Afbeelding door auteur
In deze tutorial wordt besproken hoe u gebruik kunt maken van de mogelijkheden van Python om multithreading- en multiprogrammeringstaken uit te voeren. Ze bieden een gateway voor het uitvoeren van gelijktijdige bewerkingen binnen een enkel proces of over meerdere processen heen. Parallelle en gelijktijdige uitvoering verhoogt de snelheid en efficiëntie van de systemen. Nadat we de basisprincipes van multithreading en multiprogrammering hebben besproken, zullen we ook de praktische implementatie ervan met behulp van Python-bibliotheken bespreken. Laten we eerst kort de voordelen van parallelle systemen bespreken.
- Verbeterde prestatie: Met de mogelijkheid om taken gelijktijdig uit te voeren, kunnen we de uitvoeringstijd verkorten en de algehele prestaties van het systeem verbeteren.
- schaalbaarheid: We kunnen een grote taak opdelen in verschillende kleinere subtaken en er een aparte kern of draad aan toewijzen voor hun onafhankelijke uitvoering. Het kan nuttig zijn in grootschalige systemen.
- Efficiënte I/O-bewerkingen: Met behulp van gelijktijdigheid hoeft de CPU niet te wachten tot een proces zijn I/O-bewerkingen heeft voltooid. De CPU kan onmiddellijk beginnen met het uitvoeren van het volgende proces totdat het vorige proces bezig is met zijn I/O.
- Optimalisatie van hulpbronnen: Door de middelen te verdelen, kunnen we voorkomen dat één enkel proces alle middelen in beslag neemt. Dit kan het probleem van voorkomen uithongering voor kleinere processen.
Voordelen van parallel computergebruik | Afbeelding door auteur
Dit zijn enkele veelvoorkomende redenen waarvoor gelijktijdige of parallelle uitvoeringen nodig zijn. Ga nu terug naar de hoofdonderwerpen, dat wil zeggen Multithreading en Multiprogrammering, en bespreek hun belangrijkste verschillen.
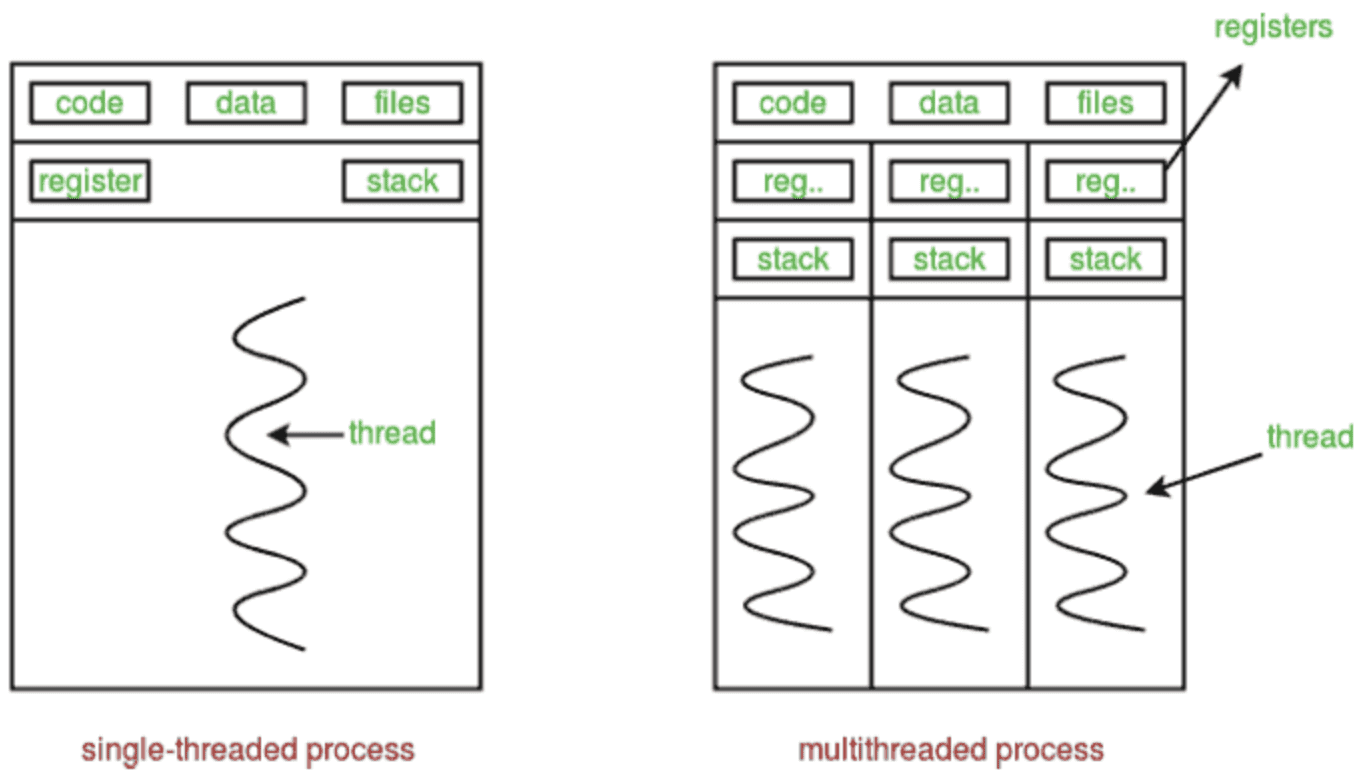
Multithreading is een van de manieren om parallellisme in een enkel proces te bereiken en gelijktijdige taken uit te voeren. Binnen één proces kunnen meerdere threads worden aangemaakt en binnen dat proces kleinere taken parallel worden uitgevoerd.
De threads die binnen een enkel proces aanwezig zijn, delen een gemeenschappelijke geheugenruimte, maar hun stapelsporen en registers zijn gescheiden. Ze zijn rekentechnisch gezien minder duur vanwege dit gedeelde geheugen.
Env. met enkele schroefdraad en meerdere schroefdraad. | Afbeelding door GeeksForGeeks
Multithreading wordt voornamelijk gebruikt bij het uitvoeren van I/O-bewerkingen. Dit betekent dat als een deel van het programma bezig is met I/O-bewerkingen, het resterende programma kan reageren. In de implementatie van Python kan multithreading echter geen echt parallellisme bereiken vanwege Global Interpreter Lock (GIL).
Kortom, GIL is een mutex-slot waarmee slechts één thread tegelijk kan communiceren met de Python-bytecode, dwz dat zelfs in de multithreaded-modus slechts één thread de bytecode tegelijk kan uitvoeren.
Dit wordt gedaan om de threadveiligheid in CPython te behouden, maar dit beperkt de prestatievoordelen van multithreading. Om dit probleem aan te pakken heeft Python een aparte multiprocessingbibliotheek, die we later zullen bespreken.
Wat zijn Daemon-threads?
De threads die constant op de achtergrond draaien, worden de demonthreads genoemd. Hun belangrijkste taak is het ondersteunen van de hoofdthread of de niet-daemon-threads. De daemon-thread blokkeert de uitvoering van de hoofdthread niet en blijft zelfs actief als de uitvoering ervan is voltooid.
In Python worden de daemon-threads voornamelijk gebruikt als garbage collector. Het zal alle nutteloze objecten vernietigen en standaard het geheugen vrijmaken, zodat de hoofdthread correct kan worden gebruikt en uitgevoerd.
Multiprocessing wordt gebruikt om de parallelle uitvoering van meerdere processen uit te voeren. Het helpt ons echt parallellisme te bereiken, omdat we afzonderlijke processen tegelijkertijd uitvoeren en hun eigen geheugenruimte hebben. Het maakt gebruik van afzonderlijke kernen van de CPU en is ook nuttig bij het uitvoeren van communicatie tussen processen om gegevens tussen meerdere processen uit te wisselen.
Multiprocessing is rekentechnisch duurder in vergelijking met multithreading, omdat we geen gedeelde geheugenruimte gebruiken. Toch maakt het ons onafhankelijke uitvoering mogelijk en overwint het de beperkingen van Global Interpreter Lock.
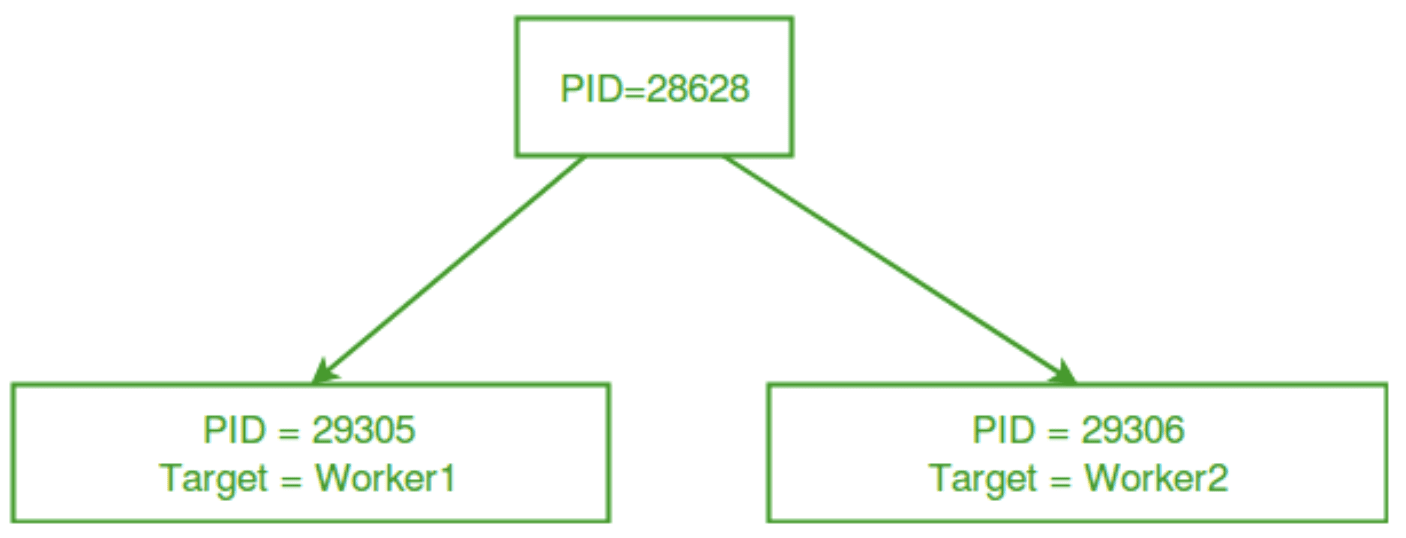
Multiprocessing-omgeving | Afbeelding door GeeksForGeeks
De bovenstaande afbeelding demonstreert een multi-processingomgeving waarin een hoofdproces twee afzonderlijke processen creëert en er afzonderlijk werk aan toewijst.
Het is tijd om een basisvoorbeeld van multithreading met Python te implementeren. Python heeft een ingebouwde module threading gebruikt voor de multithreading-implementatie.
- Bibliotheken importeren:
import threading
import os
- Functie om de vierkanten te berekenen:
Dit is een eenvoudige functie die wordt gebruikt om het kwadraat van getallen te vinden. Er wordt een lijst met getallen gegeven als invoer, en deze geeft het kwadraat van elk nummer van de lijst weer, samen met de naam van de gebruikte thread en de proces-ID die aan die thread is gekoppeld.
def calculate_squares(numbers):
for num in numbers:
square = num * num
print(
f"Square of the number {num} is {square} | Thread Name {threading.current_thread().name} | PID of the process {os.getpid()}"
)
- Belangrijkste functie:
We hebben een lijst met getallen en we verdelen die lijst gelijk en noemen ze fisrt_half en second_half respectievelijk. Nu zullen we twee afzonderlijke threads toewijzen t1 en t2 aan deze lijsten.
Thread function maakt een nieuwe thread aan, die een functie met een lijst met argumenten naar die functie overneemt. U kunt ook een aparte naam aan een thread toewijzen.
.start() -functie zal beginnen met het uitvoeren van deze threads en .join() functie blokkeert de uitvoering van de hoofdthread totdat de gegeven thread niet volledig is uitgevoerd.
if __name__ == "__main__":
numbers = [1, 2, 3, 4, 5, 6, 7, 8]
half = len(numbers) // 2
first_half = numbers[:half]
second_half = numbers[half:]
t1 = threading.Thread(target=calculate_squares, name="t1", args=(first_half,))
t2 = threading.Thread(target=calculate_squares, name="t2", args=(second_half,))
t1.start()
t2.start()
t1.join()
t2.join()
Output:
Square of the number 1 is 1 | Thread Name t1 | PID of the process 345
Square of the number 2 is 4 | Thread Name t1 | PID of the process 345
Square of the number 5 is 25 | Thread Name t2 | PID of the process 345
Square of the number 3 is 9 | Thread Name t1 | PID of the process 345
Square of the number 6 is 36 | Thread Name t2 | PID of the process 345
Square of the number 4 is 16 | Thread Name t1 | PID of the process 345
Square of the number 7 is 49 | Thread Name t2 | PID of the process 345
Square of the number 8 is 64 | Thread Name t2 | PID of the process 345
Opmerking: Alle hierboven gemaakte threads zijn niet-daemon-threads. Om een daemonthread te maken, moet je schrijven
t1.setDaemon(True)om de draad te makent1een daemon-thread.
Nu zullen we de uitvoer begrijpen die door de bovenstaande code wordt gegenereerd. We kunnen zien dat de proces-ID (dwz PID) voor beide threads hetzelfde blijft, wat betekent dat deze twee threads deel uitmaken van hetzelfde proces.
U kunt ook zien dat de uitvoer niet opeenvolgend wordt gegenereerd. Op de eerste regel ziet u de uitvoer gegenereerd door thread1, vervolgens op de derde regel de uitvoer gegenereerd door thread3 en vervolgens opnieuw door thread2 op de vierde regel. Dit betekent duidelijk dat deze draden gelijktijdig samenwerken.
Gelijktijdigheid betekent niet dat deze twee threads parallel worden uitgevoerd, aangezien er slechts één thread tegelijk wordt uitgevoerd. Het verkort de uitvoeringstijd niet. Het duurt even lang als sequentiële uitvoering. De CPU begint een thread uit te voeren, maar verlaat deze halverwege en gaat naar een andere thread, en keert na enige tijd terug naar de hoofdthread en begint de uitvoering vanaf hetzelfde punt waar hij de vorige keer vertrok.
Ik hoop dat je een basiskennis hebt van multithreading, de implementatie ervan en de beperkingen ervan. Nu is het tijd om meer te leren over de implementatie van multiprocessing en hoe we deze beperkingen kunnen overwinnen.
We zullen hetzelfde voorbeeld volgen, maar in plaats van twee afzonderlijke threads te creëren, zullen we twee onafhankelijke processen creëren en de observaties bespreken.
- Bibliotheken importeren:
from multiprocessing import Process
import os
We zullen gebruik maken van de multiprocessing module om onafhankelijke processen te creëren.
- Functie om de vierkanten te berekenen:
Die functie blijft hetzelfde. We hebben zojuist de printverklaring met inrijginformatie verwijderd.
def calculate_squares(numbers):
for num in numbers:
square = num * num
print(
f"Square of the number {num} is {square} | PID of the process {os.getpid()}"
)
- Belangrijkste functie:
Er zijn een paar wijzigingen in de hoofdfunctie. We hebben zojuist een apart proces gemaakt in plaats van een thread.
if __name__ == "__main__":
numbers = [1, 2, 3, 4, 5, 6, 7, 8]
half = len(numbers) // 2
first_half = numbers[:half]
second_half = numbers[half:]
p1 = Process(target=calculate_squares, args=(first_half,))
p2 = Process(target=calculate_squares, args=(second_half,))
p1.start()
p2.start()
p1.join()
p2.join()
Output:
Square of the number 1 is 1 | PID of the process 1125
Square of the number 2 is 4 | PID of the process 1125
Square of the number 3 is 9 | PID of the process 1125
Square of the number 4 is 16 | PID of the process 1125
Square of the number 5 is 25 | PID of the process 1126
Square of the number 6 is 36 | PID of the process 1126
Square of the number 7 is 49 | PID of the process 1126
Square of the number 8 is 64 | PID of the process 1126
We hebben gezien dat elke lijst door een afzonderlijk proces wordt uitgevoerd. Beide hebben verschillende proces-ID's. Om te controleren of onze processen parallel zijn uitgevoerd, moeten we een aparte omgeving creëren, die we hieronder zullen bespreken.
Runtime berekenen met en zonder multiprocessing
Om te controleren of we een echt parallellisme krijgen, zullen we de looptijd van het algoritme berekenen met en zonder multiprocessing.
Hiervoor hebben we een uitgebreide lijst met gehele getallen nodig die meer dan 10^6 gehele getallen bevatten. We kunnen een lijst genereren met behulp van random bibliotheek. Wij zullen gebruik maken van de time module van Python om de runtime te berekenen. Hieronder vindt u de implementatie hiervoor. De code spreekt voor zich, hoewel u altijd de codecommentaren kunt bekijken.
from multiprocessing import Process
import os
import time
import random
def calculate_squares(numbers):
for num in numbers:
square = num * num
if __name__ == "__main__":
numbers = [
random.randrange(1, 50, 1) for i in range(10000000)
] # Creating a random list of integers having size 10^7.
half = len(numbers) // 2
first_half = numbers[:half]
second_half = numbers[half:]
# ----------------- Creating Single Process Environment ------------------------#
start_time = time.time() # Start time without multiprocessing
p1 = Process(
target=calculate_squares, args=(numbers,)
) # Single process P1 is executing all list
p1.start()
p1.join()
end_time = time.time() # End time without multiprocessing
print(f"Execution Time Without Multiprocessing: {(end_time-start_time)*10**3}ms")
# ----------------- Creating Multi Process Environment ------------------------#
start_time = time.time() # Start time with multiprocessing
p2 = Process(target=calculate_squares, args=(first_half,))
p3 = Process(target=calculate_squares, args=(second_half,))
p2.start()
p3.start()
p2.join()
p3.join()
end_time = time.time() # End time with multiprocessing
print(f"Execution Time With Multiprocessing: {(end_time-start_time)*10**3}ms")
Output:
Execution Time Without Multiprocessing: 619.8039054870605ms
Execution Time With Multiprocessing: 321.70287895202637ms
Je kunt zien dat de tijd met multiprocessing bijna de helft is vergeleken met zonder multiprocessing. Dit toont aan dat deze twee processen gelijktijdig worden uitgevoerd en een gedrag van echt parallellisme vertonen.
Je kunt dit artikel ook lezen Opeenvolgend versus gelijktijdig versus parallellisme van Medium, waarmee u het fundamentele verschil tussen deze sequentiële, gelijktijdige en parallelle processen kunt begrijpen.
Arische Gargo is een B.Tech. Student Electrical Engineering, zit momenteel in het laatste jaar van zijn bachelor. Zijn interesse ligt op het gebied van Web Development en Machine Learning. Hij heeft deze interesse nagestreefd en staat te popelen om meer in deze richtingen te werken.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.kdnuggets.com/introduction-to-multithreading-and-multiprocessing-in-python?utm_source=rss&utm_medium=rss&utm_campaign=introduction-to-multithreading-and-multiprocessing-in-python

