Dit bericht is geschreven in samenwerking met Ramesh Daddala, Jitendra Kumar Dash en Pavan Kumar Bijja van Bristol Myers Squibb.
Bristol Myers Squibb (BMS) is een mondiaal biofarmaceutisch bedrijf met als missie het ontdekken, ontwikkelen en leveren van innovatieve medicijnen die patiënten helpen de overhand te krijgen op ernstige ziekten. BMS innoveert voortdurend en boekt aanzienlijke klinische en regelgevende successen. In samenwerking met AWS identificeerde BMS een zakelijke behoefte om hun aangepaste extractie-, transformatie- en laadplatform (ETL) te migreren en te moderniseren naar een native AWS-oplossing om de complexiteit, middelen en investeringen te verminderen om te upgraden wanneer er nieuwe Spark-, Python- of nieuwe versies beschikbaar zijn. AWS lijm versies worden uitgebracht. Naast het gebruik van native beheerde AWS-services waarover BMS zich geen zorgen hoefde te maken over het upgraden, wilde BMS een ETL-service aanbieden aan niet-technische zakelijke gebruikers die visueel datatransformatieworkflows konden samenstellen en deze naadloos konden uitvoeren op de AWS Glue Apache Spark -gebaseerde serverloze data-integratie-engine. AWS Lijm Studio is een grafische interface waarmee u eenvoudig ETL-taken in AWS Glue kunt maken, uitvoeren en monitoren. Het aanbieden van deze service verminderde het operationele onderhoud en de kosten van BMS en bood zakelijke gebruikers flexibiliteit om ETL-taken gemakkelijk uit te voeren.
De afgelopen vijf jaar heeft BMS een aangepast raamwerk met de naam Enterprise Data Lake Services (EDLS) gebruikt om ETL-taken voor zakelijke gebruikers te creëren. Hoewel dit raamwerk aan hun ETL-doelstellingen voldeed, was het moeilijk te onderhouden en te upgraden. Het EDLS-platform van BMS biedt plaats aan meer dan 5 banen en groeit met 5,000% op jaarbasis (jaar na jaar). Elke keer dat de nieuwere versie van Apache Spark (en de bijbehorende AWS Glue-versie) werd uitgebracht, was er aanzienlijke operationele ondersteuning en tijdrovende handmatige wijzigingen nodig om bestaande ETL-taken te upgraden. Het handmatig upgraden, testen en implementeren van meer dan 15 banen om de paar kwartalen was tijdrovend, foutgevoelig, kostbaar en niet duurzaam. Omdat een nieuwe release voor het EDLS-framework in behandeling was, besloot BMS alternatieve beheerde oplossingen te beoordelen om de operationele en upgrade-uitdagingen te verminderen.
In dit bericht delen we hoe BMS zal moderniseren door gebruik te maken van het succes van de proof of concept gericht op het ETL-platform van BMS met behulp van AWS Glue Studio.
Overzicht oplossingen
Deze oplossing komt tegemoet aan de EDLS-vereisten van BMS om uitdagingen te overwinnen met behulp van een op maat gebouwd ETL-framework dat regelmatig onderhoud en componentupgrades vereiste (waarvoor uitgebreide testcycli nodig waren), complexiteit vermijdt en de totale kosten van de onderliggende infrastructuur, afgeleid van de proof of concept, verlaagt. BMS had de volgende doelstellingen:
- Ontwikkel ETL-taken met behulp van visuele workflows van de AWS Lijm Studio visuele redacteur. De visuele editor van AWS Glue Studio is een low-code-omgeving waarmee u workflows voor gegevenstransformatie kunt samenstellen, deze naadloos kunt uitvoeren op de op AWS Glue Apache Spark gebaseerde serverloze gegevensintegratie-engine en het schema en de gegevensresultaten bij elke stap van de taak kunt inspecteren. .
- Migreer meer dan 5,000 bestaande ETL-taken met behulp van native AWS Glue Studio op een geautomatiseerde en schaalbare manier.
EDLS-taakstappen en metagegevens
Elke EDLS-taak bestaat uit een of meer taakstappen die aan elkaar zijn gekoppeld en in een vooraf gedefinieerde volgorde worden uitgevoerd, georkestreerd door het aangepaste ETL-framework. Elke taakstap omvat de volgende ETL-functies:
- Bestandsopname – Met bestandsopname kunt u bestanden uit meerdere bestandsbronnen opnemen of weergeven, zoals Amazon eenvoudige opslagservice (Amazon S3), SFTP en meer. De metagegevens bevatten configuraties voor de stap van het opnemen van bestanden om verbinding te maken met Amazon S3- of SFTP-eindpunten en bestanden op te nemen naar de doellocatie. Het haalt de opgegeven bestanden en beschikbare metagegevens op om in de gebruikersinterface weer te geven.
- Controle van de gegevenskwaliteit – Met de datakwaliteitsmodule kunt u kwaliteitscontroles uitvoeren op een grote hoeveelheid gegevens en rapporten genereren die de gegevenskwaliteit beschrijven en valideren. De stap voor gegevenskwaliteit maakt gebruik van een door EDLS opgenomen bronobject van Amazon S3 en voert één op veel gegevensconformiteitscontroles uit die door de tenant zijn geconfigureerd.
- Deelname aan gegevenstransformatie – Dit is een van de submodules van de datatransformatiemodule die joins tussen de datasets kan uitvoeren met behulp van een aangepaste SQL op basis van de metadataconfiguratie.
- Database-opname – De database-opnamestap is een van de belangrijke servicecomponenten in EDLS, waarmee u de gewenste gegevens uit de database kunt verkrijgen, importeren en exporteren naar een specifiek bestand op de locatie van uw keuze.
- Gegevenstransformatie – De datatransformatiemodule voert verschillende datatransformaties uit op de brongegevens met behulp van JSON-gestuurde regels. Elke mogelijkheid voor gegevenstransformatie heeft zijn eigen JSON-regel en op basis van de specifieke JSON-regel die u opgeeft, voert EDLS de gegevenstransformatie uit op de bestanden die beschikbaar zijn op de Amazon S3-locatie.
- Data persistentie – De datapersistentiemodule is een van de belangrijke servicecomponenten in EDLS, waarmee u de gewenste gegevens uit de bron kunt halen en deze op een Amazon relationele databaseservice (Amazon RDS)-database.
De metagegevens die overeenkomen met elke taakstap omvatten opnamebronnen, transformatieregels, gegevenskwaliteitscontroles en gegevensbestemmingen die zijn opgeslagen in een RDS-instantie.
Hulpprogramma voor migratie
De oplossing omvat het bouwen van een Python-hulpprogramma dat EDLS-metagegevens uit de RDS-database leest en elk van de taakstappen vertaalt naar een gelijkwaardige AWS Glue Studio visuele editor JSON-knooppuntrepresentatie.
AWS Glue Studio biedt twee soorten transformaties:
- AWS Glue-native transformaties – Deze zijn beschikbaar voor alle gebruikers en worden beheerd door AWS Glue.
- Aangepaste visuele transformaties – Met deze nieuwe functionaliteit kunt u op maat gemaakte transformaties uploaden die worden gebruikt in AWS Glue Studio. Aangepaste visuele transformaties breiden de beheerde transformaties uit, waardoor u transformaties kunt zoeken en gebruiken vanuit de AWS Glue Studio-interface.
Het volgende is een diagram op hoog niveau dat de volgorde weergeeft van het migreren van een BMS EDLS-taak naar een visuele editortaak van AWS Glue Studio.

Het migreren van BMS EDLS-taken naar AWS Glue Studio omvat de volgende stappen:
- Het Python-hulpprogramma leest bestaande metagegevens uit de EDLS-metagegevensdatabase.
- Voor elk taakstaptype selecteert het Python-hulpprogramma, op basis van de taakmetagegevens, de native AWS Glue-transformatie, indien beschikbaar, of een op maat gemaakte visuele transformatie (wanneer de native functionaliteit ontbreekt).
- Het Python-hulpprogramma parseert de afhankelijkheidsinformatie uit metagegevens en bouwt een JSON-object dat een visuele workflow vertegenwoordigt, weergegeven als een Directed Acyclic Graph (DAG).
- Het JSON-object wordt verzonden naar de AWS Glue-API, waarbij de AWS Glue ETL-taak wordt gemaakt. Deze taken worden visueel weergegeven in de visuele editor van AWS Glue Studio met behulp van een reeks bronnen, transformaties (native en aangepast) en doelen.
Voorbeeld van het genereren van ETL-taken met AWS Glue Studio
Het volgende stroomdiagram toont een voorbeeld van een ETL-taak die stapsgewijs de bron-RDBMS-gegevens in AWS Glue opneemt op basis van gewijzigde tijdstempels met behulp van een aangepaste SQL en deze samenvoegt met de doelgegevens op Amazon S3.
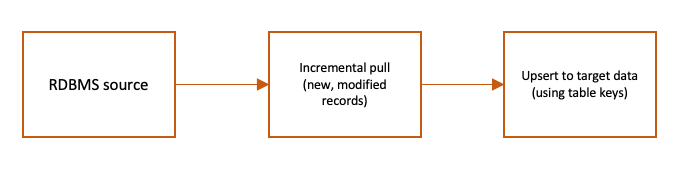
De voorgaande ETL-stroom kan worden weergegeven met behulp van de visuele editor van AWS Glue Studio door een combinatie van native en aangepaste visuele transformaties.
Aangepaste visuele transformatie voor incrementele opname
Post POC, BMS en AWS hebben vastgesteld dat er behoefte zal zijn aan aangepaste transformaties om een subset van taken uit te voeren met behulp van hun huidige EDLS-service, waarbij de Glue Studio-functionaliteit niet vanzelfsprekend zal zijn. De eis van het BMS-team was om gegevens uit verschillende databases op te nemen zonder afhankelijk te zijn van het bestaan van transactielogboeken of een specifiek schema. AWS-databasemigratieservice (AWS DMS) was voor hen geen optie. AWS Glue Studio biedt de native visuele transformatie van SQL-query's, waarbij een aangepaste SQL-query kan worden gebruikt om de brongegevens te transformeren. Als u echter de brondatabasetabel wilt bevragen op basis van een gewijzigde tijdstempelkolom om nieuwe en gewijzigde records op te halen sinds de laatste ETL-run, moet de status van de vorige tijdstempelkolom behouden blijven, zodat deze kan worden gebruikt in de huidige ETL-run. Dit moet een terugkerend proces zijn en kan ook worden geabstraheerd over verschillende RDBMS-bronnen, waaronder Oracle, MySQL, Microsoft SQL Server, SAP Hana en meer.
AWS Glue biedt een taakbladwijzerfunctie om de gegevens bij te houden die al zijn verwerkt tijdens een eerdere ETL-run. Een AWS Glue-taakbladwijzer ondersteunt een of meer kolommen als bladwijzersleutels om nieuwe en verwerkte gegevens te bepalen, en vereist dat de sleutels opeenvolgend toenemen of afnemen zonder gaten. Hoewel dit voor veel gevallen van incrementeel laden werkt, is het de vereiste om gegevens uit verschillende bronnen op te nemen zonder afhankelijk te zijn van een specifiek schema. Daarom hebben we in dit geval geen AWS Glue-taakbladwijzer gebruikt.
De op SQL gebaseerde incrementele opname-pull kan op een generieke manier worden ontwikkeld met behulp van een aangepaste visuele transformatie met behulp van een voorbeeld van een incrementele opnametaak uit een MySQL-database. De incrementele gegevens worden samengevoegd met de doel-Amazon S3-locatie in Apache Hudi-indeling met behulp van een upsert-schrijfbewerking.
In het volgende voorbeeld gebruiken we het MySQL-gegevensbronknooppunt om de verbinding te definiëren, maar het DynamicFrame van de gegevensbron zelf wordt niet gebruikt. Het aangepaste transformatieknooppunt (incrementele database-opname) fungeert als bron voor het stapsgewijs lezen van de gegevens met behulp van de aangepaste SQL-query en de eerder bewaarde tijdstempel van de laatste opname.
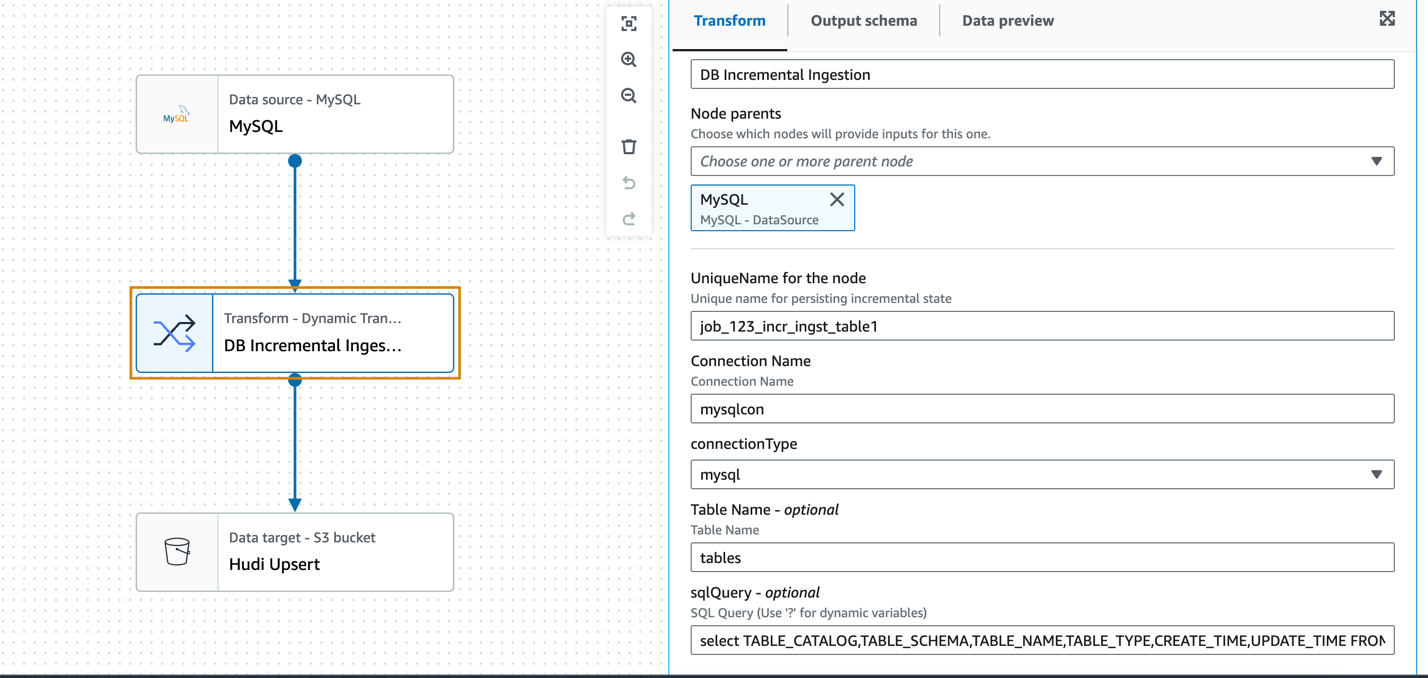
De transformatie accepteert als invoerparameters de vooraf geconfigureerde AWS Glue-verbindingsnaam, het databasetype, de tabelnaam en de aangepaste SQL (geparametriseerd tijdstempelveld).
Hier volgt een voorbeeld van een visuele transformatie-Python-code:
Om de brongegevens samen te voegen met het Amazon S3-doel kan een data lake-framework zoals Apache Hudi of Apache Iceberg worden gebruikt, dat standaard wordt ondersteund in AWS Glue 3.0 en hoger.
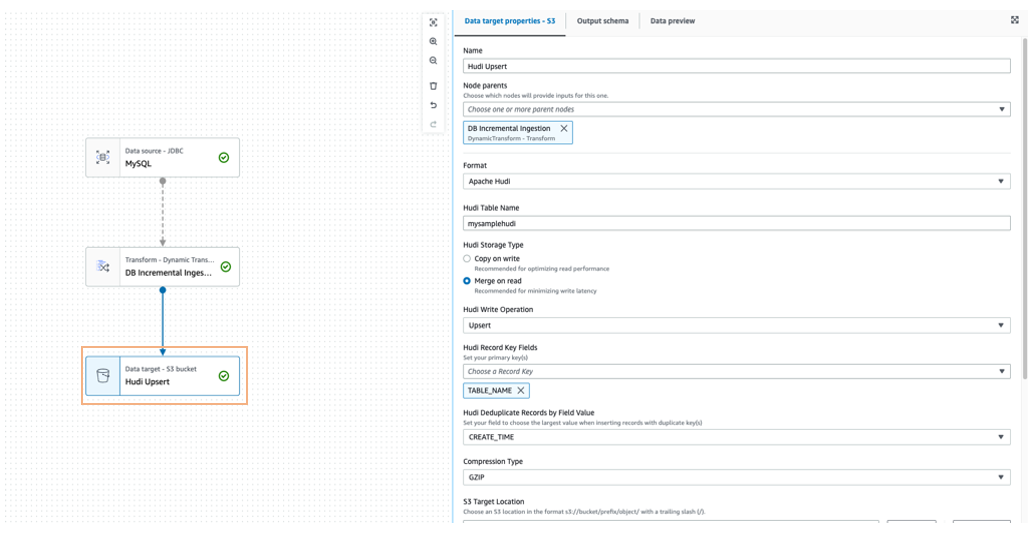
U kunt ook gebruik maken van Amazon EventBridge om de laatste wijziging in de AWS Glue-taakstatus te detecteren en de update bij te werken Amazon DynamoDB overeenkomstig de laatst opgenomen tijdstempel van de tabel.
Bouw de AWS Glue Studio-taak met behulp van de AWS SDK voor Python (Boto3) en AWS Glue API
Voor de voorbeeld-ETL-stroom en de bijbehorende AWS Glue Studio ETL-taak lieten we eerder de onderliggende zien CodeGenConfigurationNode struct (een AWS Glue-taakdefinitie getrokken met behulp van de AWS-opdrachtregelinterface (AWS CLI)-opdracht aws glue get-job –job-name <jobname>) wordt weergegeven als een JSON-object, weergegeven in de volgende code:
Het JSON-object (ETL-taak DAG) dat wordt weergegeven in het CodeGenConfigurationNode wordt gegenereerd via een reeks native en aangepaste transformaties met de respectieve invoerparameterarrays. Dit kan worden bereikt met behulp van Python JSON-encoders die de klasseobjecten serialiseren naar JSON en vervolgens de visuele editortaak van AWS Glue Studio creëren met behulp van de Boto3-bibliotheek en AWS Glue API.
De invoer die nodig is om de AWS Glue-transformaties te configureren, is afkomstig uit de metadatadatabase van EDLS-taken. Het Python-hulpprogramma leest de metadata-informatie, parseert deze en configureert de knooppunten automatisch.
De volgorde en volgorde van de knooppunten zijn afkomstig van de metagegevens van de EDLS-taken, waarbij één knooppunt de invoer wordt voor een of meer stroomafwaartse knooppunten die de DAG-stroom opbouwen.
Voordelen van de oplossing
Het migratiepad zal BMS helpen hun kerndoelstellingen te bereiken: het ontbinden van hun bestaande aangepaste ETL-framework tot modulaire, visueel configureerbare, minder complexe en gemakkelijk te beheren pijplijnen met behulp van visuele ETL-componenten. Het hulpprogramma helpt de migratie van de oudere ETL-pijplijnen naar native AWS Glue Studio-taken op een geautomatiseerde en schaalbare manier.
Met consistente out-of-the-box visuele ETL-transformaties in de AWS Glue Studio-interface kan BMS geavanceerde datapijplijnen bouwen zonder code te hoeven schrijven.
De aangepaste visuele transformaties zullen de mogelijkheden van AWS Glue Studio uitbreiden en voldoen aan enkele van de BMS ETL-vereisten waarbij de native transformaties die functionaliteit missen. Aangepaste transformaties helpen bij het definiëren, hergebruiken en delen van bedrijfsspecifieke ETL-logica tussen alle teams. De oplossing vergroot de consistentie tussen teams en houdt de ETL-pijplijnen up-to-date door dubbele inspanningen en code te minimaliseren.
Met kleine aanpassingen kan het migratiehulpprogramma opnieuw worden gebruikt om de migratie van pijpleidingen te automatiseren tijdens toekomstige AWS Glue-versie-upgrades.
Conclusie
Het succesvolle resultaat van deze proof of concept heeft aangetoond dat het migreren van meer dan 5,000 banen van de aangepaste applicatie van BMS naar native AWS-services aanzienlijke productiviteitswinsten en kostenbesparingen kan opleveren. Door over te stappen op AWS kan BMS de inspanningen verminderen die nodig zijn om AWS Glue te ondersteunen, de levering van DevOps verbeteren en naar schatting 58% besparen op AWS Glue-uitgaven.
Deze resultaten zijn veelbelovend en BMS is verheugd om aan de volgende fase van de migratie te beginnen. Wij geloven dat dit project een positieve impact zal hebben op de activiteiten van BMS en ons zal helpen onze strategische doelen te bereiken.
Over de auteurs
 Sivaprasad Mahamkali is een Senior Streaming Data Engineer bij AWS Professional Services. Siva leidt klantbetrokkenheid met betrekking tot realtime streamingoplossingen, datameren en analyses met behulp van opensource- en AWS-services. Siva luistert graag naar muziek en brengt graag tijd door met zijn gezin.
Sivaprasad Mahamkali is een Senior Streaming Data Engineer bij AWS Professional Services. Siva leidt klantbetrokkenheid met betrekking tot realtime streamingoplossingen, datameren en analyses met behulp van opensource- en AWS-services. Siva luistert graag naar muziek en brengt graag tijd door met zijn gezin.
 Dan Gibbar is Senior Engagement Manager bij AWS Professional Services. Dan geeft leiding aan projecten op het gebied van de gezondheidszorg en de biowetenschappen, waarbij hij samenwerkt met klanten en partners om resultaten te behalen. Dan houdt van het buitenleven, probeert triatlons, muziek en brengt tijd door met zijn gezin.
Dan Gibbar is Senior Engagement Manager bij AWS Professional Services. Dan geeft leiding aan projecten op het gebied van de gezondheidszorg en de biowetenschappen, waarbij hij samenwerkt met klanten en partners om resultaten te behalen. Dan houdt van het buitenleven, probeert triatlons, muziek en brengt tijd door met zijn gezin.
 Shrinath Parikh als Senior Cloud Data Architect bij AWS. Hij werkt met klanten over de hele wereld om hen te helpen met hun data-analyse, data lake, data lake house, serverless, governance en NoSQL-gebruiksscenario's. In de vrije tijd van Shrinath houdt hij van reizen, tijd doorbrengen met familie en nieuwe tools leren/bouwen met behulp van de allernieuwste technologieën.
Shrinath Parikh als Senior Cloud Data Architect bij AWS. Hij werkt met klanten over de hele wereld om hen te helpen met hun data-analyse, data lake, data lake house, serverless, governance en NoSQL-gebruiksscenario's. In de vrije tijd van Shrinath houdt hij van reizen, tijd doorbrengen met familie en nieuwe tools leren/bouwen met behulp van de allernieuwste technologieën.
 Ramesh Daddala is adjunct-directeur bij BMS. Ramesh leidt enterprise data engineering-opdrachten met betrekking tot enterprise data lake services (EDL's) en werkt samen met datapartners om enterprise data engineering en ML-mogelijkheden te leveren en te ondersteunen. Ramesh houdt van het buitenleven, reizen en brengt graag tijd door met zijn gezin.
Ramesh Daddala is adjunct-directeur bij BMS. Ramesh leidt enterprise data engineering-opdrachten met betrekking tot enterprise data lake services (EDL's) en werkt samen met datapartners om enterprise data engineering en ML-mogelijkheden te leveren en te ondersteunen. Ramesh houdt van het buitenleven, reizen en brengt graag tijd door met zijn gezin.
 Jitendra Kumar Dash is een Senior Cloud Architect bij BMS met expertise in hybride clouddiensten, Infrastructure Engineering, DevOps, Data Engineering en Data Analytics-oplossingen. Hij is gepassioneerd door eten, sport en avontuur.
Jitendra Kumar Dash is een Senior Cloud Architect bij BMS met expertise in hybride clouddiensten, Infrastructure Engineering, DevOps, Data Engineering en Data Analytics-oplossingen. Hij is gepassioneerd door eten, sport en avontuur.
 Pavan Kumar Bijja is senior data-ingenieur bij BMS. Pavan maakt data-engineering en analytische diensten mogelijk voor het BMS Commercial-domein met behulp van bedrijfsmogelijkheden. Pavan leidt de enterprise metadata-mogelijkheden bij BMS. Pavan brengt graag tijd door met zijn gezin en speelt badminton en cricket.
Pavan Kumar Bijja is senior data-ingenieur bij BMS. Pavan maakt data-engineering en analytische diensten mogelijk voor het BMS Commercial-domein met behulp van bedrijfsmogelijkheden. Pavan leidt de enterprise metadata-mogelijkheden bij BMS. Pavan brengt graag tijd door met zijn gezin en speelt badminton en cricket.
 Sjovan Kanjilal is een Senior Data Lake Architect die werkt met strategische accounts in AWS Professional Services. Shovan werkt samen met klanten om data- en machine learning-oplossingen op AWS te ontwerpen.
Sjovan Kanjilal is een Senior Data Lake Architect die werkt met strategische accounts in AWS Professional Services. Shovan werkt samen met klanten om data- en machine learning-oplossingen op AWS te ontwerpen.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/modernize-your-etl-platform-with-aws-glue-studio-a-case-study-from-bms/

