Toen ik een paar jaar geleden data-analyse begon te leren, was het eerste wat ik leerde SQL en Panda's. Als data-analist is het cruciaal om een sterke basis te hebben in het werken met SQL en Panda's. Beide zijn krachtige tools die gegevensanalisten helpen bij het efficiënt analyseren en manipuleren van opgeslagen gegevens in databases.
Overzicht van SQL en Panda's
SQL (Structured Query Language) is een programmeertaal die wordt gebruikt voor het beheren en manipuleren van relationele databases. Aan de andere kant is Pandas een Python-bibliotheek die wordt gebruikt voor gegevensmanipulatie en -analyse.
Data-analyse omvat het werken met grote hoeveelheden data en databases worden vaak gebruikt om deze data op te slaan. SQL en Panda's bieden krachtige hulpmiddelen voor het werken met databases, waardoor gegevensanalisten efficiënt gegevens kunnen extraheren, manipuleren en analyseren. Door gebruik te maken van deze tools kunnen gegevensanalisten waardevolle inzichten verkrijgen uit gegevens die anders moeilijk te verkrijgen zouden zijn.
In dit artikel zullen we onderzoeken hoe u SQL en Panda's kunt gebruiken om een database te lezen en ernaar te schrijven.
Aansluiten op de DB
De bibliotheken installeren
We moeten eerst de nodige bibliotheken installeren voordat we met Panda's verbinding kunnen maken met de SQL-database. De twee belangrijkste vereiste bibliotheken zijn Pandas en SQLAlchemy. Panda's is een populaire bibliotheek voor gegevensmanipulatie die de opslag van grote gegevensstructuren mogelijk maakt, zoals vermeld in de inleiding. SQLAlchemy biedt daarentegen een API voor verbinding met en interactie met de SQL-database.
We kunnen beide bibliotheken installeren met behulp van de Python-pakketbeheerder, pip, door de volgende opdrachten uit te voeren bij de opdrachtprompt.
$ pip install pandas
$ pip install sqlalchemy
De verbinding maken
Nu de bibliotheken zijn geïnstalleerd, kunnen we nu Panda's gebruiken om verbinding te maken met de SQL-database.
Om te beginnen zullen we een SQLAlchemy engine-object maken met create_engine(). De create_engine() functie verbindt de Python-code met de database. Het neemt als argument een verbindingsreeks die het databasetype en de verbindingsdetails specificeert. In dit voorbeeld gebruiken we het databasetype SQLite en het pad van het databasebestand.
Maak een engine-object voor een SQLite-database aan de hand van het onderstaande voorbeeld:
import pandas as pd
from sqlalchemy import create_engine engine = create_engine('sqlite:///C/SQLite/student.db')
Als het SQLite-databasebestand, student.db in ons geval, zich in dezelfde map bevindt als het Python-script, kunnen we de bestandsnaam rechtstreeks gebruiken, zoals hieronder wordt weergegeven.
engine = create_engine('sqlite:///student.db')
SQL-bestanden lezen met Panda's
Laten we gegevens lezen nu we een verbinding tot stand hebben gebracht. In dit onderdeel gaan we kijken naar de read_sql, read_sql_table en read_sql_query functies en hoe ze te gebruiken om met een database te werken.
SQL-query's uitvoeren met behulp van Panda's lees_sql() Functie
De read_sql() is een Pandas-bibliotheekfunctie waarmee we een SQL-query kunnen uitvoeren en de resultaten kunnen ophalen in een Pandas-dataframe. De read_sql() functie verbindt SQL en Python, waardoor we kunnen profiteren van de kracht van beide talen. De functie wikkelt read_sql_table() en read_sql_query(). De read_sql() functie wordt intern gerouteerd op basis van de geleverde invoer, wat betekent dat als de invoer een SQL-query moet uitvoeren, deze wordt gerouteerd naar read_sql_query(), en als het een databasetabel is, wordt het ernaar gerouteerd read_sql_table().
De read_sql() syntaxis is als volgt:
pandas.read_sql(sql, con, index_col=None, coerce_float=True, params=None, parse_dates=None, columns=None, chunksize=None)
SQL- en con-parameters zijn vereist; de rest is optioneel. We kunnen het resultaat echter manipuleren met behulp van deze optionele parameters. Laten we elke parameter eens nader bekijken.
sql: SQL-query of databasetabelnaamcon: Verbindingsobject of verbindings-URLindex_col: Met deze parameter kunnen we een of meer kolommen uit het resultaat van de SQL-query gebruiken als dataframe-index. Het kan een enkele kolom of een lijst met kolommen zijn.coerce_float: Deze parameter geeft aan of niet-numerieke waarden moeten worden geconverteerd naar zwevende getallen of als tekenreeksen moeten worden achtergelaten. Het is standaard ingesteld op waar. Indien mogelijk converteert het niet-numerieke waarden naar zwevende typen.params: De parameters bieden een veilige methode voor het doorgeven van dynamische waarden aan de SQL-query. We kunnen de parameter params gebruiken om een woordenboek, tuple of lijst door te geven. Afhankelijk van de database varieert de syntaxis van parameters.parse_dates: Hiermee kunnen we specificeren welke kolom in het resulterende dataframe als een datum wordt geïnterpreteerd. Het accepteert een enkele kolom, een lijst met kolommen of een woordenboek met de sleutel als de kolomnaam en de waarde als de kolomindeling.columns: Hiermee kunnen we alleen geselecteerde kolommen uit de lijst ophalen.chunksize: Bij het werken met een grote dataset is chunksize belangrijk. Het haalt het queryresultaat op in kleinere delen, waardoor de prestaties worden verbeterd.
Hier is een voorbeeld van hoe te gebruiken read_sql():
Code:
import pandas as pd
from sqlalchemy import create_engine engine = create_engine('sqlite:///C/SQLite/student.db') df = pd.read_sql("SELECT * FROM Student", engine, index_col='Roll Number', parse_dates='dateOfBirth')
print(df)
print("The Data type of dateOfBirth: ", df.dateOfBirth.dtype) engine.dispose()
Output:
firstName lastName email dateOfBirth
rollNumber
1 Mark Simson [email protected] 2000-02-23
2 Peter Griffen [email protected] 2001-04-15
3 Meg Aniston [email protected] 2001-09-20
Date type of dateOfBirth: datetime64[ns]
Nadat we verbinding hebben gemaakt met de database, voeren we een query uit die alle records uit de Student tabel en slaat ze op in het DataFrame df. De kolom "Rolnummer" wordt geconverteerd naar een index met behulp van de index_col parameter, en het datatype "dateOfBirth" is "datetime64[ns]" vanwege parse_dates. We kunnen gebruiken read_sql() niet alleen om gegevens op te halen, maar ook om andere bewerkingen uit te voeren, zoals invoegen, verwijderen en bijwerken. read_sql() is een generieke functie.
Specifieke tabellen of weergaven laden vanuit de database
Een specifieke tabel of weergave laden met Panda's read_sql_table() is een andere techniek om gegevens uit de database in een Pandas-dataframe te lezen.
Wat is lees_sql_tabel?
De Pandas-bibliotheek biedt de read_sql_table functie, die specifiek is ontworpen om een volledige SQL-tabel te lezen zonder query's uit te voeren en het resultaat als een Pandas-dataframe te retourneren.
De syntaxis van read_sql_table() is zoals hieronder:
pandas.read_sql_table(table_name, con, schema=None, index_col=None, coerce_float=True, parse_dates=None, columns=None, chunksize=None)
Behalve voor table_name en schema, worden de parameters op dezelfde manier uitgelegd als read_sql().
table_name: De parametertable_nameis de naam van de SQL-tabel in de database.schema: Deze optionele parameter is de naam van het schema dat de tabelnaam bevat.
Nadat we een verbinding met de database hebben gemaakt, gebruiken we de read_sql_table functie om de Student tabel in een Panda's DataFrame.
import pandas as pd
from sqlalchemy import create_engine engine = create_engine('sqlite:///C/SQLite/student.db') df = pd.read_sql_table('Student', engine)
print(df.head()) engine.dispose()
Output:
rollNumber firstName lastName email dateOfBirth
0 1 Mark Simson [email protected] 2000-02-23
1 2 Peter Griffen [email protected] 2001-04-15
2 3 Meg Aniston [email protected] 2001-09-20
We nemen aan dat het een grote tabel is die geheugenintensief kan zijn. Laten we eens kijken hoe we de chunksize parameter om dit probleem aan te pakken.
Bekijk onze praktische, praktische gids voor het leren van Git, met best-practices, door de industrie geaccepteerde normen en bijgevoegd spiekbriefje. Stop met Googlen op Git-commando's en eigenlijk leren het!
Code:
import pandas as pd
from sqlalchemy import create_engine engine = create_engine('sqlite:///C/SQLite/student.db') df_iterator = pd.read_sql_table('Student', engine, chunksize = 1) for df in df_iterator: print(df.head()) engine.dispose()
Output:
rollNumber firstName lastName email dateOfBirth
0 1 Mark Simson [email protected] 2000-02-23
0 2 Peter Griffen [email protected] 2001-04-15
0 3 Meg Aniston [email protected] 2001-09-20
Houd er rekening mee dat de chunksize Ik gebruik hier is 1 omdat ik maar 3 records in mijn tabel heb.
De database rechtstreeks bevragen met de SQL-syntaxis van Panda's
Het extraheren van inzichten uit de database is een belangrijk onderdeel voor data-analisten en wetenschappers. Hiervoor maken we gebruik van de read_sql_query() functie.
Wat is read_sql_query()?
Panda's gebruiken read_sql_query() functie kunnen we SQL-query's uitvoeren en de resultaten rechtstreeks in een DataFrame krijgen. De read_sql_query() functie is speciaal gemaakt voor SELECT verklaringen. Het kan niet worden gebruikt voor andere bewerkingen, zoals DELETE or UPDATE.
Syntax:
pandas.read_sql_query(sql, con, index_col=None, coerce_float=True, params=None, parse_dates=None, chunksize=None, dtype=None, dtype_backend=_NoDefault.no_default)
Alle parameterbeschrijvingen zijn hetzelfde als de read_sql() functie. Hier is een voorbeeld van read_sql_query():
Code:
import pandas as pd
from sqlalchemy import create_engine engine = create_engine('sqlite:///C/SQLite/student.db') df = pd.read_sql_query('Select firstName, lastName From Student Where rollNumber = 1', engine)
print(df) engine.dispose()
Output:
firstName lastName
0 Mark Simson
SQL-bestanden schrijven met Panda's
Stel dat we tijdens het analyseren van gegevens hebben ontdekt dat een paar vermeldingen moeten worden gewijzigd of dat er een nieuwe tabel of weergave met de gegevens nodig is. Een methode is om een nieuw record bij te werken of in te voegen read_sql() en schrijf een vraag. Die methode kan echter lang duren. Panda's bieden een geweldige methode genaamd to_sql() voor dit soort situaties.
In deze sectie zullen we eerst een nieuwe tabel in de database bouwen en vervolgens een bestaande bewerken.
Een nieuwe tabel maken in de SQL-database
Voordat we een nieuwe tabel maken, gaan we eerst overleggen to_sql() in detail.
Wat is naar_sql()?
De to_sql() functie van de Pandas-bibliotheek stelt ons in staat om de database te schrijven of bij te werken. De to_sql() functie kan DataFrame-gegevens opslaan in een SQL-database.
Syntaxis voor to_sql():
DataFrame.to_sql(name, con, schema=None, if_exists='fail', index=True, index_label=None, chunksize=None, dtype=None, method=None)
Alleen name en con parameters zijn verplicht om uit te voeren to_sql(); andere parameters bieden echter extra flexibiliteit en aanpassingsmogelijkheden. Laten we elke parameter in detail bespreken:
name: De naam van de SQL-tabel die moet worden gemaakt of gewijzigd.con: Het verbindingsobject van de database.schema: Het schema van de tabel (optioneel).if_exists: De standaardwaarde van deze parameter is "mislukt". Met deze parameter kunnen we beslissen welke actie moet worden ondernomen als de tabel al bestaat. Opties zijn onder meer "mislukt", "vervangen" en "toevoegen".index: De indexparameter accepteert een booleaanse waarde. Standaard is deze ingesteld op True, wat betekent dat de index van het DataFrame naar de SQL-tabel wordt geschreven.index_label: Met deze optionele parameter kunnen we een kolomlabel specificeren voor de indexkolommen. Standaard wordt de index naar de tabel geschreven, maar met deze parameter kan een specifieke naam worden gegeven.chunksize: Het aantal rijen dat tegelijk in de SQL-database moet worden geschreven.dtype: Deze parameter accepteert een woordenboek met sleutels als kolomnamen en waarden als datatypes.method: Met de methodeparameter kunt u de methode specificeren die wordt gebruikt voor het invoegen van gegevens in de SQL. Standaard staat deze op Geen, wat betekent dat panda's de meest efficiënte manier vinden op basis van de database. Er zijn twee hoofdopties voor methodeparameters:multi: Hiermee kunnen meerdere rijen in een enkele SQL-query worden ingevoegd. Niet alle databases ondersteunen echter het invoegen van meerdere rijen.- Oproepbare functie: Hier kunnen we een aangepaste functie voor invoegen schrijven en deze aanroepen met behulp van methodeparameters.
Hier is een voorbeeld van het gebruik van to_sql():
import pandas as pd
from sqlalchemy import create_engine engine = create_engine('sqlite:///C/SQLite/student.db') data = {'Name': ['Paul', 'Tom', 'Jerry'], 'Age': [9, 8, 7]}
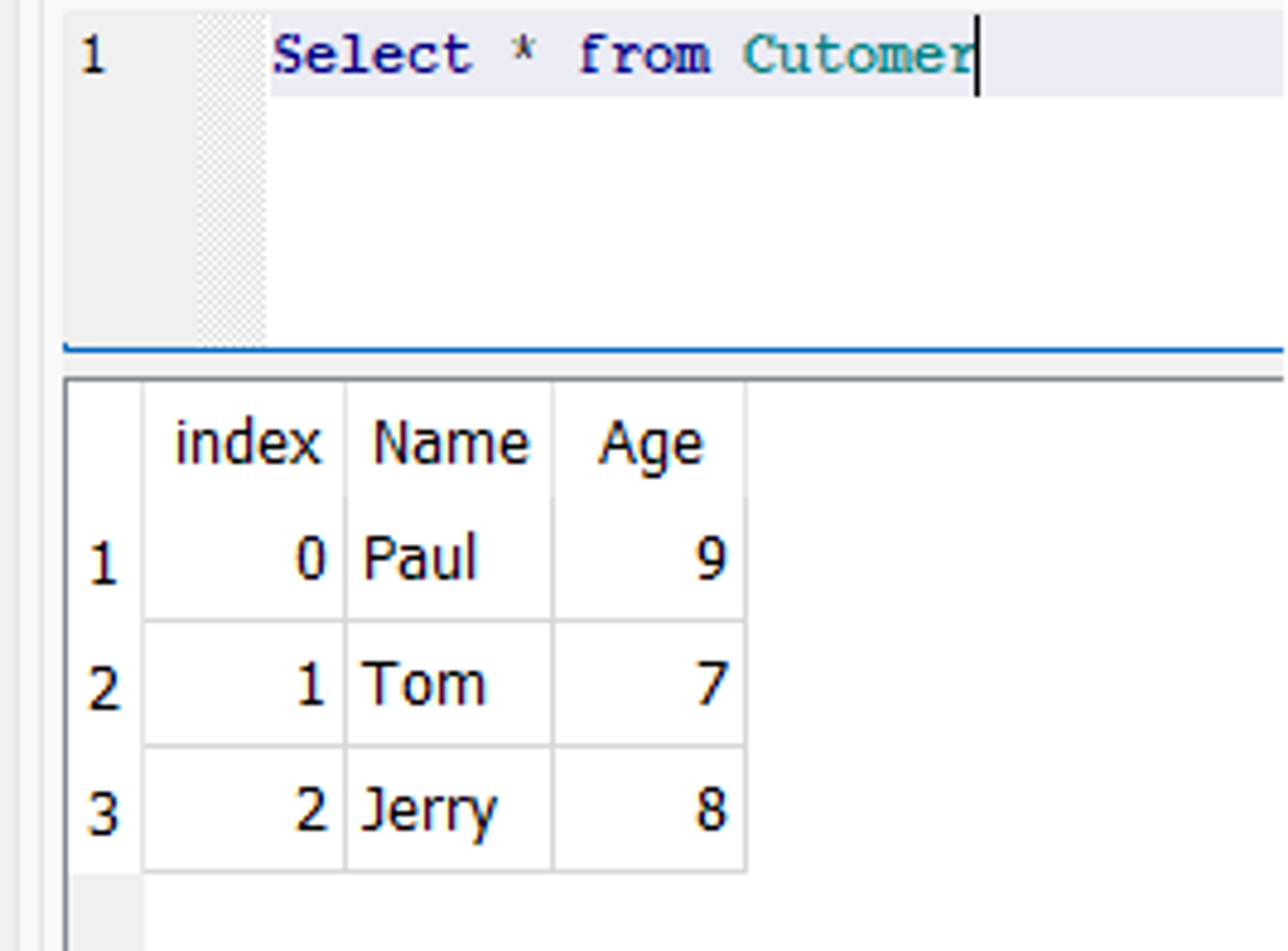
df = pd.DataFrame(data) df.to_sql('Customer', con=engine, if_exists='fail') engine.dispose()
In de database wordt een nieuwe tabel met de naam Klant gemaakt, met twee velden genaamd "Naam" en "Leeftijd".
Database momentopname:
Bestaande tabellen bijwerken met Panda's Dataframes
Het bijwerken van gegevens in een database is een complexe taak, vooral als het gaat om grote hoeveelheden gegevens. Echter met behulp van de to_sql() functie in Panda's kan deze taak veel gemakkelijker maken. Om de bestaande tabel in de database bij te werken, moet het to_sql() functie kan worden gebruikt met de if_exists parameter ingesteld op "vervangen". Hierdoor wordt de bestaande tabel overschreven met de nieuwe gegevens.
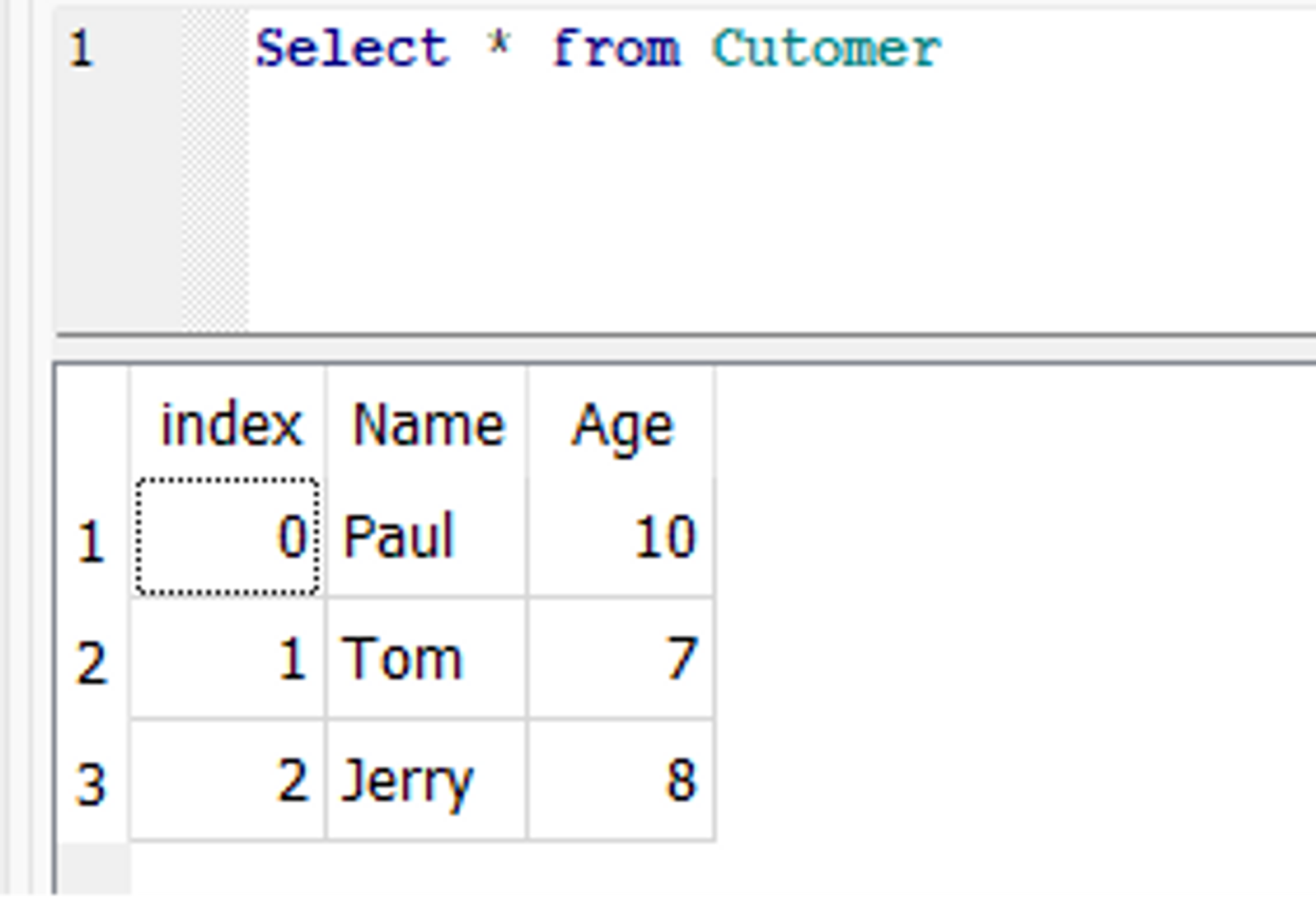
Hier is een voorbeeld van to_sql() waarmee het eerder gemaakte bestand wordt bijgewerkt Customer tafel. Stel, in de Customer tabel willen we de leeftijd van een klant met de naam Paul bijwerken van 9 naar 10. Om dit te doen, kunnen we eerst de overeenkomstige rij in het DataFrame wijzigen en vervolgens de to_sql() functie om de database bij te werken.
Code:
import pandas as pd
from sqlalchemy import create_engine engine = create_engine('sqlite:///C/SQLite/student.db') df = pd.read_sql_table('Customer', engine) df.loc[df['Name'] == 'Paul', 'Age'] = 10 df.to_sql('Customer', con=engine, if_exists='replace') engine.dispose()
In de database wordt de leeftijd van Paul bijgewerkt:
Conclusie
Kortom, Panda's en SQL zijn beide krachtige tools voor data-analysetaken zoals het lezen en schrijven van data naar de SQL-database. Pandas biedt een eenvoudige manier om verbinding te maken met de SQL-database, gegevens uit de database in een Pandas-dataframe te lezen en dataframe-gegevens terug naar de database te schrijven.
De Pandas-bibliotheek maakt het gemakkelijk om gegevens in een dataframe te manipuleren, terwijl SQL een krachtige taal biedt voor het opvragen van gegevens in een database. Door zowel Panda's als SQL te gebruiken om de gegevens te lezen en te schrijven, kan tijd en moeite worden bespaard bij gegevensanalysetaken, vooral wanneer de gegevens erg groot zijn. Over het algemeen kan het samen gebruiken van SQL en Panda's data-analisten en wetenschappers helpen hun workflow te stroomlijnen.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoAiStream. Web3 gegevensintelligentie. Kennis versterkt. Toegang hier.
- De toekomst slaan met Adryenn Ashley. Toegang hier.
- Koop en verkoop aandelen in PRE-IPO-bedrijven met PREIPO®. Toegang hier.
- Bron: https://stackabuse.com/reading-and-writing-sql-files-in-pandas/

