Amazon T-extract is een machine learning (ML)-service die automatisch tekst, handschrift en gegevens uit gescande documenten haalt. Queries is een functie waarmee u specifieke stukjes informatie uit variërende, complexe documenten kunt extraheren met behulp van natuurlijke taal. Aangepaste zoekopdrachten biedt u een manier om de functie Query's op een zelfbedieningsmanier aan te passen voor uw bedrijfsspecifieke, niet-standaard documenten, zoals autoleningscontracten, cheques en loonoverzichten. Door de functie aan te passen zodat de unieke termen, structuren en belangrijke informatie die specifiek zijn voor deze documenttypen worden herkend, kunt u met grotere precisie en minimale menselijke tussenkomst aan uw downstream-verwerkingsbehoeften voldoen. Aangepaste zoekopdrachten zijn eenvoudig te integreren in uw bestaande Textract-pijplijn en u blijft profiteren van de volledig beheerde intelligente documentverwerkingsfuncties van Amazon Textract zonder dat u hoeft te investeren in ML-expertise of infrastructuurbeheer.
In dit bericht laten we zien hoe aangepaste query's nauwkeurig gegevens kunnen extraheren uit cheques die complexe, niet-standaard documenten zijn. Daarnaast bespreken we de voordelen van aangepaste zoekopdrachten en delen we best practices voor het effectief gebruik van deze functie.
Overzicht oplossingen
Wanneer u met een nieuw gebruiksscenario begint, kunt u evalueren hoe Textract Queries op uw documenten presteert door naar het Textract-console en gebruik de Analyse Document Demo of Bulk Document Uploader. Verwijzen naar Best Practices voor Query's om zoekopdrachten op te stellen die van toepassing zijn op uw gebruiksscenario. Als u fouten in de antwoorden op de vragen constateert vanwege de aard van uw bedrijfsdocumenten, kunt u aangepaste zoekopdrachten gebruiken om de nauwkeurigheid te verbeteren. Binnen enkele uren kunt u uw voorbeelddocumenten annoteren met behulp van de AWS-beheerconsole en train een adapter. Adapters zijn componenten die worden aangesloten op het vooraf getrainde deep learning-model van Amazon Textract, waarbij de uitvoer wordt aangepast op basis van uw geannoteerde documenten. U kunt de adapter gebruiken voor gevolgtrekking door de adapter-ID als extra parameter door te geven aan de Analyseer documentquery's API-verzoek.
Laten we onderzoeken hoe Aangepaste zoekopdrachten kan de nauwkeurigheid van de extractie verbeteren in een uitdagend real-world scenario, zoals het extraheren van gegevens uit cheques. De belangrijkste uitdaging bij het verwerken van cheques komt voort uit de grote mate van variatie, afhankelijk van het type (bijvoorbeeld persoonlijke cheques of cheques), financiële instelling en land (bijvoorbeeld MICR-lijnformaat). . Deze variaties kunnen de plaatsing van de naam van de begunstigde, het bedrag in cijfers en woorden, de datum en de handtekening omvatten. Het herkennen van en aanpassen aan deze variaties kan een complexe taak zijn tijdens de gegevensextractie. Om de gegevensextractie te verbeteren, maken organisaties vaak gebruik van handmatige verificatie- en validatieprocessen, waardoor de kosten en tijd van het extractieproces toenemen.
Aangepaste query's pakken deze uitdagingen aan door u in staat te stellen de vooraf getrainde functies voor query's aan te passen voor de verschillende varianten van controles. Door de vooraf getrainde functie aan te passen, kunt u een hoge nauwkeurigheid van de gegevensextractie bereiken voor de specifieke verscheidenheid aan lay-outs die u verwerkt.
In ons gebruiksscenario wil een financiële instelling de volgende velden uit een cheque halen: naam van de begunstigde, naam van de betaler, rekeningnummer, routeringsnummer, betalingsbedrag (in cijfers), betalingsbedrag (in woorden), chequenummer, datum en memo.
Laten we eens kijken naar het proces van het genereren van een adapter (een component die de uitvoer aanpast) voor de verwerking van cheques. Adapters kunnen via de console of programmatisch via de API worden gemaakt. Dit bericht beschrijft de console-ervaring; Als u de adapter echter programmatisch wilt maken, raadpleegt u de codevoorbeelden in de aangepaste-queries-checks-blog.ipynb Jupyter-notebook (optie 2).
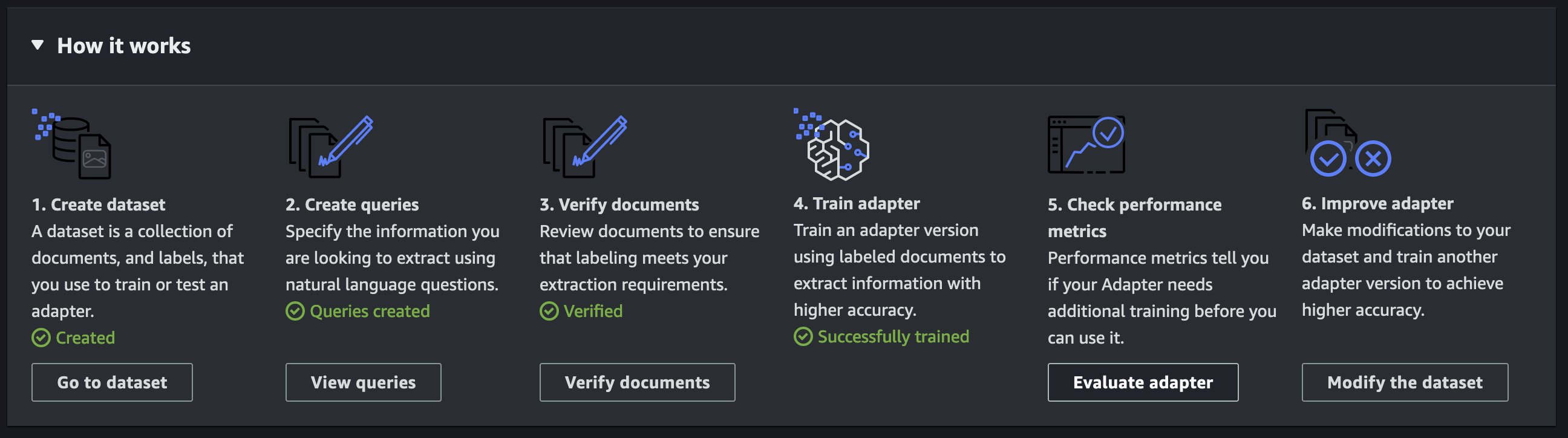
Het proces voor het genereren van de adapter omvat vijf stappen op hoog niveau: een adapter maken, voorbeelddocumenten uploaden, de documenten annoteren, de adapter trainen en de prestatiestatistieken evalueren.
Maak een adapter
Maak op de Amazon Textract-console een nieuwe adapter door een naam, beschrijving en optionele tags op te geven waarmee u de adapter kunt identificeren. U heeft de mogelijkheid om automatische updates in te schakelen, waardoor Amazon Textract uw adapter kan updaten wanneer de onderliggende Queries-functie wordt bijgewerkt met nieuwe mogelijkheden.

Nadat de adapter is gemaakt, ziet u een pagina met adapterdetails met een lijst met stappen in het Hoe het werkt sectie. In dit gedeelte worden uw volgende stappen geactiveerd terwijl u ze opeenvolgend voltooit.

Voorbeelddocumenten uploaden
De eerste fase bij het genereren van adapters omvat de zorgvuldige selectie van een geschikte set voorbeelddocumenten voor annotatie, training en testen. We hebben een optie om de documenten automatisch te splitsen in test- en treindatasets; Voor dit proces splitsen we de dataset echter handmatig.
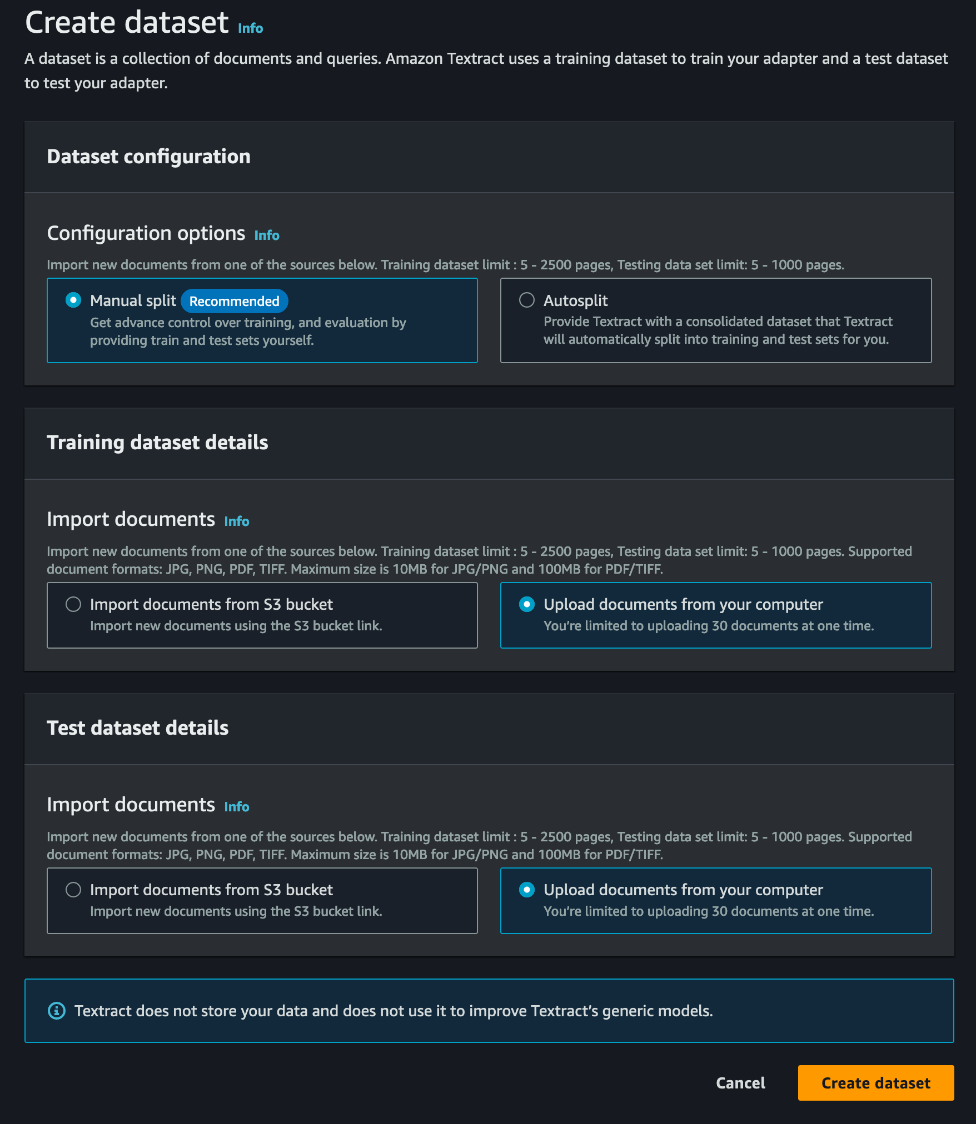
Het is belangrijk op te merken dat u een adapter kunt construeren met slechts vijf test- en vijf trainingsvoorbeelden, maar het is essentieel om ervoor te zorgen dat deze voorbeeldset divers is en representatief voor de werklast die u in een productieomgeving tegenkomt.
Voor deze zelfstudie hebben we voorbeeldcontrolegegevenssets samengesteld die u kunt gebruiken Download. Onze dataset bevat variaties zoals persoonlijke cheques, kassiercheques, stimuluscheques en cheques ingebed in loonstrookjes. We hebben ook handgeschreven en gedrukte cheques toegevoegd; samen met variaties in velden zoals de memoregel.
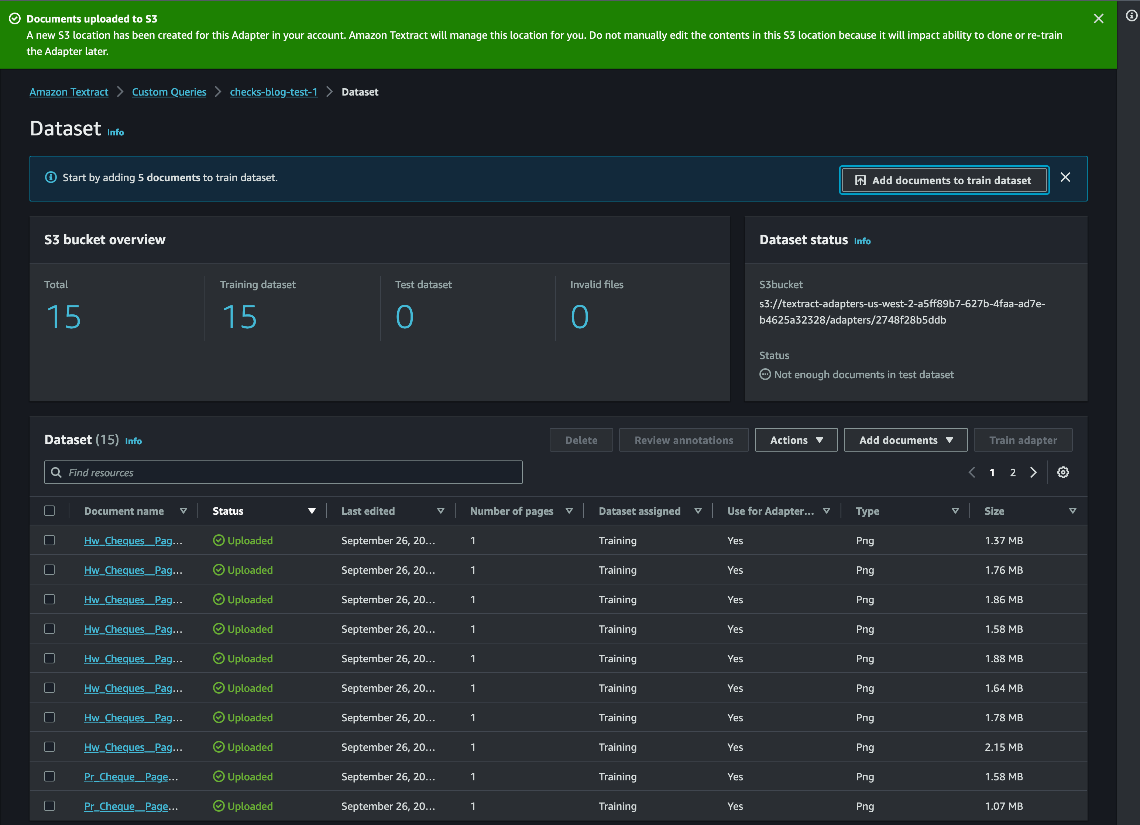
Annoteer voorbeelddocumenten
Als volgende stap annoteert u de voorbeelddocumenten door via de console queries te koppelen aan de bijbehorende antwoorden. U kunt annotaties starten via automatisch labelen of handmatig labelen. Automatische labeling maakt gebruik van Amazon Textract Queries om de dataset vooraf te labelen. We raden u aan automatische labeling te gebruiken om het annotatieproces te versnellen.
Voor deze gebruikssituatie voor de verwerking van controles gebruiken we de volgende query's. Als uw gebruiksscenario andere documenttypen betreft, raadpleegt u Best Practices voor Query's om zoekopdrachten op te stellen die van toepassing zijn op uw gebruiksscenario.
- Wie is de begunstigde?
- Wat is de cheque#?
- Wat is het adres van de begunstigde?
- Wat is de datum?
- Wat is het rekeningnummer?
- Wat is het chequebedrag in woorden?
- Wat is de rekeningnaam/betaler/ladenaam?
- Wat is het dollarbedrag?
- Wat is de naam van de bank/trekker?
- Wat is het bankrouteringsnummer?
- Wat is de MICR-lijn?
- Wat is de nota?

Wanneer het automatische etiketteringsproces is voltooid, heeft u de mogelijkheid om de antwoorden voor elk document te bekijken en te bewerken. Kiezen Begin met reviewen om de annotaties bij elke afbeelding te bekijken.
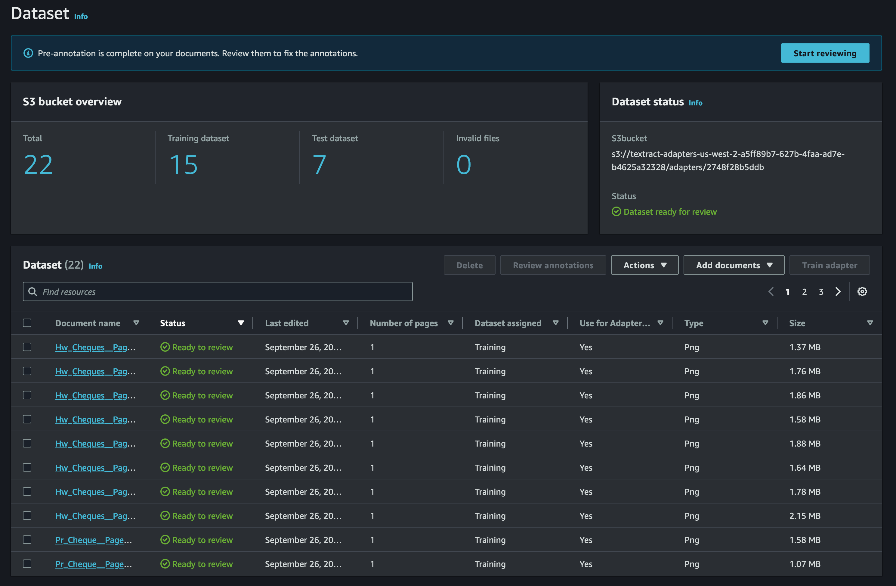
Als het antwoord op een vraag ontbreekt of onjuist is, kunt u het antwoord toevoegen of bewerken door een selectiekader te tekenen of door het antwoord handmatig in te voeren.
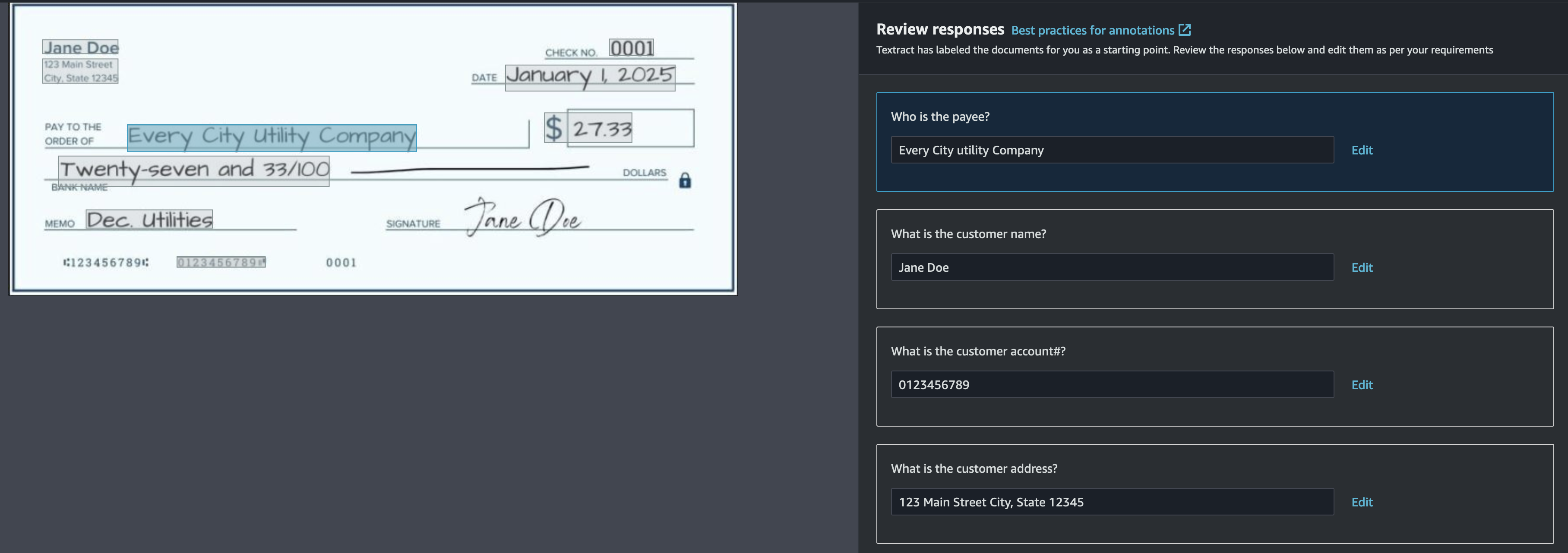
Om uw walkthrough te versnellen, hebben we de chequevoorbeelden vooraf geannoteerd, zodat u deze naar uw AWS-account kunt kopiëren. Voer de ... uit aangepaste-queries-checks-blog.ipynb Jupyter-notebook in de Amazon Textract-codevoorbeelden bibliotheek om uw annotaties automatisch bij te werken.
Train de adapter
Nadat u alle voorbeelddocumenten heeft gecontroleerd om de nauwkeurigheid van de aantekeningen te garanderen, kunt u beginnen met het adaptertrainingsproces. Tijdens deze stap moet u een opslaglocatie aanwijzen waar de adapter moet worden opgeslagen. De duur van het trainingsproces zal variëren afhankelijk van de grootte van de dataset die voor training wordt gebruikt. De trainings-API kan ook programmatisch worden aangeroepen als u ervoor kiest een annotatietool naar keuze te gebruiken en de relevante invoerbestanden door te geven aan de API. Verwijzen naar Aangepaste zoekopdrachten voor meer details.

Evalueer prestatiestatistieken
Nadat de adapter de training heeft voltooid, kunt u de prestaties ervan beoordelen door evaluatiestatistieken te onderzoeken, zoals F1-score, precisie en herinnering. U kunt deze statistieken collectief of per document analyseren. Met behulp van onze voorbeeldcontrolegegevensset ziet u dat de nauwkeurigheidsstatistiek (F1-score) verbetert van 68% naar 92% met de getrainde adapter.

Bovendien kunt u de uitvoer van de adapter op nieuwe documenten testen door te kiezen Probeer Adapter.

Na de evaluatie kunt u ervoor kiezen de prestaties van de adapter te verbeteren door aanvullende voorbeelddocumenten op te nemen in de trainingsgegevensset of door documenten opnieuw te annoteren met scores die lager zijn dan uw drempelwaarde. Als u documenten opnieuw wilt annoteren, kiest u Documenten verifiëren op de pagina met adapterdetails selecteert u het document en kiest u Annotaties bekijken.
Test de adapter programmatisch
Nadat de training met succes is afgerond, kunt u de adapter nu in uw computer gebruiken AnalyseDocument API-aanroepen. Het API-verzoek is vergelijkbaar met het Amazon Textract Queries API-verzoek, met de toevoeging van de AdaptersConfig voorwerp.
U kunt de volgende voorbeeldcode uitvoeren of deze rechtstreeks uitvoeren binnen het aangepaste-queries-checks-blog.ipynb Jupyter-notitieboekje. Het voorbeeldnotitieboekje biedt ook code om resultaten tussen Amazon Textract Queries en Amazon Textract Custom Queries te vergelijken.
Maak een AdaptersConfig object met de adapter-ID en adapterversie, en voeg optioneel de pagina's toe waarop u de adapter wilt toepassen:
Maak een QueriesConfig object met de vragen waarmee u de adapter hebt getraind en roep de Amazon Textract API aan. Houd er rekening mee dat u ook aanvullende query's kunt opnemen waarvoor de adapter niet is getraind. Amazon Textract gebruikt automatisch de functie Query's voor deze vragen en niet voor aangepaste query's, waardoor u de flexibiliteit krijgt om aangepaste query's alleen te gebruiken waar dat nodig is.
Ten slotte hebben we onze resultaten in tabelvorm weergegeven voor een betere leesbaarheid:
Opruimen
Voer de volgende stappen uit om uw bronnen op te schonen:
- Kies op de Amazon Textract-console Aangepaste zoekopdrachten in het navigatievenster.
- Selecteer de adapter die u wilt verwijderen.
- Kies Verwijder.
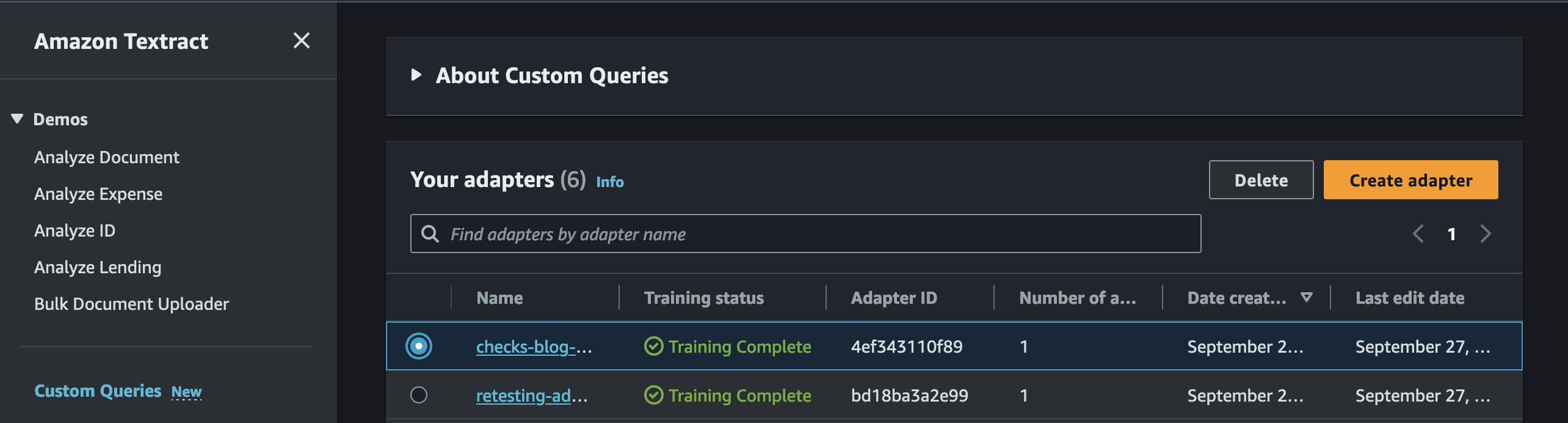
Adapterbeheer
U kunt uw adapters regelmatig verbeteren door nieuwe versies van een eerder gegenereerde adapter te maken. Als u een nieuwe versie van een adapter wilt maken, voegt u nieuwe voorbeelddocumenten toe aan een bestaande adapter, labelt u de documenten en voert u training uit. U kunt tegelijkertijd meerdere versies van een adapter onderhouden voor gebruik in uw ontwikkelingspijplijnen. Om uw adapters naadloos bij te werken, dient u geen wijzigingen aan te brengen of uw adapters te verwijderen Amazon eenvoudige opslagservice (Amazon S3) bucket waarin de bestanden worden opgeslagen die nodig zijn voor het genereren van adapters.
Beste praktijken
Wanneer u aangepaste query's op uw documenten gebruikt, raadpleegt u Best practices voor aangepaste Amazon Textract-query's voor aanvullende overwegingen en best practices.
Voordelen van aangepaste zoekopdrachten
Aangepaste query's bieden de volgende voordelen:
- Verbeterd documentbegrip – Door de mogelijkheid om gegevens met hoge nauwkeurigheid te extraheren en te normaliseren, vermindert Custom Queries de afhankelijkheid van handmatige beoordelingen en audits, en stelt u in staat betrouwbaardere automatisering te bouwen voor uw intelligente documentverwerkingsworkflows.
- Snellere time-to-value – Wanneer u nieuwe documenttypen tegenkomt waarbij u een hogere nauwkeurigheid nodig heeft, kunt u met Custom Query's binnen een paar uur op selfservice-wijze een adapter genereren. U hoeft niet te wachten op een vooraf getrainde modelupdate wanneer u nieuwe documenttypen of varianten van bestaande documenttypen tegenkomt in uw workflow. U heeft volledige controle over uw pijplijn en hoeft niet afhankelijk te zijn van Amazon Textract om uw nieuwe documenttypen te ondersteunen.
- Data Privacy – Aangepaste zoekopdrachten bewaren of gebruiken de gegevens die worden gebruikt bij het genereren van adapters niet om onze algemene, vooraf getrainde modellen die voor alle klanten beschikbaar zijn, te verbeteren. De adapter is beperkt tot het account van de klant of andere accounts die expliciet door de klant zijn aangewezen, zodat alleen dergelijke accounts toegang hebben tot de verbeteringen die zijn aangebracht met behulp van de gegevens van de klant.
- Gemak –Aangepaste query's bieden een volledig beheerde gevolgtrekkingservaring, vergelijkbaar met query's. De adaptertraining is gratis en u betaalt alleen voor gevolgtrekking. Aangepaste query's besparen u de overhead en kosten van training en het gebruik van aangepaste modellen.
Conclusie
In dit bericht hebben we de voordelen van aangepaste query's besproken, laten zien hoe aangepaste query's nauwkeurig gegevens uit controles kunnen extraheren, en best practices gedeeld voor het effectief gebruik van deze functie. Binnen slechts een paar uur kunt u met behulp van de console een adapter maken en deze in de AnalyseDocument API gebruiken voor uw gegevensextractiebehoeften. Voor meer informatie, zie Aangepaste zoekopdrachten.
Over de auteurs
 Shibin Michaëlraj is een Sr. Product Manager bij het Amazon Textract-team. Hij richt zich op het bouwen van op AI/ML gebaseerde producten voor AWS-klanten. Hij is enthousiast om klanten te helpen bij het oplossen van hun complexe zakelijke uitdagingen door gebruik te maken van AI- en ML-technologieën. In zijn vrije tijd houdt hij van hardlopen, luisteren naar podcasts en het verfijnen van zijn amateurtennisvaardigheden.
Shibin Michaëlraj is een Sr. Product Manager bij het Amazon Textract-team. Hij richt zich op het bouwen van op AI/ML gebaseerde producten voor AWS-klanten. Hij is enthousiast om klanten te helpen bij het oplossen van hun complexe zakelijke uitdagingen door gebruik te maken van AI- en ML-technologieën. In zijn vrije tijd houdt hij van hardlopen, luisteren naar podcasts en het verfijnen van zijn amateurtennisvaardigheden.
 Keith Mascarenhas is een Sr. Solutions Architect bij het Amazon Textract-serviceteam. Hij heeft een passie voor het op grote schaal oplossen van bedrijfsproblemen met behulp van machine learning, en helpt momenteel onze wereldwijde klanten bij het automatiseren van hun documentverwerking om een snellere time-to-market te bereiken met lagere operationele kosten.
Keith Mascarenhas is een Sr. Solutions Architect bij het Amazon Textract-serviceteam. Hij heeft een passie voor het op grote schaal oplossen van bedrijfsproblemen met behulp van machine learning, en helpt momenteel onze wereldwijde klanten bij het automatiseren van hun documentverwerking om een snellere time-to-market te bereiken met lagere operationele kosten.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/customize-amazon-textract-with-business-specific-documents-using-custom-queries/

