Voorspellend onderhoud is een datagestuurde onderhoudsstrategie voor het bewaken van industriële bedrijfsmiddelen om afwijkingen in de werking en gezondheid van apparatuur op te sporen die kunnen leiden tot apparatuurstoringen. Door proactieve bewaking van de toestand van een asset kan onderhoudspersoneel worden gewaarschuwd voordat er zich problemen voordoen, waardoor kostbare ongeplande downtime wordt vermeden, wat op zijn beurt leidt tot een toename van de Overall Equipment Effectiveness (OEE).
Het bouwen van de benodigde machine learning (ML)-modellen voor voorspellend onderhoud is echter complex en tijdrovend. Het vereist verschillende stappen, waaronder het voorverwerken van de gegevens, het bouwen, trainen, evalueren en vervolgens afstemmen van meerdere ML-modellen die op betrouwbare wijze afwijkingen in de gegevens van uw asset kunnen voorspellen. De afgewerkte ML-modellen moeten vervolgens worden ingezet en voorzien van live data voor online voorspellingen (inferencing). Het opschalen van dit proces naar meerdere bedrijfsmiddelen van verschillende typen en bedrijfsprofielen vergt vaak te veel middelen om een bredere acceptatie van voorspellend onderhoud haalbaar te maken.
met Amazon Lookout voor apparatuur, kunt u naadloos sensorgegevens voor uw industriële apparatuur analyseren om abnormaal machinegedrag te detecteren - zonder dat ML-ervaring vereist is.
Wanneer klanten gebruiksscenario's voor voorspellend onderhoud implementeren met Lookout for Equipment, kiezen ze meestal uit drie opties om het project te leveren: zelf bouwen, samenwerken met een AWS-partner of AWS Professional Services gebruiken. Voordat besluitvormers, zoals fabrieksmanagers, betrouwbaarheids- of onderhoudsmanagers en lijnleiders, zich aan dergelijke projecten committeren, willen ze bewijs zien van de potentiële waarde die voorspellend onderhoud kan ontdekken in hun bedrijfstakken. Een dergelijke evaluatie wordt meestal uitgevoerd als onderdeel van een proof of concept (POC) en vormt de basis voor een business case.
Dit bericht is bedoeld voor zowel technische als niet-technische gebruikers: het biedt een effectieve aanpak voor het evalueren van Lookout for Equipment met uw eigen gegevens, zodat u de zakelijke waarde kunt meten die het biedt voor uw voorspellende onderhoudsactiviteiten.
Overzicht oplossingen
In dit bericht leiden we u door de stappen om een dataset in Lookout for Equipment op te nemen, de kwaliteit van de sensorgegevens te beoordelen, een model te trainen en het model te evalueren. Als u deze stappen voltooit, krijgt u meer inzicht in de gezondheid van uw apparatuur.
Voorwaarden
Alles wat u nodig heeft om aan de slag te gaan, is een AWS-account en een geschiedenis van sensorgegevens voor activa die kunnen profiteren van een voorspellende onderhoudsbenadering. De sensorgegevens moeten worden opgeslagen als CSV-bestanden in een Amazon eenvoudige opslagservice (Amazon S3) bucket van uw account. Uw IT-team moet aan deze vereisten kunnen voldoen door te verwijzen naar Opmaak van uw gegevens. Om het simpel te houden, is het het beste om alle sensorgegevens in één CSV-bestand op te slaan, waarbij de rijen tijdstempels zijn en de kolommen individuele sensoren (maximaal 300).
Zodra je je dataset beschikbaar hebt op Amazon S3, kun je de rest van dit bericht volgen.
Voeg een dataset toe
Lookout for Equipment gebruikt projecten om de middelen te organiseren voor het evalueren van industriële apparatuur. Voer de volgende stappen uit om een nieuw project aan te maken:
- Kies in de Lookout for Equipment-console Maak een project aan.

- Voer een projectnaam in en kies Maak een project aan.
Nadat het project is gemaakt, kunt u een gegevensset opnemen die wordt gebruikt om een model voor afwijkingsdetectie te trainen en te evalueren.
- Kies op de projectpagina Gegevensset toevoegen.

- Voor S3 locatie, voer de S3-locatie (exclusief de bestandsnaam) van uw gegevens in.
- Voor Schema detectie methodeselecteer Op bestandsnaam, waarbij wordt aangenomen dat alle sensorgegevens voor een asset zijn opgenomen in één CSV-bestand op de opgegeven S3-locatie.
- Houd de andere instellingen als standaard en kies Begin met inslikken om het opnameproces te starten.
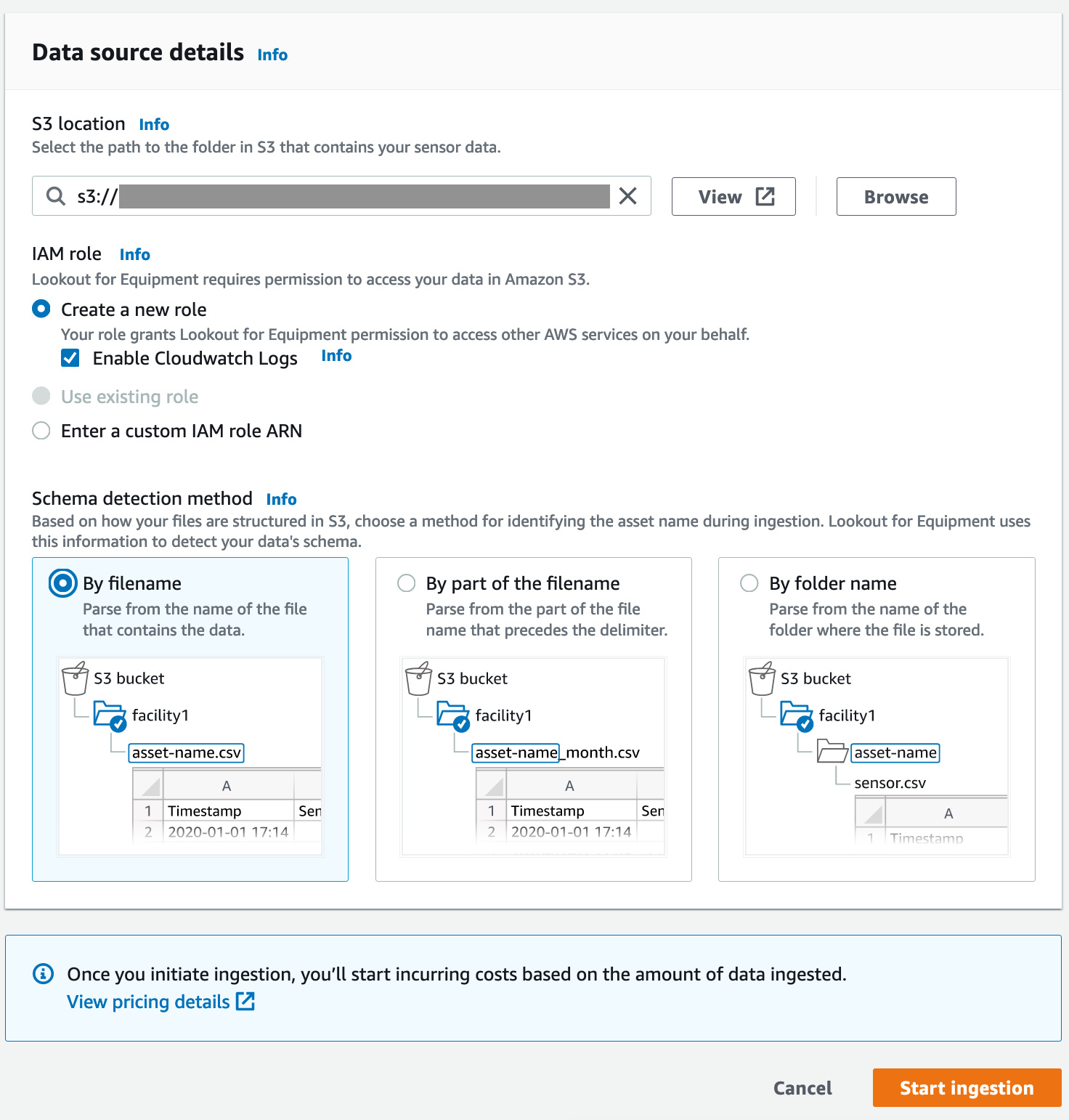
Inslikken kan ongeveer 10-20 minuten duren. Op de achtergrond voert Lookout for Equipment de volgende taken uit:
- Het detecteert de structuur van de data, zoals sensornamen en datatypes.
- De tijdstempels tussen sensoren worden uitgelijnd en ontbrekende waarden worden opgevuld (met de laatst bekende waarde).
- Dubbele tijdstempels worden verwijderd (alleen de laatste waarde voor elke tijdstempel wordt behouden).
- Lookout for Equipment gebruikt meerdere soorten algoritmen voor het bouwen van het ML-afwijkingsdetectiemodel. Tijdens de opnamefase bereidt het de gegevens voor zodat deze kunnen worden gebruikt voor het trainen van die verschillende algoritmen.
- Het analyseert de meetwaarden en beoordeelt elke sensor als hoge, gemiddelde of lage kwaliteit.
- Wanneer de opname van de gegevensset is voltooid, inspecteert u deze door te kiezen Gegevensset bekijken onder Stap 2 van de projectpagina.

Bij het maken van een afwijkingsdetectiemodel is het selecteren van de beste sensoren (de sensoren met de hoogste gegevenskwaliteit) vaak cruciaal voor het trainen van modellen die bruikbare inzichten opleveren. De Gegevenssetdetails sectie toont de verdeling van sensorclassificaties (tussen hoog, gemiddeld en laag), terwijl de tabel informatie over elke sensor afzonderlijk weergeeft (inclusief de sensornaam, het datumbereik en de classificatie voor de sensorgegevens). Met dit gedetailleerde rapport kunt u een weloverwogen beslissing nemen over welke sensoren u gaat gebruiken om uw modellen te trainen. Als een groot deel van de sensoren in uw dataset als gemiddeld of laag wordt beoordeeld, is er mogelijk een gegevensprobleem dat moet worden onderzocht. Indien nodig kunt u het gegevensbestand opnieuw uploaden naar Amazon S3 en de gegevens opnieuw opnemen door te kiezen Dataset vervangen.

Door de invoer van de sensorkwaliteit in de detailtabel te kiezen, kunt u details bekijken over de validatiefouten die resulteren in een bepaalde beoordeling. Door deze details weer te geven en aan te pakken, kunt u ervoor zorgen dat de informatie die aan het model wordt verstrekt, van hoge kwaliteit is. U kunt bijvoorbeeld zien dat een signaal onverwacht grote hoeveelheden ontbrekende waarden bevat. Is dit een probleem met de gegevensoverdracht of werkte de sensor niet goed? Tijd om dieper in uw data te duiken!

Voor meer informatie over de verschillende soorten sensorproblemen Kijk uit voor apparatuuradressen bij het beoordelen van uw sensoren, zie Evalueren van sensorkwaliteiten. Ontwikkelaars kunnen deze inzichten ook extraheren met behulp van de ListSensorStatistics-API.
Als u tevreden bent met uw dataset, kunt u doorgaan naar de volgende stap van het trainen van een model voor het voorspellen van afwijkingen.
Train een model
Lookout for Equipment maakt het trainen van modellen voor specifieke sensoren mogelijk. Dit geeft u de flexibiliteit om te experimenteren met verschillende sensorcombinaties of sensoren met een lage grading uit te sluiten. Voer de volgende stappen uit:
- In het Details per sensor sectie op de gegevenssetpagina, selecteert u de sensoren die u in uw model wilt opnemen en kiest u Maak een model.

- Voor Modelnaam, voer een modelnaam in en maak uw keuze Volgende.

- In het Trainings- en evaluatie-instellingen sectie, configureert u de invoergegevens van het model.
Om modellen effectief te trainen, moeten de gegevens worden opgesplitst in afzonderlijke trainings- en evaluatiesets. U kunt in deze sectie datumbereiken voor deze splitsing definiëren, samen met een bemonsteringsfrequentie voor de sensoren. Hoe kies je deze splitsing? Stel je de volgende situatie voor:
- Lookout for Equipment verwacht ten minste 3 maanden aan gegevens in het trainingsbereik, maar de optimale hoeveelheid gegevens wordt bepaald door uw use case. Er kunnen meer gegevens nodig zijn om rekening te houden met elk type seizoensgebondenheid of operationele cycli die uw productie doormaakt.
- Er zijn geen beperkingen op het evaluatiebereik. We raden u echter aan een evaluatiebereik in te stellen dat bekende afwijkingen omvat. Op deze manier kunt u testen of Lookout for Equipment in staat is om interessante gebeurtenissen vast te leggen die tot deze afwijkingen leiden.
Door de bemonsteringsfrequentie te specificeren, verkleint Lookout for Equipment effectief de sensorgegevens, wat de trainingstijd aanzienlijk kan verkorten. De ideale bemonsteringsfrequentie hangt af van het soort afwijkingen dat u vermoedt in uw gegevens: voor afwijkingen met een trage trend is het selecteren van een bemonsteringsfrequentie tussen 1 en 10 minuten meestal een goed uitgangspunt. Het kiezen van lagere waarden (verhogen van de bemonsteringsfrequentie) resulteert in langere trainingstijden, terwijl hogere waarden (lage bemonsteringsfrequentie) de trainingstijd verkorten met het risico leidende indicatoren uit uw gegevens te verwijderen die relevant zijn voor het voorspellen van de afwijkingen.

Om alleen te trainen op relevante delen van uw gegevens waar de industriële apparatuur in werking was, kunt u uitschakeldetectie uitvoeren door een sensor te selecteren en een drempel te definiëren die aangeeft of de apparatuur aan of uit stond. Dit is van cruciaal belang omdat Lookout for Equipment hierdoor tijdsperioden voor training kan filteren wanneer de machine is uitgeschakeld. Dit betekent dat het model alleen relevante bedrijfstoestanden leert en niet alleen wanneer de machine uit staat.
- Specificeer uw off-time detectie en maak vervolgens uw keuze Volgende.

Optioneel kunt u gegevenslabels leveren, die onderhoudsperioden of bekende uitvaltijden van apparatuur aangeven. Als u over dergelijke gegevens beschikt, kunt u een CSV-bestand maken met de gegevens in een gedocumenteerd formaat, upload het naar Amazon S3 en gebruik het voor modeltraining. Het verstrekken van labels kan de nauwkeurigheid van het getrainde model verbeteren door Lookout for Equipment te vertellen waar het bekende afwijkingen kan verwachten.
- Geef eventuele gegevenslabels op en kies vervolgens Volgende.

- Controleer uw instellingen in de laatste stap. Als alles er goed uitziet, kun je de training starten.
Afhankelijk van de grootte van uw dataset, het aantal sensoren en de bemonsteringsfrequentie kan het trainen van het model enkele ogenblikken tot enkele uren duren. Als u bijvoorbeeld 1 jaar aan gegevens gebruikt met een bemonsteringsfrequentie van 5 minuten met 100 sensoren en geen labels, duurt het trainen van een model minder dan 15 minuten. Als uw gegevens daarentegen een groot aantal labels bevatten, kan de trainingstijd aanzienlijk toenemen. In een dergelijke situatie kunt u de trainingstijd verkorten door aangrenzende labelperiodes samen te voegen om hun aantal te verminderen.
Je hebt zojuist je eerste anomaliedetectiemodel getraind zonder enige ML-kennis! Laten we nu eens kijken naar de inzichten die u kunt krijgen van een getraind model.
Evalueer een getraind model
Wanneer de modeltraining is voltooid, kunt u de details van het model bekijken door te kiezen Bekijk modellen op de projectpagina en kies vervolgens de naam van het model.
Naast algemene informatie zoals naam, status en trainingstijd, geeft de modelpagina een overzicht van de prestatiegegevens van het model, zoals het aantal gedetecteerde gelabelde gebeurtenissen (ervan uitgaande dat u labels hebt opgegeven), de gemiddelde waarschuwingstijd en het aantal afwijkende apparatuurgebeurtenissen dat is gedetecteerd buiten de labelreeksen. De volgende schermafbeelding toont een voorbeeld. Voor een betere zichtbaarheid worden de gedetecteerde gebeurtenissen gevisualiseerd (de rode balken bovenaan het lint) samen met de gelabelde gebeurtenissen (de blauwe balken onderaan het lint).

U kunt gedetecteerde gebeurtenissen selecteren door de rode gebieden te kiezen die afwijkingen vertegenwoordigen in de tijdlijnweergave om aanvullende informatie te krijgen. Dit bevat:
- De start- en eindtijden van het evenement en de duur ervan.
- Een staafdiagram met de sensoren die volgens het model het meest relevant zijn voor het waarom van een afwijking. De procentuele scores vertegenwoordigen de berekende totale bijdrage.

Met deze inzichten kunt u samenwerken met uw proces- of betrouwbaarheidsingenieurs om verdere oorzaakevaluaties van gebeurtenissen uit te voeren en uiteindelijk onderhoudsactiviteiten te optimaliseren, ongeplande uitvaltijden te verminderen en suboptimale bedrijfsomstandigheden te identificeren.
Ter ondersteuning van voorspellend onderhoud met realtime inzichten (inferentie), ondersteunt Lookout for Equipment live evaluatie van online gegevens via inferentieschema's. Dit vereist dat sensorgegevens periodiek naar Amazon S3 worden geüpload, en vervolgens voert Lookout for Equipment conclusies uit op de gegevens met het getrainde model, waardoor er in real-time afwijkingen worden gescoord. De gevolgtrekkingsresultaten, inclusief een geschiedenis van gedetecteerde afwijkende gebeurtenissen, kunnen worden bekeken op de Lookout for Equipment-console.

De resultaten worden ook weggeschreven naar bestanden in Amazon S3, waardoor integratie met andere systemen mogelijk is, bijvoorbeeld een geautomatiseerd onderhoudsbeheersysteem (CMMS), of om operaties en onderhoudspersoneel in realtime op de hoogte te stellen.
Naarmate u meer gebruikmaakt van Lookout for Equipment, moet u een groter aantal modellen en inferentieschema's beheren. Om dit proces gemakkelijker te maken, de Inferentie schema's pagina toont alle planners die momenteel zijn geconfigureerd voor een project in één weergave.

Opruimen
Wanneer u klaar bent met het evalueren van Lookout for Equipment, raden we u aan alle bronnen op te schonen. U kunt het Lookout for Equipment-project samen met de dataset en alle gemaakte modellen verwijderen door het project te selecteren en te kiezen Verwijder, en de actie bevestigen.
Samengevat
In dit bericht hebben we de stappen doorlopen van het opnemen van een dataset in Lookout for Equipment, het trainen van een model erop en het evalueren van de prestaties ervan om inzicht te krijgen in de waarde die het kan ontdekken voor individuele activa. We hebben met name onderzocht hoe Lookout for Equipment voorspellende onderhoudsprocessen kan ondersteunen die resulteren in minder ongeplande downtime en hogere OEE.
Als u uw eigen gegevens hebt gevolgd en enthousiast bent over de vooruitzichten van het gebruik van Lookout for Equipment, is de volgende stap het starten van een proefproject, met de steun van uw IT-organisatie, uw belangrijkste partners of onze AWS Professional Services-teams. Deze pilot moet gericht zijn op een beperkt aantal industriële apparatuur en vervolgens worden opgeschaald om uiteindelijk alle bedrijfsmiddelen te omvatten die in aanmerking komen voor voorspellend onderhoud.
Over de auteurs
 Johann Fuchsl is een oplossingsarchitect bij Amazon Web Services. Hij begeleidt zakelijke klanten in de maakindustrie bij het implementeren van AI/ML-use cases, het ontwerpen van moderne data-architecturen en het bouwen van cloud-native oplossingen die tastbare bedrijfswaarde opleveren. Johann heeft een achtergrond in wiskunde en kwantitatieve modellering, die hij combineert met 10 jaar ervaring in IT. Buiten zijn werk brengt hij graag tijd door met zijn gezin en is hij graag in de natuur.
Johann Fuchsl is een oplossingsarchitect bij Amazon Web Services. Hij begeleidt zakelijke klanten in de maakindustrie bij het implementeren van AI/ML-use cases, het ontwerpen van moderne data-architecturen en het bouwen van cloud-native oplossingen die tastbare bedrijfswaarde opleveren. Johann heeft een achtergrond in wiskunde en kwantitatieve modellering, die hij combineert met 10 jaar ervaring in IT. Buiten zijn werk brengt hij graag tijd door met zijn gezin en is hij graag in de natuur.
 Michael Hoarau is een Industrial AI/ML Specialist Solution Architect bij AWS die afhankelijk van het moment afwisselt tussen data scientist en machine learning architect. Hij is gepassioneerd om de kracht van AI/ML naar de werkvloer van zijn industriële klanten te brengen en heeft gewerkt aan een breed scala aan ML-use cases, variërend van afwijkingsdetectie tot voorspellende productkwaliteit of productie-optimalisatie. Wanneer hij klanten niet helpt bij het ontwikkelen van de volgende beste machine learning-ervaringen, geniet hij van het observeren van de sterren, reizen of piano spelen.
Michael Hoarau is een Industrial AI/ML Specialist Solution Architect bij AWS die afhankelijk van het moment afwisselt tussen data scientist en machine learning architect. Hij is gepassioneerd om de kracht van AI/ML naar de werkvloer van zijn industriële klanten te brengen en heeft gewerkt aan een breed scala aan ML-use cases, variërend van afwijkingsdetectie tot voorspellende productkwaliteit of productie-optimalisatie. Wanneer hij klanten niet helpt bij het ontwikkelen van de volgende beste machine learning-ervaringen, geniet hij van het observeren van de sterren, reizen of piano spelen.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/enable-predictive-maintenance-for-line-of-business-users-with-amazon-lookout-for-equipment/

