De afgelopen jaren zijn datameren een reguliere architectuur geworden, en validatie van de datakwaliteit is een cruciale factor om de herbruikbaarheid en consistentie van de data te verbeteren. AWS Glue-gegevenskwaliteit vermindert de inspanning die nodig is om gegevens te valideren van dagen tot uren, en biedt computeraanbevelingen, statistieken en inzichten over de bronnen die nodig zijn om gegevensvalidatie uit te voeren.
Op AWS Glue Data Quality is gebouwd DeeQu, een open source-tool die bij Amazon is ontwikkeld en gebruikt om gegevenskwaliteitsstatistieken te berekenen en beperkingen voor de gegevenskwaliteit en veranderingen in de gegevensdistributie te verifiëren, zodat u zich kunt concentreren op het beschrijven van hoe gegevens eruit moeten zien in plaats van op het implementeren van algoritmen.
In dit bericht bieden we benchmarkresultaten van het uitvoeren van steeds complexere regelsets voor gegevenskwaliteit op een vooraf gedefinieerde testgegevensset. Als onderdeel van de resultaten laten we zien hoe AWS Glue Data Quality informatie biedt over de runtime van extractie-, transformatie- en laadtaken (ETL), de bronnen gemeten in termen van dataverwerkingseenheden (DPU's) en hoe u de kosten kunt volgen van het uitvoeren van AWS Glue Data Quality voor ETL-pijplijnen door aangepaste kostenrapportage te definiëren in AWS Cost Explorer.
Overzicht oplossingen
We beginnen met het definiëren van onze testdataset om te onderzoeken hoe AWS Glue Data Quality automatisch schaalt, afhankelijk van de invoerdatasets.
Gegevenssetdetails
De testgegevensset bevat 104 kolommen en 1 miljoen rijen, opgeslagen in Parquet-indeling. Jij kan download de dataset of maak het lokaal opnieuw met behulp van het Python-script in de bewaarplaats. Als u ervoor kiest om het generatorscript uit te voeren, moet u het Pandas en Mimesis pakketten in uw Python-omgeving:
Het datasetschema is een combinatie van numerieke, categorische en stringvariabelen om voldoende attributen te hebben om een combinatie van ingebouwde AWS Glue Data Quality te gebruiken soorten regels. Het schema repliceert enkele van de meest voorkomende kenmerken die voorkomen in financiële marktgegevens, zoals instrumentticker, verhandelde volumes en prijsvoorspellingen.
Regels voor gegevenskwaliteit
We categoriseren enkele van de ingebouwde AWS Glue Data Quality-regeltypen om de benchmarkstructuur te definiëren. De categorieën overwegen of de regels kolomcontroles uitvoeren die geen inspectie op rijniveau vereisen (eenvoudige regels), rij-voor-rij-analyse (middelgrote regels) of gegevenstypecontroles, waarbij uiteindelijk rijwaarden worden vergeleken met andere gegevensbronnen (complexe regels). ). De volgende tabel vat deze regels samen.
| Eenvoudige regels | Middelgrote regels | Complexe regels |
| Kolomtelling | DistinctValuesCount | Kolomwaarden |
| KolomDataType | Is compleet | Volledigheid |
| KolomBestaat | Som | ReferentiëleIntegriteit |
| KolomNamenMatchPattern | Standaardafwijking | KolomCorrelatie |
| Aantal rijen | Gemiddelde | RowCountMatch |
| Kolomlengte | . | . |
We definiëren acht verschillende AWS Glue ETL-taken waarin we de regelsets voor gegevenskwaliteit uitvoeren. Aan elke taak is een ander aantal regels voor gegevenskwaliteit gekoppeld. Elke taak heeft ook een bijbehorende door de gebruiker gedefinieerde kostentoewijzingstag die we gebruiken om later een kostenrapport voor de gegevenskwaliteit in AWS Cost Explorer te maken.
In de volgende tabel vindt u de definitie van platte tekst voor elke regelset.
| Taaknaam | Eenvoudige regels | Middelgrote regels | Complexe regels | Aantal regels | Tag | Definitie |
| regelset-0 | 0 | 0 | 0 | 0 | dqjob:rs0 | - |
| regelset-1 | 0 | 0 | 1 | 1 | dqjob:rs1 | Link |
| regelset-5 | 3 | 1 | 1 | 5 | dqjob:rs5 | Link |
| regelset-10 | 6 | 2 | 2 | 10 | dqjob:rs10 | Link |
| regelset-50 | 30 | 10 | 10 | 50 | dqjob:rs50 | Link |
| regelset-100 | 50 | 30 | 20 | 100 | dqjob:rs100 | Link |
| regelset-200 | 100 | 60 | 40 | 200 | dqjob:rs200 | Link |
| regelset-400 | 200 | 120 | 80 | 400 | dqjob:rs400 | Link |
Maak de AWS Glue ETL-taken met de regelsets voor gegevenskwaliteit
Wij uploaden de dataset testen naar Amazon eenvoudige opslagservice (Amazon S3) en ook twee extra CSV-bestanden die we zullen gebruiken om referentiële integriteitsregels te evalueren in AWS Glue Data Quality (isocodes.csv en uitwisselingen.csv) nadat ze zijn toegevoegd aan de AWS Glue Data Catalog. Voer de volgende stappen uit:
- Maak op de Amazon S3-console een nieuwe S3-bucket in uw account en upload de dataset testen.
- Maak een map in de S3-bucket met de naam
isocodesen upload het isocodes.csv bestand. - Maak een andere map in de S3-bucket genaamd exchange en upload het uitwisselingen.csv bestand.
- Voer op de AWS Glue-console twee AWS Glue-crawlers uit, één voor elke map, om de CSV-inhoud in de AWS Glue Data Catalog te registreren (
data_quality_catalog). Voor instructies, zie Een AWS Glue Crawler toevoegen.
De AWS Glue-crawlers genereren twee tabellen (exchanges en isocodes) als onderdeel van de AWS Glue Data Catalog.

Nu zullen we de AWS Identiteits- en toegangsbeheer (IAM) rol dat wordt overgenomen door de ETL-taken tijdens runtime:
- Maak op de IAM-console een nieuwe IAM-rol genaamd
AWSGlueDataQualityPerformanceRole - Voor Vertrouwd entiteitstypeselecteer AWS-service.
- Voor Service of gebruiksscenario, kiezen Lijm.
- Kies Volgende.

- Voor Toestemmingsbeleid, ga naar binnen
AWSGlueServiceRole - Kies Volgende.

- Maak een nieuw inline beleid en voeg dit toe (
AWSGlueDataQualityBucketPolicy) met de volgende inhoud. Vervang de tijdelijke aanduiding door de S3-bucketnaam die u eerder hebt gemaakt:
Vervolgens maken we een van de AWS Glue ETL-taken, ruleset-5.
- Op de AWS Glue-console, onder ETL-banen in het navigatievenster, kies Visuele ETL.
- In het Baan creëren sectie, kies Visuele ETL.x

- Voeg in de Visuele Editor een Gegevensbron – S3-bucket bronknooppunt:
- Voor S3-URL, voer de S3-map in die de testgegevensset bevat.
- Voor Data formaat, kiezen Parket.

- Maak een nieuw actieknooppunt, Transformeren: Evaluate-Data-Catalogus:
- Voor Knooppunt ouders, kies het knooppunt dat u hebt gemaakt.
- Voeg de regelset-5 definitie voor Regelset-editor.

- Scroll naar het einde en onder Prestatieconfiguratie, inschakelen Cachegegevens.

- Onder Details van de baanvoor IAM-rol, kiezen
AWSGlueDataQualityPerformanceRole.
- In het Tags sectie, definiëren dqjob labelen als rs5.
Deze tag zal voor elk van de ETL-taken voor gegevenskwaliteit verschillend zijn; we gebruiken ze in AWS Cost Explorer om de kosten van ETL-taken te bekijken.

- Kies Bespaar.
- Herhaal deze stappen met de rest van de regelsets om alle ETL-taken te definiëren.

Voer de AWS Glue ETL-taken uit
Voer de volgende stappen uit om de ETL-taken uit te voeren:
- Kies op de AWS Glue-console: Visuele ETL voor ETL-banen in het navigatievenster.
- Selecteer de ETL-taak en kies Voer de taak uit.
- Herhaal dit voor alle ETL-taken.

Wanneer de ETL-taken zijn voltooid, wordt de Bewaking van de uitvoering van taken pagina toont de taakdetails. Zoals weergegeven in de volgende schermafbeelding, a DPU-uren Er is een kolom beschikbaar voor elke ETL-taak.

Beoordeel de prestaties
De volgende tabel geeft een overzicht van de duur, DPU-uren en geschatte kosten van het uitvoeren van de acht verschillende regelsets voor gegevenskwaliteit op dezelfde testgegevensset. Houd er rekening mee dat alle regelsets zijn uitgevoerd met de volledige testgegevensset die eerder is beschreven (104 kolommen, 1 miljoen rijen).
| ETL-taaknaam | Aantal regels | Tag | Duur (sec) | # DPU-uren | # DPU's | Kosten ($) |
| regelset-400 | 400 | dqjob:rs400 | 445.7 | 1.24 | 10 | $0.54 |
| regelset-200 | 200 | dqjob:rs200 | 235.7 | 0.65 | 10 | $0.29 |
| regelset-100 | 100 | dqjob:rs100 | 186.5 | 0.52 | 10 | $0.23 |
| regelset-50 | 50 | dqjob:rs50 | 155.2 | 0.43 | 10 | $0.19 |
| regelset-10 | 10 | dqjob:rs10 | 152.2 | 0.42 | 10 | $0.18 |
| regelset-5 | 5 | dqjob:rs5 | 150.3 | 0.42 | 10 | $0.18 |
| regelset-1 | 1 | dqjob:rs1 | 150.1 | 0.42 | 10 | $0.18 |
| regelset-0 | 0 | dqjob:rs0 | 53.2 | 0.15 | 10 | $0.06 |
De kosten voor het evalueren van een lege regelset zijn bijna nul, maar zijn opgenomen omdat deze kunnen worden gebruikt als een snelle test om de IAM-rollen te valideren die zijn gekoppeld aan de AWS Glue Data Quality-taken en leesrechten voor de testdataset in Amazon S3. De kosten van datakwaliteitstaken beginnen pas te stijgen na evaluatie van regelsets met meer dan 100 regels, en blijven constant onder dat aantal.
We kunnen vaststellen dat de kosten voor het uitvoeren van de gegevenskwaliteit voor de grootste regelset in de benchmark (400 regels) nog steeds iets boven de $ 0.50 liggen.
Kostenanalyse van gegevenskwaliteit in AWS Cost Explorer
Om de ETL-taaktags van de gegevenskwaliteit in AWS Cost Explorer te kunnen zien, moet u dit doen activeer de door de gebruiker gedefinieerde kostentoewijzingstags kopen.
Nadat u door de gebruiker gedefinieerde tags hebt gemaakt en op uw resources hebt toegepast, kan het tot 24 uur duren voordat de tagsleutels op de pagina met kostentoewijzingstags verschijnen voor activering. Het kan vervolgens tot 24 uur duren voordat de tagsleutels worden geactiveerd.
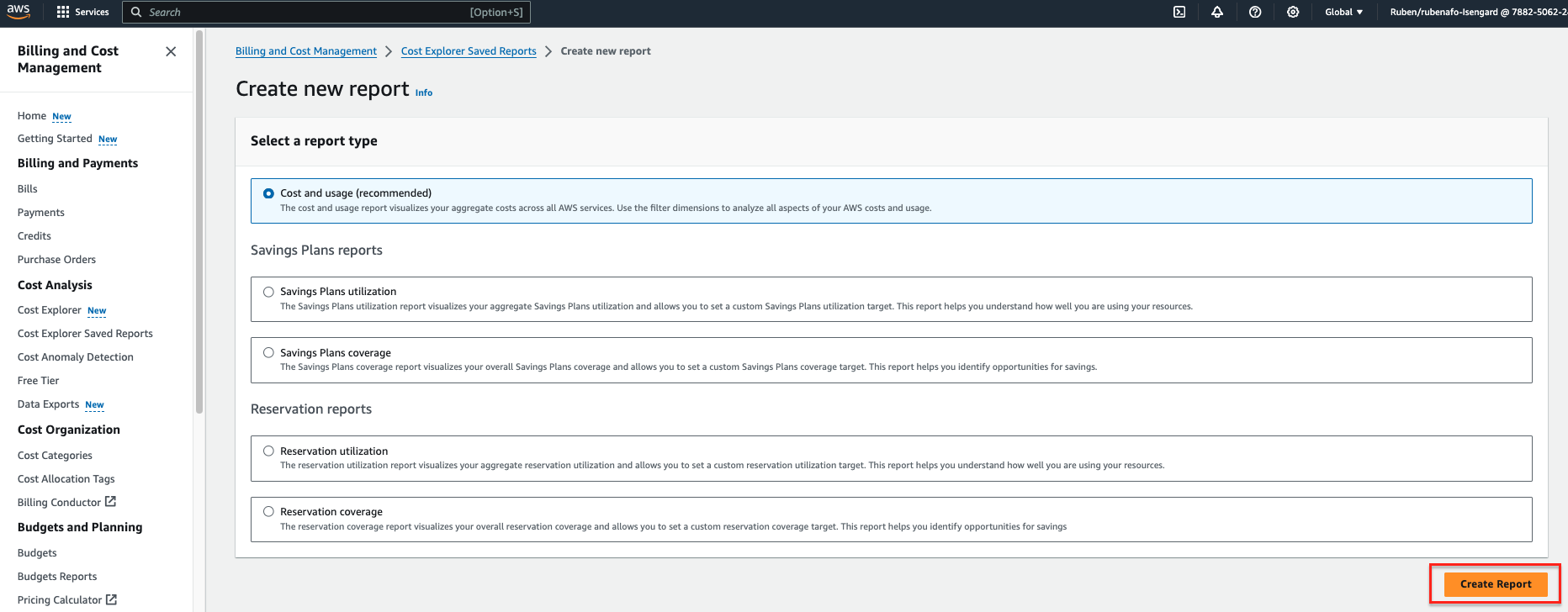
- Op de AWS Kosten Verkenner console, kies Kostenverkenner Opgeslagen rapporten in het navigatievenster.
- Kies Nieuw rapport maken.

- kies Kosten en gebruik als rapporttype.
- Kies Rapport maken.
- Voor Datumbereik, voer een datumbereik in.
- Voor granularityKiezen Dagelijkse.
- Voor Afmeting, kiezen Tag, kies dan de
dqjoblabel.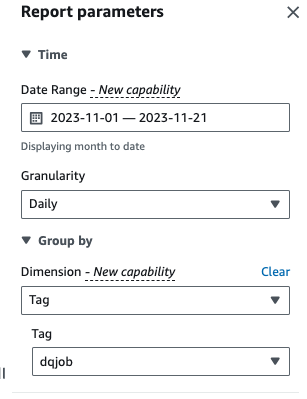
- Onder Toegepaste filters, kies de
dqjobtag en de acht tags die worden gebruikt in de regelsets voor gegevenskwaliteit (rs0, rs1, rs5, rs10, rs50, rs100, rs200 en rs400).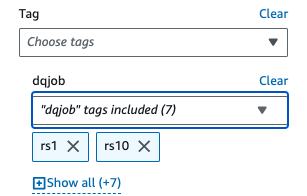
- Kies Solliciteer.
Het rapport Kosten en gebruik wordt bijgewerkt. Op de X-as worden de regelsettags voor gegevenskwaliteit weergegeven als categorieën. De Kosten en gebruik De grafiek in AWS Cost Explorer wordt vernieuwd en toont de totale maandelijkse kosten van de laatste uitgevoerde ETL-taken met gegevenskwaliteit, geaggregeerd per ETL-taak.

Opruimen
Voer de volgende stappen uit om de infrastructuur op te schonen en extra kosten te vermijden:
- Maak de S3-bucket leeg die oorspronkelijk is gemaakt om de testgegevensset op te slaan.
- Verwijder de ETL-taken die u in AWS Glue hebt gemaakt.
- Verwijder de
AWSGlueDataQualityPerformanceRoleIAM-rol. - Verwijder het aangepaste rapport dat is gemaakt in AWS Cost Explorer.
Conclusie
AWS Glue Data Quality biedt een efficiënte manier om datakwaliteitsvalidatie op te nemen als onderdeel van ETL-pijplijnen en schaalt automatisch om toenemende datavolumes op te vangen. De ingebouwde typen regels voor gegevenskwaliteit bieden een breed scala aan opties om de gegevenskwaliteitscontroles aan te passen en zich te concentreren op hoe uw gegevens eruit moeten zien in plaats van ongedifferentieerde logica te implementeren.
In deze benchmarkanalyse hebben we laten zien hoe gangbare AWS Glue Data Quality-regelsets weinig of geen overhead hebben, terwijl in complexe gevallen de kosten lineair stijgen. We hebben ook bekeken hoe u AWS Glue Data Quality-taken kunt taggen om kosteninformatie beschikbaar te maken in AWS Cost Explorer voor snelle rapportage.
AWS Glue-gegevenskwaliteit is algemeen verkrijgbaar in alle AWS-regio's waar AWS Glue beschikbaar is. Lees meer over AWS Glue Data Quality en AWS Glue Data Catalog in Aan de slag met AWS Glue Data Quality uit de AWS Glue Data Catalog.
Over de auteurs
 Ruben Afonso is een Global Financial Services Solutions Architect bij AWS. Hij werkt graag aan analytics en AI/ML-uitdagingen, met een passie voor automatisering en optimalisatie. Als hij niet aan het werk is, vindt hij het leuk om verborgen plekken buiten de gebaande paden in Barcelona te vinden.
Ruben Afonso is een Global Financial Services Solutions Architect bij AWS. Hij werkt graag aan analytics en AI/ML-uitdagingen, met een passie voor automatisering en optimalisatie. Als hij niet aan het werk is, vindt hij het leuk om verborgen plekken buiten de gebaande paden in Barcelona te vinden.
 Kalyan Kumar Neelampudi (KK) is een Specialist Partner Solutions Architect (Data Analytics & Generative AI) bij AWS. Hij treedt op als technisch adviseur en werkt samen met verschillende AWS-partners om praktijken rond data-analyse en AI/ML-workloads te ontwerpen, implementeren en bouwen. Buiten zijn werk is hij een badmintonliefhebber en culinaire avonturier. Hij ontdekt de lokale keuken en reist samen met zijn partner om nieuwe smaken en ervaringen te ontdekken.
Kalyan Kumar Neelampudi (KK) is een Specialist Partner Solutions Architect (Data Analytics & Generative AI) bij AWS. Hij treedt op als technisch adviseur en werkt samen met verschillende AWS-partners om praktijken rond data-analyse en AI/ML-workloads te ontwerpen, implementeren en bouwen. Buiten zijn werk is hij een badmintonliefhebber en culinaire avonturier. Hij ontdekt de lokale keuken en reist samen met zijn partner om nieuwe smaken en ervaringen te ontdekken.

Gonzalo herreros is een Senior Big Data Architect in het AWS Glue-team.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/measure-performance-of-aws-glue-data-quality-for-etl-pipelines/

