Dit artikel is gepubliceerd als onderdeel van het Data Science-blogathon.
Intro
is een van de best presterende ensembletechnieken die worden gebruikt in datawetenschap, waarbij meerdere modellen van dezelfde algoritmen worden gebruikt als bootstrapping. De aggregatiefase wordt uitgevoerd terwijl talloze outputs van verschillende modellen worden ontvangen, die dienen als de uiteindelijke output door het gemiddelde ervan te berekenen in regressieproblemen of de meest voorkomende categorie in classificatieproblemen te retourneren.
Uit zak score of Out of bag-fout is de techniek, of we kunnen zeggen dat het een validatietechniek is die voornamelijk wordt gebruikt in de bagging-algoritmen om de fout of de prestaties van de modellen in elk tijdperk te meten om uiteindelijk de totale fout van de modellen te verminderen.
Dit artikel bespreekt de out-of-bag-fout, de betekenis ervan en de use-case met zijn kernintuïtie in algoritmen voor het inpakken van zakken, met voorbeelden van elk. Hier zullen we de out-of-bag-score voor inpakken in drie delen bestuderen en bespreken: Wat, waarom en hoe?
Out of Bag Score: wat is het?
Out of Bag-score is de techniek die wordt gebruikt in de zakken algoritmen om de fout van elk bodemmodel te meten om de absolute fout van het model te verminderen, aangezien we weten dat inpakken een proces is van optelling van bootstrapping en aggregatie. In het bootstrapping-gedeelte worden de gegevensmonsters genomen en naar de bodemmodellen gevoerd, en elk bodemmodel maakt daar treinen op. Ten slotte wordt in de aggregatiestap de voorspelling gedaan door bodemmodellen en geaggregeerd om de uiteindelijke output van het model te krijgen.
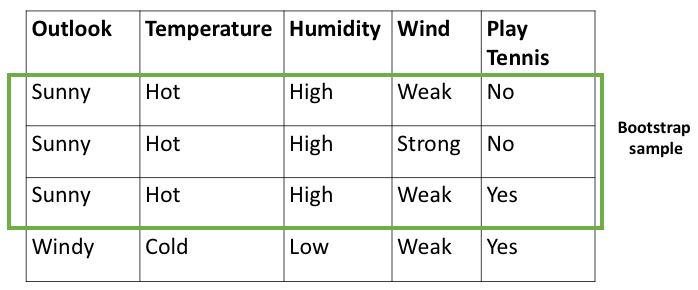
In elke stap van de bootstrapping, wordt een klein deel van de gegevenspunten van de monsters die aan de onderste leerling zijn toegevoerd, genomen, en elk onderste model doet voorspellingen nadat het op de voorbeeldgegevens is getraind. De voorspellingsfout op dat monster staat bekend als de out-of-bag-fout. De OOB-score is het aantal correct voorspelde gegevens over OOB-monsters genomen ter validatie. Het betekent dat hoe meer het foutbodemmodel doet, hoe lager de OOB-score voor het bodemmodel. Nu wordt deze OOB-score gebruikt als de fout van de specifieke bodemmodellen en afhankelijk hiervan worden de prestaties van het model verbeterd.
Out of Bag Score: waarom gebruiken?
Nu kan een vraag rijzen, waarom is de OOB-score vereist? Wat is daar voor nodig?
De OOB wordt berekend als het aantal correct voorspelde waarden door de onderste modellen op de validatiegegevensset die is genomen uit de bootstrap-voorbeeldgegevens. Deze OOB-score helpt het bagging-algoritme de bodem te begrijpen fouten van modellen op anonieme gegevens, afhankelijk van welke bodemmodellen hyperafgesteld kunnen worden.
Een beslisboom met volledige diepte kan bijvoorbeeld leiden tot overfitting, dus laten we aannemen dat we een bodemmodel hebben van de beslisboom met volledige diepte en overfit zijn op de dataset. In het geval van overfitting zal het foutenpercentage op de trainingsgegevens , maar op de testgegevens zeer hoog zijn. De validatiegegevens worden dus uit de bootstrap-steekproef gehaald en de OOB-score zal oppervlakkig zijn. Omdat het model overfitting is, zullen de fouten hoog zijn op validatiegegevens die volledig onbekend zijn en leiden tot de lage OOB-score.
Zoals we in het bovenstaande voorbeeld kunnen zien, helpt de OOB-score het model om de scenario's te begrijpen waarin het model zich niet goed gedraagt en waarmee de uiteindelijke fouten van de modellen kunnen worden verminderd.
Out of Bag Score: hoe werkt het?
Laten we proberen te begrijpen hoe de OOB-score werkt, aangezien we weten dat de OOB-score een maat is voor de correct berekende waarden op de validatiedataset. De validatiegegevens zijn de substeekproef van de bootstrapped steekproefgegevens gevoerd naar de onderste modellen. Dus hier worden de validatiegegevens voor elk bodemmodel vastgelegd en wordt elk bodemmodel getraind op de bootstrap-voorbeelden. Zodra alle bottom-modellen zijn getraind op de gevoede selectie, worden de validatiemonsters gebruikt om de OOB-fout van de bottom-modellen te berekenen.
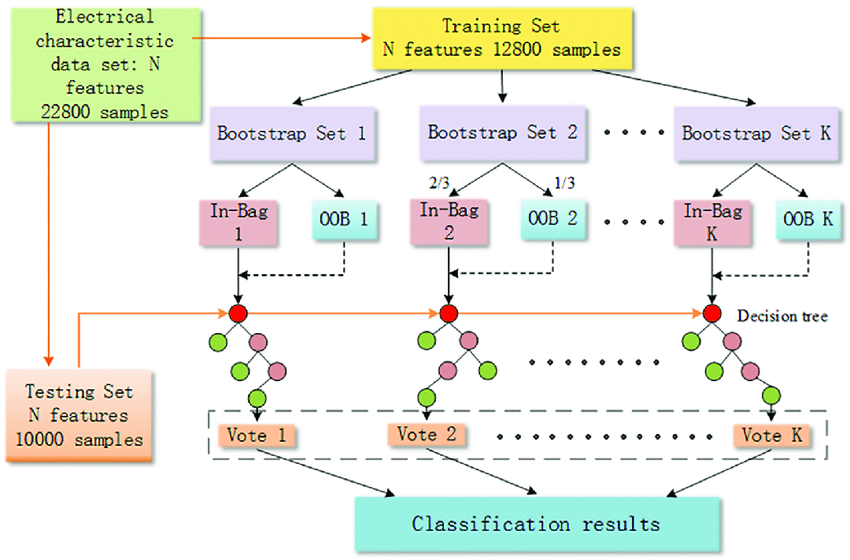
Zoals we in de bovenstaande afbeelding kunnen zien, bevat de dataset-sample in totaal 1200 rijen, waarvan de drie bootstrap-samples voor training naar het onderste model worden gevoerd. Van de bootstrap-samples, 1,2, 3 en XNUMX, wordt het kleine deel of validatiegedeelte van de gegevens genomen als OOB-samples. Deze bottom-modellen worden getraind op het andere deel van de bootstrap-voorbeelden, en eenmaal getraind, zullen de OOB-samples worden gebruikt om de bodemmodellen te voorspellen. Zodra de onderste modellen de OOB-monsters voorspellen, wordt de OOB-score berekend. Het exacte proces wordt nu gevolgd voor alle ondermodellen; vandaar, afhankelijk van de OOB-fout, zal het model dat doen zijn prestaties verbeteren.
Om het te krijgen OOB-score van het Willekeurig bosalgoritme, Gebruik onderstaande code.
van sklearn.trees importeren RandomForestClassifier rfc = RandomForestClassifier(oob_score=True) rfc.fit(X_train,y_train) print(rfc.oob_score_)
De voordelen van de OOB-score
1. Betere prestaties van het model
Omdat de OOB-score de fout van de onderste modellen aangeeft op basis van de validatiegegevensset, kan het model een idee krijgen van de fouten en de prestaties van het model verbeteren.
2. Geen gegevenslekkage
Aangezien de validatiegegevens voor OOB-samples worden genomen uit de bootstrap-samples, worden de gegevens alleen gebruikt voor voorspelling, wat betekent dat de gegevens niet worden gebruikt voor de training, wat ervoor zorgt dat de gegevens niet lekken. Het model ziet de validatiegegevens niet, wat best goed is, aangezien de OOB-score echt zou zijn als de gegevens geheim worden gehouden.
3. Betere datasets
OOB-score is een uitstekende aanpak als de dataset klein tot middelgroot is. Het presteert zo goed op een kleine dataset en retourneert een beter voorspellend model.
Het nadeel van de OOB-score
1. Hoogwaardige complexiteit
Aangezien validatiemonsters worden genomen en gebruikt voor het valideren van het model, kost het veel tijd om hetzelfde proces voor meerdere tijdperken uit te voeren; vandaar dat de tijdscomplexiteit van de OOB-score erg hoog is.
2. Ruimtecomplexiteit
Aangezien een deel van de validatiegegevens wordt verzameld uit bootstrap-voorbeelden, zullen er nu meer splitsingen van de gegevens in het model zijn, waardoor er meer ruimte nodig is om het model op te slaan en te gebruiken.
2. Slechte prestaties op grote dataset
OOB-score moet beter presteren op grote datasets vanwege ruimte- en tijdcomplexiteiten.
In dit artikel hebben we de kernintuïtie van de OOB-score besproken met drie belangrijke onderdelen: wat, waarom en hoe. Ook worden de voor- en nadelen van de OOB-score besproken, met de achterliggende redenen. Kennis van deze kernconcepten van de OOB-score zal iemand helpen de score beter te begrijpen en te gebruiken voor hun modellen.
sommige Key Takeaways uit dit artikel zijn:
1. OOB-fout is de meting van de fout van de bodemmodellen op de validatiegegevens uit de bootstrap monster
2. OOB-score helpt het model de fout en het rendement van het onderste model te begrijpen betere voorspellende modellen.
3. OOB-score presteert zo goed op kleine datasets maar [of grote.
4. OOB-score heeft hoge tijdscomplexiteit maar verzekert geen gegevenslekkage.
De in dit artikel getoonde media zijn geen eigendom van Analytics Vidhya en worden naar goeddunken van de auteur gebruikt.
Verwant
- Coinsmart. Europa's beste Bitcoin- en crypto-uitwisseling.Klik Hier
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://www.analyticsvidhya.com/blog/2022/11/out-of-bag-oob-score-for-bagging-in-data-science/

