Gegevens zijn een integraal onderdeel geworden van de meeste bedrijven en de complexiteit van gegevensverwerking neemt snel toe met de exponentiële groei van de hoeveelheid en verscheidenheid aan gegevens. Data engineering teams staan voor de volgende uitdagingen:
- Gegevens manipuleren om ze bruikbaar te maken voor zakelijke gebruikers
- Het bouwen en verbeteren van extractie-, transformatie- en laadpijplijnen (ETL).
- Hun ETL-infrastructuur opschalen
Veel klanten die gegevens naar de cloud migreren, zoeken naar manieren om te moderniseren door native AWS-services te gebruiken om ETL-taken verder op te schalen en efficiënt af te handelen. In de vroege stadia van hun cloudtraject hebben klanten mogelijk begeleiding nodig bij het moderniseren van hun ETL-workload met minimale inspanning en tijd. Klanten gebruiken vaak veel SQL-scripts om de gegevens te selecteren en te transformeren in relationele databases die worden gehost in een on-premises omgeving of op AWS en gebruiken aangepaste workflows om hun ETL te beheren.
AWS lijm is een serverloze data-integratie en ETL-service met de mogelijkheid om on demand te schalen. In dit bericht laten we zien hoe u uw bestaande op SQL gebaseerde ETL-workload naar AWS Glue kunt migreren Spark-SQL, wat de refactoring-inspanning minimaliseert.
Overzicht oplossingen
Het volgende diagram beschrijft de architectuur op hoog niveau voor onze oplossing. Deze oplossing ontkoppelt de ETL- en analyseworkloads van onze transactiegegevensbron Amazon Aurora en gebruikt Amazon Redshift als de datawarehouse-oplossing om een datamart te bouwen. In deze oplossing gebruiken we AWS Database Migration Service (AWS DMS) voor zowel volledige belasting als continue replicatie van wijzigingen van Aurora. AWS DMS stelt ons in staat om delta's vast te leggen, inclusief verwijderingen uit de brondatabase, door gebruik te maken van de configuratie Change Data Capture (CDC). CDC in DMS stelt ons in staat om delta's vast te leggen zonder code te schrijven en zonder wijzigingen te missen, wat cruciaal is voor de integriteit van de gegevens. Raadpleeg CDC-ondersteuning in DMS om de oplossingen voor lopende CDC uit te breiden.
De workflow omvat de volgende stappen:
- AWS-databasemigratieservice (AWS DMS) maakt verbinding met de Aurora-gegevensbron.
- AWS DMS repliceert gegevens van Aurora en migreert naar de doelbestemming Amazon eenvoudige opslagservice (Amazon S3) emmer.
- AWS Glue-crawlers leiden automatisch schema-informatie van de S3-gegevens af en integreren in de AWS Glue-gegevenscatalogus.
- AWS Glue-taken voeren ETL-code uit om de gegevens te transformeren en naar Amazon Redshift te laden.

Voor dit bericht gebruiken we de TPCH-gegevensset voor voorbeeldtransactiegegevens. De onderdelen van TPCH bestaan uit acht tabellen. De relaties tussen kolommen in deze tabellen worden geïllustreerd in het volgende diagram.

We gebruiken Amazon Redshift als datawarehouse om de datamart-oplossing te implementeren. De datamart-feiten- en dimensietabellen worden gemaakt in de Amazon Redshift-database. Het volgende diagram illustreert de relaties tussen de feitentabellen (ORDER) en dimensietabellen (DATE, PARTS en REGION).

Stel de omgeving in
Om te beginnen hebben we de omgeving opgezet met behulp van AWS CloudFormatie. Voer de volgende stappen uit:
- Log in op AWS-beheerconsole met uw AWS Identiteits- en toegangsbeheer (IAM) gebruikersnaam en wachtwoord.
- Kies Start Stack en open de pagina op een nieuw tabblad:

- Kies Volgende.
- Voor Stack naam, voer een naam in.
- In het parameters sectie, voert u de vereiste parameters in.
- Kies Volgende.
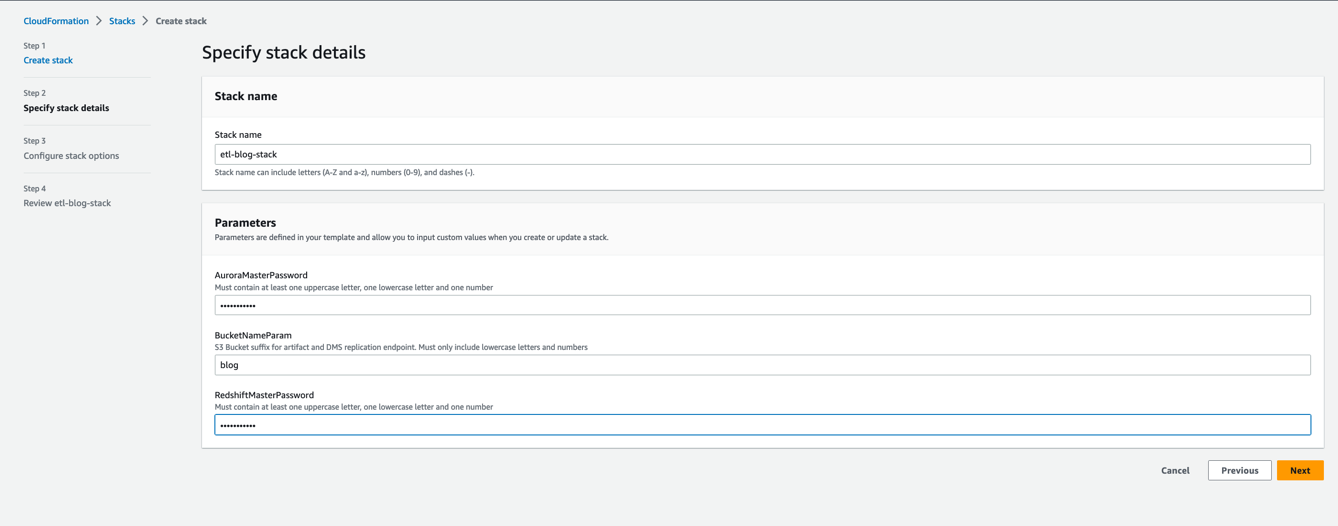
- Op de Configureer stapelopties pagina, laat alle waarden als standaard staan en kies Volgende.
- Op de Review-stapel pagina, schakelt u de selectievakjes in om het maken van IAM-resources te bevestigen.
- Kies Verzenden.
Wacht tot het maken van de stapel is voltooid. U kunt verschillende gebeurtenissen bekijken tijdens het maken van een stapel op de Evenementen tabblad. Wanneer het maken van de stapel is voltooid, ziet u de status CREATE_COMPLETE. De stapel duurt ongeveer 25-30 minuten om te voltooien.
Met deze sjabloon worden de volgende bronnen geconfigureerd:
- De Aurora MySQL-instantie
sales-db. - De AWS DMS-taak
dmsreplicationtask-*voor een volledige belasting van gegevens en het repliceren van wijzigingen van Aurora (bron) naar Amazon S3 (bestemming). - AWS-lijmcrawlers
s3-crawlerenredshift_crawler. - De AWS Glue-database
salesdb. - Vacatures voor AWS Lijm
insert_region_dim_tbl,insert_parts_dim_tbleninsert_date_dim_tbl. We gebruiken deze banen voor de use cases die in dit bericht worden behandeld. Wij creëren deinsert_orders_fact_tblAWS Glue taak handmatig met behulp van AWS Glue Visual Studio. - De Redshift-cluster
blog_clustermet databaseverkoop en feiten- en dimensietabellen. - Een S3-bucket om de uitvoer van de AWS Glue-taak op te slaan.
- IAM-rollen en -beleid met de juiste machtigingen.
Repliceer gegevens van Aurora naar Amazon S3
Laten we nu eens kijken naar de stappen om gegevens van Aurora naar Amazon S3 te repliceren met behulp van AWS DMS:
- Kies op de AWS DMS-console: Databasemigratietaken in het navigatievenster.
- Selecteer de taak
dmsreplicationtask-*en in de Actie menu, kies Herstarten/Hervatten.
Hiermee wordt de replicatietaak gestart om de gegevens van Aurora naar de S3-bucket te repliceren. Wacht tot de taakstatus verandert in Volledige lading voltooid. De gegevens uit de Aurora-tabellen worden nu gekopieerd naar de S3-bucket onder een nieuwe map, sales.
Maak AWS Glue Data Catalog-tabellen
Laten we nu AWS Glue Data Catalog-tabellen maken voor de S3-gegevens en Amazon Redshift-tabellen:
- Op de AWS Glue-console, onder Gegevenscatalogus in het navigatievenster, kies aansluitingen.
- kies
RedshiftConnectionen in de Acties menu, kies Edit. - Kies Wijzigingen opslaan.
- Selecteer de verbinding opnieuw en op de Acties menu, kies Test verbinding.
- Voor IAM-rolKiezen
GlueBlogRole. - Kies Bevestigen.
Het testen van de verbinding kan ongeveer 1 minuut duren. U ziet het bericht “Successfully connected to the data store with connection blog-redshift-connection.” Als u problemen hebt met succesvol verbinden, raadpleeg dan Verbindingsproblemen oplossen in AWS Glue.
- Onder Gegevenscatalogus in het navigatievenster, kies crawlers.
- kies
s3_crawlerEn kies lopen.
Dit genereert acht tabellen in de AWS Glue Data Catalog. Om de gemaakte tabellen te bekijken, kiest u in het navigatievenster databases voor Gegevenscatalogus, kies dan salesdb.
- Herhaal de stappen om uit te voeren
redshift_crawleren genereer vier extra tabellen.
Als de crawler faalt, raadpleeg dan Fout: het uitvoeren van de crawler is mislukt.

Maak op SQL gebaseerde AWS Glue-taken
Laten we nu eens kijken hoe de SQL-instructies worden gebruikt om ETL-taken te maken met behulp van AWS Glue. AWS Glue voert uw ETL-taken uit in een serverloze Apache Spark-omgeving. AWS Glue voert deze taken uit op virtuele bronnen die het levert en beheert in zijn eigen serviceaccount. AWS Glue Studio is een grafische interface die het eenvoudig maakt om ETL-taken in AWS Glue te maken, uit te voeren en te bewaken. U kunt AWS Glue Studio gebruiken om jobs te maken die gestructureerde of semi-gestructureerde gegevens uit een gegevensbron extraheren, een transformatie van die gegevens uitvoeren en de resultatenset opslaan in een gegevensdoel.
Laten we de stappen doorlopen van het maken van een AWS Glue-taak voor het laden van de feitentabel met bestellingen met behulp van AWS Glue Studio.
- Kies op de AWS Glue-console: Vacatures in het navigatievenster.
- Kies Baan creëren.
- kies Visueel met een leeg canvas, kies dan creëren.

- Navigeer naar de Details van de baan Tab.
- Voor Naam, ga naar binnen
insert_orders_fact_tbl. - Voor IAM-rol, kiezen
GlueBlogRole. - Voor Job bladwijzer, kiezen Enable .
- Laat alle andere parameters als standaard staan en kies Bespaar.

- Navigeer naar de Visual Tab.
- Kies het plusteken.
- Onder Knooppunten toevoegen, voer Glue in de zoekbalk in en kies AWS-lijmgegevenscatalogus (Bron) om de gegevenscatalogus als bron toe te voegen.

- In het rechterdeelvenster, op de Gegevensbroneigenschappen – Gegevenscatalogus tabblad, kies
salesdbFor Database en klant voor tafel.

- Op de Knooppunt eigenschappen tabblad, voor Naam, ga naar binnen
Customers.
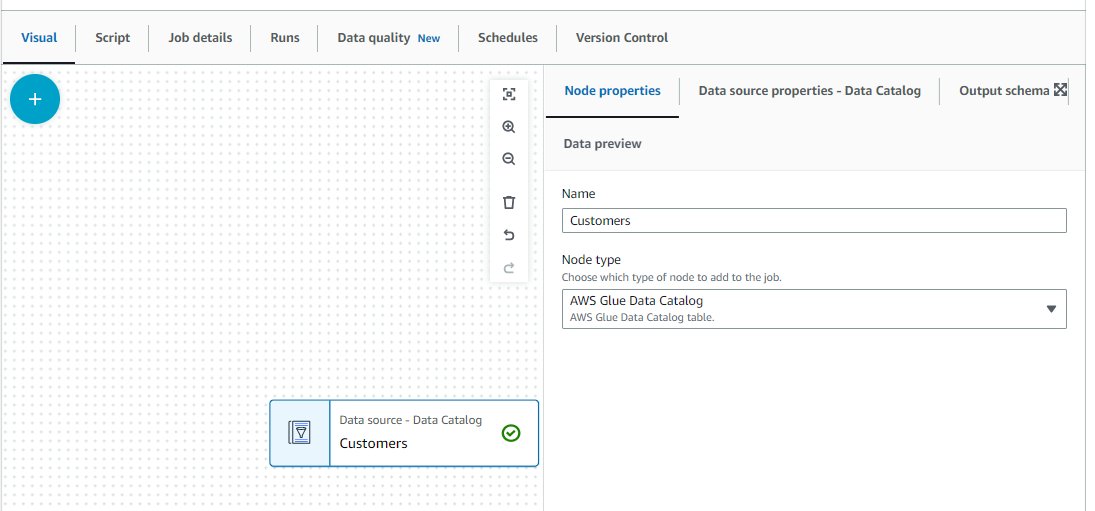
- Herhaal deze stappen voor de
OrdersenLineItemtabellen.

Dit concludeert het maken van gegevensbronnen op het AWS Glue-taakcanvas. Vervolgens voegen we transformaties toe door gegevens uit deze verschillende tabellen te combineren.
Transformeer de gegevens
Voer de volgende stappen uit om gegevenstransformaties toe te voegen:
- Kies het plusteken op het AWS Glue-taakcanvas.
- Onder transformaties, kiezen SQL-query.
- Op de Transformeren tabblad, voor Knooppunt ouders, selecteert u alle drie de gegevensbronnen.
- Op de Transformeren tab, onder SQL-query, voer de volgende vraag in:
- Werk het SQL-aliassen waarden zoals weergegeven in de volgende schermafbeelding.

- Op de Gegevensvoorbeeld tabblad, kies Gegevensvoorbeeldsessie starten.
- Kies wanneer u hierom wordt gevraagd
GlueBlogRoleFor IAM-rol En kies Bevestigen.
Het proces van gegevensvoorbeeld duurt een minuut.
- Op de Uitvoerschema tabblad, kies Gebruik het gegevensvoorbeeldschema.
U ziet het uitvoerschema dat lijkt op de volgende schermafbeelding.

Nu we een voorbeeld van de gegevens hebben bekeken, wijzigen we enkele gegevenstypen.
- Kies het plusteken op het AWS Glue-taakcanvas.
- Onder transformaties, kiezen Schema wijzigen.
- Selecteer het knooppunt.
- Op de Transformeren tabblad, update de Data type waarden zoals weergegeven in de volgende schermafbeelding.

Laten we nu het doelknooppunt toevoegen.
- Kies de Schema wijzigen knoop en kies het plusteken.
- Voer doel in de zoekbalk in.
- Kies Amazon roodverschuiving als het doelwit.

- Kies het Amazon Redshift-knooppunt en op de Eigenschappen van gegevensdoel - Amazon Redshift tabblad, voor Redshift-toegangstype, kiezen Directe dataverbinding.
- Kies
RedshiftConnectionFor Roodverschuiving verbinding, openbaar voor Schema enorder_tableFor tafel. - kies Voeg gegevens samen in de doeltabel voor Verwerking van gegevens en doeltabel.
- Kies
orderkeyFor Bijpassende sleutels.

- Kies Bespaar.
AWS Glue Studio genereert automatisch de Spark-code voor u. Je kunt het bekijken op de Script tabblad. Als u kant-en-klare transformaties wilt uitvoeren, kunt u de Spark-code wijzigen. De AWS Glue-taak gebruikt de Apache SparkSQL-query voor SQL-querytransformatie. Om de beschikbare SparkSQL-transformaties te vinden, raadpleegt u de Spark SQL-documentatie.

- Kies lopen om de baan uit te voeren.
Als onderdeel van de CloudFormation-stack worden drie andere taken gemaakt om de dimensietabellen te laden.
- Navigeer terug naar de Vacatures pagina op de AWS Glue-console, selecteer de taak
insert_parts_dim_tblen kies lopen.
Deze taak gebruikt de volgende SQL om de tabel met onderdelenafmetingen te vullen:
- Selecteer de baan
insert_region_dim_tblEn kies lopen.
Deze taak gebruikt de volgende SQL om het region afmeting tafel:
- Selecteer de baan
insert_date_dim_tblEn kies lopen.
Deze taak gebruikt de volgende SQL om het date afmeting tafel:
U kunt de status van de lopende taken bekijken door naar de Bewaking van de uitvoering van taken sectie over de Vacatures bladzijde. Wacht tot alle taken zijn voltooid. Deze taken laden de gegevens in de feiten- en dimensietabellen in Amazon Redshift.
Om de middelen en kosten te helpen optimaliseren, kunt u de AWS Glue automatisch schalen kenmerk.
Controleer het laden van Amazon Redshift-gegevens
Voer de volgende stappen uit om het laden van gegevens te verifiëren:
- Selecteer op de Amazon Redshift-console de cluster blog-cluster en op de Gegevens opvragen menu, kies Query in query-editor 2.
- Voor authenticatieselecteer Tijdelijke inloggegevens.
- Voor Database, ga naar binnen
sales. - Voor gebruikersnaam, ga naar binnen
admin. - Kies Bespaar.

- Voer de volgende opdrachten uit in de query-editor om te controleren of de gegevens in de Amazon Redshift-tabellen zijn geladen:
De volgende schermafbeelding toont de resultaten van een van de SELECT-query's.

Werk nu voor de CDC de hoeveelheid van een regelitem bij voor ordernummer 1 in de Aurora-database met behulp van de onderstaande query. (Gebruik om verbinding te maken met uw Aurora-cluster Cloud9 of andere SQL-clienttools zoals MySQL-opdrachtregelclient).
DMS repliceert de wijzigingen in de S3-bucket, zoals weergegeven in de onderstaande schermafbeelding.

De Glue-taak opnieuw uitvoeren insert_orders_fact_tbl zal de wijzigingen in de ORDER feitentabel zoals weergegeven in de onderstaande schermafbeelding

Opruimen
Verwijder de resources die voor de oplossing zijn gemaakt om toekomstige kosten te voorkomen:
- Selecteer op de Amazon S3-console de S3-bucket die is gemaakt als onderdeel van de CloudFormation-stack en kies vervolgens Leeg.
- Selecteer op de AWS CloudFormation-console de stapel die u aanvankelijk hebt gemaakt en kies Verwijder om alle bronnen te verwijderen die door de stapel zijn gemaakt.
Conclusie
In dit bericht hebben we laten zien hoe u bestaande op SQL gebaseerde ETL kunt migreren naar een AWS serverloze ETL-infrastructuur met behulp van AWS Glue-taken. We gebruikten AWS DMS om gegevens van Aurora naar een S3-bucket te migreren en vervolgens op SQL gebaseerde AWS Glue-taken om de gegevens naar feiten- en dimensietabellen in Amazon Redshift te verplaatsen.
Deze oplossing demonstreert een eenmalige gegevensbelasting van Aurora naar Amazon Redshift met behulp van AWS Glue-taken. U kunt deze oplossing uitbreiden voor het verplaatsen van de gegevens op een geplande basis door taken te orkestreren en te plannen met behulp van AWS Glue-workflows. Raadpleeg voor meer informatie over de mogelijkheden van AWS Glue AWS lijm.
Over de auteurs
 Mitesh Patél is een Principal Solutions Architect bij AWS met specialisatie in data-analyse en machine learning. Hij is gepassioneerd om klanten te helpen bij het bouwen van schaalbare, veilige en kosteneffectieve cloud-native oplossingen in AWS om de bedrijfsgroei te stimuleren. Hij woont in DC Metro gebied met zijn vrouw en twee kinderen.
Mitesh Patél is een Principal Solutions Architect bij AWS met specialisatie in data-analyse en machine learning. Hij is gepassioneerd om klanten te helpen bij het bouwen van schaalbare, veilige en kosteneffectieve cloud-native oplossingen in AWS om de bedrijfsgroei te stimuleren. Hij woont in DC Metro gebied met zijn vrouw en twee kinderen.
 Sumitha AP is Sr. Solutions Architect bij AWS. Ze werkt samen met klanten en helpt hen hun zakelijke doelstellingen te bereiken door veilige, schaalbare, betrouwbare en kosteneffectieve oplossingen te ontwerpen in de AWS Cloud. Ze heeft een focus op data en analyse en biedt begeleiding bij het bouwen van analyseoplossingen op AWS.
Sumitha AP is Sr. Solutions Architect bij AWS. Ze werkt samen met klanten en helpt hen hun zakelijke doelstellingen te bereiken door veilige, schaalbare, betrouwbare en kosteneffectieve oplossingen te ontwerpen in de AWS Cloud. Ze heeft een focus op data en analyse en biedt begeleiding bij het bouwen van analyseoplossingen op AWS.
 Deepti Venuturumilli is Sr. Solutions Architect in AWS. Ze werkt samen met klanten uit het commerciële segment en AWS-partners om de bedrijfsresultaten van klanten te versnellen door expertise in AWS-services te bieden en hun werklast te moderniseren. Ze richt zich op data-analyse-workloads en het opzetten van een moderne datastrategie op AWS.
Deepti Venuturumilli is Sr. Solutions Architect in AWS. Ze werkt samen met klanten uit het commerciële segment en AWS-partners om de bedrijfsresultaten van klanten te versnellen door expertise in AWS-services te bieden en hun werklast te moderniseren. Ze richt zich op data-analyse-workloads en het opzetten van een moderne datastrategie op AWS.
 Deephi Paruchuri is een AWS Solutions Architect gevestigd in NYC. Ze werkt nauw samen met klanten om een strategie voor cloudadoptie op te stellen en hun zakelijke behoeften op te lossen door veilige, schaalbare en kosteneffectieve oplossingen in de AWS-cloud te ontwerpen.
Deephi Paruchuri is een AWS Solutions Architect gevestigd in NYC. Ze werkt nauw samen met klanten om een strategie voor cloudadoptie op te stellen en hun zakelijke behoeften op te lossen door veilige, schaalbare en kosteneffectieve oplossingen in de AWS-cloud te ontwerpen.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. Automotive / EV's, carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- BlockOffsets. Eigendom voor milieucompensatie moderniseren. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/migrate-your-existing-sql-based-etl-workload-to-an-aws-serverless-etl-infrastructure-using-aws-glue/

