Amazon Relational Database Service (Amazon RDS) voor MySQL zero-ETL-integratie met Amazon roodverschuiving was aangekondigd in preview op AWS re:Invent 2023 voor Amazon RDS voor MySQL versie 8.0.28 of hoger. In dit bericht bieden we stapsgewijze richtlijnen over hoe u met deze functie aan de slag kunt gaan met vrijwel realtime operationele analyses. Dit bericht is een voortzetting van de zero-ETL-serie waarmee begon Handleiding om aan de slag te gaan voor bijna realtime operationele analyses met behulp van Amazon Aurora zero-ETL-integratie met Amazon Redshift.
Uitdagingen
Klanten uit verschillende sectoren willen tegenwoordig data gebruiken om hun concurrentievoordeel te behalen en de omzet en klantbetrokkenheid te vergroten door vrijwel realtime analytische gebruiksscenario's te implementeren, zoals personalisatiestrategieën, fraudedetectie, voorraadmonitoring en nog veel meer. Er zijn twee brede benaderingen voor het analyseren van operationele gegevens voor deze gebruiksscenario's:
- Analyseer de gegevens in de operationele database (zoals leesreplica's, federatieve query's en analyseversnellers)
- Verplaats de gegevens naar een gegevensarchief dat is geoptimaliseerd voor het uitvoeren van gebruiksspecifieke query's, zoals een datawarehouse
De zero-ETL-integratie is gericht op het vereenvoudigen van de laatste benadering.
Het extractie-, transformatie- en laadproces (ETL) is een gebruikelijk patroon voor het verplaatsen van gegevens van een operationele database naar een analytisch datawarehouse. ELT is waar de geëxtraheerde gegevens eerst in het doel worden geladen en vervolgens worden getransformeerd. ETL- en ELT-pijpleidingen kunnen duur zijn om te bouwen en complex om te beheren. Met meerdere contactpunten kunnen periodieke fouten in ETL- en ELT-pijplijnen tot grote vertragingen leiden, waardoor datawarehouse-applicaties met verouderde of ontbrekende gegevens achterblijven, wat verder leidt tot gemiste zakelijke kansen.
Als alternatief kunnen oplossingen die gegevens ter plaatse analyseren prima werken voor het versnellen van zoekopdrachten op één database, maar dergelijke oplossingen zijn niet in staat gegevens uit meerdere operationele databases samen te voegen voor klanten die uniforme analyses moeten uitvoeren.
Nul-ETL
In tegenstelling tot de traditionele systemen waarbij gegevens in één database worden opgeslagen en de gebruiker een afweging moet maken tussen uniforme analyse en prestaties, kunnen data-ingenieurs nu gegevens uit meerdere RDS voor MySQL-databases repliceren naar één enkel Redshift-datawarehouse om holistische inzichten te verkrijgen over de hele wereld. veel applicaties of partities. Updates in transactionele databases worden automatisch en continu doorgegeven aan Amazon Redshift, zodat data-ingenieurs vrijwel in realtime over de meest recente informatie beschikken. Er hoeft geen infrastructuur te worden beheerd en de integratie kan automatisch op- en afschalen op basis van het datavolume.
Bij AWS hebben we gestage vooruitgang geboekt bij het brengen van onze nul-ETL visie tot leven. De volgende bronnen worden momenteel ondersteund voor nul-ETL-integraties:
Wanneer u een nul-ETL-integratie voor Amazon Redshift maakt, blijft u betalen voor de onderliggende brondatabase en het doelgebruik van de Redshift-database. Verwijzen naar Zero-ETL-integratiekosten (preview) voor meer details.
Met zero-ETL-integratie met Amazon Redshift repliceert de integratie gegevens uit de brondatabase naar het doeldatawarehouse. De gegevens zijn binnen enkele seconden beschikbaar in Amazon Redshift, waardoor u de analysefuncties van Amazon Redshift en mogelijkheden zoals het delen van gegevens, autonome werklastoptimalisatie, schaalvergroting van gelijktijdigheid, machinaal leren en nog veel meer kunt gebruiken. U kunt doorgaan met uw transactieverwerking op Amazon RDS of Amazon Aurora terwijl je tegelijkertijd Amazon Redshift gebruikt voor analytische workloads zoals rapportage en dashboards.
Het volgende diagram illustreert deze architectuur.
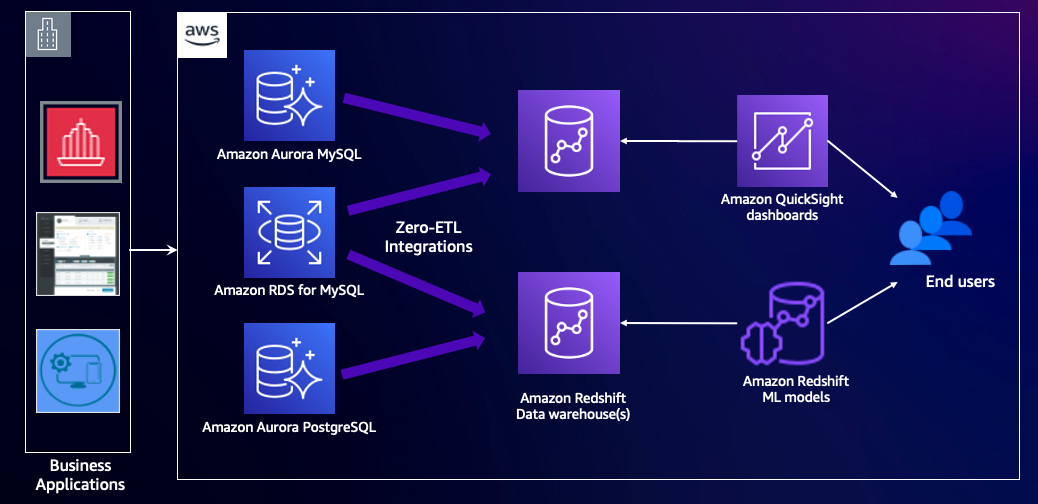
Overzicht oplossingen
Laat ons nadenken TICKIT, een fictieve website waar gebruikers online kaartjes kopen en verkopen voor sportevenementen, shows en concerten. De transactiegegevens van deze website worden geladen in een Amazon RDS voor MySQL 8.0.28 (of hogere versie) database. De bedrijfsanalisten van het bedrijf willen statistieken genereren om de ticketbewegingen in de loop van de tijd, de succespercentages voor verkopers en de best verkochte evenementen, locaties en seizoenen te identificeren. Ze willen deze statistieken bijna in realtime verkrijgen met behulp van een nul-ETL-integratie.
De integratie is opgezet tussen Amazon RDS voor MySQL (bron) en Amazon Redshift (bestemming). De transactiegegevens van de bron worden vrijwel in realtime vernieuwd op de bestemming, die analytische vragen verwerkt.
U kunt de serverloze optie of een gecodeerd RA3-cluster voor Amazon Redshift gebruiken. Voor dit bericht gebruiken we een ingerichte RDS-database en een door Redshift ingericht datawarehouse.
Het volgende diagram illustreert de architectuur op hoog niveau.
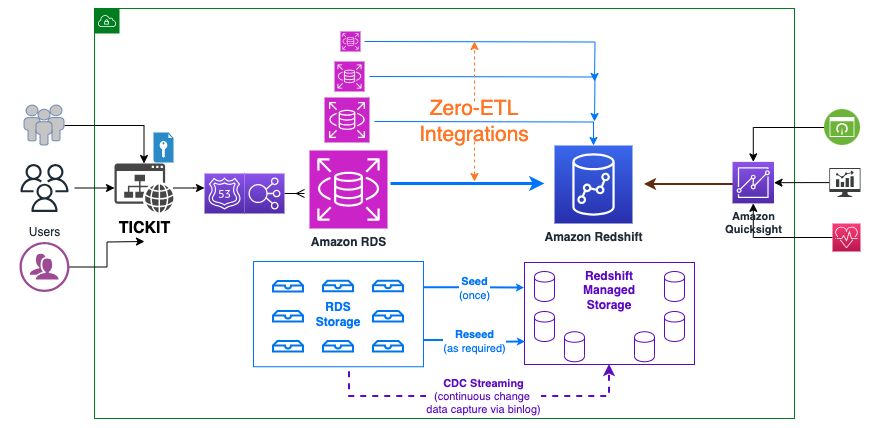
Hieronder volgen de stappen die nodig zijn om zero-ETL-integratie in te stellen. Deze stappen kunnen automatisch worden uitgevoerd door de zero-ETL-wizard, maar u moet opnieuw opstarten als de wizard de instelling voor Amazon RDS of Amazon Redshift wijzigt. U kunt deze stappen handmatig uitvoeren, als dit nog niet is geconfigureerd, en de herstart op uw gemak uitvoeren. Voor de volledige handleidingen om aan de slag te gaan, raadpleegt u Werken met Amazon RDS zero-ETL-integraties met Amazon Redshift (preview) en Werken met zero-ETL-integraties.
- Configureer de RDS voor MySQL-bron met een aangepaste DB-parametergroep.
- Configureer het Redshift-cluster om hoofdlettergevoelige ID's in te schakelen.
- Configureer de vereiste machtigingen.
- Maak de nul-ETL-integratie.
- Maak een database van de integratie in Amazon Redshift.
Configureer de RDS voor MySQL-bron met een aangepaste DB-parametergroep
Voer de volgende stappen uit om een RDS voor MySQL-database te maken:
- Maak op de Amazon RDS-console een DB-parametergroep met de naam
zero-etl-custom-pg.
Zero-ETL-integratie werkt met behulp van binaire logs (binlogs) gegenereerd door de MySQL-database. Om binlogs op Amazon RDS voor MySQL in te schakelen, moet een specifieke set parameters zijn ingeschakeld.
- Stel de volgende binlog-clusterparameterinstellingen in:
binlog_format = ROWbinlog_row_image = FULLbinlog_checksum = NONE
Zorg er bovendien voor dat de binlog_row_value_options parameter is niet ingesteld PARTIAL_JSON. Standaard is deze parameter niet ingesteld.
- Kies databases in het navigatievenster en kies vervolgens Maak een database.
- Voor Engine versie, kiezen MySQL 8.0.28 (of hoger).

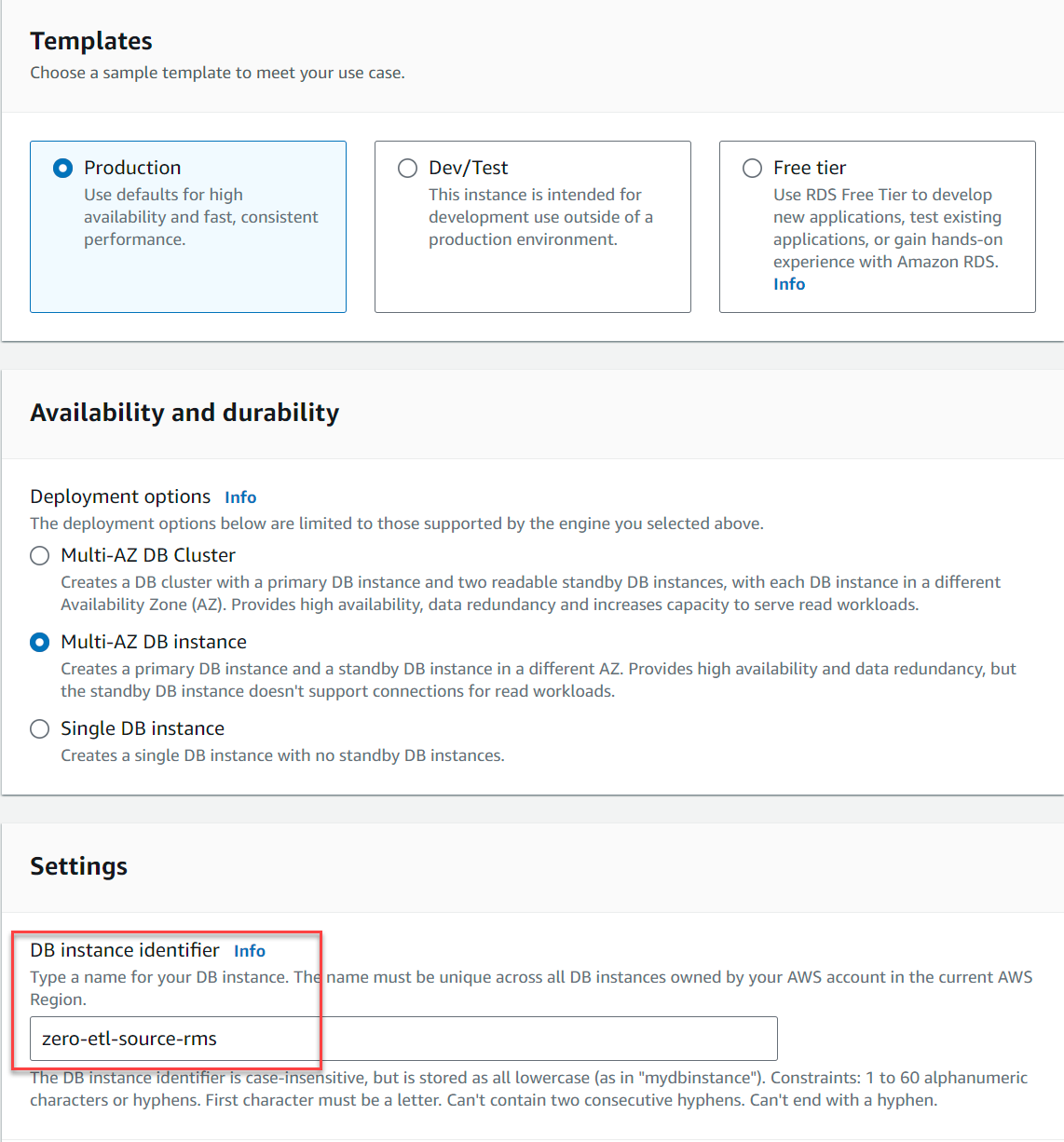
- Voor Sjablonenselecteer Productie.
- Voor Beschikbaarheid en duurzaamheid, selecteer een van beide Multi-AZ DB-instantie or Eén DB-exemplaar (Multi-AZ DB-clusters worden op het moment van schrijven niet ondersteund).
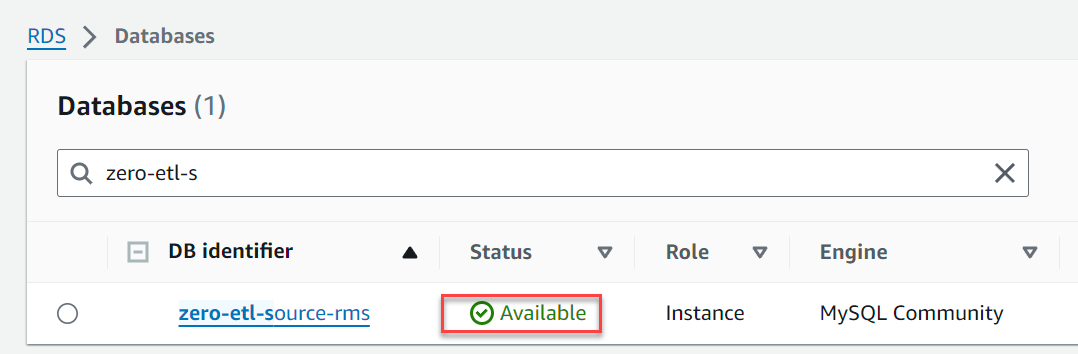
- Voor DB-instantie-ID, ga naar binnen
zero-etl-source-rms.
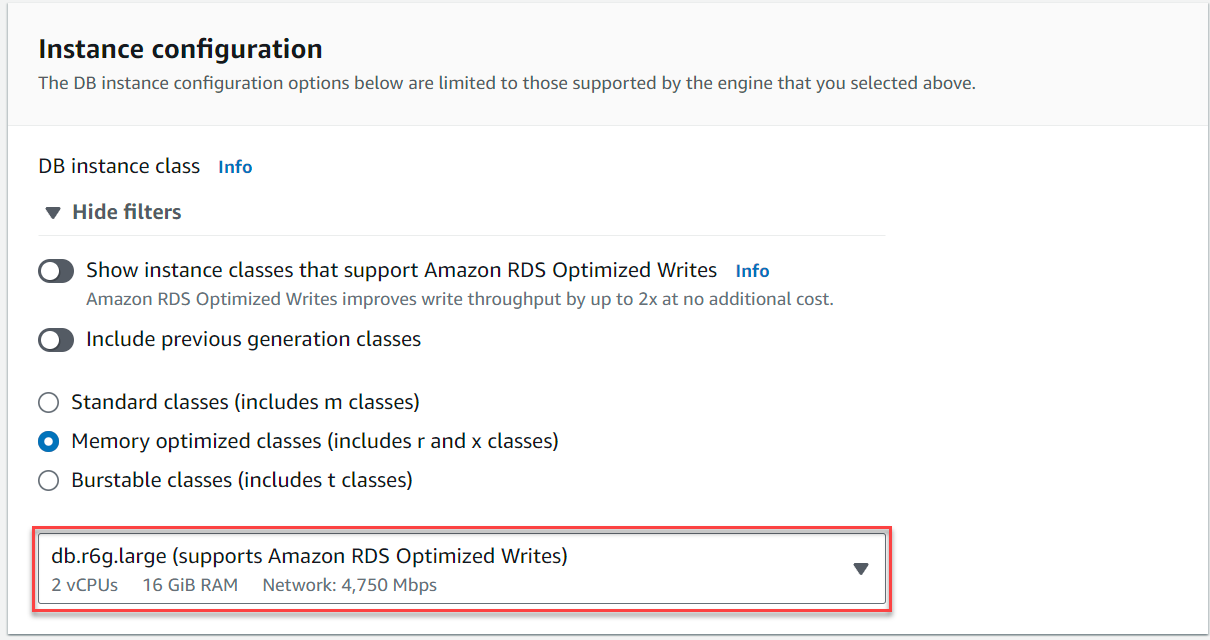
- Onder Instantie configuratieselecteer Geheugen geoptimaliseerde klassen en kies het exemplaar
db.r6g.large, wat voldoende zou moeten zijn voor TICKIT-gebruiksscenario.
- Onder Aanvullende configuratievoor DB-clusterparametergroep, kies de parametergroep die u eerder hebt gemaakt (
zero-etl-custom-pg).
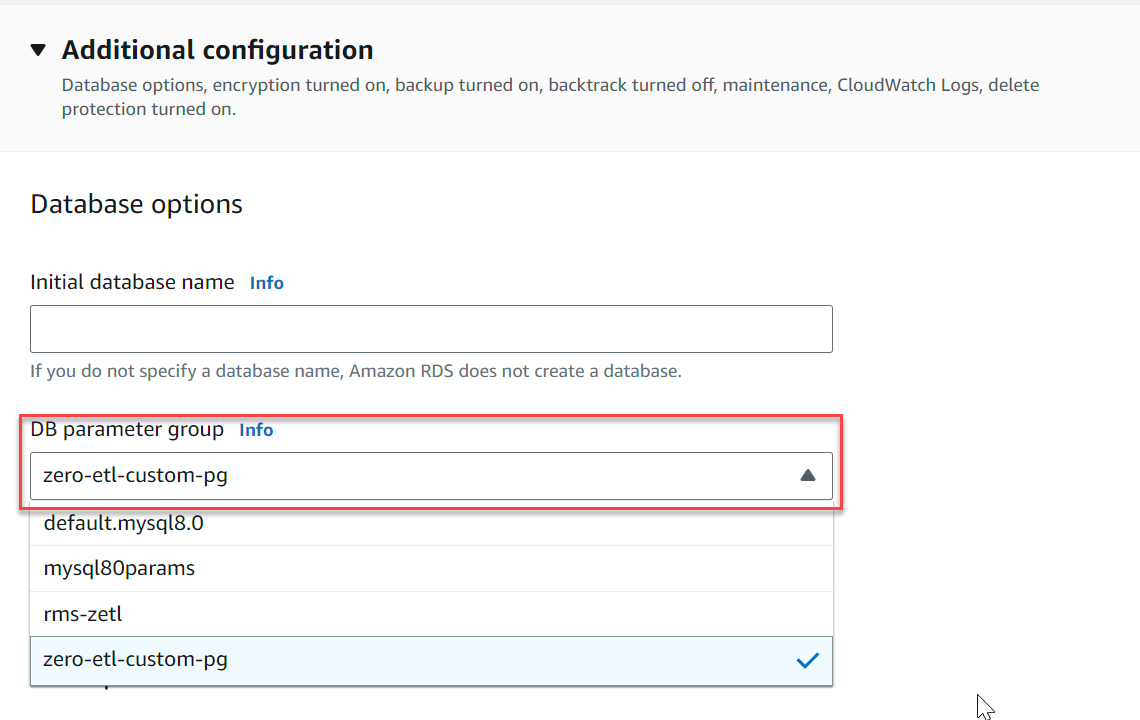
- Kies Maak een database.
Binnen een paar minuten zou het een RDS voor MySQL-database moeten opstarten als bron voor zero-ETL-integratie.
Configureer de Redshift-bestemming
Nadat u uw bron-DB-cluster hebt gemaakt, moet u een doeldatawarehouse maken en configureren in Amazon Redshift. Het datawarehouse moet aan de volgende eisen voldoen:
- Een RA3-knooppunttype gebruiken (
ra3.16xlarge,ra3.4xlargeofra3.xlplus) Of Amazon Redshift Serverloos - Versleuteld (bij gebruik van een ingericht cluster)
Maak voor ons gebruiksscenario een Redshift-cluster door de volgende stappen te voltooien:
- Kies op de Amazon Redshift-console Configuraties en kies dan Beheer van de werklast.
- Kies in het parametergroepgedeelte creëren.
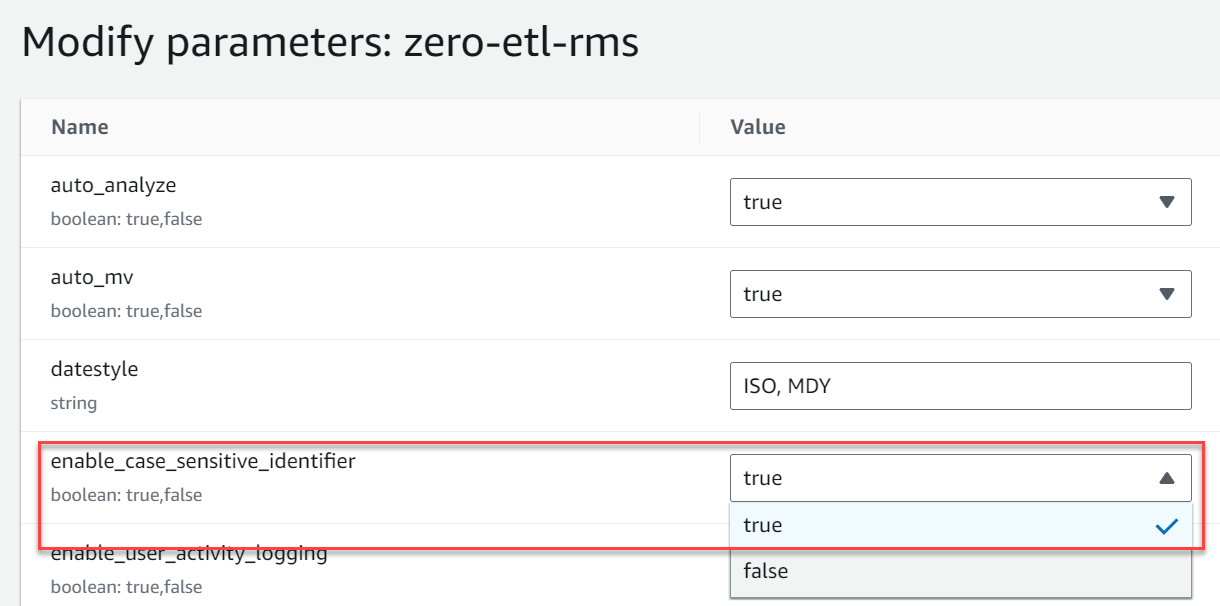
- Maak een nieuwe parametergroep met de naam
zero-etl-rms. - Kies Bewerk parameters en verander de waarde van
enable_case_sensitive_identifiernaarTrue. - Kies Bespaar.
U kunt ook gebruik maken van de AWS-opdrachtregelinterface (AWS CLI)-opdracht update-werkgroep voor Redshift serverloos:
- Kies Dashboard voor ingerichte clusters.
Bovenaan uw consolevenster ziet u een Probeer nieuwe Amazon Redshift-functies in preview banner.
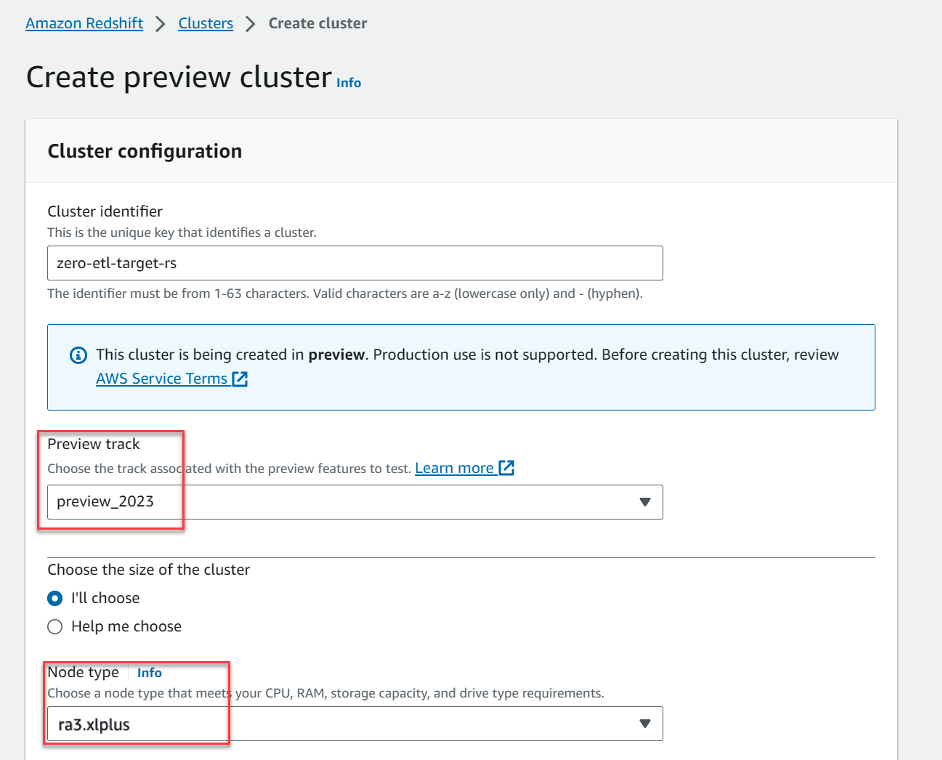
- Kies Maak een voorbeeldcluster.

- Voor Voorbeeld van het nummer, koos
preview_2023. - Voor Knooppunttype, kies een van de ondersteunde knooppunttypen (voor dit bericht gebruiken we
ra3.xlplus).
- Onder Aanvullende configuraties, uitbreiden Databaseconfiguraties.
- Voor Parametergroepen, kiezen
zero-etl-rms. - Voor Encryptieselecteer Gebruik de AWS Key Management Service.
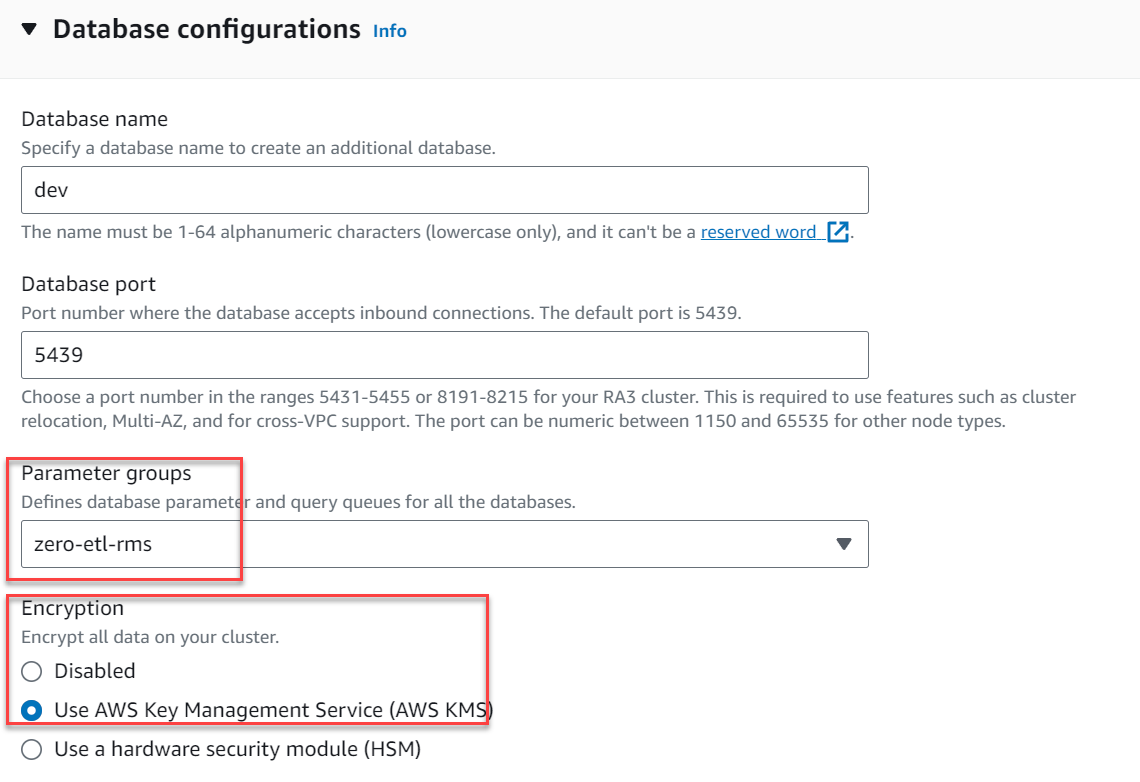
- Kies Cluster maken.
Het cluster zou moeten worden Beschikbaar in een paar minuten.

- Navigeer naar de naamruimte
zero-etl-target-rs-nsEn kies de Middelenbeleid Tab. - Kies Gemachtigde opdrachtgevers toevoegen.
- Voer de Amazon Resource Name (ARN) in van de AWS-gebruiker of -rol, of de AWS-account-ID (IAM-principals) die integraties mogen maken.
Een account-ID wordt opgeslagen als een ARN met rootgebruiker.
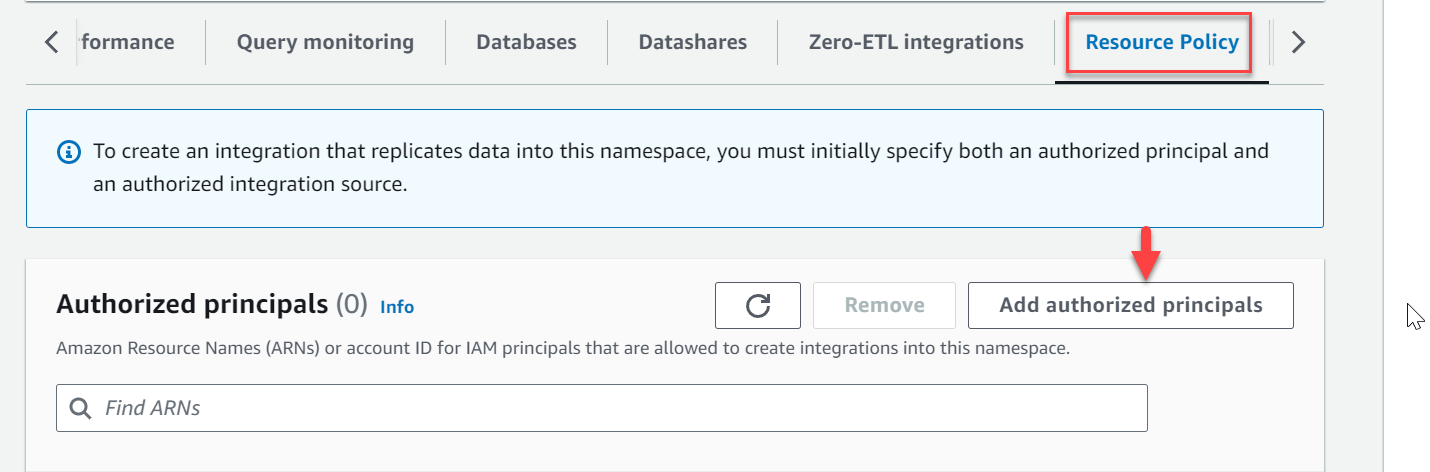
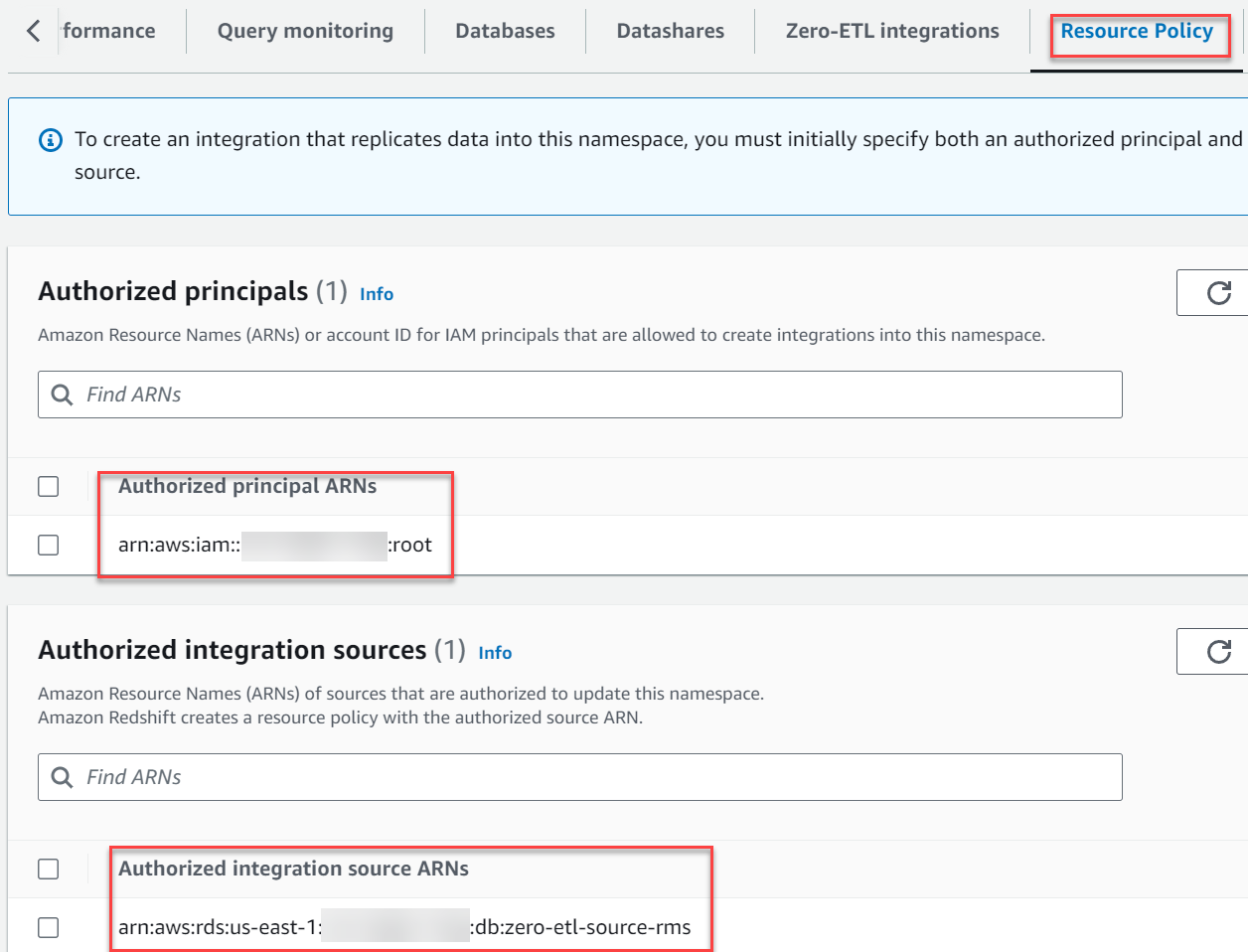
- In het Geautoriseerde integratiebronnen sectie, kies Voeg een geautoriseerde integratiebron toe om de ARN toe te voegen van de RDS voor MySQL DB-instantie die de gegevensbron is voor de nul-ETL-integratie.
Je kunt deze waarde vinden door naar de Amazon RDS-console te gaan en naar de Configuratie tabblad van de zero-etl-source-rms DB-instantie.

Uw resourcebeleid zou op de volgende schermafbeelding moeten lijken.
Configureer vereiste machtigingen
Om een zero-ETL-integratie te creëren, moet uw gebruiker of rol een gekoppeld op identiteit gebaseerd beleid met de juiste AWS Identiteits- en toegangsbeheer (IAM)-machtigingen. Een AWS-accounteigenaar kan dat wel configureer de vereiste machtigingen voor gebruikers of rollen die zero-ETL-integraties kunnen creëren. Met het voorbeeldbeleid kan de gekoppelde principal de volgende acties uitvoeren:
- Maak nul-ETL-integraties voor de bron-RDS voor MySQL DB-instantie.
- Bekijk en verwijder alle zero-ETL-integraties.
- Creëer inkomende integraties in het doeldatawarehouse. Deze toestemming is niet vereist als hetzelfde account eigenaar is van het Redshift-datawarehouse en dit account een geautoriseerde opdrachtgever is voor dat datawarehouse. Houd er ook rekening mee dat Amazon Redshift een ander ARN-formaat heeft voor ingerichte en serverloze clusters:
- Voorzien -
arn:aws:redshift:{region}:{account-id}:namespace:namespace-uuid - Serverless -
arn:aws:redshift-serverless:{region}:{account-id}:namespace/namespace-uuid
- Voorzien -
Voer de volgende stappen uit om de machtigingen te configureren:
- Kies op de IAM-console Policies in het navigatievenster.
- Kies Maak beleid.
- Maak een nieuw beleid met de naam
rds-integrationsmet behulp van de volgende JSON (replaceregionenaccount-idmet uw werkelijke waarden):
{
"Version": "2012-10-17",
"Statement": [{
"Effect": "Allow",
"Action": [
"rds:CreateIntegration"
],
"Resource": [
"arn:aws:rds:{region}:{account-id}:db:source-instancename",
"arn:aws:rds:{region}:{account-id}:integration:*"
]
},
{
"Effect": "Allow",
"Action": [
"rds:DescribeIntegration"
],
"Resource": ["*"]
},
{
"Effect": "Allow",
"Action": [
"rds:DeleteIntegration"
],
"Resource": [
"arn:aws:rds:{region}:{account-id}:integration:*"
]
},
{
"Effect": "Allow",
"Action": [
"redshift:CreateInboundIntegration"
],
"Resource": [
"arn:aws:redshift:{region}:{account-id}:cluster:namespace-uuid"
]
}]
}
- Koppel het beleid dat u hebt gemaakt aan uw IAM-gebruikers- of rolmachtigingen.
Maak de nul-ETL-integratie
Voer de volgende stappen uit om de zero-ETL-integratie te maken:
- Kies op de Amazon RDS-console Zero-ETL-integraties in het navigatievenster.
- Kies Creëer zero-ETL-integratie.

- Voor Integratie-ID, voer bijvoorbeeld een naam in
zero-etl-demo.
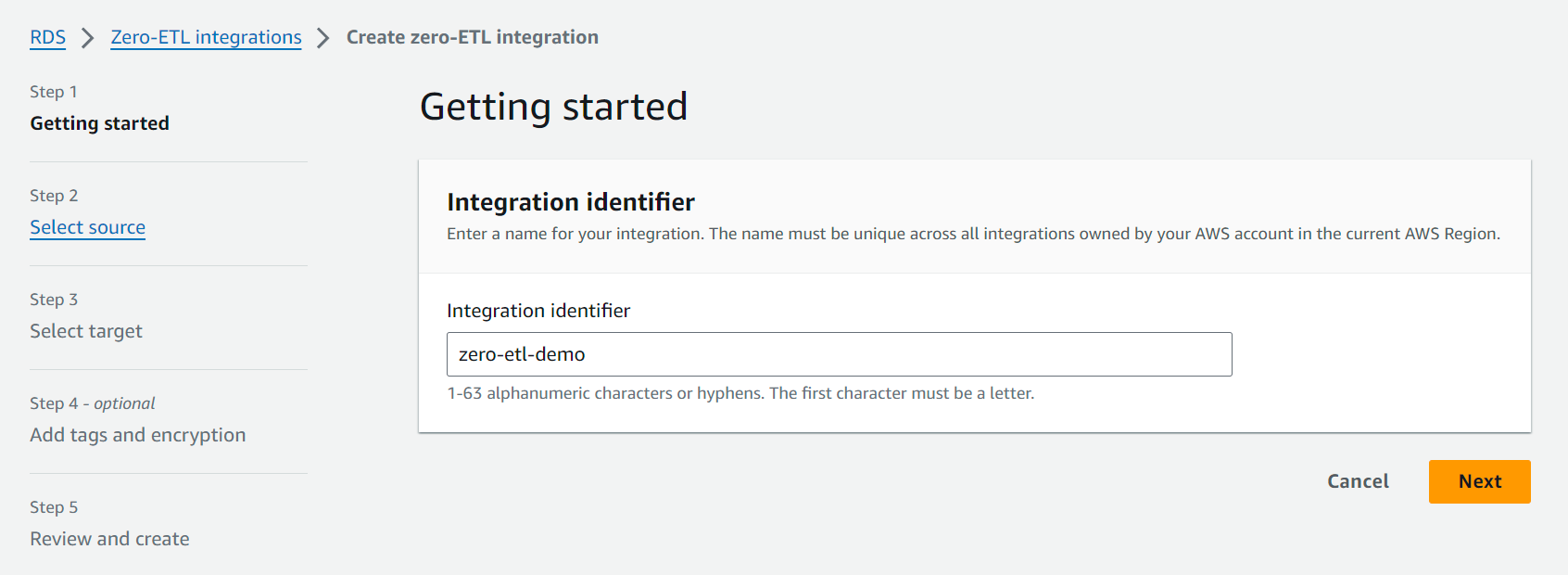
- Voor Brondatabase, kiezen Blader door RDS-databases en kies het broncluster
zero-etl-source-rms. - Kies Volgende.

- Onder doelwitvoor Amazon Redshift-datawarehouse, kiezen Blader door Redshift-datawarehouses en kies het Redshift-datawarehouse (
zero-etl-target-rs). - Kies Volgende.
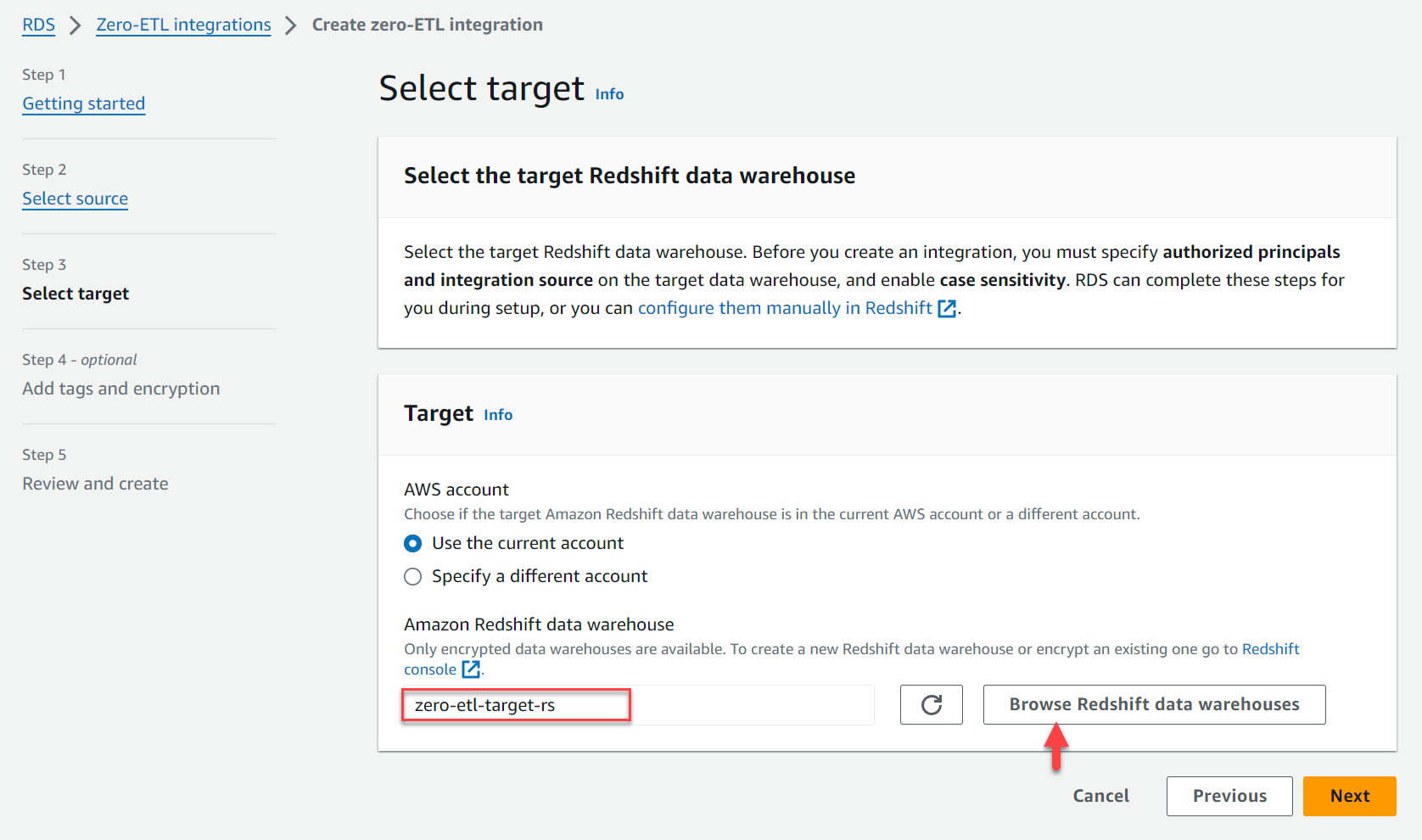
- Voeg tags en encryptie toe, indien van toepassing.
- Kies Volgende.
- Controleer de integratienaam, bron, doel en andere instellingen.
- Kies Creëer zero-ETL-integratie.
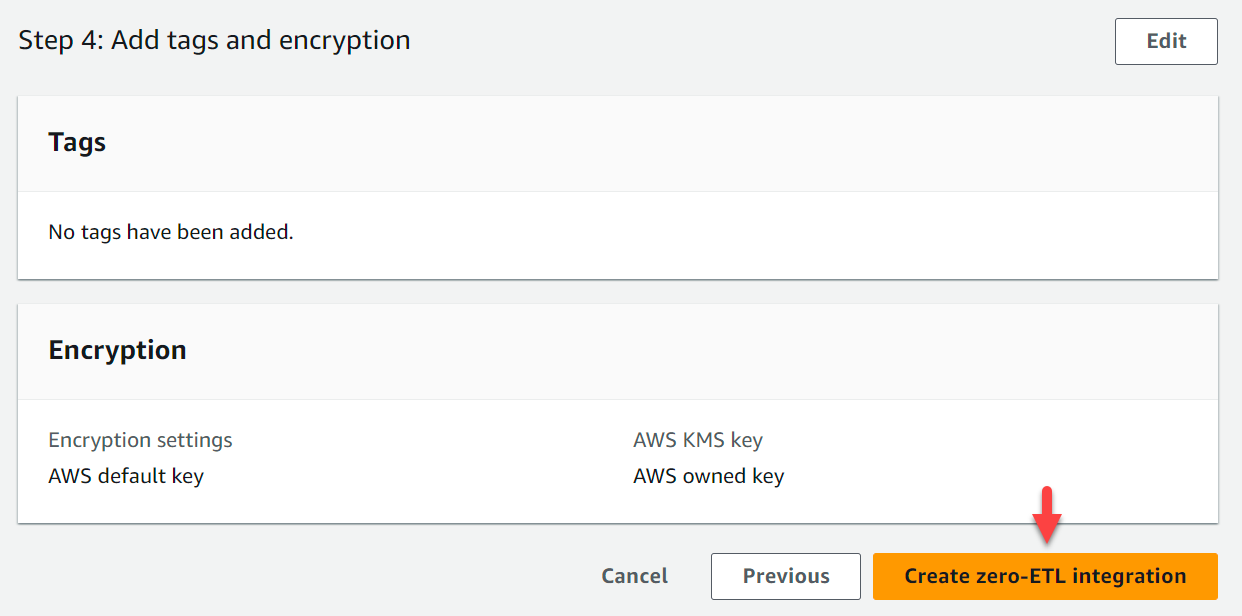
U kunt de integratie kiezen om de details te bekijken en de voortgang ervan te volgen. Het duurde ongeveer 30 minuten voordat de status veranderde Wij creëren naar Actief.

De tijd varieert afhankelijk van de grootte van uw gegevensset in de bron.
Maak een database van de integratie in Amazon Redshift
Om uw database te creëren vanuit de zero-ETL-integratie, voert u de volgende stappen uit:
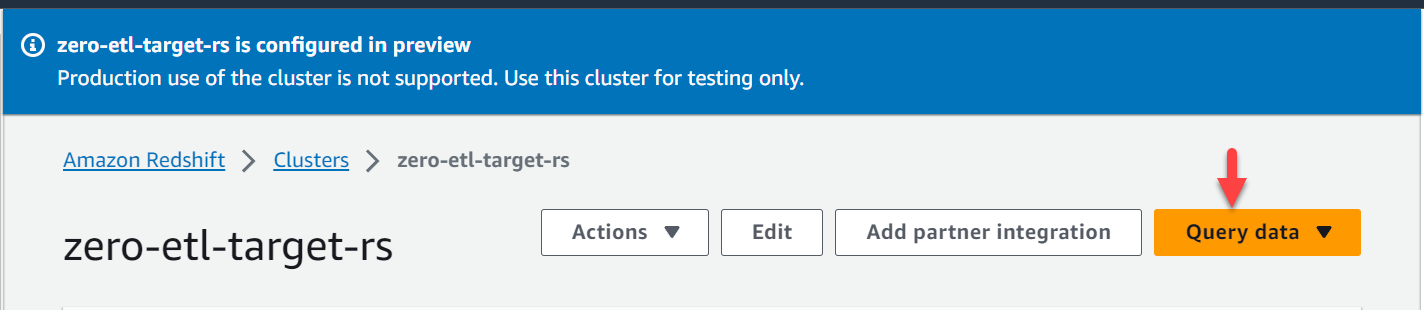
- Kies op de Amazon Redshift-console Clusters in het navigatievenster.
- Open de
zero-etl-target-rsTROS. - Kies Gegevens opvragen om de query-editor v2 te openen.
- Maak verbinding met het Redshift-datawarehouse door te kiezen Bespaar.
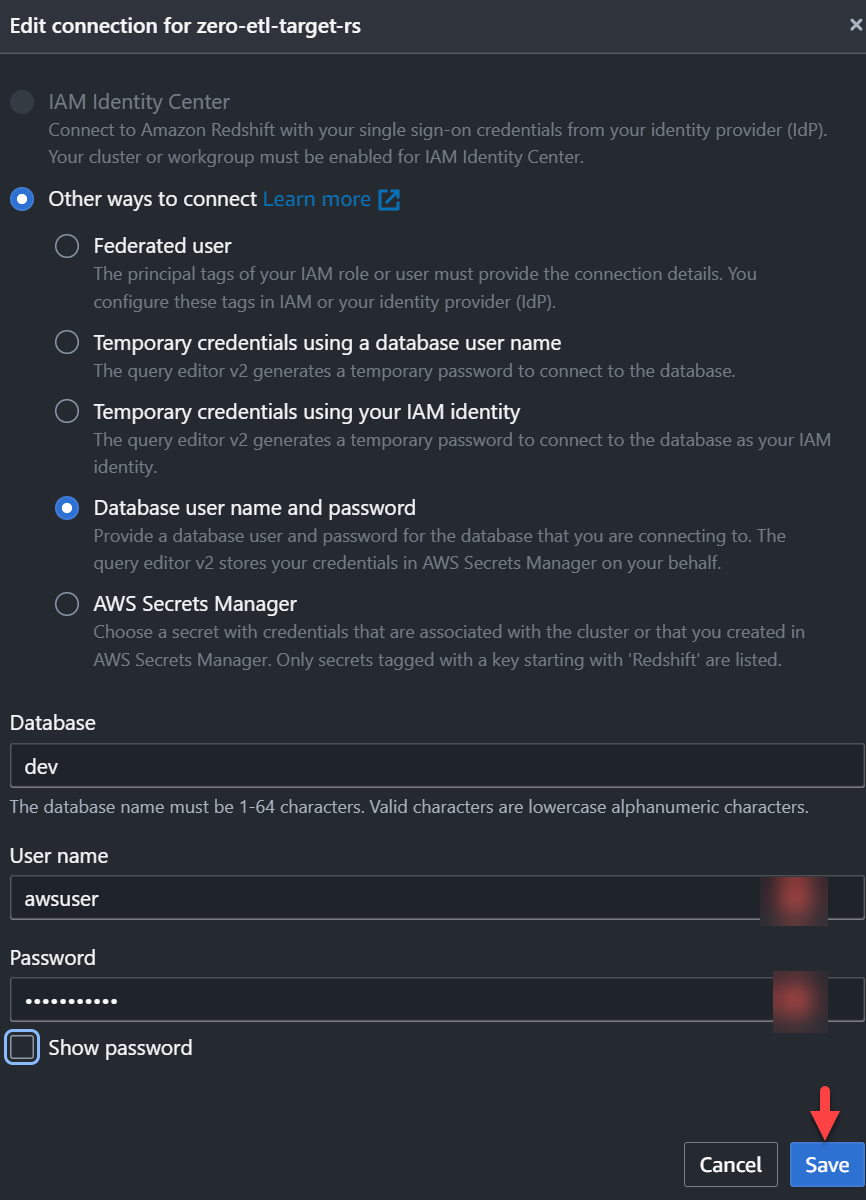
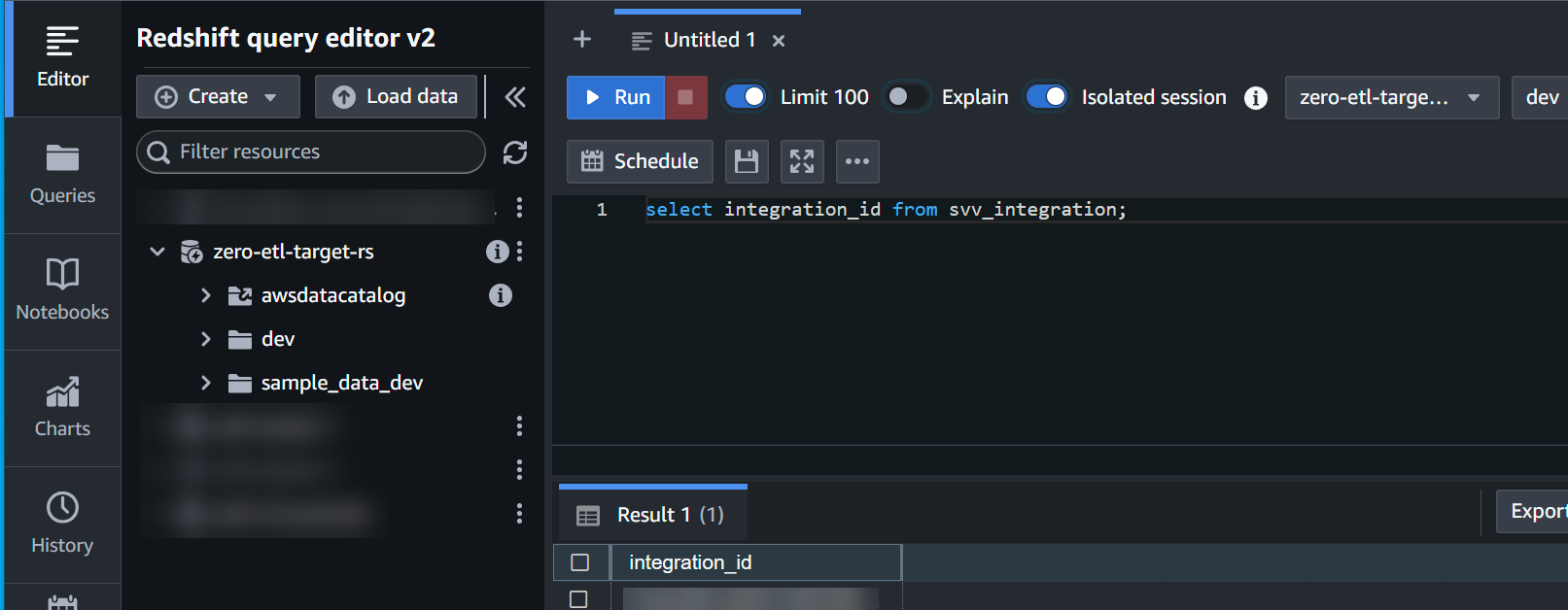
- Verkrijg het
integration_idvan hetsvv_integrationsysteem tafel:
select integration_id from svv_integration; -- copy this result, use in the next sql
- Gebruik de
integration_idvan de vorige stap om een nieuwe database te maken vanuit de integratie:
CREATE DATABASE zetl_source FROM INTEGRATION '<result from above>';
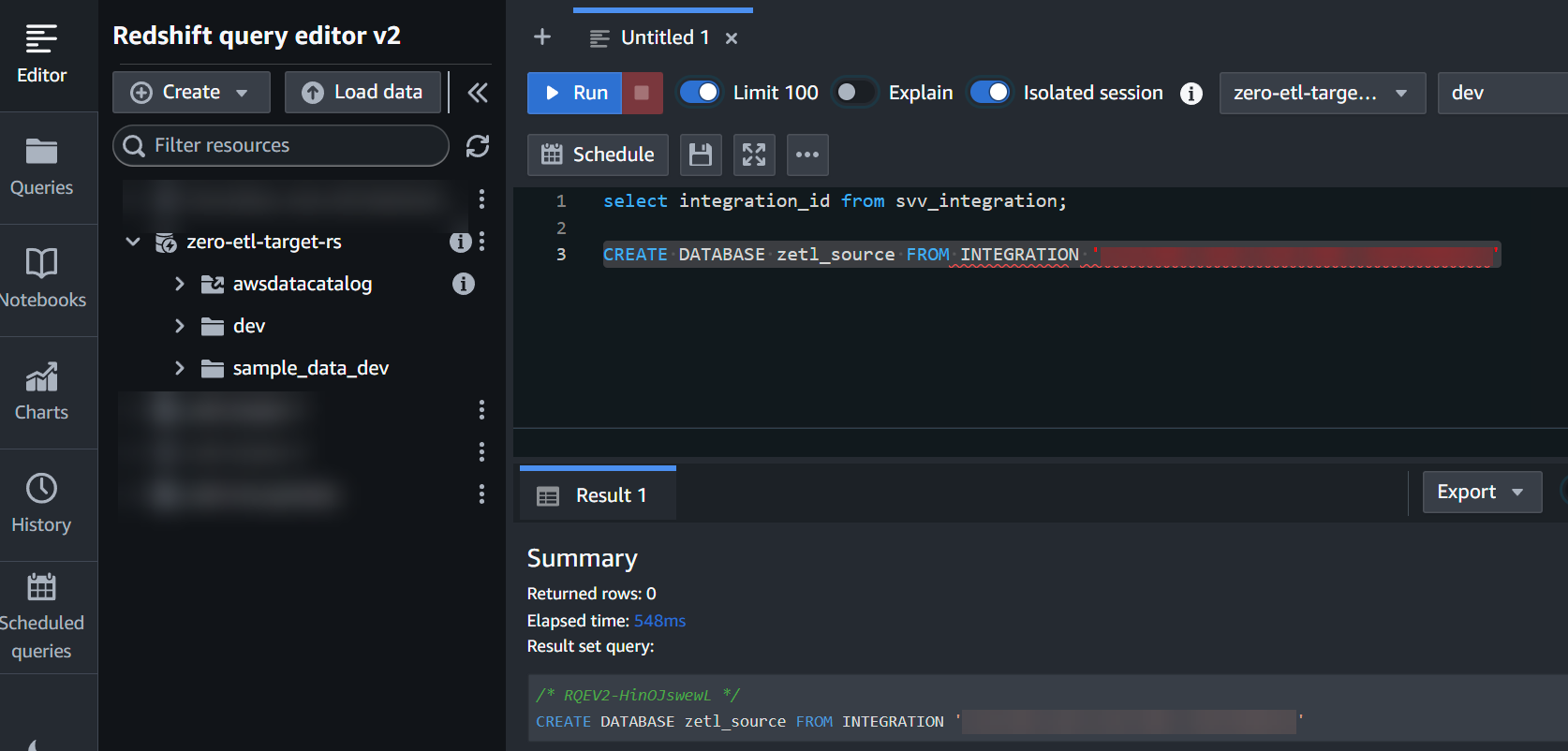
De integratie is nu voltooid en een volledige momentopname van de bron wordt weergegeven zoals deze zich op de bestemming bevindt. Lopende wijzigingen worden vrijwel in realtime gesynchroniseerd.
Analyseer de bijna realtime transactiegegevens
Nu kunnen we analyses uitvoeren op de operationele gegevens van TICKIT.
Vul de bron-TICKIT-gegevens in
Voer de volgende stappen uit om de brongegevens in te vullen:
- Kopieer de CSV-invoergegevensbestanden naar een lokale map. Het volgende is een voorbeeldopdracht:
aws s3 cp 's3://redshift-blogs/zero-etl-integration/data/tickit' . --recursive
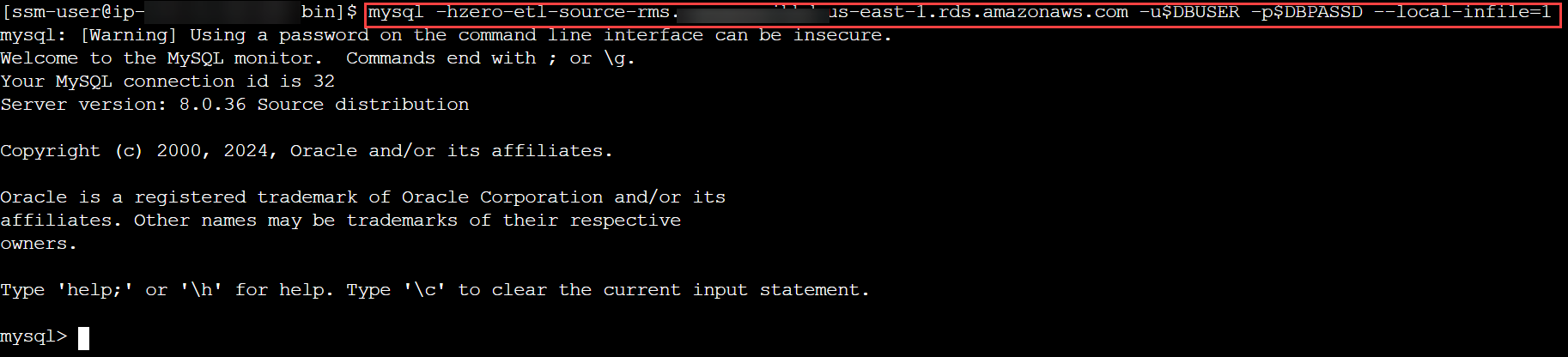
- Maak verbinding met uw RDS voor MySQL-cluster en maak een database of schema voor het TICKIT-gegevensmodel, controleer of de tabellen in dat schema een primaire sleutel hebben en start het laadproces:
mysql -h <rds_db_instance_endpoint> -u admin -p password --local-infile=1
- Gebruik het volgende CREATE TABLE-opdrachten.
- Laad de gegevens uit lokale bestanden met de opdracht LOAD DATA.
Het volgende is een voorbeeld. Houd er rekening mee dat het invoer-CSV-bestand in verschillende bestanden is opgesplitst. Deze opdracht moet voor elk bestand worden uitgevoerd als u alle gegevens wilt laden. Voor demodoeleinden zou een gedeeltelijke gegevensbelasting ook moeten werken.

Analyseer de bron TICKIT-gegevens in de bestemming
Open op de Amazon Redshift-console de query-editor v2 met behulp van de database die u hebt gemaakt als onderdeel van de integratie-instellingen. Gebruik de volgende code om de zaad- of CDC-activiteit te valideren:

U kunt nu uw bedrijfslogica voor transformaties rechtstreeks toepassen op de gegevens die naar het datawarehouse zijn gerepliceerd. U kunt ook prestatie-optimalisatietechnieken gebruiken, zoals het maken van een gematerialiseerde Redshift-weergave die de gerepliceerde tabellen en andere lokale tabellen samenvoegt om de queryprestaties voor uw analytische query's te verbeteren.
Monitoren
U kunt de volgende systeemweergaven en tabellen in Amazon Redshift opvragen om informatie te krijgen over uw zero-ETL-integraties met Amazon Redshift:
Om de integratiegerelateerde statistieken te bekijken die zijn gepubliceerd naar Amazon Cloud Watch, open de Amazon Redshift-console. Kiezen Zero-ETL-integraties in het navigatievenster en kies de integratie om activiteitsstatistieken weer te geven.
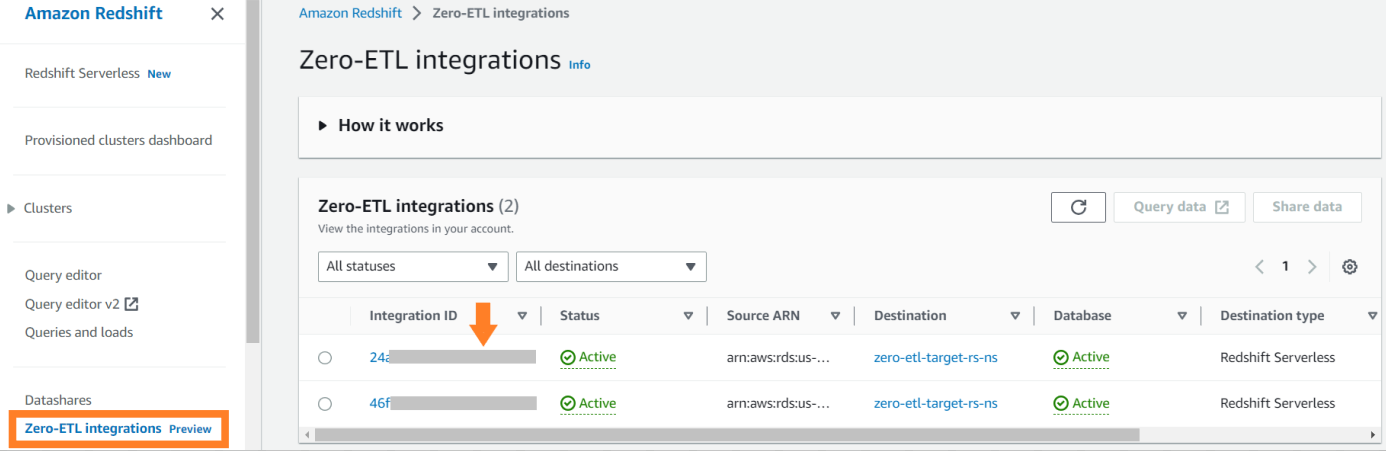
Beschikbare statistieken op de Amazon Redshift-console zijn integratiestatistieken en tabelstatistieken, waarbij tabelstatistieken details geven van elke tabel die is gerepliceerd van Amazon RDS voor MySQL naar Amazon Redshift.

Integratiestatistieken omvatten het aantal succesvolle en mislukte tabelreplicaties en vertragingsdetails.
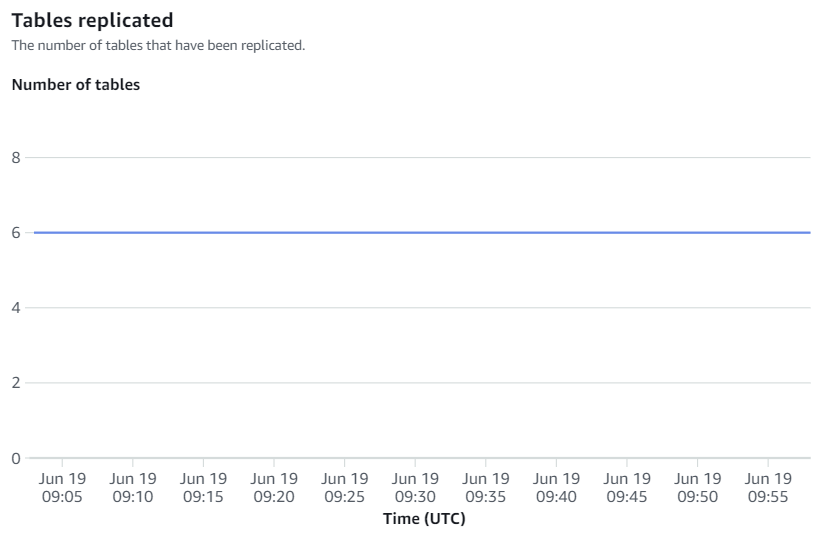
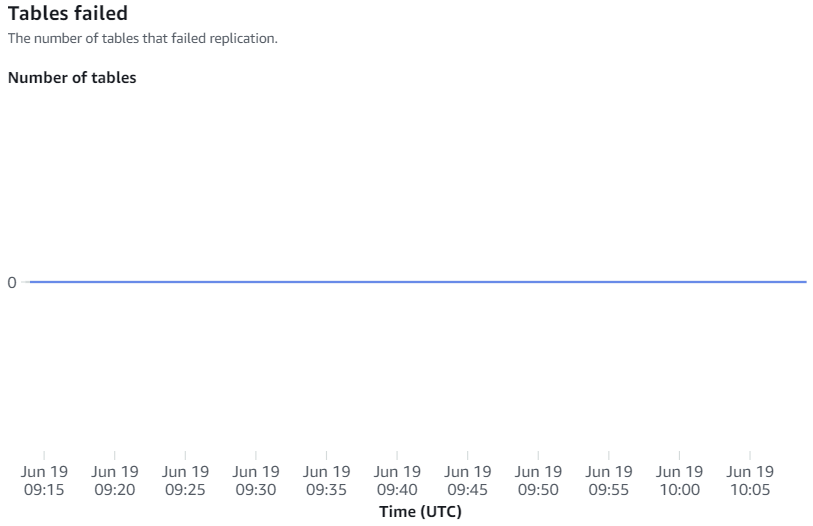
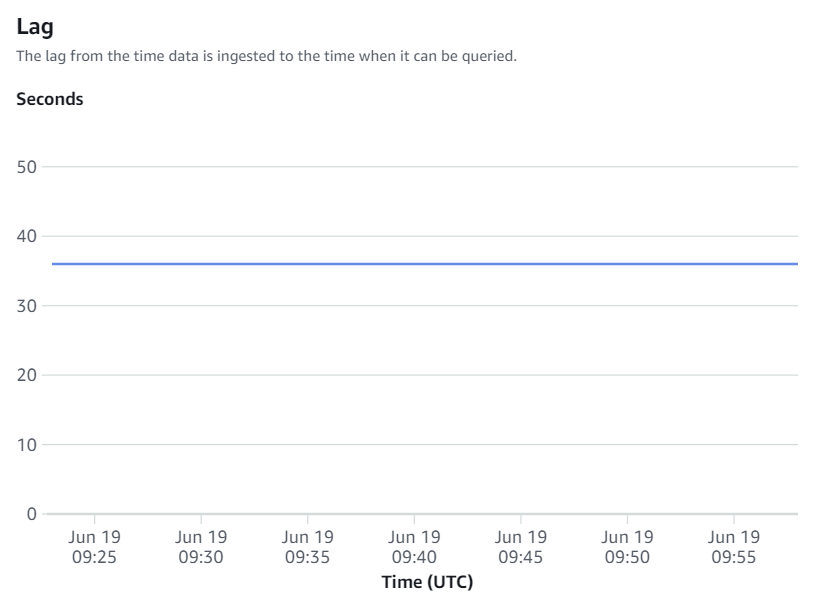
Handmatige hersynchronisaties
De nul-ETL-integratie zal automatisch een hersynchronisatie initiëren als de synchronisatiestatus van een tabel wordt weergegeven als mislukt of als hersynchronisatie vereist is. Maar in het geval dat de automatische hersynchronisatie mislukt, kunt u een hersynchronisatie starten op tabelniveau:
ALTER DATABASE zetl_source INTEGRATION REFRESH TABLES tbl1, tbl2;
Een tabel kan om meerdere redenen de status Mislukt krijgen:
- De primaire sleutel is uit de tabel verwijderd. In dergelijke gevallen moet u de primaire sleutel opnieuw toevoegen en de eerder genoemde ALTER-opdracht uitvoeren.
- Er wordt tijdens de replicatie een ongeldige waarde aangetroffen of er wordt een nieuwe kolom aan de tabel toegevoegd met een niet-ondersteund gegevenstype. In dergelijke gevallen moet u de kolom met het niet-ondersteunde gegevenstype verwijderen en de eerder genoemde ALTER-opdracht uitvoeren.
- Een interne fout kan in zeldzame gevallen een tafelfout veroorzaken. Het ALTER-commando zou dit moeten oplossen.
Opruimen
Wanneer u een nul-ETL-integratie verwijdert, worden uw transactiegegevens niet verwijderd uit de bron-RDS of de doel-RDS-databases, maar stuurt Amazon RDS geen nieuwe wijzigingen naar Amazon Redshift.
Voer de volgende stappen uit om een nul-ETL-integratie te verwijderen:
- Kies op de Amazon RDS-console Zero-ETL-integraties in het navigatievenster.
- Selecteer de zero-ETL-integratie die u wilt verwijderen en kies Verwijder.
- Kies om de verwijdering te bevestigen Verwijder.

Conclusie
In dit bericht hebben we je laten zien hoe je een zero-ETL-integratie van Amazon RDS voor MySQL naar Amazon Redshift kunt opzetten. Dit minimaliseert de noodzaak om complexe datapijplijnen te onderhouden en maakt vrijwel realtime analyses van transactionele en operationele gegevens mogelijk.
Voor meer informatie over Amazon RDS zero-ETL-integratie met Amazon Redshift raadpleegt u Werken met Amazon RDS zero-ETL-integraties met Amazon Redshift (preview).
Over de auteurs
 Milde oke is een senior specialist in Redshift-oplossingen en heeft drie jaar bij Amazon Web Services gewerkt. Hij is een AWS-gecertificeerde SA Associate, Security Specialty en Analytics Specialty-certificeringhouder, gevestigd in Queens, New York.
Milde oke is een senior specialist in Redshift-oplossingen en heeft drie jaar bij Amazon Web Services gewerkt. Hij is een AWS-gecertificeerde SA Associate, Security Specialty en Analytics Specialty-certificeringhouder, gevestigd in Queens, New York.
 Aditya Samant is een veteraan in de relationele database-industrie met meer dan twintig jaar ervaring in het werken met commerciële en open-sourcedatabases. Momenteel werkt hij bij Amazon Web Services als Principal Database Specialist Solutions Architect. In zijn rol besteedt hij tijd aan het werken met klanten aan het ontwerpen van schaalbare, veilige en robuuste cloud-native architecturen. Aditya werkt nauw samen met de serviceteams en werkt mee aan het ontwerpen en leveren van de nieuwe functies voor de beheerde databases van Amazon.
Aditya Samant is een veteraan in de relationele database-industrie met meer dan twintig jaar ervaring in het werken met commerciële en open-sourcedatabases. Momenteel werkt hij bij Amazon Web Services als Principal Database Specialist Solutions Architect. In zijn rol besteedt hij tijd aan het werken met klanten aan het ontwerpen van schaalbare, veilige en robuuste cloud-native architecturen. Aditya werkt nauw samen met de serviceteams en werkt mee aan het ontwerpen en leveren van de nieuwe functies voor de beheerde databases van Amazon.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/unlock-insights-on-amazon-rds-for-mysql-data-with-zero-etl-integration-to-amazon-redshift/

