Is het de moeite waard om benaderingen van het machine learning-proces te vergelijken? Zijn er fundamentele verschillen tussen dergelijke kaders?
Hoewel klassieke benaderingen Aangezien dergelijke taken bestaan en al een tijdje bestaan, is het de moeite waard om om verschillende redenen vanuit nieuwe en andere perspectieven te raadplegen: Heb ik iets gemist? Zijn er nieuwe benaderingen die nog niet eerder waren overwogen? Moet ik mijn kijk op hoe ik machine learning benader veranderen?
De 2 meest recente bronnen die ik ben tegengekomen die kaders schetsen voor het benaderen van het proces van machine learning zijn die van Yufeng Guo De 7 stappen van machinaal leren en sectie 4.5 van Francois Chollet's Diep leren met Python. Is een van deze iets anders dan hoe je zo'n taak al verwerkt?
Wat volgt zijn de contouren van deze 2 benaderingen van gesuperviseerd machinaal leren, een korte vergelijking en een poging om de twee te verzoenen in een derde raamwerk dat de belangrijkste gebieden van het (gesuperviseerde) machinale leerproces belicht.
Ik kwam het artikel van Guo eigenlijk tegen door voor het eerst te kijken een filmpje van hem op Youtube. Het bericht heeft dezelfde inhoud als de video, dus als je geïnteresseerd bent, is een van de twee bronnen voldoende.
Guo legde de stappen als volgt uit (met een beetje ad-libbing van mijn kant):
- Data Collection
→ De kwantiteit en kwaliteit van uw gegevens bepalen hoe nauwkeurig ons model is
→ Het resultaat van deze stap is over het algemeen een weergave van gegevens (Guo vereenvoudigt het specificeren van een tabel) die we zullen gebruiken voor training
→ Het gebruiken van vooraf verzamelde data, via datasets van Kaggle, UCI, etc., past nog steeds in deze stap - Data voorbereiding
→ Wrangle data en bereid deze voor op training
→ Ruim op wat dit nodig heeft (verwijder duplicaten, corrigeer fouten, behandel ontbrekende waarden, normalisatie, conversies van gegevenstypes, enz.)
→ Willekeurige gegevens, waardoor de effecten worden gewist van de specifieke volgorde waarin we onze gegevens hebben verzameld en/of anderszins hebben voorbereid
→ Visualiseer gegevens om relevante verbanden tussen variabelen of klassenonevenwichtigheden te detecteren (waarschuwing voor vooringenomenheid!), of voer andere verkennende analyses uit
→ Opgesplitst in trainings- en evaluatiesets - Kies een model
→ Verschillende algoritmen zijn voor verschillende taken; kies de juiste - Train het model
→ Het doel van trainen is om zo vaak mogelijk een vraag goed te beantwoorden of een voorspelling te doen
→ Voorbeeld lineaire regressie: algoritme zou waarden moeten leren voor m (of W) en b (x is invoer, y wordt uitgevoerd)
→ Elke procesherhaling is een trainingsstap - Evalueer het model
→ Gebruikt een metriek of een combinatie van metrieken om de objectieve prestaties van het model te "meten".
→ Test het model tegen eerder ongeziene gegevens
→ Deze ongeziene gegevens zijn bedoeld om enigszins representatief te zijn voor de modelprestaties in de echte wereld, maar helpen nog steeds bij het afstemmen van het model (in tegenstelling tot testgegevens, wat niet het geval is)
→ Goede trein/evaluatie verdeling? 80/20, 70/30 of vergelijkbaar, afhankelijk van domein, beschikbaarheid van gegevens, bijzonderheden van de dataset, enz. - Parameter afstemmen
→ Deze stap verwijst naar hyperparameter afstemmen, wat een "kunstvorm" is in tegenstelling tot een wetenschap
→ Stem modelparameters af voor verbeterde prestaties
→ Hyperparameters van een eenvoudig model kunnen zijn: aantal trainingsstappen, leersnelheid, initialisatiewaarden en distributie, enz. - Voorspellingen maken
→ Met behulp van verdere (testset)gegevens die tot nu toe aan het model zijn onthouden (en waarvan klasselabels bekend zijn), wordt het model getest; een betere benadering van hoe het model in de echte wereld zal presteren
In sectie 4.5 van zijn boek, schetst Chollet een universele workflow van machine learning, die hij beschrijft als een blauwdruk voor het oplossen van machine learning-problemen:
De blauwdruk verbindt de concepten waarover we in dit hoofdstuk hebben geleerd: probleemdefinitie, evaluatie, feature-engineering en het bestrijden van overfitting.
Hoe verhoudt dit zich tot het bovenstaande raamwerk van Guo? Laten we eens kijken naar de 7 stappen van de behandeling van Chollet (in gedachten houdend dat, hoewel niet expliciet wordt vermeld dat het specifiek voor hen is gemaakt, zijn blauwdruk is geschreven voor een boek over neurale netwerken):
- Het definiëren van het probleem en het samenstellen van een dataset
- Een maatstaf voor succes kiezen
- Beslissen over een evaluatieprotocol
- Voorbereiding van uw gegevens
- Een model ontwikkelen dat het beter doet dan een baseline
- Opschalen: een model ontwikkelen dat overfit
- Uw model regulariseren en uw parameters afstemmen
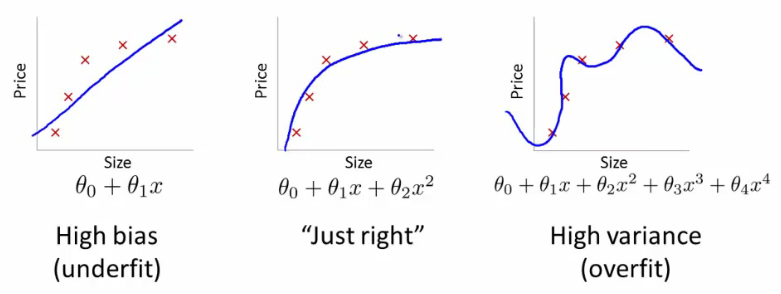
Bron: Andrew Ng's Machine Learning-klas op Stanford
De workflow van Chollet is van een hoger niveau en richt zich meer op het van goed naar geweldig krijgen van uw model, in tegenstelling tot die van Guo, die zich meer bezig lijkt te houden met het van nul naar goed gaan. Hoewel het niet noodzakelijkerwijs andere belangrijke stappen overboord gooit om dit te doen, legt de blauwdruk meer nadruk op afstemming van hyperparameters en regularisatie in zijn streven naar grootsheid. Een vereenvoudiging lijkt hier te zijn:
We kunnen redelijkerwijs concluderen dat het raamwerk van Guo een "beginnersbenadering" schetst van het machine-leerproces, waarbij vroege stappen explicieter worden gedefinieerd, terwijl dat van Chollet een meer geavanceerde benadering is, waarbij zowel de expliciete beslissingen met betrekking tot modelevaluatie als het aanpassen van machine-leermodellen worden benadrukt. Beide benaderingen zijn even geldig en schrijven niets voor dat fundamenteel van elkaar verschilt; je zou Chollet's bovenop die van Guo kunnen leggen en ontdekken dat, hoewel de 7 stappen van de 2 modellen niet op één lijn zouden liggen, ze in totaal dezelfde taken zouden uitvoeren.
Chollet's toewijzen aan Guo's, hier zie ik de stappen in een rij staan (Guo's zijn genummerd, terwijl Chollet's worden vermeld onder de overeenkomstige Guo-stap met hun Chollet-workflowstapnummer tussen haakjes):
- Software voor buiten
→ Het probleem definiëren en een dataset samenstellen (1) - Data voorbereiding
→ Uw gegevens voorbereiden (4) - Kies model
- Trein model
→ Een model ontwikkelen dat het beter doet dan een baseline (5) - Evalueer model
→ Een maatstaf voor succes kiezen (2)
→ Beslissen over een evaluatieprotocol (3) - Afstemming van parameters
→ Opschalen: een model ontwikkelen dat overfit (6)
→ Uw model regulariseren en uw parameters afstemmen (7) - Voorspellen
Het is niet perfect, maar ik blijf erbij.
Mijns inziens levert dit iets belangrijks op: beide kaders zijn het eens en leggen samen de nadruk op bepaalde punten van het kader. Het moge duidelijk zijn dat modelevaluatie en parameterafstemming belangrijke aspecten zijn van machine learning. Daarnaast zijn afgesproken gebieden van belang zijn de assemblage/voorbereiding van gegevens en originele modelselectie/training.
Laten we het bovenstaande gebruiken om een vereenvoudigd raamwerk voor machine learning samen te stellen, de 5 hoofdgebieden van het machine learning-proces:
- Gegevensverzameling en voorbereiding
→ alles, van het kiezen waar de gegevens moeten worden opgehaald tot het punt waarop ze schoon zijn en klaar zijn voor functieselectie/engineering - Feature selectie en feature engineering
→ dit omvat alle wijzigingen in de gegevens vanaf het moment dat ze zijn opgeschoond tot het moment dat ze worden opgenomen in het machine learning-model - Het machine learning-algoritme kiezen en ons eerste model trainen
→ een “beter dan baseline” resultaat krijgen waarop we (hopelijk) kunnen verbeteren - Ons model evalueren
→ dit omvat zowel de selectie van de maatregel als de eigenlijke evaluatie; schijnbaar een kleinere stap dan andere, maar belangrijk voor ons eindresultaat - Modeltweaking, regularisatie en hyperparametertuning
→ dit is waar we iteratief van een "goed genoeg" model naar onze beste inspanning gaan
Dus, welk raamwerk moet je gebruiken? Zijn er echt belangrijke verschillen? Bieden die van Guo en Chollet iets dat eerder ontbrak? Levert dit vereenvoudigde raamwerk echt voordeel op? Zolang de basis wordt gedekt en de taken die expliciet bestaan in de overlapping van de kaders worden nagestreefd, zou het resultaat van het volgen van een van de twee modellen gelijk zijn aan dat van het andere. Uw uitkijkpunt of ervaringsniveau kan een voorkeur voor één vertonen.
Zoals je misschien al geraden hebt, ging het hier niet zozeer om het beslissen over of het contrasteren met specifieke kaders, maar om een onderzoek naar wat een redelijk machine learning-proces is. moet ziet eruit als.
Matthijs Mayo (@mattmayo13) is een datawetenschapper en de hoofdredacteur van KDnuggets, het baanbrekende online hulpmiddel voor gegevenswetenschap en machine learning. Zijn interesses liggen in natuurlijke taalverwerking, ontwerp en optimalisatie van algoritmen, leren zonder toezicht, neurale netwerken en geautomatiseerde benaderingen van machine learning. Matthew heeft een master in computerwetenschappen en een graduaat in datamining. Hij is te bereiken via editor1 op kdnuggets[dot]com.

