Amazon roodverschuiving is een snel, volledig beheerd datawarehouse op petabyte-schaal dat de flexibiliteit biedt om ingerichte of serverloze rekenkracht te gebruiken voor uw analytische workloads. Gebruik makend van Amazon Redshift Serverloos en Query-editor v2, u kunt met slechts een paar klikken grote datasets laden en opvragen en alleen betalen voor wat u gebruikt. De ontkoppelde reken- en opslagarchitectuur van Amazon Redshift stelt je in staat zeer schaalbare, veerkrachtige en kosteneffectieve workloads te bouwen. Veel klanten migreren hun datawarehousing-workloads naar Amazon Redshift en profiteren van de uitgebreide mogelijkheden die het biedt. De volgende zijn slechts enkele van de opmerkelijke mogelijkheden:
- Amazon Redshift integreert naadloos met breder analyseservices op AWS. Zo kunt u het juiste gereedschap voor de juiste klus kiezen. Moderne analyse is veel breder dan op SQL gebaseerde datawarehousing. Met Amazon Redshift kun je bouwen architectuur aan het meer en voer vervolgens elke vorm van analyse uit, zoals interactieve analyse, operationele analyses, big data verwerking, visuele gegevensvoorbereiding, voorspellende analyses, machine learning (ML) en meer.
- U hoeft zich geen zorgen te maken dat workloads, zoals ETL, dashboards, ad-hocquery's, enzovoort, elkaar in de weg zitten. Jij kan werklast isoleren gebruikmakend van het delen van gegevens, terwijl dezelfde onderliggende datasets worden gebruikt.
- Wanneer gebruikers tijdens piekmomenten veel query's uitvoeren, schaalt compute naadloos binnen enkele seconden om consistente prestaties met hoge gelijktijdigheid te bieden. U krijgt één uur gratis gelijktijdige schaalcapaciteit voor 24 uur gebruik. Dit gratis tegoed voldoet aan de concurrency-vraag van 97% van het Amazon Redshift-klantenbestand.
- Amazon Redshift is eenvoudig te gebruiken zelf afstemmend en zelf optimaliserend mogelijkheden. U kunt sneller inzicht krijgen zonder kostbare tijd te besteden aan het beheren van uw datawarehouse.
- Fouttolerantie is ingebouwd. Alle gegevens die naar Amazon Redshift worden geschreven, worden automatisch en continu gerepliceerd Amazon Simple Storage-service (Amazon S3). Eventuele hardwarestoringen worden automatisch vervangen.
- Amazon Redshift is dat wel eenvoudig te communiceren Met. U hebt toegang tot gegevens met traditionele, cloud-native, container- en serverloze op webservices gebaseerde of gebeurtenisgestuurde applicaties, enzovoort.
- Roodverschuiving ML maakt het voor datawetenschappers gemakkelijk om ML-modellen te maken, trainen en implementeren met behulp van vertrouwde SQL. Ze kunnen ook voorspellingen uitvoeren met behulp van SQL.
- Amazon Redshift biedt uitgebreide gegevensbeveiliging zonder extra kosten. U kunt end-to-end gegevensversleuteling instellen, firewallregels configureren, gedetailleerde beveiligingscontroles op rij- en kolomniveau definiëren voor gevoelige gegevens, enzovoort.
- Amazon roodverschuiving integreert naadloos met andere AWS-services en tools van derden. U kunt grote datasets snel en betrouwbaar verplaatsen, transformeren, laden en bevragen.
In dit bericht bieden we een walkthrough voor het migreren van een datawarehouse van Google BigQuery naar Amazon Redshift met behulp van AWS-schemaconversietool (AWS SCT) en AWS SCT-gegevensextractiemiddelen. AWS SCT is een service die heterogene databasemigraties voorspelbaar maakt door het merendeel van de databasecode en opslagobjecten automatisch te converteren naar een indeling die compatibel is met de doeldatabase. Objecten die niet automatisch kunnen worden geconverteerd, zijn duidelijk gemarkeerd, zodat ze handmatig kunnen worden geconverteerd om de migratie te voltooien. Bovendien kan AWS SCT uw applicatiecode scannen op ingesloten SQL-instructies en deze converteren.
Overzicht oplossingen
AWS SCT gebruikt een serviceaccount om verbinding te maken met uw BigQuery-project. Eerst maken we een Amazon Redshift-database waarin BigQuery-gegevens worden gemigreerd. Vervolgens maken we een S3-bucket. Vervolgens gebruiken we AWS SCT om BigQuery-schema's te converteren en toe te passen op Amazon Redshift. Ten slotte gebruiken we AWS SCT-gegevensextractiemiddelen om gegevens te migreren, die gegevens uit BigQuery extraheren, uploaden naar de S3-bucket en vervolgens kopiëren naar Amazon Redshift.

Voorwaarden
Voordat u aan deze walkthrough begint, moet u over de volgende vereisten beschikken:
- Een werkstation met AWS SCT, Amazon Corretto 11, en Amazon Redshift-stuurprogramma's.
- U kunt een gebruiken Amazon Elastic Compute Cloud (Amazon EC2) instantie of uw lokale desktop als werkstation. In deze walkthrough gebruiken we Amazon EC2 Windows-instantie. Gebruik om het te maken Deze gids.
- Gebruik om AWS SCT te downloaden en te installeren op de EC2-instantie die u eerder hebt gemaakt Deze gids.
- Download het Amazon Redshift JDBC-stuurprogramma van deze locatie.
- Download en installeer Amazon Corretto 11.
- Een GCP-serviceaccount dat AWS SCT kan gebruiken om verbinding te maken met uw BigQuery-bronproject.
- Grant BigQuery-beheerder en Opslag beheerder rollen toe aan het serviceaccount.
- Kopieer het sleutelbestand van het serviceaccount, dat is gemaakt in de Google-cloudbeheerconsole, naar de EC2-instantie met AWS SCT.
- Maak een Cloud Storage-bucket in GCP om uw brongegevens op te slaan tijdens de migratie.
Deze walkthrough omvat de volgende stappen:
- Maak een Amazon Redshift serverloze werkgroep en naamruimte
- Maak de AWS S3-bucket en -map
- Converteer en pas BigQuery Schema toe op Amazon Redshift met behulp van AWS SCT
- Verbinding maken met de Google BigQuery-bron
- Maak verbinding met het Amazon Redshift-doelwit
- Converteer BigQuery-schema naar een Amazon Redshift
- Analyseer het assessmentrapport en pak de actiepunten aan
- Pas geconverteerd schema toe om Amazon Redshift te targeten
- Migreer gegevens met behulp van AWS SCT-gegevensextractiemiddelen
- Vertrouwen en sleutelopslag genereren (optioneel)
- Installeer en start de data-extractie-agent
- Registreer data-extractie-agent
- Voeg virtuele partities toe voor grote tabellen (optioneel)
- Maak een lokale migratietaak
- Start de lokale gegevensmigratietaak
- Bekijk gegevens in Amazon Redshift
Maak een Amazon Redshift serverloze werkgroep en naamruimte
In deze stap maken we een Amazon Redshift serverloze werkgroep en naamruimte. Workgroup is een verzameling rekenresources en naamruimte is een verzameling database-objecten en gebruikers. Om workloads te isoleren en verschillende bronnen in Amazon Redshift Serverless te beheren, kunt u naamruimten en werkgroepen maken en opslag- en rekenbronnen afzonderlijk beheren.
Volg deze stappen om een Amazon Redshift serverloze werkgroep en naamruimte te maken:
- Navigeer naar de Amazon Redshift-console.
- Kies rechtsboven de AWS-regio die u wilt gebruiken.
- Vouw het Amazon Redshift-venster aan de linkerkant uit en kies Roodverschuiving Serverloos.
- Kies Werkgroep maken.
- Voor werkgroep naam, voer een naam in die de rekenresources beschrijft.
- Controleer of de VPC dezelfde is als de VPC als de EC2-instantie met AWS SCT.
- Kies Volgende.

- Voor Naamruimte naam, voer een naam in die uw dataset beschrijft.
- In Databasenaam en wachtwoord sectie, schakelt u het selectievakje in Pas beheerdersreferenties aan.
- Voor gebruikersnaam beheerder, voer een gebruikersnaam naar keuze in, bijvoorbeeld awsuser.
- Voor Admin gebruikerswachtwoord: voer bijvoorbeeld een zelfgekozen wachtwoord in MijnRedShiftPW2022.

- Kies Next. Houd er rekening mee dat gegevens in Amazon Redshift Serverless naamruimte standaard worden versleuteld.
- In het Beoordeel en maak pagina, kies creëren.
- Maak een AWS identiteits- en toegangsbeheer (IAM) rol en stel deze in als standaard in uw naamruimte, zoals hieronder wordt beschreven. Houd er rekening mee dat er slechts één standaard IAM-rol kan zijn.
- Navigeer naar de Amazon Redshift serverloos dashboard.
- Onder Naamruimten / Werkgroepen, kies de naamruimte die u zojuist hebt gemaakt.
- Navigeer naarBeveiliging en codering.
- Onder machtigingen, kiezen IAM-rollen beheren.
- Navigeer naar IAM-rollen beheren. Kies dan de IAM-rollen beheren vervolgkeuzelijst en kies Maak een IAM-rol.
- Onder Geef een Amazon S3-bucket op waartoe de IAM-rol toegang moet hebben, kies een van de volgende methoden:
- Kies Geen extra Amazon S3-emmer om de gemaakte IAM-rol alleen toegang te geven tot de S3-buckets met een naam die begint met roodverschuiving.
- Kies Elke Amazon S3-emmer om de gemaakte IAM-rol toegang te geven tot alle S3-buckets.
- Kies Specifieke Amazon S3-emmers om een of meer S3-buckets op te geven voor toegang tot de gemaakte IAM-rol. Kies dan één of meerdere S3 emmers uit de tabel.
- Kies IAM-rol als standaard aanmaken. Amazon Redshift maakt en stelt automatisch de IAM-rol in als standaard.
- Leg het eindpunt vast voor de Amazon Redshift Serverless-werkgroep die u zojuist hebt gemaakt.
Maak de S3-bucket en -map
Tijdens het datamigratieproces gebruikt AWS SCT Amazon S3 als staging area voor de geëxtraheerde data. Volg deze stappen om de S3-bucket te maken:
- Navigeer naar de Amazon S3-console
- Kies Maak een bucket. De Maak een bucket wizard wordt geopend.
- Voor Bucketnaam, voer een unieke DNS-compatibele naam in voor uw bucket (bijv. uniekenaam-bq-rs). Zie regels voor het benoemen van buckets bij het kiezen van een naam.
- Kies voor AWS-regio de regio waarin u de Amazon Redshift Serverless-werkgroep hebt gemaakt.
- kies Emmer maken.
- In het Amazon S3-console, navigeer naar de S3-bucket die u zojuist hebt gemaakt (bijv. uniekenaam-bq-rs).
- Kies "Map aanmaken" om een nieuwe map aan te maken.
- Voor Naam van de map, invoeren inkomend En kies Map maken.
Converteer en pas BigQuery Schema toe op Amazon Redshift met behulp van AWS SCT
Om het BigQuery-schema naar het Amazon Redshift-formaat te converteren, gebruiken we AWS SCT. Begin door in te loggen op de EC2-instantie die we eerder hebben gemaakt en start vervolgens AWS SCT.
Volg deze stappen met behulp van AWS SCT:
Maak verbinding met de BigQuery-bron
- Van de Menu Bestand kiezen Maak een nieuw project.
- Kies een locatie om uw projectbestanden en gegevens op te slaan.
- Geef een betekenisvolle maar gedenkwaardige naam voor uw project, zoals BigQuery naar Amazon Redshift.
- Kies om verbinding te maken met het BigQuery-brondatawarehouse bron toevoegen in het hoofdmenu.
- Kies BigQuery En kies Volgende. De bron toevoegen dialoogvenster verschijnt.
- Voor Verbindingsnaam, voer een naam in om de BigQuery-verbinding te beschrijven. AWS SCT geeft deze naam weer in de boom in het linkerdeelvenster.
- Voor Sleutel pad, geeft u het pad op van het serviceaccountsleutelbestand dat eerder is gemaakt in de Google Cloud Management Console.
- Kies Verbinding testen om te controleren of AWS SCT verbinding kan maken met uw BigQuery-bronproject.
- Zodra de verbinding met succes is gevalideerd, kiest u Verbinden.

Maak verbinding met het Amazon Redshift-doelwit
Volg deze stappen om verbinding te maken met Amazon Redshift:
- Kies in AWS SCT Doel toevoegen in het hoofdmenu.
- Kies Amazon roodverschuiving, kies dan Next. De Doel toevoegen dialoogvenster verschijnt.
- Voor Verbindingsnaam, voer een naam in om de Amazon Redshift-verbinding te beschrijven. AWS SCT geeft deze naam weer in de boom in het rechterdeelvenster.
- Voor Server naam, voer het eerder vastgelegde eindpunt van de Amazon Redshift Serverless-werkgroep in.
- Voor Server poort, invoeren 5439.
- Voor databank, invoeren dev.
- Voor Gebruikersnaam, voer de gebruikersnaam in die is gekozen bij het maken van de Amazon Redshift Serverless-werkgroep.
- Voor Wachtwoord, voer het gekozen wachtwoord in bij het maken van de Amazon Redshift Serverless-werkgroep.
- Haal het vinkje weg het vak "AWS-lijm gebruiken".
- Kies Verbinding testen om te verifiëren dat AWS SCT verbinding kan maken met uw Amazon Redshift-doelgroep.
- Kies Verbinden om verbinding te maken met het Amazon Redshift-doelwit.
Merk op dat u als alternatief verbindingswaarden kunt gebruiken die zijn opgeslagen in AWS-geheimenmanager.

Converteer BigQuery-schema naar een Amazon Redshift
Nadat de bron- en doelverbindingen met succes zijn gemaakt, ziet u de BigQuery-bronobjectstructuur in het linkerdeelvenster en de doel-Amazon Redshift-objectstructuur in het rechterdeelvenster.
Volg deze stappen om het BigQuery-schema te converteren naar de Amazon Redshift-indeling:
- Klik in het linkerdeelvenster met de rechtermuisknop op het schema dat u wilt converteren.
- Kies Schema converteren.
- Er verschijnt een dialoogvenster met een vraag, De objecten bestaan mogelijk al in de doeldatabase. Vervangen?. Kies Ja.
Zodra de conversie is voltooid, ziet u een nieuw schema gemaakt in het deelvenster Amazon Redshift (rechterdeelvenster) met dezelfde naam als uw BigQuery-schema.

Het voorbeeldschema dat we hebben gebruikt, heeft 16 tabellen, 3 weergaven en 3 procedures. U kunt deze objecten in het Amazon Redshift-formaat in het rechterdeelvenster zien. AWS SCT converteert alle BigQuery-code en data-objecten naar het Amazon Redshift-formaat. Bovendien kunt u AWS SCT gebruiken om externe SQL-scripts, applicatiecode of aanvullende bestanden met ingesloten SQL te converteren.
Analyseer het assessmentrapport en pak de actiepunten aan
AWS SCT maakt een beoordelingsrapport om de migratiecomplexiteit te beoordelen. AWS SCT kan de meeste code- en database-objecten converteren. Sommige objecten kunnen echter handmatige conversie vereisen. AWS SCT markeert deze objecten in het blauw in het diagram met conversiestatistieken en maakt actie-items waaraan een complexiteit is gekoppeld.
Om het beoordelingsrapport te bekijken, schakelt u over van de Hoofdweergave aan de Beoordelingsrapport bekijken als volgt:

De Samengevat tabblad toont objecten die automatisch zijn geconverteerd en objecten die niet automatisch zijn geconverteerd. Groen staat voor automatisch geconverteerde of met eenvoudige actie-items. Blauw staat voor middelgrote en complexe actie-items die handmatige tussenkomst vereisen.

De Actie-items tabblad toont de aanbevolen acties voor elk conversieprobleem. Als u een actiepunt uit de lijst selecteert, markeert AWS SCT het object waarop het actiepunt van toepassing is.
Het rapport bevat ook aanbevelingen voor het handmatig converteren van het schema-item. Nadat de beoordeling is uitgevoerd, laten gedetailleerde rapporten voor de database/het schema u bijvoorbeeld zien hoeveel moeite het kost om de aanbevelingen voor het converteren van actie-items te ontwerpen en te implementeren. Zie voor meer informatie over hoe om te gaan met handmatige conversies Handmatige conversies afhandelen in AWS SCT. Amazon Redshift voert automatisch enkele acties uit tijdens het converteren van het schema naar Amazon Redshift. Objecten met deze acties zijn gemarkeerd met een rood waarschuwingsbord.

U kunt het individuele object DDL evalueren en inspecteren door het in het rechterdeelvenster te selecteren, en u kunt het indien nodig ook bewerken. In het volgende voorbeeld wijzigt AWS SCT de gegevenstypekolommen RECORD en JSON in BigQuery-tabel ncaaf_referee_data naar het SUPER-gegevenstype in Amazon Redshift. De partitiesleutel in de tabel ncaaf_referee_data wordt geconverteerd naar de distributiesleutel en sorteersleutel in Amazon Redshift.

Pas geconverteerd schema toe om Amazon Redshift te targeten
Om het geconverteerde schema toe te passen op Amazon Redshift, selecteert u het geconverteerde schema in het rechterdeelvenster, klikt u met de rechtermuisknop en kiest u Toepassen op databank.
Migreer gegevens van BigQuery naar Amazon Redshift met behulp van AWS SCT-gegevensextractiemiddelen
AWS SCT-extractiemiddelen halen gegevens uit uw brondatabase en migreren deze naar de AWS Cloud. In deze walkthrough laten we zien hoe u AWS SCT-extractiemiddelen configureert om gegevens uit BigQuery te extraheren en te migreren naar Amazon Redshift.
Installeer eerst de AWS SCT-extractieagent op dezelfde Windows-instantie waarop AWS SCT is geïnstalleerd. Voor betere prestaties raden we u aan om indien mogelijk een afzonderlijke Linux-instantie te gebruiken om extractiemiddelen te installeren. Voor grote datasets kunt u verschillende data-extractiemiddelen gebruiken om de datamigratiesnelheid te verhogen.
Vertrouwen en sleutelwinkels genereren (optioneel)
U kunt Secure Socket Layer (SSL) gecodeerde communicatie gebruiken met AWS SCT-gegevensextractors. Wanneer u SSL gebruikt, blijven alle gegevens die tussen de applicaties worden uitgewisseld privé en integraal. Om SSL-communicatie te gebruiken, moet u vertrouwens- en sleutelarchieven genereren met behulp van AWS SCT. U kunt deze stap overslaan als u geen gebruik wilt maken van SSL. We raden aan om SSL te gebruiken voor productieworkloads.
Volg deze stappen om vertrouwen en sleutelwinkels te genereren:
- Navigeer in AWS SCT naar Instellingen → Algemene instellingen → Beveiliging.
- Kies Genereer vertrouwen en sleutelopslag.

- Voer de naam en het wachtwoord in voor vertrouwens- en sleutelopslagplaatsen en kies een locatie waar u ze wilt opslaan.

- Kies Genereer.
Installeer en configureer Data Extraction Agent
In het installatiepakket voor AWS SCT vindt u een submapagent (aws-schema-conversion-tool-1.0.latest.zipagents). Zoek en installeer het uitvoerbare bestand met een naam als aws-schema-conversietool-extractor-xxxxxxxx.msi.
Volg tijdens het installatieproces deze stappen om AWS SCT Data Extractor te configureren:
- Voor Luisterpoort, voer het poortnummer in waarop de agent luistert. Standaard is dit 8192.
- Voor Voeg een bronleverancier toe, ga naar binnen Nee, omdat u geen stuurprogramma's nodig heeft om verbinding te maken met BigQuery.
- Voor Voeg het Amazon Redshift-stuurprogramma toe, ga naar binnen JA.
- Voor Voer Redshift JDBC-stuurprogrammabestand of -bestanden in, voer de locatie in waar u Amazon Redshift JDBC-stuurprogramma's hebt gedownload.
- Voor Werkende map, voer het pad in waar de AWS SCT-gegevensextractieagent de geëxtraheerde gegevens zal opslaan. De werkmap kan zich op een andere computer dan de agent bevinden en een enkele werkmap kan door meerdere agenten op verschillende computers worden gedeeld.
- Voor Schakel SSL-communicatie in, ga naar binnen ja. Kies hier Nee als u geen gebruik wilt maken van SSL.
- Voor Sleutelwinkel, voer de opslaglocatie in die is gekozen bij het maken van de vertrouwens- en sleutelopslag.
- Voor Wachtwoord voor sleutelopslag, voer het wachtwoord voor de sleutelopslag in.
- Voor SSL-authenticatie voor client inschakelen, ga naar binnen ja.
- Voor Vertrouw winkel, voer de opslaglocatie in die is gekozen bij het maken van de vertrouwens- en sleutelopslag.
- Voor Wachtwoord voor winkel vertrouwen, voer het wachtwoord in voor de trust store.
Gegevensextractieagent(en) starten
Gebruik de volgende procedure om extractiemiddelen te starten. Herhaal deze procedure op elke computer waarop een extractiemiddel is geïnstalleerd.
Extractiemiddelen fungeren als luisteraars. Wanneer u een agent start met deze procedure, begint de agent te luisteren naar instructies. In een latere sectie stuurt u de agenten instructies om gegevens uit uw datawarehouse te extraheren.
Om de extractie-agent te starten, navigeert u naar de map AWS SCT Data Extractor Agent. Dubbelklik bijvoorbeeld in Microsoft Windows C:Program FilesAWS SCT Data Extractor AgentStartAgent.bat.
- Op de computer waarop het extractiemiddel is geïnstalleerd, voert u vanaf een opdrachtprompt of terminalvenster de opdracht uit die wordt vermeld onder uw besturingssysteem.
- Om de status van de agent te controleren, voert u dezelfde opdracht uit, maar vervangt u start door status.
- Om een agent te stoppen, voert u dezelfde opdracht uit, maar vervangt u start door stop.
- Om een agent opnieuw op te starten, voert u hetzelfde bestand RestartAgent.bat uit.
Registreer de gegevensextractie-agent
Volg deze stappen om de Data Extraction Agent te registreren:
- Wijzig in AWS SCT de weergave in Gegevensmigratieweergave (andere) En kies + Registreer.
- Op het tabblad verbinding:

- Voor Omschrijving, voer een naam in om de Data Extraction Agent te identificeren.
- Voor hostnaam, als u de Data Extraction Agent op hetzelfde werkstation als AWS SCT hebt geïnstalleerd, voert u 0.0.0.0 in om de lokale host aan te geven. Voer anders de hostnaam in van de machine waarop de AWS SCT Data Extraction Agent is geïnstalleerd. Het wordt aanbevolen om de Data Extraction Agents op Linux te installeren voor betere prestaties.
- Voor Haven, voer het nummer in dat is ingevoerd voor de Luisterpoort bij het installeren van de AWS SCT Data Extraction Agent.
- Schakel het selectievakje in om SSL te gebruiken (bij gebruik van SSL) om de AWS SCT-verbinding met de Data Extraction Agent te coderen.
- Als u SSL gebruikt, doet u in het tabblad SSL het volgende:
- Voor Vertrouw winkel, kies de naam van de truststore die is gemaakt wanneer het genereren van Trust- en Key Stores (optioneel kunt u dit overslaan als SSL-connectiviteit niet nodig is).
- Voor Sleutelwinkel, kies de sleutelopslagnaam die is gemaakt wanneer het genereren van Trust- en Key Stores (optioneel kunt u dit overslaan als SSL-connectiviteit niet nodig is).

- Kies Verbinding testen.
- Zodra de verbinding met succes is gevalideerd, kiest u Registreren.

Voeg virtuele partities toe voor grote tabellen (optioneel)
U kunt AWS SCT gebruiken om virtuele partities te maken om de migratieprestaties te optimaliseren. Wanneer virtuele partities worden gemaakt, extraheert AWS SCT de gegevens parallel voor partities. We raden aan om virtuele partities te maken voor grote tabellen.
Volg deze stappen om virtuele partities te maken:
- Deselecteer alle objecten in de brondatabaseweergave in AWS SCT.
- Kies de tabel waarvoor u virtuele partities wilt toevoegen.
- Klik met de rechtermuisknop op de tabel en kies Voeg virtuele partitionering toe.

- U kunt lijst-, bereik- of automatisch gesplitste partities gebruiken. Raadpleeg voor meer informatie over virtuele partitionering Gebruik virtuele partitionering in AWS SCT. In dit voorbeeld gebruiken we Auto split partitioning, die automatisch bereikpartities genereert. U zou de startwaarde, eindwaarde en hoe groot de partitie moet zijn specificeren. AWS SCT bepaalt automatisch de partities. Voor een demonstratie, op de Lineorder tafel:
- Voor Startwaarde, voer 1000000 in.
- Voor Eindwaarde, voer 3000000 in.
- Voor interval, voer 1000000 in om de partitiegrootte aan te geven.
- Kies Ok.

U kunt de automatisch gegenereerde partities zien onder de Virtuele partities tabblad. In dit voorbeeld heeft AWS SCT automatisch de volgende vijf partities voor het veld gemaakt:
-
- >=1000000 en <=2000000
- > 2000000 en <= 3000000
- > 3000000
- IS NIETS

Maak een lokale migratietaak
Om gegevens van BigQuery naar Amazon Redshift te migreren, moet u de lokale migratietaak vanuit AWS SCT maken, uitvoeren en bewaken. Deze stap gebruikt de gegevensextractieagent om gegevens te migreren door een taak te maken.
Volg deze stappen om een lokale migratietaak te maken:
- Klik in AWS SCT onder de schemanaam in het linkerdeelvenster met de rechtermuisknop op Standaard tafels.
- Kies Lokale taak maken.

- Er zijn drie migratiemodi waaruit u kunt kiezen:
- Extraheer brongegevens en sla deze op een lokale pc/virtuele machine (VM) op waarop de agent draait.
- Extraheer gegevens en upload deze naar een S3-bucket.
- Kies Uploaden en kopiëren extraheren, waarmee gegevens naar een S3-bucket worden geëxtraheerd en vervolgens naar Amazon Redshift worden gekopieerd.

- In het Geavanceerd tabblad, voor Google CS-bucketmap voer de Google Cloud Storage-bucket/map in die u eerder in de GCP-beheerconsole heeft gemaakt. AWS SCT slaat de geëxtraheerde gegevens op deze locatie op.

- In het Amazon S3-instellingen tabblad, voor Amazon S3 bucketmap, geef de bucket- en mapnamen op van de S3-bucket die u eerder hebt gemaakt. De AWS SCT-gegevensextractieagent uploadt de gegevens naar de S3-bucket/map voordat ze naar Amazon Redshift worden gekopieerd.

- Kies Taak testen.
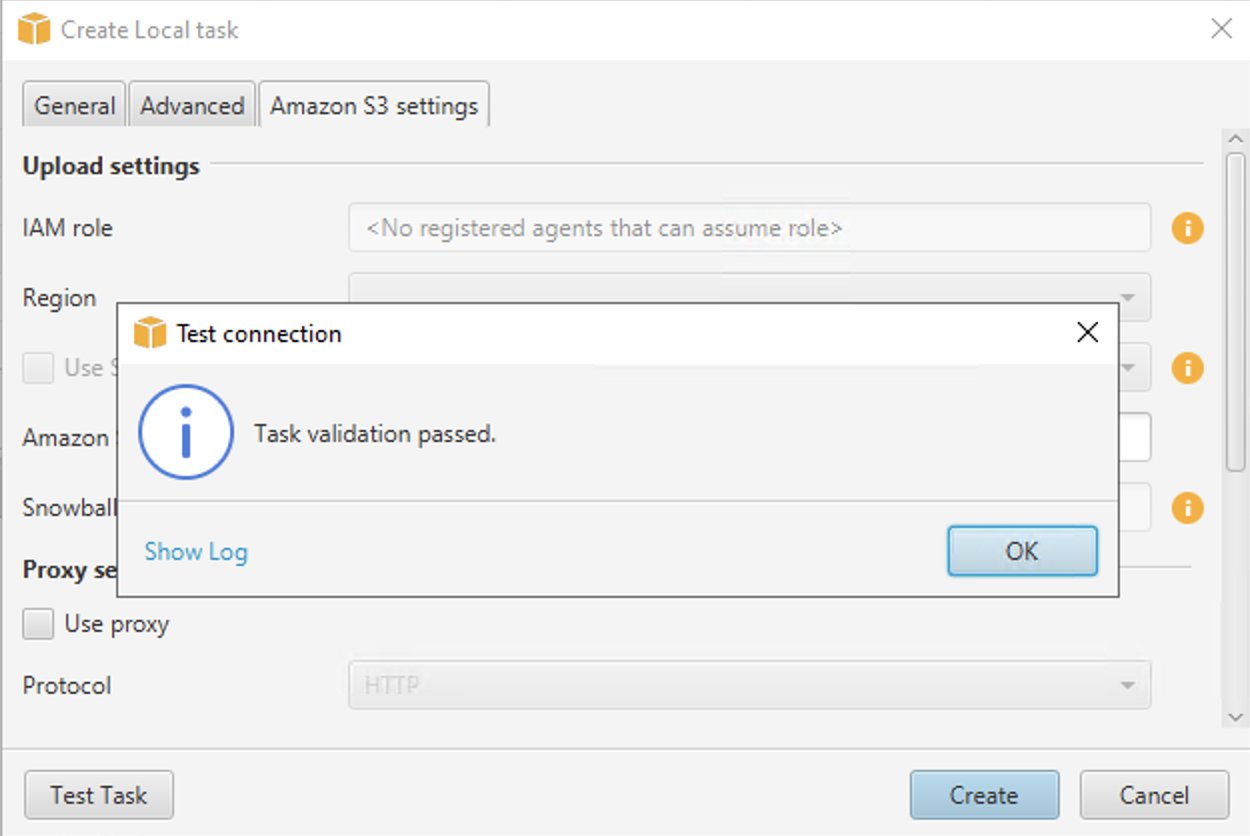
- Zodra de taak met succes is gevalideerd, kiest u creëren.
Start de lokale gegevensmigratietaak
Om de taak te starten, kiest u de Start knop in de Taken Tab.

- Eerst extraheert de Data Extraction Agent gegevens uit BigQuery naar de GCP-opslagbucket.
- Vervolgens uploadt de agent gegevens naar Amazon S3 en start een kopieeropdracht om de gegevens naar Amazon Redshift te verplaatsen.
- Op dit moment heeft AWS SCT met succes gegevens gemigreerd van de bron-BigQuery-tabel naar de Amazon Redshift-tabel.
Bekijk gegevens in Amazon Redshift
Nadat de gegevensmigratietaak met succes is uitgevoerd, kunt u verbinding maken met Amazon Redshift en de gegevens valideren.
Volg deze stappen om de gegevens in Amazon Redshift te valideren:
- Navigeer naar de Amazon Redshift QueryEditor V2.
- Dubbelklik op de naam van de Amazon Redshift Serverless-werkgroep die u hebt gemaakt.
- Kies de Gefedereerde gebruiker optie onder Authenticatie.
- Kies Verbinding maken.

- Maak een nieuwe editor aan door het + icoon.
- Schrijf in de editor een query om een keuze te maken uit de schemanaam en tabelnaam/weergavenaam die u wilt verifiëren. Verken de gegevens, voer ad-hocquery's uit en maak visualisaties en grafieken en weergaven.

Het volgende is een zij-aan-zij vergelijking tussen de bron BigQuery en de doel-Amazon Redshift voor de sportdataset die we in deze walkthrough hebben gebruikt.

Ruim alle AWS-bronnen op die u voor deze oefening hebt gemaakt
Volg deze stappen om de EC2-instantie te beëindigen:
- Navigeer naar de Amazon EC2-console.
- Kies in het navigatievenster Gevallen.
- Schakel het selectievakje in voor de EC2-instantie die u hebt gemaakt.
- Kies Instantie staat, En vervolgens Beëindig instantie.
- Kies Beëindigen wanneer om bevestiging wordt gevraagd.
Volg deze stappen om Amazon Redshift Serverless werkgroep en naamruimte te verwijderen
- Navigeer naar Amazon Redshift serverloos dashboard.
- Onder Naamruimten / Werkgroepen, kies de werkruimte die u hebt gemaakt.
- Onder Acties, kiezen Werkgroep verwijderen.
- Selecteer het selectievakje Verwijder de bijbehorende naamruimte.
- Haal het vinkje weg Maak een definitieve momentopname.
- Enter verwijderen in het bevestigingstekstvak voor verwijderen en kies Verwijderen.

Volg deze stappen om de S3-bucket te verwijderen
- Navigeer naar Amazon S3-console.
- Kies de bucket die u hebt gemaakt.
- Kies Verwijder.
- Om de verwijdering te bevestigen, voert u de naam van de bucket in het tekstinvoerveld in.
- Kies Emmer verwijderen.
Conclusie
Het migreren van een datawarehouse kan een uitdagend, complex en toch lonend project zijn. AWS SCT vermindert de complexiteit van datawarehouse-migraties. Door deze walkthrough te volgen, kunt u begrijpen hoe een gegevensmigratietaak gegevens extraheert, downloadt en vervolgens migreert van BigQuery naar Amazon Redshift. De oplossing die we in dit bericht hebben gepresenteerd, voert een eenmalige migratie uit van database-objecten en -gegevens. Gegevenswijzigingen die in BigQuery zijn aangebracht tijdens de migratie, worden niet weergegeven in Amazon Redshift. Wanneer de gegevensmigratie bezig is, zet u uw ETL-taken naar BigQuery in de wacht of speelt u de ETL's opnieuw af door na de migratie naar Amazon Redshift te wijzen. Overweeg het gebruik van de best practices voor AWS SCT.
AWS SCT heeft enkele beperkingen bij het gebruik van BigQuery als bron. AWS SCT kan bijvoorbeeld geen subquery's omzetten in analytische functies, geografische functies, statistische aggregatiefuncties, enzovoort. Vind de volledige lijst met beperkingen in de AWS SCT-gebruikershandleiding. We zijn van plan deze beperkingen in toekomstige releases aan te pakken. Ondanks deze beperkingen kunt u AWS SCT gebruiken om de meeste van uw BigQuery-code en opslagobjecten automatisch te converteren.
Download en installeer AWS SCT, log in op de AWS-console, bekijk Amazon Redshift Serverless en begin met migreren!
Over de auteurs
 Cedrick Hoodye is een Solutions Architect met een focus op databasemigraties met behulp van de AWS Database Migration Service (DMS) en de AWS Schema Conversion Tool (SCT) bij AWS. Hij werkt aan uitdagingen op het gebied van DB-migraties. Hij werkt nauw samen met klanten uit de EdTech-, Energy- en ISV-businesssector om hen te helpen het ware potentieel van de DMS-service te realiseren. Hij heeft geholpen bij het migreren van honderden databases naar de AWS-cloud met behulp van DMS en SCT.
Cedrick Hoodye is een Solutions Architect met een focus op databasemigraties met behulp van de AWS Database Migration Service (DMS) en de AWS Schema Conversion Tool (SCT) bij AWS. Hij werkt aan uitdagingen op het gebied van DB-migraties. Hij werkt nauw samen met klanten uit de EdTech-, Energy- en ISV-businesssector om hen te helpen het ware potentieel van de DMS-service te realiseren. Hij heeft geholpen bij het migreren van honderden databases naar de AWS-cloud met behulp van DMS en SCT.
 Amit Arora is een Solutions Architect met een focus op Database en Analytics bij AWS. Hij werkt samen met onze Financial Technology en Global Energy-klanten en AWS-gecertificeerde partners om technische assistentie te bieden en klantoplossingen te ontwerpen voor cloudmigratieprojecten, waarbij hij klanten helpt bij het migreren en moderniseren van hun bestaande databases naar de AWS Cloud.
Amit Arora is een Solutions Architect met een focus op Database en Analytics bij AWS. Hij werkt samen met onze Financial Technology en Global Energy-klanten en AWS-gecertificeerde partners om technische assistentie te bieden en klantoplossingen te ontwerpen voor cloudmigratieprojecten, waarbij hij klanten helpt bij het migreren en moderniseren van hun bestaande databases naar de AWS Cloud.
 Jagadische Kumar is een Analytics Specialist Solution Architect bij AWS gericht op Amazon Redshift. Hij is zeer gepassioneerd door data-architectuur en helpt klanten bij het bouwen van analytische oplossingen op schaal op AWS.
Jagadische Kumar is een Analytics Specialist Solution Architect bij AWS gericht op Amazon Redshift. Hij is zeer gepassioneerd door data-architectuur en helpt klanten bij het bouwen van analytische oplossingen op schaal op AWS.
 Anusha Challa is een Senior Analytics Specialist Solution Architect bij AWS gericht op Amazon Redshift. Ze heeft veel klanten geholpen bij het bouwen van grootschalige datawarehouse-oplossingen in de cloud en op locatie. Anusha heeft een passie voor data-analyse en datawetenschap en klanten in staat stellen succes te behalen met hun grootschalige dataprojecten.
Anusha Challa is een Senior Analytics Specialist Solution Architect bij AWS gericht op Amazon Redshift. Ze heeft veel klanten geholpen bij het bouwen van grootschalige datawarehouse-oplossingen in de cloud en op locatie. Anusha heeft een passie voor data-analyse en datawetenschap en klanten in staat stellen succes te behalen met hun grootschalige dataprojecten.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/migrate-google-bigquery-to-amazon-redshift-using-aws-schema-conversion-tool-sct/

