Krones voorziet brouwerijen, drankbottelaars en voedselproducenten over de hele wereld van individuele machines en complete productielijnen. Elke dag passeren miljoenen glazen flessen, blikjes en PET-containers een Krones-lijn. Productielijnen zijn complexe systemen met veel mogelijke fouten die de lijn kunnen vertragen en de productieopbrengst kunnen verlagen. Krones wil de storing zo vroeg mogelijk detecteren (soms zelfs voordat deze plaatsvindt) en de operators van de productielijn op de hoogte stellen om de betrouwbaarheid en output te verhogen. Dus hoe kun je een storing detecteren? Krones rust hun lijnen uit met sensoren voor het verzamelen van gegevens, die vervolgens aan de hand van regels kunnen worden beoordeeld. Krones heeft als lijnfabrikant en als lijnoperator de mogelijkheid om bewakingsregels voor machines op te stellen. Daarom kunnen drankbottelaars en andere operators hun eigen foutmarge voor de lijn definiëren. In het verleden gebruikte Krones een systeem gebaseerd op een tijdreeksdatabase. De belangrijkste uitdagingen waren dat dit systeem moeilijk te debuggen was en dat zoekopdrachten de huidige status van machines vertegenwoordigden, maar niet de statusovergangen.
Dit bericht laat zien hoe Krones een streamingoplossing heeft gebouwd om hun lijnen te monitoren, op basis van Amazon Kinesis en Amazon Managed Service voor Apache Flink. Deze volledig beheerde services verminderen de complexiteit van het bouwen van streaming-applicaties met Apache Flink. Managed Service voor Apache Flink beheert de onderliggende Apache Flink-componenten die een duurzame applicatiestatus, statistieken, logboeken en meer bieden, en Kinesis stelt u in staat om streaminggegevens op elke schaal kosteneffectief te verwerken. Als je aan de slag wilt met je eigen Apache Flink-applicatie, bekijk dan de GitHub-repository voor voorbeelden met behulp van de Java-, Python- of SQL-API's van Flink.
Overzicht van de oplossing
De lijnmonitoring van Krones is onderdeel van de Krones Begeleiding op de werkvloer systeem. Het biedt ondersteuning bij de organisatie, prioritering, beheer en documentatie van alle activiteiten in het bedrijf. Hiermee kunnen ze een operator waarschuwen als de machine is gestopt of als er materialen nodig zijn, ongeacht waar de operator zich in de rij bevindt. Beproefde regels voor condition monitoring zijn al ingebouwd, maar kunnen ook door de gebruiker worden gedefinieerd via de gebruikersinterface. Als een bepaald datapunt dat wordt gemonitord bijvoorbeeld een drempel overschrijdt, kan er een sms of trigger voor een onderhoudsopdracht op de lijn verschijnen.
Het systeem voor conditiebewaking en regelevaluatie is gebouwd op AWS en maakt gebruik van AWS-analyseservices. Het volgende diagram illustreert de architectuur.
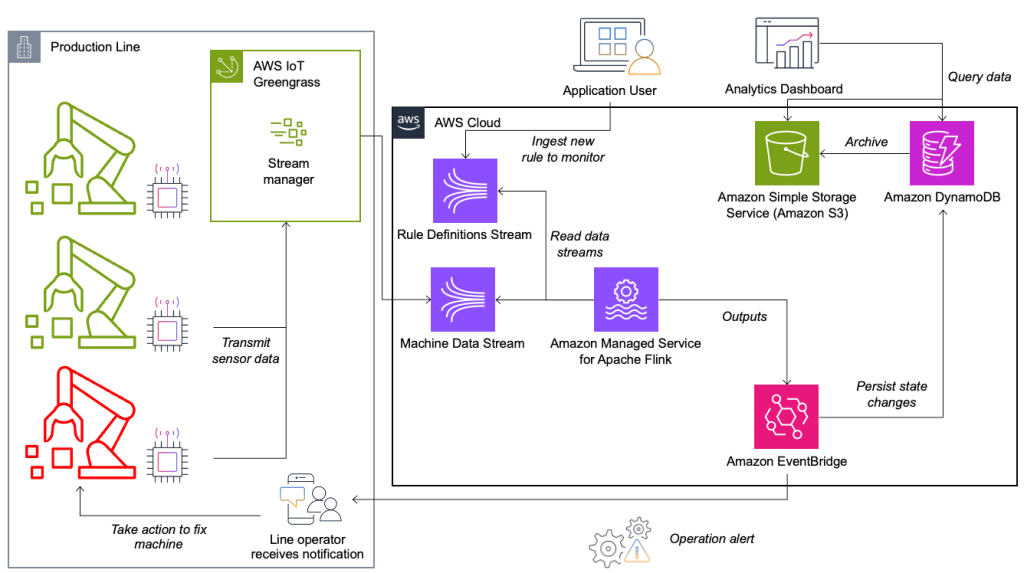
Bijna elke datastreamingtoepassing bestaat uit vijf lagen: gegevensbron, streamopname, streamopslag, streamverwerking en een of meer bestemmingen. In de volgende secties duiken we dieper in elke laag en hoe de lijnmonitoringoplossing, gebouwd door Krones, in detail werkt.
Databron
De gegevens worden verzameld door een service die draait op een edge-apparaat en verschillende protocollen leest, zoals Siemens S7 of OPC/UA. Ruwe gegevens worden voorbewerkt om een uniforme JSON-structuur te creëren, waardoor ze later gemakkelijker in de regelengine kunnen worden verwerkt. Een voorbeeldpayload die naar JSON is geconverteerd, kan er als volgt uitzien:
{
"version": 1,
"timestamp": 1234,
"equipmentId": "84068f2f-3f39-4b9c-a995-d2a84d878689",
"tag": "water_temperature",
"value": 13.45,
"quality": "Ok",
"meta": {
"sequenceNumber": 123,
"flags": ["Fst", "Lst", "Wmk", "Syn", "Ats"],
"createdAt": 12345690,
"sourceId": "filling_machine"
}
}Stream-opname
AWS IoT Greengrass is een open source Internet of Things (IoT) edge runtime- en cloudservice. Hierdoor kunt u lokaal actie ondernemen op gegevens en apparaatgegevens aggregeren en filteren. AWS IoT Greengrass biedt kant-en-klare componenten die tot aan de rand kunnen worden ingezet. De productielijnoplossing maakt gebruik van de streammanagercomponent, die gegevens kan verwerken en overbrengen naar AWS-bestemmingen zoals AWS IoT-analyse, Amazon eenvoudige opslagservice (Amazon S3) en Kinesis. De streammanager buffert en aggregeert records en stuurt deze vervolgens naar een Kinesis-gegevensstroom.
Stream-opslag
De taak van de streamopslag is om berichten op een fouttolerante manier te bufferen en beschikbaar te maken voor gebruik door een of meer consumententoepassingen. Om dit op AWS te bereiken, zijn de meest voorkomende technologieën Kinesis en Amazon Managed Streaming voor Apache Kafka (Amazone MSK). Voor het opslaan van onze sensordata van productielijnen kiest Krones voor Kinesis. Kinesis is een serverloze streaming-dataservice die op elke schaal werkt met een lage latentie. Shards binnen een Kinesis-gegevensstroom zijn een uniek geïdentificeerde reeks gegevensrecords, waarbij een stroom is samengesteld uit een of meer scherven. Elke Shard heeft een leescapaciteit van 2 MB/s en een schrijfcapaciteit van 1 MB/s (met maximaal 1,000 records/s). Om te voorkomen dat deze limieten worden bereikt, moeten gegevens zo gelijkmatig mogelijk over de shards worden verdeeld. Elk record dat naar Kinesis wordt verzonden, heeft een partitiesleutel, die wordt gebruikt om gegevens in een shard te groeperen. Daarom wilt u een groot aantal partitiesleutels hebben om de belasting gelijkmatig te verdelen. De streammanager die draait op AWS IoT Greengrass ondersteunt willekeurige partitiesleuteltoewijzingen, wat betekent dat alle records in een willekeurige shard terechtkomen en de belasting gelijkmatig wordt verdeeld. Een nadeel van willekeurige partitiesleuteltoewijzingen is dat records niet op volgorde worden opgeslagen in Kinesis. Hoe u dit kunt oplossen, leggen we uit in de volgende sectie, waar we het hebben over watermerken.
Watermerken
A watermerk is een mechanisme dat wordt gebruikt om de voortgang van de gebeurtenistijd in een datastroom te volgen en te meten. De gebeurtenistijd is de tijdstempel vanaf het moment waarop de gebeurtenis bij de bron is gemaakt. Het watermerk geeft de tijdige voortgang van de streamverwerkingstoepassing aan, dus alle gebeurtenissen met een eerdere of gelijke tijdstempel worden als verwerkt beschouwd. Deze informatie is essentieel voor Flink om de gebeurtenistijd te versnellen en relevante berekeningen te activeren, zoals vensterevaluaties. De toegestane vertraging tussen de gebeurtenistijd en het watermerk kan worden geconfigureerd om te bepalen hoe lang er moet worden gewacht op late gegevens voordat een venster als voltooid wordt beschouwd en het watermerk verder wordt gezet.
Krones heeft systemen over de hele wereld en moest late aankomsten verwerken als gevolg van verbindingsverliezen of andere netwerkbeperkingen. Ze begonnen met het monitoren van late aankomsten en stelden de standaard Flink-late afhandeling in op de maximale waarde die ze in deze statistiek zagen. Ze ondervonden problemen met de tijdsynchronisatie van de edge-apparaten, wat hen leidde tot een meer geavanceerde manier van watermerken. Ze bouwden een globaal watermerk voor alle afzenders en gebruikten de laagste waarde als watermerk. De tijdstempels worden voor alle inkomende gebeurtenissen opgeslagen in een HashMap. Wanneer de watermerken periodiek worden uitgezonden, wordt de kleinste waarde van deze HashMap gebruikt. Om te voorkomen dat watermerken vastlopen door gegevens te missen, hebben ze een idleTimeOut parameter, die tijdstempels negeert die ouder zijn dan een bepaalde drempelwaarde. Dit verhoogt de latentie, maar zorgt voor een sterke gegevensconsistentie.
public class BucketWatermarkGenerator implements WatermarkGenerator<DataPointEvent> {
private HashMap <String, WatermarkAndTimestamp> lastTimestamps;
private Long idleTimeOut;
private long maxOutOfOrderness;
}
Streamverwerking
Nadat de gegevens uit sensoren zijn verzameld en in Kinesis zijn opgenomen, moeten deze worden geëvalueerd door een regelengine. Een regel in dit systeem vertegenwoordigt de status van een enkele metriek (zoals temperatuur) of een verzameling metrieken. Om een metriek te interpreteren, wordt meer dan één gegevenspunt gebruikt, wat een stateful berekening is. In deze sectie duiken we dieper in de ingetoetste staat en de uitzendstatus in Apache Flink en hoe deze worden gebruikt om de Krones-regelengine te bouwen.
Beheer stream- en uitzendstatuspatroon
In Apache Flink, staat verwijst naar het vermogen van het systeem om informatie persistent op te slaan en te beheren gedurende de tijd en tijdens bewerkingen, waardoor de verwerking van streaminggegevens mogelijk wordt met ondersteuning voor stateful berekeningen.
De uitgezonden staatspatroon maakt de distributie van een status naar alle parallelle instanties van een operator mogelijk. Daarom hebben alle operators dezelfde status en kunnen gegevens met dezelfde status worden verwerkt. Deze alleen-lezen gegevens kunnen worden opgenomen met behulp van een controlestroom. Een controlestroom is een reguliere datastroom, maar meestal met een veel lagere datasnelheid. Met dit patroon kunt u de status van alle operators dynamisch bijwerken, zodat de gebruiker de status en het gedrag van de toepassing kan wijzigen zonder dat deze opnieuw hoeft te worden geïmplementeerd. Preciezer gezegd, de verdeling van de staat gebeurt door het gebruik van een controlestroom. Door een nieuw record toe te voegen aan de controlestroom ontvangen alle operators deze update en gebruiken ze de nieuwe status voor de verwerking van nieuwe berichten.
Hierdoor kunnen gebruikers van de Krones-applicatie nieuwe regels in de Flink-applicatie opnemen zonder deze opnieuw te starten. Dit voorkomt downtime en geeft een geweldige gebruikerservaring omdat wijzigingen in realtime plaatsvinden. Een regel omvat een scenario om een procesafwijking te detecteren. Soms zijn de machinegegevens niet zo eenvoudig te interpreteren als het op het eerste gezicht lijkt. Als een temperatuursensor hoge waarden verzendt, kan dit duiden op een fout, maar ook het gevolg zijn van een lopende onderhoudsprocedure. Het is belangrijk om statistieken in context te plaatsen en enkele waarden te filteren. Dit wordt bereikt door een concept genaamd groepering.
Groepering van statistieken
Door gegevens en statistieken te groeperen, kunt u de relevantie van binnenkomende gegevens definiëren en nauwkeurige resultaten produceren. Laten we het voorbeeld in de volgende afbeelding bekijken.
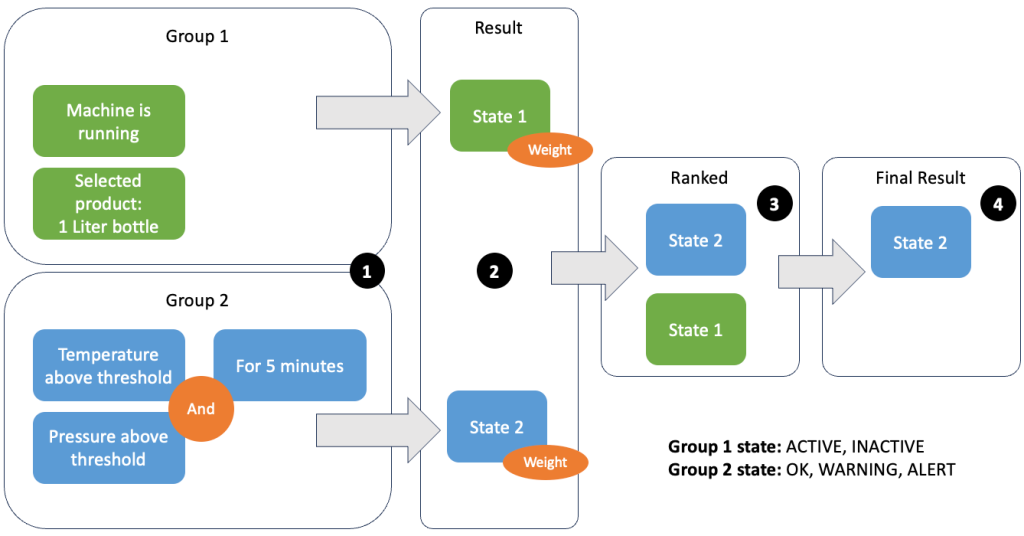
In stap 1 definiëren we twee voorwaardegroepen. Groep 1 verzamelt de machinestatus en welk product er door de lijn gaat. Groep 2 gebruikt de waarde van de temperatuur- en druksensoren. Een voorwaardegroep kan verschillende statussen hebben, afhankelijk van de waarden die deze ontvangt. In dit voorbeeld ontvangt groep 1 gegevens dat de machine draait en wordt de fles van één liter als product geselecteerd; dit geeft deze groep de staat ACTIVE. Groep 2 heeft statistieken voor temperatuur en druk; beide statistieken liggen langer dan vijf minuten boven hun drempelwaarden. Hierdoor komt groep 5 in a terecht WARNING staat. Dit betekent dat groep 1 meldt dat alles in orde is en groep 2 niet. In stap 2 worden gewichten aan de groepen toegevoegd. In sommige situaties is dit nodig omdat groepen tegenstrijdige informatie kunnen rapporteren. In dit scenario rapporteert groep 1 ACTIVE en groep 2-rapporten WARNING, dus het is voor het systeem niet duidelijk wat de status van de lijn is. Na het toevoegen van de gewichten kunnen de staten worden gerangschikt, zoals weergegeven in stap 3. Ten slotte wordt de hoogst gerangschikte staat gekozen als de winnende, zoals weergegeven in stap 4.
Nadat de regels zijn geëvalueerd en de uiteindelijke machinestatus is gedefinieerd, worden de resultaten verder verwerkt. De ondernomen actie is afhankelijk van de regelconfiguratie; Dit kan een melding zijn aan de lijnoperator om materialen aan te vullen, wat onderhoud uit te voeren, of gewoon een visuele update op het dashboard. Dit deel van het systeem, dat statistieken en regels evalueert en acties onderneemt op basis van de resultaten, wordt een regel motor.
Het schalen van de regelengine
Door gebruikers hun eigen regels te laten maken, kan de regelengine een groot aantal regels hebben die moeten worden geëvalueerd, en sommige regels kunnen dezelfde sensorgegevens gebruiken als andere regels. Flink is een gedistribueerd systeem dat horizontaal zeer goed schaalt. Om een gegevensstroom over verschillende taken te verdelen, kunt u de keyBy() methode. Hierdoor kunt u een datastroom op een logische manier verdelen en delen van de gegevens naar verschillende taakbeheerders sturen. Vaak gebeurt dit door een willekeurige sleutel te kiezen, zodat je een gelijkmatig verdeelde belasting krijgt. In dit geval heeft Krones een ruleId naar het datapunt en gebruikte het als sleutel. Anders worden de benodigde gegevenspunten door een andere taak verwerkt. De ingetoetste gegevensstroom kan voor alle regels worden gebruikt, net als een gewone variabele.
Bestemmingen
Wanneer een regel van status verandert, wordt de informatie naar een Kinesis-stream gestuurd en vervolgens via Amazon EventBridge aan consumenten. Eén van de consumenten maakt van de gebeurtenis een melding die naar de productielijn wordt verzonden en waarschuwt het personeel om actie te ondernemen. Om de wijzigingen in de regelstatus te kunnen analyseren, schrijft een andere service de gegevens naar een Amazon DynamoDB tabel voor snelle toegang en er is een TTL aanwezig om de langetermijngeschiedenis naar Amazon S3 over te dragen voor verdere rapportage.
Conclusie
In dit bericht hebben we u laten zien hoe Krones een realtime monitoringsysteem voor de productielijn op AWS heeft gebouwd. Dankzij Managed Service voor Apache Flink kon het Krones-team snel aan de slag door zich te concentreren op applicatieontwikkeling in plaats van op infrastructuur. Dankzij de real-time mogelijkheden van Flink kon Krones de stilstand van de machine met 10% verminderen en de efficiëntie tot 5% verhogen.
Als je je eigen streaming-applicaties wilt bouwen, bekijk dan de beschikbare voorbeelden op de website GitHub-repository. Als u uw Flink-applicatie wilt uitbreiden met aangepaste connectoren, zie Het eenvoudiger maken om connectoren te bouwen met Apache Flink: introductie van de Async Sink. De Async Sink is beschikbaar in Apache Flink versie 1.15.1 en hoger.
Over de auteurs
 Florian Mair is een Senior Solutions Architect en datastreamingexpert bij AWS. Hij is een technoloog die klanten in Europa helpt succesvol te zijn en te innoveren door zakelijke uitdagingen op te lossen met behulp van AWS Cloud-services. Naast zijn werk als Solutions Architect is Florian een gepassioneerd bergbeklimmer en heeft hij enkele van de hoogste bergen van Europa beklommen.
Florian Mair is een Senior Solutions Architect en datastreamingexpert bij AWS. Hij is een technoloog die klanten in Europa helpt succesvol te zijn en te innoveren door zakelijke uitdagingen op te lossen met behulp van AWS Cloud-services. Naast zijn werk als Solutions Architect is Florian een gepassioneerd bergbeklimmer en heeft hij enkele van de hoogste bergen van Europa beklommen.
 Emil Dietl is een Senior Tech Lead bij Krones, gespecialiseerd in data-engineering, met een sleutelgebied in Apache Flink en microservices. Zijn werk omvat vaak de ontwikkeling en het onderhoud van bedrijfskritische software. Buiten zijn professionele leven hecht hij veel waarde aan het doorbrengen van quality time met zijn gezin.
Emil Dietl is een Senior Tech Lead bij Krones, gespecialiseerd in data-engineering, met een sleutelgebied in Apache Flink en microservices. Zijn werk omvat vaak de ontwikkeling en het onderhoud van bedrijfskritische software. Buiten zijn professionele leven hecht hij veel waarde aan het doorbrengen van quality time met zijn gezin.
 Simon Peyer is een Solutions Architect bij AWS, gevestigd in Zwitserland. Hij is een praktische doener en heeft een passie voor het verbinden van technologie en mensen die AWS Cloud-services gebruiken. Een speciaal aandachtspunt voor hem is datastreaming en automatisering. Naast zijn werk geniet Simon van zijn gezin, het buitenleven en wandelen in de bergen.
Simon Peyer is een Solutions Architect bij AWS, gevestigd in Zwitserland. Hij is een praktische doener en heeft een passie voor het verbinden van technologie en mensen die AWS Cloud-services gebruiken. Een speciaal aandachtspunt voor hem is datastreaming en automatisering. Naast zijn werk geniet Simon van zijn gezin, het buitenleven en wandelen in de bergen.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/krones-real-time-production-line-monitoring-with-amazon-managed-service-for-apache-flink/

