At AWS re: Invent In 2023 hebben we de algemene beschikbaarheid aangekondigd van Kennisbanken voor Amazon Bedrock. Met Knowledge Bases voor Amazon Bedrock kunt u veilig funderingsmodellen (FM's) aansluiten Amazonebodem naar uw bedrijfsgegevens met behulp van een volledig beheerd Retrieval Augmented Generation (RAG)-model.
Voor op RAG gebaseerde toepassingen is de nauwkeurigheid van de gegenereerde reacties van FM's afhankelijk van de context die aan het model wordt gegeven. Contexten worden opgehaald uit vectorarchieven op basis van gebruikersquery's. In de onlangs uitgebrachte functie voor Knowledge Bases voor Amazon Bedrock, hybride zoeken, kunt u semantisch zoeken combineren met zoeken op trefwoorden. In veel situaties kan het echter voorkomen dat u documenten moet ophalen die in een bepaalde periode zijn gemaakt of die met bepaalde categorieën zijn getagd. Om de zoekresultaten te verfijnen, kunt u filteren op basis van documentmetagegevens om de nauwkeurigheid van het ophalen te verbeteren, wat op zijn beurt leidt tot relevantere FM-generaties die aansluiten bij uw interesses.
In dit bericht bespreken we de nieuwe functie voor het filteren van aangepaste metagegevens in Knowledge Bases voor Amazon Bedrock, die u kunt gebruiken om de zoekresultaten te verbeteren door uw opvragingen uit vectorwinkels vooraf te filteren.
Overzicht van metadatafiltering
Voorafgaand aan de release van metadatafiltering zouden alle semantisch relevante stukjes tot aan het vooraf ingestelde maximum worden geretourneerd als context die de FM kan gebruiken om een antwoord te genereren. Met metadatafilters kun je nu niet alleen semantisch relevante stukken ophalen, maar ook een goed gedefinieerde subset van die relevante chucks, gebaseerd op toegepaste metadatafilters en bijbehorende waarden.
Met deze functie kunt u nu voor elk document in de kennisbank een aangepast metadatabestand (elk maximaal 10 KB) aanleveren. U kunt filters toepassen op uw opvragingen, waarbij u de vectoropslag de opdracht geeft om vooraf te filteren op basis van documentmetagegevens en vervolgens naar relevante documenten te zoeken. Op deze manier heeft u controle over de opgehaalde documenten, vooral als uw zoekopdrachten dubbelzinnig zijn. U kunt bijvoorbeeld juridische documenten gebruiken met vergelijkbare termen voor verschillende contexten, of films met een vergelijkbaar plot die in verschillende jaren zijn uitgebracht. Bovendien bereikt u, door het aantal chunks waarnaar wordt gezocht, prestatievoordelen te verminderen, zoals een vermindering van de CPU-cycli en de kosten voor het bevragen van de vectoropslag, naast een verbetering van de nauwkeurigheid.

Om de functie voor het filteren van metagegevens te gebruiken, moet u naast de brongegevensbestanden metagegevensbestanden aanleveren met dezelfde naam als het brongegevensbestand en .metadata.json achtervoegsel. Metagegevens kunnen een tekenreeks, een getal of een Booleaanse waarde zijn. Hier volgt een voorbeeld van de inhoud van het metadatabestand:
De metadatafilterfunctie van Knowledge Bases voor Amazon Bedrock is beschikbaar in de AWS-regio's US East (N. Virginia) en US West (Oregon).
Hieronder volgen veelvoorkomende gebruiksscenario's voor het filteren van metagegevens:
- Documentchatbot voor een softwarebedrijf – Hiermee kunnen gebruikers productinformatie en handleidingen voor probleemoplossing vinden. Filters op het besturingssysteem of de applicatieversie kunnen bijvoorbeeld helpen voorkomen dat verouderde of irrelevante documenten worden opgehaald.
- Conversationeel zoeken naar de applicatie van een organisatie – Hiermee kunnen gebruikers documenten, kanbans, transcripties van vergaderingsopnamen en andere middelen doorzoeken. Met behulp van metadatafilters op werkgroepen, bedrijfseenheden of project-ID's kunt u de chatervaring personaliseren en de samenwerking verbeteren. Een voorbeeld zou zijn: 'Wat is de status van project Sphinx en de risico's die zich voordoen', waarbij gebruikers documenten kunnen filteren op een specifiek project of brontype (zoals e-mail of vergaderdocumenten).
- Intelligent zoeken naar softwareontwikkelaars – Hiermee kunnen ontwikkelaars zoeken naar informatie over een specifieke release. Filters op de releaseversie en het documenttype (zoals code, API-referentie of probleem) kunnen helpen bij het lokaliseren van relevante documenten.
Overzicht oplossingen
In de volgende secties laten we zien hoe u een gegevensset kunt voorbereiden voor gebruik als kennisbank, en vervolgens query's kunt uitvoeren met behulp van metagegevensfilters. U kunt een query uitvoeren met behulp van de AWS-beheerconsole of SDK.
Bereid een dataset voor Knowledge Bases voor Amazon Bedrock voor
Voor dit bericht gebruiken we een voorbeeldgegevensset over fictieve videogames om te illustreren hoe je metagegevens kunt opnemen en ophalen met behulp van Knowledge Bases voor Amazon Bedrock. Als je mee wilt volgen in je eigen AWS-account, download dan het bestand.
Als u metagegevens wilt toevoegen aan uw documenten in een bestaande kennisbank, maakt u de metagegevensbestanden met de verwachte bestandsnaam en het verwachte schema en gaat u vervolgens verder met de stap om uw gegevens te synchroniseren met de kennisbank om de incrementele opname te starten.
In onze voorbeeldgegevensset is het document van elke game een afzonderlijk CSV-bestand (bijvoorbeeld s3://$bucket_name/video_game/$game_id.csv) met de volgende kolommen:
title, description, genres, year, publisher, score
De metadata van elke game hebben het achtervoegsel .metadata.json (bijvoorbeeld, s3://$bucket_name/video_game/$game_id.csv.metadata.json) met het volgende schema:
Creëer een kennisbank voor Amazon Bedrock
Voor instructies voor het maken van een nieuwe kennisbank, zie Creëer een kennisbank. Voor dit voorbeeld gebruiken we de volgende instellingen:
- Op de Gegevensbron instellen pagina, onder Chunking-strategieselecteer Geen chunking, omdat u de documenten in de vorige stap al hebt voorbewerkt.
- In het Inbeddingsmodel sectie, kies Titan G1-inbedding – tekst.
- In het Vector-database sectie, kies Maak snel een nieuwe vectorwinkel. De functie voor het filteren van metagegevens is beschikbaar voor alle ondersteunde vectorarchieven.
Synchroniseer de dataset met de kennisbank
Nadat u de kennisbank hebt gemaakt en uw gegevensbestanden en metagegevensbestanden zich in een Amazon eenvoudige opslagservice (Amazon S3) bucket, kunt u de incrementele opname starten. Voor instructies, zie Synchroniseer om uw gegevensbronnen op te nemen in de kennisbank.
Query met metadatafiltering op de Amazon Bedrock-console
Om de metadatafilteropties op de Amazon Bedrock-console te gebruiken, voert u de volgende stappen uit:
- Kies op de Amazon Bedrock-console Kennisbanken in het navigatievenster.
- Kies de kennisbank die u heeft gemaakt.
- Kies Kennisbank testen.
- Kies de Configuraties pictogram en vouw vervolgens uit filters.
- Voer een voorwaarde in met de notatie: sleutel = waarde (bijvoorbeeld genres = Strategie) en druk op Enter.
- Als u de sleutel, waarde of operator wilt wijzigen, kiest u de voorwaarde.
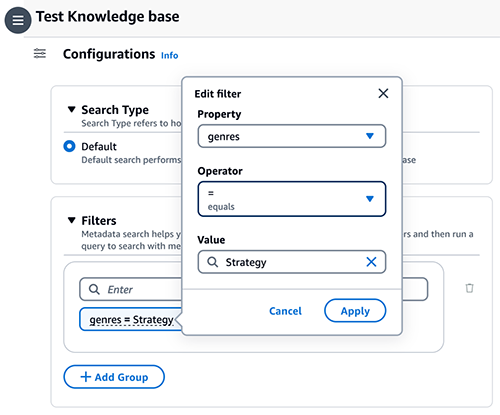
- Ga verder met de overige voorwaarden (bijvoorbeeld (genres = Strategie EN jaar >= 2023) OF (beoordeling >= 9))

- Wanneer u klaar bent, voert u uw vraag in het berichtvak in en kiest u vervolgens lopen.
Voor dit bericht voeren we de vraag in: “Een strategiespel met coole graphics uitgebracht na 2023.”
Query's uitvoeren met metadatafiltering met behulp van de SDK
Als u de SDK wilt gebruiken, maakt u eerst de client voor de Agenten voor Amazon Bedrock looptijd:
Bouw vervolgens het filter (hier volgen enkele voorbeelden):
Geef het filter door aan retrievalConfiguration van de Ophaal-API or Ophalen en genereren API:
De volgende tabel bevat een aantal reacties met verschillende voorwaarden voor het filteren van metagegevens.
| Vraag | Metagegevens filteren | Opgehaalde documenten | Waarnemingen |
| “Een strategiespel met coole graphics uitgebracht na 2023” | af |
* Viking Saga: The Sea Raider, jaar: 2023, genres: Strategie * Middeleeuws kasteel: belegering en verovering, jaar:2022, genres: Strategie * Cybernetische revolutie: opkomst van de machines, jaar:2022, genres: Strategie |
2/5 games voldoen aan de voorwaarde (genres = Strategie en jaartal >= 2023) |
| On | * Viking Saga: The Sea Raider, jaar: 2023, genres: Strategie * Fantasy Kingdoms: Chronicles of Eldoria, jaar: 2023, genres: Strategie |
2/2 games voldoen aan de voorwaarde (genres = Strategie en jaartal >= 2023) |
Naast aangepaste metagegevens kunt u ook filteren met S3-voorvoegsels (dit zijn ingebouwde metagegevens, u hoeft dus geen metagegevensbestanden aan te leveren). Als u de speldocumenten bijvoorbeeld in voorvoegsels ordent op uitgever (bijvoorbeeld s3://$bucket_name/video_game/$publisher/$game_id.csv), kunt u filteren op de specifieke uitgever (bijvoorbeeld neo_tokyo_games) met behulp van de volgende syntaxis:
Opruimen
Voer de volgende stappen uit om uw bronnen op te schonen:
- Verwijder de kennisbank:
- Kies op de Amazon Bedrock-console Kennisbanken voor orkestratie in het navigatievenster.
- Kies de kennisbank die u heeft gemaakt.
- Let op de AWS Identiteits- en toegangsbeheer (IAM) servicerolnaam in het Overzicht kennisbank pagina.
- In het Vector-database sectie, let op de collectie ARN.
- Kies Verwijderen voer vervolgens verwijderen in om te bevestigen.
- Verwijder de vectordatabase:
- Op de Amazon OpenSearch-service console, kies Collecties voor Serverless in het navigatievenster.
- Voer in de zoekbalk de collectie ARN in die u heeft opgeslagen.
- Selecteer de collectie en kies Verwijder.
- Voer bevestigen in de bevestigingsvraag in en kies vervolgens Verwijder.
- Verwijder de IAM-servicerol:
- Kies op de IAM-console rollen in het navigatievenster.
- Zoek naar de rolnaam die u eerder hebt genoteerd.
- Selecteer de rol en kies Verwijder.
- Voer de rolnaam in de bevestigingsprompt in en verwijder de rol.
- Verwijder de voorbeeldgegevensset:
- Navigeer op de Amazon S3-console naar de S3-bucket die u hebt gebruikt.
- Selecteer het voorvoegsel en de bestanden en kies vervolgens Verwijder.
- Voer permanent verwijderen in de bevestigingsvraag in om te verwijderen.
Conclusie
In dit bericht hebben we de functie voor het filteren van metagegevens in Knowledge Bases voor Amazon Bedrock besproken. Je hebt geleerd hoe je aangepaste metagegevens aan documenten kunt toevoegen en deze als filters kunt gebruiken terwijl je de documenten ophaalt en bevraagt met behulp van de Amazon Bedrock-console en de SDK. Dit helpt de nauwkeurigheid van de context te verbeteren, waardoor de antwoorden op zoekopdrachten nog relevanter worden en tegelijkertijd de kosten voor het doorzoeken van de vectordatabase worden verlaagd.
Voor aanvullende bronnen raadpleegt u het volgende:
Over de auteurs
 Corvus Lee is een Senior GenAI Labs Solutions Architect, gevestigd in Londen. Hij heeft een passie voor het ontwerpen en ontwikkelen van prototypen die generatieve AI gebruiken om klantproblemen op te lossen. Hij blijft ook op de hoogte van de nieuwste ontwikkelingen op het gebied van generatieve AI en retrievaltechnieken door deze toe te passen op scenario's uit de echte wereld.
Corvus Lee is een Senior GenAI Labs Solutions Architect, gevestigd in Londen. Hij heeft een passie voor het ontwerpen en ontwikkelen van prototypen die generatieve AI gebruiken om klantproblemen op te lossen. Hij blijft ook op de hoogte van de nieuwste ontwikkelingen op het gebied van generatieve AI en retrievaltechnieken door deze toe te passen op scenario's uit de echte wereld.
 Ahmed Ewis is een Senior Solutions Architect bij AWS GenAI Labs en helpt klanten bij het bouwen van generatieve AI-prototypes om bedrijfsproblemen op te lossen. Als hij niet met klanten samenwerkt, speelt hij graag met zijn kinderen en kookt hij graag.
Ahmed Ewis is een Senior Solutions Architect bij AWS GenAI Labs en helpt klanten bij het bouwen van generatieve AI-prototypes om bedrijfsproblemen op te lossen. Als hij niet met klanten samenwerkt, speelt hij graag met zijn kinderen en kookt hij graag.
 Chris Pecora is een generatieve AI-datawetenschapper bij Amazon Web Services. Hij heeft een passie voor het bouwen van innovatieve producten en oplossingen, terwijl hij zich ook richt op door de klant geobsedeerde wetenschap. Als hij niet bezig is met het uitvoeren van experimenten en het bijhouden van de nieuwste ontwikkelingen op het gebied van GenAI, brengt hij graag tijd door met zijn kinderen.
Chris Pecora is een generatieve AI-datawetenschapper bij Amazon Web Services. Hij heeft een passie voor het bouwen van innovatieve producten en oplossingen, terwijl hij zich ook richt op door de klant geobsedeerde wetenschap. Als hij niet bezig is met het uitvoeren van experimenten en het bijhouden van de nieuwste ontwikkelingen op het gebied van GenAI, brengt hij graag tijd door met zijn kinderen.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/knowledge-bases-for-amazon-bedrock-now-supports-metadata-filtering-to-improve-retrieval-accuracy/

