Data-integratie is de basis van robuuste data-analyse. Het omvat de ontdekking, voorbereiding en samenstelling van gegevens uit verschillende bronnen. In het moderne datalandschap is het benaderen, integreren en transformeren van data uit diverse bronnen een essentieel proces voor datagestuurde besluitvorming. AWS lijm, een serverloze data-integratie- en extractie-, transformatie- en laadservice (ETL), heeft een revolutie in dit proces teweeggebracht, waardoor het toegankelijker en efficiënter is geworden. AWS Glue elimineert complexiteit en kosten, waardoor organisaties data-integratietaken binnen enkele minuten kunnen uitvoeren, wat de efficiëntie vergroot.
Deze blogpost verkent de nieuw aangekondigd beheerde connector voor Google BigQuery en demonstreert hoe u een moderne ETL-pijplijn kunt bouwen met AWS Glue Studio zonder code te schrijven.
Overzicht van AWS-lijm
AWS lijm is een serverloze data-integratieservice die het gemakkelijker maakt om gegevens te ontdekken, voor te bereiden en te combineren voor analyse, machine learning (ML) en applicatie-ontwikkeling. AWS Glue biedt alle mogelijkheden die nodig zijn voor data-integratie, zodat u binnen enkele minuten in plaats van maanden kunt beginnen met het analyseren van uw gegevens en deze in gebruik kunt nemen. AWS Glue biedt zowel visuele als op code gebaseerde interfaces om data-integratie eenvoudiger te maken. Gebruikers kunnen gemakkelijker gegevens vinden en openen met behulp van de AWS-lijmgegevenscatalogus. Data-ingenieurs en ETL-ontwikkelaars (extract, transform, and load) kunnen in een paar stappen visueel ETL-workflows creëren, uitvoeren en monitoren. AWS Lijm Studio. Data-analisten en datawetenschappers kunnen er gebruik van maken AWS lijm DataBrew om gegevens visueel te verrijken, op te schonen en te normaliseren zonder code te schrijven.
Maak kennis met de Google BigQuery Spark-connector
Om te voldoen aan de eisen van diverse gebruiksscenario's voor data-integratie, biedt AWS Glue nu een native spark-connector voor Google BigQuery. Klanten kunnen nu AWS Glue 4.0 voor Spark gebruiken om te lezen van en te schrijven naar tabellen in Google BigQuery. Bovendien kunt u een hele tabel lezen of een aangepaste query uitvoeren en uw gegevens schrijven met behulp van directe en indirecte schrijfmethoden. U maakt verbinding met BigQuery met behulp van de serviceaccountgegevens die veilig zijn opgeslagen in AWS-geheimenmanager.
Voordelen van de Google BigQuery Spark-connector
- Naadloze integratie: De native connector biedt een intuïtieve en gestroomlijnde interface voor gegevensintegratie, waardoor de leercurve wordt verkort.
- Kost efficiëntie: Het bouwen en onderhouden van aangepaste connectoren kan duur zijn. De native connector van AWS Glue is een kosteneffectief alternatief.
- Efficiënt: Gegevenstransformatietaken die voorheen weken of maanden in beslag namen, kunnen nu binnen enkele minuten worden uitgevoerd, waardoor de efficiëntie wordt geoptimaliseerd.
Overzicht oplossingen
In dit voorbeeld maakt u twee ETL-taken met AWS Glue met de native Google BigQuery-connector.
- Query's uitvoeren in een BigQuery-tabel en de gegevens opslaan in Eenvoudige opslagservice van Amazon (Amazon S3) in Parquet-formaat.
- Gebruik de gegevens uit de eerste taak om deze te transformeren en een samengevoegd resultaat te creëren dat in Google BigQuery kan worden opgeslagen.

Voorwaarden
De dataset die in deze oplossing wordt gebruikt, is de NCEI/WDS Wereldwijde database met significante aardbevingen, met een wereldwijde lijst van meer dan 5,700 aardbevingen van 2150 voor Christus tot heden. Kopieer deze openbare gegevens naar uw Google BigQuery-project of gebruik uw bestaande dataset.
Configureer BigQuery-verbindingen
Om verbinding te maken met Google BigQuery vanuit AWS Glue, zie BigQuery-verbindingen configureren. U moet uw Google Cloud Platform-inloggegevens aanmaken en opslaan in een Secrets Manager-geheim en dat geheim vervolgens koppelen aan een Google BigQuery AWS Glue-verbinding.
Amazon S3 instellen
Elk object in Amazon S3 wordt opgeslagen in een bucket. Voordat u gegevens in Amazon S3 kunt opslaan, moet u dit doen maak een S3-bucket om de resultaten op te slaan.
Een S3-bucket maken:
- Op de AWS Management Console voor Amazon S3, kiezen Maak een bucket.
- Voer een globaal uniek in Naam voor je emmer; Bijvoorbeeld,
awsglue-demo. - Kies Maak een bucket.
Maak een IAM-rol voor de AWS Glue ETL-taak
Wanneer u de AWS Glue ETL-taak maakt, geeft u een AWS identiteits- en toegangsbeheer (IAM) rol die voor de functie moet worden gebruikt. De rol moet toegang verlenen tot alle bronnen die door de taak worden gebruikt, inclusief Amazon S3 (voor alle bronnen, doelen, scripts, stuurprogrammabestanden en tijdelijke mappen) en Secrets Manager.
Voor instructies, zie Configureer een IAM-rol voor uw ETL-taak.
Oplossingsoverzicht
Maak een visuele ETL-taak in AWS Glue Studio om gegevens over te dragen van Google BigQuery naar Amazon S3
- Open de AWS lijm console.
- Navigeer in AWS Glue naar Visuele ETL onder de ETL-banen sectie en maak een nieuwe ETL-taak met behulp van Visual met een leeg canvas.
- Voer een Naam voor bijvoorbeeld uw AWS Glue klus,
bq-s3-dataflow. - kies Google BigQuery als de gegevensbron.
- Voer een naam voor uw Google BigQuery-bronknooppunt, bijvoorbeeld
noaa_significant_earthquakes. - Selecteer een Google BigQuery verbinding, bijvoorbeeld
bq-connection. - Voer een Ouder projecteren, bijvoorbeeld
bigquery-public-datasources. - kies Kies een enkele tafel voor de BigQuery-bron.
- Voer de tafel u wilt migreren in de vorm [dataset].[tabel], bijvoorbeeld
noaa_significant_earthquakes.earthquakes.
- Voer een naam voor uw Google BigQuery-bronknooppunt, bijvoorbeeld
- Kies vervolgens het gegevensdoel als Amazon S3.
- Voer een Naam voor het doel-Amazon S3-knooppunt, bijvoorbeeld aardbevingen.
- Selecteer de uitvoergegevens Formaat as Parket.
- Selecteer het Compressietype as pittig.
- Voor de S3 doellocatieVoer de bucket in die in de vereisten is gemaakt, bijvoorbeeld
s3://<YourBucketName>/noaa_significant_earthquakes/earthquakes/. - Je zou moeten vervangen
<YourBucketName>met de naam van uw emmer.
- Ga vervolgens naar de Details van de baan. In de IAM-rolselecteert u de IAM-rol uit de vereisten, bijvoorbeeld
AWSGlueRole.
- Kies Bespaar.
Voer de taak uit en controleer deze
- Nadat uw ETL-taak is geconfigureerd, kunt u de taak uitvoeren. AWS Glue voert het ETL-proces uit, haalt gegevens uit Google BigQuery en laadt deze naar de door u opgegeven S3-locatie.
- Volg de voortgang van de taak in de AWS Glue-console. U kunt logboeken en taakuitvoeringsgeschiedenis bekijken om ervoor te zorgen dat alles soepel verloopt.

Gegevensvalidatie
- Nadat de taak met succes is uitgevoerd, valideert u de gegevens in uw S3-bucket om er zeker van te zijn dat deze aan uw verwachtingen voldoen. U kunt de resultaten bekijken met behulp van Amazon S3 Selecteren.

Automatiseer en plan
- Stel indien nodig een taakplanning in om het ETL-proces regelmatig uit te voeren. U kunt AWS gebruiken om uw ETL-taken te automatiseren, zodat uw S3-bucket altijd up-to-date is met de nieuwste gegevens van Google BigQuery.
U heeft met succes een AWS Glue ETL-taak geconfigureerd om gegevens over te dragen van Google BigQuery naar Amazon S3. Vervolgens maakt u de ETL-taak om deze gegevens te verzamelen en over te dragen naar Google BigQuery.
Het vinden van hotspots voor aardbevingen met AWS Glue Studio Visual ETL.
- Openen AWS lijm console.
- Navigeer in AWS Glue naar Visuele ETL onder de ETL-banen sectie en maak een nieuwe ETL-taak met behulp van Visual met een leeg canvas.
- Geef een naam op voor uw AWS Glue-taak, bijvoorbeeld
s3-bq-dataflow. - Kies Amazon S3 als de gegevensbron.
- Voer een Naam voor het bron Amazon S3-knooppunt, bijvoorbeeld aardbevingen.
- kies S3 locatie de S3-brontype.
- Voer de S3-bucket in die in de vereisten is gemaakt als S3-URLBijvoorbeeld
s3://<YourBucketName>/noaa_significant_earthquakes/earthquakes/. - Je zou moeten vervangen
<YourBucketName>met de naam van uw emmer. - Selecteer het Data formaat as Parket.
- kies Schema afleiden.

- Kies vervolgens Selecteer Velden transformatie.
- kies
earthquakesas Knooppunt ouders. - Velden selecteren:
id, eq_primary, and country.
- kies
- Kies vervolgens Geaggregeerde transformatie.
- Voer een NaamBijvoorbeeld
Aggregate. - Kies
Select Fieldsas Knooppunt ouders. - Kies
eq_primary and countryde groeperen op kolommen. - Toevoegen
idde aggregaat kolom encountde aggregatie functie.
- Voer een NaamBijvoorbeeld
- Kies vervolgens HernoemVeld transformatie.
- Voer een naam in voor het Amazon S3-bronknooppunt, bijvoorbeeld
Rename eq_primary. - Kies
Aggregateas Knooppunt ouders. - Kies
eq_primaryde Huidige veldnaam en ga naar binnenearthquake_magnitudede Nieuwe veldnaam.
- Voer een naam in voor het Amazon S3-bronknooppunt, bijvoorbeeld
- Kies vervolgens HernoemVeld transformatie
- Voer een naam in voor het Amazon S3-bronknooppunt, bijvoorbeeld
Rename count(id). - Kies
Rename eq_primaryas Knooppunt ouders. - Kies
count(id)de Huidige veldnaam en ga naar binnennumber_of_earthquakesde Nieuwe veldnaam.
- Voer een naam in voor het Amazon S3-bronknooppunt, bijvoorbeeld
- Kies vervolgens het gegevensdoel als Google BigQuery.
- Geef een naam op voor uw Google BigQuery-bronknooppunt, bijvoorbeeld
most_powerful_earthquakes. - Selecteer een Google BigQuery-verbindingBijvoorbeeld
bq-connection. - kies Ouder projectBijvoorbeeld
bigquery-public-datasources. - Voer de naam van de in tafel die u wilt maken in de vorm [dataset].[tabel], bijvoorbeeld
noaa_significant_earthquakes.most_powerful_earthquakes. - Kies Direct de Schrijf methode.

- Geef een naam op voor uw Google BigQuery-bronknooppunt, bijvoorbeeld
- Ga vervolgens naar de Details van de baan tab en in de IAM-rolselecteert u de IAM-rol uit de vereisten, bijvoorbeeld
AWSGlueRole.
- Kies Bespaar.
Voer de taak uit en controleer deze
- Nadat uw ETL-taak is geconfigureerd, kunt u de taak uitvoeren. AWS Glue voert het ETL-proces uit, extraheert gegevens uit Google BigQuery en laadt deze naar de door u opgegeven S3-locatie.
- Volg de voortgang van de taak in de AWS Glue-console. U kunt logboeken en taakuitvoeringsgeschiedenis bekijken om ervoor te zorgen dat alles soepel verloopt.
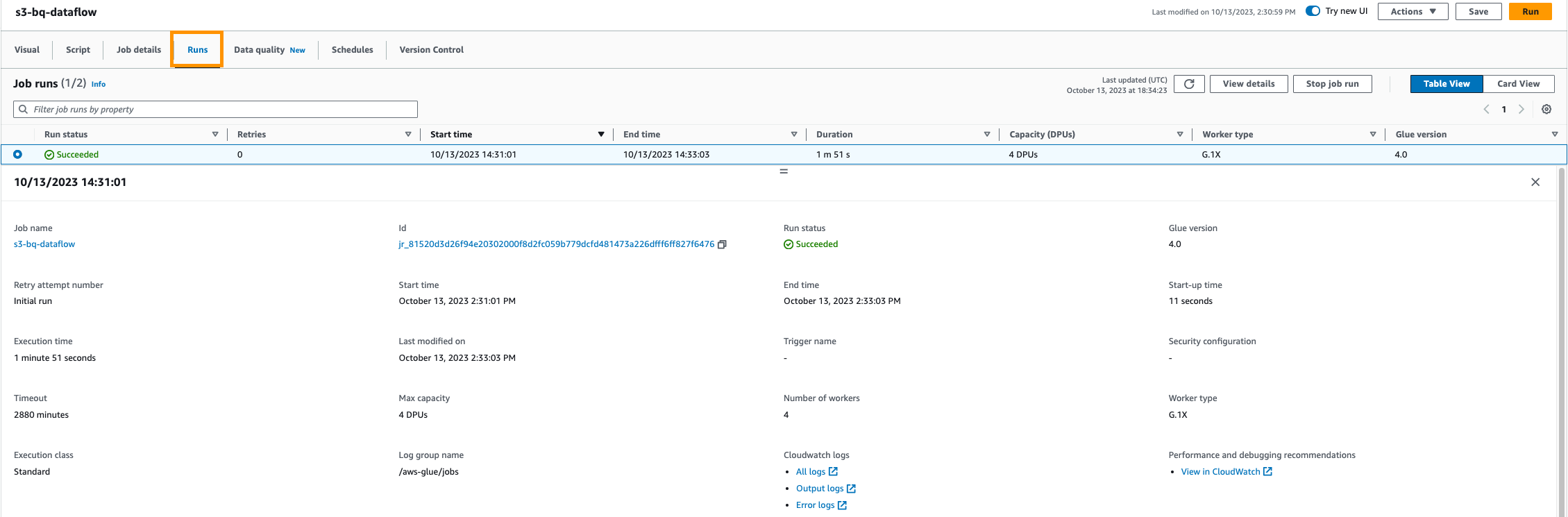
Gegevensvalidatie
- Nadat de taak is uitgevoerd, valideert u de gegevens in uw Google BigQuery-dataset. Deze ETL-taak retourneert een lijst met landen waar de krachtigste aardbevingen hebben plaatsgevonden. Het verschaft deze door het aantal aardbevingen voor een bepaalde omvang per land te tellen.

Automatiseer en plan
- U kunt taakplanning instellen om het ETL-proces regelmatig uit te voeren. Met AWS Glue kunt u uw ETL-taken automatiseren, zodat uw S3-bucket altijd up-to-date is met de nieuwste gegevens van Google BigQuery.
Dat is het! U heeft met succes een AWS Glue ETL-taak opgezet om gegevens van Amazon S3 naar Google BigQuery over te dragen. U kunt deze integratie gebruiken om het proces van gegevensextractie, transformatie en laden tussen deze twee platforms te automatiseren, waardoor uw gegevens direct beschikbaar zijn voor analyse en andere toepassingen.
Opruimen
Om te voorkomen dat er kosten in rekening worden gebracht, ruimt u de bronnen die in deze blogpost worden gebruikt op uit uw AWS-account door de volgende stappen te voltooien:
- Kies op de AWS Glue-console: Visuele ETL in het navigatievenster.
- Selecteer de taak in de lijst met taken
bq-s3-data-flowen verwijder het. - Selecteer de taak in de lijst met taken
s3-bq-data-flowen verwijder het. - Kies op de AWS Glue-console: aansluitingen in het navigatievenster onder Gegevenscatalogus.
- Kies de BiqQuery-verbinding die je hebt gemaakt en verwijderd.
- Kies op de Secrets Manager-console het geheim dat u hebt gemaakt en verwijder het.
- Kies op de IAM-console rollen in het navigatievenster, selecteer vervolgens de rol die u voor de AWS Glue ETL-taak hebt gemaakt en verwijder deze.
- Zoek op de Amazon S3-console naar de S3-bucket die u hebt gemaakt en kies Leeg om de objecten te verwijderen en verwijder vervolgens de bucket.
- Ruim bronnen in uw Google-account op door het project te verwijderen dat de Google BigQuery-bronnen bevat. Volg de documentatie naar ruim de Google-bronnen op.
Conclusie
De integratie van AWS Glue met Google BigQuery vereenvoudigt de analysepijplijn, verkort de time-to-insight en vergemakkelijkt datagestuurde besluitvorming. Het stelt organisaties in staat data-integratie en -analyse te stroomlijnen. Het serverloze karakter van AWS Glue betekent dat er geen infrastructuurbeheer nodig is en dat u alleen betaalt voor de bronnen die worden verbruikt terwijl uw taken worden uitgevoerd. Omdat organisaties steeds meer afhankelijk zijn van data voor hun besluitvorming, biedt deze native spark-connector een efficiënte, kosteneffectieve en flexibele oplossing om snel te voldoen aan de behoeften op het gebied van data-analyse.
Als u wilt zien hoe u kunt lezen van en schrijven naar tabellen in Google BigQuery in AWS Glue, bekijk dan stap voor stap video tutorial. In deze zelfstudie doorlopen we het hele proces, van het opzetten van de verbinding tot het uitvoeren van de gegevensoverdrachtstroom. Ga voor meer informatie over AWS Glue naar AWS lijm.
Bijlage
Als u dit voorbeeld wilt implementeren en code wilt gebruiken in plaats van de AWS Glue-console, gebruikt u de volgende codefragmenten.
Gegevens uit Google BigQuery lezen en gegevens naar Amazon S3 schrijven
Gegevens uit Amazon S3 lezen en samenvoegen en naar Google BigQuery schrijven
Over de auteurs
 Kartikay Khator is een Solutions Architect in Global Life Sciences bij Amazon Web Services (AWS). Hij heeft een passie voor het bouwen van innovatieve en schaalbare oplossingen om aan de behoeften van klanten te voldoen, met de nadruk op AWS Analytics-services. Naast de technische wereld is hij een fervent hardloper en houdt hij van wandelen.
Kartikay Khator is een Solutions Architect in Global Life Sciences bij Amazon Web Services (AWS). Hij heeft een passie voor het bouwen van innovatieve en schaalbare oplossingen om aan de behoeften van klanten te voldoen, met de nadruk op AWS Analytics-services. Naast de technische wereld is hij een fervent hardloper en houdt hij van wandelen.
 Kamen Sharlandjev is een Sr. Big Data en ETL Solutions Architect en Amazon AppFlow-expert. Hij heeft een missie om het leven gemakkelijker te maken voor klanten die worden geconfronteerd met complexe uitdagingen op het gebied van data-integratie. Zijn geheime wapen? Volledig beheerde, low-code AWS-services die de klus kunnen klaren met minimale inspanning en zonder codering.
Kamen Sharlandjev is een Sr. Big Data en ETL Solutions Architect en Amazon AppFlow-expert. Hij heeft een missie om het leven gemakkelijker te maken voor klanten die worden geconfronteerd met complexe uitdagingen op het gebied van data-integratie. Zijn geheime wapen? Volledig beheerde, low-code AWS-services die de klus kunnen klaren met minimale inspanning en zonder codering.
 Anshul Sharma is een softwareontwikkelingsingenieur in het AWS Glue-team. Hij geeft leiding aan het connectiviteitscharter dat de klant van Glue een eigen manier biedt om elke gegevensbron (datawarehouse, datalakes, NoSQL enz.) te verbinden met Glue ETL Jobs. Naast de technische wereld is hij een cricket- en voetballiefhebber.
Anshul Sharma is een softwareontwikkelingsingenieur in het AWS Glue-team. Hij geeft leiding aan het connectiviteitscharter dat de klant van Glue een eigen manier biedt om elke gegevensbron (datawarehouse, datalakes, NoSQL enz.) te verbinden met Glue ETL Jobs. Naast de technische wereld is hij een cricket- en voetballiefhebber.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/unlock-scalable-analytics-with-aws-glue-and-google-bigquery/

