Naarmate bedrijven groter worden, overtreft de vraag naar IP-adressen binnen het bedrijfsnetwerk vaak het aanbod. Het netwerk van een organisatie wordt vaak ontworpen met enige anticipatie op toekomstige vereisten, maar naarmate bedrijven evolueren, overtreffen hun behoeften op het gebied van informatietechnologie (IT) het eerder ontworpen netwerk. Bedrijven kunnen geconfronteerd worden met de uitdaging om de beperkte pool van IP-adressen te beheren.
Voor data-engineering-workloads wanneer AWS lijm wordt gebruikt in een dergelijke beperkte netwerkconfiguratie, kan uw team soms hindernissen tegenkomen bij het tegelijkertijd uitvoeren van veel taken. Dit gebeurt omdat u mogelijk niet over voldoende IP-adressen beschikt om de vereiste verbindingen met databases te ondersteunen. Om dit tekort te verhelpen, kan het team meer IP-adressen uit uw bedrijfsnetwerkpool halen. Deze verkregen IP-adressen kunnen uniek (niet-overlappend) of overlappend zijn, wanneer de IP-adressen worden hergebruikt in uw bedrijfsnetwerk.
Wanneer u overlappende IP-adressen gebruikt, heeft u extra netwerkbeheer nodig om connectiviteit tot stand te brengen. Netwerkoplossingen kunnen opties omvatten zoals particuliere Network Address Translation (NAT)-gateways, AWS PrivéLink, of zelfbeheerde NAT-apparaten om IP-adressen te vertalen.
In dit bericht bespreken we twee strategieën om AWS Glue-taken te schalen:
- Het optimaliseren van het IP-adresverbruik door Data Processing Units (DPU's) op de juiste grootte te zetten, met behulp van de Auto Scaling-functie van AWS Glue, en het verfijnen van de taken.
- Uitbreiding van de netwerkcapaciteit met behulp van een extra niet-routeerbaar CIDR-bereik (Classless Inter-Domain Routing) met een privé NAT-gateway.
Voordat we diep ingaan op deze oplossingen, moeten we eerst begrijpen hoe AWS Glue gebruikt Elastische netwerkinterface (ENI) voor het tot stand brengen van connectiviteit. Om toegang tot datastores binnen een VPC mogelijk te maken, moet u een AWS Glue-verbinding maken die aan uw VPC is gekoppeld. Wanneer een AWS Glue-taak op uw VPC wordt uitgevoerd, maakt de taak voor elke dataverbinding een ENI aan binnen de geconfigureerde VPC, en die ENI gebruikt een IP-adres in de opgegeven VPC. Deze ENI's zijn van korte duur en actief totdat de taak is voltooid.
Laten we nu eens kijken naar de eerste oplossing die het optimaliseren van het AWS Glue IP-adresverbruik uitlegt.
Strategieën voor efficiënt IP-adresverbruik
In AWS Glue bepaalt het aantal werknemers dat een taak gebruikt het aantal IP-adressen dat wordt gebruikt vanuit uw VPC-subnet. Dit komt omdat elke werknemer één IP-adres nodig heeft dat is toegewezen aan één ENI. Als er niet voldoende CIDR-bereik is toegewezen aan het AWS Glue-subnet, kunnen er fouten optreden bij het uitputten van IP-adressen. Hieronder volgen enkele best practices om het gebruik van AWS Glue IP-adressen te optimaliseren:
- De DPU's van de taak op de juiste maat brengen – AWS Glue is een gedistribueerde verwerkingsengine. Het werkt efficiënt wanneer het taken parallel kan uitvoeren. Als een taak meer dan de vereiste DPU's heeft, wordt deze niet altijd sneller uitgevoerd. Het vinden van het juiste aantal DPU's zorgt er dus voor dat u IP-adressen optimaal gebruikt. Door zichtbaarheid in het systeem in te bouwen en de taakprestaties te analyseren, kunt u inzicht krijgen in ENI-verbruikstrends en vervolgens de juiste capaciteit voor de taak configureren voor de juiste omvang. Voor meer details, zie Monitoring voor DPU-capaciteitsplanning. De Spark UI is een handig hulpmiddel om het gebruik van AWS Glue-taken door werknemers te monitoren. Voor meer details, zie Taken bewaken met behulp van de Apache Spark-webgebruikersinterface.
- AWS Glue Auto Scaling – Het is vaak moeilijk om vooraf de capaciteitsvereisten van een taak te voorspellen. Het inschakelen van de Auto Scaling-functie van AWS Glue zal een deel van deze verantwoordelijkheid overbrengen naar AWS. Tijdens runtime schaalt de taak, op basis van de werklastvereisten, automatisch werkknooppunten tot aan de gedefinieerde maximale configuratie. Als er geen extra behoefte is, zal AWS Glue de werknemers niet overbezetten, waardoor middelen worden bespaard en de kosten worden verlaagd. De functie Automatisch schalen is beschikbaar in AWS Glue 3.0 en hoger. Voor meer informatie, zie Introductie van AWS Glue Auto Scaling: automatisch formaat wijzigen van serverloze computerbronnen voor lagere kosten met geoptimaliseerde Apache Spark.
- Optimalisatie op taakniveau – Identificeer optimalisaties op taakniveau met behulp van AWS Glue-taakstatistieken , en best practices van toepassen Best practices voor het afstemmen van prestaties op AWS Glue voor Apache Spark-taken.
Laten we vervolgens eens kijken naar de tweede oplossing die uitbreiding van de netwerkcapaciteit uitwerkt.
Oplossingen voor uitbreiding van de netwerkgrootte (IP-adres).
In deze sectie bespreken we twee mogelijke oplossingen om de netwerkomvang in meer detail uit te breiden.
Breid het VPC CIDR-bereik uit met routeerbare adressen
Eén oplossing is om meer private IPv4 CIDR-bereiken toe te voegen RFC 1918 naar uw VPC. Theoretisch kan elk AWS-account worden toegewezen aan enkele of al deze IP-adres-CIDR's. Uw IP Address Management (IPAM)-team beheert vaak de toewijzing van IP-adressen die elke bedrijfseenheid kan gebruiken vanuit RFC1918 om overlappende IP-adressen tussen meerdere AWS-accounts of bedrijfseenheden te voorkomen. Als uw huidige door het IPAM-team toegewezen quotum voor routeerbare IP-adressen niet voldoende is, kunt u om meer verzoeken.
Als uw IPAM-team u een extra, niet-overlappende CIDR-reeks verstrekt, kunt u deze toevoegen als secundaire CIDR aan uw bestaande VPC of er een nieuwe VPC mee maken. Als u van plan bent een nieuwe VPC aan te maken, kunt u de VPC's onderling met elkaar verbinden via VPC-peering or AWS-transitgateway.
Als deze extra capaciteit voldoende is om al uw opdrachten binnen een bepaald tijdsbestek uit te voeren, dan is het een eenvoudige en kosteneffectieve oplossing. Anders kunt u overwegen om overlappende IP-adressen te gebruiken met een particuliere NAT-gateway, zoals beschreven in de volgende sectie. Met de volgende oplossing moet u Transit Gateway gebruiken om VPC's te verbinden, omdat VPC-peering niet mogelijk is als er overlappende CIDR-bereiken zijn in die twee VPC's.
Configureer niet-routeerbare CIDR met een privé NAT-gateway
Zoals beschreven in de AWS-whitepaper Bouwen aan een schaalbare en veilige multi-VPC AWS-netwerkinfrastructuur, kunt u uw netwerkcapaciteit uitbreiden door een niet-routeerbaar IP-adressubnet te creëren en een privé NAT-gateway te gebruiken die zich in een routeerbare IP-adresruimte (niet-overlappend) bevindt om verkeer te routeren. Een particuliere NAT-gateway vertaalt en routeert verkeer tussen niet-routeerbare IP-adressen en routeerbare IP-adressen. Het volgende diagram demonstreert de oplossing met verwijzing naar AWS Glue.
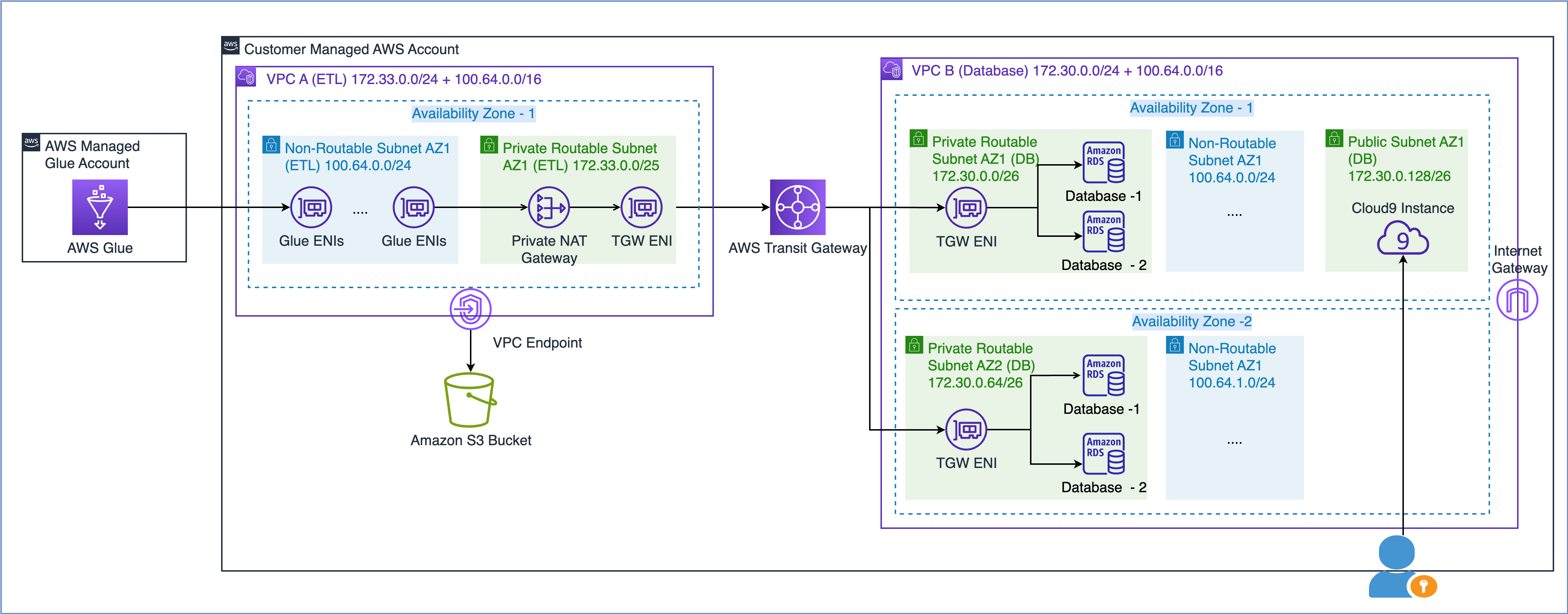
Zoals u in het bovenstaande diagram kunt zien, heeft VPC A (ETL) twee aangesloten CIDR-bereiken. Het kleinere CIDR-bereik 172.33.0.0/24 is routeerbaar omdat het nergens opnieuw wordt gebruikt, terwijl het grotere CIDR-bereik 100.64.0.0/16 niet routeerbaar is omdat het wordt hergebruikt in de database VPC.
In VPC B (Database) hebben we twee databases gehost in routeerbare subnetten 172.30.0.0/26 en 172.30.0.64/26. Deze twee subnetten bevinden zich in twee afzonderlijke beschikbaarheidszones voor hoge beschikbaarheid. We hebben ook twee extra ongebruikte subnetten 100.64.0.0/24 en 100.64.1.0/24 om een niet-routeerbare opstelling te simuleren.
U kunt de grootte van het niet-routeerbare CIDR-assortiment kiezen op basis van uw capaciteitsvereisten. Omdat u IP-adressen kunt hergebruiken, kunt u indien nodig een zeer groot subnet creëren. Een CIDR-masker van /16 zou u bijvoorbeeld ongeveer 65,000 IPv4-adressen opleveren. U kunt samenwerken met uw netwerkengineeringteam en de grootte van de subnetten bepalen.
Kortom, u kunt AWS Glue-taken configureren om zowel routeerbare als niet-routeerbare subnetten in uw VPC te gebruiken om de beschikbare IP-adrespool te maximaliseren.
Laten we nu begrijpen hoe Glue ENI's die zich in een niet-routeerbaar subnet bevinden, communiceren met gegevensbronnen in een andere VPC.
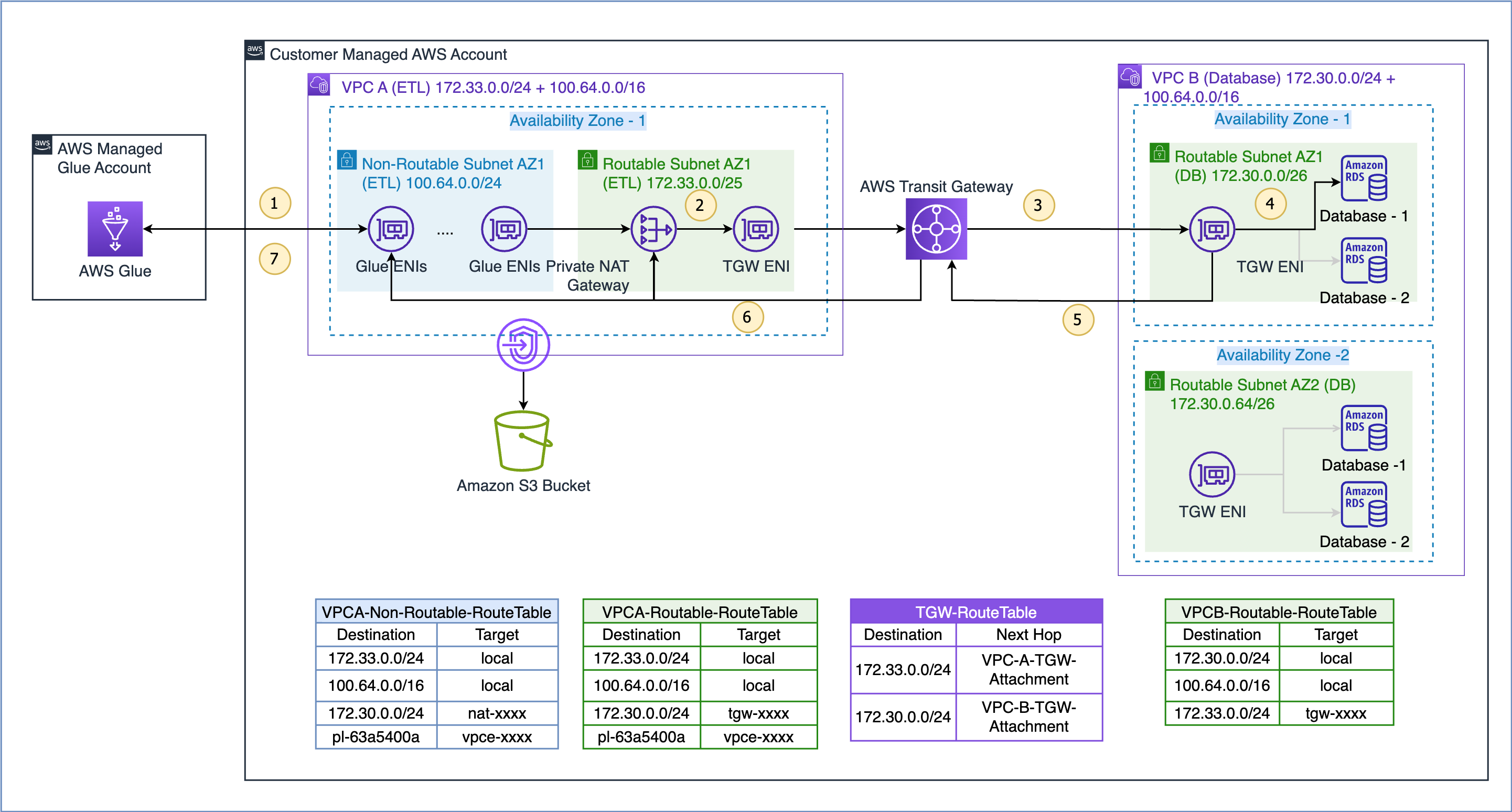
De gegevensstroom voor de hier gedemonstreerde use case is als volgt (verwijzend naar de genummerde stappen in de bovenstaande afbeelding):
- Wanneer een AWS Glue-taak toegang nodig heeft tot een gegevensbron, gebruikt deze eerst de AWS Glue-verbinding op de taak en creëert de ENI's in het niet-routeerbare subnet 100.64.0.0/24 in VPC A. Later gebruikt AWS Glue de configuratie van de databaseverbinding en probeert verbinding te maken met de database in VPC B 172.30.0.0/24.
- Volgens de routetabel
VPCA-Non-Routable-RouteTablede bestemming 172.30.0.0/24 is geconfigureerd voor een privé NAT-gateway. Het verzoek wordt naar de NAT-gateway gestuurd, die vervolgens het bron-IP-adres vertaalt van een niet-routeerbaar IP-adres naar een routeerbaar IP-adres. Verkeer wordt vervolgens naar de transitgatewaybijlage in VPC A gestuurd omdat het is gekoppeld aan deVPCA-Routable-RouteTableroutetabel in VPC A. - Transit Gateway gebruikt de 172.30.0.0/24-route en stuurt het verkeer naar de VPC B-transitgatewaybijlage.
- De transitgateway ENI in VPC B gebruikt de lokale route van VPC B om verbinding te maken met het database-eindpunt en de gegevens op te vragen.
- Wanneer de zoekopdracht is voltooid, wordt het antwoord teruggestuurd naar VPC A. Het antwoordverkeer wordt doorgestuurd naar de transitgateway-bijlage in VPC B, waarna Transit Gateway de route 172.33.0.0/24 gebruikt en verkeer naar de transitgateway-bijlage van VPC A stuurt .
- De transitgateway ENI in VPC A gebruikt de lokale route om het verkeer door te sturen naar de private NAT-gateway, die het bestemmings-IP-adres vertaalt naar dat van ENI's in een niet-routeerbaar subnet.
- Ten slotte ontvangt de AWS Glue-taak de gegevens en gaat door met de verwerking.
De private NAT gateway oplossing is een optie als u extra IP-adressen nodig heeft wanneer u deze niet kunt verkrijgen via een routeerbaar netwerk in uw organisatie. Soms worden er bij elke extra service extra kosten gemaakt, en deze afweging is nodig om uw doelen te bereiken. Raadpleeg het gedeelte over NAT Gateway-prijzen op de website Amazon VPC-prijspagina voor meer informatie.
Voorwaarden
Om het overzicht van de private NAT-gatewayoplossing te voltooien, hebt u het volgende nodig:
Implementeer de oplossing
Voer de volgende stappen uit om de oplossing te implementeren:
- Meld u aan bij uw AWS-beheerconsole.
- Implementeer de oplossing door te klikken
 . Deze stapel is standaard ingesteld op
. Deze stapel is standaard ingesteld op us-east-1, kunt u de gewenste regio selecteren. - Klik volgende en geef vervolgens de stapeldetails op. U kunt de invoerparameters behouden op de vooraf ingevulde standaardwaarden of deze indien nodig wijzigen.
- Voor
DatabaseUserPassword, voer een alfanumeriek wachtwoord naar keuze in en zorg ervoor dat u dit noteert voor verder gebruik. - Voor
S3BucketName, voer een uniek in Amazon eenvoudige opslagservice (Amazon S3) bucketnaam. In deze bucket wordt het AWS Glue-taakscript opgeslagen dat wordt gekopieerd uit een openbare AWS-coderepository.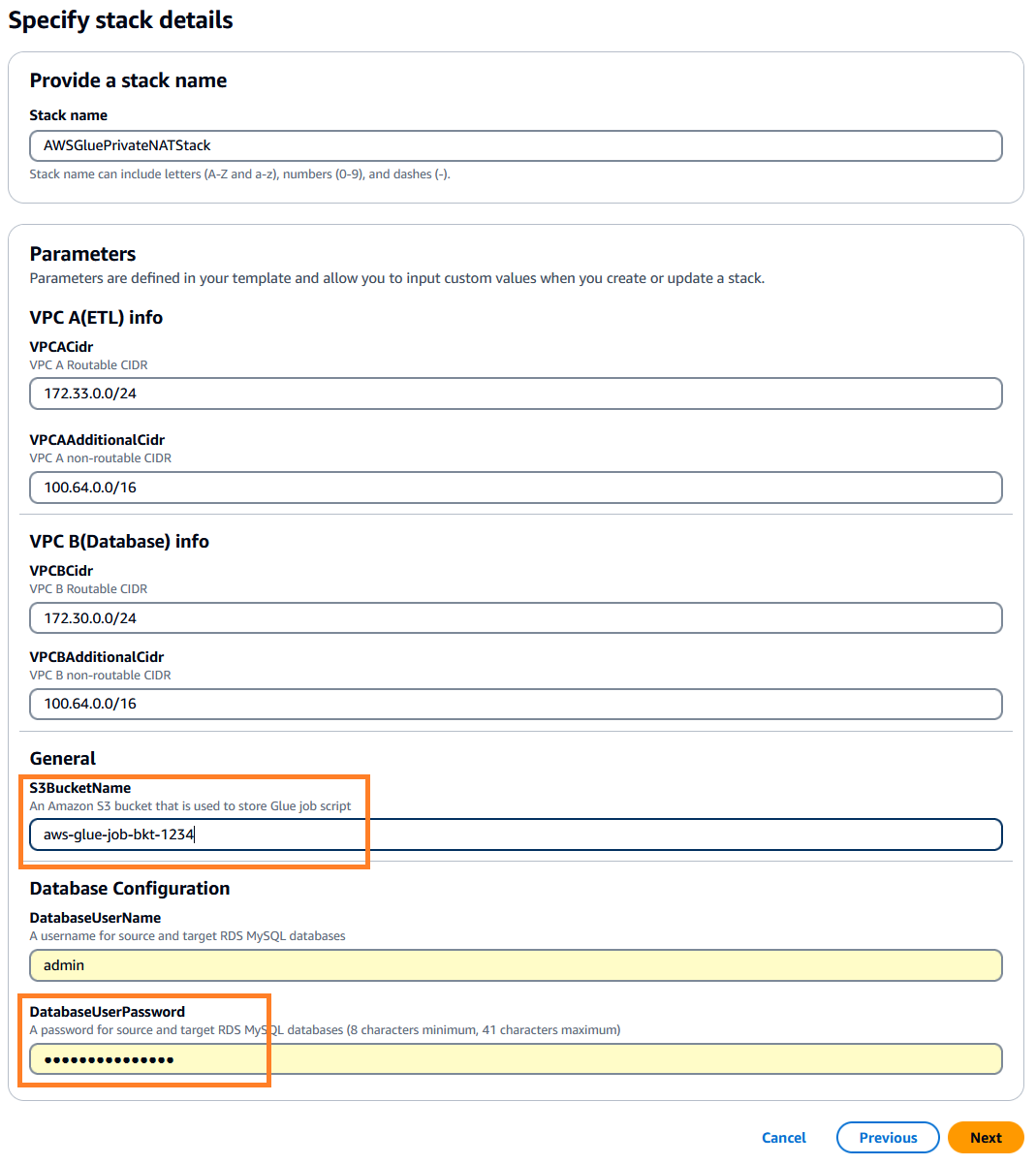
- Klik volgende.
- Laat de standaardwaarden staan en klik volgende weer.
- Bekijk de details, bevestig de creatie van IAM-bronnen en klik voorleggen om de implementatie te starten.
U kunt de gebeurtenissen volgen om te zien hoe bronnen worden aangemaakt op de AWS CloudFormation-console. Het kan ongeveer 20 minuten duren voordat de stapelresources zijn gemaakt.
Nadat het maken van de stapel is voltooid, gaat u naar het tabblad Uitvoer op de AWS CloudFormation-console en noteert u de volgende waarden voor later gebruik:
DBSourceDBTargetSourceCrawlerTargetCrawler
Maak verbinding met een AWS Cloud9-instantie
Vervolgens moeten we de bron- en doel-Amazon RDS voor MySQL-tabellen voorbereiden met behulp van een AWS-Cloud9 voorbeeld. Voer de volgende stappen uit:
- Zoek op de AWS Cloud9-consolepagina het
aws-glue-cloud9milieu. - Klik in de Cloud9 IDE-kolom op Openen om uw AWS Cloud9-instantie in een nieuwe webbrowser te starten.
Bereid de MySQL-brontabel voor
Voer de volgende stappen uit om uw brontabel voor te bereiden:
- Installeer vanaf de AWS Cloud9-terminal de MySQL-client met behulp van de volgende opdracht:
sudo yum update -y && sudo yum install -y mysql - Maak verbinding met de brondatabase met behulp van de volgende opdracht. Vervang de bronhostnaam door de DBSource-waarde die u eerder hebt vastgelegd. Voer desgevraagd het databasewachtwoord in dat u hebt opgegeven tijdens het maken van de stapel.
mysql -h <Source Hostname> -P 3306 -u admin -p - Voer de volgende scripts uit om de bron te maken
emptabel en laad de testgegevens:-- connect to source database USE srcdb; -- Drop emp table if it exists DROP TABLE IF EXISTS emp; -- Create the emp table CREATE TABLE emp (empid INT AUTO_INCREMENT, ename VARCHAR(100) NOT NULL, edept VARCHAR(100) NOT NULL, PRIMARY KEY (empid)); -- Create a stored procedure to load sample records into emp table DELIMITER $$ CREATE PROCEDURE sp_load_emp_source_data() BEGIN DECLARE empid INT; DECLARE ename VARCHAR(100); DECLARE edept VARCHAR(50); DECLARE cnt INT DEFAULT 1; -- Initialize counter to 1 to auto-increment the PK DECLARE rec_count INT DEFAULT 1000; -- Initialize sample records counter TRUNCATE TABLE emp; -- Truncate the emp table WHILE cnt <= rec_count DO -- Loop and load the required number of sample records SET ename = CONCAT('Employee_', FLOOR(RAND() * 100) + 1); -- Generate random employee name SET edept = CONCAT('Dept_', FLOOR(RAND() * 100) + 1); -- Generate random employee department -- Insert record with auto-incrementing empid INSERT INTO emp (ename, edept) VALUES (ename, edept); -- Increment counter for next record SET cnt = cnt + 1; END WHILE; COMMIT; END$$ DELIMITER ; -- Call the above stored procedure to load sample records into emp table CALL sp_load_emp_source_data(); - Controleer de bron
emptabeltelling met behulp van de onderstaande SQL-query (u hebt deze bij een latere stap nodig voor verificatie).select count(*) from emp; - Voer de volgende opdracht uit om het MySQL-clienthulpprogramma af te sluiten en terug te keren naar de terminal van de AWS Cloud9-instantie:
quit;
Bereid de doel-MySQL-tabel voor
Voer de volgende stappen uit om de doeltabel voor te bereiden:
- Maak verbinding met de doeldatabase met behulp van de volgende opdracht. Vervang de doelhostnaam door de DBTarget-waarde die u eerder hebt vastgelegd. Wanneer daarom wordt gevraagd, voert u het databasewachtwoord in dat u hebt opgegeven tijdens het maken van de stapel.
mysql -h <Target Hostname> -P 3306 -u admin -p - Voer de volgende scripts uit om het doel te maken
emptafel. Deze tabel wordt in de volgende stap door de AWS Glue-taak geladen.-- connect to the target database USE targetdb; -- Drop emp table if it exists DROP TABLE IF EXISTS emp; -- Create the emp table CREATE TABLE emp (empid INT AUTO_INCREMENT, ename VARCHAR(100) NOT NULL, edept VARCHAR(100) NOT NULL, PRIMARY KEY (empid) );
Controleer de netwerkinstellingen (optioneel)
De volgende stappen zijn handig om inzicht te krijgen in de NAT-gateway, routetabellen en de transitgatewayconfiguraties van een particuliere NAT-gatewayoplossing. Deze componenten zijn gemaakt tijdens het maken van de CloudFormation-stack.
- Navigeer op de Amazon VPC-consolepagina naar het gedeelte Virtuele privécloud en zoek NAT-gateways.
- Zoek naar NAT Gateway met naam
Glue-OverlappingCIDR-NATGWen onderzoek het verder. Zoals u in de volgende schermafbeelding kunt zien, is de NAT-gateway gemaakt in VPC A (ETL) op het routeerbare subnet.
- Navigeer in het navigatievenster aan de linkerkant naar Routetabellen onder de sectie Virtual Private Cloud.
- Zoek naar
VPCA-Non-Routable-RouteTableen onderzoek het verder. U kunt zien dat de routetabel is geconfigureerd om verkeer van overlappende CIDR te vertalen met behulp van de NAT-gateway.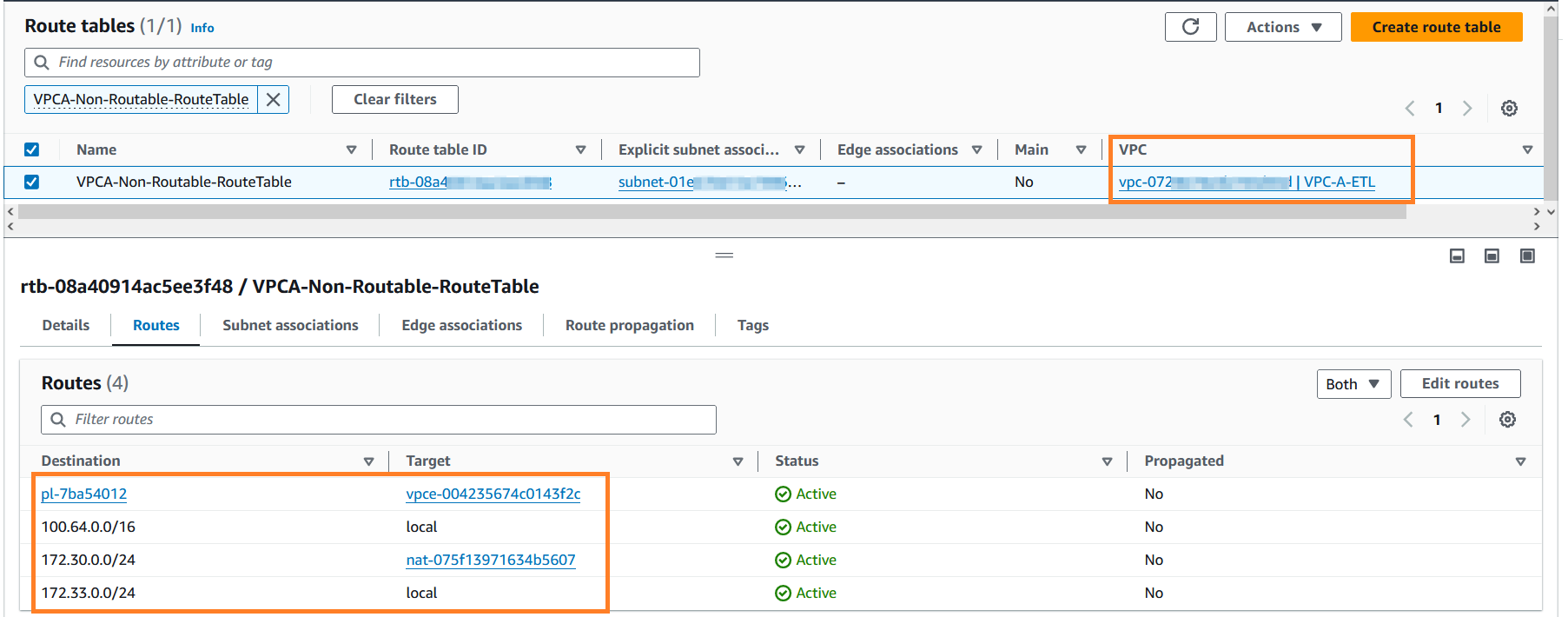
- Navigeer in het navigatievenster aan de linkerkant naar de sectie Transit-gateways en klik op Transit-gateway-bijlagen. Binnenkomen
VPC-in het zoekvak en zoek de twee nieuw gemaakte transitgateway-bijlagen. - U kunt deze bijlagen verder verkennen om hun configuraties te leren kennen.
Voer de AWS Glue-crawlers uit
Voer de volgende stappen uit om de AWS Glue-crawlers uit te voeren die nodig zijn om de bron en het doel te catalogiseren emp tafels. Dit is een vereiste stap voor het uitvoeren van de AWS Glue-taak.
- Klik op de AWS Glue Console-pagina, onder de sectie Gegevenscatalogus in het navigatievenster, op crawlers.
- Zoek de bron- en doelcrawlers die u eerder hebt genoteerd.
- Selecteer deze crawlers en klik lopen om de respectieve AWS Glue Data Catalog-tabellen te maken.
- U kunt de AWS Glue-crawlers controleren op een succesvolle voltooiing. Het kan ongeveer 3 tot 4 minuten duren voordat beide crawlers zijn voltooid. Wanneer ze klaar zijn, verandert de status van de laatste run van de taak in Geslaagd, en je kunt ook zien dat er twee AWS Glue-catalogustabellen zijn gemaakt op basis van deze run.

Voer de AWS Glue ETL-taak uit
Nadat u de tabellen hebt ingesteld en de vereiste stappen hebt voltooid, bent u nu klaar om de AWS Glue-taak uit te voeren die u hebt gemaakt met behulp van de CloudFormation-sjabloon. Deze taak maakt verbinding met de bron-RDS voor MySQL-database, extraheert de gegevens en laadt de gegevens in de doel-RDS voor MySQL-database. Deze taak leest gegevens uit een MySQL-brontabel en laadt deze naar de MySQL-doeltabel met behulp van een privé-NAT-gatewayoplossing. Voer de volgende stappen uit om de AWS Glue-taak uit te voeren:
- Klik op de AWS Glue-console op ETL-banen in het navigatievenster.
- Klik op de baan
glue-private-nat-job. - Klik lopen om het te starten.
Het volgende is het PySpark-script voor deze ETL-taak:
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
args = getResolvedOptions(sys.argv, ["JOB_NAME"])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args["JOB_NAME"], args)
# Script generated for node AWS Glue Data Catalog
AWSGlueDataCatalog_node = glueContext.create_dynamic_frame.from_catalog(
database="glue_cat_db_source",
table_name="srcdb_emp",
transformation_ctx="AWSGlueDataCatalog_node",
)
# Script generated for node Change Schema
ChangeSchema_node = ApplyMapping.apply(
frame=AWSGlueDataCatalog_node,
mappings=[
("empid", "int", "empid", "int"),
("ename", "string", "ename", "string"),
("edept", "string", "edept", "string"),
],
transformation_ctx="ChangeSchema_node",
)
# Script generated for node AWS Glue Data Catalog
AWSGlueDataCatalog_node = glueContext.write_dynamic_frame.from_catalog(
frame=ChangeSchema_node,
database="glue_cat_db_target",
table_name="targetdb_emp",
transformation_ctx="AWSGlueDataCatalog_node",
)
job.commit()
Op basis van de DPU-configuratie van de taak creëert AWS Glue een set ENI's in het niet-routeerbare subnet dat is geconfigureerd op de AWS Glue-verbinding. U kunt deze ENI's volgen op de pagina Netwerkinterfaces van de Amazon Elastic Compute-cloud (Amazon EC2)-console.
De onderstaande schermafbeelding toont de 10 ENI's die zijn gemaakt voor de taakuitvoering om overeen te komen met het gevraagde aantal werknemers dat is geconfigureerd in de taakparameters. Zoals verwacht zijn de ENI's gemaakt in het niet-routeerbare subnet van VPC A, waardoor schaalbaarheid van IP-adressen mogelijk is. Nadat de klus is voltooid, worden deze ENI's automatisch vrijgegeven door AWS Glue.
Wanneer de AWS Glue-taak actief is, kunt u de status ervan controleren. Na succesvolle voltooiing verandert de status van de taak in Langs.
Controleer de resultaten
Nadat de AWS Glue-taak is voltooid, maakt u verbinding met de doel-MySQL-database. Controleer of het doelrecordaantal overeenkomt met de bron. U kunt de onderstaande SQL-query gebruiken in de AWS Cloud9-terminal.
USE targetdb;
SELECT count(*) from emp;Sluit ten slotte het MySQL-clienthulpprogramma af met de volgende opdracht en keer terug naar de AWS Cloud9-terminal: quit;
U kunt nu bevestigen dat AWS Glue met succes een taak heeft voltooid om gegevens naar een doeldatabase te laden met behulp van de IP-adressen van een niet-routeerbaar subnet. Hiermee zijn de end-to-end tests van de private NAT-gatewayoplossing afgerond.
Opruimen
Om te voorkomen dat er in de toekomst kosten in rekening worden gebracht, verwijdert u de via de CloudFormation-stack gemaakte bron door de volgende stappen te voltooien:
- Klik in de AWS CloudFormation-console op Stapels in het navigatievenster.
- Selecteer de stapel
AWSGluePrivateNATStack. - Klik op Verwijderen om de stapel te verwijderen. Bevestig het verwijderen van de stapel wanneer daarom wordt gevraagd.
Conclusie
In dit bericht hebben we gedemonstreerd hoe u AWS Glue-taken kunt schalen door het verbruik van IP-adressen te optimaliseren en uw netwerkcapaciteit uit te breiden met behulp van een particuliere NAT-gatewayoplossing. Deze tweeledige aanpak helpt u de blokkering op te heffen in een omgeving met beperkingen op het gebied van de IP-adrescapaciteit. De opties die worden besproken in de sectie AWS Glue IP-adresoptimalisatie zijn complementair aan de oplossingen voor IP-adresuitbreiding, en u kunt iteratief bouwen om uw dataplatform volwassen te maken.
Lees meer over AWS Glue-taakoptimalisatietechnieken van Bewaak en optimaliseer de kosten op AWS Glue voor Apache Spark en Best practices voor het schalen van Apache Spark-taken en het partitioneren van gegevens met AWS Glue.
Over de auteurs
 Sushanth Kothapally is een Solutions Architect bij Amazon Web Services die klanten uit de automobiel- en productiesector ondersteunt. Hij heeft een passie voor het ontwerpen van technologische oplossingen om bedrijfsdoelen te bereiken en heeft een grote interesse in serverloze en gebeurtenisgestuurde architecturen.
Sushanth Kothapally is een Solutions Architect bij Amazon Web Services die klanten uit de automobiel- en productiesector ondersteunt. Hij heeft een passie voor het ontwerpen van technologische oplossingen om bedrijfsdoelen te bereiken en heeft een grote interesse in serverloze en gebeurtenisgestuurde architecturen.
 Senthil Kamala Rathinam is een Solutions Architect bij Amazon Web Services, gespecialiseerd in Data en Analytics. Hij heeft een passie voor het helpen van klanten bij het ontwerpen en bouwen van moderne dataplatforms. In zijn vrije tijd brengt Senthil graag tijd door met zijn gezin en speelt hij graag badminton.
Senthil Kamala Rathinam is een Solutions Architect bij Amazon Web Services, gespecialiseerd in Data en Analytics. Hij heeft een passie voor het helpen van klanten bij het ontwerpen en bouwen van moderne dataplatforms. In zijn vrije tijd brengt Senthil graag tijd door met zijn gezin en speelt hij graag badminton.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/scale-aws-glue-jobs-by-optimizing-ip-address-consumption-and-expanding-network-capacity-using-a-private-nat-gateway/

