Klanten gebruiken datawarehousing-oplossingen om hun traditionele analytische taken uit te voeren. De laatste tijd hebben datameren veel aan populariteit gewonnen om de basis te worden voor analytische oplossingen, omdat ze voordelen bieden zoals schaalbaarheid, fouttolerantie en ondersteuning voor gestructureerde, semi-gestructureerde en ongestructureerde datasets.
Datalakes zijn niet standaard transactioneel; er zijn echter meerdere opensource-frameworks die datameren verbeteren met ACID-eigenschappen, waardoor een beste van beide werelden wordt geboden tussen transactionele en niet-transactionele opslagmechanismen.
Traditionele pijplijnen voor batchopname en verwerking, waarbij bewerkingen zoals het opschonen van gegevens en het samenvoegen met referentiegegevens betrokken zijn, zijn eenvoudig te maken en kostenefficiënt te onderhouden. Het is echter een uitdaging om datasets, zoals Internet of Things (IoT) en clickstreams, snel op te nemen met SLA's voor bijna realtime levering. U wilt ook incrementele updates toepassen met change data capture (CDC) van het bronsysteem naar de bestemming. Om tijdig datagestuurde beslissingen te nemen, moet u rekening houden met gemiste records en tegendruk, en de ordening en integriteit van gebeurtenissen handhaven, vooral als de referentiegegevens ook snel veranderen.
In dit bericht proberen we deze uitdagingen aan te pakken. We bieden een stapsgewijze handleiding om streaminggegevens samen te voegen met een referentietabel die in realtime verandert AWS lijm, Amazon DynamoDB en AWS-databasemigratieservice (AWS-DMS). We laten ook zien hoe u streaminggegevens kunt opnemen in een transactioneel datameer met behulp van Apache Hudi om incrementele updates te bereiken met ACID-transacties.
Overzicht oplossingen
Voor ons voorbeeldgebruik komen er streaminggegevens door Amazon Kinesis-gegevensstromen, en referentiegegevens worden beheerd in MySQL. De referentiegegevens worden continu gerepliceerd van MySQL naar DynamoDB via AWS DMS. De vereiste hier is om de real-time stroomgegevens te verrijken door ze bijna in realtime samen te voegen met de referentiegegevens, en om ze bevraagbaar te maken vanuit een query-engine zoals Amazone Athene met behoud van consistentie. In dit geval kunnen referentiegegevens in MySQL worden bijgewerkt wanneer de vereiste wordt gewijzigd, en vervolgens moeten query's resultaten opleveren door updates in de referentiegegevens weer te geven.
Deze oplossing verhelpt het probleem dat gebruikers zich willen aansluiten bij streams met veranderende referentiedatasets wanneer de grootte van de referentiedataset klein is. De referentiegegevens worden bijgehouden in DynamoDB-tabellen en de streamingtaak laadt de volledige tabel in het geheugen voor elke microbatch, waarbij een high-throughput-stream wordt samengevoegd met een kleine referentiegegevensset.
Het volgende diagram illustreert de oplossingsarchitectuur.

Voorwaarden
Voor deze walkthrough moet u aan de volgende vereisten voldoen:
IAM-rollen en S3-bucket maken
In deze sectie maakt u een Amazon eenvoudige opslagservice (Amazon S3) emmer en twee AWS Identiteits- en toegangsbeheer (IAM) rollen: één voor de AWS Glue-taak en één voor AWS DMS. Dit doen we aan de hand van een AWS CloudFormatie sjabloon. Voer de volgende stappen uit:
- Meld u aan bij de AWS CloudFormation-console.
- Kies Start Stack::

- Kies Volgende.
- Voor Stack naam, voer een naam in voor uw stapel.
- Voor DynamoDBTabelnaam, ga naar binnen
tgt_country_lookup_table. Dit is de naam van uw nieuwe DynamoDB-tabel. - Voor S3BucketNamePrefix, voer het voorvoegsel van uw nieuwe S3-bucket in.
- kies Ik erken dat AWS CloudFormation IAM-bronnen met aangepaste namen kan maken.
- Kies Maak een stapel.
Het maken van een stapel kan ongeveer 1 minuut duren.
Een Kinesis-gegevensstroom maken
In deze sectie maakt u een Kinesis-gegevensstroom:
- Kies op de Kinesis-console Gegevensstromen in het navigatievenster.
- Kies Maak een datastroom.
- Voor Naam gegevensstroom, voer je streamnaam in.
- Laat de overige instellingen als standaard staan en kies Maak een datastroom.
Er wordt een Kinesis-gegevensstroom gemaakt met de on-demand-modus.
Maak en configureer een Aurora MySQL-cluster
In deze sectie maakt en configureert u een Aurora MySQL-cluster als de brondatabase. Eerst, configureer uw bron Aurora MySQL-databasecluster om CDC in te schakelen via AWS DMS naar DynamoDB.
Maak een parametergroep
Voer de volgende stappen uit om een nieuwe parametergroep te maken:
- Kies op de Amazon RDS-console Parametergroepen in het navigatievenster.
- Kies Parametergroep maken.
- Voor Familie van parametergroepenselecteer
aurora-mysql5.7. - Voor Type, kiezen DB-clusterparametergroep.
- Voor Groepsnaam, ga naar binnen
my-mysql-dynamodb-cdc. - Voor Omschrijving, ga naar binnen
Parameter group for demo Aurora MySQL database. - Kies creëren.
- kies
my-mysql-dynamodb-cdcen kies Edit voor Parametergroepacties. - Bewerk de parametergroep als volgt:
| Naam | Waarde |
| binlog_row_image | vol |
| binlog_format | RIJ |
| binlog_checksum | GEEN |
| log_slave_updates | 1 |
- Kies Wijzigingen opslaan.

Maak het Aurora MySQL-cluster
Voer de volgende stappen uit om het Aurora MySQL-cluster te maken:
- Kies op de Amazon RDS-console databases in het navigatievenster.
- Kies Maak een database.
- Voor Kies een methode voor het maken van een database, kiezen Standaard maken.
- Onder Motor optiesvoor Aandrijving, kiezen Aurora (MySQL-compatibel).
- Voor Motorversie, kiezen Aurora (MySQL 5.7) 2.11.2.
- Voor Sjablonen, kiezen Productie.
- Onder Instellingenvoor DB-cluster-ID, voer een naam in voor uw database.
- Voor Master-gebruikersnaam, voer uw primaire gebruikersnaam in.
- Voor Master wachtwoord en Bevestig het hoofdwachtwoord, voer je primaire wachtwoord in.
- Onder Instantie configuratievoor DB-instantieklasse, kiezen Burstable-klassen (inclusief t-klassen) En kies db.t3.klein.
- Onder Beschikbaarheid & duurzaamheidvoor Multi-AZ-implementatie, kiezen Maak geen Aurora-replica.
- Onder Connectiviteitvoor Rekenbron, kiezen Maak geen verbinding met een EC2-rekenresource.
- Voor Netwerktype, kiezen IPv4.
- Voor Virtuele privécloud (VPC), kies uw VPC.
- Voor DB-subnetgroep, kies uw openbare subnet.
- Voor Publieke toegang, kiezen Ja.
- Voor VPC-beveiligingsgroep (firewall), kiest u de beveiligingsgroep voor uw openbare subnet.
- Onder Database-authenticatievoor Opties voor database-authenticatie, kiezen Wachtwoord authenticatie.
- Onder Aanvullende configuratievoor DB-clusterparametergroep, kiest u de clusterparametergroep die u eerder hebt gemaakt.
- Kies Maak een database.
Machtigingen verlenen aan de brondatabase
De volgende stap is het verlenen van de vereiste toestemming voor de bron Aurora MySQL-database. Nu kunt u verbinding maken met het DB-cluster met behulp van de MySQL-hulpprogramma. U kunt query's uitvoeren om de volgende taken uit te voeren:
- Maak een demodatabase en -tabel en voer query's uit op de gegevens
- Verleen toestemming voor een gebruiker die wordt gebruikt door het AWS DMS-eindpunt
Voer de volgende stappen uit:
- Meld u aan bij de EC2-instantie die u gebruikt om verbinding te maken met uw DB-cluster.
- Voer de volgende opdracht in bij de opdrachtprompt om verbinding te maken met de primaire DB-instantie van uw DB-cluster:
- Voer de volgende SQL-opdracht uit om een database te maken:
- Voer de volgende SQL-opdracht uit om een tabel te maken:
- Voer de volgende SQL-opdracht uit om de tabel met gegevens te vullen:
- Voer de volgende SQL-opdracht uit om een gebruiker voor het AWS DMS-eindpunt te maken en machtigingen verlenen voor CDC-taken (vervang de tijdelijke aanduiding door uw voorkeurswachtwoord):
Maak en configureer AWS DMS-bronnen om gegevens in de DynamoDB-referentietabel te laden
In deze sectie maakt en configureert u AWS DMS om gegevens te repliceren naar de DynamoDB-referentietabel.
Maak een AWS DMS-replicatie-instantie
Maak eerst een AWS DMS-replicatie-instantie door de volgende stappen uit te voeren:
- Kies op de AWS DMS-console: Replicatie-exemplaren in het navigatievenster.
- Kies Maak een replicatie-exemplaar.
- Onder Instellingenvoor Naam, voer een naam in voor uw instantie.
- Onder Instantie configuratievoor Hoge beschikbaarheid, kiezen Dev- of testworkload (Single-AZ).
- Onder Connectiviteit en beveiligingvoor VPC-beveiligingsgroepen, kiezen verzuim.
- Kies Maak een replicatie-exemplaar.
Creëer Amazon VPC-eindpunten
Optioneel kunt u creëren Amazon VPC-eindpunten voor DynamoDB wanneer u verbinding moet maken met uw DynamoDB-tabel vanuit de AWS DMS-instantie in een particulier netwerk. Zorg er ook voor dat u inschakelen Publiek toegankelijk wanneer u verbinding moet maken met een database buiten uw VPC.
Maak een AWS DMS-broneindpunt
Maak een AWS DMS-broneindpunt door de volgende stappen uit te voeren:
- Kies op de AWS DMS-console: Eindpunten in het navigatievenster.
- Kies Eindpunt maken.
- Voor Type eindpunt, kiezen Bron eindpunt.
- Onder Eindpunt configuratievoor Eindpunt-ID, voer een naam in voor uw eindpunt.
- Voor Bron-engine, kiezen Amazon Aurora MySQL.
- Voor Toegang tot eindpuntdatabase, kiezen Geef toegangsinformatie handmatig op.
- Voor Server Naam, voert u de eindpuntnaam van uw Aurora-schrijverinstantie in (bijvoorbeeld
mycluster.cluster-123456789012.us-east-1.rds.amazonaws.com). - Voor Haven, ga naar binnen
3306. - Voor gebruikersnaam, voer een gebruikersnaam in voor uw AWS DMS-taak.
- Voor Wachtwoord, Vul een wachtwoord in.
- Kies Eindpunt maken.
Crate een AWS DMS-doeleindpunt
Maak een AWS DMS-doeleindpunt door de volgende stappen uit te voeren:
- Kies op de AWS DMS-console: Eindpunten in het navigatievenster.
- Kies Eindpunt maken.
- Voor Type eindpunt, kiezen Doeleindpunt.
- Onder Eindpunt configuratievoor Eindpunt-ID, voer een naam in voor uw eindpunt.
- Voor Doel motor, kiezen Amazon DynamoDB.
- Voor Servicetoegangsrol ARN, voer de IAM-rol in voor uw AWS DMS-taak.
- Kies Eindpunt maken.
AWS DMS-migratietaken maken
Maak AWS DMS-databasemigratietaken door de volgende stappen uit te voeren:
- Kies op de AWS DMS-console: Databasemigratietaken in het navigatievenster.
- Kies Taak maken.
- Onder Taak configuratievoor Taak-ID, voer een naam in voor uw taak.
- Voor Replicatie-exemplaar, kies uw replicatie-exemplaar.
- Voor Brondatabase-eindpunt, kies uw broneindpunt.
- Voor Doeldatabase-eindpunt, kies uw doeleindpunt.
- Voor Migratie type, kiezen Migreer bestaande gegevens en repliceer lopende wijzigingen.
- Onder Taakinstellingenvoor Doeltabel voorbereidingsmodus, kiezen Doe niets.
- Voor Stop de taak nadat de volledige belasting is voltooid, kiezen Stop niet.
- Voor LOB-kolominstellingen, kiezen Beperkte LOB-modus.
- Voor Taaklogboeken, inschakelen Schakel CloudWatch-logboeken in en Schakel batch-geoptimaliseerde toepassing in.
- Onder Tabeltoewijzingen, kiezen JSON-editor en voer de volgende regels in.
Hier kunt u waarden aan de kolom toevoegen. Met de volgende regels maakt de AWS DMS CDC-taak eerst een nieuwe DynamoDB-tabel met de opgegeven naam in target-table-name. Dan zal het alle records repliceren, de kolommen in de DB-tabel toewijzen aan de attributen in de DynamoDB-tabel.

- Kies Taak maken.
Nu is de AWS DMS-replicatietaak gestart.
- Wacht op de Status laten zien als Laden voltooid.
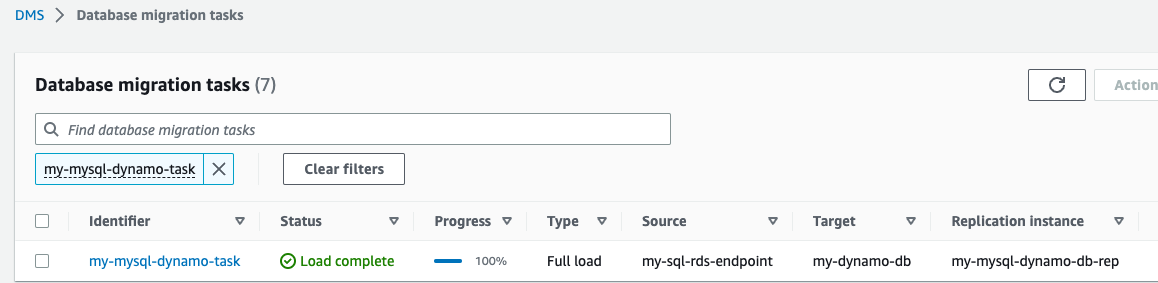
- Kies op de DynamoDB-console Tafels in het navigatievenster.
- Selecteer de DynamoDB-referentietabel en kies Verken tafelitems om de gerepliceerde records te bekijken.

Maak een AWS Glue Data Catalog-tabel en een AWS Glue streaming ETL-taak
In deze sectie maakt u een AWS Glue Data Catalog-tabel en een AWS Glue streaming extractie-, transformatie- en laadtaak (ETL).
Maak een Data Catalog-tabel
Maak een AWS Glue Data Catalog-tabel voor de Kinesis-brongegevensstroom met de volgende stappen:
- Kies op de AWS Glue-console: databases voor Gegevenscatalogus in het navigatievenster.
- Kies Voeg database toe.
- Voor Naam, ga naar binnen
my_kinesis_db. - Kies Maak een database.
- Kies Tafels voor databases, kies dan Tabel toevoegen.
- Voor Naam, ga naar binnen
my_stream_src_table. - Voor Database, kiezen
my_kinesis_db. - Voor Selecteer het type bron, kiezen Kinesis.
- Voor Kinesis-gegevensstroom bevindt zich in, kiezen mijn rekening.
- Voor Naam Kinesis-stream, voer een naam in voor uw gegevensstroom.
- Voor Classificatieselecteer JSON.
- Kies Volgende.
- Kies Schema bewerken als JSON, voer de volgende JSON in en kies vervolgens Bespaar.
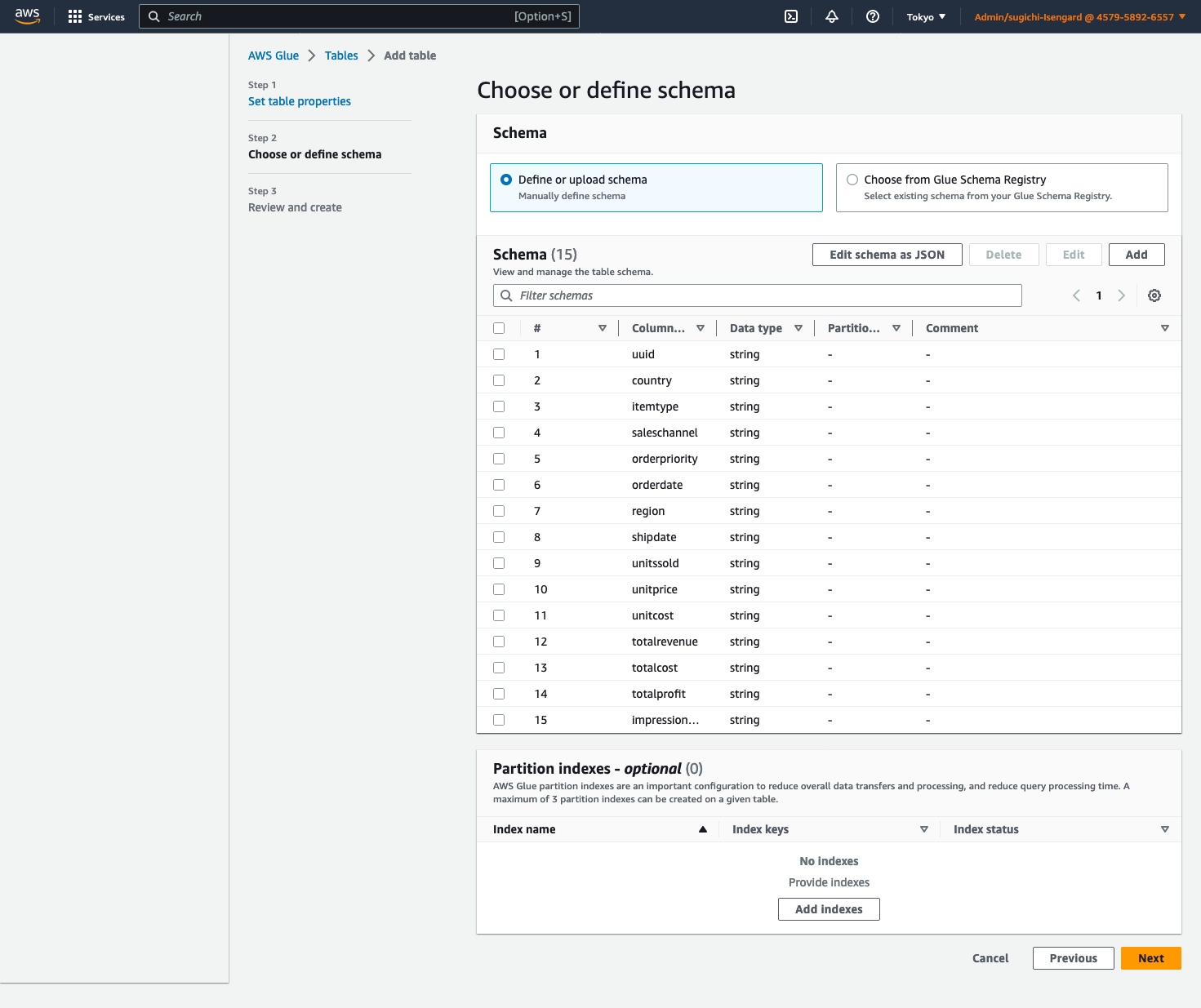
-
- Kies Volgende, kies dan creëren.
Maak een AWS Glue streaming ETL-taak
Vervolgens maakt u een AWS Glue-streamingtaak aan. AWS Glue 3.0 en hoger ondersteunt native Apache Hudi, dus gebruiken we deze native integratie om op te nemen in een Hudi-tabel. Voer de volgende stappen uit om de AWS Glue-streamingtaak te maken:
- Kies op de AWS Glue Studio-console: Spark-scripteditor En kies creëren.
- Onder Details van de baan tabblad, voor Naam, voer een naam in voor uw job.
- Voor IAM-rol, kies de IAM-rol voor uw AWS Glue-taak.
- Voor Typeselecteer Spark-streaming.
- Voor Lijm versie, kiezen Glue 4.0 – Ondersteunt spark 3.3, Scala 2, Python 3.
- Voor Gevraagd aantal werknemers, ga naar binnen
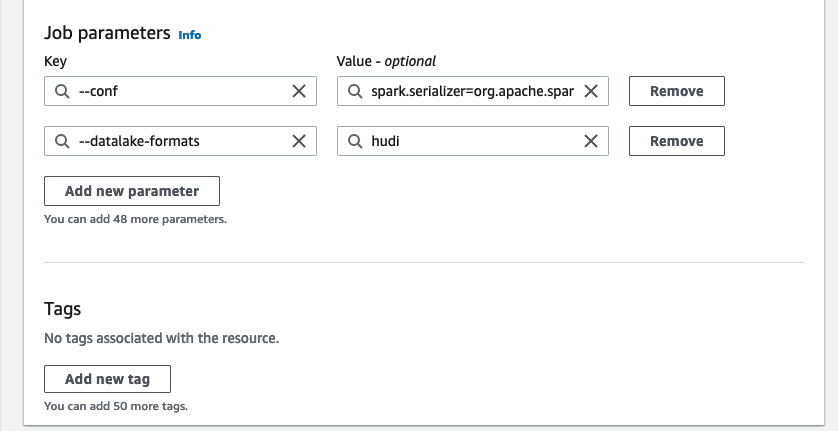
3. - Onder Geavanceerde eigenschappenvoor Taakparameters, kiezen Nieuwe parameter toevoegen.
- Voor sleutel, ga naar binnen
--conf. - Voor Waarde, ga naar binnen
spark.serializer=org.apache.spark.serializer.KryoSerializer --conf spark.sql.hive.convertMetastoreParquet=false. - Kies Nieuwe parameter toevoegen.
- Voor sleutel, ga naar binnen
--datalake-formats. - Voor Waarde, ga naar binnen
hudi. - Voor Scriptpad, ga naar binnen
s3://<S3BucketName>/scripts/. - Voor Tijdelijk pad, ga naar binnen
s3://<S3BucketName>/temporary/. - Optioneel, voor Pad naar Spark UI-logboeken, ga naar binnen
s3://<S3BucketName>/sparkHistoryLogs/.
- Op de Script tab, voer het volgende script in de AWS Glue Studio-editor in en kies creëren.
De bijna realtime streamingtaak verrijkt gegevens door een Kinesis-gegevensstroom samen te voegen met een DynamoDB-tabel die regelmatig bijgewerkte referentiegegevens bevat. De verrijkte dataset wordt geladen in de doel Hudi-tabel in het datameer. Vervangen met je bucket die je hebt gemaakt via AWS CloudFormation:
- Kies lopen om de streamingtaak te starten.
De volgende schermafbeelding toont voorbeelden van de DataFrames data_frame, country_lookup_df en final_frame.
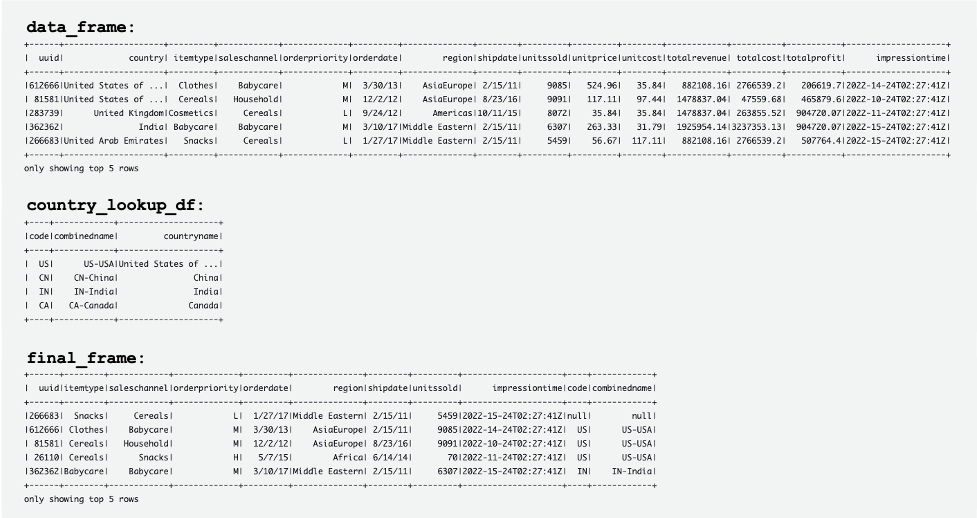
De AWS Glue-taak heeft met succes records samengevoegd die afkomstig zijn van de Kinesis-gegevensstroom en de referentietabel in DynamoDB, en vervolgens de samengevoegde records opgenomen in Amazon S3 in Hudi-indeling.
Maak en voer een Python-script uit om voorbeeldgegevens te genereren en laad deze in de Kinesis-gegevensstroom
In deze sectie maakt en voert u een Python uit om voorbeeldgegevens te genereren en deze in de Kinesis-brongegevensstroom te laden. Voer de volgende stappen uit:
- Log in op AWS Cloud9, uw EC2-instantie of een andere computerhost die records in uw gegevensstroom plaatst.
- Maak een Python-bestand met de naam
generate-data-for-kds.py:
- Open het Python-bestand en voer het volgende script in:
Dit script plaatst elke 2 seconden een Kinesis-gegevensstroomrecord.
Simuleer het bijwerken van de referentietabel in het Aurora MySQL-cluster
Nu zijn alle bronnen en configuraties klaar. Voor dit voorbeeld willen we toevoegen een 3-cijferige landcode naar de referentietabel. Laten we records in de Aurora MySQL-tabel bijwerken om wijzigingen te simuleren. Voer de volgende stappen uit:
- Zorg ervoor dat de AWS Glue-streamingtaak al actief is.
- Maak opnieuw verbinding met het primaire DB-exemplaar, zoals eerder beschreven.
- Voer uw SQL-opdrachten in om records bij te werken:
Nu is de referentietabel in de Aurora MySQL-brondatabase bijgewerkt. Vervolgens worden de wijzigingen automatisch gerepliceerd naar de referentietabel in DynamoDB.
De volgende tabellen tonen records in data_frame, country_lookup_df en final_frame. in country_lookup_df en final_frame combinedname kolom heeft waarden die zijn opgemaakt als <2-digit-country-code>-<3-digit-country-code>-<country-name>, waaruit blijkt dat de gewijzigde records in de tabel waarnaar wordt verwezen, worden weerspiegeld in de tabel zonder de AWS Glue-streamingtaak opnieuw te starten. Het betekent dat de AWS Glue-taak met succes de inkomende records uit de Kinesis-gegevensstroom samenvoegt met de referentietabel, zelfs wanneer de referentietabel verandert.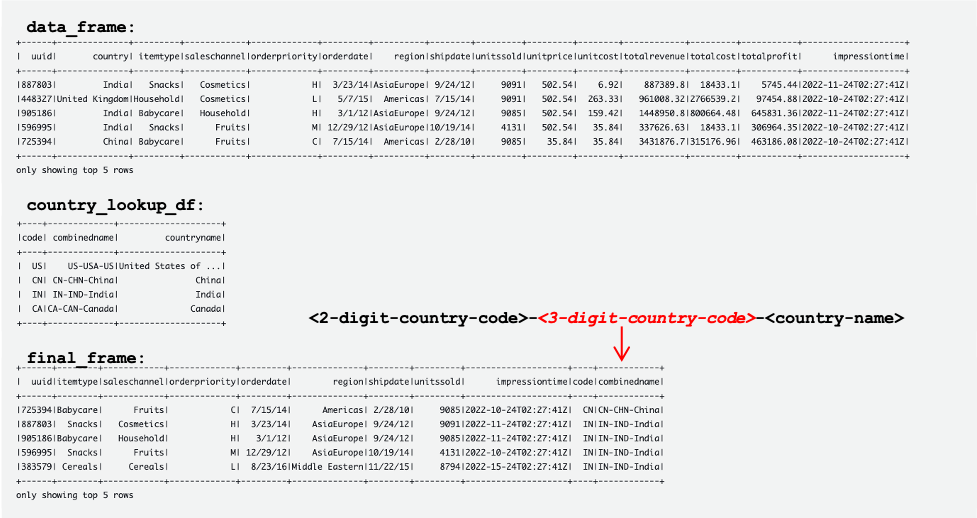
Voer een query uit op de Hudi-tabel met behulp van Athena
Laten we de Hudi-tabel opvragen met behulp van Athena om de records in de bestemmingstabel te bekijken. Voer de volgende stappen uit:
- Zorg ervoor dat het script en de AWS Glue Streaming-taak nog steeds werken:
- Het Python-script (
generate-data-for-kds.py) loopt nog steeds. - De gegenereerde data wordt naar de datastroom gestuurd.
- De AWS Glue-streamingtaak is nog steeds actief.
- Het Python-script (
- Voer op de Athena-console de volgende SQL uit in de query-editor:
Het volgende queryresultaat toont de records die zijn verwerkt voordat de tabel waarnaar wordt verwezen, is gewijzigd. Opnames in de combinedname kolom zijn vergelijkbaar met <2-digit-country-code>-<country-name>.

Het volgende queryresultaat toont de records die zijn verwerkt nadat de tabel waarnaar wordt verwezen, is gewijzigd. Opnames in de combinedname kolom zijn vergelijkbaar met <2-digit-country-code>-<3-digit-country-code>-<country-name>.

U begrijpt nu dat de gewijzigde referentiegegevens met succes worden weerspiegeld in de doel-Hudi-tabel die records samenvoegt uit de Kinesis-gegevensstroom en de referentiegegevens in DynamoDB.
Opruimen
Ruim als laatste stap de bronnen op:
- Verwijder de Kinesis-gegevensstroom.
- Verwijder de AWS DMS-migratietaak, het eindpunt en de replicatie-instantie.
- Stop en verwijder de AWS Glue-streamingtaak.
- Verwijder de AWS Cloud9-omgeving.
- Verwijder de CloudFormation-sjabloon.
Conclusie
Het bouwen en onderhouden van een transactioneel datameer dat realtime gegevensopname en -verwerking omvat, heeft meerdere variabele componenten en er moeten beslissingen worden genomen, zoals welke opnameservice moet worden gebruikt, hoe uw referentiegegevens moeten worden opgeslagen en welk raamwerk voor transactiegegevensmeer moet worden gebruikt. In dit bericht hebben we de implementatiedetails van een dergelijke pijplijn gegeven, met behulp van AWS-native componenten als bouwstenen en Apache Hudi als het open-sourceframework voor een transactioneel datameer.
Wij zijn van mening dat deze oplossing een startpunt kan zijn voor organisaties die een nieuw datameer met dergelijke vereisten willen implementeren. Bovendien zijn de verschillende componenten volledig plugbaar en kunnen ze worden gecombineerd met bestaande datalakes om nieuwe vereisten aan te pakken of bestaande vereisten te migreren en hun pijnpunten aan te pakken.
Over de auteurs
 Manische Kola is een Data Lab Solutions Architect bij AWS, waar hij nauw samenwerkt met klanten in verschillende sectoren om cloud-native oplossingen te ontwerpen voor hun data-analyse en AI-behoeften. Hij werkt samen met klanten op hun AWS-reis om hun bedrijfsproblemen op te lossen en schaalbare prototypes te bouwen. Voordat hij bij AWS kwam, heeft Manish onder meer ervaring met het helpen van klanten bij het implementeren van datawarehouse-, BI-, data-integratie- en datalake-projecten.
Manische Kola is een Data Lab Solutions Architect bij AWS, waar hij nauw samenwerkt met klanten in verschillende sectoren om cloud-native oplossingen te ontwerpen voor hun data-analyse en AI-behoeften. Hij werkt samen met klanten op hun AWS-reis om hun bedrijfsproblemen op te lossen en schaalbare prototypes te bouwen. Voordat hij bij AWS kwam, heeft Manish onder meer ervaring met het helpen van klanten bij het implementeren van datawarehouse-, BI-, data-integratie- en datalake-projecten.
 Santosh Kotagiri is een Solutions Architect bij AWS met ervaring in data-analyse en cloudoplossingen die leiden tot tastbare bedrijfsresultaten. Zijn expertise ligt in het ontwerpen en implementeren van schaalbare data-analyseoplossingen voor klanten in verschillende sectoren, met een focus op cloud-native en open-source services. Hij is gepassioneerd door het gebruik van technologie om bedrijfsgroei te stimuleren en complexe problemen op te lossen.
Santosh Kotagiri is een Solutions Architect bij AWS met ervaring in data-analyse en cloudoplossingen die leiden tot tastbare bedrijfsresultaten. Zijn expertise ligt in het ontwerpen en implementeren van schaalbare data-analyseoplossingen voor klanten in verschillende sectoren, met een focus op cloud-native en open-source services. Hij is gepassioneerd door het gebruik van technologie om bedrijfsgroei te stimuleren en complexe problemen op te lossen.
 Chiho Sugimoto is een Cloud Support Engineer in het AWS Big Data Support-team. Ze is gepassioneerd om klanten te helpen bij het bouwen van datameren met behulp van ETL-workloads. Ze houdt van planetaire wetenschap en geniet ervan om in het weekend de asteroïde Ryugu te bestuderen.
Chiho Sugimoto is een Cloud Support Engineer in het AWS Big Data Support-team. Ze is gepassioneerd om klanten te helpen bij het bouwen van datameren met behulp van ETL-workloads. Ze houdt van planetaire wetenschap en geniet ervan om in het weekend de asteroïde Ryugu te bestuderen.
 Noritaka Sekiyama is een Principal Big Data Architect in het AWS Glue-team. Hij is verantwoordelijk voor het bouwen van software-artefacten om klanten te helpen. In zijn vrije tijd fietst hij graag met zijn nieuwe racefiets.
Noritaka Sekiyama is een Principal Big Data Architect in het AWS Glue-team. Hij is verantwoordelijk voor het bouwen van software-artefacten om klanten te helpen. In zijn vrije tijd fietst hij graag met zijn nieuwe racefiets.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoAiStream. Web3 gegevensintelligentie. Kennis versterkt. Toegang hier.
- De toekomst slaan met Adryenn Ashley. Toegang hier.
- Koop en verkoop aandelen in PRE-IPO-bedrijven met PREIPO®. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/join-streaming-source-cdc-glue/

