Afbeelding door auteur
Als je duikt in de wereld van datawetenschap en machinaal leren, is een van de fundamentele vaardigheden die je tegenkomt de kunst van het lezen van gegevens. Als u er al enige ervaring mee heeft, bent u waarschijnlijk bekend met JSON (JavaScript Object Notation) – een populair formaat voor zowel het opslaan als uitwisselen van gegevens.
Bedenk hoe NoSQL-databases zoals MongoDB graag gegevens in JSON opslaan, of hoe REST API's vaak in hetzelfde formaat reageren.
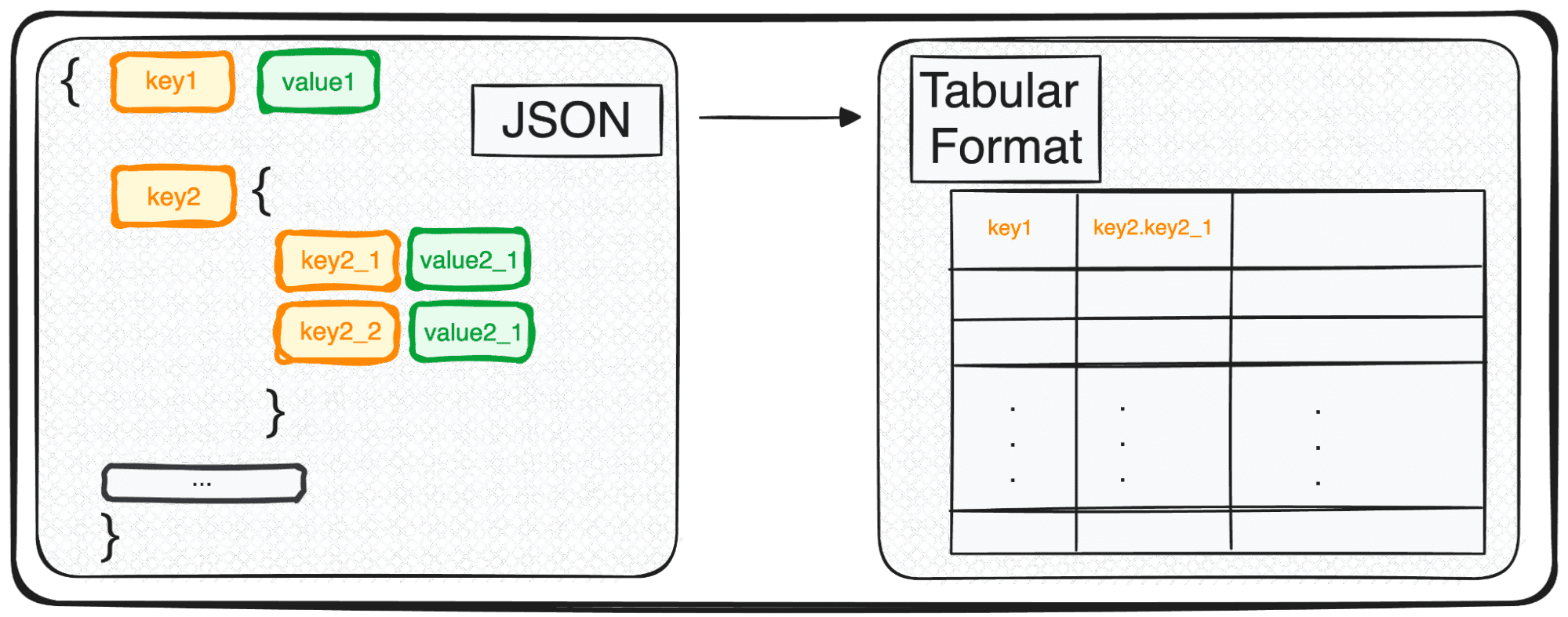
Hoewel JSON perfect is voor opslag en uitwisseling, is het echter nog niet helemaal klaar voor diepgaande analyse in zijn ruwe vorm. Dit is waar we het transformeren in iets dat analytisch vriendelijker is: een tabelformaat.
Dus of je nu te maken hebt met een enkel JSON-object of een prachtige reeks daarvan, in de termen van Python ben je in wezen bezig met een dictaat of een lijst met dictaten.
Laten we samen onderzoeken hoe deze transformatie zich ontvouwt, waardoor onze data rijp worden voor analyse ????
Vandaag leg ik een magisch commando uit waarmee we elke JSON binnen enkele seconden gemakkelijk in een tabelvorm kunnen parseren.
En het is... pd.json_normalize()
Laten we dus eens kijken hoe het werkt met verschillende soorten JSON's.
Het eerste type JSON waarmee we kunnen werken, zijn JSON's met één niveau met een paar sleutels en waarden. We definiëren onze eerste eenvoudige JSON's als volgt:
Code door auteur
Laten we dus de noodzaak simuleren om met deze JSON te werken. We weten allemaal dat er niet veel te doen is in hun JSON-formaat. We moeten deze JSON's transformeren in een leesbaar en aanpasbaar formaat... wat betekent Panda's DataFrames!
1.1 Omgaan met eenvoudige JSON-structuren
Eerst moeten we de panda-bibliotheek importeren en dan kunnen we de opdracht pd.json_normalize() als volgt gebruiken:
import pandas as pd
pd.json_normalize(json_string)
Door deze opdracht toe te passen op een JSON met één record, verkrijgen we de meest eenvoudige tabel. Wanneer onze gegevens echter wat complexer zijn en een lijst met JSON's presenteren, kunnen we nog steeds dezelfde opdracht gebruiken zonder verdere complicaties en zal de uitvoer overeenkomen met een tabel met meerdere records.

Afbeelding door auteur
Makkelijk... toch?
De volgende natuurlijke vraag is wat er gebeurt als sommige waarden ontbreken.
1.2 Omgaan met nulwaarden
Stel je voor dat sommige waarden niet worden vermeld, bijvoorbeeld dat het inkomensrecord voor David ontbreekt. Wanneer we onze JSON transformeren in een eenvoudig panda-dataframe, wordt de overeenkomstige waarde weergegeven als NaN.

Afbeelding door auteur
En hoe zit het als ik slechts een deel van de velden wil hebben?
1.3 Alleen die kolommen selecteren die van belang zijn
In het geval dat we slechts enkele specifieke velden willen transformeren in een panda's DataFrame in tabelvorm, staat de opdracht json_normalize() ons niet toe te kiezen welke velden we willen transformeren.
Daarom moet een kleine voorbewerking van de JSON worden uitgevoerd, waarbij we alleen die kolommen filteren die van belang zijn.
# Fields to include
fields = ['name', 'city']
# Filter the JSON data
filtered_json_list = [{key: value for key, value in item.items() if key in fields} for item in simple_json_list]
pd.json_normalize(filtered_json_list)
Laten we dus naar een meer geavanceerde JSON-structuur gaan.
Als we te maken hebben met JSON's met meerdere niveaus, hebben we te maken met geneste JSON's binnen verschillende niveaus. De procedure is hetzelfde als voorheen, maar in dit geval kunnen we kiezen hoeveel niveaus we willen transformeren. Standaard zal de opdracht altijd alle niveaus uitvouwen en nieuwe kolommen genereren die de samengevoegde naam van alle geneste niveaus bevatten.
Dus als we de volgende JSON's normaliseren.
Code door auteur
We zouden de volgende tabel krijgen met 3 kolommen onder de veldvaardigheden:
- vaardigheden.python
- vaardigheden.SQL
- vaardigheden.GCP
en 4 kolommen onder de veldrollen
- rollen.projectmanager
- rollen.data engineer
- rollen.datawetenschapper
- rollen.data-analist

Afbeelding door auteur
Stel je echter voor dat we gewoon ons hoogste niveau willen transformeren. We kunnen dit doen door de parameter max_level specifiek te definiëren op 0 (het max_level dat we willen uitbreiden).
pd.json_normalize(mutliple_level_json_list, max_level = 0)
De in behandeling zijnde waarden worden onderhouden binnen JSON's binnen ons panda's DataFrame.

Afbeelding door auteur
Het laatste geval dat we kunnen vinden is het hebben van een geneste lijst binnen een JSON-veld. Daarom definiëren we eerst onze JSON's die we moeten gebruiken.
Code door auteur
We kunnen deze gegevens effectief beheren met behulp van Pandas in Python. De functie pd.json_normalize() is in deze context bijzonder nuttig. Het kan de JSON-gegevens, inclusief de geneste lijst, afvlakken tot een gestructureerd formaat dat geschikt is voor analyse. Wanneer deze functie wordt toegepast op onze JSON-gegevens, produceert deze een genormaliseerde tabel waarin de geneste lijst is opgenomen als onderdeel van de velden.
Bovendien biedt Pandas de mogelijkheid om dit proces verder te verfijnen. Door gebruik te maken van de parameter record_path in pd.json_normalize(), kunnen we de functie opdracht geven om specifiek de geneste lijst te normaliseren.
Deze actie resulteert in een speciale tabel exclusief voor de inhoud van de lijst. Standaard worden bij dit proces alleen de elementen in de lijst uitgevouwen. Om deze tabel echter te verrijken met extra context, zoals het behouden van een bijbehorende ID voor elk record, kunnen we de metaparameter gebruiken.

Afbeelding door auteur
Samenvattend is de transformatie van JSON-gegevens naar CSV-bestanden met behulp van Python's Pandas-bibliotheek eenvoudig en effectief.
JSON is nog steeds het meest voorkomende formaat in moderne gegevensopslag en -uitwisseling, met name in NoSQL-databases en REST API's. Het brengt echter enkele belangrijke analytische uitdagingen met zich mee bij het omgaan met gegevens in het ruwe formaat.
De cruciale rol van pd.json_normalize() van Pandas komt naar voren als een geweldige manier om met dergelijke formaten om te gaan en onze gegevens om te zetten in Panda's DataFrame.
Ik hoop dat deze handleiding nuttig was, en dat u de volgende keer dat u met JSON te maken krijgt, dit op een effectievere manier kunt doen.
U kunt de bijbehorende Jupyter Notebook bekijken in de volgende GitHub-opslagplaats.
Joseph Ferrer is een analytisch ingenieur uit Barcelona. Hij is afgestudeerd in natuurkunde en werkt momenteel op het gebied van datawetenschap toegepast op menselijke mobiliteit. Hij is een parttime contentmaker die zich richt op datawetenschap en -technologie. U kunt contact met hem opnemen via LinkedIn, Twitter or Medium.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.kdnuggets.com/converting-jsons-to-pandas-dataframes-parsing-them-the-right-way?utm_source=rss&utm_medium=rss&utm_campaign=converting-jsons-to-pandas-dataframes-parsing-them-the-right-way

