Wanneer Apache Flink-applicaties worden uitgevoerd Amazon Managed Service voor Apache Flink, heeft u het unieke voordeel dat u profiteert van het serverloze karakter ervan. Dit betekent dat kostenoptimalisatie-oefeningen op elk moment kunnen plaatsvinden; ze hoeven niet langer in de planningsfase te gebeuren. Met Managed Service voor Apache Flink kunt u met één klik op de knop rekenkracht toevoegen en verwijderen.
Apache Flink is een open source streamverwerkingsframework dat door honderden bedrijven wordt gebruikt in kritieke bedrijfsapplicaties, en door duizenden ontwikkelaars die streamverwerkingsbehoeften hebben voor hun werklasten. Het is zeer beschikbaar en schaalbaar en biedt een hoge doorvoer en lage latentie voor de meest veeleisende streamverwerkingstoepassingen. Deze schaalbare eigenschappen van Apache Flink kunnen van cruciaal belang zijn voor het optimaliseren van uw kosten in de cloud.
Managed Service voor Apache Flink is een volledig beheerde service die de complexiteit van het bouwen en beheren van Apache Flink-applicaties vermindert. Managed Service voor Apache Flink beheert de onderliggende infrastructuur en Apache Flink-componenten die een duurzame applicatiestatus, statistieken, logboeken en meer bieden.
In dit bericht kunt u meer te weten komen over het Managed Service for Apache Flink-kostenmodel, gebieden waarop u kosten kunt besparen in uw Apache Flink-applicaties en in het algemeen een beter inzicht krijgen in uw gegevensverwerkingspijplijnen. We duiken diep in het begrijpen van uw kosten, begrijpen of uw applicatie overprovisioned is, hoe u kunt nadenken over automatisch schalen en manieren om uw Apache Flink-applicaties te optimaliseren om kosten te besparen. Ten slotte stellen we belangrijke vragen over uw werklast om te bepalen of Apache Flink de juiste technologie is voor uw gebruiksscenario.
Hoe de kosten worden berekend op Managed Service voor Apache Flink
Om de kosten met betrekking tot uw Managed Service voor Apache Flink-applicatie te optimaliseren, kan het helpen om een goed idee te hebben van wat er in de prijs voor de managed service zit.
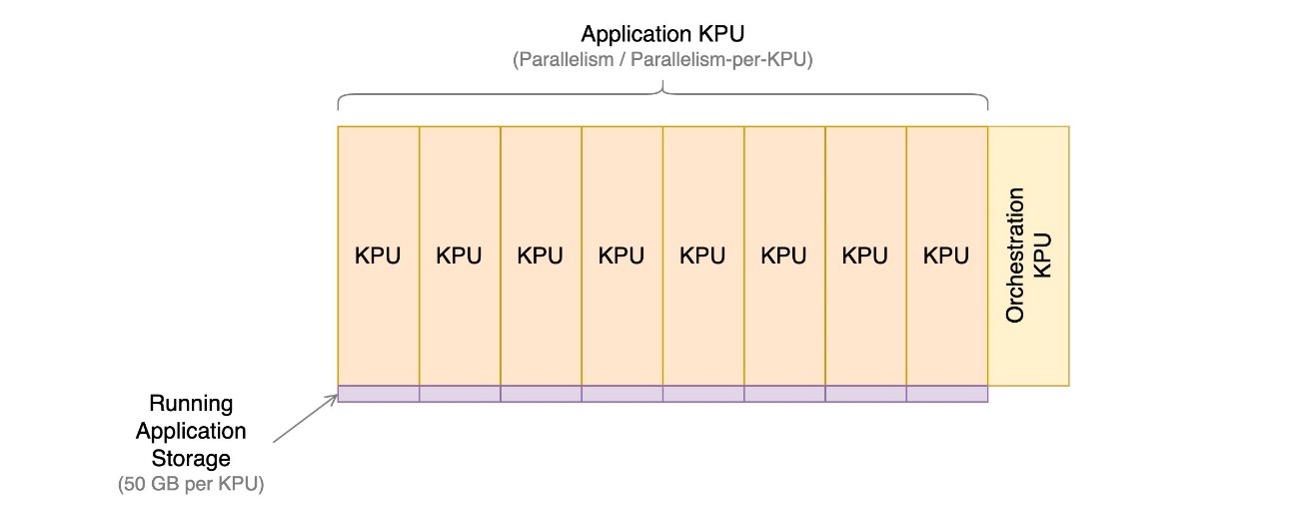
Managed Service voor Apache Flink-applicaties bestaat uit Kinesis Processing Units (KPU's), dit zijn rekeninstanties die zijn samengesteld uit 1 virtuele CPU en 4 GB geheugen. Het totale aantal KPU's dat aan de applicatie is toegewezen, wordt bepaald door twee parameters te vermenigvuldigen die u rechtstreeks beheert:
- Parallellisme – Het niveau van parallelle verwerking in de Apache Flink-applicatie
- Parallelliteit per KPU – Het aantal bronnen dat aan elk parallellisme is toegewezen
Het aantal KPU's wordt bepaald door de eenvoudige formule: KPU = Parallellisme / ParallellismePerKPU, naar boven afgerond op het volgende gehele getal.
Er wordt ook een extra KPU per applicatie in rekening gebracht voor orkestratie, die niet rechtstreeks wordt gebruikt voor gegevensverwerking.
Het totale aantal KPU's bepaalt het aantal bronnen, CPU, geheugen en applicatieopslag dat aan de applicatie is toegewezen. Voor elke KPU ontvangt de applicatie 1 vCPU en 4 GB geheugen, waarvan 3 GB standaard wordt toegewezen aan de actieve applicatie en de resterende 1 GB wordt gebruikt voor het beheer van de applicatiestatusopslag. Elke KPU wordt ook geleverd met 50 GB opslagruimte die aan de applicatie is gekoppeld. Apache Flink behoudt de applicatiestatus in het geheugen tot een configureerbare limiet, en overloop naar de aangesloten opslag.
De derde kostencomponent zijn duurzame back-ups van applicaties, of snapshots. Dit is volledig optioneel en de impact ervan op de totale kosten is klein, tenzij u een zeer groot aantal snapshots bewaart.
Op het moment van schrijven kost elke KPU in de AWS-regio US East (Ohio) $0.11 per uur, en de aangesloten applicatieopslag kost $0.10 per GB per maand. De kosten voor duurzame applicatieback-up (snapshots) bedragen $ 0.023 per GB per maand. Verwijzen naar Amazon Managed Service voor Apache Flink-prijzen voor actuele prijzen en verschillende regio's.
Het volgende diagram illustreert de relatieve verhoudingen van kostencomponenten voor een actieve applicatie op Managed Service voor Apache Flink. U regelt het aantal KPU's via de parallelliteit en parallelliteit per KPU-parameters. Duurzame back-upopslag voor applicaties is niet vertegenwoordigd.
In de volgende secties onderzoeken we hoe u uw kosten kunt bewaken, het gebruik van applicatiebronnen kunt optimaliseren en het vereiste aantal KPU's kunt vinden om uw doorvoerprofiel te verwerken.
AWS Cost Explorer en inzicht in uw factuur
Om te zien wat uw huidige Managed Service for Apache Flink-uitgaven zijn, kunt u gebruiken AWS-kostenverkenner.
Op de Cost Explorer-console kunt u filteren op datumbereik, gebruikstype en service om uw uitgaven voor Managed Service voor Apache Flink-applicaties te isoleren. De volgende schermafbeelding toont de kosten van de afgelopen twaalf maanden, opgesplitst in de prijscategorieën die in de vorige sectie zijn beschreven. Het merendeel van de uitgaven in veel van deze maanden was afkomstig van interactieve KPU's Amazon Managed Service voor Apache Flink Studio.
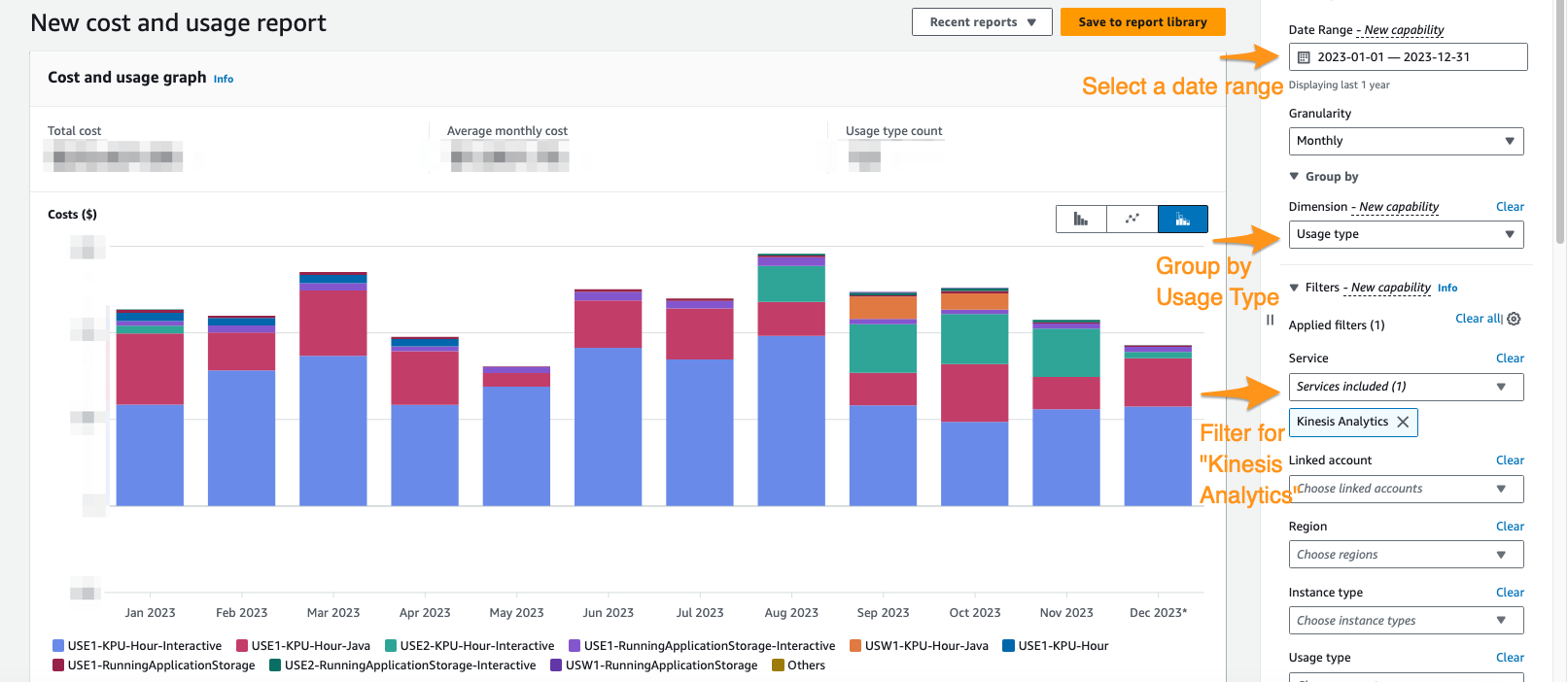
Het gebruik van Cost Explorer kan u niet alleen helpen uw factuur te begrijpen, maar ook helpen bij het verder optimaliseren van bepaalde applicaties die mogelijk automatisch of vanwege doorvoervereisten boven verwachting zijn geschaald. Met de juiste applicatietagging kunt u deze uitgaven ook per applicatie opsplitsen om te zien welke applicaties de kosten voor hun rekening nemen.
Tekenen van overprovisioning of inefficiënt gebruik van hulpbronnen
Om de kosten die verband houden met Managed Service voor Apache Flink-applicaties te minimaliseren, bestaat er een eenvoudige aanpak uit het verminderen van het aantal KPU's dat uw applicaties gebruiken. Het is echter van cruciaal belang om te erkennen dat deze reductie de prestaties negatief kan beïnvloeden als deze niet grondig wordt beoordeeld en getest. Om snel te bepalen of uw applicaties mogelijk overprovisioned zijn, onderzoekt u belangrijke indicatoren zoals CPU- en geheugengebruik, applicatiefunctionaliteit en gegevensdistributie. Hoewel deze indicatoren kunnen wijzen op mogelijke overprovisioning, is het echter essentieel om prestatietests uit te voeren en uw schaalpatronen te valideren voordat u wijzigingen aanbrengt in het aantal KPU's.
Metriek
Het analyseren van statistieken voor uw toepassing on Amazon Cloud Watch kunnen duidelijke signalen van overprovisioning aan het licht brengen. Als de containerCPUUtilization en containerMemoryUtilization Als de statistieken gedurende een statistisch significante periode consistent onder de 20% blijven voor de verkeerspatronen van uw applicatie, kan het haalbaar zijn om terug te schalen en meer gegevens aan minder machines toe te wijzen. Over het algemeen beschouwen we toepassingen van de juiste grootte wanneer containerCPUUtilization schommelt tussen 50-75%. Hoewel containerMemoryUtilization kan gedurende de dag fluctueren en worden beïnvloed door code-optimalisatie, een consistent lage waarde gedurende een aanzienlijke periode kan duiden op mogelijke overprovisioning.
Parallelliteit per KPU onderbenut
Een ander subtiel teken dat uw toepassing overprovisioned is, is als uw toepassing puur I/O-gebonden is, of alleen eenvoudige aanroepen naar databases en niet-CPU-intensieve bewerkingen uitvoert. Als dit het geval is, kunt u de parallelliteit per KPU-parameter binnen Managed Service voor Apache Flink gebruiken om meer taken op één verwerkingseenheid te laden.
U kunt het parallellisme per KPU-parameter bekijken als een maatstaf voor de dichtheid van de werklast per eenheid reken- en geheugenbronnen (de KPU). Als u het parallellisme per KPU boven de standaardwaarde van 1 verhoogt, wordt de verwerking dichter, waardoor er meer parallelle processen aan één enkele KPU worden toegewezen.
In het volgende diagram ziet u hoe uw toepassing, door het parallellisme van de toepassing constant te houden (bijvoorbeeld 4) en het parallellisme per KPU te verhogen (bijvoorbeeld van 1 naar 2), minder bronnen gebruikt bij hetzelfde niveau aan parallelle uitvoeringen.
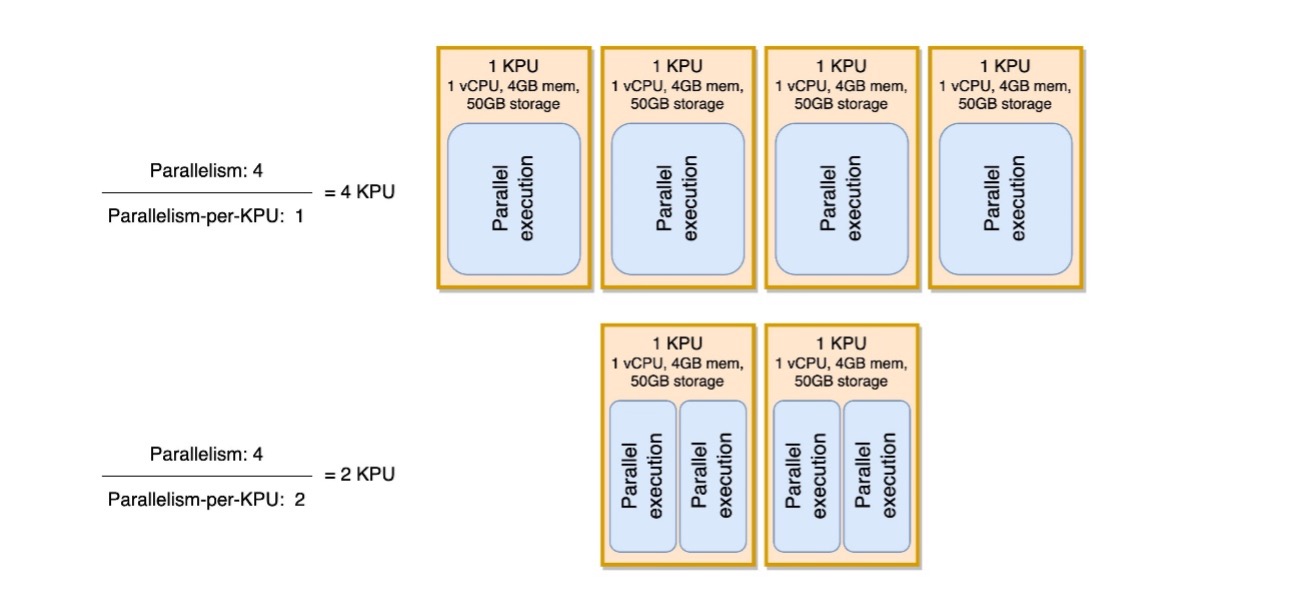
De beslissing om de parallelliteit per KPU te vergroten, moet, zoals alle aanbevelingen in dit bericht, met grote zorg worden genomen. Het verhogen van de parallelliteit per KPU-waarde kan een enkele KPU meer belasten, en deze moet bereid zijn die belasting te tolereren. I/O-gebonden bewerkingen zullen het CPU- of geheugengebruik op geen enkele zinvolle manier verhogen, maar een procesfunctie die veel complexe bewerkingen op basis van de gegevens berekent, zou geen ideale bewerking zijn om op één enkele KPU te verzamelen, omdat deze de bronnen zou kunnen overweldigen. Prestatietest en evalueer of dit een goede optie is voor uw toepassingen.
Hoe de maatvoering te benaderen
Voordat u een Managed Service voor Apache Flink-applicatie opzet, kan het lastig zijn om in te schatten hoeveel KPU's u voor uw applicatie moet toewijzen. Over het algemeen moet u een goed beeld hebben van uw verkeerspatronen voordat u een schatting maakt. Als u uw verkeerspatronen op basis van de opnamesnelheid van megabytes per seconde begrijpt, kunt u een beginpunt bepalen.
Als algemene regel kunt u beginnen met één KPU per 1 MB/s die uw aanvraag zal verwerken. Als uw applicatie bijvoorbeeld (gemiddeld) 10 MB/s verwerkt, wijst u 10 KPU's toe als uitgangspunt voor uw applicatie. Houd er rekening mee dat dit een benadering op zeer hoog niveau is die volgens ons effectief is voor een algemene schatting. U moet echter ook prestatietests uitvoeren en evalueren of dit op de lange termijn de juiste maatvoering is, op basis van statistieken (CPU, geheugen, latentie, algehele taakprestaties) over een lange periode.
Om de juiste grootte voor uw toepassing te vinden, moet u de Apache Flink-toepassing omhoog en omlaag schalen. Zoals gezegd heb je in Managed Service voor Apache Flink twee afzonderlijke besturingselementen: parallellisme en parallellisme per KPU. Samen bepalen deze parameters het niveau van parallelle verwerking binnen de applicatie en de totale beschikbare reken-, geheugen- en opslagbronnen.
De aanbevolen testmethode is om parallellisme of parallellisme per KPU afzonderlijk te wijzigen, terwijl u experimenteert om de juiste maatvoering te vinden. Wijzig in het algemeen alleen het parallellisme per KPU om het aantal parallelle I/O-gebonden bewerkingen te vergroten, zonder de totale bronnen te vergroten. In alle andere gevallen wijzigt u alleen het parallellisme (KPU zal consequent veranderen) om de juiste maat voor uw werklast te vinden.
Ook stel parallelliteit in op operatorniveau om bronnen, putten of andere operatoren te beperken die mogelijk moeten worden beperkt en onafhankelijk van schaalmechanismen. U kunt dit gebruiken voor een Apache Flink-toepassing die leest uit een Apache Kafka-onderwerp met 10 partities. Met de setParallelism() Met deze methode kunt u de KafkaSource beperken tot 10, maar de Managed Service for Apache Flink-toepassing schalen naar een parallellisme hoger dan 10 zonder inactieve taken voor de Kafka-bron te creëren. Voor andere gevallen van gegevensverwerking wordt aanbevolen om het parallellisme van de operator niet statisch in te stellen op een statische waarde, maar eerder op een functie van het parallellisme van de applicatie, zodat deze schaalt wanneer de algehele applicatie schaalt.
Schalen en automatisch schalen
In Managed Service voor Apache Flink is het wijzigen van parallellisme of parallellisme per KPU een update van de applicatieconfiguratie. Het zorgt ervoor dat de toepassing automatisch een momentopname (tenzij uitgeschakeld), stop de toepassing en start deze opnieuw met de nieuwe grootte, waarbij u de status herstelt vanaf de momentopname. Schaalbewerkingen veroorzaken geen gegevensverlies of inconsistenties, maar pauzeren wel de gegevensverwerking voor een korte periode terwijl infrastructuur wordt toegevoegd of verwijderd. Dit is iets waarmee u rekening moet houden bij het herschalen in een productieomgeving.
Tijdens het test- en optimalisatieproces raden we u aan deze uit te schakelen automatisch schalen en het aanpassen van parallellisme en parallellisme per KPU om de optimale waarden te vinden. Zoals gezegd is handmatig schalen slechts een update van de applicatieconfiguratie en kan het worden uitgevoerd via de AWS-beheerconsole of API met de Actie Applicatie bijwerken.
Wanneer u de optimale grootte heeft gevonden en u verwacht dat uw opgenomen doorvoer aanzienlijk zal variëren, kunt u besluiten automatisch schalen in te schakelen.
In Managed Service voor Apache Flink kunt u meerdere typen automatische schaling gebruiken:
- Kant-en-klaar automatisch schalen – U kunt dit inschakelen om de parallelliteit van de toepassing automatisch aan te passen op basis van de
containerCPUUtilizationmetriek. Automatisch schalen is standaard ingeschakeld voor nieuwe applicaties. Voor meer informatie over het automatische schalingsalgoritme raadpleegt u Automatische schaalverdeling. - Fijnkorrelige, op metrische gegevens gebaseerde automatische schaling – Dit is eenvoudig te implementeren. De automatisering kan op vrijwel alle statistieken worden gebaseerd, inclusief aangepaste statistieken uw toepassing blootlegt.
- Geplande schaalvergroting – Dit kan handig zijn als u op bepaalde tijdstippen van de dag of dagen van de week pieken in de werkdruk verwacht.
Kant-en-klare automatische schaling en fijnmazige, op statistieken gebaseerde schaling sluiten elkaar uit. Voor meer details over fijnmazige, op metrische gegevens gebaseerde automatische schaling en geplande schaling, en een volledig werkend codevoorbeeld, raadpleegt u Schakel op statistieken gebaseerde en geplande schaling in voor Amazon Managed Service voor Apache Flink.
Code-optimalisaties
Een andere manier om kostenbesparingen voor uw Managed Service voor Apache Flink-applicaties te realiseren is door middel van code-optimalisatie. Voor niet-geoptimaliseerde code zijn meer machines nodig om dezelfde berekeningen uit te voeren. Het optimaliseren van de code zou een lager totaalgebruik van bronnen mogelijk kunnen maken, wat op zijn beurt schaalverkleining en kostenbesparingen mogelijk zou maken.
De eerste stap om inzicht te krijgen in de prestaties van uw code is via het ingebouwde hulpprogramma binnen Apache Flink genaamd Vlamgrafieken.
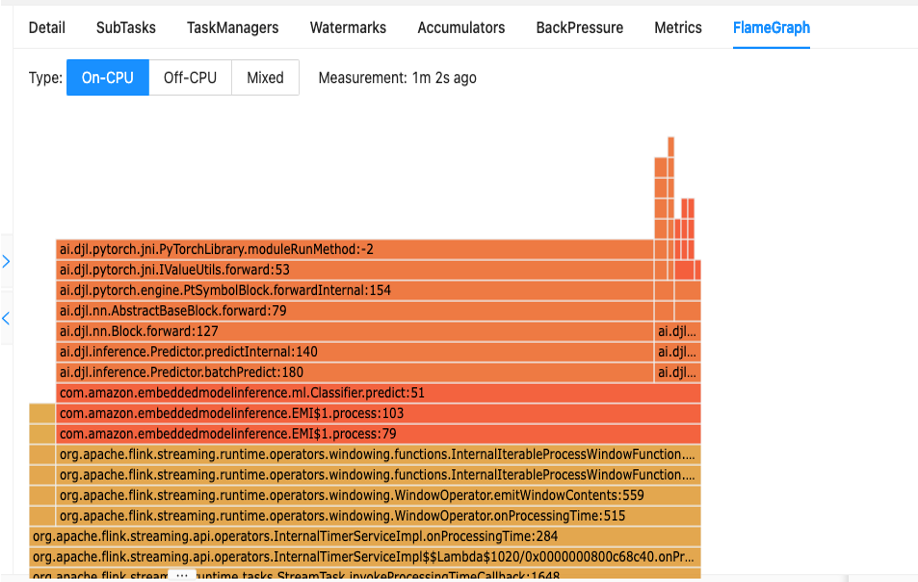
Flame Graphs, die toegankelijk zijn via het Apache Flink-dashboard, geven u een visuele weergave van uw stacktrace. Elke keer dat een methode wordt aangeroepen, wordt de balk die die methodeaanroep in de stacktrace vertegenwoordigt, groter in verhouding tot het totale aantal monsters. Dit betekent dat als je een inefficiënt stuk code hebt met een hele lange balk in de vlamgrafiek, dit reden kan zijn om te onderzoeken hoe je deze code efficiënter kunt maken. Bovendien kunt u gebruik maken van Amazon CodeGuru-profiler naar bewaak en optimaliseer uw Apache Flink-applicaties die draaien op Managed Service voor Apache Flink.
Bij het ontwerpen van uw applicaties wordt aanbevolen om de API van het hoogste niveau te gebruiken die op een bepaald moment voor een bepaalde bewerking vereist is. Apache Flink biedt vier niveaus van API-ondersteuning: Flink SQL, Table API, Datastream API, en ProcessFunction API's, met toenemende complexiteit en verantwoordelijkheid. Als uw toepassing volledig in de Flink SQL- of Table-API kan worden geschreven, kunt u hiermee profiteren van het Apache Flink-framework in plaats van de status en berekeningen handmatig te beheren.
Gegevens scheef
Op het Apache Flink-dashboard kunt u andere nuttige informatie verzamelen over uw Managed Service voor Apache Flink-taken.
Op het dashboard kunt u individuele taken binnen uw sollicitatiegrafiek bekijken. Elk blauw vak vertegenwoordigt een taak en elke taak is samengesteld uit subtaken of gedistribueerde werkeenheden voor die taak. Op deze manier kunt u gegevensscheefheid tussen subtaken identificeren.
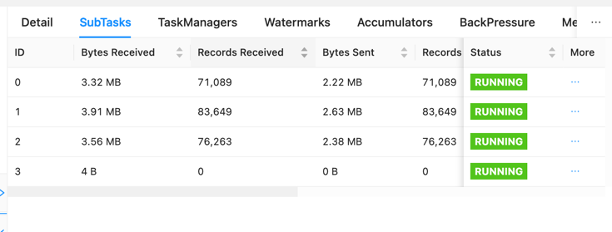
Gegevensscheefheid is een indicatie dat er meer gegevens naar de ene subtaak worden verzonden dan naar de andere, en dat een subtaak die meer gegevens ontvangt, meer werk doet dan de andere. Als u dergelijke symptomen van scheeftrekking van gegevens heeft, kunt u eraan werken deze te elimineren door de bron te identificeren. Bijvoorbeeld, een GroupBy or KeyedStream er kan een scheefheid in de sleutel zitten. Dit zou betekenen dat de gegevens niet gelijkmatig over de sleutels worden verdeeld, wat resulteert in een ongelijke verdeling van het werk over de Apache Flink-rekeninstances. Stel je een scenario voor waarin je groepeert userId, maar uw toepassing ontvangt aanzienlijk meer gegevens van de ene gebruiker dan de rest. Dit kan leiden tot gegevensvertekening. Om dit te elimineren, kunt u een andere groeperingssleutel kiezen om de gegevens gelijkmatig over subtaken te verdelen. Houd er rekening mee dat hiervoor een codewijziging nodig is om een andere sleutel te kiezen.
Wanneer de gegevensscheefheid is geëlimineerd, kunt u terugkeren naar het containerCPUUtilization en containerMemoryUtilization statistieken om het aantal KPU's te verminderen.
Andere gebieden voor code-optimalisatie zijn onder meer ervoor zorgen dat u toegang krijgt tot externe systemen via de Asynchrone I/O-API of via een datastream-join, omdat een synchrone query naar een datastore vertragingen en problemen bij de checkpointing kan veroorzaken. Zie bovendien Problemen met prestaties oplossen voor problemen die u mogelijk ondervindt met trage controlepunten of logboekregistratie, die tegendruk in de applicatie kunnen veroorzaken.
Hoe u kunt bepalen of Apache Flink de juiste technologie is
Als uw toepassing geen van de krachtige mogelijkheden achter het Apache Flink-framework en Managed Service voor Apache Flink gebruikt, kunt u mogelijk kosten besparen door iets eenvoudigers te gebruiken.
De slogan van Apache Flink is 'Stateful Computations over Data Streams'. Stateful betekent in deze context dat u de Apache Flink-statusconstructie gebruikt. Met State kun je in Apache Flink berichten die je in het verleden hebt gezien voor langere tijd onthouden, waardoor zaken als streaming joins, deduplicatie, precies één keer verwerken, windowing en verwerking van late gegevens mogelijk worden. Dit gebeurt door gebruik te maken van een in-memory state store. Op Managed Service voor Apache Flink wordt gebruik gemaakt van RocksDB om zijn staat te behouden.
Als uw toepassing geen stateful bewerkingen omvat, kunt u alternatieven overwegen, zoals AWS Lambda, gecontaineriseerde toepassingen, of een Amazon Elastic Compute-cloud (Amazon EC2)-instantie waarop uw toepassing wordt uitgevoerd. De complexiteit van Apache Flink is in dergelijke gevallen misschien niet nodig. Stateful berekeningen, inclusief gegevens in de cache of verrijkingsprocedures die een onafhankelijk stroompositiegeheugen vereisen, kunnen de stateful mogelijkheden van Apache Flink garanderen. Als de kans bestaat dat uw applicatie in de toekomst stateful wordt, bijvoorbeeld door langdurig bewaren van gegevens of andere stateful vereisten, kan het eenvoudiger zijn om Apache Flink te blijven gebruiken. Organisaties die de nadruk leggen op Apache Flink vanwege de mogelijkheden voor streamverwerking, blijven misschien liever bij Apache Flink voor stateful en stateless applicaties, zodat al hun applicaties gegevens op dezelfde manier verwerken. Je moet ook rekening houden met de orkestratiefuncties zoals precies één keer verwerken, fan-out-mogelijkheden en gedistribueerde berekeningen voordat je overstapt van Apache Flink naar alternatieven.
Een andere overweging zijn uw latentievereisten. Omdat Apache Flink uitblinkt in realtime gegevensverwerking, heeft het gebruik ervan voor een applicatie met een latentievereiste van 6 uur of 1 dag geen zin. De kostenbesparingen door over te stappen op een tijdelijk batchproces Amazon eenvoudige opslagservice (Amazon S3) zou bijvoorbeeld aanzienlijk zijn.
Conclusie
In dit bericht hebben we enkele aspecten besproken waarmee u rekening moet houden bij het proberen van kostenbesparende maatregelen voor Managed Service voor Apache Flink. We hebben besproken hoe u uw totale uitgaven aan de beheerde service kunt identificeren, enkele nuttige statistieken die u kunt monitoren bij het terugschalen van uw KPU's, hoe u uw code kunt optimaliseren voor het terugschalen en hoe u kunt bepalen of Apache Flink geschikt is voor uw gebruiksscenario.
Het implementeren van deze kostenbesparende strategieën verbetert niet alleen uw kostenefficiëntie, maar zorgt ook voor een gestroomlijnde en goed geoptimaliseerde Apache Flink-implementatie. Door rekening te houden met uw totale uitgaven, belangrijke meetgegevens te gebruiken en weloverwogen beslissingen te nemen over het terugschalen van resources, kunt u een kosteneffectieve bedrijfsvoering realiseren zonder dat dit ten koste gaat van de prestaties. Terwijl u door het landschap van Apache Flink navigeert, wordt het voortdurend evalueren of het aansluit bij uw specifieke gebruiksscenario cruciaal, zodat u een op maat gemaakte en efficiënte oplossing voor uw gegevensverwerkingsbehoeften kunt bereiken.
Als een van de aanbevelingen die in dit bericht worden besproken, resoneert met uw werklast, raden we u aan deze uit te proberen. Met de gespecificeerde statistieken en de tips over hoe u uw workloads beter kunt begrijpen, beschikt u nu over wat u nodig heeft om uw Apache Flink-workloads op Managed Service voor Apache Flink efficiënt te optimaliseren. Hier volgen enkele nuttige bronnen die u kunt gebruiken om dit bericht aan te vullen:
Over de auteurs
 Jeremy Ber heeft de afgelopen 10 jaar in de telemetriedataruimte gewerkt als Software Engineer, Machine Learning Engineer en meest recentelijk als Data Engineer. Bij AWS is hij een Streaming Specialist Solutions Architect, die zowel Amazon Managed Streaming voor Apache Kafka (Amazon MSK) als Amazon Managed Service voor Apache Flink ondersteunt.
Jeremy Ber heeft de afgelopen 10 jaar in de telemetriedataruimte gewerkt als Software Engineer, Machine Learning Engineer en meest recentelijk als Data Engineer. Bij AWS is hij een Streaming Specialist Solutions Architect, die zowel Amazon Managed Streaming voor Apache Kafka (Amazon MSK) als Amazon Managed Service voor Apache Flink ondersteunt.
 Lorenzo Nicora werkt als Senior Streaming Solution Architect bij AWS en helpt klanten in heel EMEA. Hij bouwt al meer dan 25 jaar cloud-native, data-intensieve systemen en werkt in de financiële sector, zowel via adviesbureaus als voor FinTech-productbedrijven. Hij heeft op grote schaal gebruik gemaakt van open-sourcetechnologieën en heeft bijgedragen aan verschillende projecten, waaronder Apache Flink.
Lorenzo Nicora werkt als Senior Streaming Solution Architect bij AWS en helpt klanten in heel EMEA. Hij bouwt al meer dan 25 jaar cloud-native, data-intensieve systemen en werkt in de financiële sector, zowel via adviesbureaus als voor FinTech-productbedrijven. Hij heeft op grote schaal gebruik gemaakt van open-sourcetechnologieën en heeft bijgedragen aan verschillende projecten, waaronder Apache Flink.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/real-time-cost-savings-for-amazon-managed-service-for-apache-flink/

