Data-engineering speelt een cruciale rol in het enorme data-ecosysteem door het verzamelen, transformeren en leveren van gegevens die essentieel zijn voor analyse, rapportage en machine learning. Aspirant-data-ingenieurs zoeken vaak naar projecten in de echte wereld om praktijkervaring op te doen en hun expertise te demonstreren. Dit artikel presenteert de twintig beste data-engineeringprojectideeën met hun broncode. Of u nu een beginner, een ingenieur op gemiddeld niveau of een gevorderde beoefenaar bent, deze projecten bieden een uitstekende gelegenheid om uw vaardigheden op het gebied van data-engineering aan te scherpen.
Inhoudsopgave
Data-engineeringprojecten voor beginners
1. Slimme IoT-infrastructuur
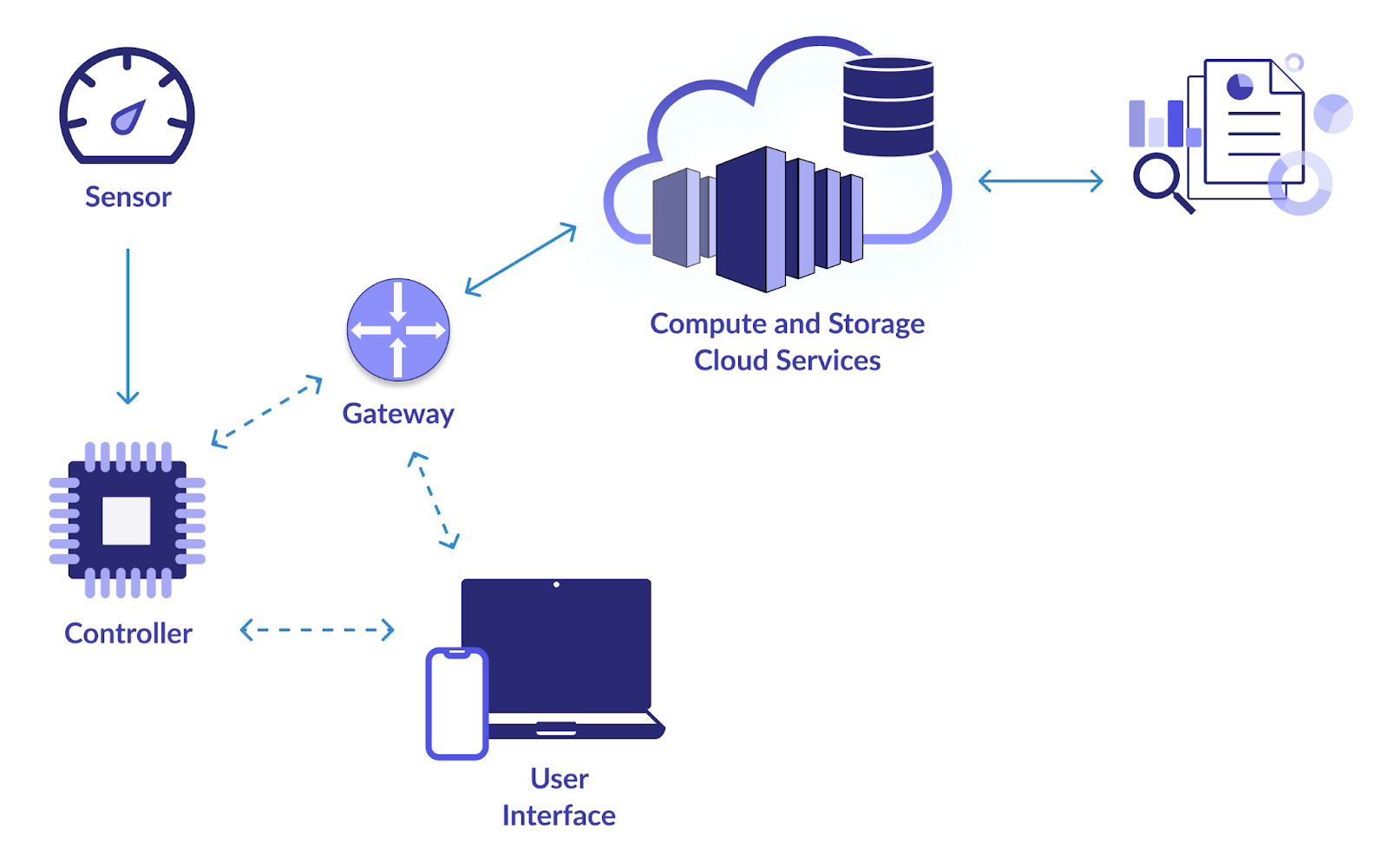
Objectief
Het belangrijkste doel van dit project is het opzetten van een betrouwbare datapijplijn voor het verzamelen en analyseren van gegevens van IoT-apparaten (Internet of Things). Webcams, temperatuursensoren, bewegingsdetectoren en andere IoT-apparaten genereren allemaal veel gegevens. U wilt een systeem ontwerpen om deze gegevens effectief te consumeren, op te slaan, te verwerken en te analyseren. Door dit te doen, wordt realtime monitoring en besluitvorming op basis van de lessen uit de IoT-gegevens mogelijk gemaakt.
Hoe op te lossen?
- Maak gebruik van technologieën zoals Apache Kafka of MQTT voor efficiënte gegevensopname vanaf IoT-apparaten. Deze technologieën ondersteunen datastromen met hoge doorvoer.
- Gebruik schaalbare databases zoals Apache Cassandra of MongoDB om de binnenkomende IoT-gegevens op te slaan. Deze NoSQL-databases kunnen het volume en de verscheidenheid aan IoT-gegevens aan.
- Implementeer realtime gegevensverwerking met Apache Spark Streaming of Apache Flink. Met deze raamwerken kunt u gegevens analyseren en transformeren zodra deze binnenkomen, waardoor deze geschikt worden voor realtime monitoring.
- Gebruik visualisatietools zoals Grafana of Kibana om dashboards te maken die inzicht bieden in de IoT-gegevens. Realtime visualisaties kunnen belanghebbenden helpen weloverwogen beslissingen te nemen.
Klik hier om de broncode te controleren
2. Analyse van luchtvaartgegevens

Objectief
Om luchtvaartgegevens uit talloze bronnen, waaronder de Federal Aviation Administration (FAA), luchtvaartmaatschappijen en luchthavens, te verzamelen, verwerken en analyseren, probeert dit project een datapijplijn te ontwikkelen. Luchtvaartgegevens omvatten vluchten, luchthavens, het weer en demografische gegevens van passagiers. Jouw doel is om betekenisvolle inzichten uit deze gegevens te halen om de vluchtplanning te verbeteren, veiligheidsmaatregelen te verbeteren en verschillende aspecten van de luchtvaartindustrie te optimaliseren.
Hoe op te lossen?
- Apache Nifi of AWS Kinesis kunnen worden gebruikt voor gegevensopname uit verschillende bronnen.
- Bewaar de verwerkte gegevens in datawarehouses zoals Amazon Redshift of Google BigQuery voor efficiënte bevraging en analyse.
- Gebruik Python met bibliotheken zoals Pandas en Matplotlib om diepgaande luchtvaartgegevens te analyseren. Hierbij kan het gaan om het identificeren van patronen in vluchtvertragingen, het optimaliseren van routes en het evalueren van passagierstrends.
- Tools zoals Tableau of Power BI kunnen worden gebruikt om informatieve visualisaties te creëren die belanghebbenden helpen datagestuurde beslissingen te nemen in de luchtvaartsector.
Klik hier om de broncode te bekijken
3. Voorspelling van de vraag naar verzending en distributie
Objectief
In dit project is het uw doel om een robuuste ETL-pijplijn (Extract, Transform, Load) te creëren die verzend- en distributiegegevens verwerkt. Door gebruik te maken van historische gegevens bouwt u een vraagvoorspellingssysteem dat de toekomstige productvraag in de context van verzending en distributie voorspelt. Dit is cruciaal voor het optimaliseren van het voorraadbeheer, het verlagen van de operationele kosten en het garanderen van tijdige leveringen.
Hoe op te lossen?
- Apache NiFi of Talend kan worden gebruikt om de ETL-pijplijn te bouwen, die gegevens uit verschillende bronnen zal extraheren, transformeren en in een geschikte oplossing voor gegevensopslag laden.
- Gebruik tools zoals Python of Apache Spark voor gegevenstransformatietaken. Mogelijk moet u gegevens opschonen, aggregeren en voorbewerken om deze geschikt te maken voor prognosemodellen.
- Implementeer voorspellingsmodellen zoals ARIMA (AutoRegressive Integrated Moving Average) of Prophet om de vraag nauwkeurig te voorspellen.
- Bewaar de opgeschoonde en getransformeerde gegevens in databases zoals PostgreSQL of MySQL.
Klik hier om de broncode voor dit data-engineeringproject te bekijken,
4. Analyse van gebeurtenisgegevens

Objectief
Maak een datapijplijn die informatie verzamelt van verschillende evenementen, waaronder conferenties, sportevenementen, concerten en sociale bijeenkomsten. Realtime gegevensverwerking, sentimentanalyse van socialemediaberichten over deze evenementen en het creëren van visualisaties om trends en inzichten in realtime te tonen, maken allemaal deel uit van het project.
Hoe op te lossen?
- Afhankelijk van de gebeurtenisgegevensbronnen kunt u de Twitter API gebruiken voor het verzamelen van tweets, webscraping voor gebeurtenisgerelateerde websites of andere methoden voor gegevensopname.
- Gebruik Natural Language Processing (NLP)-technieken in Python om sentimentanalyses uit te voeren op posts op sociale media. Tools zoals NLTK of spaCy kunnen waardevol zijn.
- Gebruik streamingtechnologieën zoals Apache Kafka of Apache Flink voor realtime gegevensverwerking en -analyse.
- Creëer interactieve dashboards en visualisaties met behulp van frameworks zoals Dash of Plotly om gebeurtenisgerelateerde inzichten in een gebruiksvriendelijk formaat te presenteren.
Klik hier om de broncode te controleren.
5. Log Analytics-project
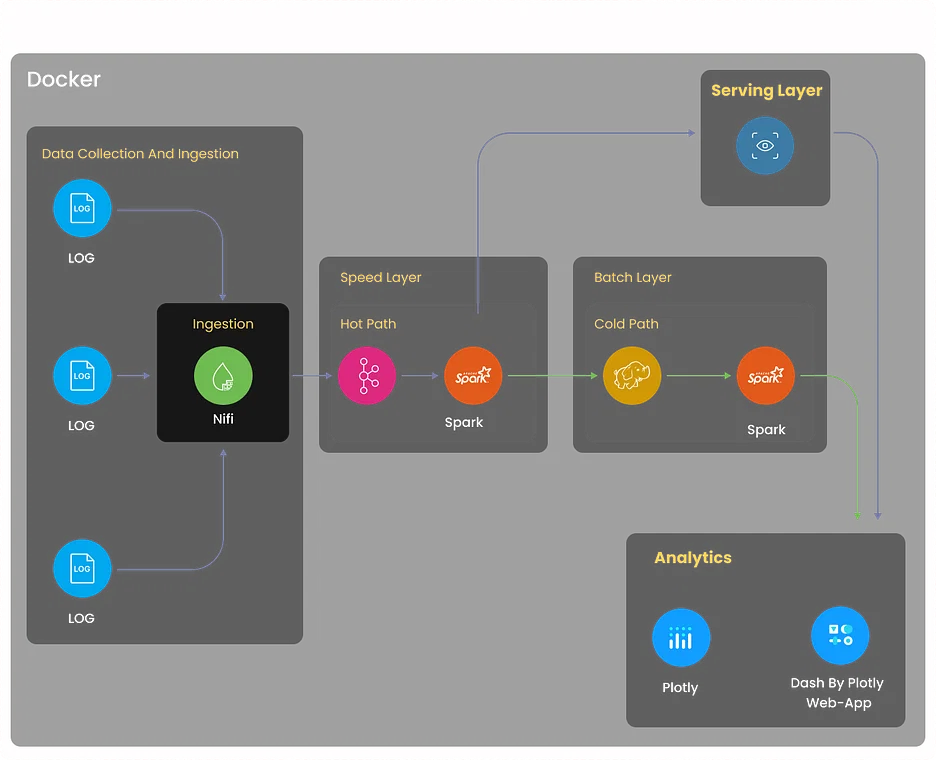
Objectief
Bouw een uitgebreid loganalysesysteem dat logbestanden verzamelt van verschillende bronnen, waaronder servers, applicaties en netwerkapparaten. Het systeem moet loggegevens centraliseren, afwijkingen detecteren, probleemoplossing vergemakkelijken en de systeemprestaties optimaliseren door middel van op logs gebaseerde inzichten.
Hoe op te lossen?
- Implementeer het verzamelen van logboeken met behulp van tools zoals Logstash of Fluentd. Deze tools kunnen logbestanden uit diverse bronnen samenvoegen en normaliseren voor verdere verwerking.
- Gebruik Elasticsearch, een krachtige gedistribueerde zoek- en analyse-engine, om loggegevens efficiënt op te slaan en te indexeren.
- Gebruik Kibana om dashboards en visualisaties te maken waarmee gebruikers loggegevens in realtime kunnen volgen.
- Stel waarschuwingsmechanismen in met Elasticsearch Watcher of Grafana Alerts om relevante belanghebbenden op de hoogte te stellen wanneer specifieke logpatronen of afwijkingen worden gedetecteerd.
Klik hier om dit data-engineeringproject te verkennen
6. Movielens-gegevensanalyse voor aanbevelingen

Objectief
- Ontwerp en ontwikkel een aanbevelingsengine met behulp van de Movielens-dataset.
- Creëer een robuuste ETL-pijplijn om de gegevens voor te verwerken en op te schonen.
- Implementeer collaboratieve filteralgoritmen om gebruikers gepersonaliseerde filmaanbevelingen te bieden.
Hoe op te lossen?
- Maak gebruik van Apache Spark of AWS Glue om een ETL-pijplijn te bouwen die film- en gebruikersgegevens extraheert, deze omzet in een geschikt formaat en deze in een oplossing voor gegevensopslag laadt.
- Implementeer collaboratieve filtertechnieken, zoals op gebruikers of items gebaseerd collaboratief filteren, met behulp van bibliotheken zoals Scikit-learn of TensorFlow.
- Bewaar de opgeschoonde en getransformeerde gegevens in oplossingen voor gegevensopslag zoals Amazon S3 of Hadoop HDFS.
- Ontwikkel een webgebaseerde applicatie (bijvoorbeeld met Flask of Django) waar gebruikers hun voorkeuren kunnen invoeren, en de aanbevelingsengine biedt gepersonaliseerde filmaanbevelingen.
Klik hier om dit data-engineeringproject te verkennen.
7. Retailanalyseproject
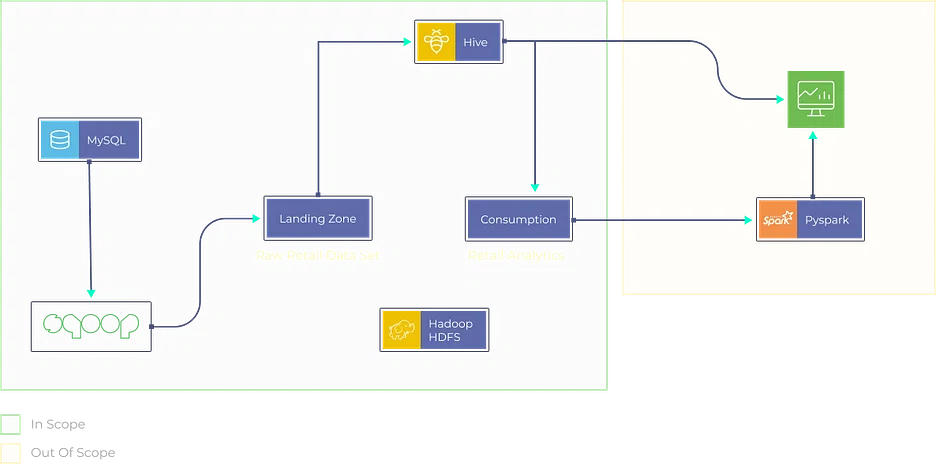
Objectief
Creëer een retailanalyseplatform dat gegevens uit verschillende bronnen opneemt, waaronder verkooppuntsystemen, voorraaddatabases en klantinteracties. Analyseer verkooptrends, optimaliseer het voorraadbeheer en genereer gepersonaliseerde productaanbevelingen voor klanten.
Hoe op te lossen?
- Implementeer ETL-processen met behulp van tools zoals Apache Beam of AWS Data Pipeline om gegevens uit retailbronnen te extraheren, transformeren en laden.
- Maak gebruik van machine learning-algoritmen zoals XGBoost of Random Forest voor verkoopvoorspelling en voorraadoptimalisatie.
- Bewaar en beheer gegevens in datawarehousing-oplossingen zoals Snowflake of Azure Synapse Analytics voor efficiënte query's.
- Creëer interactieve dashboards met behulp van tools als Tableau of Looker om inzichten in retailanalyses te presenteren in een visueel aantrekkelijk en begrijpelijk formaat.
Klik hier om de broncode te verkennen.
Data-engineeringprojecten op GitHub
8. Realtime gegevensanalyse
Objectief
Draag bij aan een open-sourceproject gericht op realtime data-analyse. Dit project biedt de mogelijkheid om de gegevensverwerkingssnelheid, de schaalbaarheid en de real-time visualisatiemogelijkheden van het project te verbeteren. Mogelijk krijgt u de taak om de prestaties van componenten voor gegevensstreaming te verbeteren, het gebruik van bronnen te optimaliseren of nieuwe functies toe te voegen ter ondersteuning van gebruiksscenario's voor realtime analyse.
Hoe op te lossen?
De oplossingsmethode hangt af van het project waaraan je bijdraagt, maar vaak gaat het om technologieën als Apache Flink, Spark Streaming of Apache Storm.
Klik hier om de broncode voor dit data-engineeringproject te verkennen.
9. Realtime gegevensanalyse met Azure Stream Services

Objectief
Verken Azure Stream Analytics door bij te dragen aan of een realtime gegevensverwerkingsproject op Azure te maken. Dit kan gepaard gaan met de integratie van Azure-services zoals Azure Functions en Power BI om inzichten te verkrijgen en realtime gegevens te visualiseren. U kunt zich concentreren op het verbeteren van de realtime analysemogelijkheden en het gebruiksvriendelijker maken van het project.
Hoe op te lossen?
- Geef een duidelijke omschrijving van de doelstellingen en vereisten van het project, inclusief gegevensbronnen en gewenste inzichten.
- Creëer een Azure Stream Analytics-omgeving, configureer invoer/uitvoer en integreer Azure Functions en Power BI.
- Neem realtime gegevens op en pas de noodzakelijke transformaties toe met behulp van SQL-achtige query's.
- Implementeer aangepaste logica voor realtime gegevensverwerking met behulp van Azure Functions.
- Stel Power BI in voor realtime datavisualisatie en zorg voor een gebruiksvriendelijke ervaring.
Klik hier om de broncode voor dit data-engineeringproject te verkennen.
10. Realtime pijplijn met financiële marktgegevens met Finnhub API en Kafka
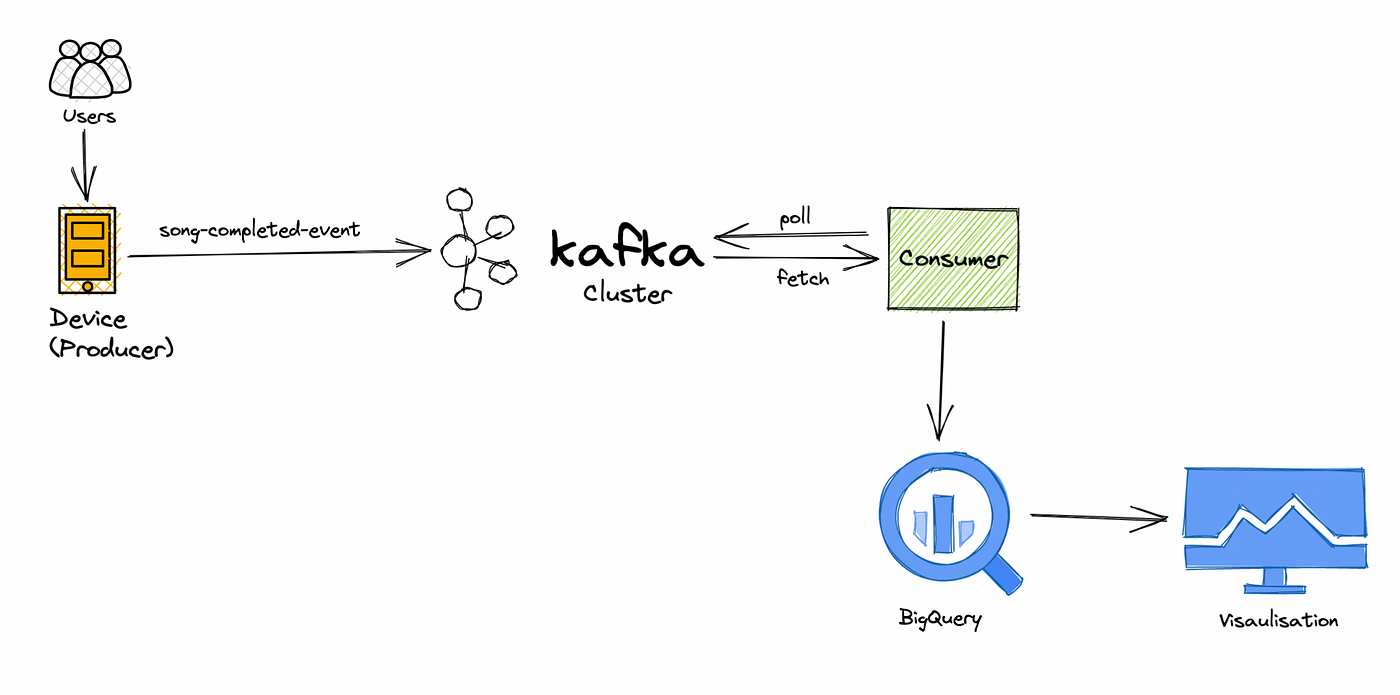
Objectief
Bouw een datapijplijn die realtime financiële marktgegevens verzamelt en verwerkt met behulp van de Finnhub API en Apache Kafka. Dit project omvat het analyseren van aandelenkoersen, het uitvoeren van sentimentanalyses op nieuwsgegevens en het visualiseren van realtime markttrends. Bijdragen kunnen bestaan uit het optimaliseren van de gegevensopname, het verbeteren van de gegevensanalyse of het verbeteren van de visualisatiecomponenten.
Hoe op te lossen?
- Geef een duidelijke omschrijving van de doelstellingen van het project, waaronder het verzamelen en verwerken van realtime financiële marktgegevens en het uitvoeren van aandelenanalyses en sentimentanalyses.
- Creëer een datapijplijn met Apache Kafka en de Finnhub API om realtime marktgegevens te verzamelen en te verwerken.
- Analyseer aandelenkoersen en voer sentimentanalyses uit op nieuwsgegevens binnen de pijplijn.
- Visualiseer realtime markttrends en overweeg optimalisaties voor gegevensopname en -analyse.
- Ontdek mogelijkheden om de gegevensverwerking te optimaliseren, de analyse te verbeteren en de visualisatiecomponenten gedurende het hele project te verbeteren.
Klik hier om de broncode voor dit project te verkennen.
11. Pijplijn voor verwerking van realtime muziekapplicatiegegevens
Objectief
Werk samen aan een realtime dataproject voor muziekstreaming, gericht op het in realtime verwerken en analyseren van gegevens over gebruikersgedrag. Je onderzoekt gebruikersvoorkeuren, houdt populariteit bij en verbetert het muziekaanbevelingssysteem. Bijdragen kunnen bestaan uit het verbeteren van de efficiëntie van de gegevensverwerking, het implementeren van geavanceerde aanbevelingsalgoritmen of het ontwikkelen van realtime dashboards.
Hoe op te lossen?
- Definieer duidelijk projectdoelen, met de nadruk op realtime analyse van gebruikersgedrag en verbetering van muziekaanbevelingen.
- Werk samen aan realtime gegevensverwerking om gebruikersvoorkeuren te onderzoeken, populariteit te volgen en het aanbevelingssysteem te verfijnen.
- Identificeer en implementeer efficiëntieverbeteringen binnen de dataverwerkingspijplijn.
- Ontwikkel en integreer geavanceerde aanbevelingsalgoritmen om het systeem te verbeteren.
- Creëer realtime dashboards voor het monitoren en visualiseren van gegevens over gebruikersgedrag, en overweeg voortdurende verbeteringen.
Klik hier om de broncode te verkennen.
Geavanceerde data-engineeringprojecten voor CV
12. Website Monitoring

Objectief
Ontwikkel een uitgebreid websitemonitoringsysteem dat de prestaties, uptime en gebruikerservaring bijhoudt. Dit project omvat het gebruik van tools zoals Selenium voor webscraping om gegevens van websites te verzamelen en waarschuwingsmechanismen te creëren voor realtime meldingen wanneer prestatieproblemen worden gedetecteerd.
Hoe op te lossen?
- Definieer projectdoelstellingen, waaronder het bouwen van een websitemonitoringsysteem voor het volgen van de prestaties en uptime, en het verbeteren van de gebruikerservaring.
- Gebruik Selenium voor webscraping om gegevens van doelwebsites te verzamelen.
- Implementeer realtime waarschuwingsmechanismen om te waarschuwen wanneer prestatieproblemen of downtime worden gedetecteerd.
- Creëer een uitgebreid systeem om de prestaties, uptime en gebruikerservaring van websites bij te houden.
- Plan voor doorlopend onderhoud en optimalisatie van het monitoringsysteem om de effectiviteit ervan in de loop van de tijd te garanderen.
Klik hier om de broncode van dit data-engineeringproject te verkennen.
13. Bitcoin-mijnbouw

Objectief
Duik in de cryptocurrency-wereld door een Bitcoin-mijndatapijplijn te creëren. Analyseer transactiepatronen, verken het blockchain-netwerk en krijg inzicht in het Bitcoin-ecosysteem. Dit project vereist gegevensverzameling van blockchain-API's, analyse en visualisatie.
Hoe op te lossen?
- Definieer de doelstellingen van het project, met de nadruk op het creëren van een Bitcoin-mijndatapijplijn voor transactieanalyse en blockchain-verkenning.
- Implementeer mechanismen voor gegevensverzameling vanuit blockchain-API's voor mijnbouwgerelateerde gegevens.
- Duik in blockchain-analyse om transactiepatronen te onderzoeken en inzicht te krijgen in het Bitcoin-ecosysteem.
- Ontwikkel componenten voor datavisualisatie om Bitcoin-netwerkinzichten effectief weer te geven.
- Creëer een uitgebreide datapijplijn die het verzamelen, analyseren en visualiseren van gegevens omvat voor een holistisch beeld van Bitcoin-mijnbouwactiviteiten.
Klik hier om de broncode voor dit data-engineeringproject te verkennen.
14. GCP-project om cloudfuncties te verkennen

Objectief
Ontdek Google Cloud Platform (GCP) door een data-engineeringproject te ontwerpen en te implementeren dat gebruikmaakt van GCP-services zoals Cloud Functions, BigQuery en Dataflow. Dit project kan gegevensverwerkings-, transformatie- en visualisatietaken omvatten, waarbij de nadruk ligt op het optimaliseren van het gebruik van bronnen en het verbeteren van de data-engineeringworkflows.
Hoe op te lossen?
- Definieer de reikwijdte van het project duidelijk en leg de nadruk op het gebruik van GCP-services voor data-engineering, waaronder Cloud Functions, BigQuery en Dataflow.
- Ontwerp en implementeer de integratie van GCP-services en zorg voor een efficiënt gebruik van Cloud Functions, BigQuery en Dataflow.
- Voer gegevensverwerkings- en transformatietaken uit als onderdeel van het project, in lijn met de overkoepelende doelen.
- Focus op het optimaliseren van het resourcegebruik binnen de GCP-omgeving om de efficiëntie te verbeteren.
- Zoeken naar mogelijkheden om de data-engineering-workflows gedurende de hele levenscyclus van het project te verbeteren, met als doel gestroomlijnde en effectieve processen.
Klik hier om de broncode voor dit project te verkennen.
15. Reddit-gegevens visualiseren
Objectief
Verzamel en analyseer gegevens van Reddit, een van de populairste sociale-mediaplatforms. Creëer interactieve visualisaties en krijg inzicht in gebruikersgedrag, trending topics en sentimentanalyse op het platform. Dit project vereist webscraping, data-analyse en creatieve datavisualisatietechnieken.
Hoe op te lossen?
- Definieer de doelstellingen van het project, waarbij de nadruk ligt op het verzamelen en analyseren van gegevens van Reddit om inzicht te krijgen in gebruikersgedrag, trending topics en sentimentanalyse.
- Implementeer webscraping-technieken om gegevens van het Reddit-platform te verzamelen.
- Duik in data-analyse om gebruikersgedrag te onderzoeken, trending topics te identificeren en sentimentanalyses uit te voeren.
- Creëer interactieve visualisaties om op effectieve wijze inzichten uit de Reddit-gegevens over te brengen.
- Gebruik innovatieve datavisualisatietechnieken om de presentatie van bevindingen gedurende het hele project te verbeteren.
Klik hier om de broncode voor dit project te verkennen.
Azure Data Engineering-projecten
16. Yelp-gegevensanalyse

Objectief
In dit project is het jouw doel om Yelp-gegevens uitgebreid te analyseren. Je bouwt een datapijplijn om Yelp-gegevens te extraheren, transformeren en laden in een geschikte opslagoplossing. De analyse kan betrekking hebben op:
- Populaire bedrijven identificeren.
- Analyseren van het sentiment van gebruikersrecensies.
- Het verstrekken van inzichten aan lokale bedrijven om hun dienstverlening te verbeteren.
Hoe op te lossen?
- Gebruik webscrapingtechnieken of de Yelp API om gegevens te extraheren.
- Gegevens opschonen en voorverwerken met Python of Azure Data Factory.
- Sla gegevens op in Azure Blob Storage of Azure SQL Data Warehouse.
- Voer data-analyse uit met behulp van Python-bibliotheken zoals Pandas en Matplotlib.
Klik hier om de broncode voor dit project te verkennen.
17. Gegevensbeheer
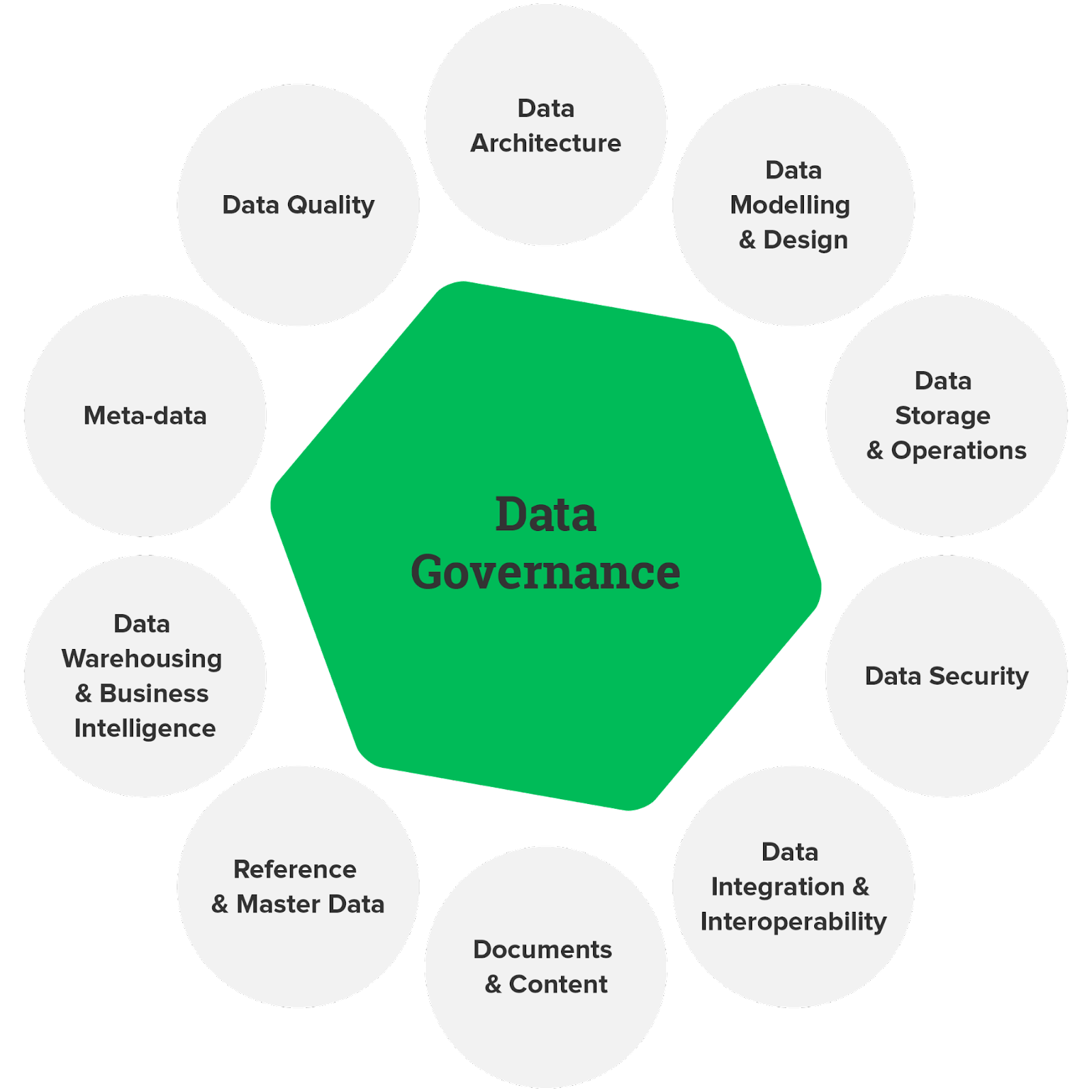
Objectief
Gegevensbeheer is van cruciaal belang voor het waarborgen van de gegevenskwaliteit, compliance en beveiliging. In dit project ontwerp en implementeer je een data governance framework met behulp van Azure-services. Dit kan het definiëren van databeleid inhouden, het creëren van datacatalogi en het opzetten van datatoegangscontroles om ervoor te zorgen dat data op verantwoorde wijze en in overeenstemming met de regelgeving worden gebruikt.
Hoe op te lossen?
- Gebruik Azure Purview om een catalogus te maken die gegevensassets documenteert en classificeert.
- Implementeer gegevensbeleid met behulp van Azure Policy en Azure Blueprints.
- Stel op rollen gebaseerd toegangsbeheer (RBAC) en Azure Active Directory-integratie in om gegevenstoegang te beheren.
Klik hier om de broncode voor dit data-engineeringproject te verkennen.
18. Realtime gegevensopname

Objectief
Ontwerp een realtime pijplijn voor gegevensopname op Azure met behulp van services zoals Azure Data Factory, Azure Stream Analytics en Azure Event Hubs. Het doel is om gegevens uit verschillende bronnen op te nemen en deze in realtime te verwerken, waardoor onmiddellijke inzichten worden verkregen voor de besluitvorming.
Hoe op te lossen?
- Gebruik Azure Event Hubs voor gegevensopname.
- Implementeer realtime gegevensverwerking met Azure Stream Analytics.
- Bewaar verwerkte gegevens in Azure Data Lake Storage of Azure SQL Database.
- Visualiseer realtime inzichten met Power BI of Azure Dashboards.
lik hier om de broncode voor dit project te verkennen.
AWS Data Engineering-projectideeën
19. ETL-pijplijn

Objectief
Bouw een end-to-end ETL-pijplijn (Extract, Transform, Load) op AWS. De pijplijn moet gegevens uit verschillende bronnen extraheren, transformaties uitvoeren en de verwerkte gegevens in een datawarehouse of lake laden. Dit project is ideaal voor het begrijpen van de kernprincipes van data-engineering.
Hoe op te lossen?
- Gebruik AWS Glue of AWS Data Pipeline voor gegevensextractie.
- Implementeer transformaties met Apache Spark op Amazon EMR of AWS Glue.
- Bewaar verwerkte gegevens in Amazon S3 of Amazon Redshift.
- Stel automatisering in met AWS Step Functions of AWS Lambda voor orkestratie.
Klik hier om de broncode voor dit project te verkennen.
20. ETL- en ELT-operaties

Objectief
Ontdek ETL (Extract, Transform, Load) en ELT (Extract, Load, Transform) data-integratiebenaderingen op AWS. Vergelijk hun sterke en zwakke punten in verschillende scenario's. Dit project zal inzicht bieden in wanneer elke aanpak moet worden gebruikt op basis van specifieke data-engineeringvereisten.
Hoe op te lossen?
- Implementeer ETL-processen met behulp van AWS Glue voor datatransformatie en laden. Gebruik AWS Data Pipeline of AWS DMS (Database Migration Service) voor ELT-operaties.
- Bewaar gegevens in Amazon S3, Amazon Redshift of Amazon Aurora, afhankelijk van de aanpak.
- Automatiseer gegevensworkflows met behulp van AWS Step Functions of AWS Lambda-functies.
Klik hier om de broncode voor dit project te verkennen.
Conclusie
Data-engineeringprojecten bieden een ongelooflijke kans om in de wereld van data te duiken, de kracht ervan te benutten en betekenisvolle inzichten te genereren. Of u nu pijplijnen bouwt voor realtime streaminggegevens of oplossingen bedenkt om enorme datasets te verwerken, deze projecten scherpen uw vaardigheden aan en openen deuren naar opwindende carrièreperspectieven.
Maar stop hier niet; als u graag uw data-engineering-reis naar een hoger niveau wilt tillen, overweeg dan om u in te schrijven voor onze BlackBelt Plus-programma. Met BB+ krijgt u toegang tot deskundige begeleiding, praktische ervaring en een ondersteunende community, waardoor uw vaardigheden op het gebied van data-engineering naar nieuwe hoogten worden gestuwd. Schrijf nu in!
Veelgestelde Vragen / FAQ
A. Data-engineering omvat het ontwerpen, bouwen en onderhouden van datapijplijnen. Voorbeeld: een pijplijn maken om klantgegevens te verzamelen, op te schonen en op te slaan voor analyse.
A. Best practices op het gebied van data-engineering omvatten robuuste datakwaliteitscontroles, efficiënte ETL-processen, documentatie en schaalbaarheid voor toekomstige datagroei.
A. Data-ingenieurs werken aan taken zoals de ontwikkeling van datapipelines, het waarborgen van de nauwkeurigheid van data, het samenwerken met datawetenschappers en het oplossen van datagerelateerde problemen.
A. Om data-engineeringprojecten op een cv te presenteren, markeert u belangrijke projecten, vermeldt u de gebruikte technologieën en kwantificeert u de impact op de gegevensverwerking of analyseresultaten.
Verwant
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.analyticsvidhya.com/blog/2023/09/data-engineering-project/

