Introductie
Het vakgebied van de kunstmatige intelligentie heeft de afgelopen jaren opmerkelijke vooruitgang geboekt, vooral op het gebied van grote taalmodellen. LLM's kunnen mensachtige tekst genereren, documenten samenvatten en softwarecode schrijven. Mistral-7B is een van de recente grote taalmodellen die mogelijkheden voor het genereren van Engelse tekst en code ondersteunen, en kan voor verschillende taken worden gebruikt, zoals tekst samenvatting, classificatie, tekstaanvulling en codeaanvulling.

Wat Mistral-7B-Instruct onderscheidt, is het vermogen om geweldige prestaties te leveren ondanks dat er minder parameters zijn, waardoor het een goed presterende en kosteneffectieve oplossing is. Het model werd onlangs populair nadat uit benchmarkresultaten bleek dat het niet alleen beter presteert dan alle 7B-modellen op MT-Bench, maar ook gunstig concurreert met 13B-chatmodellen. In deze blog zullen we de kenmerken en mogelijkheden van Mistral 7B verkennen, inclusief de gebruiksscenario's, prestaties en een praktische gids voor het verfijnen van het model.
leerdoelen
- Begrijp hoe grote taalmodellen en Mistral 7B werken
- Architectuur van Mistral 7B en benchmarks
- Gebruik cases van Mistral 7B en hoe deze presteert
- Duik diep in de code voor gevolgtrekking en verfijning
Dit artikel is gepubliceerd als onderdeel van het Data Science-blogathon.
Inhoudsopgave
Wat zijn grote taalmodellen?
Grote taalmodellen'architectuur wordt gevormd met transformatoren, die aandachtsmechanismen gebruiken om langeafstandsafhankelijkheden in gegevens vast te leggen, waarbij meerdere lagen transformatorblokken meerkoppige zelfaandacht en feed-forward neurale netwerken bevatten. Deze modellen zijn vooraf getraind op tekstgegevens en leren het volgende woord in een reeks te voorspellen, waardoor de patronen in talen worden vastgelegd. De pre-trainingsgewichten kunnen worden afgestemd op specifieke taken. We zullen specifiek kijken naar de architectuur van Mistral 7B LLM, en wat deze opvalt.
Mistral 7B-architectuur
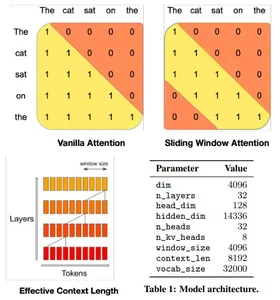
De architectuur van de Mistral 7B-modeltransformator combineert op efficiënte wijze hoge prestaties met geheugengebruik, waarbij gebruik wordt gemaakt van aandachtsmechanismen en cachingstrategieën om grotere modellen qua snelheid en kwaliteit te overtreffen. Het maakt gebruik van Sliding Window Attention (SWA) met 4096 vensters, waardoor de aandacht over langere reeksen wordt gemaximaliseerd door elk token een subset van voorlopertokens te laten behandelen, waardoor de aandacht over langere reeksen wordt geoptimaliseerd.
Een bepaalde verborgen laag heeft toegang tot tokens van invoerlagen op afstanden die worden bepaald door de venstergrootte en laagdiepte. Het model integreert aanpassingen aan Flash Attention en xFormers, waardoor de snelheid ten opzichte van traditionele aandachtsmechanismen wordt verdubbeld. Bovendien handhaaft een Rolling Buffer Cache-mechanisme een vaste cachegrootte voor efficiënt geheugengebruik.
Mistral 7B in Google Colab
Laten we diep in de code duiken en kijken naar het uitvoeren van gevolgtrekkingen met het Mistral 7B-model in Google Colab. We zullen de gratis versie gebruiken met een enkele T4 GPU en het model laden Knuffelend gezicht.
1. Installeer en importeer de ctransformers-bibliotheek in Colab.
#intsall ctransformers
pip install ctransformers[cuda] #import
from ctransformers import AutoModelForCausalLM2. Initialiseer het modelobject vanuit Hugging Face en stel de benodigde parameters in. We zullen een andere versie van het model gebruiken, omdat het originele model van Mistral AI problemen kan hebben met het laden van het hele model in het geheugen van Google Colab.
#load the model from huggingface with 50 gpu layers
llm = AutoModelForCausalLM.from_pretrained("TheBloke/Mistral-7B-Instruct-v0.1-GGUF", model_file="mistral-7b-instruct-v0.1.Q4_K_M.gguf", model_type = "mistral", gpu_layers = 50)3. Definieer een functie om de resultaten verticaal af te drukken in Google Colab. Deze stap kan worden overgeslagen of aangepast als deze in een andere omgeving wordt uitgevoerd.
#function to print the model output in colab in a readable manner
def colab_print(text, max_width = 120): words = text.split() line = "" for word in words: if len(line) + len(word) + 1 > max_width: print(line) line = "" line += word + " " print (line)4. Genereer tekst met behulp van het model en bekijk de resultaten. Wijzig de parameters om de kwaliteit van de gegenereerde tekst te wijzigen.
#generate text
colab_print(llm('''Give me a well-written paragraph in 5 sentences about a Senior Data Scientist (name - Suvojit) who writes blogs on LLMs on Analytics Vidhya. He studied Masters in AIML in BITS Pilani and works at AZ Company, with a total of 4 years of experience. Start the sentence with - Suvojit is a''', max_new_tokens = 2048, temperature = 0.9, top_k = 55, top_p = 0.93, repetition_penalty = 1.2))Modelreactie: Suvojit is een Senior Data Scientist die al vier jaar bij AZ werkt als onderdeel van hun team en zich richt op het ontwerp, de implementatie en de verbetering van voorspellende modellen voor consumentengedrag in de merken en bedrijfslijnen van hun klanten met behulp van Limited Memory Machine Learning-technieken. Hij schrijft over LLM's op Analytics Vidhya, waardoor hij op de hoogte blijft van de nieuwste trends op het gebied van Data Science. Hij heeft een masterdiploma in AIML van BITS Pilani, waar hij machine learning-algoritmen en hun toepassingen bestudeerde. Suvojit gebruikt zijn kennis van datawetenschap met passie om bedrijven te helpen betere beslissingen te nemen en hun prestaties te verbeteren.
Cases
Laten we enkele gebruiksscenario's van de Mistral 7B in meer detail bekijken.
Vertaling
Mistral 7B ondersteunt meerdere talen voor vertaling. Laten we eens kijken naar vertalingen van Engels naar Frans en Spaans en de juistheid ervan controleren.
#translate English to French
colab_print(llm('''Translate this text from English to French: "Suvojit is a Senior Data Scientist who writes blogs on Analytics Vidhya."''', max_new_tokens = 2048, temperature = 0.9, top_k = 55, top_p = 0.93, repetition_penalty = 1.2))Modelreactie: De vertaling zou zijn: “Suvojit est un scientifique des données sénior qui écrit des blogues sur Analytics Vidhya.”
#tranlsate English to Spanish
colab_print(llm('''Translate this text from English to Spanish: "Suvojit is a Senior Data Scientist who writes blogs on Analytics Vidhya."''', max_new_tokens = 2048, temperature = 0.9, top_k = 55, top_p = 0.93, repetition_penalty = 1.2))Modelreactie: De vertaling zou zijn: “Suvojit es un Senior Data Científico que escribe blogs en Analytics Vidhya.”
Samenvattend
Gebruik Mistral 7B om documenten samen te vatten in een kortere versie met behulp van de juiste samenvattingsinstructies.
#Define the prompt with instructions
prompt = '''[INST] You are a helpful code assistant. Your task is to summarize text into exactly two short sentences: Transformers have revolutionized the field of large language models with their ability to capture long-range dependencies and intricate patterns in text. Originating from the paper "Attention Is All You Need" by Vaswani et al. in 2017, transformers introduced the self-attention mechanism, which weighs input tokens differently based on their relevance to a given token. This mechanism enables transformers to process
information more flexibly than traditional RNNs or LSTMs. Consequently, models like GPT, BERT, and their subsequent iterations have been built on the transformer architecture, leading to breakthroughs in numerous natural language processing tasks. Their parallel processing capabilities further make them conducive to training on vast amounts of data. However, as these models grow in size, concerns about their environmental impact and computational demands also emerge. Despite these challenges, the transformative power of transformers in language models remains undeniable. Just summarize the text in exactly 2 short sentences without explanations:
[/INST]''' #Summarize
colab_print(llm(prompt, max_new_tokens = 2048, temperature = 0.9, top_k = 55, top_p = 0.93, repetition_penalty = 1.2))Modelreactie: Transformers hebben een revolutie teweeggebracht in grote taalmodellen door langeafstandsafhankelijkheden en ingewikkelde patronen vast te leggen, een zelfaandachtsmechanisme geïntroduceerd waardoor ze informatie flexibel kunnen verwerken en daaropvolgende implementaties omvatten doorbraken zoals GPT & BERT. Naarmate deze modellen echter groter worden, ontstaan er zorgen over hun impact op het milieu en de computervereisten, ondanks deze uitdagingen blijven ze onmiskenbaar transformatief in taalmodellering.
Aangepaste instructies
We kunnen de tag [INST] gebruiken om de gebruikersinvoer te wijzigen om een bepaald antwoord van het model te krijgen. We kunnen bijvoorbeeld een JSON genereren op basis van tekstbeschrijving.
prompt = '''[INST] You are a helpful code assistant. Your task is to generate a valid JSON object based on the given information: My name is Suvojit Hore, working in company AB and my address is AZ Street NY. Just generate the JSON object without explanations:
[/INST] ''' colab_print(llm(prompt, max_new_tokens = 2048, temperature = 0.9, top_k = 55, top_p = 0.93, repetition_penalty = 1.2))Modelreactie: “`json { “naam”: “Suvojit Hore”, “bedrijf”: “AB”, “adres”: “AZ Street NY” } “`
Mistral 7B nauwkeurig afstellen
Laten we eens kijken hoe we het model kunnen verfijnen met behulp van een enkele GPU op Google Colab. We zullen een dataset gebruiken die beschrijvingen van weinig woorden over afbeeldingen omzet in gedetailleerde en zeer beschrijvende tekst. Deze resultaten kunnen in Midjourney worden gebruikt om het specifieke beeld te genereren. Het doel is om de LLM op te leiden om op te treden als een snelle ingenieur voor het genereren van afbeeldingen.
Richt de omgeving in en importeer de benodigde bibliotheken in Google Colab:
# Install the necessary libraries
!pip install pandas autotrain-advanced -q
!autotrain setup --update-torch
!pip install -q peft accelerate bitsandbytes safetensors #import the necesary libraries
import pandas as pd
import torch
from peft import PeftModel
from transformers import AutoModelForCausalLM, AutoTokenizer
import transformers
from huggingface_hub import notebook_loginLog in op Hugging Face vanuit een browser en kopieer het toegangstoken. Gebruik dit token om in te loggen op Knuffelgezicht in het notitieboekje.
notebook_login()
Upload de dataset naar Colab-sessieopslag. We zullen de Midjourney-dataset gebruiken.
df = pd.read_csv("prompt_engineering.csv")
df.head(5)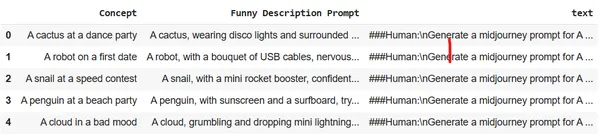
Train het model met behulp van Autotrain met de juiste parameters. Wijzig de onderstaande opdracht om deze uit te voeren voor uw eigen Huggin Face-opslagplaats en gebruikerstoegangstoken.
!autotrain llm --train --project_name mistral-7b-sh-finetuned --model username/Mistral-7B-Instruct-v0.1-sharded --token hf_yiguyfTFtufTFYUTUfuytfuys --data_path . --use_peft --use_int4 --learning_rate 2e-4 --train_batch_size 12 --num_train_epochs 3 --trainer sft --target_modules q_proj,v_proj --push_to_hub --repo_id username/mistral-7b-sh-finetunedLaten we nu het verfijnde model gebruiken om de gevolgtrekkingsengine uit te voeren en enkele gedetailleerde beschrijvingen van de afbeeldingen te genereren.
#adapter and model
adapters_name = "suvz47/mistral-7b-sh-finetuned"
model_name = "bn22/Mistral-7B-Instruct-v0.1-sharded" device = "cuda" #set the config
bnb_config = transformers.BitsAndBytesConfig( load_in_4bit=True, bnb_4bit_use_double_quant=True, bnb_4bit_quant_type="nf4", bnb_4bit_compute_dtype=torch.bfloat16
) #initialize the model
model = AutoModelForCausalLM.from_pretrained( model_name, load_in_4bit=True, torch_dtype=torch.bfloat16, quantization_config=bnb_config, device_map='auto'
)Laad het verfijnde model en de tokenizer.
#load the model and tokenizer
model = PeftModel.from_pretrained(model, adapters_name) tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.bos_token_id = 1 stop_token_ids = [0]Genereer met slechts een paar woorden een gedetailleerde en beschrijvende Midjourney-prompt.
#prompt
text = "[INST] generate a midjourney prompt in less than 20 words for A computer with an emotional chip [/INST]" #encoder and decoder
encoded = tokenizer(text, return_tensors="pt", add_special_tokens=False)
model_input = encoded
model.to(device)
generated_ids = model.generate(**model_input, max_new_tokens=200, do_sample=True)
decoded = tokenizer.batch_decode(generated_ids)
print('nn')
print(decoded[0])Modelreactie: Terwijl de computer met een emotionele chip zijn emoties begint te verwerken, begint hij het bestaan en het doel ervan in twijfel te trekken, wat leidt tot een reis van zelfontdekking en zelfverbetering.
#prompt
text = "[INST] generate a midjourney prompt in less than 20 words for A rainbow chasing its colors [/INST]" #encoder and decoder
encoded = tokenizer(text, return_tensors="pt", add_special_tokens=False)
model_input = encoded
model.to(device)
generated_ids = model.generate(**model_input, max_new_tokens=200, do_sample=True)
decoded = tokenizer.batch_decode(generated_ids)
print('nn')
print(decoded[0])Modelreactie: Een regenboog die kleuren najaagt, bevindt zich in een woestijn waar de lucht een zee van eindeloos blauw is en de kleuren van de regenboog verspreid zijn in het zand.
Conclusie
Mistral 7B is een aanzienlijke vooruitgang gebleken op het gebied van grote taalmodellen. De efficiënte architectuur, gecombineerd met de superieure prestaties, demonstreert zijn potentieel om in de toekomst een hoofdbestanddeel te zijn voor verschillende NLP-taken. Deze blog biedt inzicht in de architectuur van het model, de toepassing ervan, en hoe men de kracht ervan kan benutten voor specifieke taken zoals vertaling, samenvatting en verfijning voor andere toepassingen. Met de juiste begeleiding en experimenten zou Mistral 7B de grenzen van wat mogelijk is met LLM's opnieuw kunnen definiëren.
Key Takeaways
- Mistral-7B-Instruct blinkt uit in prestaties ondanks minder parameters.
- Het maakt gebruik van Sliding Window Attention voor optimalisatie van lange reeksen.
- Functies zoals Flash Attention en xFormers verdubbelen de snelheid.
- Rolling Buffer Cache zorgt voor efficiënt geheugenbeheer.
- Veelzijdig: verzorgt vertalingen, samenvattingen, gestructureerde gegevensgeneratie, tekstgeneratie en tekstaanvulling.
- Door Engineering te vragen aangepaste instructies toe te voegen, kan het model de query beter begrijpen en verschillende complexe taaltaken uitvoeren.
- Verfijn Mistral 7B voor specifieke taaltaken, zoals optreden als snelle ingenieur.
Veelgestelde Vragen / FAQ
A. Mistral-7B is ontworpen voor efficiëntie en prestaties. Hoewel het minder parameters heeft dan sommige andere modellen, zorgen de architectonische verbeteringen, zoals de Sliding Window Attention, ervoor dat het uitstekende resultaten levert en zelfs beter presteert dan grotere modellen bij specifieke taken.
A. Ja, Mistral-7B kan worden afgestemd op verschillende taken. De handleiding geeft een voorbeeld van het verfijnen van het model om korte tekstbeschrijvingen om te zetten in gedetailleerde aanwijzingen voor het genereren van afbeeldingen.
A. Dankzij de Sliding Window Attention (SWA) kan het model langere reeksen efficiënt verwerken. Met een venstergrootte van 4096 optimaliseert SWA de aandachtsbewerkingen, waardoor Mistral-7B lange teksten kan verwerken zonder concessies te doen aan snelheid of nauwkeurigheid.
A. Ja, bij het uitvoeren van Mistral-7B-inferenties raden we u aan de ctransformers-bibliotheek te gebruiken, vooral als u binnen Google Colab werkt. Voor extra gemak kunt u het model ook vanuit Hugging Face laden
A. Het is van cruciaal belang om gedetailleerde instructies op te stellen in de invoerprompt. De veelzijdigheid van de Mistral-7B maakt het mogelijk deze gedetailleerde instructies te begrijpen en op te volgen, waardoor nauwkeurige en gewenste resultaten worden gegarandeerd. Een goede, snelle engineering kan de prestaties van het model aanzienlijk verbeteren.
Referenties
- Miniatuur – Gegenereerd met behulp van stabiele diffusie
- Architectuur – Papier
De in dit artikel getoonde media zijn geen eigendom van Analytics Vidhya en worden naar goeddunken van de auteur gebruikt.
Verwant
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.analyticsvidhya.com/blog/2023/11/from-gpt-to-mistral-7b-the-exciting-leap-forward-in-ai-conversations/

