
Afbeelding door redacteur
Heb je gehoord van Andrej Karpathy? Hij is een gerenommeerd computerwetenschapper en AI-onderzoeker, bekend om zijn werk op het gebied van deep learning en neurale netwerken. Hij speelde een sleutelrol in de ontwikkeling van ChatGPT bij OpenAI en was voorheen Sr. Director of AI bij Tesla. Zelfs daarvoor ontwierp hij en was hij de primaire instructeur voor de eerste deep learning-les Stanford – CS 231n: convolutionele neurale netwerken voor visuele herkenning. De klas werd een van de grootste op Stanford en is gegroeid van 150 ingeschreven studenten in 2015 naar 750 studenten in 2017. Ik raad iedereen die geïnteresseerd is in diepgaand leren ten zeerste aan om dit op YouTube te bekijken. Ik zal niet dieper op hem ingaan, en we zullen onze focus verleggen naar een van zijn meest populaire lezingen op YouTube, die de 1.4 miljoen views "Inleiding tot grote taalmodellen." Deze lezing is een introductie voor LLM's voor drukbezette personen en is een must voor iedereen die geïnteresseerd is in LLM's.
Ik heb een beknopte samenvatting van dit gesprek gegeven. Als dit uw interesse wekt, raad ik u ten zeerste aan de dia's en de YouTube-link te bekijken die aan het einde van dit artikel worden verstrekt.
Deze lezing biedt een uitgebreide introductie tot LLM's, hun mogelijkheden en de potentiële risico's die aan het gebruik ervan zijn verbonden. Het is verdeeld in 3 grote delen, die als volgt zijn:
Deel 1: LLM's

Dia's van Andrej Karpathy
LLM's worden getraind op een groot tekstcorpus om mensachtige reacties te genereren. In dit deel bespreekt Andrej specifiek het Llama 2-70b-model. Het is een van de grootste LLM's met 70 miljard parameters. Het model bestaat uit twee hoofdcomponenten: het parameterbestand en het runbestand. Het parameterbestand is een groot binair bestand dat de gewichten en biases van het model bevat. Deze gewichten en vooroordelen zijn in wezen de ‘kennis’ die het model tijdens de training heeft geleerd. Het runbestand is een stukje code dat wordt gebruikt om het parameterbestand te laden en het model uit te voeren. Het trainingsproces van het model kan in de volgende twee fasen worden verdeeld:
1. Voortraining
Hierbij wordt een groot stuk tekst, ongeveer 10 terabyte, van internet verzameld en vervolgens een GPU-cluster gebruikt om het model op deze gegevens te trainen. Het resultaat van het trainingsproces is een basismodel dat de lossy compressie van internet is. Het is in staat samenhangende en relevante tekst te genereren, maar vragen niet direct te beantwoorden.
2. Fijnafstemming
Het vooraf getrainde model wordt verder getraind op een dataset van hoge kwaliteit om deze bruikbaarder te maken. Dit resulteert in een assistentmodel. Andrej noemt ook een derde fase van verfijning, waarbij gebruik wordt gemaakt van vergelijkingslabels. In plaats van vanaf het begin antwoorden te genereren, krijgt het model meerdere antwoorden van kandidaten en wordt gevraagd de beste te kiezen. Dit kan eenvoudiger en efficiënter zijn dan het genereren van antwoorden, en kan de prestaties van het model verder verbeteren. Dit proces wordt versterkend leren van menselijke feedback (RLHF) genoemd.
Deel 2: Toekomst van LLM's
Dia's van Andrej Karpathy
Terwijl we de toekomst van grote taalmodellen en hun mogelijkheden bespreken, worden de volgende kernpunten besproken:
1. Schaalwet
De prestaties van het model correleren met twee variabelen: het aantal parameters en de hoeveelheid trainingstekst. Grotere modellen die op meer gegevens zijn getraind, behalen doorgaans betere prestaties.
2. Gebruik van hulpmiddelen
LLM's zoals ChatGPT kunnen tools zoals een browser, rekenmachine en Python-bibliotheken gebruiken om taken uit te voeren die anders uitdagend of onmogelijk zouden zijn voor alleen het model.
3. Systeem één en systeem twee denken in LLM's
Momenteel maken LLM's voornamelijk gebruik van systeem één denken: snel, instinctief en op patronen gebaseerd. Er is echter interesse in het ontwikkelen van LLM's die in staat zijn zich bezig te houden met systeem-twee-denken: langzamer, rationeel en bewuste inspanning vereisend.
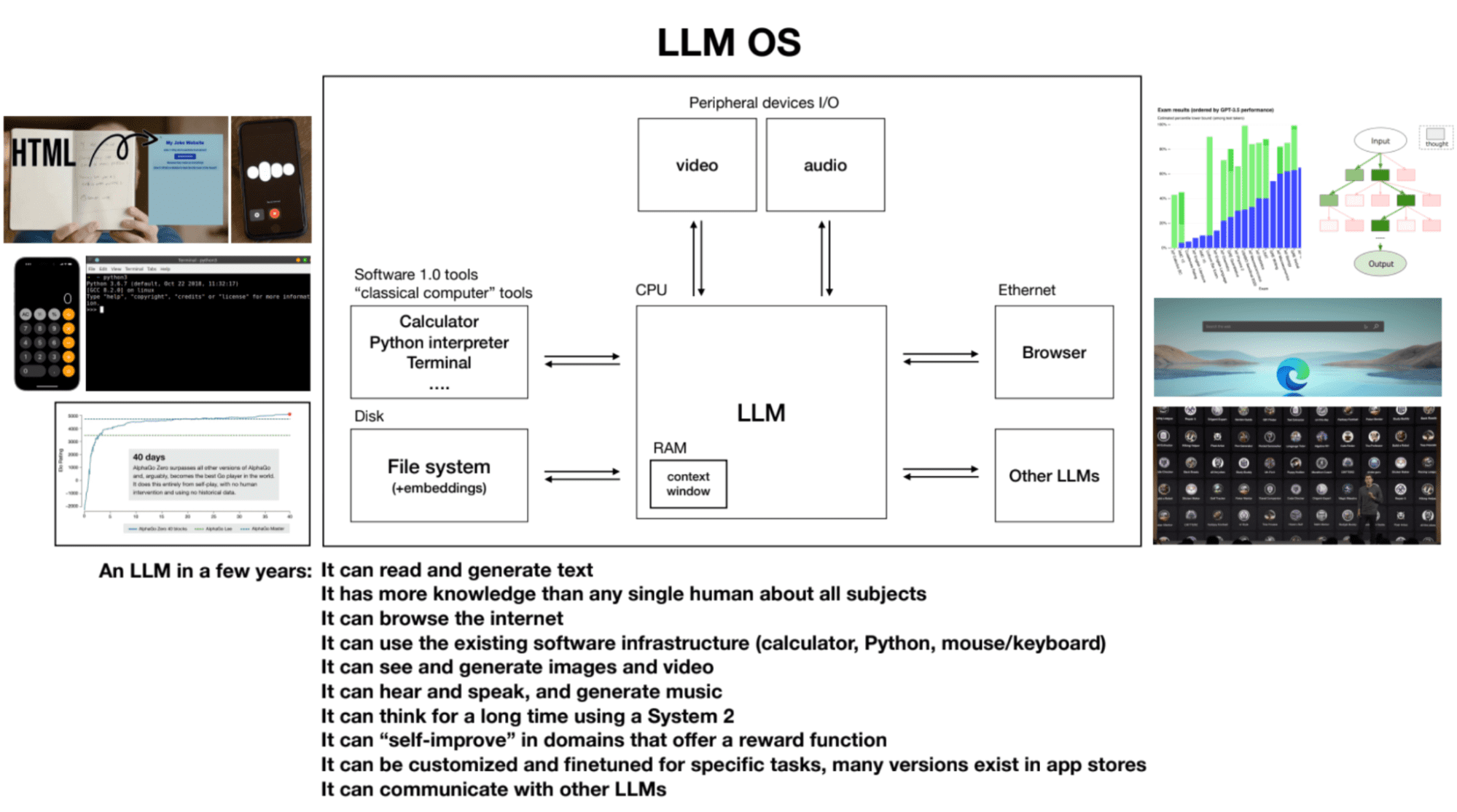
4. LLM-besturingssysteem
LLM's kunnen worden gezien als het kernelproces van een opkomend besturingssysteem. Ze kunnen tekst lezen en genereren, hebben uitgebreide kennis over verschillende onderwerpen, surfen op internet of verwijzen naar lokale bestanden, gebruiken de bestaande software-infrastructuur, genereren afbeeldingen en video's, horen en spreken, en denken gedurende langere perioden met behulp van systeem 2. Het contextvenster van een LLM is analoog aan RAM in een computer, en het kernelproces probeert relevante informatie in en uit het contextvenster te halen om taken uit te voeren.
Deel 3: LLM-beveiliging

Dia's van Andrej Karpathy
Andrej benadrukt de lopende onderzoeksinspanningen bij het aanpakken van beveiligingsuitdagingen die verband houden met LLM's. De volgende aanvallen worden besproken:
1. Ontsnapping uit de gevangenis
Pogingen om veiligheidsmaatregelen in LLM's te omzeilen om schadelijke of ongepaste informatie te verkrijgen. Voorbeelden zijn onder meer rollenspellen om het model te misleiden en het manipuleren van reacties met behulp van geoptimaliseerde reeksen woorden of afbeeldingen.
2. Snelle injectie
Betreft het injecteren van nieuwe instructies of aanwijzingen in een LLM om de reacties ervan te manipuleren. Aanvallers kunnen instructies verbergen in afbeeldingen of webpagina's, waardoor niet-gerelateerde of schadelijke inhoud in de antwoorden van het model wordt opgenomen.
3. Gegevensvergiftiging/achterdeuraanval/aanval met slaapagent
Betreft het trainen van een groot taalmodel op kwaadaardige of gemanipuleerde gegevens die triggerzinnen bevatten. Wanneer het model de triggerzin tegenkomt, kan het worden gemanipuleerd om ongewenste acties uit te voeren of onjuiste voorspellingen te doen.
U kunt de uitgebreide video op YouTube bekijken door hieronder te klikken:
[ingesloten inhoud][ingesloten inhoud]
Dia's: Klik hier
Als je nieuw bent bij LLM's en op zoek bent naar hulpmiddelen om je reis een vliegende start te geven, dan is deze uitgebreide lijst een geweldige plek om te beginnen! Het bevat zowel fundamentele als LLM-specifieke cursussen die je zullen helpen een solide basis te leggen. Als u bovendien geïnteresseerd bent in een meer gestructureerde leerervaring, Maxime Labonne heeft onlangs zijn LLM-cursus gelanceerd met drie verschillende tracks waaruit u kunt kiezen op basis van uw behoeften en ervaringsniveau. Hier zijn voor uw gemak de links naar beide bronnen:
- Een uitgebreide lijst met bronnen om grote taalmodellen onder de knie te krijgen door Kanwal Mehreen
- Grote taalmodelcursus door Maxime Labonne
Kanwal Mehreen is een aspirant-softwareontwikkelaar met een grote interesse in datawetenschap en toepassingen van AI in de geneeskunde. Kanwal werd geselecteerd als de Google Generation Scholar 2022 voor de APAC-regio. Kanwal deelt graag technische kennis door artikelen te schrijven over trending topics en heeft een passie voor het verbeteren van de vertegenwoordiging van vrouwen in de technische industrie.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.kdnuggets.com/unlock-the-secrets-of-llms-in-a-60-minute-with-andrej-karpathy?utm_source=rss&utm_medium=rss&utm_campaign=unlock-the-secrets-of-llms-in-a-60-minute-with-andrej-karpathy

