Organisaties moeten vaak een grote hoeveelheid gegevens beheren die in een buitengewoon tempo groeit. Tegelijkertijd moeten ze de operationele kosten optimaliseren om de waarde van deze gegevens te ontsluiten voor tijdige inzichten en dit met consistente prestaties.
Met deze enorme datagroei kan de verspreiding van data in uw datastores, datawarehouse en datameren een even grote uitdaging worden. Met een moderne data-architectuur op AWS kun je snel schaalbare datameren bouwen; gebruik maken van een brede en diepgaande verzameling speciaal gebouwde datadiensten; naleving garanderen via uniforme gegevenstoegang, beveiliging en governance; schaal uw systemen tegen lage kosten zonder concessies te doen aan de prestaties; en deel eenvoudig gegevens over de organisatiegrenzen heen, zodat u snel en flexibel op schaal beslissingen kunt nemen.
U kunt al uw gegevens uit verschillende silo's halen, die gegevens in uw datameer samenvoegen en rechtstreeks op die gegevens analyses en machine learning (ML) uitvoeren. U kunt ook andere gegevens opslaan in speciaal gebouwde datastores om zowel gestructureerde als ongestructureerde gegevens te analyseren en snel inzichten te krijgen. Deze gegevensbeweging kan van binnen naar buiten, van buiten naar binnen, rond de perimeter of gedeeld over de grenzen plaatsvinden.
Applicatielogboeken en sporen van webapplicaties kunnen bijvoorbeeld rechtstreeks in een datameer worden verzameld, en een deel van die gegevens kan voor dagelijkse analyse worden verplaatst naar een loganalysewinkel zoals Amazon OpenSearch Service. Wij beschouwen dit concept als binnenstebuiten gegevensbeweging. De geanalyseerde en geaggregeerde gegevens die zijn opgeslagen in Amazon OpenSearch Service kunnen opnieuw naar het datameer worden verplaatst om ML-algoritmen uit te voeren voor downstream-consumptie vanuit applicaties. Dit begrip noemen wij binnenstebuiten gegevensbeweging.
Laten we een voorbeeld van een gebruikscasus bekijken. Voorbeeld Corp. is een toonaangevend Fortune 500-bedrijf dat gespecialiseerd is in sociale inhoud. Ze beschikken over honderden applicaties die gegevens en sporen genereren met ongeveer 500 TB per dag en voldoen aan de volgende criteria:
- Houd logboeken beschikbaar voor snelle analyses gedurende 2 dagen
- Zorg ervoor dat er na twee dagen gegevens beschikbaar zijn in een opslaglaag die beschikbaar kan worden gemaakt voor analyses met een redelijke SLA
- Bewaar de gegevens langer dan 1 week in de koude opslag gedurende 30 dagen (voor compliance-, audit- en andere doeleinden)
In de volgende secties bespreken we drie mogelijke oplossingen om vergelijkbare gebruiksscenario's aan te pakken:
- Gelaagde opslag in Amazon OpenSearch Service en beheer van de gegevenslevenscyclus
- On-demand opname van logboeken met behulp van Amazon OpenSearch-opname
- Directe zoekopdrachten van Amazon OpenSearch Service met Amazon Simple Storage Service (Amazon S3)
Oplossing 1: gelaagde opslag in OpenSearch Service en beheer van de gegevenslevenscyclus
OpenSearch Service ondersteunt drie geïntegreerde opslaglagen: warme, UltraWarm- en koude opslag. Op basis van uw gegevensretentie, querylatentie en budgetteringsvereisten kunt u de beste strategie kiezen om de kosten en prestaties in evenwicht te brengen. U kunt ook gegevens migreren tussen verschillende opslaglagen.
Hot storage wordt gebruikt voor indexering en updates en biedt de snelste toegang tot gegevens. Hot storage heeft de vorm van een instance store of Amazon elastische blokwinkel (Amazon EBS) volumes die aan elk knooppunt zijn gekoppeld.
UltraWarm biedt aanzienlijk lagere kosten per GiB voor alleen-lezen gegevens die u minder vaak opvraagt en die niet dezelfde prestaties nodig hebben als hot storage. UltraWarm-knooppunten gebruiken Amazon S3 met gerelateerde caching-oplossingen om de prestaties te verbeteren.
Koude opslag is geoptimaliseerd om zelden gebruikte of historische gegevens op te slaan. Wanneer u koude opslag gebruikt, koppelt u uw indexen los van de UltraWarm-laag, waardoor ze ontoegankelijk worden. U kunt deze indexen binnen enkele seconden opnieuw koppelen als u gegevens moet opvragen.
Voor meer details over gegevenslagen binnen de OpenSearch Service raadpleegt u Kies de juiste opslaglaag voor uw behoeften in Amazon OpenSearch Service.
Overzicht oplossingen
De workflow voor deze oplossing bestaat uit de volgende stappen:
- Inkomende gegevens gegenereerd door de applicaties worden gestreamd naar een S3-datameer.
- Gegevens worden opgenomen in Amazon OpenSearch met behulp van S3-SQS bijna realtime opname via meldingen die zijn ingesteld op de S3-buckets.
- Na twee dagen worden actuele gegevens gemigreerd naar UltraWarm-opslag om leesquery's te ondersteunen.
- Na 5 dagen in UltraWarm worden de gegevens gedurende 21 dagen naar de koude opslag gemigreerd en losgekoppeld van elke computer. De gegevens kunnen indien nodig opnieuw aan UltraWarm worden gekoppeld. Gegevens worden na 21 dagen uit de koude opslag verwijderd.
- Dagelijkse indexen worden bijgehouden voor gemakkelijke rollover. Een Index State Management (ISM)-beleid automatiseert de rollover of verwijdering van indexen die ouder zijn dan twee dagen.
Het volgende is een voorbeeld van een ISM-beleid dat gegevens na twee dagen overzet naar de UltraWarm-laag, deze na vijf dagen naar de koude opslag verplaatst en na 2 dagen uit de koude opslag verwijdert:
Overwegingen
UltraWarm maakt gebruik van geavanceerde cachingtechnieken om het opvragen van zelden gebruikte gegevens mogelijk te maken. Hoewel de gegevenstoegang niet frequent is, moet de rekenkracht voor UltraWarm-knooppunten de hele tijd actief zijn om deze toegang mogelijk te maken.
Als u op PB-schaal werkt, raden we u aan om bij gebruik van gelaagde opslag de implementatie op te splitsen in meerdere OpenSearch Service-domeinen om het effectgebied van eventuele fouten te verkleinen.
De volgende twee patronen maken een einde aan de noodzaak van langdurige rekenkracht en beschrijven on-demand-technieken waarbij de gegevens ofwel worden gebracht wanneer dat nodig is, ofwel direct worden opgevraagd waar deze zich bevinden.
Oplossing 2: on-demand opname van loggegevens via OpenSearch Ingestion
OpenSearch Ingestion is een volledig beheerde gegevensverzamelaar die realtime log- en traceergegevens levert aan OpenSearch Service-domeinen. OpenSearch Ingestion wordt mogelijk gemaakt door de open source gegevensverzamelaar Gegevensvoorbereider. Data Prepper maakt deel uit van de open source OpenSearch-project.
Met OpenSearch Ingestion kunt u uw gegevens filteren, verrijken, transformeren en aanleveren voor downstream-analyse en visualisatie. U configureert uw gegevensproducenten om gegevens naar OpenSearch Ingestion te verzenden. Het levert de gegevens automatisch aan het domein of de verzameling die u opgeeft. U kunt OpenSearch Ingestion ook configureren om uw gegevens te transformeren voordat deze worden afgeleverd. OpenSearch Ingestion is serverloos, dus u hoeft zich geen zorgen te maken over het schalen van uw infrastructuur, het beheren van uw opnamevloot en het patchen of updaten van de software.
Er zijn twee manieren waarop u Amazon S3 als bron kunt gebruiken om gegevens te verwerken met OpenSearch Ingestion. De eerste optie is S3-SQS-verwerking. U kunt S3-SQS-verwerking gebruiken als u bestanden bijna in realtime wilt scannen nadat ze naar S3 zijn geschreven. Het vereist een Amazon Simple Queue-service (Amazon S3) wachtrij die ontvangt S3 gebeurtenismeldingen. U kunt S3-buckets configureren om een gebeurtenis te genereren telkens wanneer een object wordt opgeslagen of gewijzigd binnen de te verwerken bucket.
Als alternatief kunt u een eenmalige of terugkerende geplande scan gebruiken om gegevens in een S3-bucket batchgewijs te verwerken. Om een geplande scan in te stellen, configureert u uw pijplijn met een planning op scanniveau dat van toepassing is op al uw S3-buckets, of op bucketniveau. U kunt geplande scans configureren met een eenmalige scan of een terugkerende scan voor batchverwerking.
Voor een uitgebreid overzicht van OpenSearch Ingestion, zie Amazon OpenSearch-opname. Ga voor meer informatie over het open source-project Data Prepper naar Gegevensvoorbereider.
Overzicht oplossingen
We presenteren een architectuurpatroon met de volgende belangrijke componenten:
- Applicatielogboeken worden naar het datameer gestreamd, waardoor actuele gegevens vrijwel in realtime in de OpenSearch-service kunnen worden ingevoerd met behulp van OpenSearch Ingestion S3-SQS-verwerking.
- ISM-beleid binnen OpenSearch Service verwerkt indexrollovers of verwijderingen. Met ISM-beleid kunt u deze periodieke, administratieve bewerkingen automatiseren door ze te activeren op basis van wijzigingen in de indexleeftijd, indexgrootte of het aantal documenten. U kunt bijvoorbeeld een beleid definiëren dat uw index na twee dagen naar de status Alleen-lezen verplaatst en deze vervolgens na een bepaalde periode van drie dagen verwijdert.
- Koude gegevens zijn beschikbaar in het S3-datameer en kunnen op aanvraag worden gebruikt in de OpenSearch-service met behulp van OpenSearch Ingestion geplande scans.
Het volgende diagram illustreert de oplossingsarchitectuur.
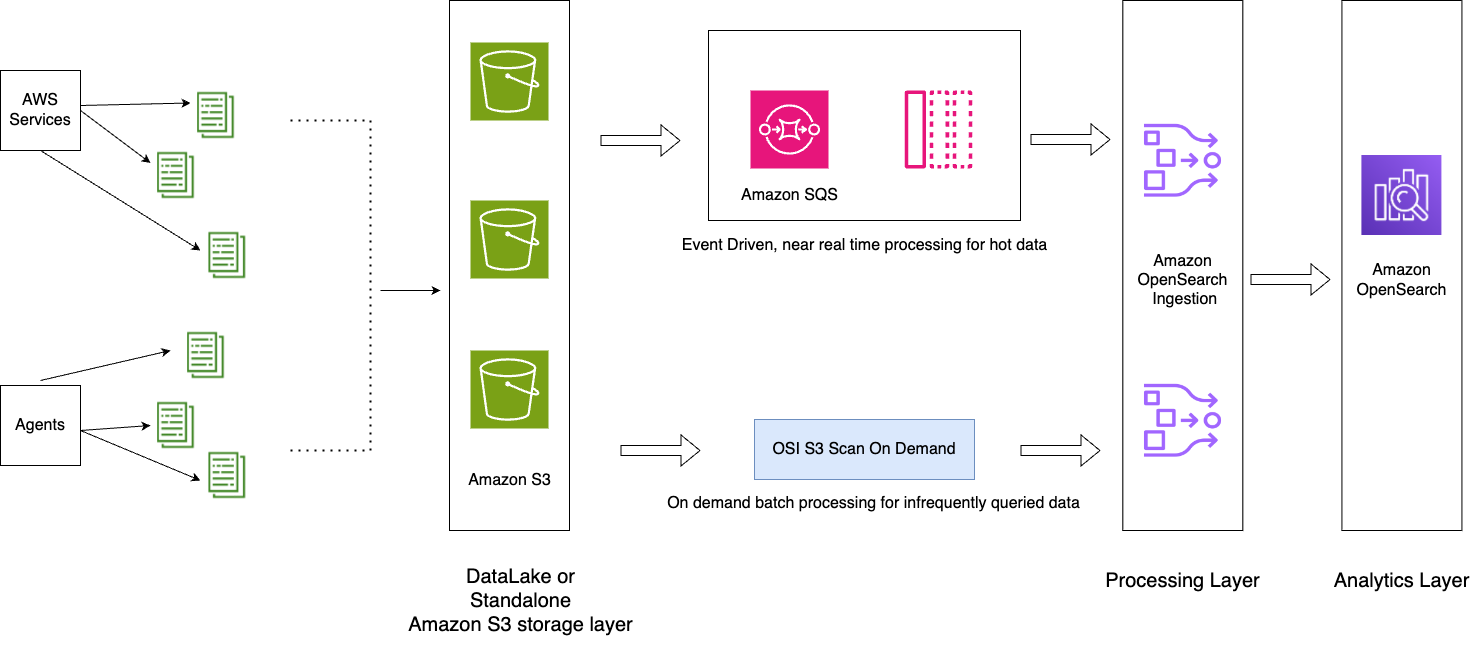
De workflow omvat de volgende stappen:
- Inkomende gegevens gegenereerd door de applicaties worden gestreamd naar het S3-datameer.
- Voor de huidige dag worden gegevens opgenomen in de OpenSearch Service met behulp van S3-SQS, bijna realtime opname via meldingen die zijn ingesteld in de S3-buckets.
- Dagelijkse indexen worden bijgehouden voor gemakkelijke rollover. Een ISM-beleid automatiseert de rollover of verwijdering van indexen die ouder zijn dan 2 dagen.
- Als er een verzoek wordt gedaan om gegevens langer dan twee dagen te analyseren en de gegevens zich niet in de UltraWarm-laag bevinden, worden de gegevens tussen het specifieke tijdvenster opgenomen met behulp van de eenmalige scanfunctie van Amazon S2.
Als het vandaag bijvoorbeeld 10 januari 2024 is en u met een specifiek interval gegevens van 6 januari 2024 nodig heeft voor analyse, kunt u in uw YAML-configuratie een OpenSearch Ingestion-pijplijn maken met een Amazon S3-scan. start_time en end_time om aan te geven wanneer u wilt dat de objecten in de bucket worden gescand:
Overwegingen
Profiteer van compressie
Gegevens in Amazon S3 kunnen worden gecomprimeerd, waardoor uw totale gegevensvoetafdruk wordt verkleind en aanzienlijke kostenbesparingen ontstaan. Als u bijvoorbeeld 15 PB aan onbewerkte JSON-applicatielogboeken per maand genereert, kunt u een compressiemechanisme zoals GZIP gebruiken, waarmee de grootte kan worden teruggebracht tot ongeveer 1 PB of minder, wat aanzienlijke kostenbesparingen oplevert.
Stop de pijpleiding indien mogelijk
OpenSearch Ingestion schaalt automatisch tussen de minimale en maximale OCU's die zijn ingesteld voor de pijplijn. Nadat de pijplijn de Amazon S3-scan heeft voltooid gedurende de gespecificeerde duur die wordt vermeld in de pijplijnconfiguratie, blijft de pijplijn draaien voor continue monitoring bij de minimale OCU's.
Voor opname op aanvraag voor eerdere perioden waarin u niet verwacht dat er nieuwe objecten worden gemaakt, kunt u overwegen ondersteunde pijplijnstatistieken te gebruiken, zoals recordsOut.count creëren Amazon Cloud Watch alarmen die de pijpleiding kunnen stoppen. Voor een lijst met ondersteunde statistieken raadpleegt u Pijplijnstatistieken bewaken.
CloudWatch-alarmen voeren een actie uit wanneer een CloudWatch-metriek gedurende een bepaalde tijd een opgegeven waarde overschrijdt. U wilt bijvoorbeeld monitoren recordsOut.count om langer dan 0 minuten 5 te zijn om een verzoek te initiëren stop de pijpleiding door de AWS-opdrachtregelinterface (AWS CLI) of API.
Oplossing 3: OpenSearch Service directe zoekopdrachten met Amazon S3
OpenSearch Service directe zoekopdrachten met Amazon S3 (preview) is een nieuwe manier om operationele logs in Amazon S3- en S3-datameren op te vragen zonder tussen services te hoeven schakelen. U kunt nu zelden opgevraagde gegevens in cloudobjectstores analyseren en tegelijkertijd de operationele analyse- en visualisatiemogelijkheden van OpenSearch Service gebruiken.
OpenSearch Service biedt directe zoekopdrachten met Amazon S3 nul-ETL-integratie om de operationele complexiteit van het dupliceren van gegevens of het beheren van meerdere analysetools te verminderen, doordat u uw operationele gegevens rechtstreeks kunt opvragen, waardoor de kosten en de time-to-action worden verlaagd. Deze nul-ETL-integratie is configureerbaar binnen OpenSearch Service, waar u kunt profiteren van verschillende logtypesjablonen, inclusief vooraf gedefinieerde dashboards, en gegevensversnellingen kunt configureren die zijn afgestemd op dat logtype. Sjablonen omvatten VPC-stroomlogboeken, Elastische load balancing logs en NGINX-logboeken, en versnellingen omvatten het overslaan van indexen, gematerialiseerde weergaven en gedekte indexen.
Met directe queries van OpenSearch Service met Amazon S3 kun je complexe queries uitvoeren die cruciaal zijn voor forensisch veiligheidsonderzoek en dreigingsanalyse, en data uit meerdere databronnen correleren, wat teams helpt bij het onderzoeken van servicedowntime en beveiligingsgebeurtenissen. Nadat u een integratie heeft gemaakt, kunt u uw gegevens rechtstreeks vanuit OpenSearch Dashboards of de OpenSearch API opvragen. U kunt verbindingen controleren om er zeker van te zijn dat ze op een schaalbare, kostenefficiënte en veilige manier worden opgezet.
Directe zoekopdrachten van OpenSearch Service naar Amazon S3 gebruiken Spark-tabellen binnen de AWS lijm Gegevenscatalogus. Nadat de tabel is gecatalogiseerd in uw AWS Glue-metagegevenscatalogus, kunt u rechtstreeks query's uitvoeren op uw gegevens in uw S3-datameer via OpenSearch Dashboards.
Overzicht oplossingen
Het volgende diagram illustreert de oplossingsarchitectuur.
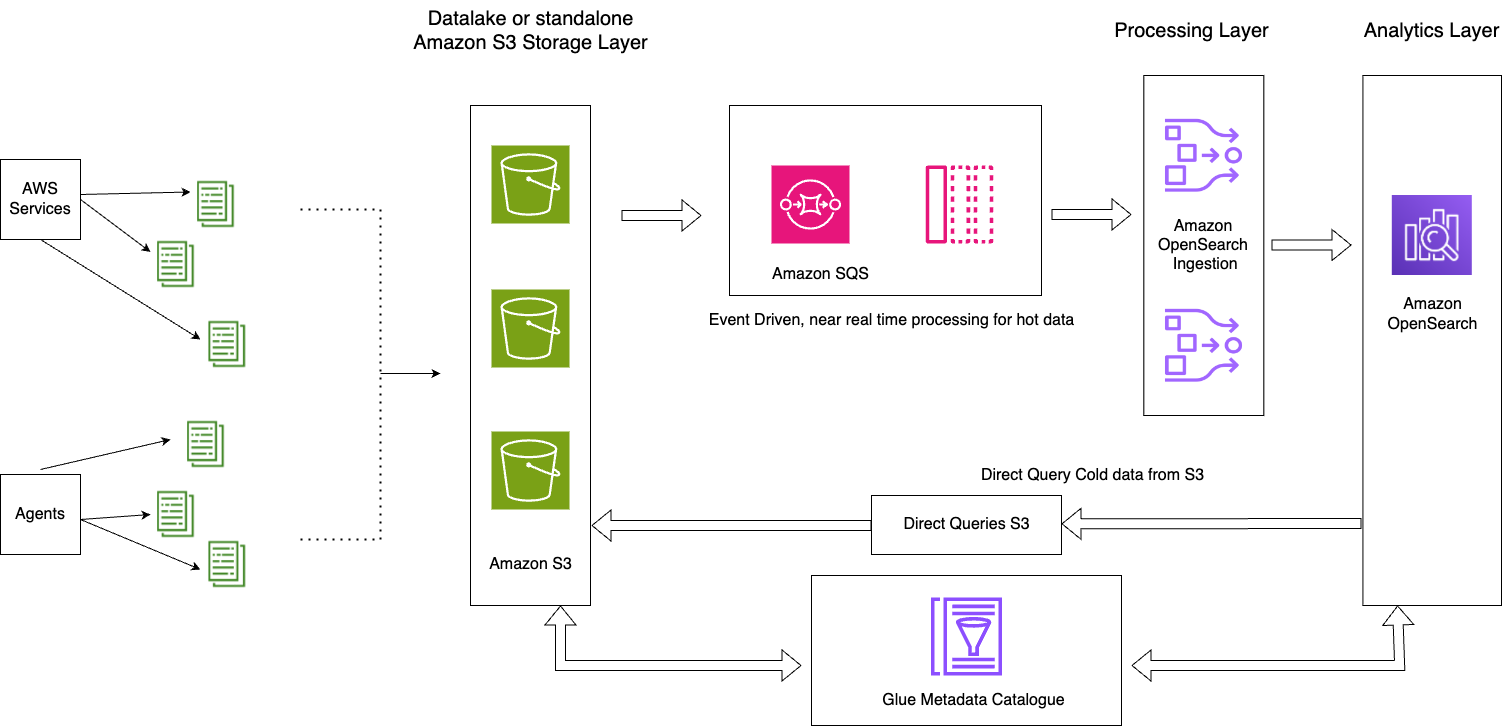
Deze oplossing bestaat uit de volgende belangrijke componenten:
- De actuele gegevens voor de huidige dag worden via het gebeurtenisgestuurde architectuurpatroon in OpenSearch Service-domeinen verwerkt met behulp van de OpenSearch Ingestion S3-SQS-verwerkingsfunctie
- De levenscyclus van actieve gegevens wordt beheerd via ISM-beleid dat is gekoppeld aan dagelijkse indexen
- De koude gegevens bevinden zich in uw Amazon S3-bucket en zijn gepartitioneerd en gecatalogiseerd
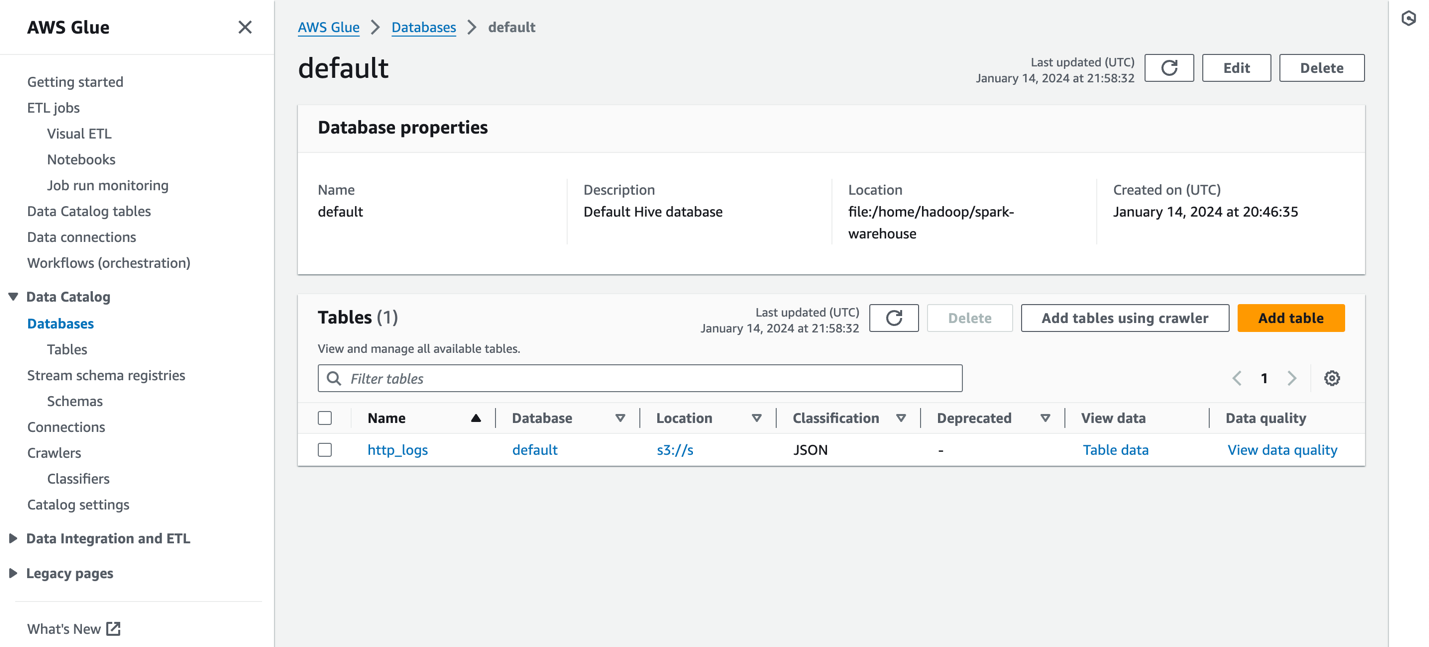
De volgende schermafbeelding toont een voorbeeld http_logs tabel die is gecatalogiseerd in de AWS Glue-metadatacatalogus. Voor gedetailleerde stappen, zie Gegevenscatalogus en crawlers in AWS Glue.
Voordat u een gegevensbron maakt, moet u een OpenSearch Service-domein hebben met versie 2.11 of hoger en een doel-S3-tabel in de AWS Glue Data Catalog met de juiste AWS Identiteits- en toegangsbeheer (IAM)-machtigingen. IAM heeft toegang nodig tot de gewenste S3-buckets en heeft lees- en schrijftoegang tot de AWS Glue Data Catalog. Het volgende is een voorbeeld van een rol- en vertrouwensbeleid met de juiste machtigingen voor toegang tot de AWS Glue-gegevenscatalogus via de OpenSearch-service:
Het volgende is een voorbeeld van aangepast beleid met toegang tot Amazon S3 en AWS Glue:
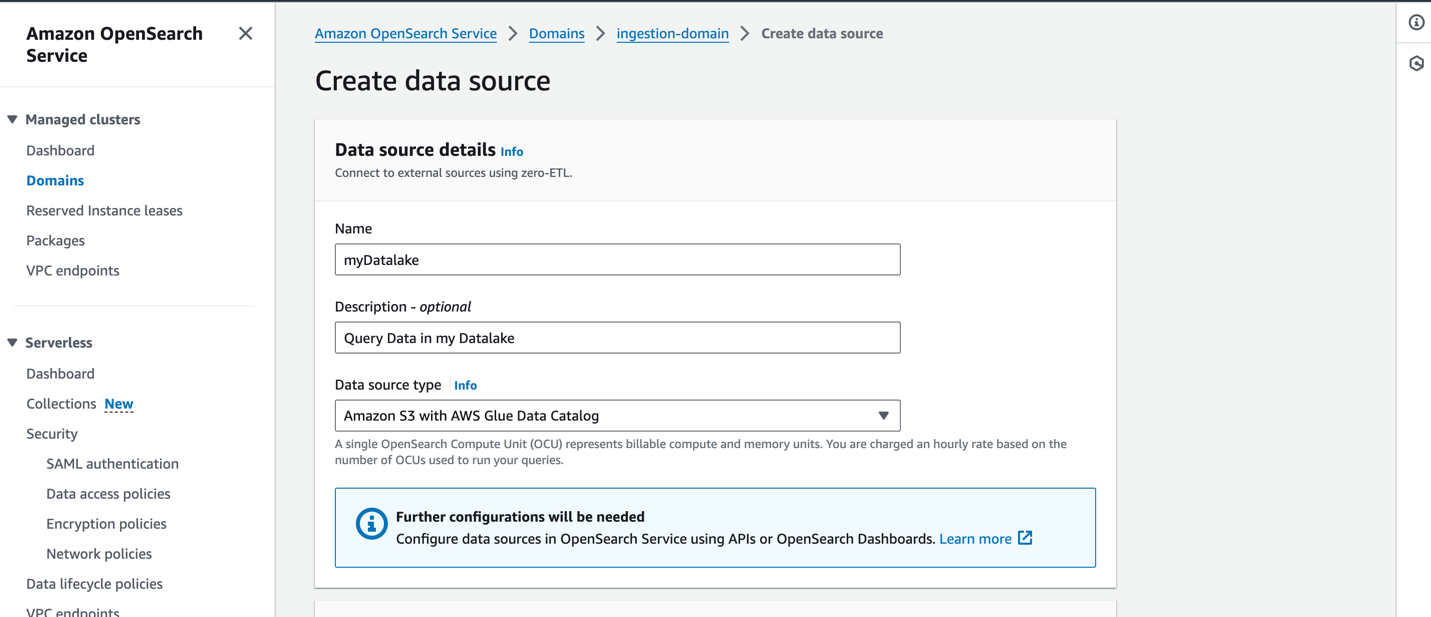
Om een nieuwe gegevensbron op de OpenSearch Service-console te maken, geeft u de naam van uw nieuwe gegevensbron op, specificeert u het gegevensbrontype als Amazon S3 met de AWS Glue Data Catalogen kies de IAM-rol voor uw gegevensbron.
Nadat u een gegevensbron hebt gemaakt, kunt u naar het OpenSearch-dashboard van het domein gaan, dat u gebruikt om toegangscontrole te configureren, tabellen te definiëren, op logboektypen gebaseerde dashboards in te stellen voor populaire logboektypen en uw gegevens op te vragen.

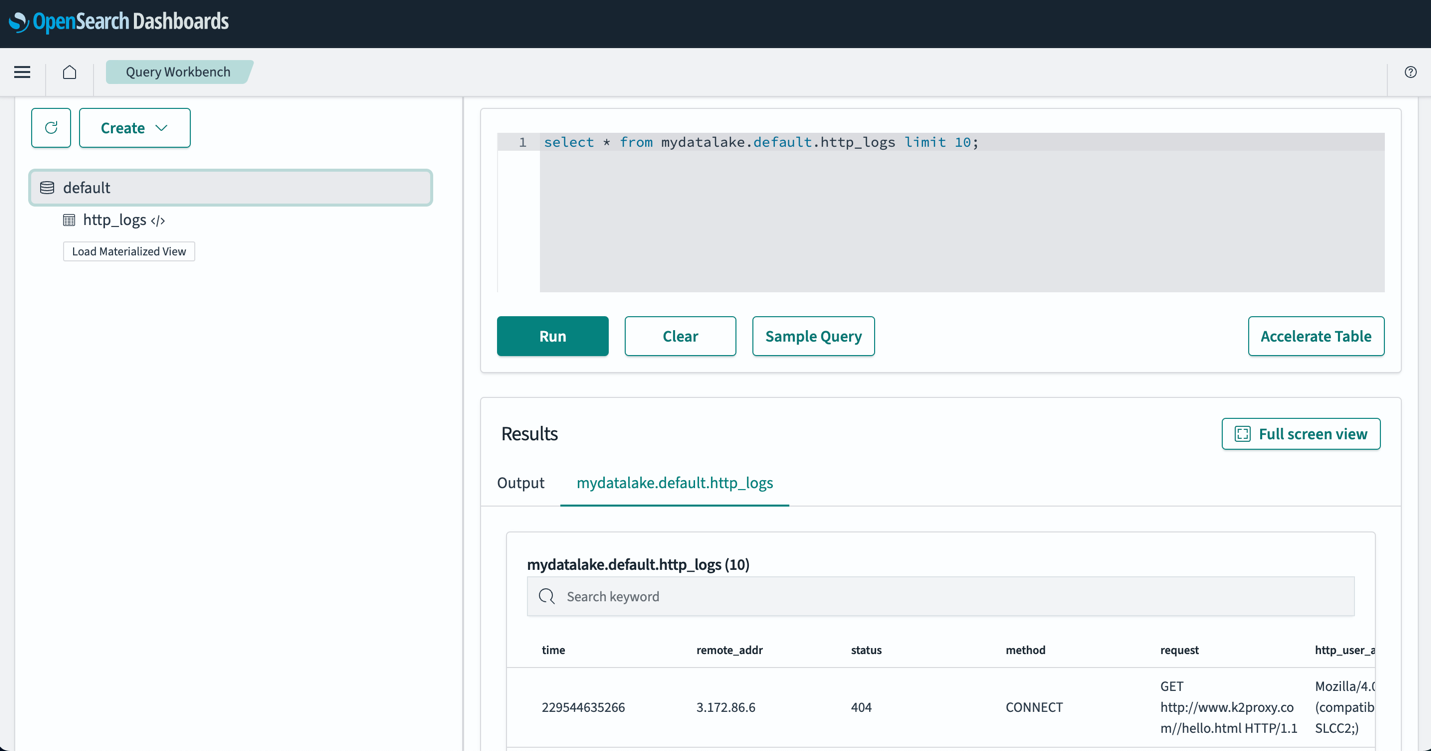
Nadat u uw tabellen heeft ingesteld, kunt u uw gegevens in uw S3-datameer opvragen via OpenSearch Dashboards. U kunt een voorbeeld van een SQL-query uitvoeren voor de http_logs tabel die u hebt gemaakt in de AWS Glue Data Catalog-tabellen, zoals weergegeven in de volgende schermafbeelding.
Beste praktijken
Neem alleen de gegevens op die u nodig heeft
Werk terug vanuit uw bedrijfsbehoeften en stel de juiste datasets samen die u nodig heeft. Evalueer of u kunt voorkomen dat u gegevens met veel ruis opneemt en alleen samengestelde, bemonsterde of geaggregeerde gegevens kunt opnemen. Door deze opgeschoonde en samengestelde datasets te gebruiken, kunt u de reken- en opslagbronnen optimaliseren die nodig zijn om deze gegevens op te nemen.
Verklein de gegevensgrootte vóór opname
Wanneer u uw pijplijnen voor gegevensopname ontwerpt, gebruikt u strategieën zoals compressie, filtering en aggregatie om de omvang van de opgenomen gegevens te verkleinen. Hierdoor kunnen kleinere gegevensgroottes via het netwerk worden overgedragen en in uw gegevenslaag worden opgeslagen.
Conclusie
In dit bericht hebben we oplossingen besproken die loganalyses op petabyte-schaal mogelijk maken met behulp van OpenSearch Service in een moderne data-architectuur. U hebt geleerd hoe u een serverloze opnamepijplijn kunt maken om logboeken te leveren aan een OpenSearch Service-domein, indexen kunt beheren via ISM-beleid, IAM-machtigingen kunt configureren om OpenSearch Ingestion te gaan gebruiken en de pijplijnconfiguratie kunt maken voor gegevens in uw datameer. U hebt ook geleerd hoe u de directe zoekopdrachten van de OpenSearch Service met de Amazon S3-functie (preview) kunt instellen en gebruiken om gegevens uit uw data lake op te vragen.
Om het juiste architectuurpatroon voor uw workloads te kiezen wanneer u OpenSearch Service op schaal gebruikt, moet u rekening houden met de prestaties, latentie, kosten en groei van het datavolume in de loop van de tijd om de juiste beslissing te nemen.
- Gebruik gelaagde opslagarchitectuur met Index State Management-beleid wanneer u snelle toegang tot uw actuele gegevens nodig heeft en de kosten en prestaties in evenwicht wilt brengen met UltraWarm-nodes voor alleen-lezen gegevens.
- Gebruik On Demand Ingestion van uw gegevens in de OpenSearch Service wanneer u opnamelatenties kunt tolereren om uw gegevens te doorzoeken die niet in uw hot-nodes zijn bewaard. U kunt aanzienlijke kostenbesparingen realiseren door gecomprimeerde gegevens in Amazon S3 te gebruiken en gegevens op verzoek in de OpenSearch Service op te nemen.
- Gebruik Directe query met S3-functie wanneer u uw operationele logboeken in Amazon S3 rechtstreeks wilt analyseren met de rijke analyse- en visualisatiefuncties van OpenSearch Service.
Raadpleeg voor een volgende stap de Amazon OpenSearch-ontwikkelaarsgids om logboeken en metrische pijplijnen te verkennen die u kunt gebruiken om een schaalbare observatieoplossing voor uw bedrijfstoepassingen te bouwen.
Over de auteurs
 Jagadish Kumar (Jag) is een Senior Specialist Solutions Architect bij AWS, gericht op Amazon OpenSearch Service. Hij heeft een grote passie voor data-architectuur en helpt klanten bij het bouwen van analytische oplossingen op schaal op AWS.
Jagadish Kumar (Jag) is een Senior Specialist Solutions Architect bij AWS, gericht op Amazon OpenSearch Service. Hij heeft een grote passie voor data-architectuur en helpt klanten bij het bouwen van analytische oplossingen op schaal op AWS.
 Muthu Pitchaimani is een Senior Specialist Solutions Architect bij Amazon OpenSearch Service. Hij bouwt grootschalige zoekapplicaties en -oplossingen. Muthu is geïnteresseerd in de onderwerpen netwerken en beveiliging en is gevestigd in Austin, Texas.
Muthu Pitchaimani is een Senior Specialist Solutions Architect bij Amazon OpenSearch Service. Hij bouwt grootschalige zoekapplicaties en -oplossingen. Muthu is geïnteresseerd in de onderwerpen netwerken en beveiliging en is gevestigd in Austin, Texas.
 Sam Selvan is een Principal Specialist Solution Architect bij Amazon OpenSearch Service.
Sam Selvan is een Principal Specialist Solution Architect bij Amazon OpenSearch Service.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/petabyte-scale-log-analytics-with-amazon-s3-amazon-opensearch-service-and-amazon-opensearch-ingestion/

