Introductie
De constante zoektocht naar precisie en betrouwbaarheid op het gebied van Artificial Intelligence (AI) heeft baanbrekende innovaties geïntroduceerd. Deze strategieën zijn van cruciaal belang bij het leiden van generatieve modellen om relevante antwoorden te bieden op een reeks vragen. Een van de grootste obstakels voor het gebruik van generatieve AI in verschillende geavanceerde toepassingen is hallucinatie. Het recente artikel uitgebracht door Meta AI Research getiteld “Keten van verificatie vermindert hallucinaties in grote taalmodellenbespreekt een eenvoudige techniek om hallucinaties direct te verminderen bij het genereren van tekst.
In dit artikel leren we over hallucinatieproblemen en onderzoeken we de concepten van CoVe die in het artikel worden genoemd, en hoe we deze kunnen implementeren met behulp van LLM's, LangChain Framework en LangChain Expression Language (LCEL) om aangepaste ketens te creëren.
leerdoelen
- Begrijp het probleem van hallucinatie bij LLM's.
- Lees meer over het Chain of Verification (CoVe)-mechanisme om hallucinaties te verminderen.
- Ken de voor- en nadelen van CoVe.
- Leer de CoVe te implementeren met behulp van LangChain en begrijp de LangChain-expressietaal.
Dit artikel is gepubliceerd als onderdeel van het Data Science-blogathon.
Inhoudsopgave
Wat is het hallucinatieprobleem bij LLM's?
Laten we eerst proberen meer te weten te komen over het hallucinatieprobleem in LLM. Met behulp van de autoregressieve generatiebenadering voorspelt het LLM-model het volgende woord gegeven de vorige context. Voor veelvoorkomende thema's heeft het model voldoende voorbeelden gezien om met vertrouwen een hoge waarschijnlijkheid toe te kennen aan het corrigeren van tokens. Omdat het model echter niet is getraind op ongebruikelijke of onbekende onderwerpen, kan het met grote zekerheid onnauwkeurige tokens opleveren. Dit resulteert in hallucinaties van plausibel klinkende maar verkeerde informatie.
Hieronder staat zo'n voorbeeld van hallucinatie in Open AI's ChatGPT, waar ik vroeg naar het boek “Economics of Small Things”, gepubliceerd in 2020 door een Indiase auteur, maar het model spuugde vol vertrouwen het verkeerde antwoord uit en verwarde het met het boek van een ander Nobelprijswinnaar Abhijit Banerjee, getiteld ‘Poor Economics’.

Chain of Verification (CoVe)-techniek
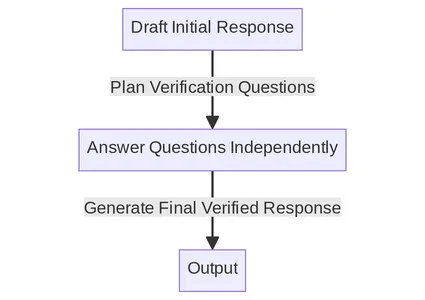
Het CoVe-mechanisme combineert prompting- en consistentiecontroles om een zelfverificatiesysteem voor LLM's te creëren. Hieronder vindt u de belangrijkste stappen die in het document worden vermeld. We zullen proberen elke stap één voor één in detail te begrijpen.
Overzicht ketenproces
- Basislijnrespons genereren: Gegeven een vraag, genereer het antwoord met behulp van de LLM.
- Planverificaties: Genereer, op basis van zowel de vraag- als de basisreactie, een lijst met verificatievragen die kunnen helpen bij het zelf analyseren of er fouten in het oorspronkelijke antwoord zitten.
- Verificaties uitvoeren: Beantwoord elke verificatievraag achtereenvolgens en controleer daarom het antwoord met het oorspronkelijke antwoord om te controleren op inconsistenties of fouten.
- Genereer een definitief geverifieerd antwoord: Genereer, gezien de ontdekte inconsistenties (indien aanwezig), een herzien antwoord waarin de verificatieresultaten zijn verwerkt.
Ketenproces begrijpen met behulp van gedetailleerd voorbeeld
Genereer een eerste reactie
We geven onze vraag eerst door aan LLM zonder enige speciale vraag om een eerste antwoord te genereren. Dit vormt het startpunt voor het CoVe-proces. Omdat dit soort basisreacties vaak vatbaar zijn voor hallucinaties, probeert de CoVe-techniek deze fouten in latere fasen te ontdekken en te corrigeren.
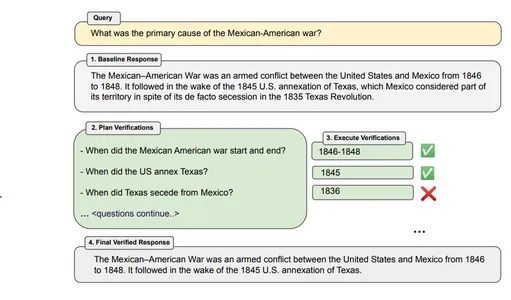
Voorbeeld - “Wat is de voornaamste oorzaak van de Mexicaans-Amerikaanse oorlog?”
Botreactie – De Mexicaans-Amerikaanse oorlog was een gewapend conflict tussen de Verenigde Staten en Mexico van 1846 tot 1848. De oorlog werd gevolgd in de nasleep van de Amerikaanse annexatie van Texas in 1845, dat ondanks zijn de facto als deel van zijn grondgebied werd beschouwd. afscheiding tijdens de Texas Revolutie van 1835.
Planverificaties
Maak verificatievragen op basis van de vraag en het basisantwoord waarmee we de feitelijke beweringen van het basisantwoord kunnen onderzoeken. Om dit te implementeren kunnen we een reeks verificatievragen modelleren op basis van zowel de vraag als het basisantwoord. Verificatievragen kunnen flexibel zijn en hoeven niet exact te worden afgestemd op de originele tekst.
Voorbeeld – Wanneer begon en eindigde de Mexicaans-Amerikaanse oorlog? Wanneer annexeerden de VS Texas? Wanneer scheidde Texas zich af van Mexico?
Voer verificaties uit
Nadat we verificatievragen hebben gepland, kunnen we deze vragen individueel beantwoorden. Het artikel bespreekt vier verschillende methoden om verificaties uit te voeren:
1. Gezamenlijk – Hierbij gebeurt de planning en uitvoering van verificatievragen in één enkele prompt. De vragen en hun antwoorden worden gegeven in dezelfde LLM-prompt. Deze methode wordt over het algemeen niet aanbevolen, omdat de verificatiereactie kan worden gehallucineerd.
2. 2-Stap – De planning en uitvoering gebeuren afzonderlijk in twee stappen met afzonderlijke LLM-prompts. Eerst genereren we verificatievragen en vervolgens beantwoorden we die vragen.
3. Gefactoriseerd – Hier wordt elke verificatievraag afzonderlijk beantwoord in plaats van in hetzelfde grote antwoord, en is het oorspronkelijke basisantwoord niet inbegrepen. Het kan verwarring tussen verschillende verificatievragen helpen voorkomen en kan ook een groter aantal vragen verwerken.
4. In aanmerking genomen + herzien – Er wordt een extra stap toegevoegd aan deze methode. Na het beantwoorden van elke verificatievraag controleert het CoVe-mechanisme of de antwoorden overeenkomen met het oorspronkelijke basisantwoord. Dit gebeurt in een aparte stap met behulp van een extra prompt.
Externe tools of zelf-LLM: We hebben een tool nodig die onze antwoorden verifieert en verificatie-antwoorden geeft. Dit kan worden uitgevoerd met behulp van de LLM zelf of een extern hulpmiddel. Als we een grotere nauwkeurigheid willen, kunnen we in plaats van te vertrouwen op LLM externe tools gebruiken, zoals een internetzoekmachine, een referentiedocument of een website, afhankelijk van ons gebruiksscenario.
Laatste geverifieerde reactie
In deze laatste stap wordt een verbeterd en geverifieerd antwoord gegenereerd. Er wordt gebruik gemaakt van een paar-shot-prompt en alle voorgaande context van basislijnantwoord en antwoorden op verificatievragen zijn inbegrepen. Als de “Factor+Revise”-methode werd gebruikt, wordt ook de uitvoer van kruiselings gecontroleerde inconsistentie geleverd.
Beperkingen van CoVe-techniek
Hoewel Chain of Verification een eenvoudige maar effectieve techniek lijkt, kent deze toch enkele beperkingen:
- Hallucinatie niet volledig verwijderd: Het garandeert niet de volledige verwijdering van hallucinaties uit de reactie en kan daarom misleidende informatie opleveren.
- Rekenintensief: Het genereren en uitvoeren van verificaties, samen met het genereren van antwoorden, kan de rekenkundige overhead en kosten verhogen. Het kan dus het proces vertragen of de computerkosten verhogen.
- Modelspecifieke beperking: Het succes van deze CoVe-methode hangt grotendeels af van de mogelijkheden van het model en zijn vermogen om zijn fouten te identificeren en recht te zetten.
LangChain Implementatie van CoVe
Basisoverzicht van algoritme
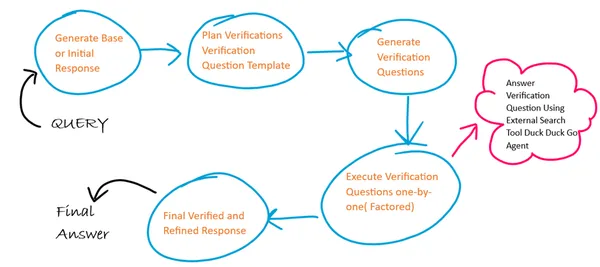
Hier zullen we 4 verschillende promptsjablonen gebruiken voor elk van de 4 stappen in CoVe en bij elke stap fungeert de uitvoer van de vorige stap als invoer voor de volgende stap. Ook volgen we een gefactoriseerde aanpak bij het uitvoeren van verificatievragen. We gebruiken een externe internetzoekmachine om antwoorden op onze verificatievragen te genereren.
Stap 1: Bibliotheken installeren en laden
!pip install langchain duckduckgo-searchStap 2: Maak en initialiseer de LLM-instantie
Hier gebruik ik Google Palm LLM in Langchain omdat het gratis beschikbaar is. Hiermee kunt u de API-sleutel voor Google Palm genereren link en log in met uw Google-account.
from langchain import PromptTemplate
from langchain.llms import GooglePalm
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough, RunnableLambda
API_KEY='Generated API KEY'
llm=GooglePalm(google_api_key=API_KEY)
llm.temperature=0.4
llm.model_name = 'models/text-bison-001'
llm.max_output_tokens=2048
Stap 3: Genereer een initiële basislijnrespons
We gaan nu een promptsjabloon maken om de initiële basislijnrespons te genereren en door deze sjabloon te gebruiken wordt de LLM-basislijnresponsketen gecreëerd.
Een LLM-keten gebruikt de LangChain-expressietaal om de keten samen te stellen. Hier geven we de promptsjabloon geketend (|) met LLM-model (|) en ten slotte Output-parser.
BASELINE_PROMPT = """Answer the below question which is asking for a concise factual answer. NO ADDITIONAL DETAILS.
Question: {query}
Answer:"""
# Chain to generate initial response
baseline_response_prompt_template = PromptTemplate.from_template(BASELINE_PROMPT)
baseline_response_chain = baseline_response_prompt_template | llm | StrOutputParser()Stap 4: Genereer een vraagsjabloon voor verificatievraag
Nu gaan we een sjabloon voor verificatievragen maken, dat u vervolgens zal helpen bij het genereren van de verificatievragen in de volgende stap.
VERIFICATION_QUESTION_TEMPLATE = """Your task is to create a verification question based on the below question provided.
Example Question: Who wrote the book 'God of Small Things' ?
Example Verification Question: Was book [God of Small Things] written by [writer]? If not who wrote [God of Small Things] ?
Explanation: In the above example the verification question focused only on the ANSWER_ENTITY (name of the writer) and QUESTION_ENTITY (book name).
Similarly you need to focus on the ANSWER_ENTITY and QUESTION_ENTITY from the actual question and generate verification question.
Actual Question: {query}
Final Verification Question:"""
# Chain to generate a question template for verification answers
verification_question_template_prompt_template = PromptTemplate.from_template(VERIFICATION_QUESTION_TEMPLATE)
verification_question_template_chain = verification_question_template_prompt_template | llm | StrOutputParser()Stap 5: Genereer een verificatievraag
Nu zullen we verificatievragen genereren met behulp van het hierboven gedefinieerde verificatievraagsjabloon:
VERIFICATION_QUESTION_PROMPT= """Your task is to create a series of verification questions based on the below question, the verfication question template and baseline response.
Example Question: Who wrote the book 'God of Small Things' ?
Example Verification Question Template: Was book [God of Small Things] written by [writer]? If not who wrote [God of Small Things]?
Example Baseline Response: Jhumpa Lahiri
Example Verification Question: 1. Was God of Small Things written by Jhumpa Lahiri? If not who wrote God of Small Things ?
Explanation: In the above example the verification questions focused only on the ANSWER_ENTITY (name of the writer) and QUESTION_ENTITY (name of book) based on the template and substitutes entity values from the baseline response.
Similarly you need to focus on the ANSWER_ENTITY and QUESTION_ENTITY from the actual question and substitute the entity values from the baseline response to generate verification questions.
Actual Question: {query}
Baseline Response: {base_response}
Verification Question Template: {verification_question_template}
Final Verification Questions:"""
# Chain to generate the verification questions
verification_question_generation_prompt_template = PromptTemplate.from_template(VERIFICATION_QUESTION_PROMPT)
verification_question_generation_chain = verification_question_generation_prompt_template | llm | StrOutputParser()
Stap 6: Voer de verificatievraag uit
Hier zullen we de externe zoektoolagent gebruiken om de verificatievraag uit te voeren. Deze agent is gebouwd met behulp van de Agent and Tools-module van LangChain en de DuckDuckGo-zoekmodule.
Opmerking – Er zijn tijdsbeperkingen in zoekagenten die zorgvuldig moeten worden gebruikt, aangezien meerdere verzoeken tot een fout kunnen leiden vanwege tijdsbeperkingen tussen verzoeken
from langchain.agents import ConversationalChatAgent, AgentExecutor
from langchain.tools import DuckDuckGoSearchResults
#create search agent
search = DuckDuckGoSearchResults()
tools = [search]
custom_system_message = "Assistant assumes no knowledge & relies on internet search to answer user's queries."
max_agent_iterations = 5
max_execution_time = 10
chat_agent = ConversationalChatAgent.from_llm_and_tools(
llm=llm, tools=tools, system_message=custom_system_message
)
search_executor = AgentExecutor.from_agent_and_tools(
agent=chat_agent,
tools=tools,
return_intermediate_steps=True,
handle_parsing_errors=True,
max_iterations=max_agent_iterations,
max_execution_time = max_execution_time
)
# chain to execute verification questions
verification_chain = RunnablePassthrough.assign(
split_questions=lambda x: x['verification_questions'].split("n"), # each verification question is passed one by one factored approach
) | RunnablePassthrough.assign(
answers = (lambda x: [{"input": q,"chat_history": []} for q in x['split_questions']])| search_executor.map() # search executed for each question independently
) | (lambda x: "n".join(["Question: {} Answer: {}n".format(question, answer['output']) for question, answer in zip(x['split_questions'], x['answers'])]))# Create final refined response
Stap 7: Genereer een definitieve, verfijnde respons
Nu zullen we het uiteindelijke, verfijnde antwoord genereren waarvoor we de promptsjabloon en de llm-keten definiëren.
FINAL_ANSWER_PROMPT= """Given the below `Original Query` and `Baseline Answer`, analyze the `Verification Questions & Answers` to finally provide the refined answer.
Original Query: {query}
Baseline Answer: {base_response}
Verification Questions & Answer Pairs:
{verification_answers}
Final Refined Answer:"""
# Chain to generate the final answer
final_answer_prompt_template = PromptTemplate.from_template(FINAL_ANSWER_PROMPT)
final_answer_chain = final_answer_prompt_template | llm | StrOutputParser()Stap 8: Zet alle ketens samen
Nu hebben we alle ketens die we eerder hebben gedefinieerd samengevoegd, zodat ze in één keer achter elkaar lopen.
chain = RunnablePassthrough.assign(
base_response=baseline_response_chain
) | RunnablePassthrough.assign(
verification_question_template=verification_question_template_chain
) | RunnablePassthrough.assign(
verification_questions=verification_question_generation_chain
) | RunnablePassthrough.assign(
verification_answers=verification_chain
) | RunnablePassthrough.assign(
final_answer=final_answer_chain
)
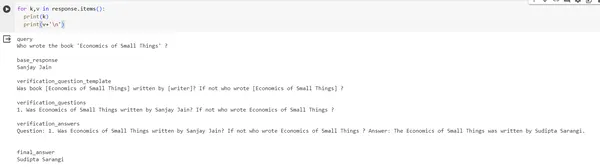
response = chain.invoke({"query": "Who wrote the book 'Economics of Small Things' ?"})
print(response)#output of response
{'query': "Who wrote the book 'Economics of Small Things' ?", 'base_response': 'Sanjay Jain', 'verification_question_template': 'Was book [Economics of Small Things] written by [writer]? If not who wrote [Economics of Small Things] ?', 'verification_questions': '1. Was Economics of Small Things written by Sanjay Jain? If not who wrote Economics of Small Things ?', 'verification_answers': 'Question: 1. Was Economics of Small Things written by Sanjay Jain? If not who wrote Economics of Small Things ? Answer: The Economics of Small Things was written by Sudipta Sarangi n', 'final_answer': 'Sudipta Sarangi'}Uitvoerafbeelding:
Conclusie
De Chain-of-Verification (CoVe)-techniek die in het onderzoek wordt voorgesteld, is een strategie die erop gericht is grote taalmodellen te construeren, kritischer na te denken over hun antwoorden en zichzelf indien nodig te corrigeren. Dit komt omdat deze methode de verificatie verdeelt in kleinere, beter beheersbare zoekopdrachten. Er is ook aangetoond dat het verbieden van het model om eerdere antwoorden te herzien helpt om herhaling van fouten of ‘hallucinaties’ te voorkomen. Door simpelweg te eisen dat het model zijn antwoorden dubbel controleert, worden de resultaten aanzienlijk vergroot. Het geven van meer mogelijkheden aan CoVe, zoals het toestaan van informatie uit externe bronnen, zou een manier kunnen zijn om de effectiviteit ervan te vergroten.
Key Takeaways
- Het Ketenproces is een handig hulpmiddel met verschillende combinaties van technieken waarmee we verschillende delen van onze reactie kunnen verifiëren.
- Naast de vele voordelen zijn er ook bepaalde beperkingen van het ketenproces die kunnen worden beperkt met behulp van verschillende instrumenten en mechanismen.
- We kunnen het LangChain-pakket gebruiken om dit CoVe-proces te implementeren.
Veelgestelde Vragen / FAQ
A. Er zijn meerdere manieren om hallucinaties op verschillende niveaus te verminderen: promptniveau (gedachteboom, gedachteketen), modelniveau (DoLa-decodering door contrasterende lagen) en zelfcontrole (CoVe).
A. We kunnen het verificatieproces in CoVe verbeteren door gebruik te maken van ondersteuning van externe zoekhulpmiddelen zoals de Google Search API etc. en voor domein- en aangepaste gebruiksscenario's kunnen we ophaaltechnieken zoals RAG gebruiken.
A. Momenteel is er geen kant-en-klare open-source tool die dit mechanisme implementeert, maar we kunnen er zelf een bouwen met behulp van de Serp API, Google Search en Lang Chains.
A. Retrieval Augmented Generation (RAG)-techniek wordt gebruikt voor domeinspecifieke gebruiksscenario's waarbij LLM feitelijk correcte antwoorden kan produceren op basis van het ophalen van deze domeinspecifieke gegevens.
A. De krant gebruikte het Llama 65B-model als LLM, en vervolgens gebruikten ze prompts-engineering met behulp van enkele voorbeelden om vragen te genereren en begeleiding te geven aan het model.
De in dit artikel getoonde media zijn geen eigendom van Analytics Vidhya en worden naar goeddunken van de auteur gebruikt.
Verwant
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.analyticsvidhya.com/blog/2023/12/chain-of-verification-implementation-using-langchain-expression-language-and-llm/

