
Afbeelding door auteur
Het hebben van een goede titel is cruciaal voor het succes van een artikel. Mensen besteden slechts één seconde (als we het boek van Ryan Holiday mogen geloven). “Vertrouw me, ik lieg” beslissen of u op de titel klikt om het hele artikel te openen. De media zijn geobsedeerd door optimalisatie klikfrequentie (CTR), het aantal klikken dat een titel ontvangt, gedeeld door het aantal keren dat de titel wordt weergegeven. Het hebben van een click-bait-titel verhoogt de CTR. De media zullen waarschijnlijk een titel kiezen met een hogere CTR tussen de twee titels, omdat dit meer inkomsten zal genereren.
Ik ben niet echt van het onder druk zetten van advertentie-inkomsten. Het gaat meer om het verspreiden van mijn kennis en expertise. En toch hebben kijkers beperkte tijd en aandacht, terwijl de inhoud op internet vrijwel onbeperkt is. Ik moet dus concurreren met andere contentmakers om de aandacht van kijkers te trekken.
Hoe kies ik een goede titel voor mijn volgende artikel? Natuurlijk heb ik een reeks opties nodig waaruit ik kan kiezen. Hopelijk kan ik ze zelf genereren of aan ChatGPT vragen. Maar wat moet ik nu doen? Als datawetenschapper stel ik voor om een A/B/N-test uit te voeren om op een datagestuurde manier te begrijpen welke optie de beste is. Maar er is een probleem. Ten eerste moet ik snel beslissen omdat inhoud snel verloopt. Ten tweede zijn er mogelijk niet genoeg waarnemingen om een statistisch significant verschil in CTR's te ontdekken, aangezien deze waarden relatief laag zijn. Er zijn dus andere opties dan een paar weken wachten met beslissen.
Hopelijk is er een oplossing! Ik kan een machine learning-algoritme met meerdere armen gebruiken dat zich aanpast aan de gegevens die we waarnemen over het gedrag van kijkers. Hoe meer mensen op een bepaalde optie in de set klikken, hoe meer verkeer we aan deze optie kunnen toewijzen. In dit artikel leg ik kort uit wat een “Bayesiaanse meerarmige bandiet” is en laat ik zien hoe deze in de praktijk werkt met behulp van Python.
Meerarmige bandieten zijn machine learning-algoritmen. Het Bayesiaanse type maakt gebruik van Thompson-bemonstering om een optie te kiezen op basis van onze eerdere overtuigingen over de waarschijnlijkheidsverdelingen van CTR's die daarna worden bijgewerkt op basis van de nieuwe gegevens. Al deze woorden over waarschijnlijkheidstheorie en wiskundige statistiek kunnen complex en intimiderend klinken. Laat me het hele concept uitleggen met zo weinig mogelijk formules.
Stel dat er slechts twee titels zijn waaruit u kunt kiezen. We hebben geen idee van hun CTR's. Maar we willen de best presterende titel hebben. We hebben meerdere opties. De eerste is om de titel te kiezen waar we meer in geloven. Zo werkte het jarenlang in de branche. De tweede wijst 50% van het binnenkomende verkeer toe aan de eerste titel en 50% aan de tweede. Dit werd mogelijk met de opkomst van digitale media, waarbij je kunt beslissen welke tekst precies moet worden weergegeven wanneer een kijker een lijst met artikelen opvraagt om te lezen. Met deze aanpak kunt u er zeker van zijn dat 50% van het verkeer is toegewezen aan de best presterende optie. Is dit een limiet? Natuurlijk niet!
Sommige mensen zouden het artikel binnen een paar minuten na publicatie lezen. Sommige mensen zouden het binnen een paar uur of dagen doen. Dit betekent dat we kunnen observeren hoe ‘vroege’ lezers op verschillende titels reageerden en de verkeerstoewijzing van 50/50 kunnen verschuiven en een beetje meer kunnen toewijzen aan de beter presterende optie. Na enige tijd kunnen we de CTR’s weer berekenen en de splitsing aanpassen. Binnen de limiet willen we de verkeerstoewijzing aanpassen nadat elke nieuwe kijker op de titel klikt of deze overslaat. We hebben een raamwerk nodig om de verkeerstoewijzing wetenschappelijk en geautomatiseerd aan te passen.
Hier komen de stelling van Bayes, de bètaverdeling en de Thompson-steekproeven.
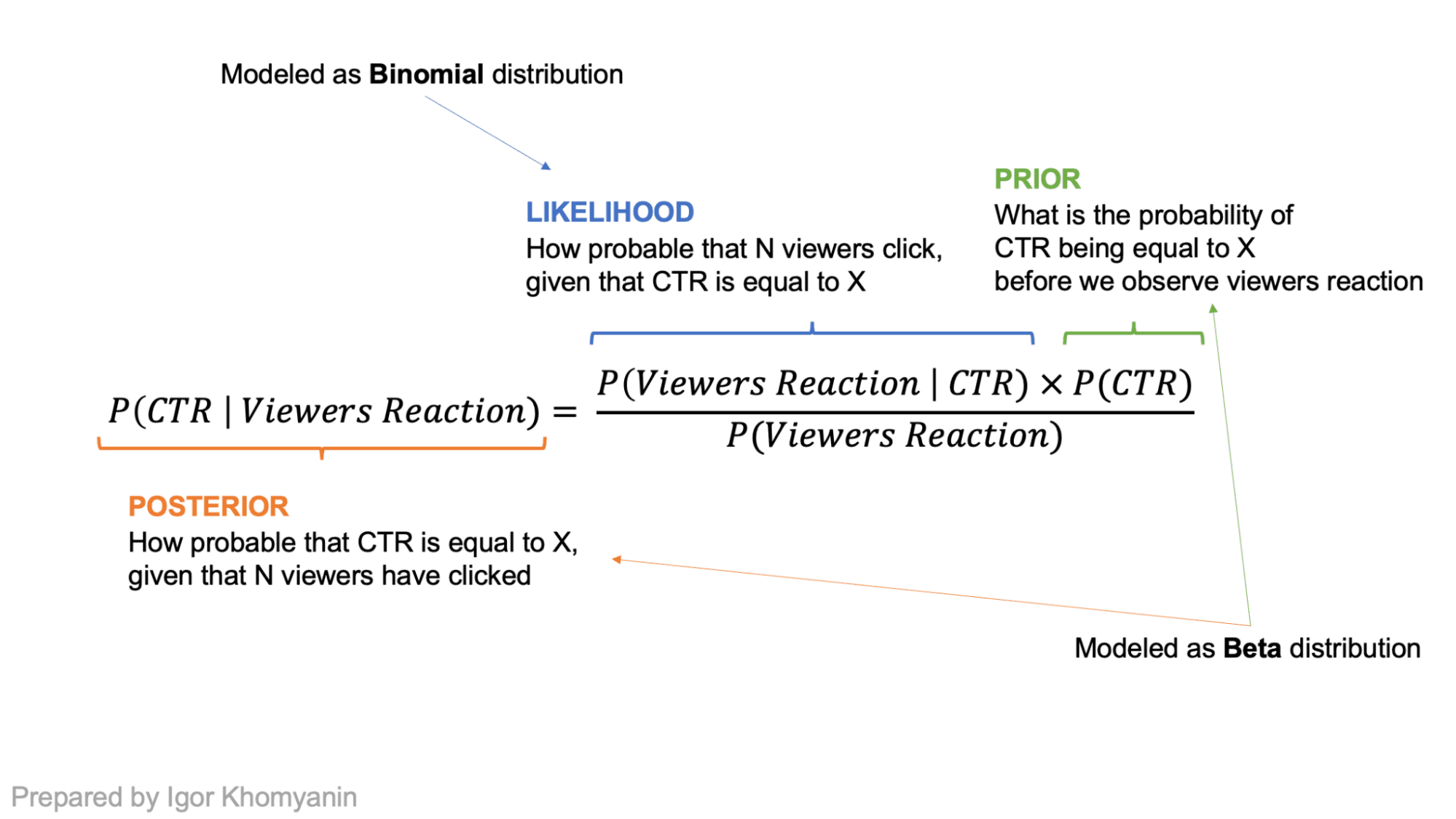
Laten we aannemen dat de CTR van een artikel een willekeurige variabele ‘theta’ is. Het is zo ontworpen dat het ergens tussen 0 en 1 ligt. Als we geen eerdere overtuigingen hebben, kan het met gelijke waarschijnlijkheid elk getal tussen 0 en 1 zijn. Nadat we enkele gegevens “x” hebben waargenomen, kunnen we onze overtuigingen aanpassen en een nieuwe verdeling voor “theta” krijgen die dichter bij 0 of 1 zal liggen met behulp van de stelling van Bayes.
Het aantal mensen dat op de titel klikt, kan worden gemodelleerd als Binomiale verdeling waarbij “n” het aantal bezoekers is dat de titel ziet, en “p” de CTR van de titel is. Dit is onze waarschijnlijkheid! Als we de prior (onze overtuiging over de verdeling van de CTR) modelleren als een Beta-distributie en als we de binomiale waarschijnlijkheid nemen, zou de posterieure ook een bètaverdeling zijn met verschillende parameters! In dergelijke gevallen wordt de bètadistributie a genoemd conjugeren voorafgaand naar de waarschijnlijkheid.
Het bewijs van dat feit is niet zo moeilijk, maar vereist enige wiskundige oefening die niet relevant is in de context van dit artikel. Zie het prachtige bewijs hier:
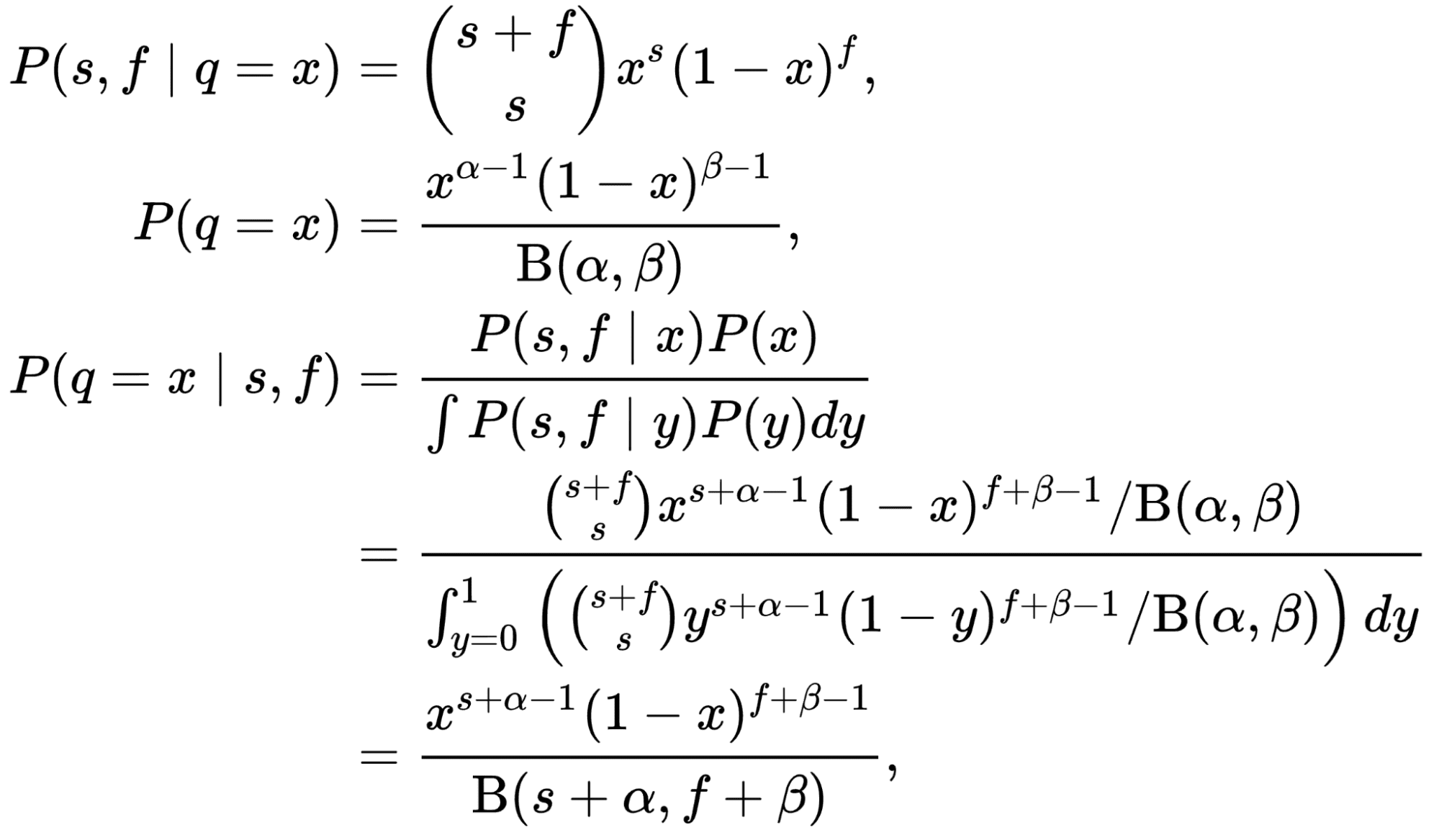
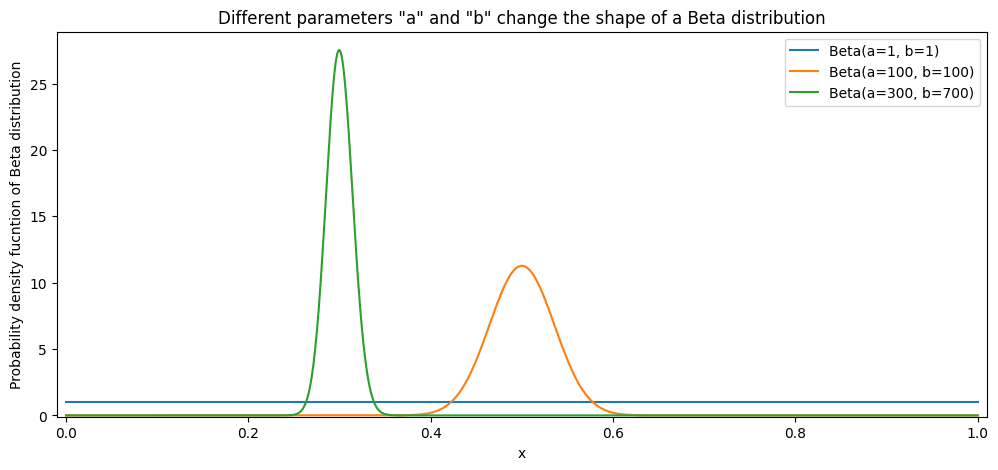
De bètaverdeling wordt begrensd door 0 en 1, waardoor het een perfecte kandidaat is om een CTR-verdeling te modelleren. We kunnen uitgaan van ‘a = 1’ en ‘b = 1’ als bètadistributieparameters die de CTR modelleren. In dit geval zouden we geen enkele overtuiging hebben over de distributie, waardoor elke CTR even waarschijnlijk is. Vervolgens kunnen we beginnen met het toevoegen van waargenomen gegevens. Zoals u kunt zien, verhoogt elke “succes” of “klik” “a” met 1. Elke “mislukking” of “overslaan” verhoogt “b” met 1. Dit vertekent de verdeling van de CTR, maar verandert niets aan de distributiefamilie. Het is nog steeds een bètadistributie!
We gaan ervan uit dat de CTR kan worden gemodelleerd als een bètadistributie. Dan zijn er twee titelopties en twee distributies. Hoe kiezen we wat we aan een kijker laten zien? Daarom wordt het algoritme een ‘meerarmige bandiet’ genoemd. Op het moment dat een kijker om een titel vraagt, ‘trek je beide armen’ en bemonster je de CTR’s. Daarna vergelijkt u waarden en toont u een titel met de hoogste bemonsterde CTR. Vervolgens klikt de kijker of slaat deze over. Als er op de titel wordt geklikt, past u de bètadistributieparameter 'a' van deze optie aan, wat staat voor 'successen'. Anders verhoogt u de bètadistributieparameter 'b' van deze optie, wat 'mislukkingen' betekent. Dit vertekent de verdeling en voor de volgende kijker zal de kans dat hij voor deze optie (of “arm”) kiest, anders zijn dan voor andere opties.
Na verschillende iteraties zal het algoritme een schatting van de CTR-verdelingen hebben. Het nemen van steekproeven uit deze distributie zal voornamelijk de hoogste CTR-arm activeren, maar nieuwe gebruikers nog steeds in staat stellen andere opties te verkennen en de toewijzing aan te passen.
Nou, dit werkt allemaal in theorie. Is het echt beter dan de 50/50-verdeling die we eerder hebben besproken?
Alle code om een simulatie te maken en grafieken te bouwen, is te vinden in mijn GitHub-opslagplaats.
Zoals eerder vermeld, hebben we slechts twee titels om uit te kiezen. We hebben geen eerdere opvattingen over de CTR's van deze titel. We gaan dus uit van a=1 en b=1 voor beide bètadistributies. Ik zal een eenvoudig inkomend verkeer simuleren, uitgaande van een rij kijkers. We weten precies of de vorige kijker heeft “geklikt” of “overgeslagen” voordat een titel aan de nieuwe kijker werd getoond. Om ‘klik’- en ‘overslaan’-acties te simuleren, moet ik enkele echte CTR’s definiëren. Laat ze 5% en 7% zijn. Het is essentieel om te vermelden dat het algoritme niets over deze waarden weet. Ik heb ze nodig om een klik te simuleren; in de echte wereld zou je daadwerkelijke klikken hebben. Ik zal een supervooringenomen munt opgooien voor elke titel die kop oplevert met een waarschijnlijkheid van 5% of 7%. Als het kop is, dan is er een klik.
Het algoritme is dan eenvoudig:
- Op basis van de waargenomen gegevens kunt u voor elke titel een bètaverdeling verkrijgen
- Voorbeeld-CTR van beide distributies
- Begrijp welke CTR hoger is en draai een relevante munt op
- Begrijp of er een klik was of niet
- Verhoog parameter “a” met 1 als er een klik was; verhoog parameter “b” met 1 als er sprake is van een overslag
- Herhaal dit totdat er gebruikers in de wachtrij staan.
Om de kwaliteit van het algoritme te begrijpen, slaan we ook een waarde op die het aandeel kijkers vertegenwoordigt dat wordt blootgesteld aan de tweede optie, omdat deze een hogere “echte” CTR heeft. Laten we een 50/50-splitstrategie als tegenhanger gebruiken om een basiskwaliteit te verkrijgen.
Code door auteur
Na 1000 gebruikers in de wachtrij heeft onze “meerarmige bandiet” al een goed inzicht in wat de CTR’s zijn.
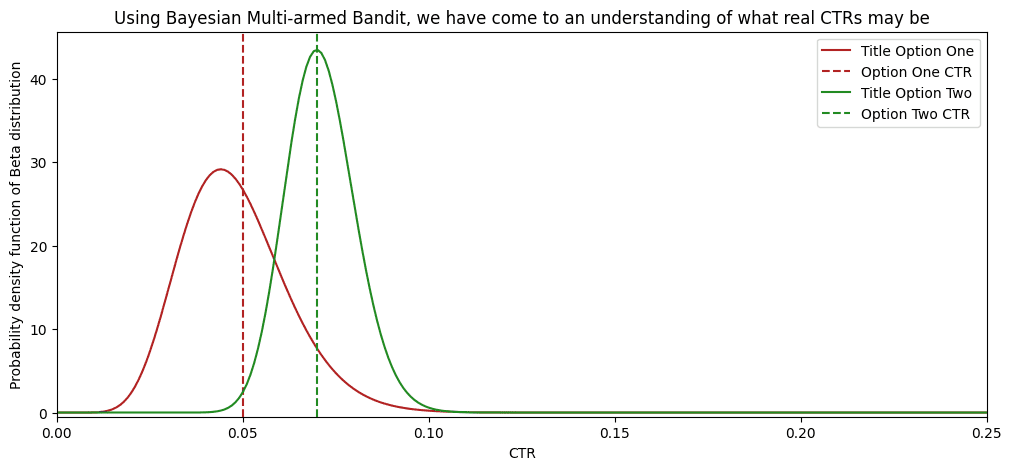
En hier is een grafiek die laat zien dat een dergelijke strategie betere resultaten oplevert. Na 100 kijkers overtrof de “meerarmige bandiet” een aandeel van 50% van de kijkers die de tweede optie aanboden. Omdat steeds meer bewijsmateriaal de tweede titel ondersteunde, wees het algoritme steeds meer verkeer toe aan de tweede titel. Bijna 80% van alle kijkers heeft de best presterende optie gezien! Terwijl in de 50/50-verdeling slechts 50% van de mensen de best presterende optie heeft gezien.
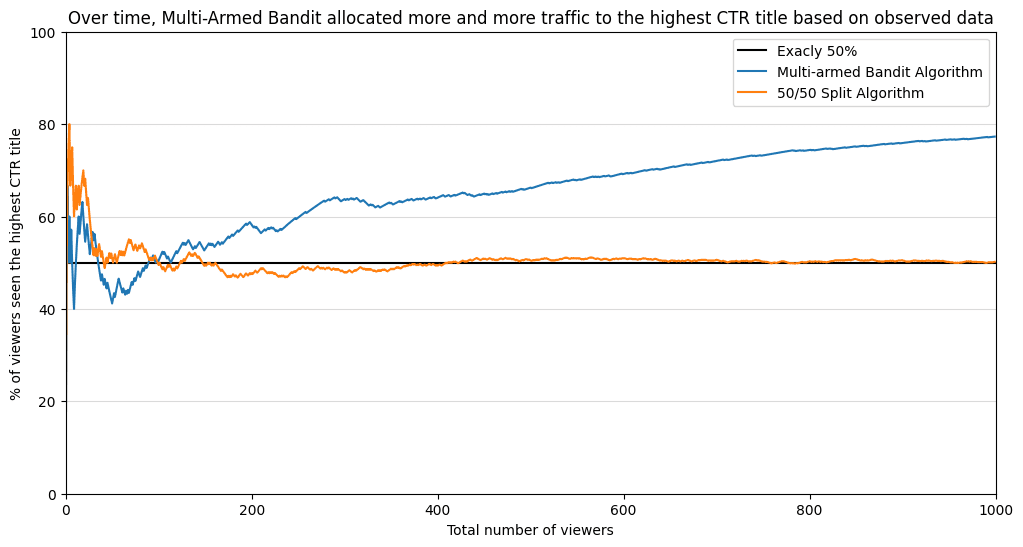
Bayesiaanse meerarmige bandiet stelde 25% extra kijkers bloot aan een beter presterende optie! Met meer binnenkomende gegevens zal het verschil tussen deze twee strategieën alleen maar groter worden.
Natuurlijk zijn ‘meerarmige bandieten’ niet perfect. Real-time bemonstering en weergave van opties is kostbaar. Het zou het beste zijn om over een goede infrastructuur te beschikken om het geheel met de gewenste latentie te implementeren. Bovendien wil je je kijkers misschien niet in paniek brengen door titels te veranderen. Als je genoeg verkeer hebt om een snelle A/B uit te voeren, doe dat dan! Wijzig vervolgens de titel één keer handmatig. Dit algoritme kan echter in veel andere toepassingen dan media worden gebruikt.
Ik hoop dat je nu begrijpt wat een ‘meerarmige bandiet’ is en hoe deze kan worden gebruikt om te kiezen tussen twee opties die zijn aangepast aan de nieuwe gegevens. Ik concentreerde me specifiek niet op wiskunde en formules, omdat de leerboeken dit beter zouden uitleggen. Ik ben van plan een nieuwe technologie te introduceren en er interesse in te wekken!
Als u vragen heeft, aarzel dan niet om contact op te nemen LinkedIn.
Het notitieboekje met alle code vind je in mijn GitHub repo.
Igor Khomyanin is een datawetenschapper bij Salmon, met eerdere datafuncties bij Yandex en McKinsey. Ik ben gespecialiseerd in het extraheren van waarde uit data met behulp van Statistiek en Datavisualisatie.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.kdnuggets.com/beyond-guesswork-leveraging-bayesian-statistics-for-effective-article-title-selection?utm_source=rss&utm_medium=rss&utm_campaign=beyond-guesswork-leveraging-bayesian-statistics-for-effective-article-title-selection

