Introductie
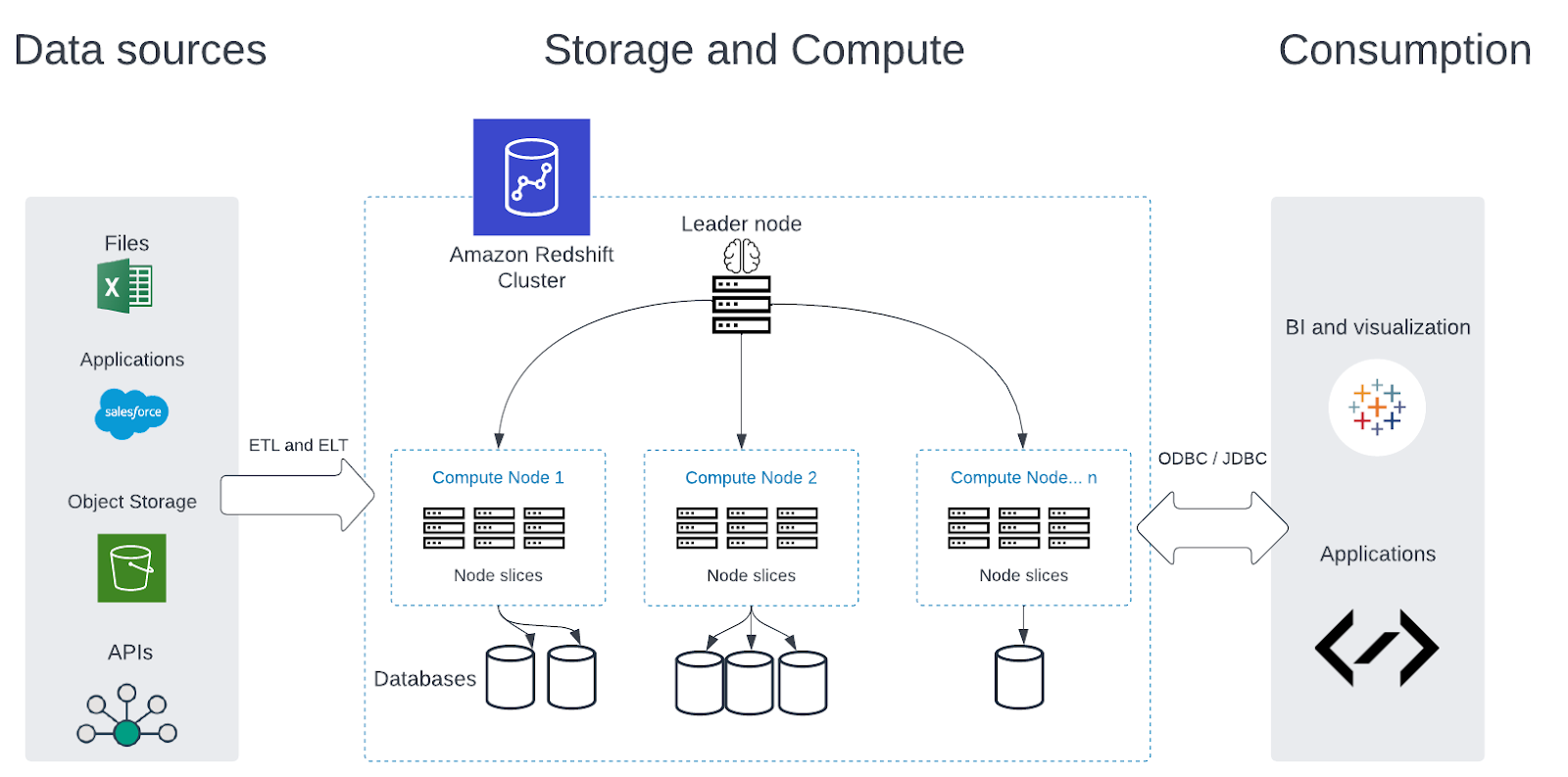
Amazon roodverschuiving is een volledig beheerde datawarehousing op petabyte-schaal Amazon Web Services (AWS). Hiermee kunnen gebruikers eenvoudig een datawarehouse in de cloud opzetten, bedienen en schalen. Redshift gebruikt kolomvormige opslagtechnieken om gegevens op te slaan met behulp van werklastinformatie, rapportage en analyse. Hiermee kunnen gebruikers binnen enkele seconden complexe query's op grote datasets uitvoeren, wat geschikt is voor datawarehousing en business intelligence-toepassingen. Redshift is geïntegreerd met andere AWS-services, EMR en Kinesis, met zijn compliancefuncties om ervoor te zorgen dat gegevens worden beschermd. Hier, in dit artikel, zullen we de top 6 van veelgestelde maar cruciale Amazon Redshift Interview-vragen onderzoeken om je te helpen die droombaan te bemachtigen.

Leerdoelen:
1. We zullen een overzicht geven van Amazon Redshift en het belang ervan in datawarehousing
2. Vervolgens zullen we Redshift-architectuur, schaalbaarheid, prestaties, prijsstelling en gebruiksgemak van het laden en lossen van gegevens in Redshift uitleggen: COPY and UNLOAD-opdracht.
3. Verder maak je kennis met het schalen van Redshift door nodes toe te voegen of te verwijderen.
4. Vervolgens implementeren we beveiliging en toegangscontrole in Redshift: met behulp van AWS Identity and Access Management (IAM) en AWS Resource Access Manager (RAM).
5. Ten slotte zullen we Redshift vergelijken met andere datawarehousing-oplossingen zoals BigQuery, inclusief hun architectuur, schaalbaarheid, prestaties, prijsstelling en gebruiksgemak.
Dit artikel is gepubliceerd als onderdeel van het Data Science-blogathon.
Inhoudsopgave
- Inleiding tot sollicitatievragen bij Amazon Redshift
- leerdoelen
- Wat is het belang en de noodzaak van Amazon Redshift?
- Hoe ga je om met datareplicatie en back-ups in Redshift?
- Hoe implementeer je beveiliging en toegangscontrole in Redshift?
- Hoe optimaliseert u de queryprestaties in Redshift?
- Hoe ga je om met dataretentie en data-archivering in Redshift?
- Leg de verschillen uit tussen Redshift en andere datawarehousing-oplossingen zoals BigQuery?
- Conclusie
Top 6 Amazon Redshift-interviewvragen
Q1. Wat is het belang en de noodzaak van Amazon Redshift?
Amazon Redshift is om verschillende redenen belangrijk:
- schaalbaarheid: Met Redshift kunnen gebruikers hun datawarehouse eenvoudig omhoog of omlaag schalen om aan hun zakelijke behoeften te voldoen. Dit betekent dat de hoeveelheid data groeit. Redshift kan het aan zonder dat het tijd kost.
- Kosten efficiëntie: Redshift is een volledig beheerde service, wat betekent dat AWS alle onderliggende infrastructuur en onderhoud afhandelt. Dit kan kosteneffectiever zijn dan het beheer van een datawarehouse op locatie of het gebruik van een cloudgebaseerde oplossing.
- prestaties: Redshift gebruikt kolomopslagtechnieken om gegevens efficiënt op te slaan, waardoor het in enkele seconden complexe query's op grote datasets kan uitvoeren. Dit maakt datawarehousing en business intelligence-toepassingen mogelijk waarbij snelle queryprestaties van cruciaal belang zijn.
- integratie: Redshift kan eenvoudig worden geïntegreerd met andere AWS-services, EMR en Kinesis, waardoor gebruikers eenvoudig toegang hebben tot hun gegevens en deze kunnen analyseren in de context van andere gegevensbronnen.
- Veiligheid: Redshift en compliance-functie om ervoor te zorgen dat gegevens worden beschermd. Dit omvat codering op en nalevingsnormen 2, PCI DSS en HIPAA.
De behoefte aan Amazon Redshift komt voort uit de groeiende hoeveelheid gegevens die door bedrijven wordt gegenereerd. Deze gegevens zijn vaak opgeslagen in verschillende systemen, waardoor het moeilijk is om toegang te krijgen tot, te analyseren en inzichten te verkrijgen. Datawarehousing-services zoals Redshift bieden een manier om grote hoeveelheden data op één plek te consolideren en te organiseren, waardoor ze bruikbaar worden. Steeds meer bedrijven verplaatsen hun data en workloads naar de cloud. Redshift biedt een manier om de schaalbaarheid en kosteneffectiviteit van de cloud te benutten voor datawarehousing en business intelligence.
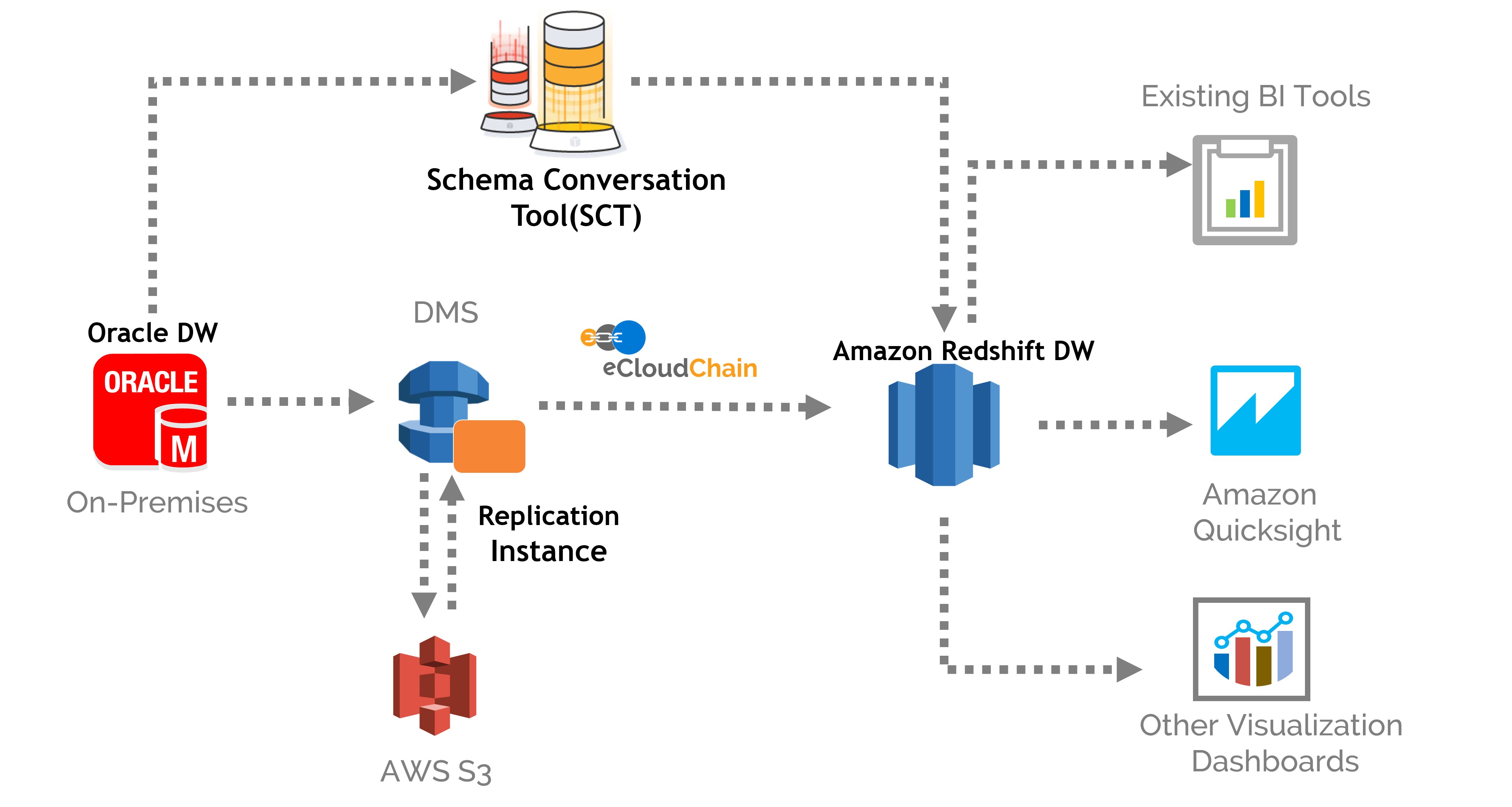
Q2. Hoe ga je om met gegevensreplicatie en back-ups in Redshift?
Het afhandelen van gegevensreplicatie en back-ups in Amazon Redshift omvat verschillende stappen:
Snapshots: Redshift biedt een ingebouwde functie voor het maken van back-ups van gegevens, snapshots genaamd. Snapshots zijn point-in-time back-ups die we kunnen gebruiken om te herstellen. U kunt regelmatige momentopnamen plannen en deze dagen bewaren.
- Kopiëren: U kunt de opdracht "COPY" gebruiken om gegevens van de ene tabel naar de andere te kopiëren. Dit kan handig zijn voor het maken van back-ups van uw gegevens of voor het repliceren van gegevens.
- Replicatie: Redshift ondersteunt multi-AZ-implementaties en biedt automatische failover voor hoge beschikbaarheid en gegevensreplicatie. Hierdoor kunt u een leesreplica maken van een andere back-up en noodherstel.
- encryptie: Redshift ondersteunt de codering van gegevens in rust. Dit kan handig zijn om gegevens te beschermen tijdens een datalek of ander beveiligingsincident.
Het is belangrijk om te onthouden dat gegevensreplicatie en back-ups doorlopende processen zijn. Plan en test regelmatig snapshots en replicatie om er zeker van te zijn dat ze correct werken en dat u uw gegevensfout of gegevensverlies kunt herstellen.
Q3. Hoe implementeer je beveiliging en toegangscontrole in Redshift?
IAM-rollen maken: u kunt AWS Identity and Access Management (IAM) gebruiken om rollen te maken die de toegang beheren. We kunnen deze rollen toewijzen aan gebruikers, groepen of applicaties die toegang nodig hebben.
Beheer netwerktoegang: u kunt een beveiligingsgroep maken. Een virtuele firewall van een beveiligingsgroep die het verkeer regelt.
- VPC gebruiken: Redshift is geïntegreerd met Amazon Virtual Private Cloud (VPC) om virtuele controletoegang te geven tot de controlelijsten (ACL's) en beveiligingsgroepen.
- Gebruik best practices voor beveiliging: Redshift volgt best practices op het gebied van AWS-beveiliging, inclusief protocollen, regelmatige software-updates en monitoring voor beveiligingsgebeurtenissen.
- Toegang tot gegevens beheren: U kunt de ingebouwde beveiligingsfuncties op rijniveau van Redshift gebruiken om de toegang tot gegevens te regelen op basis van gebruikersrollen en vooraf gedefinieerde voorwaarden. Met deze functie kunt u de toegang tot bepaalde rijen in een tabel beperken op basis van specifieke voorwaarden.
- Gebruik multi-factor authenticatie: Multi-factor authenticatie (MFA) biedt beveiliging door van gebruikers te eisen dat ze naast hun wachtwoord authenticatie, vingerafdruk of beveiligingstoken verstrekken.
Q4. Hoe optimaliseert u queryprestaties in roodverschuiving?

Het optimaliseren van queryprestaties in Amazon Redshift omvat verschillende stappen:
- Sorteer sleutels: Redshift gebruikt een zuilvormig opslagmodel en slaat gegevens op een schijf op. Sorteersleutels definiëren de gegevens en versnellen queryprestaties door de hoeveelheid gegevens die moet worden gelezen te verminderen.
- Distributiestijlen: Redshift gebruikt distributiestijlen om te definiëren hoe de gegevens zich in de knooppunten bevinden. We kunnen dit gebruiken om queryprestaties te optimaliseren door gegevens te distribueren op een manier die gegevensverplaatsing vermindert.
- Compressie: Redshift gebruikt compressie om de hoeveelheid schijfopslaggegevens te verminderen. Compressie wordt gebruikt om queryprestaties te versnellen door de hoeveelheid gegevens die moet worden gelezen te verminderen.
- Vacuüm: Redshift gebruikt een vacuümproces om ruimte terug te winnen van verwijderde of bijgewerkte rijen die zijn toegevoegd of bijgewerkt. Uitvoeren verbetert de queryprestaties door de gegevens te behouden.
- Analyseren: Redshift gebruikt het proces Analyseren om statistieken over gegevensdistributie in tabellen bij te werken en betere beslissingen te nemen over het optimaliseren van query's. Het is belangrijk om de statistieken up-to-date te houden.
- Indexeren: U kunt indexen in Redshift gebruiken om queryprestaties te versnellen door de hoeveelheid gegevens die moet worden gescand te verminderen.
- Query optimalisatie: U kunt de Redshift Query Optimizer gebruiken om uw zoekopdrachten te analyseren en aanbevelingen te doen om de prestaties te verbeteren.
- Prestatie monitoring: U kunt de ingebouwde tools voor prestatiebewaking van Redshift, Performance Insights en de systeemtabellen gebruiken om prestatieproblemen te identificeren en op te lossen. Het is belangrijk om te onthouden dat optimalisatie van queryprestaties een doorlopend proces is. Controleer regelmatig uw vragen en prestaties om efficiënt te blijven. Daarnaast is het belangrijk om op de hoogte te blijven van de nieuwste best practices voor queryoptimalisatie en om uw query's in een ontwikkelomgeving te testen voordat u ze implementeert in productie.
Q5. Hoe ga je om met gegevensbewaring en gegevensarchivering in Redshift?
Het afhandelen van gegevensretentie en gegevensarchivering in Amazon Redshift omvat verschillende stappen:
- Dataretentie: Redshift biedt de mogelijkheid om een bewaarperiode voor snapshots in te stellen, die kan worden gebruikt om snapshots te verwijderen die niet automatisch zijn. Dit kan worden gebruikt om ervoor te zorgen dat u alleen de gegevens bewaart die u nodig hebt en om schijfruimte vrij te maken.
- Gegevens archiveren: U kunt de opdracht UNLOAD gebruiken om gegevens van Redshift naar S3 te exporteren en op te slaan in een S3 Glacier- of S3 Glacier Deep Archive-opslagklasse. Dit kan handig zijn voor het archiveren van gegevens die geen actieve analyse zijn, maar die moeten worden bewaard om nalevings- of regelgevingsredenen.
- verdichting: Met Redshift kunnen we tabellen comprimeren die we kunnen gebruiken om de omvang van uw gegevens te verkleinen en de queryprestaties te verbeteren.
- Gegevensbeheer: U kunt de gegevensbeheerfuncties van Redshift, Resource Access Manager (RAM) en AWS Identity and Access Management (IAM) gebruiken om gegevenstoegang te controleren en ervoor te zorgen dat gegevens worden gebruikt in overeenstemming met het beleid.
- Gegevenslevenscyclusbeheer: U kunt AWS Glue Data Catalog gebruiken om tabellen en partities te maken, bij te werken en te verwijderen, beleid voor het bewaren van gegevens in te stellen en gegevens te archiveren.
Het is belangrijk om te onthouden dat het bewaren en archiveren van gegevens doorlopende processen zijn. Controleer uw gegevens regelmatig om ervoor te zorgen dat u alleen de gegevens bewaart die u nodig hebt en dat u gegevens archiveert die geen actieve analyse zijn. Daarnaast is het belangrijk dat uw processen voor het archiveren en bewaren van gegevens ervoor zorgen dat ze goed werken en dat u uw gegevensfout of gegevensverlies kunt herstellen. Dit is een van de meest gestelde interviewvragen van Amazon Redshift.
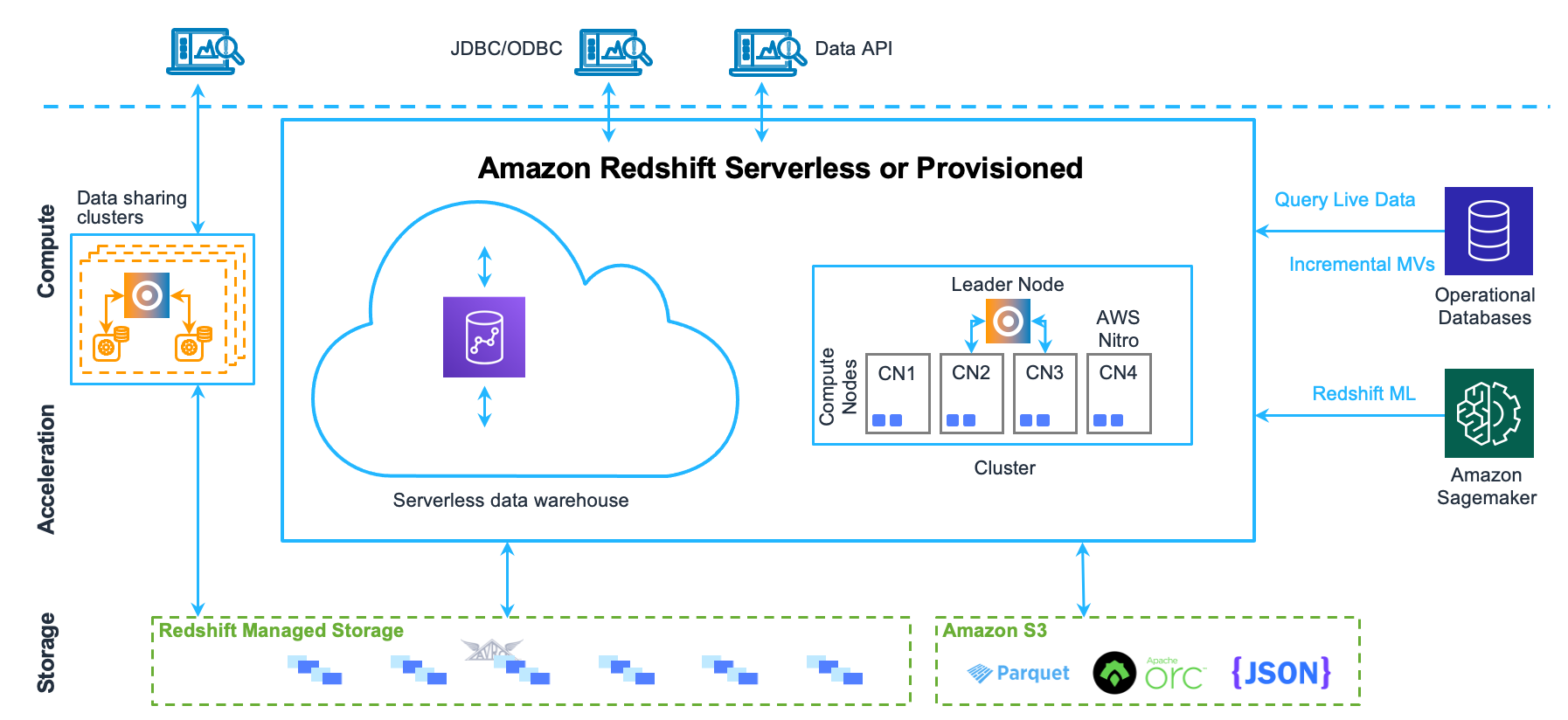
Q6. Leg de verschillen uit tussen Redshift en andere datawarehousing-oplossingen zoals BigQuery?
De laatste van alle Amazon Redshift-interviewvragen - Amazon Redshift, Snowflake en BigQuery zijn allemaal populaire oplossingen voor datawarehousing, maar ze hebben enkele verschillen die ze van elkaar onderscheiden:
- architectuur: Redshift gebruikt een zuilvormige opslagarchitectuur, terwijl Snowflake een unieke multi-cloudarchitectuur gebruikt die opslag en computergebruik scheidt. BigQuery gebruikt een combinatie van kolomopslag en op rijen gebaseerde verwerking.
- schaalbaarheid: Met Redshift kunt u uw groep schalen door knooppunten toe te voegen of te verwijderen, terwijl Snowflake volledig serverloos is en automatisch uw computer- en opslaggegevens naar behoefte schaalt. BigQuery kan uw bronnen opschalen en vereist handmatige tussenkomst.
- prestaties: Redshift heeft sterke prestatiekenmerken, vooral voor complexe analytische werklasten. De unieke architectuur van Snowflake is ontworpen om hoge prestaties en lage latentie te bieden, met name voor leesintensieve workloads. BigQuery biedt snelle prestaties, met name voor grootschalige gegevensverwerking en batchquery's.
- Prijzen: Redshift brengt kosten in rekening op basis van de grootte van uw groep en de hoeveelheid gegevens die u opslaat, terwijl Snowflake kosten in rekening brengt op basis van de hoeveelheid gegevens die u opslaat en de computerbronnen die u gebruikt. BigQuery brengt kosten in rekening op basis van de hoeveelheid gegevens die u opslaat en het aantal query's dat u uitvoert.
- Gebruiksgemak: Hulpprogramma's voor laden en beheer van Redshift. Snowflake biedt een cloudgebaseerde, volledig beheerde oplossing met een eenvoudige. BigQuery biedt eenvoudige API's voor programmatische toegang.
Integratie met andere AWS-services: Redshift is volledig geïntegreerd met andere AWS-services, S3, Amazon EC2 en Amazon Athena, waardoor het eenvoudig is om gegevens tussen deze services te verplaatsen. Snowflake biedt vergelijkbare integratie met AWS en andere cloudproviders. BigQuery biedt native integratie met andere Google Cloud-services, zoals Cloud Storage.
Over het algemeen is de keuze tussen Redshift, Snowflake en BigQuery uw specifieke behoeften op het gebied van datawarehousing, inclusief de omvang en complexiteit van uw gegevens, de prestatievereisten van uw workloads en uw budget. Het is belangrijk om elke oplossing zorgvuldig te evalueren om te bepalen welke de beste is.
Conclusie
Concluderend, Amazon Redshift is een krachtige datawarehousing-service waarmee bedrijven op een kosteneffectieve manier grote hoeveelheden gegevens kunnen opslaan, analyseren en ophalen. Redshift biedt COPY- en UNLOAD-opdrachten om het laden en ontladen van gegevens af te handelen. Om te schalen en de functie "Formaat wijzigen" te gebruiken, waarmee u knooppunten kunt toevoegen of verwijderen. Om de queryprestaties in Redshift te optimaliseren, moeten we distributiestijlen, compressie, vacuüm, analyse en indexering en Redshift Query Optimizer gebruiken. Ten slotte kunt u voor het bewaren en archiveren van gegevens in Redshift de opdracht UNLOAD, partitionering, verdichting, gegevensbeheer en gegevenslevenscyclusbeheerfuncties gebruiken. Het is belangrijk om te onthouden dat al deze lopende taken moeten worden beoordeeld en getest om de beste prestaties en beveiliging te garanderen.
Belangrijkste punten van dit artikel:
1. Ten eerste bespraken we een van de meest cruciale onderwerpen die in een Amazon Redshift-interview werden gesteld: wat Amazon Redshift is en de noodzaak en het belang ervan.
2. Daarna bespraken we enkele veelvoorkomende interviewgerichte vragen die kunnen worden gesteld in een Amazon Redshift-interview, zoals het schalen van de architectuur, het optimaliseren van de vragen, enz.
3. Ten slotte bespraken we de vergelijking van Redshift met andere architecturen zoals BigQuery en sloten toen dat artikel af. Eindelijk wat youtube-links, die je zullen helpen dat onderwerp beter te begrijpen.
Videobronnen om rekening mee te houden
Hier zijn enkele videobronnen die u kunt gebruiken om meer te weten te komen over de onderwerpen die we hebben besproken:
- Overzicht van Amazon Redshift
- Gegevens laden en lossen in Redshift
- Een Redshift-cluster schalen
- Bewaken en oplossen van prestatieproblemen in Redshift
- Beveiliging en toegangscontrole implementeren in Redshift
- Omgaan met gegevensreplicatie en back-ups in Redshift
Deze video's zouden een goed startpunt moeten zijn om meer te weten te komen over elk onderwerp dat we hebben besproken. Zoals bij elke videobron is het echter belangrijk om relevante documentatie te lezen en praktijkoefeningen te doen om een beter begrip van elk onderwerp te krijgen.
De in dit artikel getoonde media zijn geen eigendom van Analytics Vidhya en worden naar goeddunken van de auteur gebruikt.
Verwant
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://www.analyticsvidhya.com/blog/2023/02/top-6-amazon-redshift-interview-questions/

