Terugkijken en dan vooruitkijken is een traditionele oefening tegen het einde van het jaar. Welke datazorgen zijn belangrijk genoeg om je zorgen over te maken in 2024? Voor welke daarvan maken we kans iets goeds te doen in 2024? Het spreekt voor zich dat geld (budget en kosten) een probleem is. Maar het is nog onnodiger om te zeggen dat het oplossen van echte zakelijke uitdagingen waarschijnlijk belangrijker is. Houd er rekening mee dat de kosten zich opstapelen en dat de voordelen hinderlijk laat opduiken. Sommige voordelen halen zelfs de categorie ‘Win of sterf terwijl je probeert’.
Toegegeven, het is niet eenvoudig:
Dus, bemoedigd, wat kunnen we leren van het verleden?
Ik heb deze vijf zorgen naar voren gebracht als serieus interessant in 2024:
- Bedrijfsresultaten
- Onderwerpen versus processen
- Modellering: realiteit of data?
- Informatica – waarom is dat iets Europees?
- Gegevensmodellering verbeteren door verbeterde cognitie???
Bedrijfsresultaten, nu of nooit
Computergebruik toegepast op zakelijke problemen gaat terug tot eind jaren zestig. De gegevensinvoer bestond aanvankelijk uit Flexowriter-papiertape (op een elektrische typemachine) en op ponskaarten. Complexe algoritmen werden in de jaren zeventig uitgevoerd als meerstaps sorteer-/samenvoegalgoritmen op magneetband die vervangen moesten worden door apparaten met directe toegang (schijven).
Zakelijke gebruiksscenario's waren vrij eenvoudig, en mensen zoals ik waren de afgelopen 10 tot 15 jaar behoorlijk druk met het implementeren van toepassingen voor stuklijsten en materiaalvereisten; op computers die voor die gebruikssituaties zijn aangeschaft. Tegen prijzen vanaf een half miljoen dollar en hoger.
Facturatie werd al snel toegevoegd als use case, maar daardoor begon het lastig te worden data kwaliteit vraagstukken (ja, toen al; klanten zijn een lastig stel).
Integratie begon een probleem te worden, wat een grote zorg bleek te zijn, omdat de vroege databasesystemen meestal werden gebruikt als puntoplossingen voor de domeintoepassingen. De visie van bedrijfsdatabases leidde echter tot de triomf van SQL over netwerk- en geïndexeerde databases (ISAM/VSAM-databases), vanwege de waargenomen flexibiliteit van genormaliseerde databases ten opzichte van te fysieke datamodellen in oudere DBMS's.
In de jaren zeventig begon de zogenaamde “DIKW-piramide” overal te verschijnen:

De bedrijfsmodelvisies drongen ook door in de codelagen die leidden tot objectgeoriënteerde modellen (UML, OO) en OODBMS, die echter niet in de hoofdlijnen terechtkwamen.
De hypothese voor dit soort constructie en implementatie van informatiesystemen was gebaseerd op disciplines als planning, bestuur, methoden, betrokkenheid van bedrijfsexperts en bepaalde technologie (relationele modellering, OO, enz.).
In de jaren tachtig en negentig verspreidde zich echter het besef dat deze ‘silo’s’ te moeilijk en te duur waren. Nieuwe technologieën zoals minicomputers en personal computers, maar ook OLAP en datawarehousing werden op tafel gegooid om enige verlichting te bieden voor de echte zakelijke behoeften.
Onderwerpen in plaats van processen
Tot ver in de nieuwe eeuw waren ERP-systemen (zoals Oracle, SAP en andere) en enorme datawarehouses, ondersteund door analytics zoals OLAP, SAS en nog veel meer, inderdaad de leidraad voor de meeste grote ondernemingen. Tegen hoge kosten, ja. En moeilijk te veranderen, ja. De baten van de hoge kosten waren echter verdedigbaar, als je het mij vraagt. In het begin van deze eeuw deden zich externe factoren voor, zoals de groei van het marktgebaseerde beleggingsdenken (het nieuwe liberalisme), een nieuwe macropolitieke situatie met een sterke Europese Unie, en een sleutelrol voor China.
De mondialisering van bedrijfsactiviteiten vond snel plaats en gaat nog steeds door. Dit maakte de ondernemingen een stuk complexer, omdat ze voortkwamen uit fusies en overnames, conflicterende productlijnen, tegenstrijdige bedrijfsregels, enz. Er was/is hoge druk van investeerders die om aanzienlijk kortere ROI-cycli vroegen. Politiek, ideologie en tumultueuze dynamiek hadden allemaal invloed op wat traditioneel werd opgevat als (management-/computer)wetenschap.
Het succes van grote technologiebedrijven als Yahoo, Google, enz. bij het omgaan met ‘big data’ schiep ambitieuze verwachtingen van ‘technologie die te hulp schiet’.
Bijgevolg was technologie de plek waar mensen naar oplossingen zochten – denk aan NoSQL, functioneel programmeren en de ‘moderne datastack’. Opslag was nu gemakkelijk en goedkoop, terwijl ‘computergebruik’ net zo omslachtig was als voorheen. AI werd krachtiger (maar nog steeds erg duur wat betreft computerkosten en gevolgen voor het milieu).
In 2024 zal er een enorme focus (blijven) zijn op de stroom van data naar de omgeving(en) waar deze gebruikt gaat worden. (Zowel met als zonder AI, etc.) Onder een paraplu als ‘de moderne datastack’ en met behulp van technische nieuwsuitingen als ‘data engineering’, ‘data fabric’, ‘data mesh’, etc. worden data verplaatst en getransformeerd in voornamelijk fysieke structuren, geschikt voor algoritmische en statistische verwerking (ook wel AI genoemd).
De energie is intens en de gereedschappen worden in aantallen aangeschaft en toegepast, wat begint te matchen met een boodschappenlijstje voor pasgetrouwden voor wat je nodig hebt in je keuken. (Sorry, ik kon er niets aan doen.) Kijk hier eens naar (afkomstig van een zeer informatieve site genaamd Our West Nest):

En het bovenstaande is slechts de categorie gadgets en hulpmiddelen die u wordt aanbevolen. Raadpleeg hun site voor de rest van de spullen die je nodig hebt. Dus nu weet je wat er nodig is om een ‘voedselingenieur’ te zijn. Wat data-engineeringtools betreft, kijk eens naar dit overweldigende website!
Helaas, zoals elke goede kok je graag zal vertellen, zitten de kneepjes van het vak in het kennen van je materialen (het eten) en het combineren en matchen van de smaak van goede producten, die je weet te vinden en hoe je ze moet behandelen. Vertaald naar onze praktijk betekent dit dat je heel veel technische tools kunt toepassen, maar de klus wordt alleen geklaard als je de onderwerpen van de bedrijfsdomeinen kent, de zakelijke zorgen kent en de problemen samen met de zakenmensen in de federatie oplost. scenario's.
Anders bent u waarschijnlijk geen kosteneffectieve aanbieder van oplossingen. Dit is een zakelijke kwestie, geen raketwetenschap (noch computerwetenschap).
En weten waar het bedrijf over gaat, is ons volgende onderwerp.
Modellering van de werkelijkheid: kennis, geen gegevens
De werkelijkheid kan wreed zijn: een van mijn favoriete (echte) horrorverhalen gaat over een multinationaal B2C-bedrijf dat een nieuw verkooprapportagesysteem wilde implementeren. We hebben het gebouwd door gegevens te verzamelen van verschillende ERP-systemen die in verschillende landen draaien – om er vervolgens achter te komen dat de geconsolideerde database in meer dan 50% van de verkooprapportregels informatie over de productcategoriehiërarchie miste! Dat vertraagde het project met enkele maanden, waarbij jonge, stoere controllers om beurten de verschillende dochterbedrijven bezochten… Als ze dat van tevoren hadden geweten, had het project er waarschijnlijk anders uitgezien.
Genatieve AI (GenAI) lijkt tegenwoordig op alle voorpagina’s te verschijnen. En op pagina 2 beweren veel mensen dat je, om de neiging van GenAI om te hallucineren (dingen te verzinnen) te stoppen, het moet helpen met een kennis grafiek. Dat is een heel goed idee, omdat grafieken dicht bij de zakelijke semantiek liggen.
Mike Dillinger heeft een heel direct genomen over de noodzaak van kennisgrafieken om AI iets beter te laten werken:
“Voor computer- en datawetenschappers is een manier om het gebruik van kennisgrafieken te motiveren, ze te positioneren als een manier om de vele tekortkomingen van het representeren van gegevens en kennis in relationele databases en het manipuleren ervan met lineaire machine learning-modellen te overwinnen.
Een grote, slechte en dramatische, vereenvoudigende aanname van databases is dat kolommen als onafhankelijk of orthogonaal worden behandeld. Machine learning-technieken zoals classificaties gaan uit van dezelfde veronderstelling: er zijn gewichten voor elk kenmerk/variabele, maar er zijn geen termen die de covariantie of onderlinge afhankelijkheid tussen twee of meer kenmerken weergeven. Er wordt ook aangenomen dat de doelklassen voor classificaties onsamenhangend of niet-gecorreleerd zijn. Daarom presteren classificaties slecht bij het beslissen tussen hiërarchisch verwante klassen. Ze zijn niet disjunct, maar de een omvat de ander. Door te geloven dat variabelen geen verband houden terwijl ze in werkelijkheid wel verband houden, wordt de foutvariantie simpelweg opgeblazen tot ondraaglijke niveaus.”
Ook uit een van de dia's van Dillinger: “Waarom kennisgrafieken gebruiken? Omdat wiskunde letterlijk, opzettelijk, absoluut zinloos is. En logica ook.”
Het maken van zakelijke impact is waar het begint en waar het eindigt.
AI moet betrouwbare proposities opleveren. Waarom niet vraag om certificering?
Meer informatica, minder technologie
Het volgende is geen groot probleem, maar onnauwkeurige terminologie lijkt ons ‘gilde’ te hebben besmet.
Ik begon in 1969 aan de Universiteit van Kopenhagen. Mijn professor was Peter Naur, die vooral bekend staat om zaken als:
- Co-auteur met Edsger Dijkstra et al. op de programmeertaal Algol-60
- De “N” in BNF, de Backus-Naur-vorm die in veel taaldefinities wordt gebruikt
- Hij wilde geen ‘computerwetenschapper’ worden genoemd; hij gaf de voorkeur aan ‘Datalogie’ in plaats van ‘Informatica’ – de reden hiervoor is dat de twee domeinen (computers en menselijk weten) heel verschillend zijn en dat zijn interesse uitging naar data, wat gecreëerd en beschreven door ons als mensen
- In zijn boek “Computing: A Human Activity” (1992), een verzameling van zijn bijdragen aan de informatica, verwierp hij de programmeerschool die programmeren als een tak van de wiskunde beschouwt.
- Computer Pioneer Award van de IEEE Computer Society (1986)
- Winnaar van de Turing Award 2005, de titel van zijn prijslezing was “Computergebruik versus menselijk denken"
(Zie meer achtergrond hier.)
In werkelijkheid hebben we drie concurrerende termen:
- Computertechnologie
- Informatica
- Informatie wetenschap
‘Informatiewetenschap’ betekent klassiek het soort informatieverwerking dat bibliothecarissen en archivarissen doen. Tegenwoordig is het allemaal digitaal...
In grote delen van Europa en andere landen wordt ‘informatica’ gebruikt in plaats van informatica. In de VS et al. wordt informatica vaak gebruikt bij het omgaan met informatie in de gezondheidszorg.
En dan is er nog ‘computerwetenschap’. Academisch gezien is het tegenwoordig zeer wiskundig en abstract, gebaseerd op logica en functies. Het wordt echter vaak beschreven als een reeks vaardigheden die worden gebruikt bij het omgaan met gegevens. Maar de directe semantiek, ‘hoe computers te construeren’, valt niet meer onder de reikwijdte; Ik zou verwachten dat ingenieurs en natuurkundigen daarvoor zorgen.
Als ik snelwegen aanleg, kan ik speciale snelwegrelevante vaardigheden gebruiken. Maar maakt mij dat een ‘snelwegwetenschapper’? Niet zo.
In Communications of the ACM (Association for Computing Machinery, login vereist) pleit Peter Denning, voormalig president van de ACM, voor en tegen computerwetenschap in een artikel getiteld “Is Computer Science Science? Computerwetenschap voldoet aan alle criteria om een wetenschap te zijn, maar heeft een zelf veroorzaakt geloofwaardigheidsprobleem”, 2005, zoals hij concludeert:
“Valideer beweringen over computerwetenschappen
Daar heb je ons. We hebben de hype van reclameafdelingen in onze laboratoria laten infiltreren. In een steekproef van 400 computerwetenschappelijke artikelen gepubliceerd vóór 1995 ontdekte Walter Tichy dat ongeveer 50% van degenen die modellen of hypothesen voorstelden deze niet testte [12]. Op andere wetenschapsgebieden bedroeg het percentage artikelen met ongeteste hypothesen ongeveer 10%. Tichy concludeerde dat ons onvermogen om meer te testen ervoor zorgde dat veel ondeugdelijke ideeën in de praktijk konden worden uitgeprobeerd en dat dit de geloofwaardigheid van ons vakgebied als wetenschap aantastte. …
De perceptie van ons vakgebied lijkt een generatiekwestie te zijn. De oudere leden hebben de neiging zich te identificeren met een van de drie wortels van het vakgebied: wetenschap, techniek of wiskunde. Het wetenschapsparadigma is grotendeels onzichtbaar binnen de andere twee groepen.
De jongere generatie, die veel minder onder de indruk is van nieuwe computertechnologieën dan de oudere ooit, staat meer open voor kritisch denken. Computerwetenschappen hebben altijd deel uitgemaakt van hun wereld; zij twijfelen niet aan de geldigheid ervan. In hun onderzoek volgen ze steeds meer het wetenschappelijke paradigma.”
De verwijzing naar Tichy is: Tichy, W. Moeten computerwetenschappers meer experimenteren? IEEE-computer 1998.
Je vraagt je af: staan we nog steeds toe dat “de hype van reclameafdelingen onze laboratoria binnendringt”?
Ik denk dat ‘informatica’ de meest algemene en precieze term is voor wat we doen. Computergebruik is een menselijke activiteit en informatica beschrijft de menselijke activiteiten van het omgaan met informatie voor en door mensen.
Ja, ik voel me nu beter, dank je!
Vooruitkijken: cognitie verbeteren
Datamodellering in de toekomst?
Zoals sommige van mijn lezers zich zullen herinneren, ben ik een (grafiek)datamodelleur in hart en nieren, met vele jaren modelleren achter de rug. Ik ben ook een groot voorstander van het toepassen van informatica op zakelijke aangelegenheden – waarbij het oplossen van zakelijke problemen het belangrijkste is dat we doen. We hebben geleden onder de kosten-batendiscussies van de afgelopen 15 tot 25 jaar.
Mensen zijn ook geneigd te geloven dat datamodellering aan het einde van de weg is, zeg maar niet meer. Wat kan er gedaan worden om de productie productiever te maken en een hogere kwaliteit te produceren? Het is ontwikkeld in de jaren zeventig, let wel. Hoeveel is er nog meer uit de jaren zeventig bewaard gebleven? (Nou ja, gewoon plagerig: relationele modellering heeft het overleefd …)
Zoals bij elke theorie zul je de aannames moeten betwisten. Datamodellering, zoals we die nu kennen, is zeer technisch georiënteerd met complexe diagrammen, die niet al te nauw aansluiten bij de beste wensen van de consumenten. In veel opzichten zijn het nog steeds ‘blauwdrukken’ gebaseerd op axiomatische paradigma’s zoals databasenormalisatie, enz. – bedoeld voor de constructie van fysieke constructies zoals databases. De uitzondering bevindt zich aan de informaticakant van het huis, waar semantische modellen (grafieken) behoorlijk wat succes hebben vanwege de expressiviteit, precisie en relatief gebruiksgemak (lees: “kennisgrafieken”).
Er bestaat krachtig, toekomstgericht onderzoek
Is dit dus het einde van de reis? Zal JSON het hele scala aan datamodellen overnemen?
Ik denk het niet. Datamodellering, met semantiek, is een onderzoeksgebied met een open einde. Traditionele op computerwetenschappen gebaseerde datamodellering was gebaseerd op vrij beperkte axioma's en paradigma's – zogenaamd versterkt door logica en abstracties.
Maar semantiek en cognitie openen de deur naar een zeer groot universum van discours. Wat datamodellering door de jaren heen probeerde te bereiken, was in feite het domein van de cognitieve wetenschap (psychologie, klinisch en filosofisch) te betreden.
Datamodellen zijn interpretaties van de wereld zoals waargenomen door onze zintuigen, en vormen de kennis van alles wat we zien en ervaren. Dit is de open weg voorwaarts!
En waar kijken we dan naar? Laten we het, voor de lol, een ‘Cognitief Positioneringssysteem’ (CPS) noemen. Even kijken:

Ervaren CPS-gebruikers die reizen, zullen merken dat de foto uit Parijs, Frankrijk komt. Sommigen zullen zelfs weten dat de rivier bekend staat onder de naam De Seine.
Overleven door visuele cognitie
De fundamentele cognitieve capaciteiten van de meeste dieren, waaronder ikzelf, zijn in de eerste plaats gericht op het begrijpen van situaties als deze:

Oeps, een leeuw! (mannelijk), probeert zich niet echt te verstoppen in de gras - dat heb je juist! Maar geen rijke context om beslissingen van te maken. Volg je instinct (terugrennen naar de auto is een goed idee).
En hier is een andere context:

Oeps – nog een leeuw! Dit keer een vrouwtje, en ze heeft waarschijnlijk een volle maag. Iets meer context om mee te werken. Het beest (gnoe?) is al bijna opgegeten. Gevolgtrekking: Ze heeft op dit moment geen honger. Maak een foto en ga weer weg, lekker rustig – lijkt veilig genoeg voor een fotograaf van wereldklasse zoals jij …
Er bestaat een rijk portfolio aan academisch onderzoek over deze zaken. We zijn geëvolueerd om om te gaan met het begrip van de context ter plekke, nu en hier, zoals ons gepresenteerd door een voortdurende stroom van zintuigen (perceptie) die arriveren in onze cognitieve verwerkingseenheden in de hersenen. Het gaat van de fundamentele psychologie, over de neuropsychologie, over de cognitieve neurowetenschappen, over intelligentie, bewustzijn en filosofie.
Ik heb de afgelopen tien jaar verschillende onderzoekers en schrijvers gevolgd, en hier zullen we een kleine cavalcade van interessante observaties bekijken.
Maps
Het is duidelijk dat kaarten deel uitmaken van deze zoektocht naar het verlichten van de aandacht en het begrip. Hier is (het midden van) de kaart van de Londense metro:
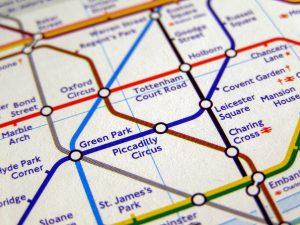
Allereerst hebben kaarten een aantal kwaliteiten, zoals hierboven geïllustreerd:
- Locaties zijn in kaart gebracht
- Relaties of paden, zo u wilt, worden in kaart gebracht
- Kaarten zijn grafieken, grafieken zijn kaarten!
- Kaarten zijn intuïtief logisch
Merk ook op dat op de kaart locaties/oriëntatiepunten worden vermeld. Als u echter bent vergeten wat er zich in de buurt van metrostation Sloane Square bevindt, kunt u altijd naar het daglicht gaan en kijken of uw CPS de omgeving (= context) voor u herkent. Zoiets als: "O ja, daar in het winkeltje in het gele huis hebben we de rode bandana voor Ellen gekocht tijdens onze huwelijksreis."
Denken in kaartallegorieën wanneer u datamodellen maakt, is eenvoudig en krachtig. Daarom heb ik jaren geleden ER-diagrammen en UML-klassendiagrammen achterwege gelaten.
Op tijdelijke aanduidingen/locatiemarkeringen/namen van plaatsen
Je weg vinden is iets meer dan kaarten en cognitieve intuïties. In zijn uitstekende boek ‘Wayfinding’, Picador MacMillan 2020, heeft Michael Bond (wetenschapsjournalist, voormalig hoofdredacteur van New Scientist) enkele verbazingwekkende observaties en onthullingen.
Hij citeert antropoloog Ariane Burke die zegt dat er archeologisch bewijs bestaat dat de vroegmoderne mens over uitgebreide sociale netwerken beschikte. “Die wijdverspreide netwerken waren essentieel voor onze cultuur”, legde ze uit tijdens een telefoongesprek. “Bedenk dat er tijdens het paleolithicum relatief weinig mensen in de buurt waren. … Het onderhouden van een ruimtelijk uitgebreid sociaal netwerk was een manier om je voortbestaan te garanderen. Je zou een zeer dynamische cognitieve kaart nodig hebben, die je voortdurend zou moeten bijwerken met informatie over je contacten en wat zij je vertelden over het landschap.”
Bond maakt ook melding van het gebruik van topografische plaatsnamen – toponiemen. Als je bijvoorbeeld vanaf de boerderij van zijn ouders in Schotland naar het noordwesten gaat, ontmoet je ‘de samenvloeiing van de heldere en glanzende beken’ en volg je het oude veepad ‘rots van de vogels’. Ongeveer anderhalve kilometer verder ontmoet je de ‘grote zwarte heuvel’ en steek je de ‘rode stroom’ over. Direct verderop ligt de ‘heuvel van de strijd’. Na een klim bevind je je op de “heuvel van de bergbraambessen” (daar groeien ze nog steeds).
Historici geloven dat topografische plaatsnamen de vroege kolonisten een geografisch referentiesysteem gaven, een voorloper van lengte- en breedtegraad. Een beschrijvende naam roept een mentaal beeld op – je zult die ‘met gras begroeide verhevenheid op een heuveltje’ (Funtulich, in het Gaelic) herkennen als je hem ziet. Een reeks plaatsnamen vormt een reeks richtingen: zo uitgerust kunt u uw reis maken.
Verder naar het noorden, naar de Iniut-bevolking in het noorden van Canada, Alaska en Groenland. Toen de ontdekkingsreiziger George Francis Lyon in 1822 door het gehucht Igloolik in het Canadese Noordpoolgebied trok, op zoek naar de Noordwestelijke Passage, merkte hij op dat ‘elk stroompje, meer, baai, punt of eiland een naam heeft, en zelfs bepaalde stapels stenen.”
Voor een buitenstaander kan het Noordpoolgebied er saai en eentonig uitzien. …op de zuidhelling van Baffin Island vind je Nuluujaak, oftewel “twee eilanden die op billen lijken.” Moeilijk te missen. Verderop langs de kust weet je precies waar je bent als je Qumanguaq ziet, ‘de schouderophalende heuvel (geen nek).’
Deze benadering van het benoemen van plaatsen is heel anders dan die van de eerste Europese ontdekkingsreizigers van Amerika, die de neiging hadden om vrienden, geldschieters of notabelen uit hun thuisland te eren in plaats van de lokale topografie of cultuur.
Hoe wij navigeren
Voordat we Michael Bond verlaten, zijn hier enkele opmerkingen die de moeite waard zijn om over na te denken:
“Mensen zijn gezegend met een innerlijke navigator die onmetelijk geavanceerder en capabeler is dan welk kunstmatig systeem dan ook. Hoe gebruiken we het?
Psychologen hebben ontdekt dat mensen bij het vinden van hun weg door onbekend terrein een van de volgende twee strategieën volgen: óf ze relateren alles aan hun eigen positie in de ruimte, de ‘egocentrische’ benadering, óf ze vertrouwen op de kenmerken van het landschap en hoe deze zich tot elkaar verhouden. naar elkaar om te vertellen waar ze zijn, de ‘ruimtelijke’ benadering.”
Een andere reeks observaties die ik interessant vind, is hoe we ons feitelijk in landschappen voortbewegen en routes volgen. Het lijkt erop dat grenzen net zo belangrijk zijn als locaties. En ik vermoed dat dit kan worden gegeneraliseerd naar geconstrueerde ‘landschappen’, waar grenzen de navigatie aanzienlijk (en intuïtief) kunnen vergemakkelijken.
Ik kan 'Wayfinding' van Michael Bond van harte aanbevelen.
Beweging, ruimtelijk
Het volgende boek dat ik zal noemen is ‘’Mind in Motion: hoe actie het denken vormt” door Barbara Tversky (prof. emerita psychologie aan Stanford) uit 2019.
In veel opzichten is het gebaseerd op dezelfde bevindingen als waarover Michael Bond rapporteerde.
Mensen verplaatsen zich, net als de meeste wezens, van plaats naar plaats. Terwijl ze bewegen, laten ze sporen achter, op de grond, in de hersenen, paden en plaatsen. De Hippocampus registreert bewegingen als routes, reeksen plaatsen en paden. Dit is feitelijk De Nobelprijs voor Fysiologie of Geneeskunde 2014, dat de ene helft werd toegekend aan John O’Keefe, de andere helft gezamenlijk aan May-Britt Moser en Edvard I. Moser “voor hun ontdekkingen van cellen die een positioneringssysteem in de hersenen vormen.” De cellen worden rastercellen genoemd en worden gebruikt als markers die met de hippocampi samenwerken bij het creëren van ruimtelijke constructies in de hersenen.
Barbara Tversky heeft een breder perspectief: ze wil bewijzen dat beweging die ruimtelijk in de geest wordt vastgelegd het platform voor denken is. Niet alleen grafieken, maar ook woorden, gebaren en afbeeldingen. Ze bevorderen ook gevolgtrekking en ontdekking, maken creatie, herziening en gevolgtrekking door de gemeenschap mogelijk. Categorisering is een mentale vereenvoudiging van het volledige waargenomen beeld. Zeker prof. Tversky heeft veel aspecten hiervan onderzocht in haar psychologielaboratorium aan Stanford en aan Columbia University.
Ruimte heeft betekenis, nabijheid betekent nabijheid op elke dimensie. Verticaal: omhoog, alles goed, horizontaal: neutraal. De ruimte is bijzonder, supramodaal en essentieel om te overleven, een basis voor andere kennis. Ondersteund door gebaren.
Met andere woorden, de communicatie vanuit de geest is gemakkelijk herkenbaar en het moet voor de consument duidelijk zijn hoe deze (de communicatie) kan helpen bij de taken die in de context belangrijk zijn. Klinkt als goede aanbevelingen voor het verbeteren van datamodellen in de toekomst!
‘Mind in Motion: How Action Shapes Thought’ is een baanbrekend werk in de cognitieve wetenschap. Er is een uitstekende YouTube-video (Spatial Thinking is the Foundation of Thought) met haar vanaf 2022, hier.
Cognitie in de hersenen (links en rechts)
Een van de belangrijkste, zorgvuldig onderzochte boeken over cognitieve zaken is ‘The Matter with Things: Our Brains, Our Delusions, and the Unmaking of the World’ van psychiater, neurowetenschappelijk onderzoeker, filosoof en literatuurwetenschapper Dr. Ian McGilchrist, Perspectiva, 2021.
In zijn eigen woorden:
“Eigenlijk zijn er geen onderdelen. Onderdelen zijn een artefact van een bepaalde manier van omgaan met de wereld. Er zijn alleen gehelen. En dingen die we als delen beschouwen, zijn op een ander niveau gehelen, en dingen die we als gehelen beschouwen, kunnen worden gezien als delen van een nog groter geheel.
Maar dit gedoe om dingen in delen op te delen is een artefact van de fragmentarische aandacht van de linkerhersenhelft. Dus omdat het zich probeert te concentreren op dit kleine detail, richt het zich op een bepaald klein stukje, misschien drie van de 360 graden aandachtsboog, en dat leidt tot een andere kijk op de wereld dan die van de rechterhersenhelft.’
De pedante linkerhersenhelft en de intuïtieve rechterhersenhelft
De taakverdeling tussen onze twee hersenhelften kan met een paar voorbeelden worden samengevat:
| Links | Rechts |
| bekend | nieuwe |
| zekerheid | mogelijkheid |
| vastheid | stroom |
| onderdelen | geheel |
| uitdrukkelijk | stilzwijgend |
| afgetrokken | contextual |
| algemeen | unieke |
| kwantificering | kwalificatie |
| levenloos | verlevendigen |
| optimistisch | realistisch |
| vertegenwoordigd | presenteren |
De redenen voor de tweedeling zijn evolutionair. De vereenvoudigde uitleg komt grofweg overeen met de twee leeuwenfoto's hierboven. De ene is: "Oh, ik weet wat dat is", en de andere is: "Help, ik kan maar beter vluchten!" Beide reacties zijn behoorlijk nuttig.
Hier is een heel interessant YouTube-lezing: Dr. Iain McGilchrist sprak in de IdeaSquare-innovatieruimte van CERN om de aard van de werkelijkheid te bespreken vanuit het perspectief van het menselijk brein en de filosofie. Het evenement werd georganiseerd in combinatie met een pilotcursus die studenten uitrustte met vaardigheden op het gebied van grootschalig systeemdenken en hoe ze maatschappelijke verandering teweeg kunnen brengen. Hij onderhoudt ook een website hier.
Zijn nieuwste boek, ‘The Matter with Things’, bestaat uit twee delen, in totaal 1,300 pagina’s. Zal je wel een tijdje bezig houden!
Ik hoop dat ik je ervan heb overtuigd dat we verschillende mogelijkheden hebben om beter te begrijpen waar datamodellen over gaan? Houd je ogen open! Communiceer met behulp van intuïtie! Moge 2024 het jaar zijn waarin innovatieve evolutie al dat datawerk eenvoudiger maakt!
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.dataversity.net/handling-data-concerns-in-2024-and-onwards/

