
Afbeelding door Freepik
Natural Language Processing, of NLP, is een veld binnen de kunstmatige intelligentie waarmee machines tekstuele gegevens kunnen begrijpen. NLP-onderzoek bestaat al heel lang, maar is pas onlangs prominenter geworden door de introductie van big data en hogere rekenkracht.
Nu het NLP-veld groter wordt, zullen veel onderzoekers proberen het vermogen van de machine om de tekstuele gegevens beter te begrijpen te verbeteren. Door de grote vooruitgang zijn er veel technieken voorgesteld en toegepast op NLP-gebied.
Dit artikel vergelijkt verschillende technieken voor het verwerken van tekstgegevens op NLP-gebied. Dit artikel zal zich richten op het bespreken van RNN, Transformers en BERT, omdat dit degene is die vaak in onderzoek wordt gebruikt. Laten we erop ingaan.
Terugkerend neuraal netwerk of RNN werd in 1980 ontwikkeld, maar kreeg pas recentelijk aantrekkingskracht op NLP-gebied. RNN is een bepaald type binnen de neurale netwerkfamilie dat wordt gebruikt voor sequentiële gegevens of gegevens die niet onafhankelijk van elkaar kunnen zijn. Voorbeelden van sequentiële gegevens zijn tijdreeks-, audio- of tekstzingegevens, eigenlijk elk soort gegevens met een betekenisvolle volgorde.
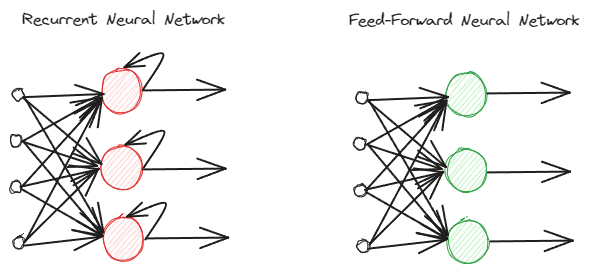
RNN's verschillen van reguliere feed-forward neurale netwerken omdat ze informatie anders verwerken. Bij de normale feed-forward wordt de informatie volgens de lagen verwerkt. RNN gebruikt echter een luscyclus op de informatie-invoer als overweging. Laten we de onderstaande afbeelding bekijken om de verschillen te begrijpen.
Afbeelding door auteur
Zoals u kunt zien, implementeert het RNNs-model een luscyclus tijdens de informatieverwerking. RNN's zouden bij het verwerken van deze informatie rekening houden met de huidige en eerdere gegevensinvoer. Daarom is het model geschikt voor elk type sequentiële data.
Als we een voorbeeld nemen in de tekstgegevens, stel je dan voor dat we de zin 'Ik word om 7 uur' s ochtends wakker, en dat we het woord als invoer hebben. Als we in het feed-forward neurale netwerk het woord ‘omhoog’ bereiken, vergeet het model de woorden ‘ik’, ‘wakker’ en ‘omhoog’ al. RNN's zouden echter elke uitvoer voor elk woord gebruiken en deze teruglussen, zodat het model het niet zou vergeten.
Op NLP-gebied worden RNN's vaak gebruikt in veel tekstuele toepassingen, zoals tekstclassificatie en -generatie. Het wordt vaak gebruikt in toepassingen op woordniveau, zoals het taggen van deel van spraak, het genereren van volgende woorden, enz.
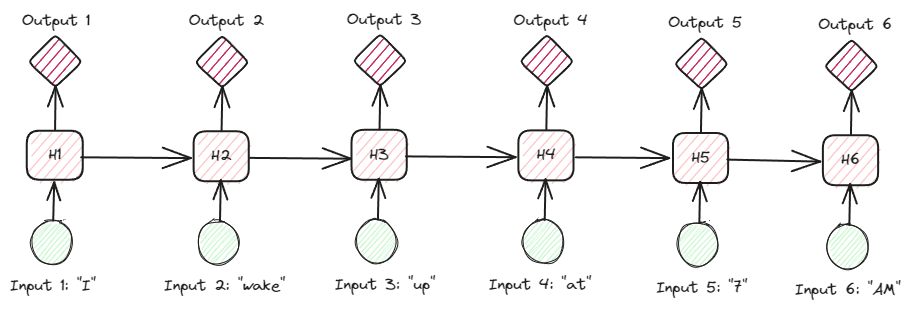
Als we dieper ingaan op de tekstuele gegevens van de RNN's, zijn er veel soorten RNN's. De onderstaande afbeelding is bijvoorbeeld het veel-op-veel-type.
Afbeelding door auteur
Als we naar de afbeelding hierboven kijken, kunnen we zien dat de uitvoer voor elke stap (tijdstap in RNN) stap voor stap wordt verwerkt, en dat bij elke iteratie altijd rekening wordt gehouden met de voorgaande informatie.
Een ander RNN-type dat in veel NLP-toepassingen wordt gebruikt, is het encoder-decoder-type (Sequence-to-Sequence). De structuur wordt weergegeven in de onderstaande afbeelding.
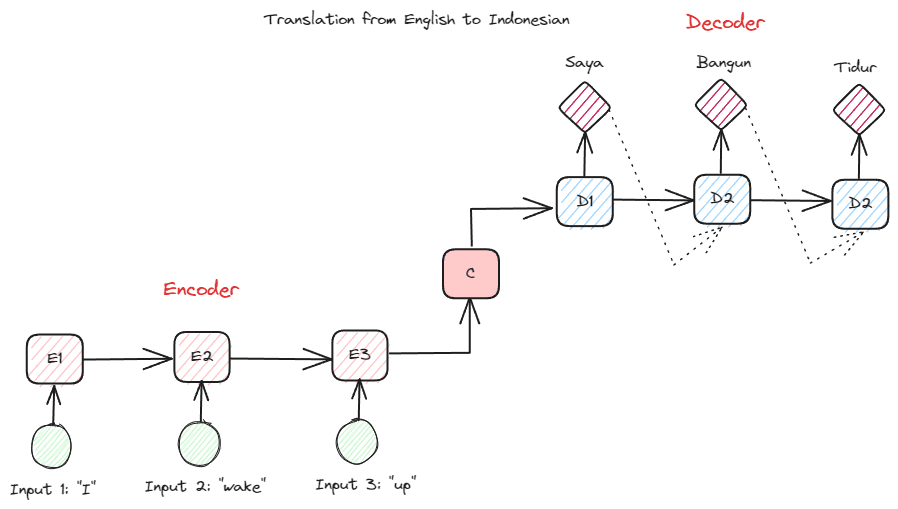
Afbeelding door auteur
Deze structuur introduceert twee delen die in het model worden gebruikt. Het eerste deel heet Encoder, een onderdeel dat gegevensreeksen ontvangt en op basis daarvan een nieuwe representatie creëert. De representatie zou worden gebruikt in het tweede deel van het model, namelijk de decoder. Met deze structuur hoeven de invoer- en uitvoerlengtes niet noodzakelijkerwijs gelijk te zijn. Het voorbeeldgebruik is een taalvertaling, die vaak niet dezelfde lengte heeft tussen de invoer en de uitvoer.
Er zijn verschillende voordelen verbonden aan het gebruik van RNN's om natuurlijke taalgegevens te verwerken, waaronder:
- RNN kan worden gebruikt om tekstinvoer te verwerken zonder lengtebeperkingen.
- Het model deelt dezelfde gewichten voor alle tijdstappen, waardoor het neurale netwerk in elke stap dezelfde parameter kan gebruiken.
- Het hebben van het geheugen van eerdere invoer maakt RNN geschikt voor alle sequentiële gegevens.
Maar er zijn ook verschillende nadelen:
- RNN is gevoelig voor zowel verdwijnende als exploderende gradiënten. Dit is waar het gradiëntresultaat de waarde bijna nul heeft (verdwijnend), waardoor het netwerkgewicht slechts voor een klein bedrag wordt bijgewerkt, of het gradiëntresultaat zo significant is (exploderend) dat het een onrealistisch enorm belang aan het netwerk toekent.
- Lange trainingstijd vanwege het sequentiële karakter van het model.
- Kortetermijngeheugen betekent dat het model begint te vergeten naarmate het model langer wordt getraind. Er is een extensie van RNN genaamd LSTM om dit probleem te verlichten.
Transformers is een NLP-modelarchitectuur die de reeks-tot-reeks-taken probeert op te lossen die eerder in de RNN's werden aangetroffen. Zoals hierboven vermeld, hebben RNN's problemen met het kortetermijngeheugen. Hoe langer de invoer, hoe prominenter het model was in het vergeten van de informatie. Dit is waar het aandachtsmechanisme het probleem zou kunnen helpen oplossen.
Het aandachtsmechanisme wordt in het artikel geïntroduceerd door Bahdanau c.s.. (2014) om het lange invoerprobleem op te lossen, vooral bij RNN's van het encoder-decoder-type. Ik zou het aandachtsmechanisme niet in detail uitleggen. Kortom, het is een laag waarmee het model zich kan concentreren op het kritische deel van de modelinvoer terwijl de uitvoervoorspelling wordt gedaan. De woordinvoer 'Klok' zou bijvoorbeeld sterk correleren met 'Jam' in het Indonesisch als de taak voor vertaling is.
Het transformatorenmodel wordt geïntroduceerd door Vaswani et al. (2017). De architectuur is geïnspireerd op de encoder-decoder RNN en gebouwd met het aandachtsmechanisme in gedachten en verwerkt gegevens niet in opeenvolgende volgorde. Het algemene transformatormodel is gestructureerd zoals in de onderstaande afbeelding.
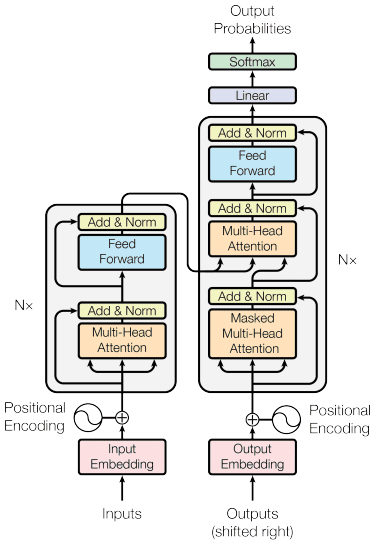
Transformers-architectuur (Vaswani c.s.. 2017)
In de bovenstaande structuur coderen de transformatoren de datavectorreeks in de woordinbedding met positionele codering terwijl de decodering wordt gebruikt om gegevens naar de oorspronkelijke vorm te transformeren. Als het aandachtsmechanisme aanwezig is, kan de codering afhankelijk van de invoer belang krijgen.
Transformers bieden weinig voordelen ten opzichte van het andere model, waaronder:
- Het parallellisatieproces verhoogt de training- en gevolgtrekkingssnelheid.
- Kan langere input verwerken, wat een beter begrip van de context biedt
Er zijn nog steeds enkele nadelen aan het transformatormodel:
- Hoge computationele verwerking en vraag.
- Het aandachtsmechanisme vereist mogelijk dat de tekst wordt gesplitst vanwege de maximale lengte die deze kan verwerken.
- De context kan verloren gaan als de splitsing verkeerd wordt uitgevoerd.
BERT
BERT, of Bidirectionele Encoder Representations from Transformers, is een model ontwikkeld door Devlin et al. (2019) dat omvat twee stappen (vooropleiding en afstemming) om het model te maken. Als we het vergelijken, is BERT een stapel transformatoren-encoder (BERT Base heeft 12 lagen terwijl BERT Large 24 lagen heeft).
De algemene modelontwikkeling van BERT kan worden weergegeven in de onderstaande afbeelding.
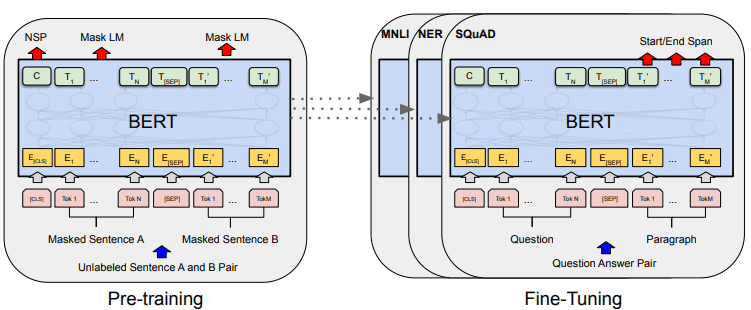
BERT algemene procedures (Devlin et al. (2019)
Taken vóór de training initiëren tegelijkertijd de training van het model, en zodra deze is voltooid, kan het model worden verfijnd voor verschillende vervolgtaken (vragen beantwoorden, classificatie, enz.).
Wat BERT speciaal maakt, is dat het het eerste bidirectionele taalmodel zonder toezicht is dat vooraf is getraind op tekstgegevens. BERT was eerder getraind in het volledige Wikipedia- en boekencorpus, bestaande uit meer dan 3000 miljoen woorden.
BERT wordt als bidirectioneel beschouwd omdat het de gegevensinvoer niet opeenvolgend leest (van links naar rechts of omgekeerd), maar de transformator-encoder de hele reeks tegelijkertijd leest.
In tegenstelling tot directionele modellen, die de tekstinvoer opeenvolgend lezen (van links naar rechts of van rechts naar links), leest de Transformer-encoder de volledige reeks woorden tegelijkertijd. Daarom wordt het model als bidirectioneel beschouwd en kan het model de hele context van de invoergegevens begrijpen.
Om bidirectioneel te bereiken, gebruikt BERT twee technieken:
- Maskertaalmodel (MLM) — Woordmaskeringstechniek. De techniek maskeert 15% van de ingevoerde woorden en probeert dit gemaskeerde woord te voorspellen op basis van het niet-gemaskeerde woord.
- Voorspelling van volgende zin (NSP) — BERT probeert de relatie tussen zinnen te leren. Het model heeft zinnenparen als gegevensinvoer en probeert te voorspellen of de volgende zin in het originele document voorkomt.
Er zijn een paar voordelen aan het gebruik van BERT op NLP-gebied, waaronder:
- BERT is eenvoudig te gebruiken voor vooraf getrainde verschillende NLP-downstream-taken.
- Bidirectioneel zorgt ervoor dat BERT de tekstcontext beter begrijpt.
- Het is een populair model dat veel steun krijgt van de gemeenschap
Hoewel er nog steeds een paar nadelen zijn, waaronder:
- Vereist een hoge rekenkracht en een lange trainingstijd voor het verfijnen van sommige downstream-taken.
- Het BERT-model zou ertoe kunnen leiden dat een groot model een veel grotere opslagcapaciteit vereist.
- Het is beter om het voor complexe taken te gebruiken, omdat de prestaties voor eenvoudige taken niet veel anders zijn dan bij het gebruik van eenvoudigere modellen.
NLP is de laatste tijd prominenter geworden en veel onderzoek is gericht op het verbeteren van de toepassingen. In dit artikel bespreken we drie NLP-technieken die vaak worden gebruikt:
- RNN
- transformers
- BERT
Elk van de technieken heeft zijn voor- en nadelen, maar over het algemeen kunnen we zien dat het model zich op een betere manier ontwikkelt.
Cornellius Yudha Wijaya is een data science assistent-manager en dataschrijver. Terwijl hij fulltime bij Allianz Indonesia werkt, deelt hij graag Python- en Data-tips via sociale media en schrijvende media.
Cornellius Yudha Wijaya is een data science assistent-manager en dataschrijver. Terwijl hij fulltime bij Allianz Indonesia werkt, deelt hij graag Python- en Data-tips via sociale media en schrijvende media.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.kdnuggets.com/comparing-natural-language-processing-techniques-rnns-transformers-bert?utm_source=rss&utm_medium=rss&utm_campaign=comparing-natural-language-processing-techniques-rnns-transformers-bert

