Amazon roodverschuiving is een snel, petabyte-schaal datawarehouse in de cloud waar tienduizenden klanten op vertrouwen om hun analyseworkloads te ondersteunen. Duizenden klanten gebruiken het delen van leesgegevens van Amazon Redshift om directe, gedetailleerde en snelle gegevenstoegang mogelijk te maken via door Redshift ingerichte clusters en serverloze werkgroepen. Hierdoor kunt u uw leesbelastingen schalen naar duizenden gelijktijdige gebruikers zonder dat u de gegevens hoeft te verplaatsen of kopiëren.
Nu kondigen we bij Amazon Redshift schrijfbewerkingen voor meerdere datawarehouses aan via het delen van gegevens in openbare preview. Hierdoor kunt u betere prestaties bereiken voor ETL-werklasten (extract, transform, and load) door verschillende magazijnen van verschillende typen en groottes te gebruiken op basis van uw werklastbehoeften. Bovendien kunt u hierdoor eenvoudig uw ETL-taken voorspelbaarder laten werken, omdat u ze met een paar klikken tussen magazijnen kunt opsplitsen, de kosten kunt bewaken en beheersen omdat elk magazijn zijn eigen monitoring- en kostencontroles heeft, en de samenwerking kunt bevorderen omdat u verschillende teams kunt inschakelen om met slechts een paar klikken naar de databases van een ander team te schrijven.
De gegevens zijn live en beschikbaar in alle magazijnen zodra ze zijn vastgelegd, zelfs als ze naar meerdere accounts of regio's zijn geschreven. Voor preview kunt u een combinatie van ra3.4xl-clusters, ra3.16xl-clusters of serverloze werkgroepen gebruiken.
In dit bericht bespreken we wanneer u zou moeten overwegen om meerdere magazijnen te gebruiken om naar dezelfde databases te schrijven, leggen we uit hoe multi-magazijn schrijft via het delen van gegevens werkt, en laten we u door een voorbeeld lopen van hoe u meerdere magazijnen kunt gebruiken om naar dezelfde database te schrijven.
Redenen om meerdere magazijnen te gebruiken om naar dezelfde databases te schrijven
In deze sectie bespreken we enkele redenen waarom u zou moeten overwegen om meerdere magazijnen te gebruiken om naar dezelfde database te schrijven.
Betere prestaties en voorspelbaarheid voor gemengde workloads
Klanten beginnen vaak met een magazijn dat zo groot is dat het aan hun aanvankelijke werklastbehoeften voldoet. Als u bijvoorbeeld af en toe gebruikersvragen en nachtelijke verwerking van 10 miljoen rijen met aankoopgegevens moet ondersteunen, kan een werkgroep van 32 RPU perfect geschikt zijn voor uw behoeften. Het toevoegen van een nieuwe opname per uur van 400 miljoen rijen gebruikerswebsite- en app-interacties zou de reactietijden van bestaande gebruikers echter kunnen vertragen, omdat de nieuwe werklast aanzienlijke bronnen verbruikt. U kunt de grootte wijzigen naar een grotere werkgroep, zodat u de werklasten snel kunt lezen en schrijven zonder dat u hoeft te vechten om resources. Dit kan echter onnodige energie en kosten opleveren voor bestaande workloads. Omdat workloads rekenkracht delen, kan een piek in één workload van invloed zijn op het vermogen van andere workloads om aan hun SLA's te voldoen.
Het volgende diagram illustreert een architectuur met één magazijn.
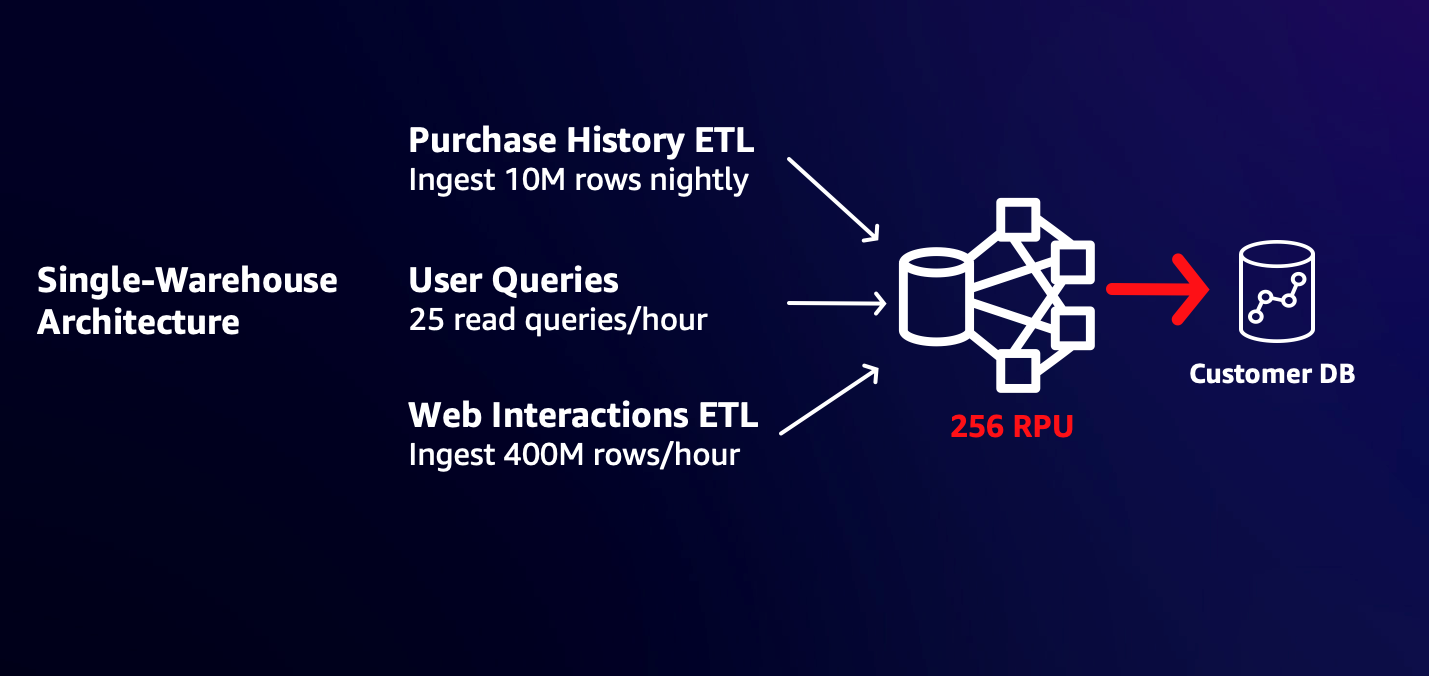
Met de mogelijkheid om via datashares te schrijven, kunt u nu de nieuwe gebruikerswebsite en app-interacties ETL in een afzonderlijke, grotere werkgroep opsplitsen, zodat deze snel wordt voltooid met de prestaties die u nodig hebt, zonder gevolgen voor de kosten of doorlooptijd van uw bestaande workloads. Het volgende diagram illustreert deze multi-warehouse-architectuur.

Dankzij de multi-warehouse-architectuur kunt u alle schrijfworkloads op tijd voltooien met minder gecombineerde rekenkracht en dus lagere kosten dan één magazijn dat alle workloads ondersteunt.
Controle en monitoring van de kosten
Wanneer u één magazijn gebruikt voor al uw ETL-taken, kan het lastig zijn om te begrijpen welke werklasten bijdragen aan uw kosten. Het kan bijvoorbeeld zijn dat het ene team een ETL-werklast uitvoert en gegevens uit een CRM-systeem opneemt, terwijl een ander team gegevens uit interne operationele systemen opneemt. Het is moeilijk voor u om de kosten voor de werklasten te bewaken en te beheersen, omdat query's samen worden uitgevoerd met behulp van dezelfde rekenkracht in het magazijn. Door de schrijfwerklasten in afzonderlijke magazijnen op te splitsen, kunt u de kosten afzonderlijk monitoren en beheersen, terwijl u ervoor zorgt dat de werklasten onafhankelijk kunnen verlopen zonder conflicten met middelen.
Werk eenvoudig samen aan live gegevens
Er zijn momenten waarop twee teams verschillende magazijnen gebruiken vanwege databeheer, computerprestaties of kostenredenen, maar soms ook naar dezelfde gedeelde gegevens moeten schrijven. U beschikt bijvoorbeeld mogelijk over een set Customer 360-tabellen die live moeten worden bijgewerkt terwijl klanten communiceren met uw marketing-, verkoop- en klantenserviceteams. Wanneer deze teams verschillende magazijnen gebruiken, kan het lastig zijn om deze gegevens live te houden, omdat je mogelijk een multi-service ETL-pijplijn moet bouwen met behulp van tools als Amazon eenvoudige opslagservice (Amazone S3), Amazon eenvoudige meldingsservice (Amazone SNS), Amazon Simple Queue-service (Amazon SQS), en AWS Lambda om live veranderingen in de gegevens van elk team bij te houden en deze in één enkele bron op te nemen.
Met de mogelijkheid om via datashares te schrijven, kunt u met een paar klikken gedetailleerde machtigingen voor uw databaseobjecten verlenen (bijvoorbeeld SELECT voor de ene tabel en SELECT, INSERT en TRUNCATE voor een andere) aan verschillende teams die verschillende magazijnen gebruiken. Hierdoor kunnen teams vanuit hun eigen magazijnen naar de gedeelde objecten schrijven. De gegevens zijn live en beschikbaar voor alle magazijnen zodra ze zijn vastgelegd, en dit werkt zelfs als de magazijnen verschillende accounts en regio's gebruiken.
In de volgende secties laten we u zien hoe u meerdere magazijnen kunt gebruiken om via het delen van gegevens naar dezelfde databases te schrijven.
Overzicht oplossingen
We gebruiken de volgende terminologie in deze oplossing:
- namespace – Een logische container voor databaseobjecten, gebruikers en rollen, hun machtigingen voor databaseobjecten en rekenkracht (serverloze werkgroepen en ingerichte clusters).
- Gegevens delen – De eenheid van delen voor het delen van gegevens. U verleent machtigingen voor objecten aan datashares.
- Producent – Het magazijn dat de datashare maakt, machtigingen verleent aan objecten voor datashares en andere magazijnen en accounts toegang verleent tot de datashare.
- Consument – Het magazijn dat toegang krijgt tot de datashare. U kunt consumenten beschouwen als datashare-tenants.
In dit gebruiksscenario is sprake van een klant met twee magazijnen: een primair magazijn dat wordt gebruikt om aan de primaire naamruimte te koppelen voor de meeste lees- en schrijfquery's, en een secundair magazijn dat aan een secundaire naamruimte is gekoppeld en dat voornamelijk wordt gebruikt om naar de primaire naamruimte te schrijven. Wij maken gebruik van het publiek beschikbare 10 GB TPCH-dataset van AWS Labs, gehost in een S3-bucket. U kunt veel van de opdrachten kopiëren en plakken om ze te volgen. Hoewel het klein is voor een datawarehouse, maakt deze dataset het eenvoudig functioneel testen van deze functie mogelijk.
Het volgende diagram illustreert onze oplossingsarchitectuur.

We hebben de primaire naamruimte opgezet door er verbinding mee te maken via het magazijn, en er een marketingdatabase in te maken met een prod en staging schema, en het maken van drie tabellen in de prod schema genoemd region, nation en af_customer. Vervolgens laden we gegevens in de region en nation tafels met behulp van het magazijn. We nemen geen gegevens op in de af_customer tafel.
Vervolgens maken we een datashare in de primaire naamruimte. We geven de datashare de mogelijkheid om objecten in de staging schema en de mogelijkheid om objecten in het prod schema. Vervolgens verlenen we gebruik van het schema aan een andere naamruimte in het account.
Op dat punt maken we verbinding met het secundaire magazijn. We maken een database aan van een datashare in dat magazijn en van een nieuwe gebruiker. Vervolgens verlenen we machtigingen voor het datashare-object aan de nieuwe gebruiker. Vervolgens maken we opnieuw verbinding met het secundaire magazijn als de nieuwe gebruiker.
Vervolgens maken we een klantentabel in de datashare's staging schema en kopieer gegevens uit de TPCH 10-klantgegevensset naar de faseringstabel. We voegen staging-klanttabelgegevens in het gedeelde bestand in af_customer productietabel en kap vervolgens de tabel af.
Op dit punt is de ETL voltooid en kunt u de gegevens in de primaire naamruimte, ingevoegd door het secundaire ETL-magazijn, lezen vanuit zowel het primaire magazijn als het secundaire ETL-magazijn.
Voorwaarden
Om dit bericht te volgen, moet u aan de volgende vereisten voldoen:
- Twee magazijnen gemaakt met de
PREVIEW_2023spoor. De magazijnen kunnen een mix zijn van serverloze werkgroepen, ra3.4xl-clusters en ra3.16xl-clusters. - Toegang tot een superuser in beide magazijnen.
- An AWS Identiteits- en toegangsbeheer (IAM)-rol die gegevens van Amazon Redshift naar Amazon S3 kan opnemen (Amazon Redshift maakt er standaard een aan wanneer u een cluster of serverloze werkgroep maakt).
- Alleen voor meerdere accounts heeft u toegang nodig tot een IAM-gebruiker of -rol die toestemming heeft om datashares te autoriseren. Voor het IAM-beleid, zie Datashares delen.
Verwijzen naar Zowel lees- als schrijfgegevens delen binnen een AWS-account of tussen accounts (preview) voor de meest up-to-date informatie.
De primaire naamruimte instellen (producent)
In deze sectie laten we zien hoe u de primaire (producent) naamruimte instelt die we zullen gebruiken om onze gegevens op te slaan.
Maak verbinding met producent
Voer de volgende stappen uit om verbinding te maken met de producent:
- Kies op de Amazon Redshift-console Query-editor v2 in het navigatievenster.

In de query-editor v2 kunt u in het linkerdeelvenster alle magazijnen zien waartoe u toegang heeft. U kunt ze uitvouwen om hun databases te zien.
- Maak verbinding met uw primaire magazijn via een superuser.
- Voer de volgende opdracht uit om het
marketingdatabank:
Maak de databaseobjecten die u wilt delen
Voer de volgende stappen uit om uw databaseobjecten te maken om te delen:
- Nadat u de hebt gemaakt
marketingdatabase, schakel uw databaseverbinding naar demarketingdatabase.
Mogelijk moet u uw pagina vernieuwen om deze te kunnen zien.
- Voer de volgende opdrachten uit om de twee schema's te maken die u wilt delen:
- Maak de tabellen die u wilt delen met de volgende code. Dit zijn standaard DDL-instructies afkomstig uit het AWS Labs DDL-bestand met aangepaste tabelnamen.
Kopieer gegevens naar het region en nation tafels
Voer de volgende opdrachten uit om gegevens van de AWS Labs S3-bucket naar de region en nation tafels. Als u een cluster hebt gemaakt terwijl u de standaard gemaakte IAM-rol behoudt, kunt u de volgende opdrachten kopiëren en plakken om gegevens in uw tabellen te laden:
Maak de gegevensshare
Maak de datashare met behulp van de volgende opdracht:
De publicaccessible De instelling specificeert of een datashare al dan niet kan worden gebruikt door consumenten met openbaar toegankelijke ingerichte clusters en serverloze werkgroepen. Als uw magazijnen niet openbaar toegankelijk zijn, kunt u dat veld negeren.
Verleen machtigingen voor schema's aan de datashare
Om objecten met machtigingen aan de datashare toe te voegen, gebruikt u de subsidiesyntaxis, waarbij u de datashare specificeert waaraan u de machtigingen wilt verlenen:
Hierdoor kunnen de datashare-consumenten objecten gebruiken die zijn toegevoegd aan de prod schema en gebruik en maak objecten toegevoegd aan de staging schema. Om achterwaartse compatibiliteit te behouden, als u de alter datashare commando om een schema toe te voegen, zal dit het equivalent zijn van het verlenen van gebruik op het schema.
Verleen machtigingen voor tabellen aan de datashare
Nu kunt u toegang verlenen tot tabellen aan de datashare met behulp van de subsidiesyntaxis, waarbij u de machtigingen en de datashare specificeert. De volgende code verleent alle rechten op het af_customer tabel naar de datashare:
Om achterwaartse compatibiliteit te behouden, zal het gebruik van de opdracht alter datashare om een tabel toe te voegen hetzelfde zijn als het toekennen van select aan de tabel.
Daarnaast hebben we bereikmachtigingen toegevoegd waarmee u dezelfde machtiging kunt verlenen aan alle huidige en toekomstige objecten binnen de datashare. We voegen de bereikbare selectiemachtiging toe aan de por schematabellen naar de datashare:
Na deze verlening beschikt de klant over selectierechten voor alle huidige en toekomstige tabellen in het prod-schema. Dit geeft hen geselecteerde toegang op de region en nation tabellen.
Bekijk de machtigingen die aan de datashare zijn verleend
U kunt de machtigingen bekijken die aan de datashare zijn verleend door de volgende opdracht uit te voeren:
Verleen machtigingen aan de secundaire ETL-naamruimte
U kunt machtigingen verlenen aan de secundaire ETL-naamruimte met behulp van de bestaande syntaxis. U doet dit door de naamruimte-ID op te geven. U kunt de naamruimte vinden op de pagina met naamruimtedetails als uw secundaire ETL-naamruimte serverloos is, als onderdeel van de naamruimte-ID op de pagina met clusterdetails als uw secundaire ETL-naamruimte is ingericht, of door verbinding te maken met het secundaire ETL-magazijn in de query-editor v2 en rennen select current_namespace. Vervolgens kunt u met het volgende commando toegang verlenen tot de andere naamruimte (verander de consumentennaamruimte naar de naamruimte-UID van uw eigen secundaire ETL-magazijn):
De secundaire ETL-naamruimte instellen (consument)
Op dit punt bent u klaar om uw secundaire (consumenten) ETL-magazijn in te stellen om te beginnen met schrijven naar de gedeelde gegevens.
Maak een database van de datashare
Voer de volgende stappen uit om uw database te maken:
- Schakel in de query-editor v2 over naar het secundaire ETL-magazijn.
- Voer het commando uit
show datasharesom de marketingdatashare en de naamruimte van de datashareproducent te zien. - Gebruik die naamruimte om een database te maken op basis van de datashare, zoals weergegeven in de volgende code:
opgeven with permissions Hiermee kunt u gedetailleerde machtigingen verlenen aan individuele databasegebruikers en -rollen. Zonder dit krijgen gebruikers en rollen, als u gebruiksrechten verleent voor de datashare-database, alle rechten voor alle objecten in de datashare-database.
Maak een gebruiker aan en verleen machtigingen aan die gebruiker
Maak een gebruiker aan met behulp van de GEBRUIKER MAKEN opdracht:
Met deze subsidies hebt u de gebruiker gegeven data_engineer alle machtigingen voor alle objecten in de datashare. Bovendien hebt u alle machtigingen die beschikbaar zijn in de schema's verleend als bereikmachtigingen voor data_engineer. Alle machtigingen voor objecten die aan deze schema's zijn toegevoegd, worden automatisch verleend data_engineer.
Op dit punt kunt u doorgaan met de stappen met de beheerder waarmee u momenteel bent aangemeld, of met de data_engineer.
Opties voor het schrijven naar de datashare-database
U kunt op drie manieren gegevens naar de datashare-database schrijven.
Gebruik driedelige notatie terwijl u verbonden bent met een lokale database
Net als bij het delen van leesgegevens kunt u een driedelige notatie gebruiken om naar de datashare-databaseobjecten te verwijzen. Bijvoorbeeld, insert into marketing_ds_db.prod.customer. Houd er rekening mee dat u geen transacties met meerdere verklaringen kunt gebruiken om op deze manier naar objecten in de datashare-database te schrijven.
Maak rechtstreeks verbinding met de datashare-database
U kunt rechtstreeks verbinding maken met de datashare-database via de Redshift JDBC-, ODBC- of Python-driver, naast de Amazon Redshift Data API (nieuw). Om op deze manier verbinding te maken, geeft u de naam van de datashare-database op in de verbindingsreeks. Hierdoor kunt u met tweedelige notatie naar de datashare-database schrijven en transacties met meerdere verklaringen gebruiken om naar de datashare-database te schrijven. Houd er rekening mee dat sommige systeem- en catalogustabellen niet op deze manier beschikbaar zijn.
Voer de use-opdracht uit
Met de opdracht kunt u nu opgeven dat u een andere database wilt gebruiken use <database_name>. Hierdoor kunt u met tweedelige notatie naar de datashare-database schrijven en transacties met meerdere verklaringen gebruiken om naar de datashare-database te schrijven. Houd er rekening mee dat sommige systeem- en catalogustabellen niet op deze manier beschikbaar zijn. Wanneer u systeem- en catalogustabellen opvraagt, zoekt u bovendien naar de systeem- en catalogustabellen van de database waarmee u bent verbonden, en niet naar de database die u gebruikt.
Om deze methode te proberen, voert u de volgende opdracht uit:
Begin met schrijven naar de datashare-database
In deze sectie laten we zien hoe u naar de datashare-database kunt schrijven met behulp van de tweede en derde optie die we hebben besproken (directe verbinding of gebruik opdracht). Wij gebruiken de AWS Labs leverde SQL om naar de datashare-database te schrijven.
Maak een faseringstabel
Maak een tabel binnen het faseringsschema, omdat u bevoegdheden voor het maken van creaties heeft gekregen. We maken een tabel binnen de datashare's staging schema met de volgende DDL-instructie:
U kunt tweedelige notatie gebruiken omdat u de opdracht USE hebt gebruikt of rechtstreeks verbinding hebt gemaakt met de datashare-database. Als dit niet het geval is, moet u ook de datashare-databasenamen opgeven.
Kopieer gegevens naar de verzameltabel
Kopieer de TPCH 10-gegevens van de klant uit de openbare S3-bucket van AWS Labs naar de tabel met behulp van de volgende opdracht:
Hiervoor moet u, net als voorheen, de standaard IAM-rol hebben ingesteld bij het aanmaken van dit magazijn.
Neem Afrikaanse klantgegevens op in de tabel prod.af_customer
Voer de volgende opdracht uit om alleen de Afrikaanse klantgegevens in de tabel op te nemen prod.af_customer:
Hiervoor moet u deelnemen aan de natie- en regiotafels waarvoor u geselecteerde machtigingen heeft.
Kap de verzameltabel af
Je kunt de regie tabel zodat u ernaar kunt schrijven zonder deze in een toekomstige taak opnieuw te maken. De afkapactie wordt transactioneel uitgevoerd en kan worden teruggedraaid als u rechtstreeks bent verbonden met de datashare-database of als u de opdracht use gebruikt (zelfs als u geen datashare-database gebruikt). Gebruik de volgende code:
Op dit punt bent u klaar met het opnemen van de gegevens in de primaire naamruimte. U kunt de af_customer tabel uit zowel het primaire magazijn als het secundaire ETL-magazijn en bekijk dezelfde gegevens.
Conclusie
In dit bericht hebben we laten zien hoe u meerdere magazijnen kunt gebruiken om naar dezelfde database te schrijven. Deze oplossing heeft de volgende voordelen:
- U kunt ingerichte clusters en serverloze werkgroepen van verschillende grootte gebruiken om naar dezelfde databases te schrijven
- U kunt over accounts en regio's schrijven
- Gegevens zijn live en beschikbaar voor alle magazijnen zodra ze zijn vastgelegd
- Schrijfwerk, zelfs als het producentenmagazijn (het magazijn dat eigenaar is van de database) is gepauzeerd
Voor meer informatie over deze functie, zie Zowel lees- als schrijfgegevens delen binnen een AWS-account of tussen accounts (preview). Als u bovendien feedback heeft, kunt u ons een e-mail sturen op dsw-feedback@amazon.com.
Over de auteurs
 Ryan Waldorf is senior productmanager bij Amazon Redshift. Ryan richt zich op functies waarmee klanten rekenkracht kunnen definiëren en schalen, inclusief het delen van gegevens en het schalen van gelijktijdigheid.
Ryan Waldorf is senior productmanager bij Amazon Redshift. Ryan richt zich op functies waarmee klanten rekenkracht kunnen definiëren en schalen, inclusief het delen van gegevens en het schalen van gelijktijdigheid.
 Harshida Patel is een Analytics Specialist Principal Solutions Architect, bij Amazon Web Services (AWS).
Harshida Patel is een Analytics Specialist Principal Solutions Architect, bij Amazon Web Services (AWS).
 Sudipto Das is Senior Principal Engineer bij Amazon Web Services (AWS). Hij leidt de technische architectuur en strategie van meerdere database- en analysediensten in AWS, met speciale aandacht voor Amazon Redshift en Amazon Aurora.
Sudipto Das is Senior Principal Engineer bij Amazon Web Services (AWS). Hij leidt de technische architectuur en strategie van meerdere database- en analysediensten in AWS, met speciale aandacht voor Amazon Redshift en Amazon Aurora.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/improve-your-etl-performance-using-multiple-redshift-warehouses-for-writes/

