AWS Lijm Studio is een grafische interface die het gemakkelijk maakt om ETL-taken (extraheren, transformeren en laden) te maken, uit te voeren en te bewaken in AWS lijm. Hiermee kunt u workflows voor gegevenstransformatie visueel samenstellen met behulp van knooppunten die verschillende stappen voor gegevensverwerking vertegenwoordigen, die later automatisch worden omgezet in code om uit te voeren.
AWS Lijm Studio Onlangs vrijgegeven 10 meer visuele transformaties om meer geavanceerde banen op een visuele manier te creëren zonder codeervaardigheden. In dit bericht bespreken we mogelijke use-cases die de gemeenschappelijke ETL-behoeften weerspiegelen.
De nieuwe transformaties die in dit bericht worden gedemonstreerd, zijn: Samenvoegen, String splitsen, Array naar kolommen, Huidige tijdstempel toevoegen, Rijen naar kolommen draaien, Kolommen naar rijen terugdraaien, Opzoeken, Array exploderen of toewijzen aan kolommen, Afgeleide kolom en Autobalance-verwerking .
Overzicht oplossingen
In dit geval hebben we enkele JSON-bestanden met bewerkingen voor aandelenopties. We willen enkele transformaties maken voordat we de gegevens opslaan om het analyseren te vergemakkelijken, en we willen ook een afzonderlijke samenvatting van de gegevensset maken.
In deze dataset vertegenwoordigt elke rij een transactie van optiecontracten. Opties zijn financiële instrumenten die het recht geven - maar niet de verplichting - om aandelen tegen een vaste prijs te kopen of te verkopen (genaamd uitoefenprijs) vóór een bepaalde vervaldatum.
Invoergegevens
De gegevens volgen het volgende schema:
- Order ID – Een uniek ID
- symbool - Een code die over het algemeen is gebaseerd op een paar letters om de onderneming te identificeren die de onderliggende aandelen uitgeeft
- instrument – De naam die de specifieke optie identificeert die wordt gekocht of verkocht
- valuta – De ISO-valutacode waarin de prijs wordt uitgedrukt
- prijs - Het bedrag dat is betaald voor de aankoop van elk optiecontract (op de meeste beurzen kunt u met één contract 100 aandelen kopen of verkopen)
- uitwisseling – De code van het uitwisselingscentrum of de plaats waar de optie werd verhandeld
- uitverkocht - Een lijst met het aantal contracten dat is toegewezen om de verkooporder uit te voeren wanneer dit een verkooptransactie is
- gekocht - Een lijst met het aantal contracten dat is toegewezen om de kooporder te vullen wanneer dit koophandel is
Het volgende is een voorbeeld van de synthetische gegevens die voor dit bericht zijn gegenereerd:
ETL-vereisten
Deze gegevens hebben een aantal unieke kenmerken, zoals vaak gevonden op oudere systemen, waardoor de gegevens moeilijker te gebruiken zijn.
Dit zijn de ETL-vereisten:
- De naam van het instrument bevat waardevolle informatie die bedoeld is voor mensen om te begrijpen; we willen het normaliseren in afzonderlijke kolommen voor eenvoudigere analyse.
- De attributen
boughtensoldsluiten elkaar uit; we kunnen ze consolideren in een enkele kolom met de contractnummers en een andere kolom hebben die aangeeft of de contracten in deze volgorde zijn gekocht of verkocht. - We willen de informatie over de individuele contracttoewijzingen behouden, maar als individuele rijen in plaats van gebruikers te dwingen met een reeks getallen om te gaan. We zouden de cijfers kunnen optellen, maar we zouden informatie verliezen over hoe de order is uitgevoerd (wat wijst op marktliquiditeit). In plaats daarvan kiezen we ervoor om de tabel te denormaliseren, zodat elke rij een enkel aantal contracten heeft, waarbij bestellingen met meerdere nummers worden opgesplitst in afzonderlijke rijen. In een gecomprimeerde kolomindeling is de extra gegevenssetgrootte van deze herhaling vaak klein wanneer compressie wordt toegepast, dus het is acceptabel om de gegevensset gemakkelijker te doorzoeken.
- We willen een samenvattende tabel met het volume genereren voor elk optietype (call en put) voor elk aandeel. Dit geeft een indicatie van het marktsentiment voor elk aandeel en de markt in het algemeen (hebzucht versus angst).
- Om algemene handelsoverzichten mogelijk te maken, willen we voor elke transactie het eindtotaal geven en de valuta standaardiseren naar Amerikaanse dollars, met behulp van een geschatte conversiereferentie.
- We willen de datum toevoegen waarop deze transformaties plaatsvonden. Dit kan bijvoorbeeld handig zijn om een referentie te hebben over wanneer de valutaomrekening heeft plaatsgevonden.
Op basis van die vereisten levert de taak twee resultaten op:
- Een CSV-bestand met een overzicht van het aantal contracten per symbool en type
- Een catalogustabel om de geschiedenis van de bestelling bij te houden, na het uitvoeren van de aangegeven transformaties
Voorwaarden
U hebt uw eigen S3-bucket nodig om deze use case te volgen. Raadpleeg voor het maken van een nieuwe bucket Een bucket maken.
Genereer synthetische gegevens
Om dit bericht te volgen (of zelf met dit soort gegevens te experimenteren), kunt u deze dataset synthetisch genereren. Het volgende Python-script kan worden uitgevoerd in een Python-omgeving met Boto3 geïnstalleerd en toegang tot Amazon eenvoudige opslagservice (Amazone S3).
Voer de volgende stappen uit om de gegevens te genereren:
- Maak in AWS Glue Studio een nieuwe taak aan met de optie Python shell-scripteditor.
- Geef de taak een naam en op de Details van de baan tabblad, selecteer een geschikte rol en een naam voor het Python-script.
- In het Details van de baan sectie, uitbreiden Geavanceerde eigenschappen en scrol omlaag naar Taakparameters.
- Voer een parameter in met de naam
--bucketen wijs als waarde de naam toe van de bucket die u wilt gebruiken om de voorbeeldgegevens op te slaan. - Voer het volgende script in de AWS Glue shell-editor in:
- Voer de taak uit en wacht tot deze als succesvol voltooid wordt weergegeven op het tabblad Uitvoeringen (dit duurt slechts enkele seconden).
Elke uitvoering genereert een JSON-bestand met 1,000 rijen onder de opgegeven bucket en het voorvoegsel transformsblog/inputdata/. U kunt de taak meerdere keren uitvoeren als u met meer invoerbestanden wilt testen.
Elke regel in de synthetische gegevens is een gegevensrij die een JSON-object vertegenwoordigt, zoals het volgende:
Maak de visuele AWS Glue-taak
Voer de volgende stappen uit om de visuele AWS Glue-taak te maken:
- Ga naar AWS Glue Studio en maak een taak aan met de optie Visueel met een leeg canvas.
- Edit
Untitled jobom het een naam te geven en toe te wijzen een rol geschikt voor AWS Glue op de Details van de baan Tab. - Voeg een S3-gegevensbron toe (u kunt deze een naam geven
JSON files source) en voer de S3-URL in waaronder de bestanden zijn opgeslagen (bijvoorbeelds3://<your bucket name>/transformsblog/inputdata/), selecteer vervolgens JSON als het gegevensformaat. - kies Schema afleiden dus stelt het het uitvoerschema in op basis van de gegevens.
Vanaf dit bronknooppunt blijf je transformaties koppelen. Zorg er bij het toevoegen van elke transformatie voor dat de geselecteerde node de laatste is die is toegevoegd, zodat deze wordt toegewezen als de ouder, tenzij anders aangegeven in de instructies.
Als u niet de juiste ouder hebt geselecteerd, kunt u de ouder altijd bewerken door deze te selecteren en een andere ouder te kiezen in het configuratievenster.
Voor elk toegevoegd knooppunt geeft u het een specifieke naam (zodat het doel van het knooppunt in de grafiek wordt weergegeven) en configuratie op de Transformeren Tab.
Telkens wanneer een transformatie het schema wijzigt (bijvoorbeeld een nieuwe kolom toevoegen), moet het uitvoerschema worden bijgewerkt zodat het zichtbaar is voor de stroomafwaartse transformaties. U kunt het uitvoerschema handmatig bewerken, maar het is praktischer en veiliger om dit te doen met behulp van het gegevensvoorbeeld.
Bovendien kunt u op die manier controleren of de transformatie zo ver werkt als verwacht. Open hiervoor de Gegevensvoorbeeld tab met de transformatie geselecteerd en start een preview-sessie. Nadat u hebt gecontroleerd of de getransformeerde gegevens eruit zien zoals verwacht, gaat u naar de Uitvoerschema tab en kies Gebruik het gegevensvoorbeeldschema om het schema automatisch bij te werken.
Terwijl u nieuwe soorten transformaties toevoegt, kan in het voorbeeld een bericht worden weergegeven over een ontbrekende afhankelijkheid. Wanneer dit gebeurt, kies dan Sessie beëindigen en begin een nieuwe, zodat de preview het nieuwe soort knooppunt oppikt.
Extraheer instrumentinformatie
Laten we beginnen met het behandelen van de informatie over de instrumentnaam om deze te normaliseren in kolommen die gemakkelijker toegankelijk zijn in de resulterende uitvoertabel.
- Voeg een String splitsen knoop en noem het
Split instrument, die de instrumentkolom tokeniseert met behulp van een regex voor witruimte:s+(een enkele spatie zou in dit geval voldoende zijn, maar op deze manier is het flexibeler en visueel duidelijker). - We willen de oorspronkelijke instrumentinformatie behouden zoals ze is, dus voer een nieuwe kolomnaam in voor de gesplitste array:
instrument_arr.
- Voeg een toe Matrix Naar Kolommen knoop en noem het
Instrument columnsom de zojuist gemaakte matrixkolom om te zetten in nieuwe velden, behalve voorsymbol, waarvoor we al een column hebben. - Selecteer de kolom
instrument_arr, sla het eerste token over en vertel het om de uitvoerkolommen te extraherenmonth, day, year, strike_price, typeindexen gebruiken2, 3, 4, 5, 6(de spaties na de komma's zijn voor de leesbaarheid, ze hebben geen invloed op de configuratie).
Het geëxtraheerde jaar wordt uitgedrukt met slechts twee cijfers; laten we een noodoplossing maken om aan te nemen dat het in deze eeuw is als ze maar twee cijfers gebruiken.
- Voeg een Afgeleide kolom knoop en noem het
Four digits year. - Enter
yearals de afgeleide kolom zodat deze deze overschrijft, en voer de volgende SQL-expressie in:CASE WHEN length(year) = 2 THEN ('20' || year) ELSE year END
Voor het gemak bouwen we een expiration_date veld dat een gebruiker kan hebben als referentie van de laatste datum waarop de optie kan worden uitgeoefend.
- Voeg een Kolommen samenvoegen knoop en noem het
Build expiration date. - Geef de nieuwe kolom een naam
expiration_date, selecteer de kolommenyear,monthenday(in die volgorde) en een koppelteken als spatie.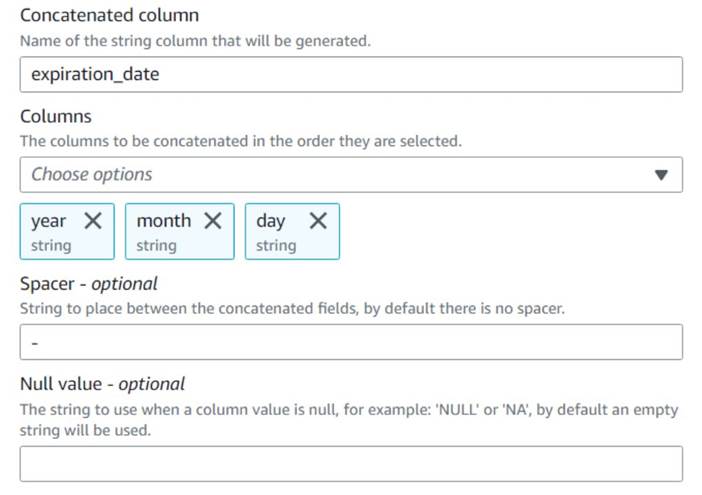
Het diagram tot nu toe zou eruit moeten zien als het volgende voorbeeld.
![]()
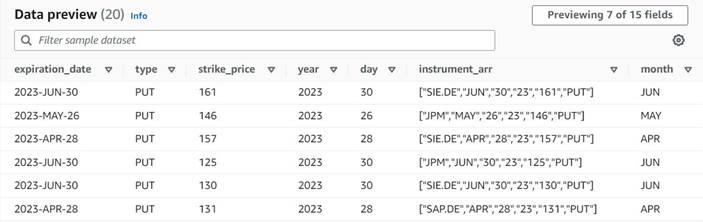
Het gegevensvoorbeeld van de nieuwe kolommen tot nu toe zou er uit moeten zien als de volgende schermafbeelding.
Normaliseer het aantal contracten
Elk van de rijen in de gegevens geeft het aantal contracten van elke optie aan dat is gekocht of verkocht en de batches waarop de bestellingen zijn uitgevoerd. Zonder de informatie over de individuele batches te verliezen, willen we elk bedrag op een individuele rij hebben met een enkele bedragwaarde, terwijl de rest van de informatie wordt gerepliceerd in elke geproduceerde rij.
Laten we eerst de bedragen samenvoegen in een enkele kolom.
- Voeg een toe Draai kolommen om naar rijen knoop en noem het
Unpivot actions. - Kies de kolommen
boughtensoldom de namen en waarden ongedaan te maken en op te slaan in kolommen namedactionencontracts, Respectievelijk.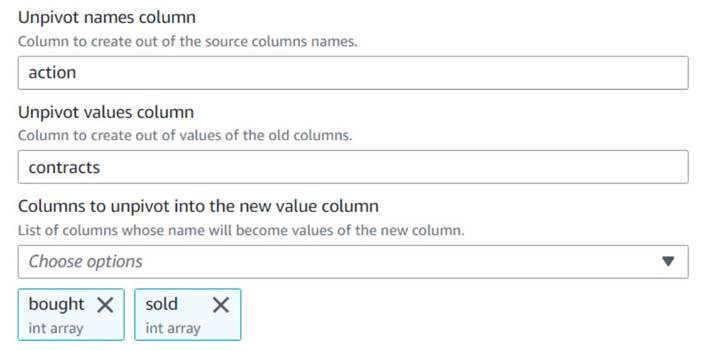
Merk in het voorbeeld op dat de nieuwe kolomcontractsis nog steeds een reeks getallen na deze transformatie.
- Voeg een toe Explodeer matrix of kaart in rijen rij genoemd
Explode contracts. - Kies de
contractskolom en voer incontractsals de nieuwe kolom om deze te overschrijven (we hoeven de originele array niet te behouden).
Het voorbeeld laat nu zien dat elke rij een single heeft contracts hoeveelheid, en de rest van de velden zijn hetzelfde.
Dit betekent ook dat order_id is niet langer een unieke sleutel. Voor uw eigen use-cases moet u beslissen hoe u uw gegevens wilt modelleren en of u wilt denormaliseren of niet.
De volgende schermafbeelding is een voorbeeld van hoe de nieuwe kolommen eruit zien na de transformaties tot nu toe.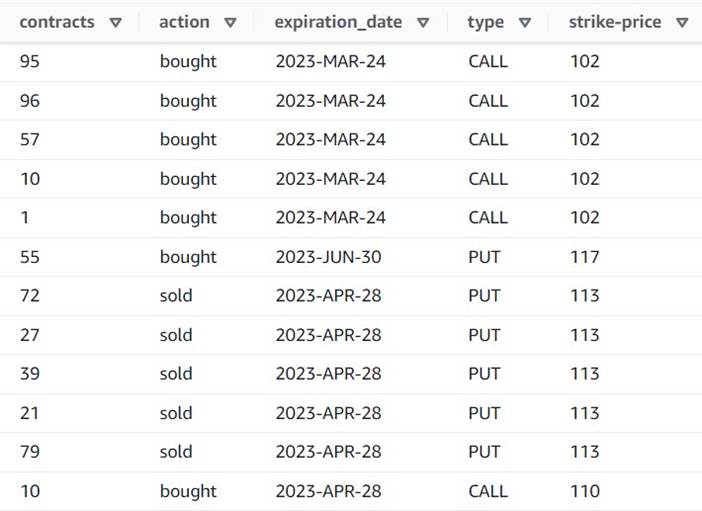
Maak een overzichtstabel
Nu maakt u een overzichtstabel met het aantal verhandelde contracten voor elk type en elk aandelensymbool.
Laten we ter illustratie aannemen dat de verwerkte bestanden tot een enkele dag behoren, zodat deze samenvatting de zakelijke gebruikers informatie geeft over wat de marktinteresse en het sentiment die dag zijn.
- Voeg een Selecteer Velden node en selecteer de volgende kolommen om te behouden voor de samenvatting:
symbol,typeencontracts.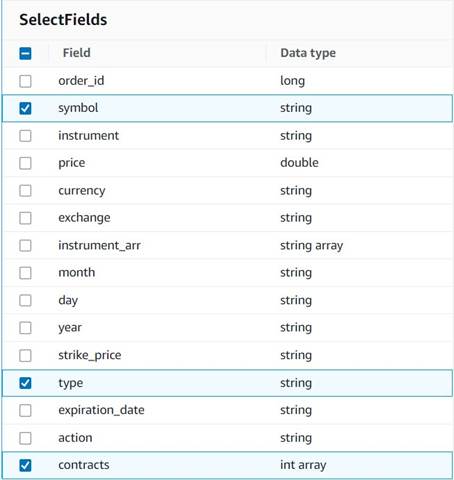
- Voeg een Draai rijen in kolommen knoop en noem het
Pivot summary. - Aggregaat op de
contractskolom met behulp vansumen kies ervoor om detypekolom.
Normaal gesproken zou u het ter referentie opslaan in een externe database of bestand; in dit voorbeeld slaan we het op als een CSV-bestand op Amazon S3.
- Voeg een toe Automatische balansverwerking knoop en noem het
Single output file. - Hoewel dat transformatietype normaal gesproken wordt gebruikt om de parallelliteit te optimaliseren, gebruiken we het hier om de uitvoer terug te brengen tot een enkel bestand. Voer daarom in
1in de configuratie van het aantal partities.
- Voeg een S3-doel toe en geef het een naam
CSV Contract summary. - Kies CSV als gegevensindeling en voer een S3-pad in waar de taakrol bestanden mag opslaan.
Het laatste deel van de taak zou er nu uit moeten zien als in het volgende voorbeeld.![]()
- Sla de taak op en voer deze uit. Gebruik de Runs tabblad om te controleren of het succesvol is voltooid.
Je zult een bestand onder dat pad vinden dat een CSV is, ondanks dat het die extensie niet heeft. U zult waarschijnlijk de extensie moeten toevoegen nadat u deze hebt gedownload om deze te openen.
Op een tool die de CSV kan lezen, zou de samenvatting er ongeveer zo uit moeten zien als in het volgende voorbeeld.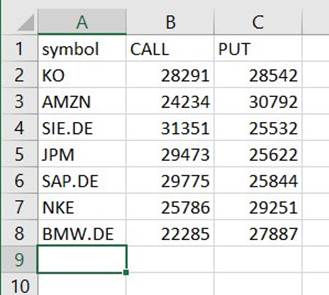
Ruim tijdelijke kolommen op
Laten we, ter voorbereiding op het opslaan van de bestellingen in een historische tabel voor toekomstige analyse, enkele tijdelijke kolommen opschonen die onderweg zijn gemaakt.
- Voeg een Velden laten vallen knoop met de
Explode contractsnode geselecteerd als ouder (we vertakken de gegevenspijplijn om een afzonderlijke uitvoer te genereren). - Selecteer de velden die moeten worden verwijderd:
instrument_arr,month,dayenyear.
De rest willen we behouden, zodat ze worden opgeslagen in de historische tabel die we later zullen maken.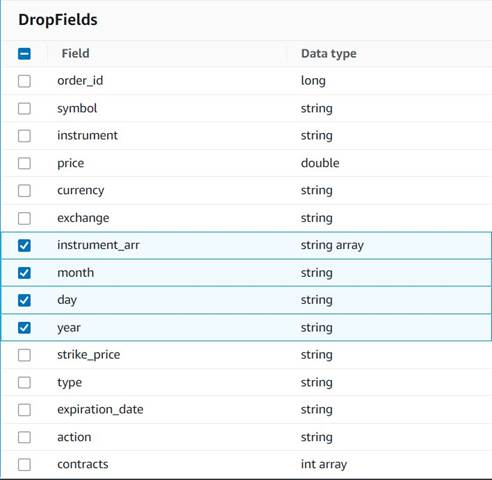
Standaardisatie van valuta
Deze synthetische gegevens bevatten fictieve bewerkingen op twee valuta's, maar in een echt systeem zou je valuta's van markten over de hele wereld kunnen krijgen. Het is handig om de verwerkte valuta's te standaardiseren in één referentievaluta, zodat ze gemakkelijk kunnen worden vergeleken en samengevoegd voor rapportage en analyse.
Wij gebruiken Amazone Athene om een tabel te simuleren met geschatte valutaconversies die periodiek wordt bijgewerkt (hier gaan we ervan uit dat we de bestellingen tijdig genoeg verwerken zodat de conversie een redelijke representatie is voor vergelijkingsdoeleinden).
- Open de Athena-console in dezelfde regio waar u AWS Glue gebruikt.
- Voer de volgende query uit om de tabel te maken door een S3-locatie in te stellen waar zowel uw Athena- als AWS Glue-rollen kunnen lezen en schrijven. Het kan ook zijn dat u de tabel in een andere database wilt opslaan dan
default(als u dat doet, werkt u de gekwalificeerde naam van de tabel dienovereenkomstig bij in de gegeven voorbeelden). - Voer een paar voorbeeldconversies in de tabel in:
INSERT INTO default.exchange_rates VALUES ('usd', 1.0), ('eur', 1.09), ('gbp', 1.24); - U zou nu de tabel moeten kunnen bekijken met de volgende query:
SELECT * FROM default.exchange_rates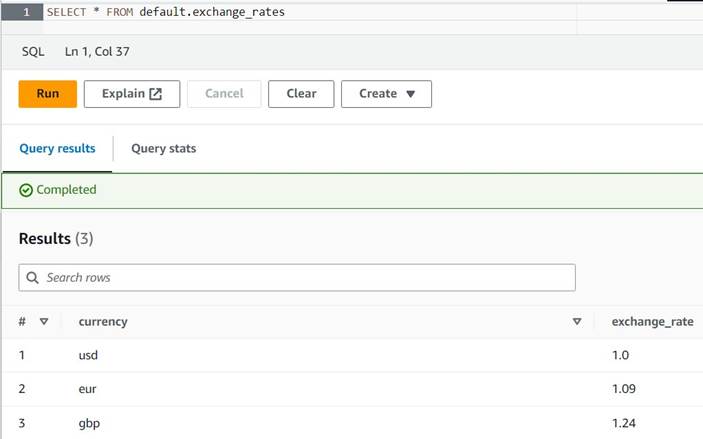
- Terug op de visuele AWS Glue-taak, voeg een Lookup node (als kind van
Drop Fields) en noem hetExchange rate. - Voer de gekwalificeerde naam in van de tabel die u zojuist hebt gemaakt, met behulp van
currencyals de sleutel en selecteer deexchange_rateveld te gebruiken.
Omdat het veld dezelfde naam heeft in zowel de gegevens als de opzoektabel, kunnen we gewoon de naam invoerencurrencyen hoeft geen mapping te definiëren.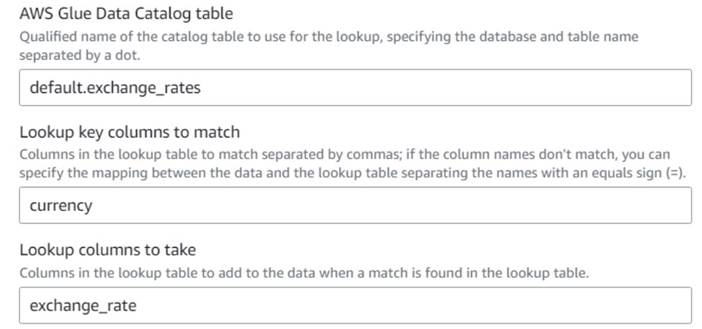
Op het moment van schrijven wordt de Lookup-transformatie niet ondersteund in het gegevensvoorbeeld en wordt er een fout weergegeven dat de tabel niet bestaat. Dit is alleen voor het gegevensvoorbeeld en verhindert niet dat de taak correct wordt uitgevoerd. Voor de weinige resterende stappen van het bericht hoeft u het schema niet bij te werken. Als u een gegevensvoorbeeld op andere knooppunten wilt uitvoeren, kunt u het opzoekknooppunt tijdelijk verwijderen en vervolgens weer terugplaatsen. - Voeg een Afgeleide kolom knoop en noem het
Total in usd. - Geef de afgeleide kolom een naam
total_usden gebruik de volgende SQL-expressie:round(contracts * price * exchange_rate, 2)
- Voeg een Huidige tijdstempel toevoegen knoop en geef de kolom een naam
ingest_date. - Gebruik het formaat
%Y-%m-%dvoor uw tijdstempel (voor demonstratiedoeleinden gebruiken we alleen de datum; u kunt deze desgewenst nauwkeuriger maken).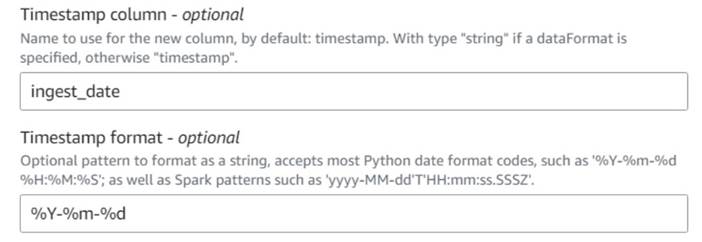
Sla de tabel met historische bestellingen op
Voer de volgende stappen uit om de tabel met historische bestellingen op te slaan:
- Voeg een S3-doelknooppunt toe en geef het een naam
Orders table. - Configureer het Parquet-formaat met pittige compressie en geef een S3-doelpad op waaronder de resultaten kunnen worden opgeslagen (los van de samenvatting).
- kies Maak een tabel in de gegevenscatalogus en werk bij volgende uitvoeringen het schema bij en voeg nieuwe partities toe.
- Voer een doeldatabase in en een naam voor de nieuwe tabel, bijvoorbeeld:
option_orders.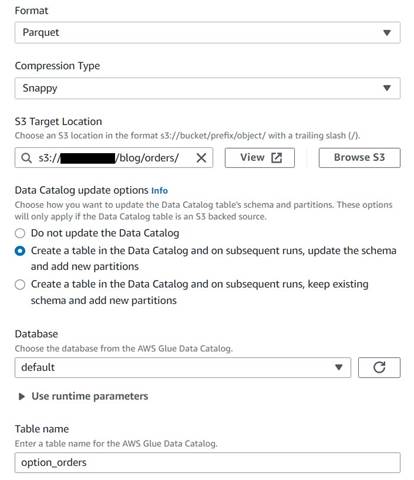
Het laatste deel van het diagram zou er nu ongeveer zo uit moeten zien, met twee takken voor de twee afzonderlijke uitgangen.![]()
Nadat u de taak met succes hebt uitgevoerd, kunt u een tool zoals Athena gebruiken om de gegevens die de taak heeft geproduceerd te bekijken door de nieuwe tabel te doorzoeken. U kunt de tafel op de Athena-lijst vinden en kiezen Voorbeeldtabel of voer gewoon een SELECT-query uit (waarbij de tabelnaam wordt bijgewerkt naar de naam en catalogus die u hebt gebruikt):
SELECT * FROM default.option_orders limit 10
De inhoud van uw tabel moet er ongeveer zo uitzien als de volgende schermafbeelding.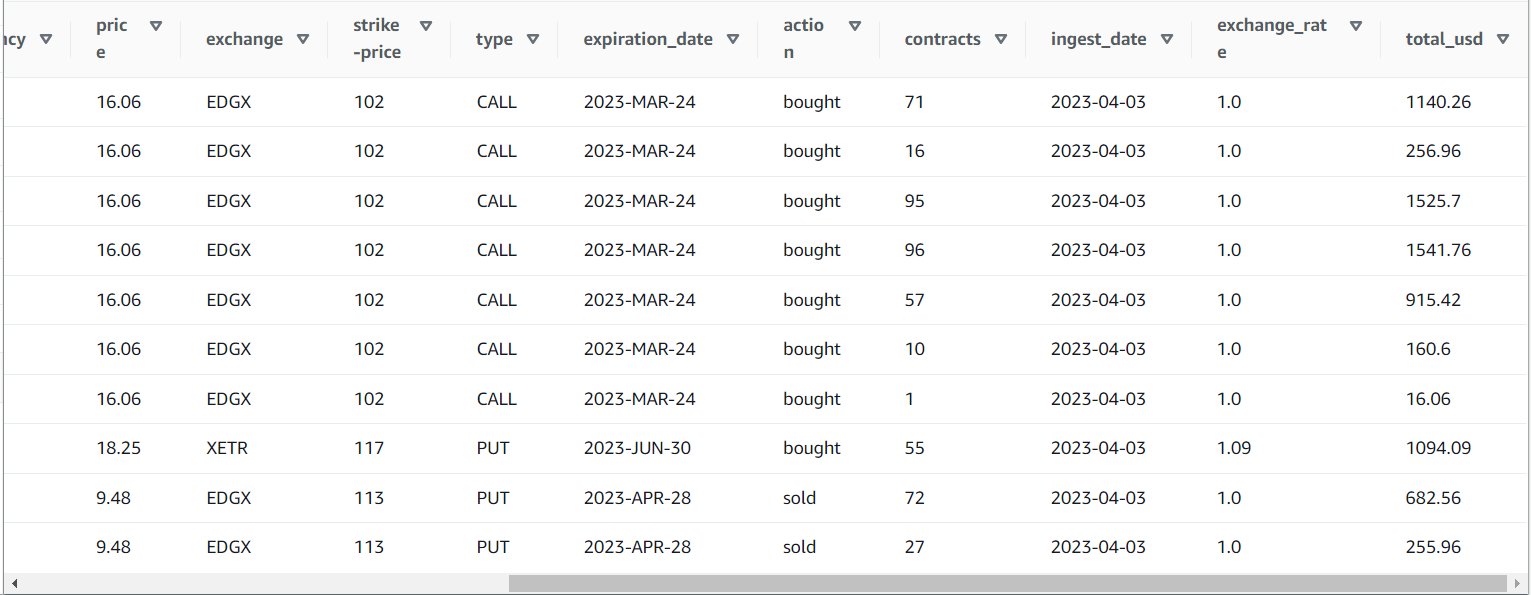
Opruimen
Als u dit voorbeeld niet wilt behouden, verwijdert u de twee taken die u hebt gemaakt, de twee tabellen in Athena en de S3-paden waar de invoer- en uitvoerbestanden zijn opgeslagen.
Conclusie
In dit bericht hebben we laten zien hoe de nieuwe transformaties in AWS Glue Studio u kunnen helpen meer geavanceerde transformaties uit te voeren met minimale configuratie. Dit betekent dat u meer ETL use cases kunt implementeren zonder code te hoeven schrijven en onderhouden. De nieuwe transformaties zijn al beschikbaar in AWS Glue Studio, dus u kunt de nieuwe transformaties vandaag nog gebruiken in uw visuele taken.
Over de auteur
![]() Gonzalo herreros is een Senior Big Data Architect in het AWS Glue-team.
Gonzalo herreros is een Senior Big Data Architect in het AWS Glue-team.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoAiStream. Web3 gegevensintelligentie. Kennis versterkt. Toegang hier.
- De toekomst slaan met Adryenn Ashley. Toegang hier.
- Koop en verkoop aandelen in PRE-IPO-bedrijven met PREIPO®. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/ten-new-visual-transforms-in-aws-glue-studio/

