rol die u voor de AWS Glue-crawler hebt gemaakt en verwijder deze.
- Op de Amazon Athena-console:
- Verwijder de tabellen die onder de database zijn gemaakt
healthcaremet behulp van AWS Glue-crawler. - Laat de database vallen
healthcare
- Verwijder de tabellen die onder de database zijn gemaakt
- Zoek op de Amazon S3-console naar de Amazon AppFlow-resultatenbucket die u hebt gemaakt en kies Leeg om de objecten te verwijderen en verwijder vervolgens de bucket.
- Zoek op de Amazon S3-console naar de Amazon Athena-resultatenbucket die u hebt gemaakt en kies Leeg om de objecten te verwijderen en verwijder vervolgens de bucket.
- Ruim bronnen in uw Google-account op door het project te verwijderen dat de Google BigQuery-bronnen bevat. Volg de documentatie naar ruim de Google-bronnen op.
Conclusie
De Google BigQuery-connector in Amazon AppFlow stroomlijnt het proces van het overbrengen van gegevens van het datawarehouse van Google naar Amazon S3. Deze integratie vereenvoudigt analytics en machine learning, archivering en langetermijnopslag, wat aanzienlijke voordelen oplevert voor dataprofessionals en organisaties die de analytische mogelijkheden van beide platforms willen benutten.
Met Amazon AppFlow worden de complexiteiten van data-integratie geëlimineerd, zodat u zich kunt concentreren op het afleiden van bruikbare inzichten uit uw data. Of u nu historische gegevens archiveert, complexe analyses uitvoert of gegevens voorbereidt op machinaal leren: deze connector vereenvoudigt het proces en maakt het toegankelijk voor een breder scala aan dataprofessionals.
Als je wilt zien hoe de gegevensoverdracht van Google BigQuery naar Amazon S3 met behulp van Amazon AppFlow plaatsvindt, bekijk dan stap voor stap video tutorial. In deze zelfstudie doorlopen we het hele proces, van het opzetten van de verbinding tot het uitvoeren van de gegevensoverdrachtstroom. Ga voor meer informatie over Amazon AppFlow naar Amazon-app-stroom.
Over de auteurs
![]() Kartikay Khator is een Solutions Architect op het gebied van de mondiale levenswetenschappen bij Amazon Web Services. Hij heeft een passie voor het helpen van klanten op hun cloudreis met de nadruk op AWS-analysediensten. Hij is een fervent hardloper en houdt van wandelen.
Kartikay Khator is een Solutions Architect op het gebied van de mondiale levenswetenschappen bij Amazon Web Services. Hij heeft een passie voor het helpen van klanten op hun cloudreis met de nadruk op AWS-analysediensten. Hij is een fervent hardloper en houdt van wandelen.
 Kamen Sharlandjev is een Sr. Big Data en ETL Solutions Architect en Amazon AppFlow-expert. Hij heeft een missie om het leven gemakkelijker te maken voor klanten die worden geconfronteerd met complexe uitdagingen op het gebied van data-integratie. Zijn geheime wapen? Volledig beheerde, low-code AWS-services die de klus kunnen klaren met minimale inspanning en zonder codering.
Kamen Sharlandjev is een Sr. Big Data en ETL Solutions Architect en Amazon AppFlow-expert. Hij heeft een missie om het leven gemakkelijker te maken voor klanten die worden geconfronteerd met complexe uitdagingen op het gebied van data-integratie. Zijn geheime wapen? Volledig beheerde, low-code AWS-services die de klus kunnen klaren met minimale inspanning en zonder codering.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/simplify-data-transfer-google-bigquery-to-amazon-s3-using-amazon-appflow/

