
Gegenereerd met Midjourney
De NeurIPS 2023-conferentie, die van 10 tot 16 december in de levendige stad New Orleans werd gehouden, legde bijzondere nadruk op generatieve AI en grote taalmodellen (LLM's). In het licht van de recente baanbrekende ontwikkelingen op dit gebied was het geen verrassing dat deze onderwerpen de discussies domineerden.
Een van de kernthema’s van de conferentie van dit jaar was de zoektocht naar efficiëntere AI-systemen. Onderzoekers en ontwikkelaars zijn actief op zoek naar manieren om AI te construeren die niet alleen sneller leert dan huidige LLM's, maar ook over verbeterde redeneermogelijkheden beschikt en tegelijkertijd minder computerbronnen verbruikt. Dit streven is cruciaal in de race naar het bereiken van Artificial General Intelligence (AGI), een doel dat in de nabije toekomst steeds beter haalbaar lijkt.
De uitgenodigde lezingen op NeurIPS 2023 waren een weerspiegeling van deze dynamische en snel evoluerende interesses. Presentatoren uit verschillende domeinen van AI-onderzoek deelden hun nieuwste prestaties en boden zo een kijkje in de allernieuwste AI-ontwikkelingen. In dit artikel duiken we in deze gesprekken, waarbij we de belangrijkste inzichten en lessen eruit halen en bespreken, die essentieel zijn voor het begrijpen van de huidige en toekomstige landschappen van AI-innovatie.
NextGenAI: de waan van schaalvergroting en de toekomst van generatieve AI
In zijn praatje, vertelde Björn Ommer, hoofd van de Computer Vision & Learning Group aan de Ludwig Maximilian Universiteit van München, hoe zijn laboratorium Stable Diffusion kwam ontwikkelen, een paar lessen die ze uit dit proces hebben geleerd, en de recente ontwikkelingen, waaronder hoe we diffusiemodellen kunnen combineren met onder meer stroommatching, ophaalvergroting en LoRA-benaderingen.
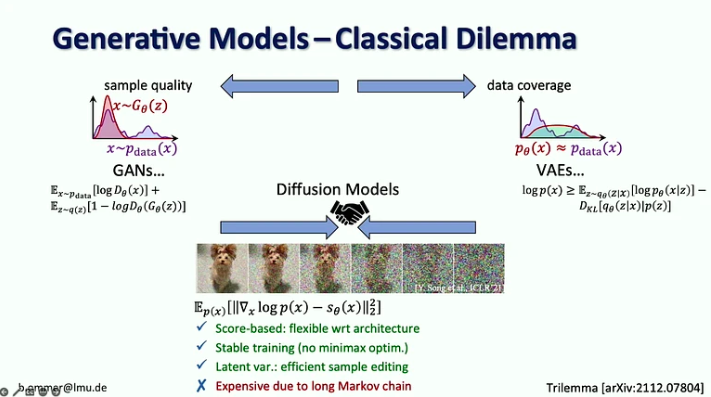
Sleutelfaciliteiten:
- In het tijdperk van generatieve AI zijn we overgestapt van de focus op perceptie in visiemodellen (dat wil zeggen objectherkenning) naar het voorspellen van de ontbrekende delen (bijvoorbeeld het genereren van afbeeldingen en video's met diffusiemodellen).
- Twintig jaar lang was computer vision gericht op benchmarkonderzoek, waardoor de aandacht op de meest prominente problemen kon worden gericht. In Generatieve AI hebben we geen benchmarks om voor te optimaliseren, waardoor het veld voor iedereen openging om zijn eigen richting in te slaan.
- Diffusiemodellen combineren de voordelen van eerdere generatieve modellen doordat ze gebaseerd zijn op scores, met een stabiele trainingsprocedure en efficiënte monsterbewerking, maar ze zijn duur vanwege hun lange Markov-keten.
- De uitdaging met sterke waarschijnlijkheidsmodellen is dat de meeste bits details bevatten die nauwelijks waarneembaar zijn voor het menselijk oog, terwijl het coderen van de semantiek, die er het meest toe doet, slechts een paar bits in beslag neemt. Schalen alleen zou dit probleem niet oplossen, omdat de vraag naar computerbronnen negen keer sneller groeit dan het GPU-aanbod.
- De voorgestelde oplossing is om de sterke punten van diffusiemodellen en ConvNets te combineren, met name de efficiëntie van convoluties voor het weergeven van lokale details en de expressiviteit van diffusiemodellen voor langeafstandscontext.
- Björn Ommer stelt ook voor om een flow-matching-aanpak te gebruiken om beeldsynthese met hoge resolutie uit kleine latente diffusiemodellen mogelijk te maken.
- Een andere benadering om de efficiëntie van beeldsynthese te vergroten, is door te focussen op de compositie van scènes en tegelijkertijd gebruik te maken van retrieval augmentation om de details in te vullen.
- Ten slotte introduceerde hij de iPoke-aanpak voor gecontroleerde stochastische videosynthese.
Als deze diepgaande inhoud nuttig voor u is, abonneer je op onze AI-mailinglijst om gewaarschuwd te worden wanneer we nieuw materiaal uitbrengen.
De vele gezichten van verantwoordelijke AI
In haar presentatieLora Aroyo, een onderzoekswetenschapper bij Google Research, benadrukte een belangrijke beperking in traditionele benaderingen van machinaal leren: hun afhankelijkheid van binaire categorisaties van gegevens als positieve of negatieve voorbeelden. Deze oversimplificatie, zo betoogde ze, gaat voorbij aan de complexe subjectiviteit die inherent is aan scenario's en inhoud uit de echte wereld. Via verschillende gebruiksscenario's liet Aroyo zien hoe dubbelzinnigheid over de inhoud en de natuurlijke variatie in menselijke standpunten vaak tot onvermijdelijke meningsverschillen leiden. Ze benadrukte hoe belangrijk het is om deze meningsverschillen te behandelen als betekenisvolle signalen en niet als louter ruis.

Dit zijn de belangrijkste conclusies uit de lezing:
- Onenigheid tussen menselijke laboranten kan productief zijn. In plaats van alle antwoorden als juist of fout te behandelen, introduceerde Lora Aroyo ‘waarheid door onenigheid’, een benadering van distributieve waarheid voor het beoordelen van de betrouwbaarheid van gegevens door gebruik te maken van onenigheid van beoordelaars.
- Gegevenskwaliteit is zelfs voor experts moeilijk, omdat experts het net zo oneens zijn als crowd labers. Deze meningsverschillen kunnen veel informatiever zijn dan de antwoorden van één enkele deskundige.
- Bij veiligheidsevaluatietaken zijn deskundigen het over 40% van de voorbeelden oneens. In plaats van te proberen deze meningsverschillen op te lossen, moeten we meer van dergelijke voorbeelden verzamelen en deze gebruiken om de modellen en evaluatiestatistieken te verbeteren.
- Lora Aroyo presenteerde ook hun Veiligheid met diversiteit methode om de gegevens nauwkeurig te onderzoeken in termen van wat erin staat en wie deze heeft geannoteerd.
- Deze methode leverde een benchmarkdataset op met variabiliteit in LLM-veiligheidsoordelen over verschillende demografische groepen beoordelaars (in totaal 2.5 miljoen beoordelingen).
- Voor 20% van de gesprekken was het moeilijk om te beslissen of de reactie van de chatbot veilig of onveilig was, aangezien er ongeveer evenveel respondenten waren die deze als veilig of onveilig bestempelden.
- De diversiteit aan beoordelaars en gegevens speelt een cruciale rol bij het evalueren van modellen. Het niet erkennen van het brede scala aan menselijke perspectieven en de dubbelzinnigheid die aanwezig is in de inhoud kan de afstemming van de prestaties van machine learning op de verwachtingen in de echte wereld belemmeren.
- 80% van de AI-veiligheidsinspanningen zijn al behoorlijk goed, maar voor de overige 20% is een verdubbeling van de inspanning nodig om randgevallen en alle varianten in de oneindige ruimte van diversiteit aan te pakken.
Samenhangstatistieken, zelf gegenereerde ervaringen en waarom jonge mensen veel slimmer zijn dan de huidige AI
In haar praatjeLinda Smith, een vooraanstaande professor aan de Indiana University Bloomington, onderzocht het onderwerp datasparsiteit in de leerprocessen van baby's en jonge kinderen. Ze concentreerde zich specifiek op objectherkenning en het leren van namen, waarbij ze zich verdiepte in de manier waarop de statistieken van zelfgegenereerde ervaringen van baby's mogelijke oplossingen bieden voor de uitdaging van gegevenssparsiteit.
Sleutelfaciliteiten:
- Op driejarige leeftijd hebben kinderen het vermogen ontwikkeld om eenmalige leerlingen te zijn in verschillende domeinen. In minder dan 16,000 wakkere uren voorafgaand aan hun vierde verjaardag slagen ze erin om meer dan 1,000 objectcategorieën te leren, de syntaxis van hun moedertaal onder de knie te krijgen en de culturele en sociale nuances van hun omgeving in zich op te nemen.
- Dr. Linda Smith en haar team ontdekten drie principes van menselijk leren waardoor kinderen zoveel uit zulke schaarse gegevens kunnen halen:
- De leerlingen controleren de input, van moment tot moment geven zij vorm en structureren zij de input. Tijdens de eerste paar maanden van hun leven hebben baby’s bijvoorbeeld de neiging om meer naar voorwerpen met eenvoudige randen te kijken.
- Omdat baby's voortdurend evolueren in hun kennis en capaciteiten, volgen ze een zeer beperkt leerplan. De gegevens waaraan zij worden blootgesteld, zijn op zeer significante manieren georganiseerd. Baby's jonger dan 4 maanden besteden bijvoorbeeld de meeste tijd aan het kijken naar gezichten, ongeveer 15 minuten per uur, terwijl baby's ouder dan 12 maanden zich voornamelijk op de handen concentreren en deze ongeveer 20 minuten per uur observeren.
- Leerepisodes bestaan uit een reeks onderling verbonden ervaringen. Ruimtelijke en temporele correlaties creëren samenhang, wat op zijn beurt de vorming van blijvende herinneringen aan eenmalige gebeurtenissen vergemakkelijkt. Wanneer kinderen bijvoorbeeld een willekeurig assortiment speelgoed aangeboden krijgen, concentreren ze zich vaak op een paar ‘favoriete’ speelgoedjes. Ze gaan met dit speelgoed aan de slag met behulp van repetitieve patronen, wat helpt bij het sneller leren van de objecten.
- Voorbijgaande (werk)herinneringen blijven langer bestaan dan de zintuiglijke input. Eigenschappen die het leerproces verbeteren zijn onder meer multimodaliteit, associaties, voorspellende relaties en activering van herinneringen uit het verleden.
- Voor snel leren heb je een alliantie nodig tussen de mechanismen die de gegevens genereren en de mechanismen die leren.
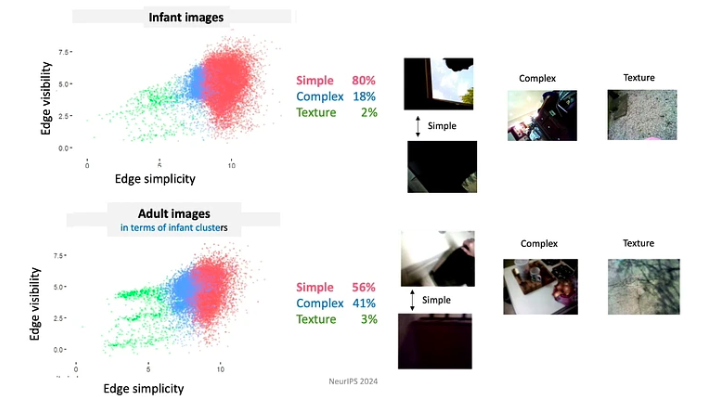
Schetsen: kernhulpmiddelen, leerverbetering en adaptieve robuustheid
Jelani Nelson, hoogleraar elektrotechniek en computerwetenschappen aan UC Berkeley, introduceerde het concept van data-schetsen – een geheugengecomprimeerde representatie van een dataset die nog steeds het beantwoorden van nuttige vragen mogelijk maakt. Hoewel de lezing behoorlijk technisch was, gaf deze een uitstekend overzicht van enkele fundamentele tekenhulpmiddelen, inclusief recente ontwikkelingen.
Belangrijkste afhaalrestaurants:
- CountSketch, de belangrijkste schetstool, werd voor het eerst geïntroduceerd in 2002 om het probleem van ‘heavy hitters’ aan te pakken, waarbij een kleine lijst werd gerapporteerd met de meest voorkomende items uit de gegeven stroom items. CountSketch was het eerste bekende sublineaire algoritme dat voor dit doel werd gebruikt.
- Twee niet-streamingtoepassingen van zware hitters zijn onder meer:
- Interior point-based method (IPM) die een asymptotisch snelste bekende algoritme voor lineaire programmering oplevert.
- HyperAttention-methode die de computationele uitdaging aanpakt die ontstaat door de groeiende complexiteit van lange contexten die in LLM's worden gebruikt.
- Veel recent werk is gericht op het ontwerpen van schetsen die robuust zijn voor adaptieve interactie. Het belangrijkste idee is om inzichten uit adaptieve data-analyse te gebruiken.
Voorbij het schaalpaneel
Deze geweldig panel over grote taalmodellen werd gemodereerd door Alexander Rush, universitair hoofddocent bij Cornell Tech en onderzoeker bij Hugging Face. Tot de andere deelnemers behoorden:
- Aakanksha Chowdhery – Onderzoekswetenschapper bij Google DeepMind met onderzoeksinteresses in systemen, LLM-vooropleiding en multimodaliteit. Ze maakte deel uit van het team dat PaLM, Gemini en Pathways ontwikkelde.
- Angela Fan – Onderzoekswetenschapper bij Meta Generative AI met onderzoeksinteresses op het gebied van afstemming, datacenters en meertaligheid. Ze nam deel aan de ontwikkeling van Llama-2 en Meta AI Assistant.
- Percy Liang – Professor aan Stanford die onderzoek doet naar makers, open source en generatieve agenten. Hij is directeur van het Center for Research on Foundation Models (CRFM) op Stanford en de oprichter van Together AI.
De discussie concentreerde zich op vier belangrijke onderwerpen: (1) architecturen en engineering, (2) data en afstemming, (3) evaluatie en transparantie, en (4) makers en bijdragers.
Hier volgen enkele conclusies uit dit panel:
- Het trainen van huidige taalmodellen is niet inherent moeilijk. De belangrijkste uitdaging bij het trainen van een model als Llama-2-7b ligt in de infrastructuurvereisten en de noodzaak om te coördineren tussen meerdere GPU's, datacenters, enz. Als het aantal parameters echter klein genoeg is om training op een enkele GPU mogelijk te maken, zelfs een student kan het beheren.
- Hoewel autoregressieve modellen meestal worden gebruikt voor het genereren van tekst en verspreidingsmodellen voor het genereren van afbeeldingen en video's, zijn er experimenten geweest met het omkeren van deze benaderingen. Concreet wordt in het Gemini-project een autoregressief model gebruikt voor het genereren van afbeeldingen. Er zijn ook verkenningen gedaan naar het gebruik van verspreidingsmodellen voor het genereren van tekst, maar deze zijn nog niet voldoende effectief gebleken.
- Gezien de beperkte beschikbaarheid van Engelstalige gegevens voor trainingsmodellen onderzoeken onderzoekers alternatieve benaderingen. Eén mogelijkheid is het trainen van multimodale modellen op een combinatie van tekst, video, afbeeldingen en audio, met de verwachting dat de vaardigheden die uit deze alternatieve modaliteiten worden geleerd, kunnen worden overgedragen naar tekst. Een andere optie is het gebruik van synthetische data. Het is belangrijk op te merken dat synthetische data vaak overgaan in echte data, maar deze integratie is niet willekeurig. Online gepubliceerde tekst wordt doorgaans door mensen beheerd en bewerkt, wat extra waarde kan toevoegen aan modeltraining.
- Open foundation-modellen worden vaak gezien als gunstig voor innovatie, maar potentieel schadelijk voor de veiligheid van AI, omdat ze kunnen worden uitgebuit door kwaadwillende actoren. Dr. Percy Liang stelt echter dat open modellen ook positief bijdragen aan de veiligheid. Hij stelt dat ze, door toegankelijk te zijn, meer onderzoekers de mogelijkheid bieden om AI-veiligheidsonderzoek uit te voeren en de modellen te beoordelen op mogelijke kwetsbaarheden.
- Tegenwoordig vereist het annoteren van gegevens aanzienlijk meer expertise op het annotatiedomein vergeleken met vijf jaar geleden. Als AI-assistenten in de toekomst echter presteren zoals verwacht, zullen we waardevollere feedbackgegevens van gebruikers ontvangen, waardoor de afhankelijkheid van uitgebreide gegevens van annotators afneemt.
Systemen voor funderingsmodellen en funderingsmodellen voor systemen
In dit gesprekChristopher Ré, universitair hoofddocent bij de afdeling Computerwetenschappen van Stanford University, laat zien hoe basismodellen de systemen die we bouwen hebben veranderd. Hij onderzoekt ook hoe efficiënt funderingsmodellen kunnen worden gebouwd, waarbij hij inzichten ontleent aan onderzoek naar databasesystemen, en bespreekt potentieel efficiëntere architecturen voor funderingsmodellen dan de Transformer.
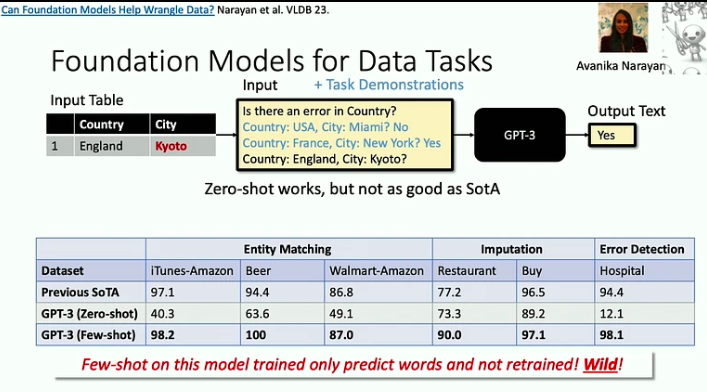
Dit zijn de belangrijkste conclusies uit deze lezing:
- Fundamentele modellen zijn effectief bij het aanpakken van ‘dood door 1000 bezuinigingen’-problemen, waarbij elke individuele taak relatief eenvoudig kan zijn, maar de enorme omvang en verscheidenheid van taken een aanzienlijke uitdaging vormen. Een goed voorbeeld hiervan is het probleem van het opschonen van gegevens, dat LLM's nu veel efficiënter kunnen helpen oplossen.
- Naarmate versnellers sneller worden, komt het geheugen vaak naar voren als een knelpunt. Dit is een probleem waar databaseonderzoekers zich al tientallen jaren mee bezig houden, en we kunnen een aantal van hun strategieën overnemen. De Flash Attention-aanpak minimaliseert bijvoorbeeld de input-outputstromen door middel van blokkering en agressieve fusie: telkens wanneer we toegang krijgen tot een stukje informatie, voeren we er zoveel mogelijk bewerkingen op uit.
- Er is een nieuwe klasse architecturen, geworteld in signaalverwerking, die efficiënter zou kunnen zijn dan het Transformer-model, vooral bij het verwerken van lange reeksen. Signaalverwerking biedt stabiliteit en efficiëntie en legt de basis voor innovatieve modellen zoals de S4.
Online versterkend leren bij digitale gezondheidszorginterventies
In haar praatjeSusan Murphy, hoogleraar statistiek en computerwetenschappen aan de Harvard University, deelde de eerste oplossingen voor enkele van de uitdagingen waarmee zij worden geconfronteerd bij het ontwikkelen van online RL-algoritmen voor gebruik bij digitale gezondheidszorginterventies.
Hier zijn enkele conclusies uit de presentatie:
- Dr. Susan Murphy besprak twee projecten waaraan ze heeft gewerkt:
- HeartStep, waar activiteiten zijn voorgesteld op basis van gegevens van smartphones en draagbare trackers, en
- Oralytics voor coaching op het gebied van mondgezondheid, waarbij interventies waren gebaseerd op betrokkenheidsgegevens ontvangen van een elektronische tandenborstel.
- Bij het ontwikkelen van een gedragsbeleid voor een AI-agent moeten onderzoekers ervoor zorgen dat deze autonoom is en haalbaar kan worden geïmplementeerd in het bredere gezondheidszorgsysteem. Dit houdt in dat ervoor moet worden gezorgd dat de tijd die nodig is voor de betrokkenheid van een individu redelijk is, en dat de aanbevolen acties zowel ethisch verantwoord als wetenschappelijk plausibel zijn.
- De belangrijkste uitdagingen bij het ontwikkelen van een RL-agent voor digitale gezondheidszorginterventies zijn onder meer het omgaan met hoge geluidsniveaus, aangezien mensen hun leven leiden en mogelijk niet altijd op berichten kunnen reageren, zelfs als ze dat willen, en het omgaan met sterke, vertraagde negatieve effecten. .
Zoals u kunt zien heeft NeurIPS 2023 een verhelderend kijkje gegeven in de toekomst van AI. De uitgenodigde lezingen benadrukten een trend naar efficiëntere, hulpbronnenbewuste modellen en de verkenning van nieuwe architecturen die verder gaan dan traditionele paradigma's.
Geniet van dit artikel? Meld u aan voor meer AI-onderzoeksupdates.
We laten het u weten wanneer we meer samenvattende artikelen zoals deze vrijgeven.
Verwant
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.topbots.com/neurips-2023-invited-talks/

