
Afbeelding door auteur
Supervised is een subcategorie van machine learning waarbij de computer leert van de gelabelde dataset die zowel de invoer als de juiste uitvoer bevat. Er wordt geprobeerd de mappingfunctie te vinden die de invoer (x) relateert aan de uitvoer (y). Je kunt het zien als het leren van je jongere broer of zus hoe ze verschillende dieren kunnen herkennen. Je laat ze een paar plaatjes zien (x) en vertelt hoe elk dier heet (y). Na een bepaalde tijd zullen ze de verschillen leren en de nieuwe afbeelding correct kunnen herkennen. Dit is de fundamentele intuïtie achter begeleid leren. Laten we, voordat we verder gaan, eerst eens dieper kijken naar de werking ervan.
Hoe werkt begeleid leren?
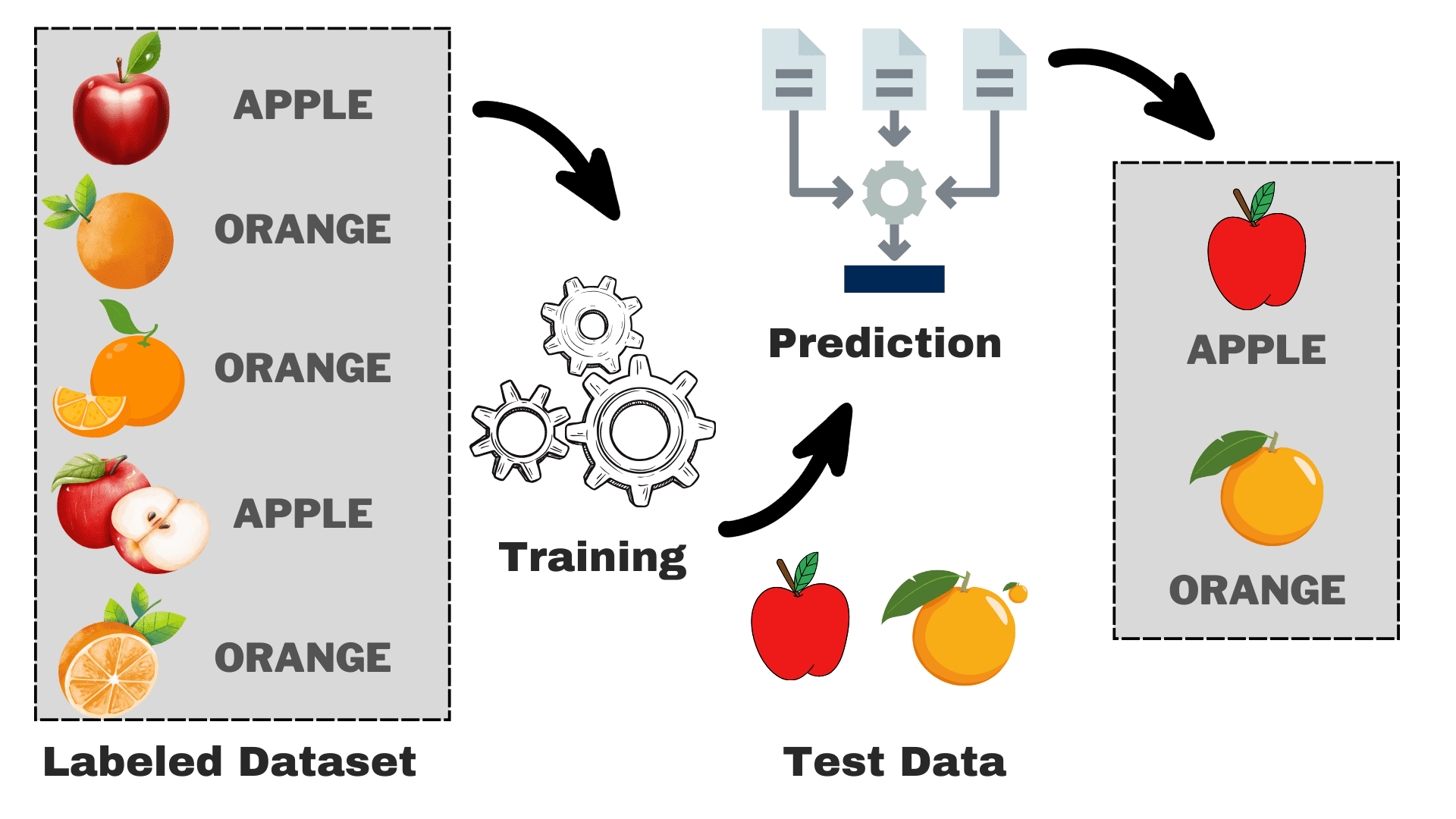
Afbeelding door auteur
Stel dat u een model wilt bouwen dat op basis van bepaalde kenmerken onderscheid kan maken tussen appels en peren. We kunnen het proces opsplitsen in de volgende taken:
- Gegevensverzameling: Verzamel een dataset met afbeeldingen van appels en sinaasappels, en elke afbeelding wordt gelabeld als 'appel' of 'sinaasappel'.
- Model selectie: We moeten hier de juiste classificator kiezen, ook wel bekend als het juiste begeleide machine learning-algoritme voor uw taak. Het is net zoiets als het kiezen van de juiste bril, waardoor u beter kunt zien
- Het model trainen: Nu voed je het algoritme met de gelabelde afbeeldingen van appels en sinaasappels. Het algoritme kijkt naar deze plaatjes en leert de verschillen herkennen, zoals de kleur, vorm en grootte van appels en sinaasappels.
- Evalueren & testen: Om te controleren of uw model correct werkt, zullen we er enkele onzichtbare afbeeldingen aan toevoegen en de voorspellingen vergelijken met de werkelijke.
Begeleid leren kan worden onderverdeeld in twee hoofdtypen:
Classificatie
Bij classificatietaken is het primaire doel om gegevenspunten toe te wijzen aan specifieke categorieën uit een reeks afzonderlijke klassen. Wanneer er slechts twee mogelijke uitkomsten zijn, zoals ‘ja’ of ‘nee’, ‘spam’ of ‘geen spam’, ‘geaccepteerd’ of ‘afgewezen’, wordt dit binaire classificatie genoemd. Als er echter meer dan twee categorieën of klassen bij betrokken zijn, zoals het beoordelen van studenten op basis van hun cijfers (bijvoorbeeld A, B, C, D, F), wordt dit een voorbeeld van een multi-classificatieprobleem.
Regressie
Voor regressieproblemen probeert u een continue numerieke waarde te voorspellen. U bent bijvoorbeeld misschien geïnteresseerd in het voorspellen van uw eindexamenscores op basis van uw eerdere prestaties in de klas. De voorspelde scores kunnen elke waarde binnen een specifiek bereik omvatten, in ons geval doorgaans van 0 tot 100.
Nu hebben we een basiskennis van het totale proces. We zullen de populaire begeleide machine learning-algoritmen, hun gebruik en hoe ze werken onderzoeken:
1. Lineaire regressie
Zoals de naam doet vermoeden, wordt het gebruikt voor regressietaken zoals het voorspellen van aandelenkoersen, het voorspellen van de temperatuur, het inschatten van de waarschijnlijkheid van ziekteprogressie, enz. We proberen het doel (afhankelijke variabele) te voorspellen met behulp van de set labels (onafhankelijke variabelen). Er wordt van uitgegaan dat we een lineaire relatie hebben tussen onze invoerkenmerken en het label. Het centrale idee draait om het voorspellen van de best passende lijn voor onze datapunten door de fout tussen onze werkelijke en voorspelde waarden te minimaliseren. Deze lijn wordt weergegeven door de vergelijking:
Waar,
- Y Voorspelde opbrengst.
- X = Voer een kenmerk of kenmerkmatrix in in meervoudige lineaire regressie
- b0 = Snijpunt (waar de lijn de Y-as kruist).
- b1 = Helling of coëfficiënt die de steilheid van de lijn bepaalt.
Het schat de helling van de lijn (gewicht) en het snijpunt (bias). Deze lijn kan verder worden gebruikt om voorspellingen te doen. Hoewel dit het eenvoudigste en bruikbaarste model is voor het ontwikkelen van de basislijnen, is het zeer gevoelig voor uitschieters die de positie van de lijn kunnen beïnvloeden.
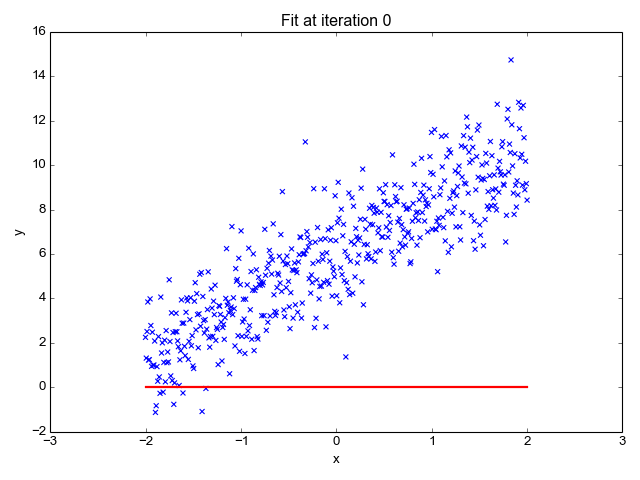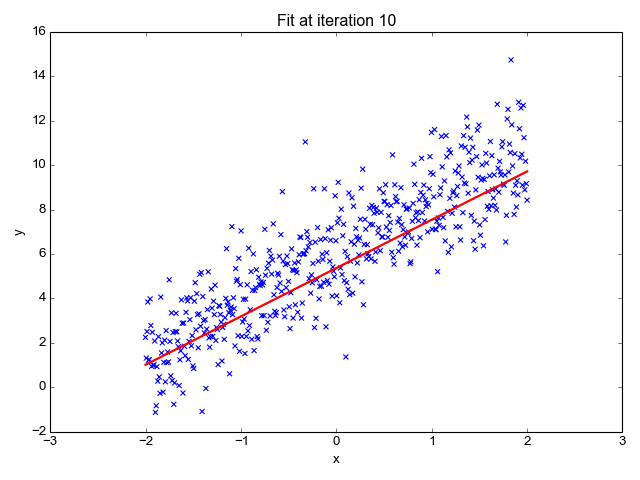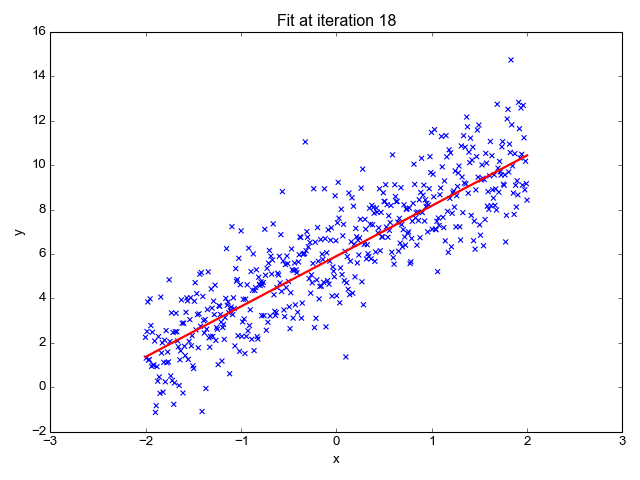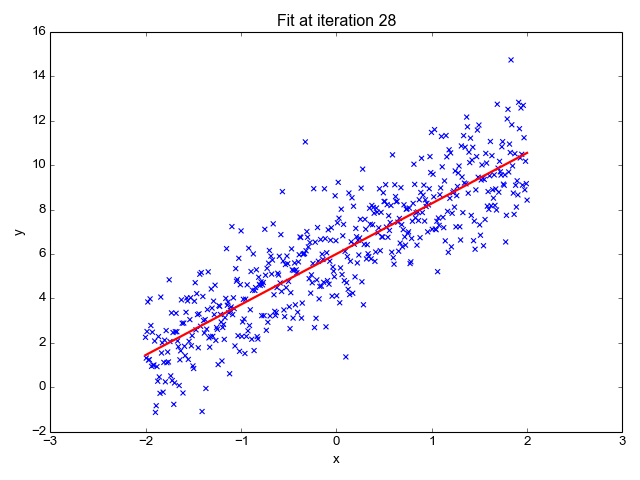
GIF aan Primo.ai
2. Logistieke regressie
Hoewel het regressie in zijn naam heeft, wordt het fundamenteel gebruikt voor binaire classificatieproblemen. Het voorspelt de waarschijnlijkheid van een positieve uitkomst (afhankelijke variabele) die in het bereik van 0 tot 1 ligt. Door een drempel in te stellen (meestal 0.5) classificeren we datapunten: die met een waarschijnlijkheid groter dan de drempel behoren tot de positieve klasse, en vice versa. Logistische regressie berekent deze waarschijnlijkheid met behulp van de sigmoïdefunctie die wordt toegepast op de lineaire combinatie van de invoerkenmerken die is gespecificeerd als:
Waar,
- P(Y=1) = Waarschijnlijkheid van het datapunt dat tot de positieve klasse behoort
- X1 ,… ,Xn = Ingangsfuncties
- b0,….,bn = Invoergewichten die het algoritme tijdens de training leert
Deze sigmoïdefunctie heeft de vorm van een S-achtige curve die elk gegevenspunt omzet in een waarschijnlijkheidsscore binnen het bereik van 0-1. Voor een beter begrip kunt u de onderstaande grafiek bekijken.
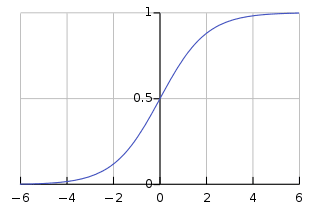
Afbeelding aan Wikipedia
Een waarde dichter bij 1 duidt op een groter vertrouwen in de voorspelling van het model. Net als lineaire regressie staat het bekend om zijn eenvoud, maar we kunnen de classificatie met meerdere klassen niet uitvoeren zonder wijziging van het oorspronkelijke algoritme.
3. Beslisbomen
In tegenstelling tot de bovenstaande twee algoritmen kunnen beslissingsbomen worden gebruikt voor zowel classificatie- als regressietaken. Het heeft een hiërarchische structuur, net als de stroomdiagrammen. Bij elk knooppunt wordt een beslissing over het pad genomen op basis van enkele kenmerkwaarden. Het proces gaat door tenzij we het laatste knooppunt bereiken dat de uiteindelijke beslissing weergeeft. Hier volgen enkele basisterminologieën waarvan u op de hoogte moet zijn:
- Hoofdknooppunt: Het bovenste knooppunt dat de gehele gegevensset bevat, wordt het hoofdknooppunt genoemd. Vervolgens selecteren we de beste eigenschap met behulp van een algoritme om de dataset in twee of meer subbomen te splitsen.
- Interne knooppunten: Elk intern knooppunt vertegenwoordigt een specifiek kenmerk en een beslissingsregel om de volgende mogelijke richting voor een datapunt te bepalen.
- Bladknopen: De eindknooppunten die een klassenlabel vertegenwoordigen, worden bladknooppunten genoemd.
Het voorspelt de continue numerieke waarden voor de regressietaken. Naarmate de omvang van de dataset groeit, vangt deze de ruis op die tot overfitting leidt. Dit kan worden verholpen door de beslisboom te snoeien. We verwijderen takken die de nauwkeurigheid van onze beslissingen niet significant verbeteren. Dit zorgt ervoor dat onze stamboom gefocust blijft op de belangrijkste factoren en voorkomt dat deze verdwaalt in de details.
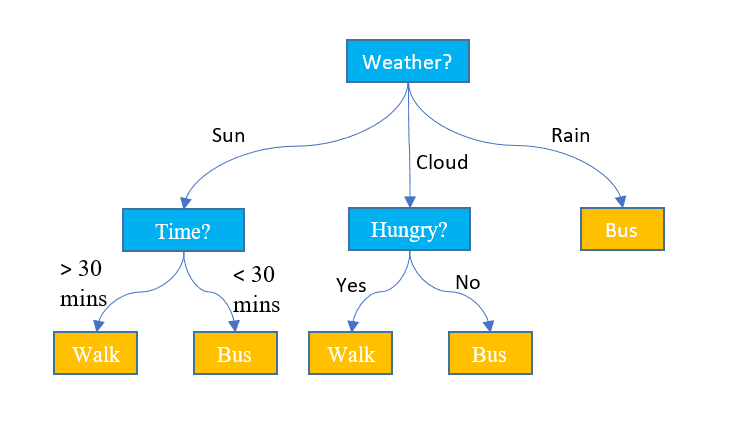
Afbeelding door Jake Hoare op Displayr
4. Willekeurig bos
Willekeurig bos kan ook worden gebruikt voor zowel de classificatie- als de regressietaken. Het is een groep beslissingsbomen die samenwerken om de uiteindelijke voorspelling te doen. Je kunt het zien als een commissie van deskundigen die een collectief besluit neemt. Hier is hoe het werkt:
- Gegevensbemonstering: In plaats van de hele dataset in één keer te nemen, worden de willekeurige steekproeven genomen via een proces dat bootstrapping of bagging wordt genoemd.
- Functiekeuze: Voor elke beslissingsboom in een willekeurig forest wordt bij de besluitvorming alleen rekening gehouden met de willekeurige subset van kenmerken, in plaats van met de volledige verzameling kenmerken.
- Stemmen: Voor classificatie brengt elke beslissingsboom in het willekeurige bos zijn stem uit en wordt de klasse met de hoogste stemmen geselecteerd. Voor regressie berekenen we het gemiddelde van de waarden die van alle bomen zijn verkregen.
Hoewel het het effect van overfitting veroorzaakt door individuele beslissingsbomen vermindert, is het rekentechnisch duur. Eén woord dat u vaak in de literatuur zult lezen, is dat het willekeurige bos een ensemble-leermethode is, wat betekent dat het meerdere modellen combineert om de algehele prestaties te verbeteren.
5. Ondersteuning van vectormachines (SVM)
Het wordt voornamelijk gebruikt voor classificatieproblemen, maar kan ook regressietaken aan. Het probeert het beste hypervlak te vinden dat de verschillende klassen scheidt met behulp van de statistische benadering, in tegenstelling tot de probabilistische benadering van logistische regressie. We kunnen de lineaire SVM gebruiken voor de lineair scheidbare gegevens. De meeste gegevens uit de echte wereld zijn echter niet-lineair en we gebruiken de kerneltrucs om de klassen te scheiden. Laten we dieper ingaan op hoe het werkt:
- Hypervlakselectie: Bij binaire classificatie vindt SVM het beste hypervlak (2D-lijn) om de klassen te scheiden en tegelijkertijd de marge te maximaliseren. Marge is de afstand tussen het hypervlak en de dichtstbijzijnde gegevenspunten bij het hypervlak.
- Kernel-truc: Voor lineair onscheidbare gegevens gebruiken we een kerneltruc die de oorspronkelijke gegevensruimte in kaart brengt in een hoogdimensionale ruimte waar ze lineair kunnen worden gescheiden. Veel voorkomende kernels zijn onder meer lineaire, polynomiale, radiale basisfunctie (RBF) en sigmoïde kernels.
- Margemaximalisatie: SVM probeert ook de generalisatie van het model te verbeteren door de maximalisatiemarge te vergroten.
- Indeling: Zodra het model is getraind, kunnen voorspellingen worden gedaan op basis van hun positie ten opzichte van het hypervlak.
SVM heeft ook een parameter genaamd C die de afweging regelt tussen het maximaliseren van de marge en het tot een minimum beperken van de classificatiefout. Hoewel ze goed overweg kunnen met hoogdimensionale en niet-lineaire data, is het kiezen van de juiste kernel en hyperparameter niet zo eenvoudig als het lijkt.
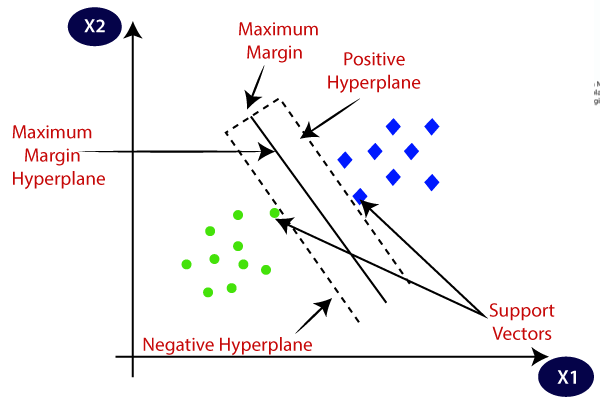
Afbeelding aan Javatpunt
6. k-dichtstbijzijnde buren (k-NN)
K-NN is het eenvoudigste leeralgoritme onder toezicht dat meestal wordt gebruikt voor classificatietaken. Het doet geen aannames over de gegevens en wijst het nieuwe gegevenspunt een categorie toe op basis van de gelijkenis met de bestaande. Tijdens de trainingsfase behoudt het de volledige dataset als referentiepunt. Vervolgens berekent het de afstand tussen het nieuwe gegevenspunt en alle bestaande punten met behulp van een afstandsmetriek (bijvoorbeeld Eucilinedain-afstand). Op basis van deze afstanden identificeert het de K die het dichtst bij deze gegevenspunten ligt. Vervolgens tellen we het voorkomen van elke klasse in de K dichtstbijzijnde buren en wijzen we de meest voorkomende klasse toe als de uiteindelijke voorspelling.
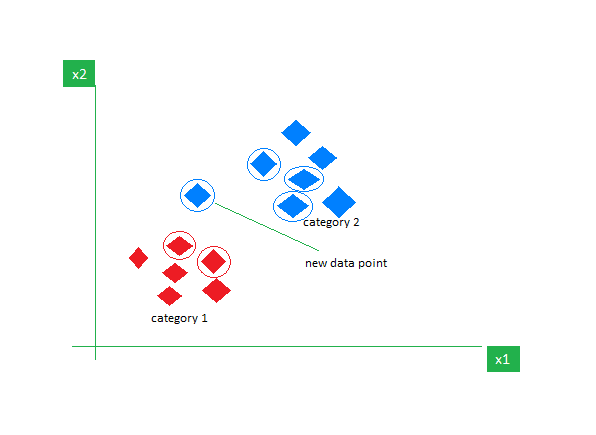
Afbeelding aan GeeksvoorGeeks
Het kiezen van de juiste waarde van K vereist experimenteren. Hoewel het robuust is tegen gegevens met veel ruis, is het niet geschikt voor hoogdimensionale datasets en zijn er hoge kosten aan verbonden vanwege de berekening van de afstand tot alle datapunten.
Terwijl ik dit artikel afsluit, wil ik de lezers aanmoedigen om meer algoritmen te verkennen en deze vanaf het begin te implementeren. Dit zal uw begrip versterken van hoe de zaken onder de motorkap werken. Hier volgen enkele aanvullende bronnen om u op weg te helpen:
Kanwal Mehreen is een aspirant-softwareontwikkelaar met een grote interesse in datawetenschap en toepassingen van AI in de geneeskunde. Kanwal werd geselecteerd als de Google Generation Scholar 2022 voor de APAC-regio. Kanwal deelt graag technische kennis door artikelen te schrijven over trending topics en heeft een passie voor het verbeteren van de vertegenwoordiging van vrouwen in de technische industrie.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. Automotive / EV's, carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- ChartPrime. Verhoog uw handelsspel met ChartPrime. Toegang hier.
- BlockOffsets. Eigendom voor milieucompensatie moderniseren. Toegang hier.
- Bron: https://www.kdnuggets.com/understanding-supervised-learning-theory-and-overview?utm_source=rss&utm_medium=rss&utm_campaign=understanding-supervised-learning-theory-and-overview

