Chipmakers maken gebruik van zowel evolutionaire als revolutionaire technologieën om ordes van grootte verbeteringen in de prestaties te bereiken bij hetzelfde of een lager vermogen, wat een fundamentele verschuiving aangeeft van productiegestuurde ontwerpen naar ontwerpen die worden aangestuurd door halfgeleiderarchitecten.
In het verleden bevatten de meeste chips een of twee geavanceerde technologieën, meestal om gelijke tred te houden met de verwachte verbeteringen in de lithografie op elk nieuw procesknooppunt om de paar jaar. Deze verbeteringen waren gebaseerd op routekaarten voor de sector die opriepen tot voorspelbare maar onopvallende winsten in de loop van de tijd. Nu de dataexplosie wordt aangewakkerd door grote taalmodellen en steeds meer sensoren – evenals de toegenomen concurrentie tussen systeembedrijven die hun eigen chips ontwerpen, en de groeiende internationale rivaliteit op het gebied van AI – veranderen de regels nogal dramatisch op het gebied van chipontwerp. Stapsgewijze verbeteringen gaan nu gepaard met gigantische sprongen in de verwerkingsprestaties, en hoewel deze een geheel nieuw niveau van rekenmogelijkheden en analyses mogelijk maken, vereisen ze ook een geheel nieuwe reeks afwegingen.
De kern van deze verschuivingen wordt gevormd door sterk op maat gemaakte chiparchitecturen, waarbij sommige chiplets omvatten die zijn ontwikkeld op de meest geavanceerde procesknooppunten. Parallelle verwerking is bijna een gegeven, net als versnellers die gericht zijn op specifieke gegevenstypen en bewerkingen. In sommige gevallen zullen deze minisystemen niet commercieel worden verkocht, omdat ze datacenters hun concurrentievoordeel geven. Maar ze kunnen ook andere commercieel beschikbare technologie omvatten, zoals verwerkingskernen of versnellers of computertechnologie in of nabij het geheugen om de latentie te verminderen, evenals verschillende caching-schema's, samenverpakte optica en veel snellere verbindingen. Veel van deze ontwikkelingen zijn al jaren in onderzoek of staan aan de zijlijn, maar worden nu volop ingezet.
Amin Vahdat, engineering fellow en vice-president voor ML-systemen bij Google Research, merkte in een presentatie op de recente Hot Chips 2023-conferentie op dat chips vandaag de dag problemen kunnen aanpakken die tien jaar geleden ondenkbaar waren, en dat machinaal leren een “steeds groter deel van de tijd” zal vergen. fractie” van rekencycli.
“We moeten de manier veranderen waarop we naar systeemontwerp kijken”, zei Vahdat. “De stijging van de vraag naar computers in de afgelopen vijf, zes, zeven jaar is verbluffend geweest… Hoewel er veel innovaties op komst zijn in termen van schaarsheid van [algoritme], toont het als je naar [figuur 1, hieronder] kijkt 10X per jaar, aanhoudend, in het aantal parameters per model. En we weten ook dat de rekenkosten superlineair groeien met het aantal parameters. Het soort computerinfrastructuur dat we moeten bouwen om deze uitdaging aan te gaan, moet dus veranderen. Het is belangrijk op te merken dat we niet zouden zijn waar we nu zijn als we dit zouden proberen te doen met algemeen computergebruik. De conventionele computerwijsheid die we de afgelopen vijftig tot zestig jaar hebben ontwikkeld, is uit het raam gegooid.”
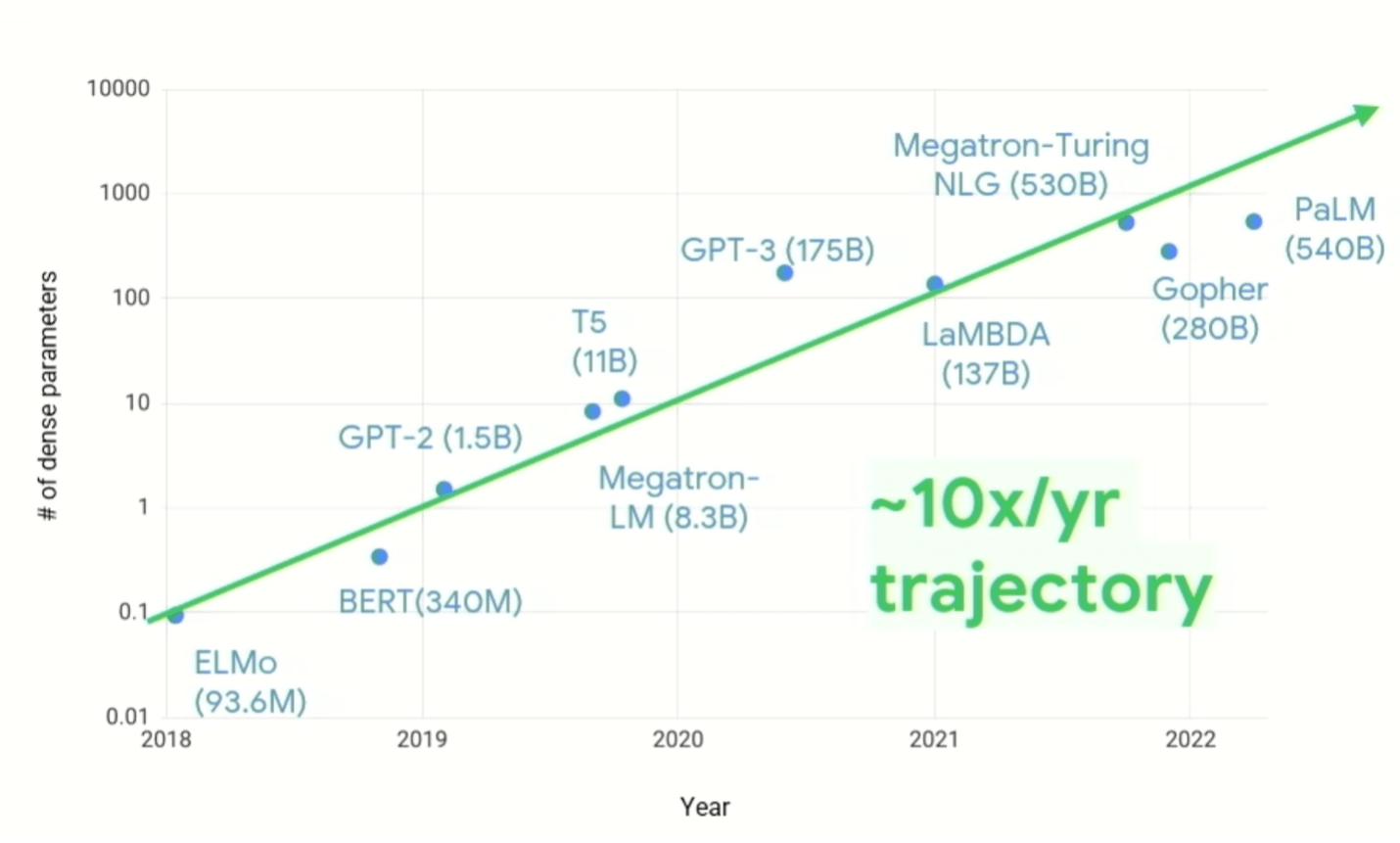
Figuur 1: Groei van de vraag naar ML-compute. Bron: Google Research/Hot Chips 2023
Dat betekent echter niet dat oude problemen verdwijnen. Vermogen en thermische dissipatie zijn aanhoudende kopzorgen voor ontwerpteams, en ze worden moeilijker op te lossen naarmate de snelheid en de hoeveelheid verwerking toeneemt. Alleen al het verhogen van de klokfrequentie was na ongeveer 3 GHz geen eenvoudige optie meer vanwege de hogere thermische dichtheid en het onvermogen van chips om die warmte af te voeren. En hoewel spaarzame datamodellen en hardware-software co-design de efficiëntie van software die op verschillende verwerkingselementen draait, aanpakken, evenals de mogelijkheid om meer per rekencyclus te verwerken, is er niet langer één knop waaraan je kunt draaien om de prestaties per watt te verbeteren.
Geheugeninnovaties
Er zijn echter veel kleinere en middelgrote knoppen, waarvan sommige nooit in productiesystemen zijn gebruikt omdat er geen economische reden voor was. Die economie is dramatisch veranderd met de toename van data en de verschuiving naar architecturale innovatie, wat duidelijk duidelijk werd op de Hot Chips-conferentie van dit jaar.
Tot de opties behoren verwerking in het geheugen/near-memory, evenals verwerking dichter bij de gegevensbron. Het probleem hier is dat het verplaatsen van grote hoeveelheden gegevens aanzienlijke systeembronnen vereist (bandbreedte, kracht en tijd), wat een directe economische impact heeft op computergebruik. Over het algemeen zijn veel van de verzamelde en verwerkte gegevens nutteloos. De relevante gegevens in een videofeed in een auto of een beveiligingssysteem kunnen bijvoorbeeld slechts een seconde of twee duren, terwijl er uren aan gegevens kunnen zijn die moeten worden doorzocht. Door de gegevens dichter bij de bron voor te verwerken en AI te gebruiken om de relevante gegevens te identificeren, hoeft slechts een klein deel te worden doorgestuurd voor verdere verwerking en opslag.
“Het grootste deel van het energieverbruik komt uit het verplaatsen van data”, zegt Jin Hyun Kim, hoofdingenieur bij Samsung. Hij wees op drie oplossingen om de efficiëntie te verbeteren en de prestaties te verbeteren:
- In-memory verwerking voor extreme bandbreedte en kracht, met behulp van HBM;
- In-memory-verwerking voor apparaten met een laag energieverbruik die een hoge capaciteit vereisen, met behulp van LPDDR, en
- Near-memory-verwerking met behulp van CXL voor extreme capaciteit tegen redelijke kosten.
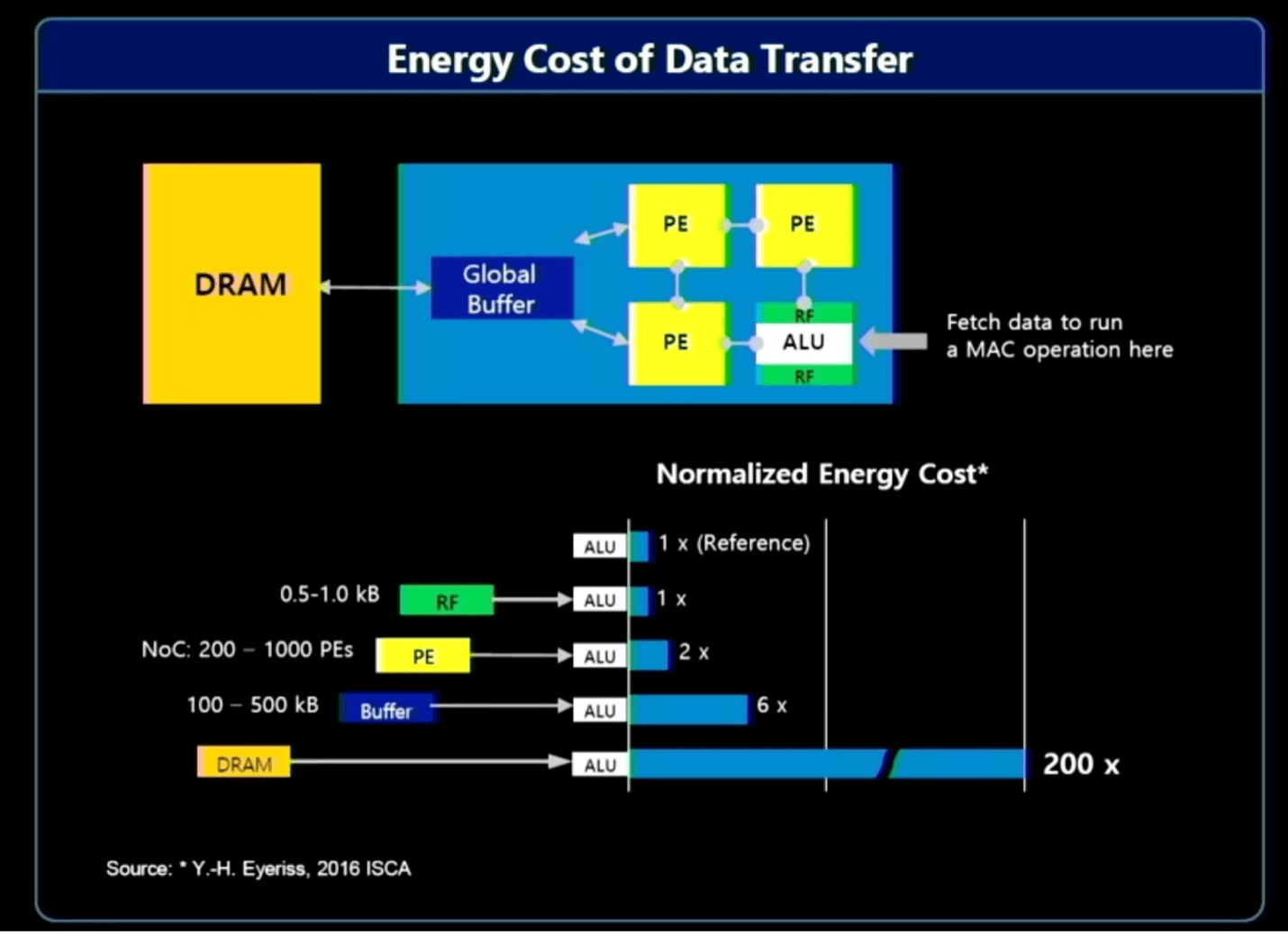
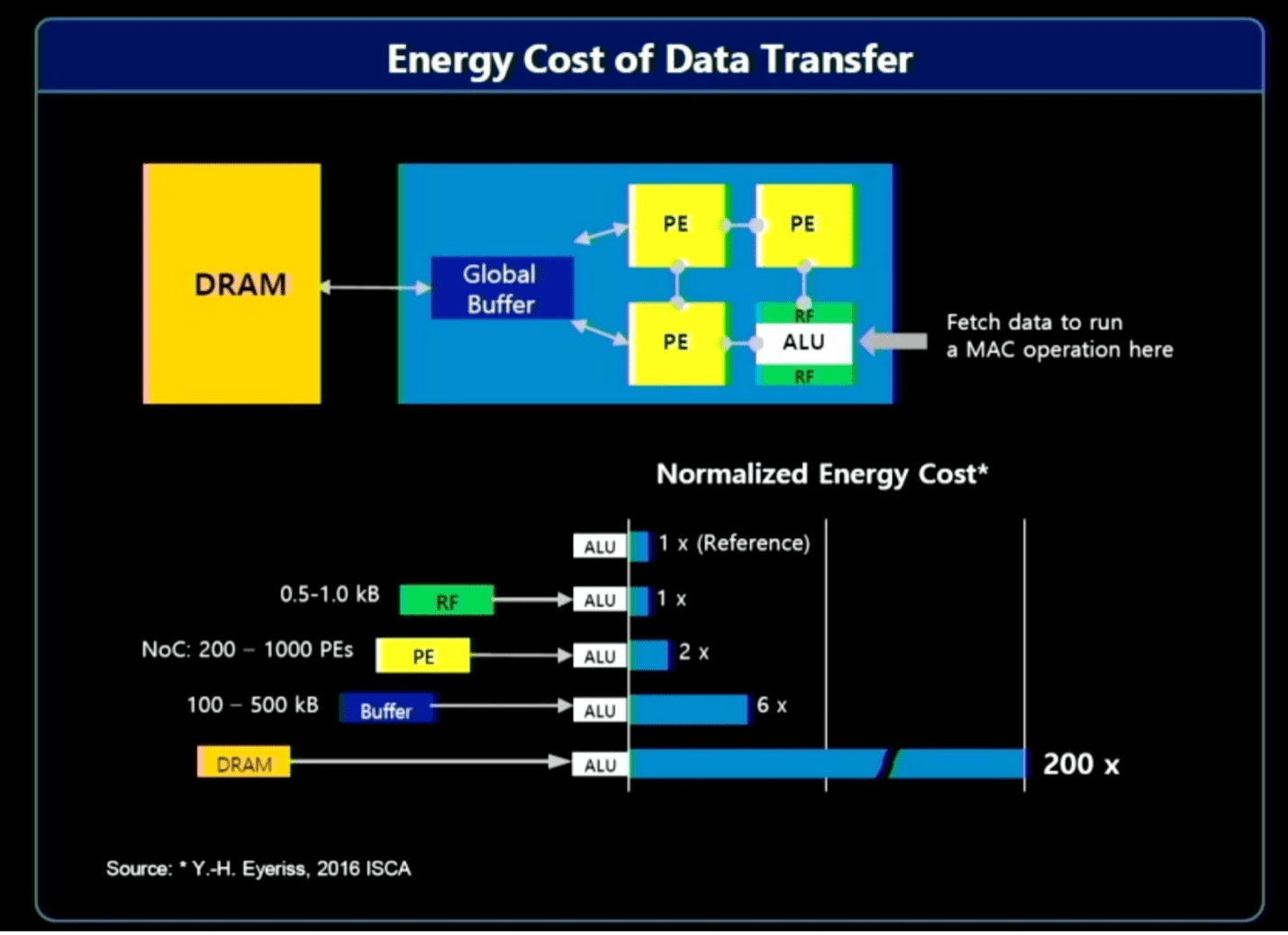
Fig. 2: Resourcekosten voor het verplaatsen van gegevens. Bron: Samsung/Hot Chips 2023
Verwerking in het geheugen ligt al jaren op de tekentafel, zonder veel beweging tot voor kort. Grote taalmodellen hebben de economie zo drastisch veranderd dat deze nu veel interessanter is geworden, en dat is niet verloren gegaan bij grote geheugenleveranciers.
Een nieuwe verfijning van dit concept is in-memory acceleratie, wat vooral handig is voor vermenigvuldigen en accumuleren (MAC)-functies voor AI/ML, waarbij de hoeveelheid gegevens die snel moet worden verwerkt explosief toeneemt. Met Genative Pre-Trained Transformer 3 (GPT-3) en GPT4 vereist alleen al het laden van de gegevens een enorme bandbreedte. Daar zijn meerdere uitdagingen aan verbonden, waaronder hoe je dit efficiënt kunt doen en tegelijkertijd de prestaties en doorvoer kunt maximaliseren, hoe je het kunt schalen om de snelle toename van het aantal parameters in grote taalmodellen aan te kunnen, en hoe je flexibiliteit kunt inbouwen om toekomstige veranderingen op te vangen.
“De mentaliteit die we in het begin hadden, is het geheugen als versneller”, zegt Yonkwee Kwon, senior technical sensing manager bij SK hynix America, in een presentatie op Hot Chips 2023. “Het eerste doel was om efficiënt opschalen mogelijk te maken. Maar het is ook belangrijk om hoge prestaties te leveren. En ten slotte hebben we de systeemarchitectuur ontworpen met het oog op programmeergemak, waarbij de overhead van de systeemstructuur werd geminimaliseerd, maar toch een softwarestack mogelijk werd gemaakt voor flexibiliteit.
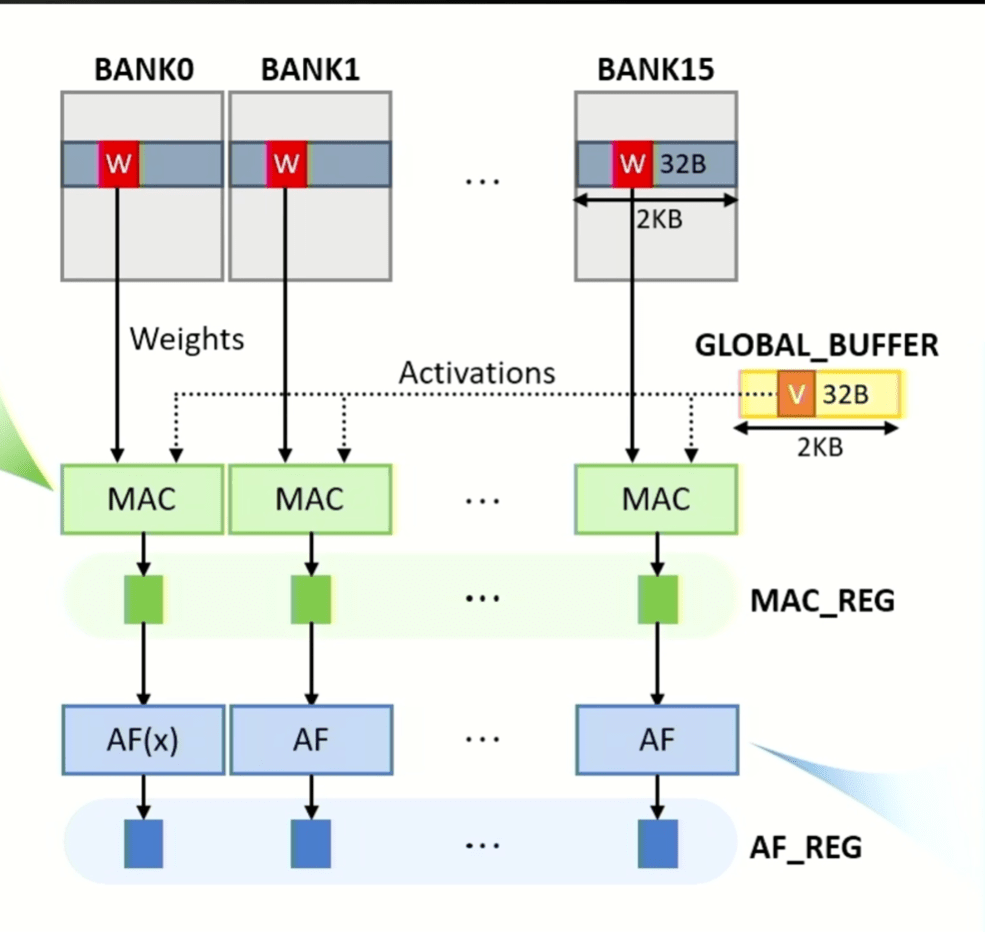
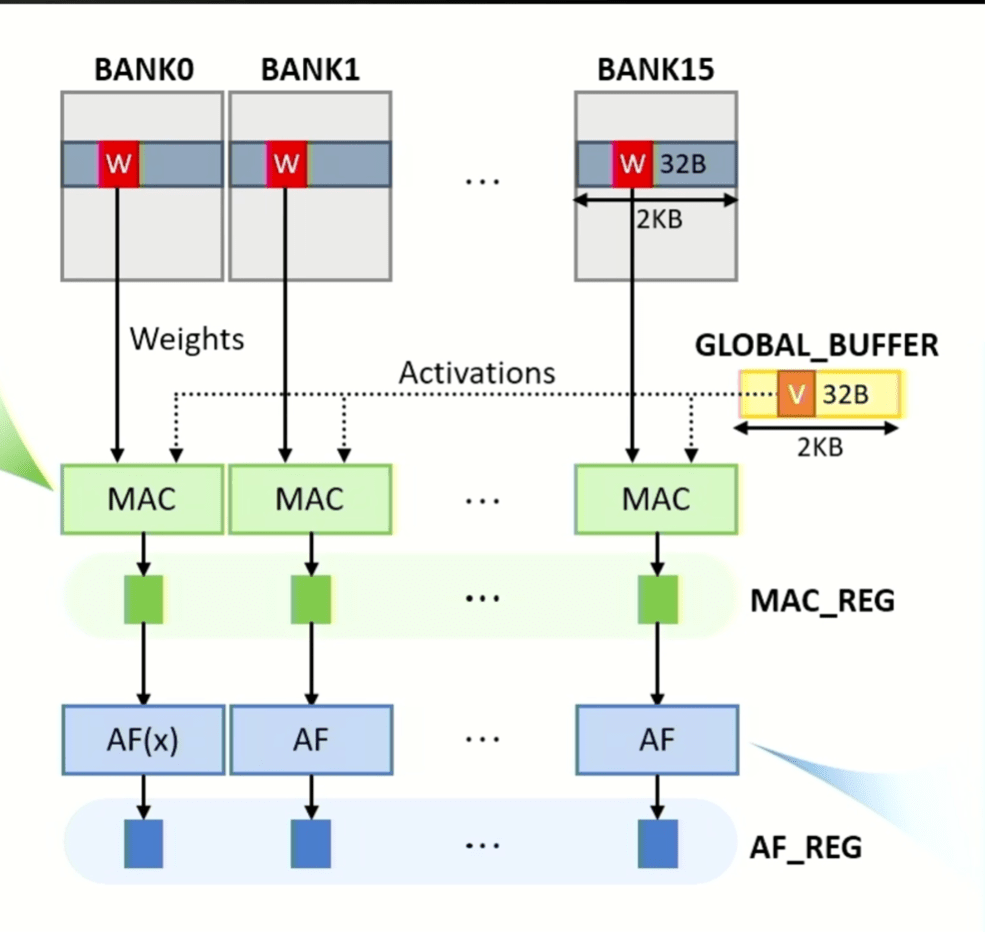
Figuur 3: MAC- en activeringsbewerkingen kunnen parallel in alle banken worden uitgevoerd, waarbij gewichtsmatrixgegevens afkomstig zijn van banken en vectorgegevens afkomstig zijn van de globale buffer. MAC- en activeringsfunctieresultaten worden opgeslagen in grendels die respectievelijk MAC_REG en AF_REG worden genoemd. Bron: SK hynix/Hot Chips 2023
CPU-verbeteringen
Hoewel veranderingen in het geheugen de hoeveelheid gegevens helpen verminderen die moeten worden verplaatst, is dat slechts een stukje van de puzzel. De volgende uitdaging is het versnellen van de belangrijkste verwerkingselementen. Eén manier om dat te doen is vertakkingsvoorspelling, die in feite voorspelt wat de volgende operatie zal zijn – bijna zoals een internetzoekmachine dat doet. Zoals bij elke geparallelliseerde architectuur is het echter de sleutel om verschillende verwerkingselementen volledig operationeel te houden, zonder inactieve tijd, om de prestaties en efficiëntie te maximaliseren.
Arm geeft een nieuwe draai aan dit concept met zijn Neoverse V2-ontwerp, waarbij branch en fetch worden losgekoppeld. Het resultaat is een hogere efficiëntie door het minimaliseren van stilstanden en een sneller herstel van verkeerde voorspellingen. “Dynamische voedingsmechanismen zorgen ervoor dat de kern de agressiviteit kan reguleren en systeemcongestie proactief kan voorkomen”, zegt Magnus Bruce, hoofd CPU-architect bij Arm. “Deze fundamentele concepten stellen ons in staat om de breedte en diepte van de machine te vergroten, terwijl we de korte pijplijn behouden voor een snel, verkeerd voorspeld herstel.”
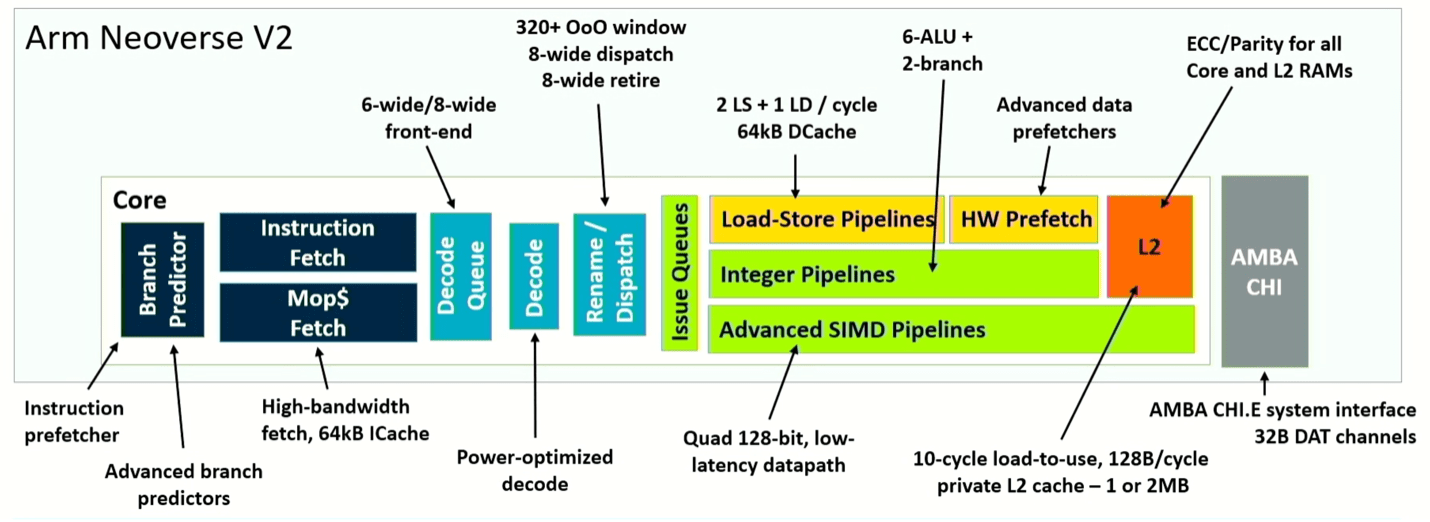
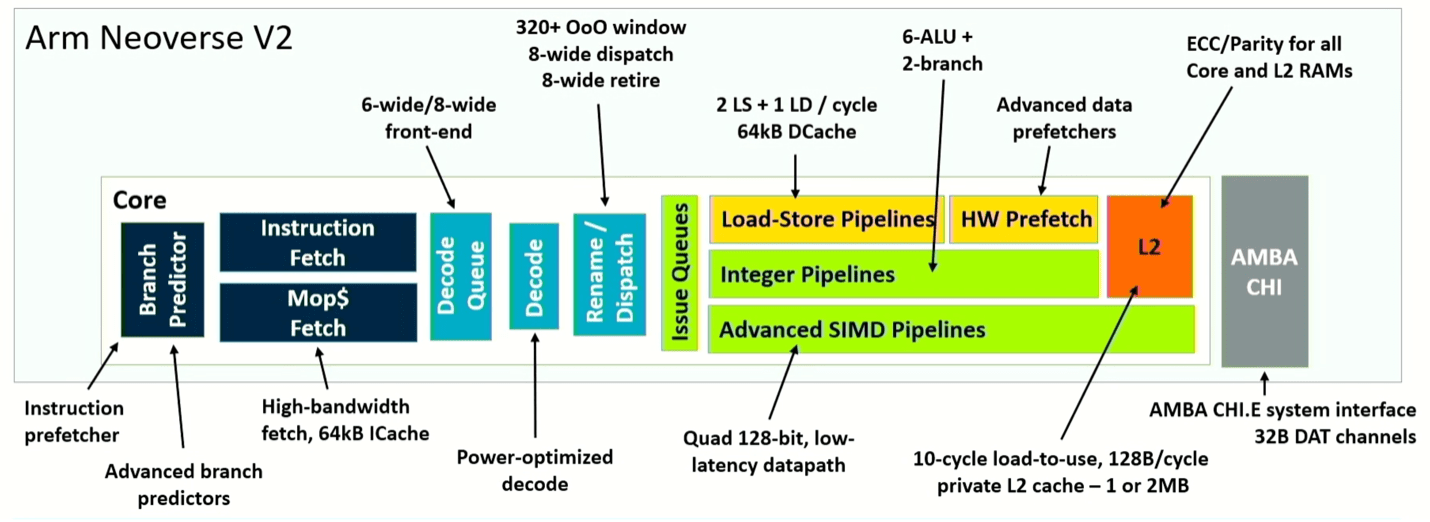
Fig. 4: Pijpleidingschema van de Neoverse V2-kern. Bron: Arm/Hot Chips 2023
Wat hier anders is, is dat de totale systeemverbetering voortkomt uit aanpassingen van de architectuur op meerdere punten, en niet uit een grootschalige verandering. Door bijvoorbeeld de vertakkingsvoorspeller en het ophalen te splitsen, kan de vertakkingsdoelbuffer in twee niveaus worden gesplitst, waardoor deze 50% meer invoer kan verwerken. Het verdrievoudigt ook de geschiedenis die is opgeslagen in de voorspeller en verdubbelt het aantal vermeldingen in de ophaalwachtrij, wat resulteert in een aanzienlijke prestatieverbetering in de echte wereld. Om dat effectief te maken, verdubbelt de architectuur ook de L2-cache, die eenmalig gebruikte en meerdere gebruikte datablokvoorspellingen scheidt. Als we de verschillende verbeteringen bij elkaar optellen, levert Neoverse V2 tot tweemaal de prestaties van V1 op, afhankelijk van de rol die het speelt in een systeem.
AMD's Zen 4 Core van de volgende generatie verhoogt ondertussen het aantal instructies per cyclus met ongeveer 14% dankzij microarchitectonische verbeteringen, biedt een 16% hogere frequentie op 5 nm bij dezelfde spanning als gevolg van processchaling, en ongeveer 60% lager vermogen dankzij micro-architectonische en fysieke ontwerpverbeteringen.
Net als Arm richt AMD zich op verbeteringen in het voorspellen en ophalen van vertakkingen. Kai Troester, AMD-collega en hoofdarchitect van de Zen 4, zei dat de nauwkeurigheid van vertakkingsvoorspellingen is toegenomen dankzij meer vertakkingen, meer vertakkingsvoorspellingen per cyclus en een grotere operationele cache die meer invoer en meer bewerkingen per invoer mogelijk maakt. Het voegt ook een 3D V-cache toe, die de L3-cache per core vergroot tot maar liefst 96 Mbytes, en biedt ondersteuning voor 512-bits bewerkingen met behulp van twee opeenvolgende cycli op een 256-bits datapad. Simpel gezegd vergroot het ontwerp de omvang van de dataleidingen, en waar mogelijk verkort het de afstanden die de data moeten afleggen.
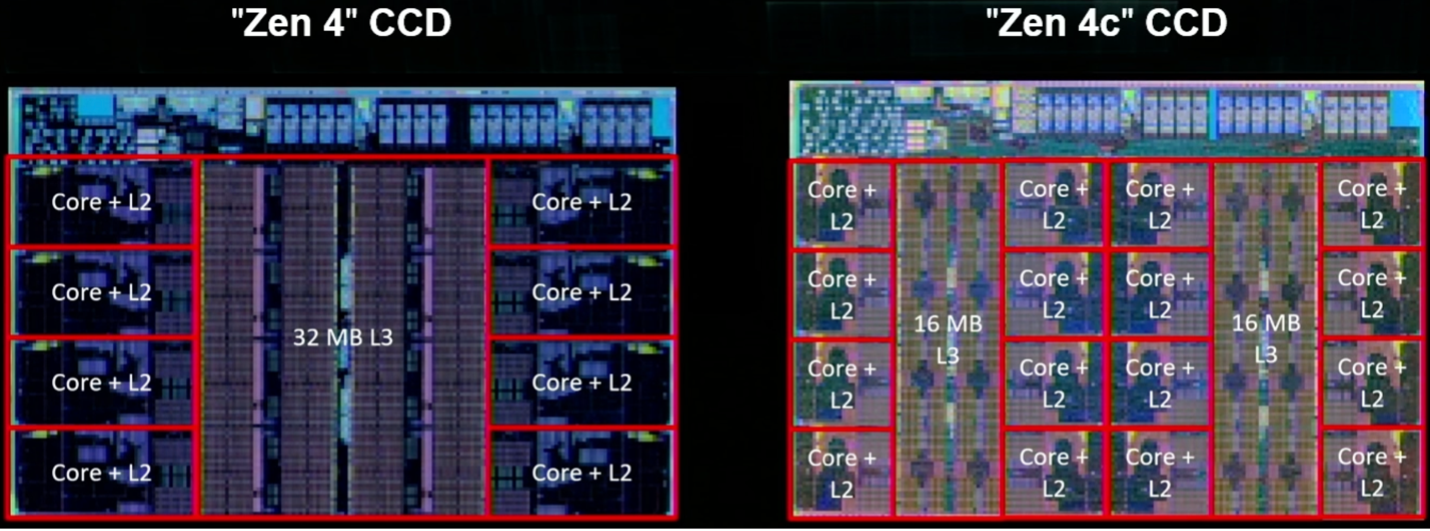
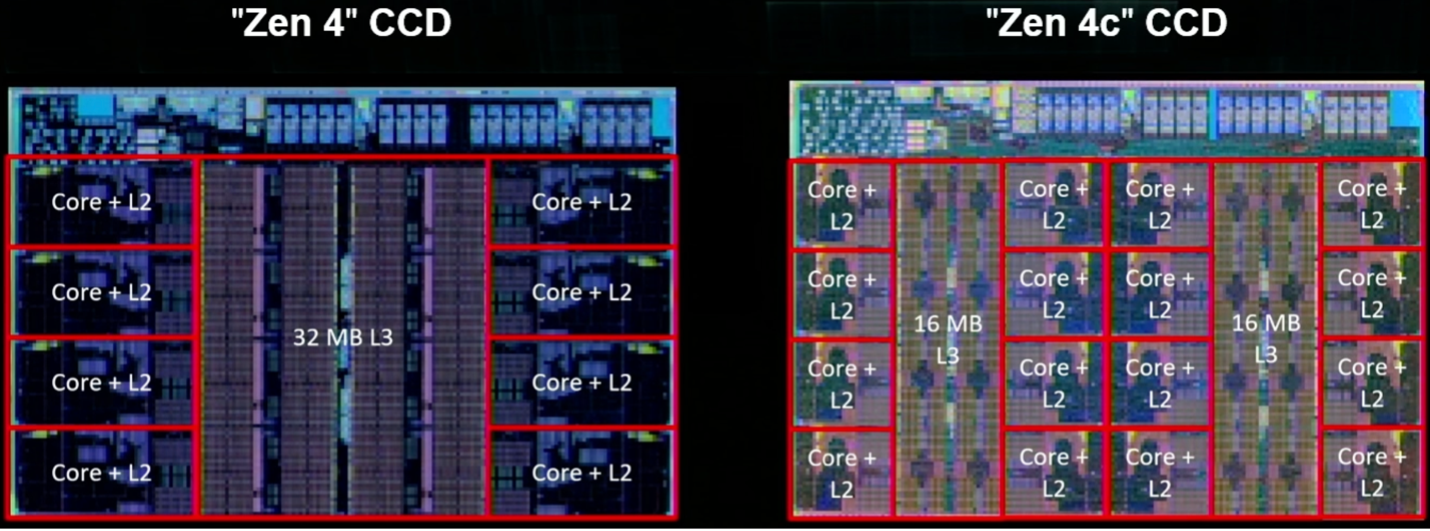
Fig. 5: Twee implementaties van Zen 4, inclusief de Zen 4c met tweemaal zoveel rekenkernen per chip en gepartitioneerde L3-cache. Bron: AMD/Hot Chips 2023
Platform-architecturen
Een van de belangrijkste trends aan de systeemkant is de toenemende domeinspecificiteit, wat grote schade heeft aangericht aan het oude model van het ontwikkelen van een processor voor algemene doeleinden die in alle applicaties werkt. De uitdaging is nu hoe te zorgen voor wat in wezen massaaanpassing is, en daar zijn twee hoofdbenaderingen voor: het toevoegen van programmeerbaarheid, hetzij via hardware of programmeerbare logica, en het ontwikkelen van een platform voor uitwisselbare onderdelen.
Intel heeft een raamwerk onthuld voor het integreren van chiplets in een geavanceerd pakket dat gebruik maakt van de Embedded Multi-die Interconnect Bridge om snelle I/O, processorkernen en geheugen met elkaar te verbinden. Het doel van Intel was om voldoende maatwerk en prestaties te bieden om klanten tevreden te stellen, maar om deze systemen veel sneller te leveren dan volledig op maat gemaakte architecturen en met voorspelbare resultaten.
“Dit wordt een multi-die-architectuur”, zegt Chris Gianos, Intel-fellow en hoofdarchitect van Xeon. “We hebben veel flexibiliteit in de structuur die we met deze chiplets kunnen bouwen. Ze werken allemaal gewoon samen, en het geeft ons een van die dimensies om de productkernen specifiek te optimaliseren. En we zullen chiplets maken die E-cores zijn (ultra-efficiënt) en chiplets die P-cores zijn (hoge prestaties).
Intel heeft ook een modulair mesh-weefsel gemaakt om verschillende componenten met elkaar te verbinden, evenals een gemeenschappelijke controller die DDR- of MCR-geheugen ondersteunt en geheugen dat is aangesloten via CXL.
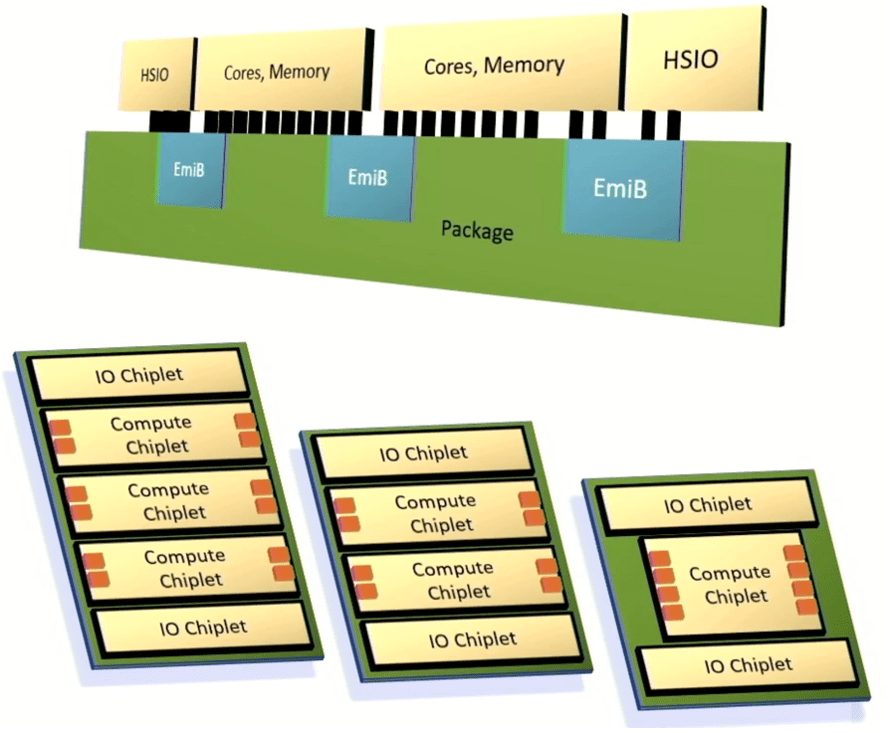
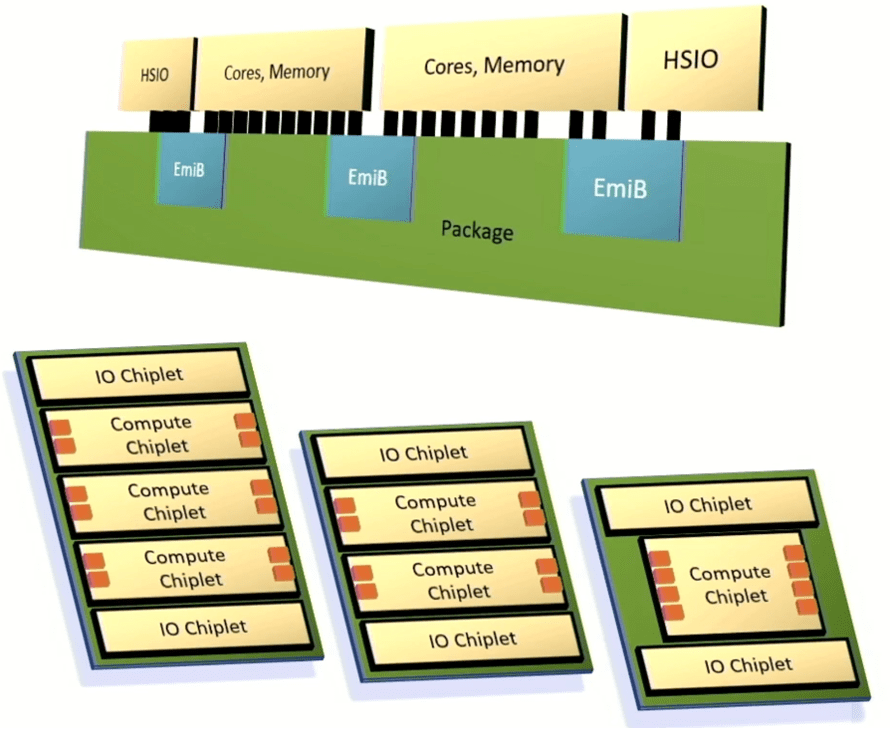
Fig. 6: Intels aanpasbare chipletarchitectuur. De oranje vakjes vertegenwoordigen geheugenkanalen. Bron: Intel/Hot Chips 2023
Neurale processors, optische verbindingen
De lijst met nieuwe benaderingen en technologieën is ongekend, zelfs voor de Hot Chips-conferentie. Wat het laat zien is hoe breed de industrie op zoek is naar nieuwe manieren om het vermogen te vergroten en te verminderen, terwijl ze toch de oppervlakte en de kosten in de gaten houden. PPAC blijft de focus, maar de afwegingen voor verschillende toepassingen en gebruiksscenario's kunnen heel verschillend zijn.
“De OpEx en CapEx van AI worden onhoudbaar”, zegt Dharmendra Modha, IBM-fellow, en voegt eraan toe dat “architectuur de wet van Moore overtroeft.”
Ook cruciaal voor AI/ML-toepassingen is precisie. Het ontwerp van IBM omvat een vectormatrixvermenigvuldiger die gemengde precisie mogelijk maakt, en vectorrekeneenheden en activeringsfunctie-eenheden met FP16-precisie. Bovendien vindt de verwerking plaats binnen een paar micron afstand van het geheugen. "Er is geen data-afhankelijke voorwaardelijke vertakking", zei hij. “Er zijn geen cache-missers, geen kraampjes, geen speculatieve executie.”

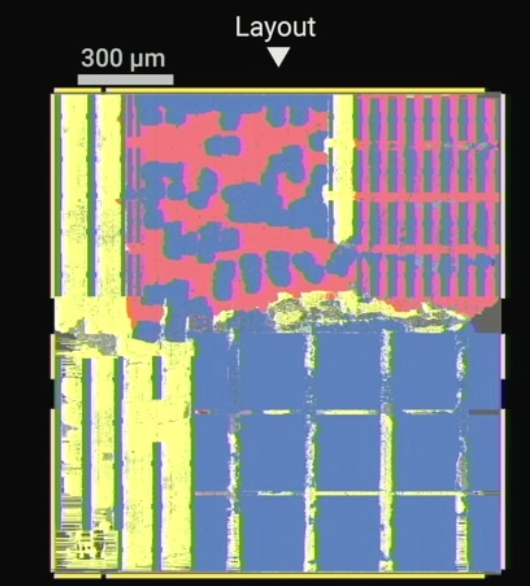
Fig. 7: IBM's Noordpoolchip, met verweven rekenkracht (rood) en geheugen (blauw). Bron: IBM/Hot Chips 2023
Een belangrijke uitdaging bij complexe chips is niet alleen het verplaatsen van gegevens tussen geheugen en processors, maar overal op de chip. Network-on-chip en andere interconnect-fabrics vereenvoudigen dit proces. Siliciumfotonica wordt al een tijdje gebruikt, vooral voor snelle netwerkchips, en fotonica speelt een rol tussen servers in een rack. Maar of en wanneer het naar het chipniveau gaat, blijft onzeker. Niettemin gaat het werk op dit gebied door, en op basis van talrijke interviews in de chipindustrie staat fotonica op de radar van veel bedrijven.
Maurice Steinman, vice-president engineering bij Lightelligence, zei dat zijn bedrijf speciaal gebouwde, op fotonica gebaseerde versnellers heeft ontwikkeld die 100x sneller zijn dan GPU's met een aanzienlijk lager vermogen. Het bedrijf heeft ook optische netwerken-op-chip ontwikkeld, die meer gaan over het gebruik van silicium-interposers als medium voor het verbinden van chiplets met behulp van fotonen in plaats van elektronen.
“De uitdaging met een puur elektrische oplossing is dat het door de demping over afstand echt praktisch wordt om alleen te communiceren tussen de dichtstbijzijnde buren”, zegt Steinman. “Als er linksboven [van een chip] een resultaat is dat moet communiceren met rechtsonder, moet het vele sprongen doorlopen. Dat schept een probleem voor de softwarecomponenten die verantwoordelijk zijn voor het toewijzen van middelen, omdat ze meerdere schaakzetten vooruit moeten denken om opstoppingen te voorkomen.”
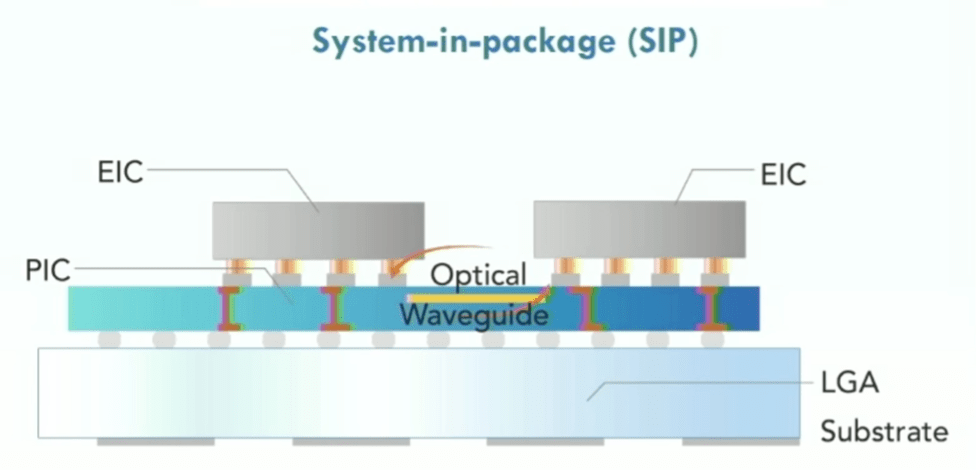
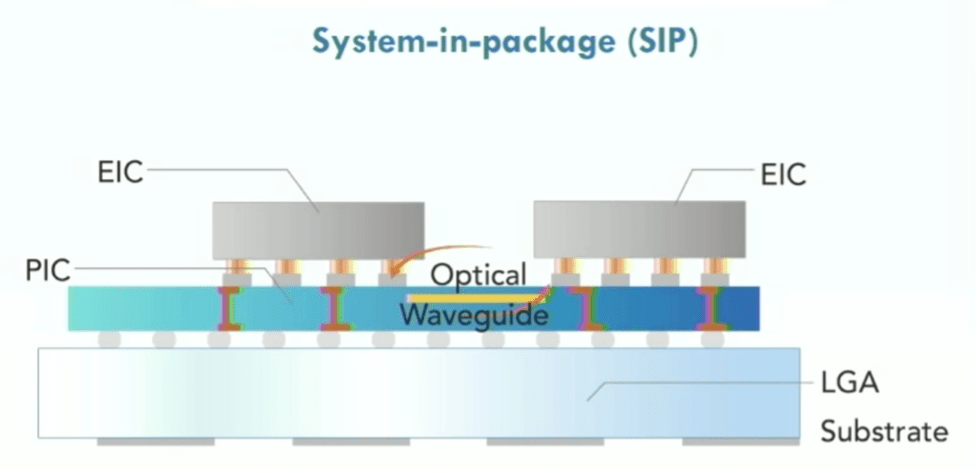
Fig. 8: Optisch netwerk op chip met fotonische geïntegreerde schakelingen (PIC), elektrische geïntegreerde schakelingen (EIC's), met behulp van land grid array (LGA) substraat. Bron: Lightelligence/Hot Chips 2023
Duurzaamheid, betrouwbaarheid en de toekomst
Met al deze veranderingen zijn er nog twee andere problemen naar voren gekomen. Eén daarvan is duurzaamheid. Naarmate meer gegevens door meer chips worden verwerkt, zal de uitdaging zelfs op het gebied van het energieverbruik blijven liggen, laat staan het verkleinen van de COXNUMX-voetafdruk. Meer apparaten die efficiënter zijn, verbruiken niet noodzakelijkerwijs in totaal minder stroom, en het kost energie om ze allemaal te produceren.
Datacenters zijn al geruime tijd een doelwit van zorg. Tien jaar geleden was de algemeen aanvaarde statistiek dat datacenters 2% tot 3% van alle elektriciteit verbruikten die op de planeet werd opgewekt. Het Amerikaanse Office of Energy Efficiency and Renewable Energy zegt dat datacenters ongeveer 2% van het totale Amerikaanse elektriciteitsverbruik vertegenwoordigen. Deze cijfers zijn niet altijd accuraat, omdat er meerdere groene energiebronnen zijn en er energie nodig is om zonnepanelen en windmolenwieken te produceren en te recyclen. Maar het is duidelijk dat de hoeveelheid verbruikte energie zal blijven groeien met de data, zelfs als dit niet in hetzelfde tempo gebeurt.
Veel van de presentaties op Hot Chips, maar ook op andere conferenties, wijzen op duurzaamheid als doel. En hoewel de onderliggende gegevens kunnen variëren, is het feit dat dit nu een bedrijfsmandaat is van veel chipfabrikanten aanzienlijk.
Een tweede probleem dat onopgelost blijft, is de betrouwbaarheid. Veel van de nieuwe chipontwerpen zijn ook ordes van grootte complexer dan eerdere generaties chips. In het verleden waren de voornaamste problemen hoeveel transistors er op een substraat konden worden gepropt en hoe te voorkomen dat de chip zou smelten. Tegenwoordig zijn er zoveel datapaden en partities dat thermische dissipatie slechts een van de vele factoren is. En naarmate de groeiende hoeveelheid gegevens wordt gepartitioneerd, verwerkt, opnieuw samengevoegd en geanalyseerd, kan de nauwkeurigheid en consistentie van de resultaten moeilijker vast te stellen en te garanderen zijn, vooral omdat apparaten anders verouderen en op onverwachte manieren met elkaar omgaan.
Bovendien verschuiven modellen van een enkele modaliteit naar vele modaliteiten – afbeeldingen, tekst, geluid en video – en van compacte modellen naar spaarzame modellen, aldus Jeff Dean, senior fellow en senior vice president bij Google Research. “Kracht, duurzaamheid en betrouwbaarheid doen er echt toe”, zei hij, waarbij hij opmerkte dat veel van de gegevens over het trainen van AI en CO2 -uitstoot is misleidend. “Als je de juiste gegevens gebruikt, zijn de zaken lang niet zo nijpend.”>
Conclusie
Vanuit puur technologisch oogpunt wijken de vooruitgang in kracht, prestatie en oppervlakte/kosten in chiparchitecturen scherp af van de verworvenheden uit het verleden. Innovatie vindt overal plaats, en routekaarten wijzen op voortdurende prestatieverbeteringen, een lager energieverbruik per berekening en lagere totale eigendomskosten.
Jarenlang werd gespeculeerd dat architecten de PPAC-vergelijking dramatisch zouden kunnen verbeteren. Hot Chips 2023 gaf een glimp van de real-world implementaties die deze verbeteringen bevatten. Innovatie is duidelijk overgedragen aan de architecten. De grote vragen zijn nu wat er daarna komt, hoe zal deze technologie worden toegepast en welke andere mogelijkheden deze veranderingen bieden. Met dit soort rekenkracht lijkt alles mogelijk.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. Automotive / EV's, carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- ChartPrime. Verhoog uw handelsspel met ChartPrime. Toegang hier.
- BlockOffsets. Eigendom voor milieucompensatie moderniseren. Toegang hier.
- Bron: https://semiengineering.com/sweeping-changes-for-leading-edge-chip-architectures/

